让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
-
论文链接:https://arxiv.org/pdf/2603.19835
TL;DR
今天解读 Qwen Pilot 团队提出的 Future-KL Influenced Policy Optimization (FIPO) 算法。该论文探讨了在大型语言模型强化学习中,现有的基于组相对策略优化(GRPO)等框架存在的“长度停滞”问题。
由于标准 GRPO 在整个轨迹上均匀分配全局优势,这种粗粒度的信用分配无法区分关键推理步骤与无关词元,从而限制了模型推理长度与性能的进一步扩展。
FIPO 提出将带有折扣因子的未来 KL 散度(Future-KL divergence)引入策略更新中,通过评估当前词元对后续轨迹行为的影响,构建了一种密集的优势加权机制。实验表明,在不引入额外价值模型(Value Model)的前提下,FIPO 使得 Qwen2.5-32B-Base 模型的平均思维链(Chain-of-Thought)长度从约 4000 个词元扩展至 10000 个词元以上,并在 AIME 2024 基准测试中将 Pass@1 准确率从 50.0% 提升至最高 58.0%。
1. 引言
在大型语言模型(LLM)的后训练阶段,强化学习(RL)已成为提升模型复杂推理能力的核心技术路径。传统的基于人类反馈的强化学习(RLHF)主要用于对齐人类偏好,而近期的研究趋势则转向利用强化学习结合可验证奖励(RLVR)来增强模型的数学和代码等客观推理能力。
目前,行业内已展现出“测试时计算缩放(Test-time scaling)”的潜力。通过在推理阶段分配更多的计算资源,模型能够生成更长的思维链和进行更深思熟虑的推理,从而在竞赛级数学和编程任务中获得显著的性能增益。然而,专有模型的具体训练算法细节尚未公开,强化学习究竟是如何作为主要催化剂,从最初不具备长思维链行为的基础模型中激发并解锁这种深度推理潜能的,仍是一个需要探索的课题。
在开源社区中,研究人员尝试在透明的设置下复现类似算法。目前的主流方法大致可以分为两类:
-
基于 PPO(Proximal Policy Optimization)的方法:这些方法依赖于广义优势估计(GAE),能够提供词元(Token)级别的密集奖励信号。但其缺点在于需要维护一个与策略模型同等规模的价值模型(Value Model,即 Critic),这带来了沉重的内存和计算开销。同时,许多 PPO 变体依赖于已经经过长思维链数据监督微调(SFT)的模型进行初始化,这引入了额外的外部知识先验。
-
基于 GRPO(Group Relative Policy Optimization)的方法:GRPO 及其变体(如 DAPO)通过组内相对奖励评估来规避价值模型的需求。然而,这种基于结果的奖励模型(Outcome-Based Rewards, ORM)只能在轨迹结束时进行二元验证,它将全局优势均匀地分配给轨迹中的每一个词元。
论文作者提出,GRPO 这种粗粒度的信用分配(Coarse-grained credit assignment)引入了结构性限制。算法对关键的逻辑转折点和无意义的填充词元赋予了同等的权重。经验观察表明,由这类基准算法训练产生的推理轨迹往往在达到中等长度后便出现停滞现象(Length stagnation)。由于均匀奖励无法凸显驱动正确逻辑的特定词元,模型无法收敛到解决困难任务所需的复杂且延伸的推理路径上。
FIPO 旨在解决这一痛点。它试图在保持 GRPO 高效性(无需价值模型)的同时,建立一种密集的优势估计公式,从而打破长链推理的性能天花板。
2. 策略优化框架预备知识
在深入介绍 FIPO 之前,论文回顾了相关策略优化框架的数学表达。设定轨迹总长度为 ,当前步骤索引为 。对于每个问题提示 ,算法采样 条轨迹,输出记为 。
2.1 PPO 框架与密集奖励
PPO 引入了一个带有裁剪机制的替代目标函数,以限制策略更新幅度,从而保持训练稳定性:
其中, 表示词元级别的概率比率, 是优势函数, 是裁剪系数。
标准 PPO 利用广义优势估计(GAE)计算 。GAE 提供特定的、词元级别的优势信号,使模型能够执行时间信用分配。这与仅从最终结果得出优势的简化公式形成对比,后者实质上向轨迹内的所有词元广播统一的信号。GAE 在生成的每一步提供密集的监督,使模型能够区分关键动作与次要动作。
2.2 GRPO 框架与全局均匀信用
GRPO 规避了计算价值网络的负担,转而通过基于组的采样来估计优势。对于给定的查询 和真实答案 ,从旧策略 中采样一组输出 。第 个样本的序列级别优势标准化为:
其中 和 分别表示采样组内奖励的经验均值和标准差。
GRPO 采用裁剪目标函数,并添加了逐词元的 KL 惩罚项:
其中 代表概率比率。
在这个设计中,计算出的标量 广播到整个序列;对于每个词元 ,其优势被统一设置为 。无论单个步骤对最终结果的实际贡献如何,GRPO 都会对轨迹中的每一步分配一致的信用。
2.3 DAPO 基准算法
DAPO 扩展了 GRPO 框架,取消了显式的 KL 惩罚项。它采用非对称裁剪机制(区间为 )来放大优势动作的更新,缓解了 GRPO 常见的熵崩溃问题。此外,DAPO 强制执行动态采样机制,确保每组样本中包含正样本和负样本的混合,从而在优化期间提供有效的非平凡梯度。论文将其作为主要的比较基准。
3. FIPO 方法论解析
建立密集的优势表达是 FIPO 的核心目标。作者团队基于前期关于强化学习如何重写基础模型的观察:强化学习仅在高度稀疏的关键词元处进行干预以保持模型在正确轨道上;带有符号的对数概率差可以精确映射优化的“方向”。并非所有词元对推理过程的贡献相同,单步的瞬时对数概率差虽然能指示优化方向,但缺乏长远视角。FIPO 的设计理念在于利用瞬时偏移构建更为准确的词元下游影响度量。
3.1 基础构建块:概率偏移
FIPO 将词元级别的概率偏移作为信用分配机制的原子单元。步骤 处的概率偏移定义为当前策略与旧策略在对数空间下的差值:
该项捕获了瞬时的策略漂移:
-
正向偏移 () :当前策略生成词元 的可能性相对于旧策略增加,这通常暗示训练目标正在强化这一特定的推理步骤。 -
负向偏移 () :当前策略抑制了 的生成,标志着更新后的模型正在主动降低该特定词元的权重。
与将其视为正则化成本的传统 KL 惩罚不同,FIPO 将 视为行为调整的方向信号,显式地将优化目标与生成动态耦合起来。
3.2 累计未来评估:Future-KL 估计
单独依赖瞬时偏移不足以捕捉决策的长期后果。推理是一个序列过程,词元的真实意义取决于它所引发的轨迹。为捕获这种因果影响,FIPO 将 Future-KL 定义为从当前步骤 到序列结束 的累积带符号概率偏移:
这一求和在数学上等同于后续序列 的联合概率分布的对数似然比。它可被解释为在未来视界内受限的样本基 KL 散度估计,测量了当前策略在剩余轨迹中偏离参考策略的累积程度。
从功能上看, 作为一个前瞻性指标:
-
表示更新后的策略总体上强化了由词元 引发的后续轨迹,暗示 作为后续推理链的稳定锚点。 -
意味着策略在集体压制 之后的未来词元,标志着由此出发的轨迹在优化过程中不再受青睐。
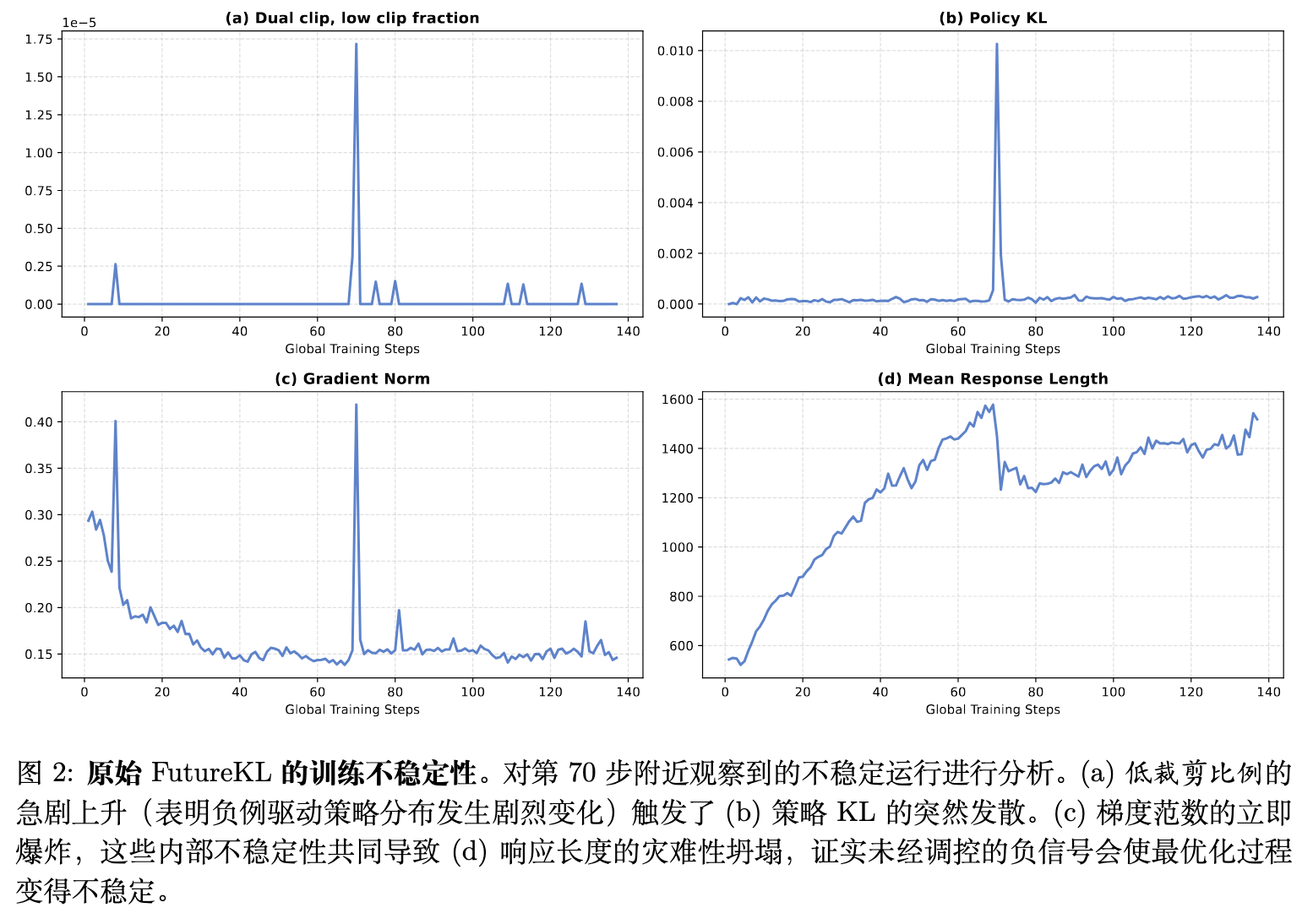
(注:图 2 展示了没有保护机制时,模型在第 70 步左右发生崩溃,负样本上的低裁剪比例急剧增加,随后出现策略 KL 散度的爆发、梯度范数飙升以及响应长度的灾难性下降。)
3.3 应对极端偏移:双重裁剪过滤机制 (Dual-Clip Filtering)
直接在优势估计中引入 会加剧由于分布偏移引起的方差问题。由于 将作为后续优势函数的加权系数,未来 logits 中的过度偏差(例如,由训练与推理不一致引起)可能会不成比例地放大比例尺,使得优化对噪声词元过于敏感。
实验发现,如果不加安全限制,训练会面临严重的不稳定性(如上述的图 2 所示)。为了解决这一问题,FIPO 显式屏蔽了超过 Dual-Clip 阈值的词元。这些词元代表梯度已经被裁剪的“有害”动作,允许其过高的重要性比率(Importance Sampling Ratios)传播到递归求和中会引入严重方差。
修改后的目标通过引入二进制掩码 来移除不稳定性源:
掩码 仅在重要性比率保持在 Dual-Clip 阈值 (通常 )内时计算为 1。这确保了触发硬约束的词元被有效排除在 Future-KL 计算之外,防止梯度爆炸。
3.4 软衰减窗口 (Soft Decay Window)
在长序列生成中,当前动作 与未来词元 之间的因果依赖关系随着时间跨度 的增加而自然减弱。紧接的后续词元直接受制于当前选择,而远处的词元则受到累积随机性的影响,可预测性降低。
为此,FIPO 引入了折扣因子 。整合该衰减项后的掩码目标为:
衰减率参数化为 ,其中 是控制未来监督有效视界(或“半衰期”)的超参数。该设置确保了信用分配集中在紧邻的推理链上,为远距离且高度不确定的词元分配较低的权重。
功能上, 定义了软衰减窗口的孔径。与在固定步数之后突然丢弃信息的硬截断不同,这种指数公式创建了一个连续滑动的窗口,允许模型在窗口 内优先考虑局部一致性,平滑滤除遥远未来的噪声。
3.5 结合裁剪的优势重加权
最后,将软衰减窗口与掩码机制集成到策略优化目标中。FIPO 提出利用未来影响权重 来调制标准优势估计 。修正后的优势 定义为:
该公式包含两个关键操作:
-
指数映射 (Exponential Mapping) :将对数空间中的累积标量信号转换为乘性域。未裁剪项在数学上表示似然比的衰减加权乘积,充当重要性权重,反映策略对所生成未来的偏好。 -
影响权重裁剪 (Influence Weight Clipping) :将乘性系数 严格限制在区间 内。这防止了指数项向梯度估计中引入过大方差,避免因对数概率极值导致数值不稳定。
当更新的策略强化后续轨迹()时,权重项 放大梯度信号。对于正优势,增强它以鼓励当前词元作为稳定锚点;对于负优势,加重惩罚以严格纠正引发此路径的错误。相反,当策略抑制未来轨迹()时, 会衰减更新,降低成功的轨迹中局部有害词元的错误奖励,并减轻失败序列中正确词元的连带惩罚。为确保训练稳定性,对于与负优势相关()且具有过高重要性比率的词元,通常会重置 以防止过度惩罚。
3.6 最终目标损失函数 (Target Loss)
采用与 DAPO 相同的词元级别公式,FIPO 最大化以下目标:
其中, 表示当前策略与旧策略之间的重要性比率, 是组相对优势, 则是上文引入的 Future-KL 重要性权重。
4. 实验设置
论文对 Qwen2.5-32B-Base 和 Qwen2.5-7B-MATH 模型进行了实验评估,以确保在数学推理任务中的严格对照。
基础设置与数据集:
基于开源的 VeRL 框架和公开的 DAPO-17K 数据集。由于研究重点在于观察强化学习如何自发地从基础模型中激发复杂的推理行为,选用 Qwen2.5-32B-Base(未接触过长链合成数据)作为主要骨干网络。
超参数配置 (以 32B 模型为例) :
-
全局批大小 (Global Batch Size) :512 -
每组样本数 (Group Size, ) :16,总计 8192 个训练样本。 -
小批量大小 (Mini-Batch Size) :DAPO 默认设置为 32,但作者观察到增加该数值能提升训练稳定性,因此 FIPO 采用 64(包含 8 次梯度更新/迭代)。 -
学习率与权重衰减:分别为 和 0.1。 -
响应长度控制:最大响应长度扩展至 20480 个词元,对超过 16384 个词元的轨迹施加过长惩罚(Overlong buffer)。 -
FIPO 特定参数:Future-KL 衰减率 设定为 32.0,影响力权重裁剪区间为 ,安全阈值(Dual Clip Ratio)设为 10.0。
评估基准:
使用 AIME 2024 作为主要验证集,结合 AIME 2025 进行补充评估。遵循多次评估范式,对每道题目生成 32 个回答,报告 Pass@1 的平均值(Avg@32)、多数投票(Cons@32)以及至少一次正确的概率(Pass@32)。生成温度设置为 1.0,Top-p 为 0.7。
5. 核心实验结果与表现
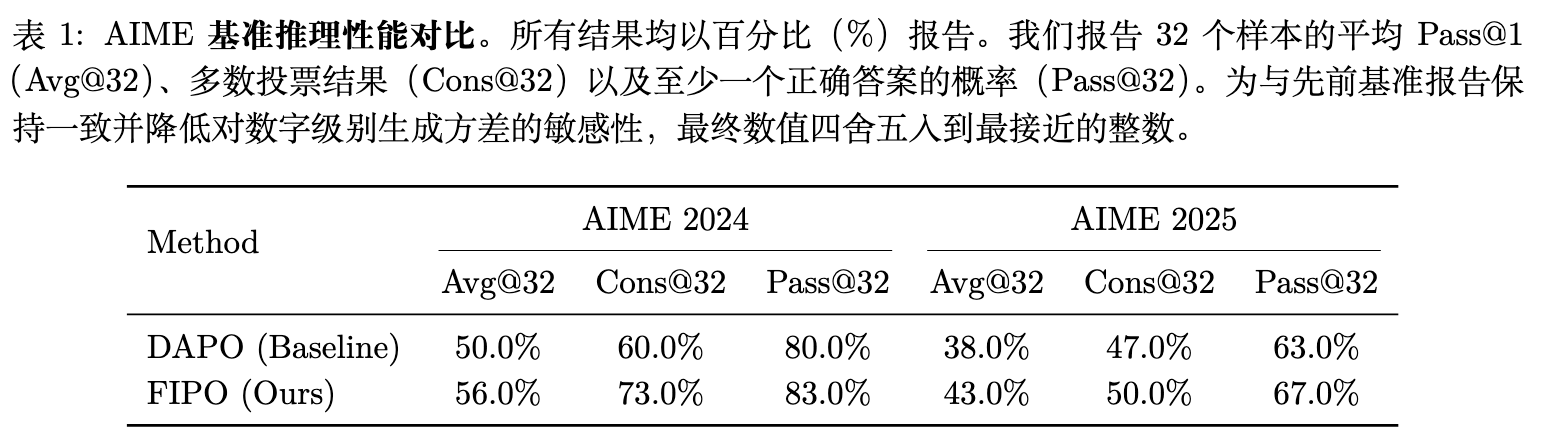
在 AIME 2024 验证集上:
-
DAPO (Baseline) :Avg@32 为 50.0%,Cons@32 为 60.0%。 -
FIPO (Ours) :Avg@32 提升至 56.0%(峰值达到 58.0%),Cons@32 提升至 73.0%,Pass@32 达到 83.0%。
在难度更高的 AIME 2025 上,FIPO 同样保持领先优势,将 Avg@32 从 DAPO 的 38.0% 提升至 43.0%。
总体而言,相较于纯 RL 基线(如复现的 DAPO),FIPO 的表现取得了系统性提升,甚至超越了如 DeepSeek-R1-Zero-Math-32B(约 47.0%)和 o1-mini(约 56.0%)等模型的报告水平。这验证了 FIPO 的密集优势构造能够有效弥补由于缺乏 Critic 模型导致的信用分配不足。
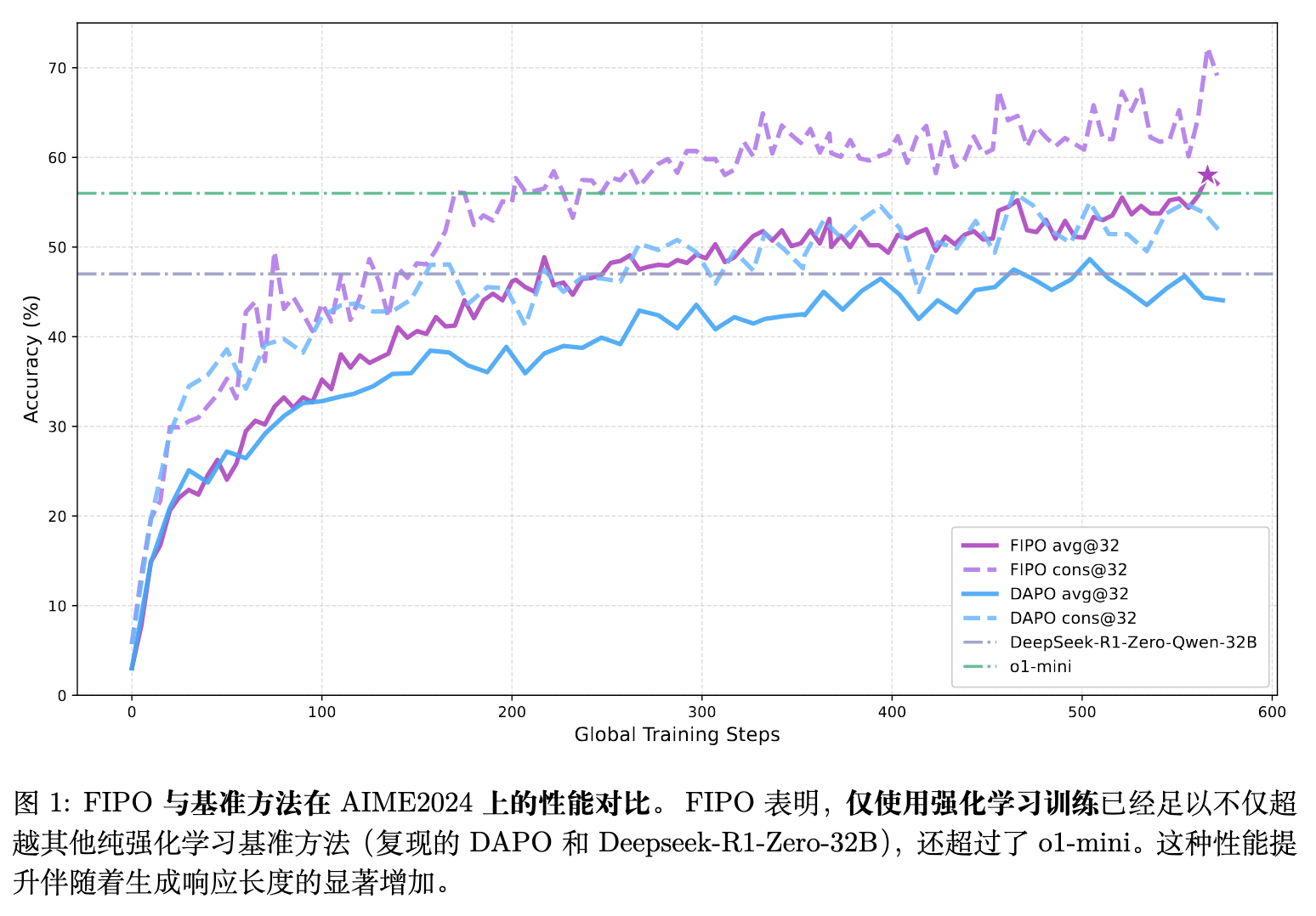
(注:图 1 直观展示了随全局训练步数增加,FIPO 的性能曲线稳步上扬并突破了 DAPO 遭遇的平台期,且这种性能收益伴随着生成长度的大幅增加。)
6. 机制分析:为什么 FIPO 能够突破性能天花板?
作者通过剖析训练动态,揭示了支撑 FIPO 有效性的三个核心机制:推理链长度与性能的协同扩展(Length-based scaling)、基于长度加权的正向学习信号,以及优化稳定性的提升。
6.1 长度扩展与性能的深度耦合
在 FIPO 训练过程中,一个处于核心位置的现象是,模型的性能收益与响应长度的连续扩展紧密相连。
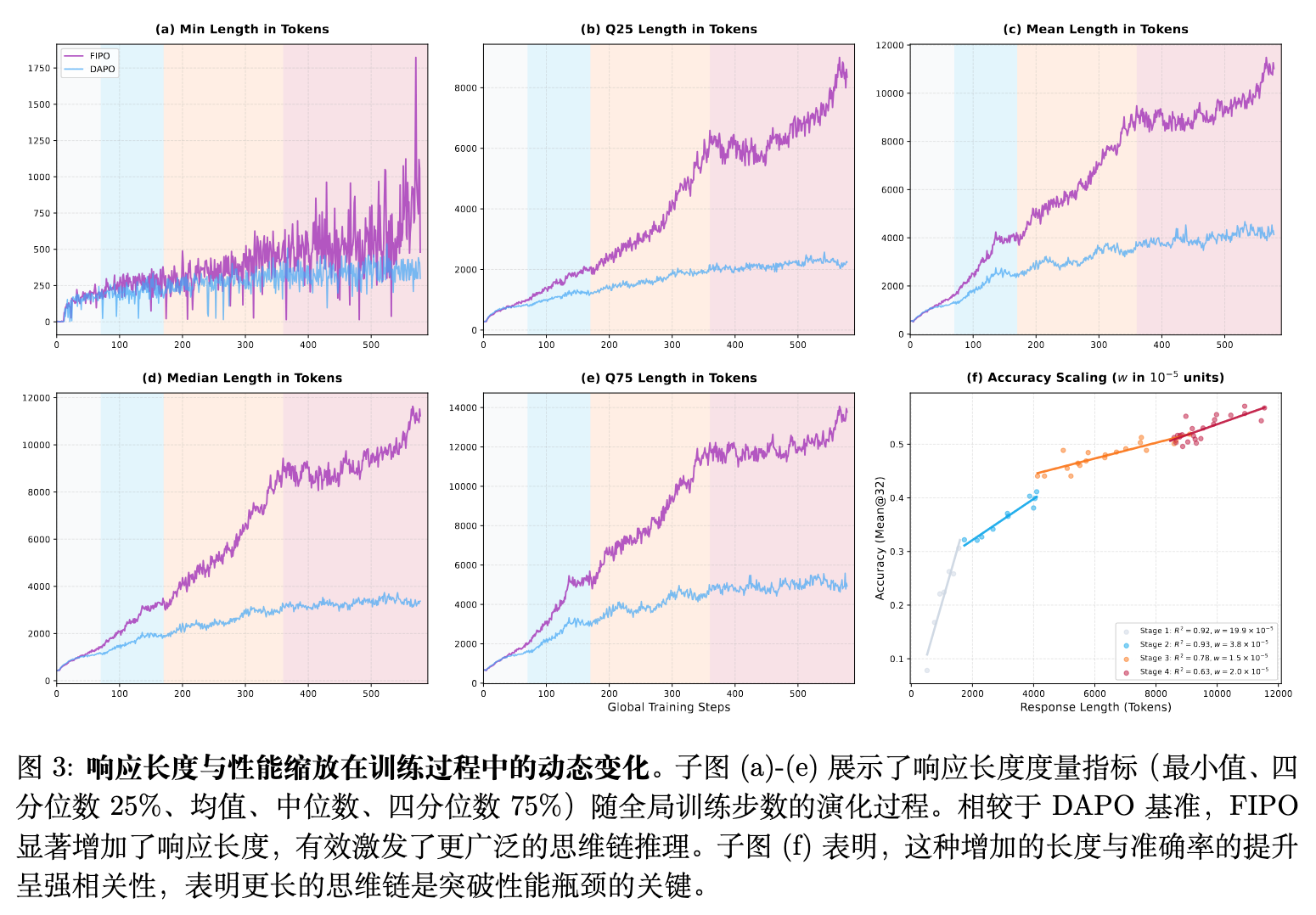
-
克服长度停滞:DAPO 的平均响应长度在最初的增长后陷入了停滞阶段,稳定在约 4000 个词元附近。与此形成对比,FIPO 表现出持续的尺度扩展能力,其中位数词元数量从最初的 200 个稳步攀升,突破了 10000 个词元。 -
全分布层面的迁移:通过分析长度的各阶百分位数(图 3(a)-(e))可以看出,这一长度的攀升并非由极个别异常长样本驱动。所有的长度分位数,从 Min 到 Q75,在 FIPO 训练下均呈现同步和稳定的上移。这种全分布层面的迁移证明,FIPO 促使了模型底层问题求解策略的根本转变,从直接回答转变为系统的自我验证推理。 -
长度兑现为准确率:图 3(f) 揭示了模型准确率与响应长度之间存在强烈的正相关关系。虽然不同训练阶段的相关系数斜率()略有波动,但轨迹始终为正。当 DAPO 由于长度停滞而遇到性能瓶颈时,FIPO 通过持续开启额外的“思考空间”,使得模型有能力应对日益复杂的逻辑依赖。
6.2 优势与持续推理增长的动态关系
作者通过分析平均训练奖励和相对优势的变化,进一步阐释了训练底层的动力学特征。
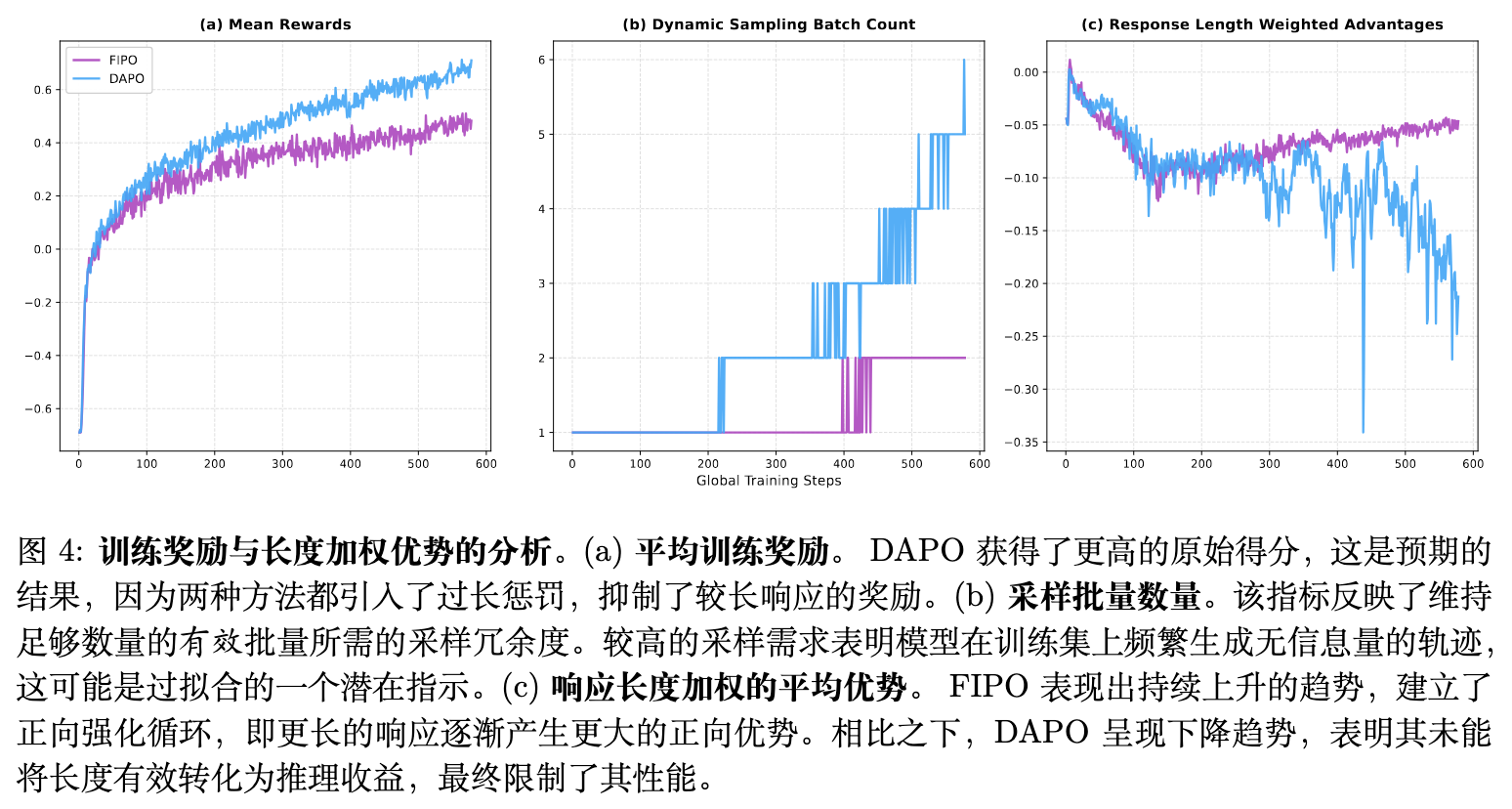
-
奖励陷阱与过度拟合:图 4(a) 显示,DAPO 在训练中持续保持着比 FIPO 更高的平均奖励。论文认为,这是奖励函数设定的数值表象而非性能优越的体现。由于奖励包含过长惩罚,FIPO 构建的复杂长推理自然受到抑制。DAPO 为了最大化直接奖励,倾向于生成短回复以规避惩罚,这使得其收敛到了一个受限搜索空间内的局部最优解。 -
批次采样率的差异:图 4(b) 记录了为收集足够的有效信息梯度而所需采样的批次数。DAPO 的批次重采样率迅速攀升,说明模型对训练集产生了过拟合,生成的样本缺乏区分度(要么全部正确,要么全部错误)。这迫使算法增加采样频率以获取有效更新。而 FIPO 能够维持稳定的低采样率,表明其主动在更广阔的空间中探索结构深度。 -
响应长度加权相对优势:图 4(c) 追踪了长度加权平均相对优势的变化。DAPO 呈现下降趋势,意味着正向样本的长度逐渐被负向样本主导,模型失去了扩展推导过程的动力。相反,FIPO 展现出一致的上升轨迹。这一现象表明,生成更长、更有效的推理链能持续获得更大的正向优势,形成了持久的自我强化正反馈循环。
6.3 平滑的策略漂移、探索与梯度更新
策略演化状态能够反映优化的平稳性。
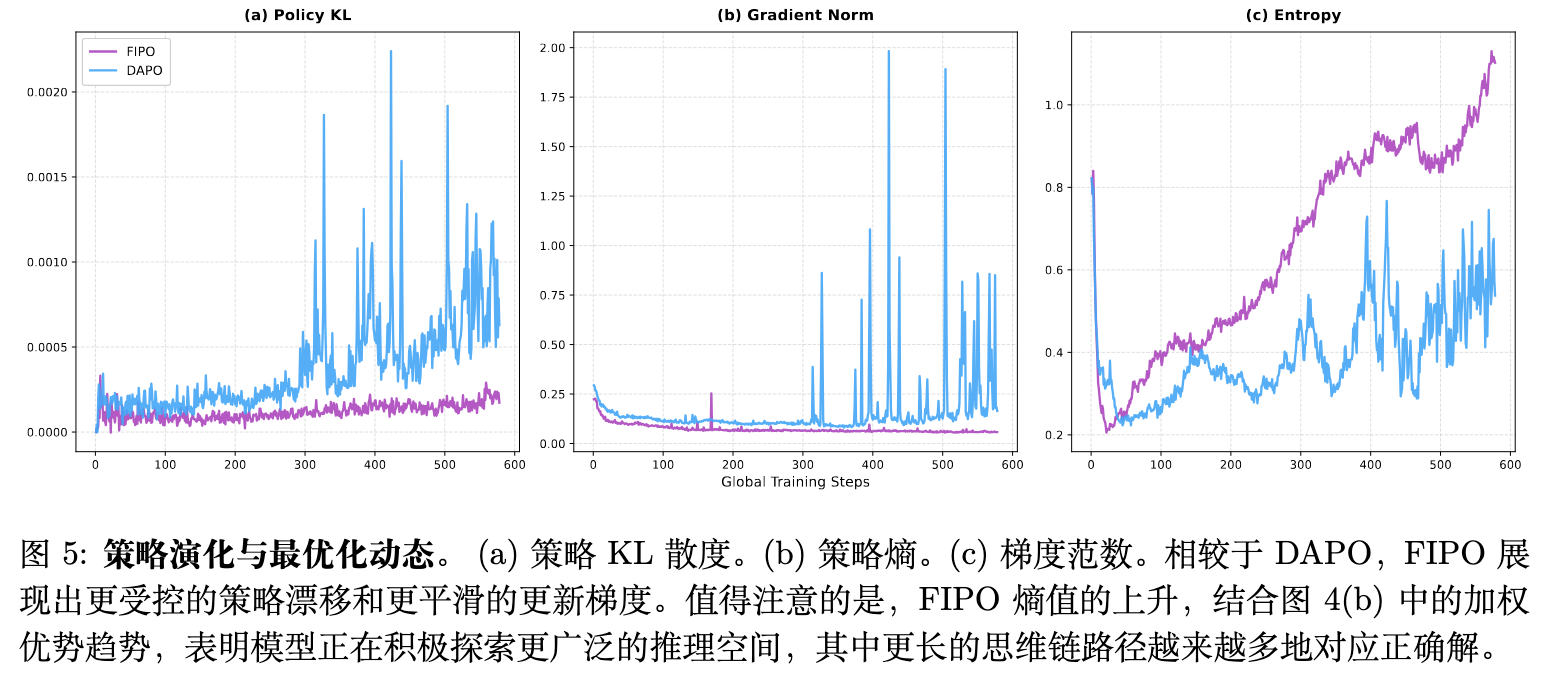
-
Policy KL:FIPO 显示出稳定和结构化的策略 KL 散度增加。这意味着模型在有序地从初始策略状态漂移,逐渐深入专门的推理领域,与实际观察到的自我反射长度逐步而非突变性增加的现象相吻合。 -
梯度范数 (Gradient Norm) :FIPO 的梯度范数在整个训练过程中维持在一致且较低的水平,反映了细粒度更新带来的平滑性。相比之下,DAPO 显示出高波动性和剧烈的突增,表明其搜索过程存在突发转向的风险。 -
策略熵 (Policy Entropy) :FIPO 维持了平滑而持续的熵上升,表明其在广阔的推理空间中保持稳定的探索能力。结合长度加权优势的上升,说明随着模型拓展搜索空间,较长的 CoT 路径越发对应正确的解。而 DAPO 的熵演变充满了噪声振荡。
7. Qwen2.5-7B-MATH 的异构表现与行为倾向分析
为了验证 FIPO 算法的通用性并在合理的计算成本下进行更充分的探究,论文在参数规模较小的 Qwen2.5-7B-MATH 模型上进行了扩展实验。在这个规模下,FIPO 同样能够优于基线,在 AIME 2024 上达到 40.0% 的 Pass@1 性能(相比之下,GRPO 为 22.0%,DAPO 为 36.0%)。
然而,在 7B 模型上的训练动态呈现出与 32B 模型大相径庭的特征。
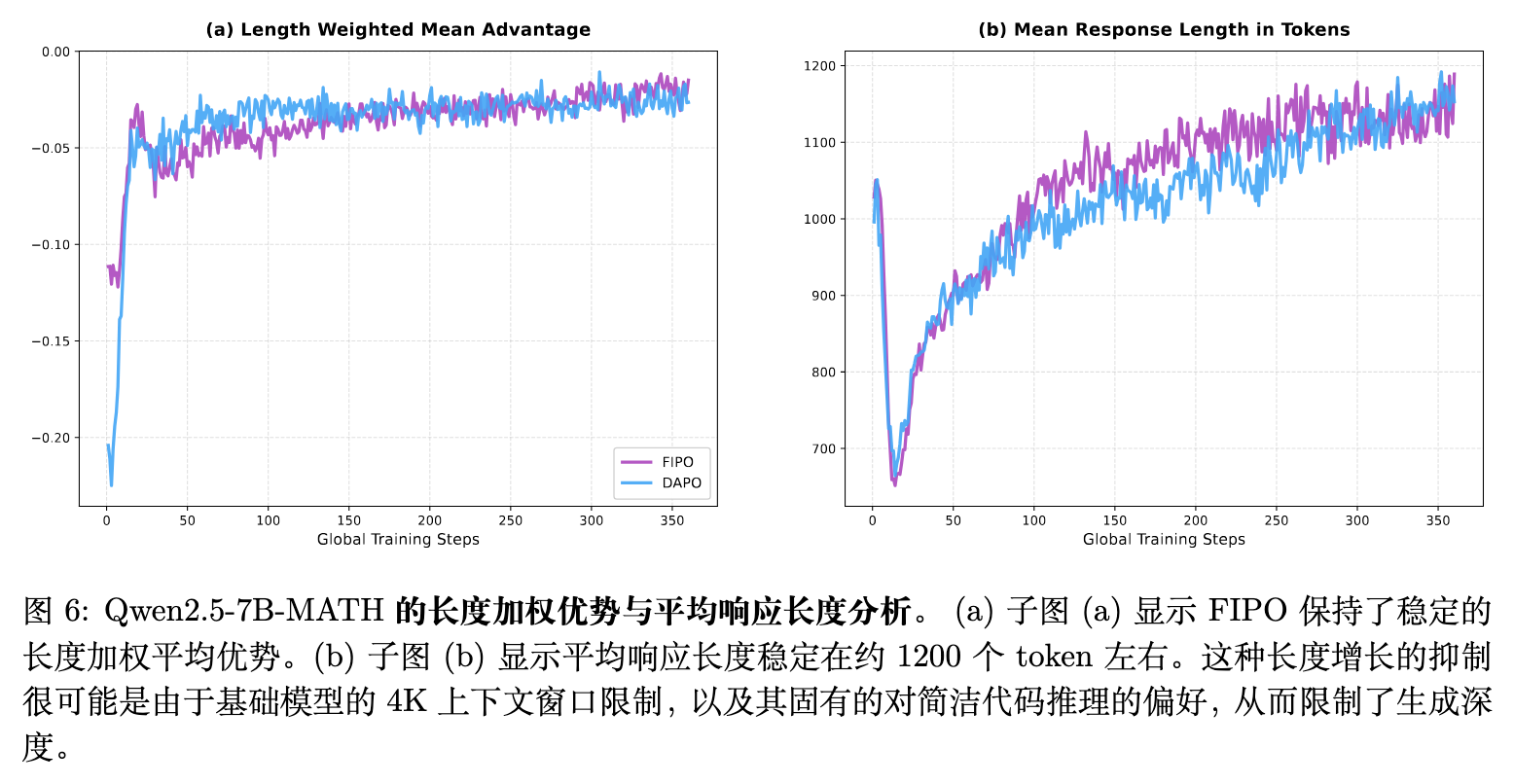
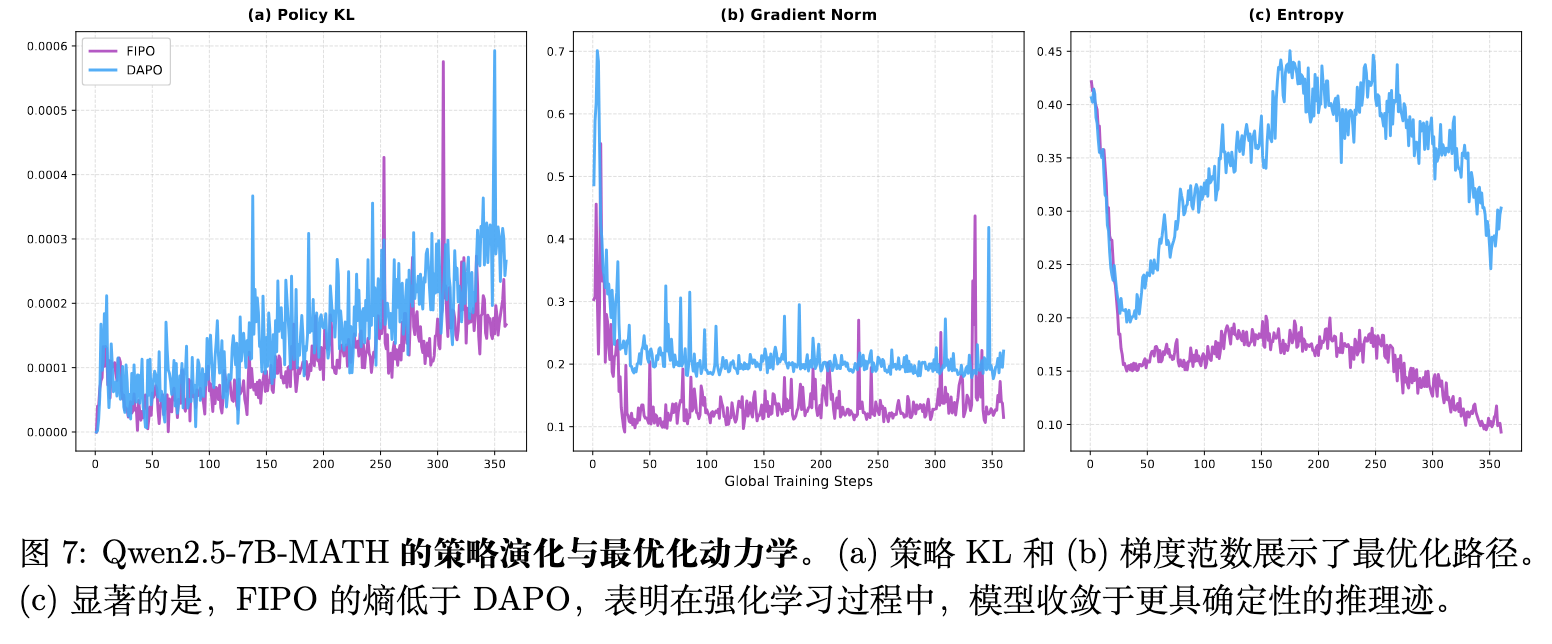
-
未出现长度指数级扩展:如图 6 所示,两个算法在 7B 模型上都保持着在 1200 个词元左右波动的平均响应长度,未表现出在 32B 模型上观察到的长程扩展。这可能源于 7B 模型的底层限制:一是其预训练主要受限于 4K 的上下文窗口,对更深推理能力设置了物理天花板;二是该模型具有强烈的代码导向先验,偏好紧凑且确定性的路径而非繁琐冗长的探索。 -
向低熵状态的收敛偏好:图 7 显示,虽然大型模型(32B)依赖熵增来探索广阔的推演空间,但在 FIPO 训练下,7B 模型却倾向于收敛向一个明显更低策略熵的状态。这表明在 7B 这个尺度下,模型缺乏足够的固有自我探索容量。因此,针对高置信度推理流形的细化聚焦(即低熵的确定性推理)比广泛探索更为有效。这一观察结果与熵最小化(Entropy minimization)及自我确定性优化等针对中小规模模型推理的理论机制不谋而合。
8. FIPO 的全面消融实验分析
论文开展了详细的消融实验,验证每个组件模块及超参数设定的必要性。
8.1 裁剪比率限制 (Clip-High) 与最大响应长度控制
论文探究了放宽限制条件(如将 PPO 目标的 调至 1.4,或将最大响应长度设定延长至 25K 个词元)对训练的影响。
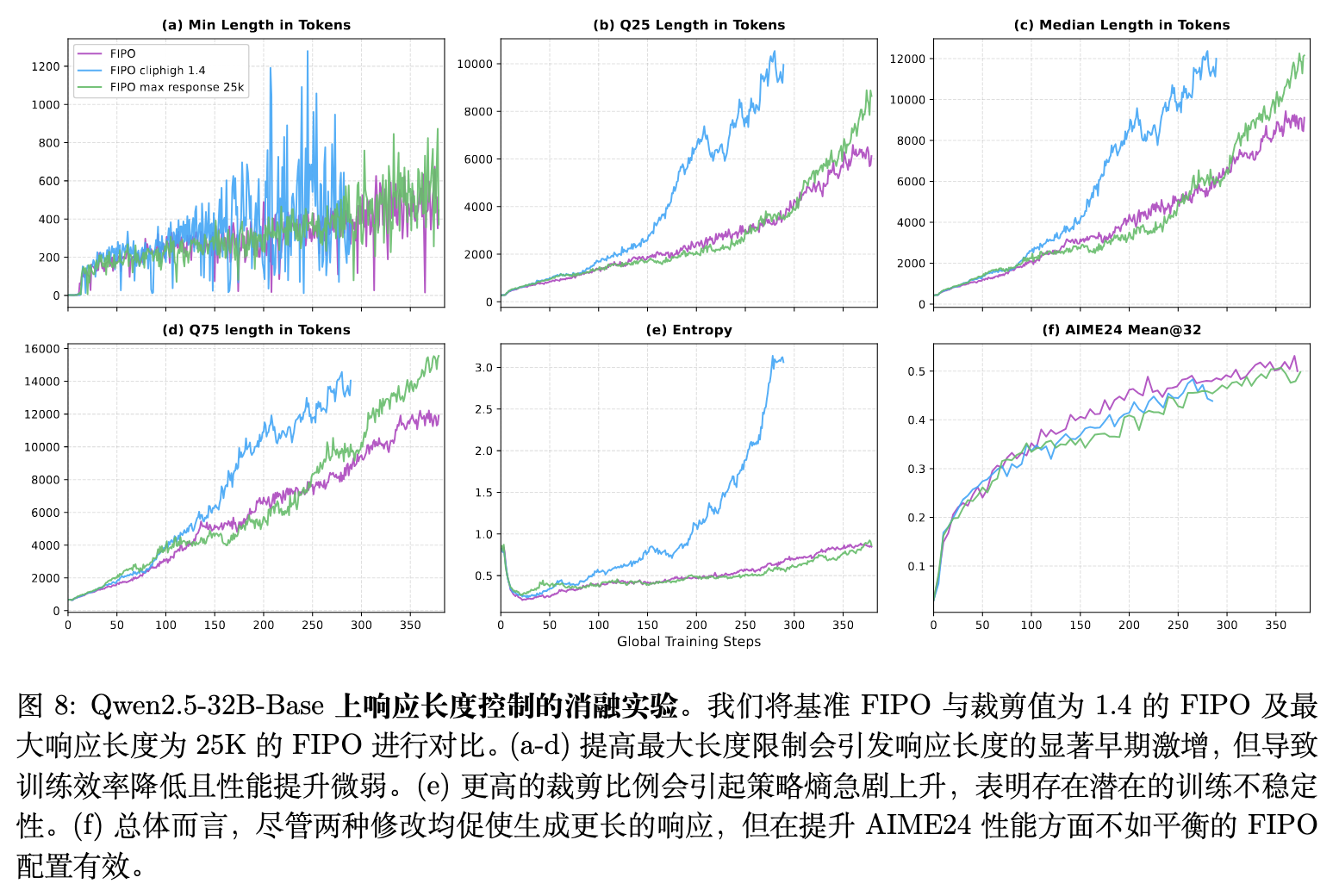
结果发现,这两种放宽操作都会在训练初期引发响应词元数量的突现式暴涨。较高的 允许模型在接收正向优势时更激烈地偏离旧分布;更大的长度缓冲则直接给出了冗余空间。
然而,这种字数激增的代价是训练稳定性的缺失和效率的低下。在放宽限制的情况下,策略熵呈现爆炸性增长,代表优化地形出现剧烈动荡。更严重的是,模型呈现出肤浅的长推理行为:它会重复相似的内容,输出与任务无关的 LaTeX 格式,或进行过早且无效的自我反思。实验表明,尚未建立坚固单步逻辑基础的模型所进行的自我反思是低效的。因此,合理的超参数配置能够约束模型沿着产生真正逻辑深度(而非冗余复核)的方向进行长度扩展。
8.2 极端值过滤机制 (Extreme Value Filtering) 的作用
Future-KL 权重的稳定性直接受重要性采样(IS)比率方差的影响。如果不加以限制,过量的比率波动将直接导致 Future-KL 失去提供稳定指引的作用。
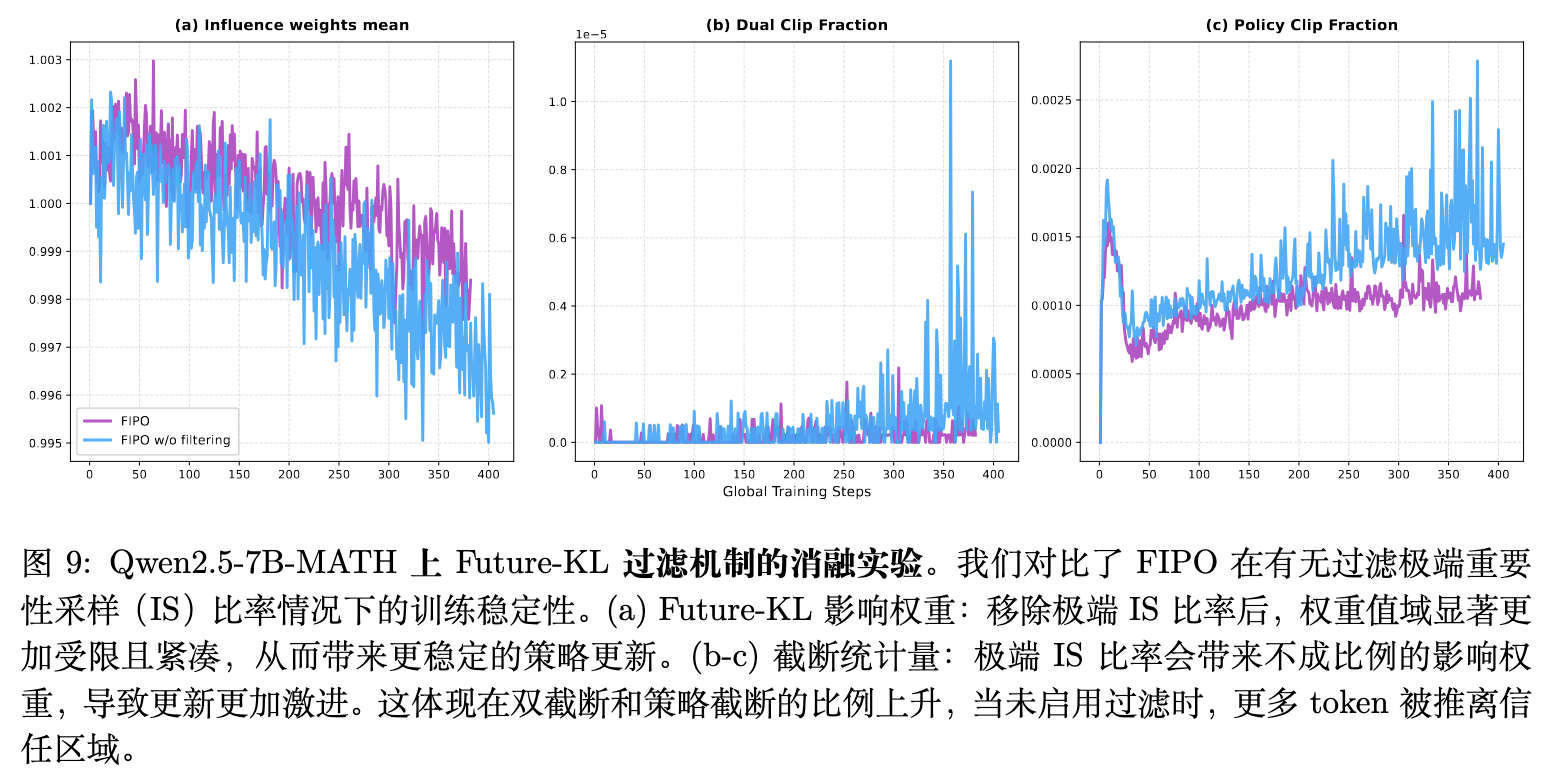
实验数据表明,移除极端 IS 比率过滤机制会导致性能回退至未优化的基线水平(从 40.0% 降至 38.0%)。图 9 的动态图显示,移除过滤后,Future-KL 的影响力权重范围被极大地拉宽,导致更高频率的激进策略更新。这直接表现为 Dual-Clip 和 Policy-Clip 截断比例急剧上升,更多词元被强行推离安全信任区,使得模型经常尝试突破目标限制,进而导致了次优的性能表现。
8.3 影响力权重裁剪 (Influence Weight Clipping) 的区间选择
对于 FIPO 将累积对数转移为权重乘子 的范围限制,作者测试了 与 的差异表现。
在 32B 模型上,由于其自身良好的探索耐受能力,设定范围在 即提供更多关于负样本的惩罚及正样本奖励的情况下,能够维持优秀的性能与熵增长。
而在 7B 模型上,设置 的均衡配置能够使得 AIME 2024 的准确率达到 40.0%,超越了 设置的 36.0%。这是因为 允许模型降低在成功样本序列中表现不佳的局部词元的奖励,并减少在错误样本序列中表现正确词元的连带惩罚。这种双向的平滑控制使得原本敏感的 7B 模型能够收敛到稳妥的低熵确定态,避免了由于 单向过度探索带来的高波动噪音。
8.4 衰减率的有效视野 (Effective Horizon of Decay Rate )
折扣因子控制的“窗口期”对 Future-KL 接收前后文信息的能力至关重要。论文考察了 时的行为。
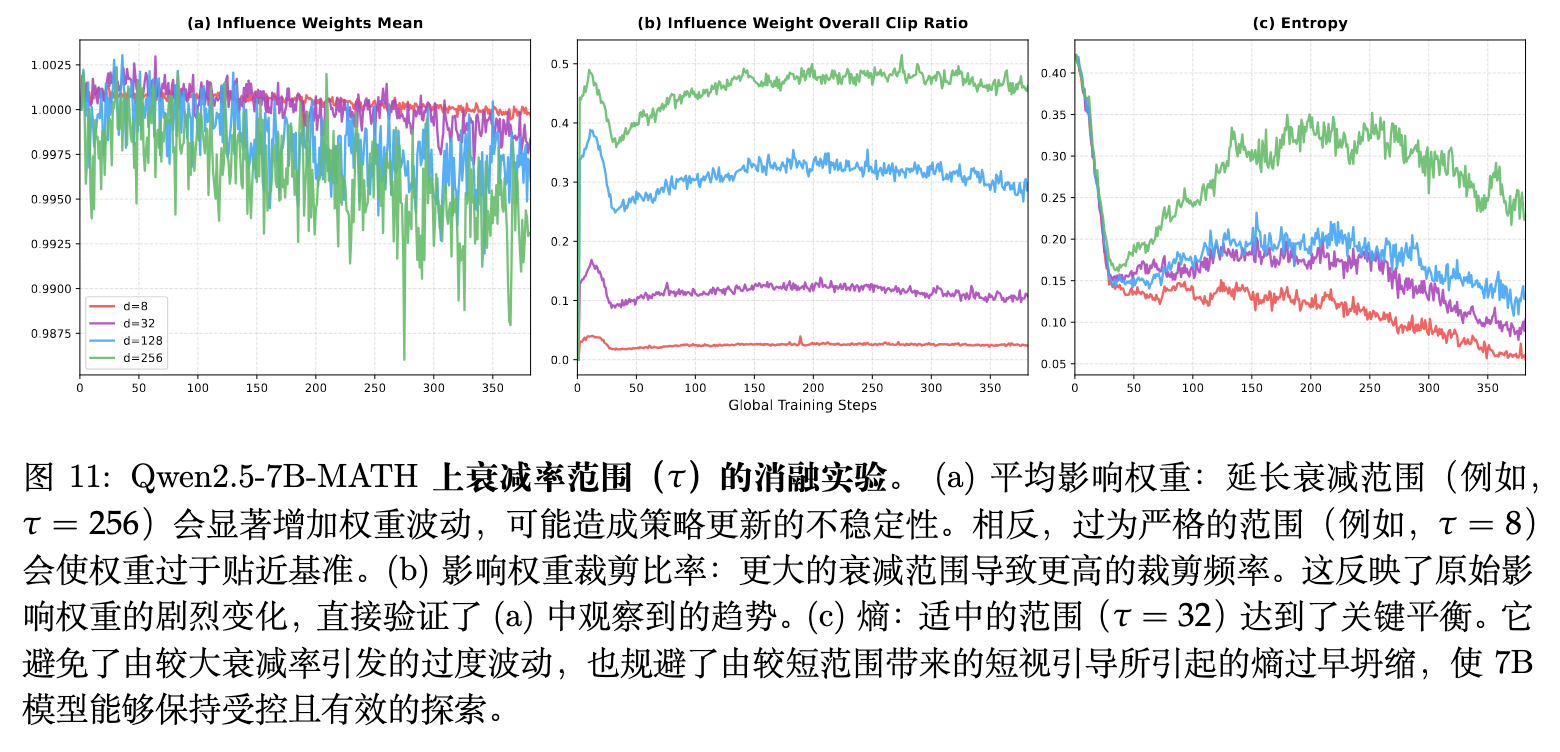
-
过短的视野 () :影响力权重几乎维持在 1.0 附近,未能充分利用未来信息的指引。这导致模型视野短视,最终引发策略过早坍塌进入次优的低熵状态。 -
过长的视野 () :权重波动幅度急剧放大,严重偏离基线 1.0。远处的长序列噪声累积导致优化出现不稳定性,模型保持着持续且过于激进的高熵探索,而其自身参数容量却难以消化这种激进的搜索信号。 -
居中平衡 () :在此数值下,FIPO 既提供了足够的局部未来信号以克服过早的停滞,又规避了远期随机性带来的波动,促成了模型在 7B 级别的高质量收敛。
9. 关于失败尝试与复现的探讨:优化稳定性与批次大小
在实践 FIPO 的过程中,论文也坦陈了探索过程中的一些曲折,并着重探讨了小批量(Mini-batch Size)对模型收敛稳定性的深刻影响。
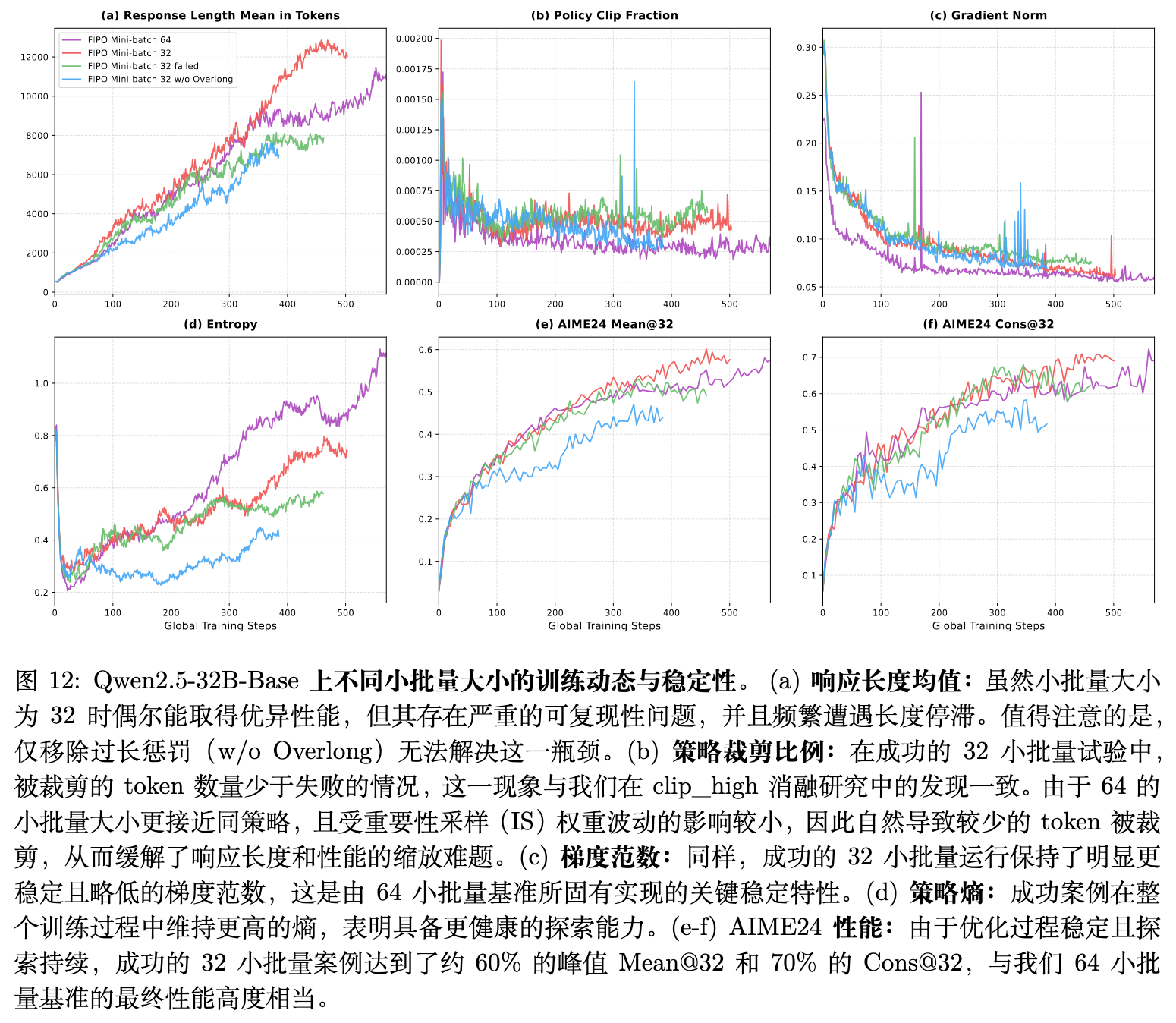
论文原本尝试采用与 DAPO 相同的 Mini-batch size = 32 进行实验。然而发现,虽然在偶尔的情况下 32 的设定能跑出较好的分数,但它存在严重的复现性危机,并频繁陷入“长度增长严重减速”的失败模式。实验证实,即使单纯移除过长惩罚机制也无法破局,表明问题的根源存在于更深层次的优化动态中。
分析表明,问题的症结在于词元裁剪率(Policy Clip Fraction)与重要性采样方差之间的平衡。当 Mini-batch size 设为 32 时,样本量偏小导致重要性权重发生高频波动,算法为了维持稳定不得不频繁触发边界裁剪将大量词元截断,这些词元便无法完全参与梯度更新信号。这就好比中断了连贯的动能供应,直接阻断了长度向更长空间延伸的动力。
而将 Mini-batch size 扩大至 64 后:
-
梯度在更广泛的样本集中进行聚合,由于计算更贴近当前的策略分布(On-policy),有效降低了重要性权重的随机波动。 -
较少的方差使得触发强制截断的词元数减少,从而允许更多的有效序列平稳通过固定边界。 -
最关键的是,这种未受破坏的优化动能确保了 FIPO 设计中的远距离前瞻性探索信号(Future KL)能够被成功且平滑地向后传播,并未被截断机制人为阻断。从而避免了模型回退至提前终结的短文本舒适区。
最终,拥有稳定梯度更新和持续活跃探索能力加持的 Mini-batch size 64 配置,实现了峰值 58.0% 的可靠输出。
10. 局限性与未来探讨方向
在论文的结尾部分,作者客观总结了 FIPO 算法当前存在的若干局限,并为社区未来的演进指明了路线:
-
成本与推理效率的权衡:FIPO 成功引出了超过 10000 词元的深度思考,但过长上下文在部署侧将带来严峻的开销问题。未来可以研究如何将冗长的推理路径提炼或压缩为更加高效、紧凑的形式。 -
泛化至更多任务域:研究的评估局限于数学领域(由于其具有可验证、逻辑密集的特性)。FIPO 引发的这些反思和长链能力是否可以自然迁移到其他开放域、代码域乃至长文本生成中,尚待考证。 -
训练数据的宽度:为了严谨对齐基准,作者限制在 DAPO-17K 数据上验证。而在更广泛和更丰富的高质量数据分布中,FIPO 所能展现出的规模扩张特性尚未探索。 -
模型范围的选择限制:此次研究重点在于探究“香草”基础模型(未见合成的长链推导数据)的潜力萌发,因此避免了测试具有已存在长期偏好的 SFT 模型。对于已历经蒸馏的模型,密集的优势设定是否能产生协同叠加的效果,需要额外研究支持。 -
与模型蒸馏之间的鸿沟:虽然强化学习能够促使模型自我演化并产生强大的推理能力,但基于试错机制的“发现主导型”进程,其效率显然仍然落后于由具有密集 logits 指导的大型教师模型直接进行蒸馏的捷径。探索如何弥合自我训练与知识提炼之间的差距依然是一道难题。
11. 结语
FIPO 论文聚焦大型语言模型强化学习中常见的痛点,深刻揭示了统一分配优势和粗粒度信用归因对复杂推理造成的阻碍。通过数学重构与算法设计,引入考虑时间衰减的 Future-KL 机制以重新校准词元优势,FIPO 实现了无需额外 Critic 成本的密集奖励分发路径。实验中所观测到的思维链长度突破、自我验证能力的涌现、以及向低熵收敛等现象,均显示出这一方法的有效性和理论潜力。配合公开的代码实现和细致的消融分析,FIPO 能够为学术界和开源社区开展高难度计算任务的大规模强化学习研究提供一条可资借鉴的有力路线。
更多细节请阅读原文。
往期文章:


