让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
-
论文链接:https://arxiv.org/pdf/2605.05242
TL;DR
今天解读一篇来自得克萨斯A&M大学、滑铁卢大学、斯坦福大学、华盛顿大学等机构的论文《Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction》。在当前的大语言模型(LLM)应用中,检索增强生成(RAG)和智能体搜索(Agentic Search)通常依赖于预先构建的向量索引和固定的 Top- 检索接口。本文指出,这种将语料库压缩为固定相似度接口的抽象方式,虽然在传统搜索中效率很高,但对于具备复杂推理能力的智能体而言,已经成为一种信息瓶颈。严格的词汇约束、稀疏线索的组合、局部上下文的核查以及多步假设的修正,很难通过调用现成的语义检索器来实现。
为了解决这一问题,作者提出了一种全新的检索范式:直接语料库交互(Direct Corpus Interaction, DCI)。在这种范式下,智能体不依赖任何嵌入模型、向量索引或检索 API,而是直接使用通用的终端工具(如 grep、文件读取、Shell 命令、轻量级脚本)在原始语料库中进行搜索。这种方法无需离线索引,能够自然适应不断变化的本地语料。
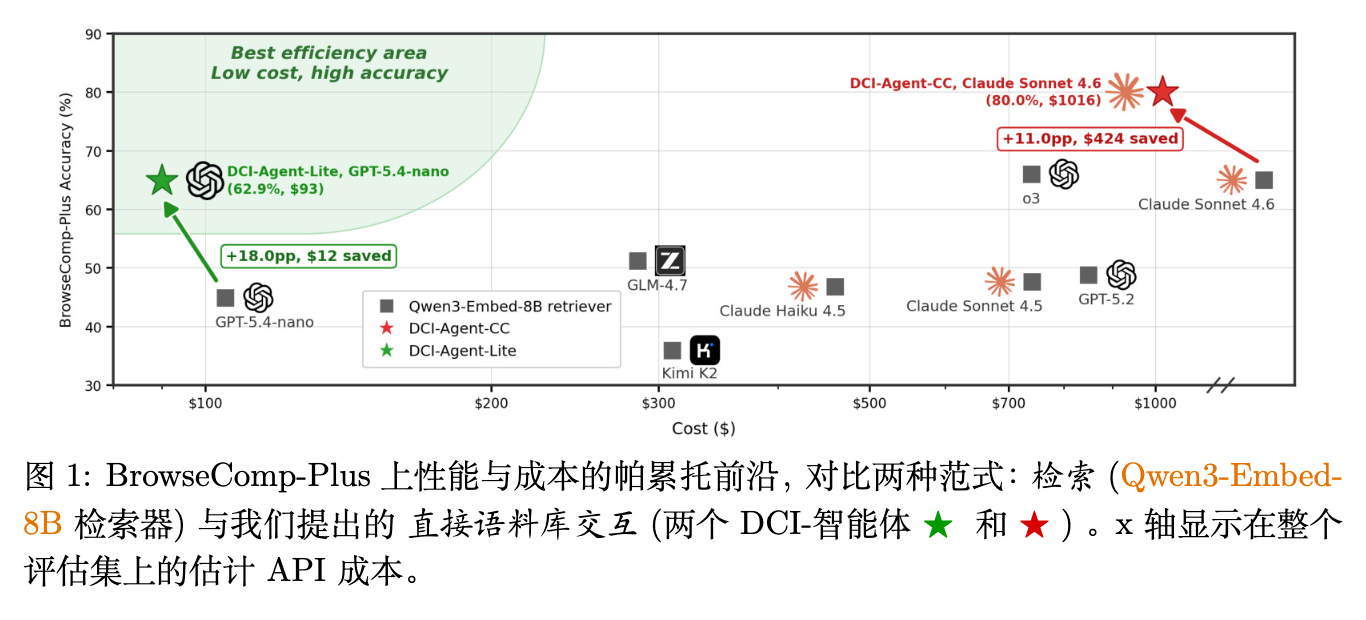
实验表明,在 BrowseComp-Plus、多跳问答(Multi-hop QA)以及信息检索(IR)基准测试中,DCI 范式在不依赖传统语义检索器的情况下,取得了优于强稀疏检索、稠密检索和重排基准的结果。例如,在 BrowseComp-Plus 上,使用相同的 Claude Sonnet 4.6 基座,DCI 将准确率从 69.0% 提升至 80.0%,同时将 API 成本降低了 29.4%。作者引入了检索接口分辨率(Retrieval Interface Resolution)这一概念来解释 DCI 的优势:DCI 的成功并不主要来源于召回了更多的Golden文档,而是通过高分辨率的接口,将已发现的初步证据转化为更高价值的细粒度局部搜索和验证步骤。
1. 引言
在语言智能体(Language Agents)的研究中,检索系统是模型访问和感知外部语料库的主要接口。这一接口支撑了广泛的应用,包括检索增强生成(RAG)、开放域问答以及深度研究(Deep Research)。在标准的 RAG 流水中,文档首先被切分(Chunking)、建立索引,并通过稀疏检索(如 BM25)或稠密检索过滤出一个 Top- 的候选集合,随后再交由下游模型进行推理。
随着智能体时代的到来,检索智能体(Retrieval Agents)能够进行迭代规划、查询重写和阅读,从而实现更复杂的多轮搜索行为。然而,这种增加的灵活性仍然受限于一个固定的、现成的检索接口。该接口在每一步只暴露语料库的 Top- 切片。在诸如 BrowseComp-Plus 这样需要智能体组合多种操作(例如:发现中间实体、聚合稀疏线索、强制执行精确的词汇匹配、在检查局部上下文后修改搜索计划)的基准测试中,这种限制变得尤为明显。在这些需求下,受限的证据暴露阻碍了智能体的有效探索。因此,性能瓶颈不仅来自检索后的推理能力,也来自检索接口本身。
为了突破这一瓶颈,本文将直接语料库交互(DCI)定位为智能体搜索的新型检索接口。智能体不再查询传统的语义检索器或检索 API,而是使用通用的终端工具(如 grep、简单的文件读取、Shell 命令和轻量级脚本)直接搜索原始语料库。没有任何现成的嵌入模型、向量索引或 Top- 接口在中间进行干预:整个语料库对智能体保持开放,语义解释的权责被下放给了智能体自身。
当智能体具备足够的战略搜索能力时,DCI 提供了一组小巧但高度灵活且可组合的操作原语,用于语料库探索(例如 find)、精确匹配(例如 grep)、局部检查(例如 head、tail 或 sed)以及迭代细化。此外,这些操作可以通过管道(Pipeline)连接起来,以执行词汇约束(例如 grep 'foo' file | grep 'bar')、组合弱线索(例如 find . | grep 'report' | grep '2024'),并对照局部上下文验证假设(例如 grep -n 'keyword' file | head)。
2. 直接语料库交互 (DCI) 范式
本文对比了智能体在搜索过程中访问语料库的两种广泛范式。
在检索器中介访问(Retriever-Mediated Access)中,语料库交互由传统的检索器作为中介:智能体构建一个查询,接收一个排好序的 Top- 文档或片段列表,并根据返回的候选结果通过重写查询来进行迭代。在这种设置下,智能体的观察结果在很大程度上受限于检索器选择暴露的内容(通常是简短的片段加上文档标识符),并且所有证据都必须经过检索器的打分和排序接口。
在直接语料库交互(DCI)中,智能体绕过任何嵌入模型、向量索引或检索 API,而是通过通用的命令行接口直接与原始语料库交互。具体而言,智能体发出工具调用,如使用 grep 和 rg 进行精确或正则表达式匹配,使用 find 和 glob 进行结构导航,以及使用目标文件读取或轻量级脚本来检查匹配项周围的局部上下文。因此,由此产生的观察结果是工具输出(例如,带有周围上下文的匹配跨度、文件路径、计数和元数据),而不是固定格式的排序列表。
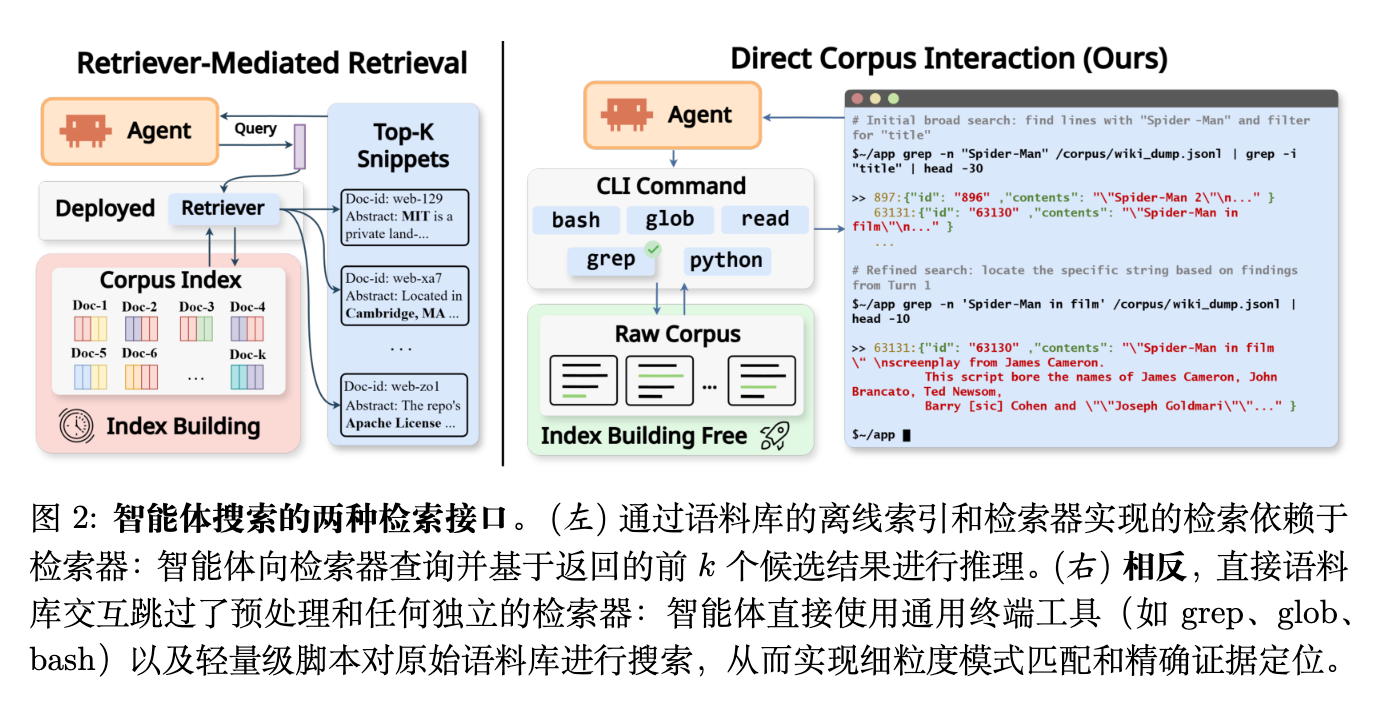
为了分离接口变化带来的核心影响,作者在两种智能体脚手架(Scaffolds)下实例化了 DCI:
2.1 DCI-Agent-Lite:极简脚手架
为了尽可能干净地隔离接口变化,作者引入了 DCI-Agent-Lite。这是一个基于 Pi 框架改造的轻量级终端编码智能体,仅限于原始终端交互。该智能体通过 bash 和文件读取访问语料库,使用通用的 Shell 操作(如 grep 和 rg 进行词汇匹配,find 和 glob 进行文件发现)以及轻量级脚本。
重要的是,DCI-Agent-Lite 不包含任何特定于检索的模块:没有离线索引,没有稠密检索器,也没有重排器。这种极简的脚手架使得控制实验成为可能,在这些实验中,性能的提升可以主要归因于 DCI 范式本身。在默认设置下,DCI-Agent-Lite 使用 GPT-5.4 nano 作为基座模型,提供了一个在严格预算约束下评估 DCI 的轻量级环境。
2.2 DCI-Agent-CC:更强的脚手架
为了探索在能力更强的工具框架下该范式的性能上限,作者还使用 Claude Code 实现了一个现成的 CLI 智能体,命名为 DCI-Agent-CC。与 DCI-Agent-Lite 相比,它提供了更强的提示词(Prompting)、更稳健的工具编排以及内置的上下文处理机制,这些共同提高了在长周期搜索和异构语料库上的稳定性。
需要注意的是,DCI-Agent-CC 被视为 DCI 的一个更强实例化,而不是一种不同的检索方法:它仍然纯粹通过终端工具在原始语料库上运行,不调用任何嵌入检索器或检索 API。DCI-Agent-CC 使用 Claude Sonnet 4.6 作为基座模型,以探测在放宽预算约束时的性能天花板。
3. 运行时上下文管理
在长周期的搜索轨迹中,连续的 grep 和 rg 调用可能会返回大量匹配项,打开文件或提取周围上下文会暴露长篇的文本。这些观察结果会迅速积累,并可能超出模型有限的上下文窗口。因此,运行时系统必须平衡两个相互竞争的需求:(1) 保留证据和中间约束以供后续推理使用;(2) 为搜索过程中产生的新观察结果腾出空间。
为了支持长周期 DCI,作者为 DCI-Agent-Lite 配备了一个轻量级的运行时上下文管理层。该层围绕三种机制构建:
-
截断(Truncation):在将每次工具调用的文本重新插入实时工作上下文之前设定上限,在限制单轮冗长度的同时保留观察发生的记录。 -
压缩(Compaction):这是一种内存中的零 LLM(Zero-LLM)操作。一旦累积的工具输出超过配置的阈值,它会清除较旧的工具结果轮次的内容,用保留工具调用结构的简短占位符替换这些轮次。 -
摘要(Summarization):这是一种干预程度更高的策略。在额外的上下文压力下,它用模型生成的摘要替换压缩的历史记录,同时保持最近的上下文完好无损。
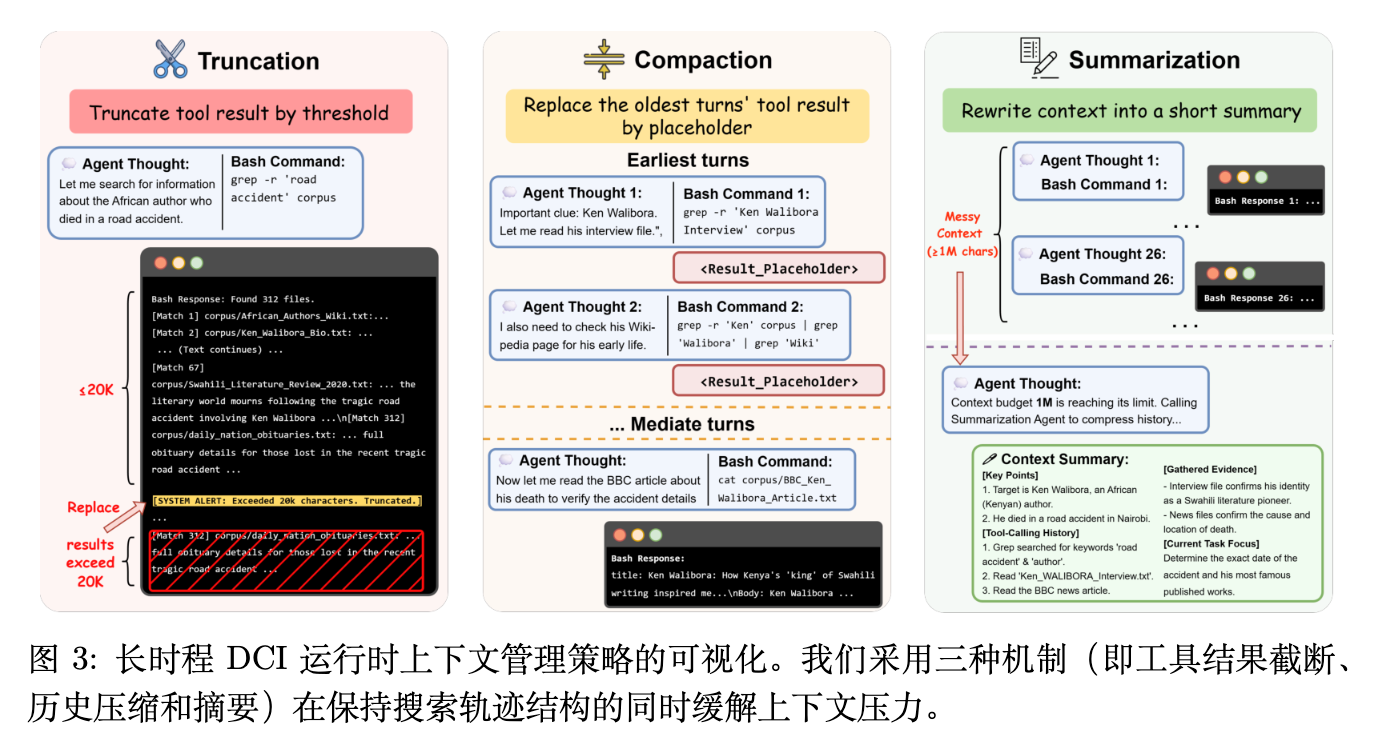
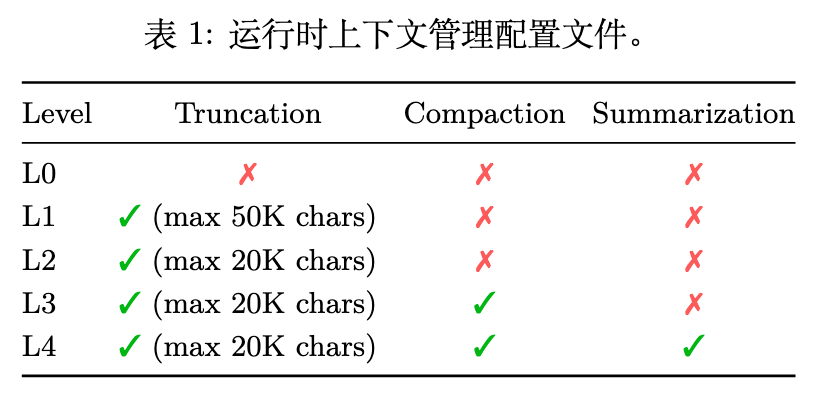
作者实现了一系列上下文管理策略(L0 到 L4),以不同的激进程度启用这些机制的子集。例如,L0 不执行任何上下文管理;L1 仅应用截断(将每个工具结果限制为 50,000 个字符);L3 在截断的基础上增加了压缩(当累积的工具结果内容超过 240,000 个字符时触发,并压缩除最近 12 轮之外的所有轮次);L4 在压缩后进一步调用摘要。
这些策略不会改变检索接口本身,它们只改变在长周期搜索期间,有多少通过工具获取的证据能够在模型的工作上下文中存活下来。
4. 评估指标:覆盖率与定位度
下游任务的答案准确率固然是评估 DCI 的重要指标。然而,单靠准确率不足以捕捉 DCI 和传统检索器中介访问在成功或失败方式上的质的差异。
检索器中介访问通常提供高水平的召回率(Recall),但对精确字符串匹配、弱词汇信号的组合以及触发下一步的精确跨度级别线索提供的控制有限。相比之下,DCI 暴露了一个高分辨率(High-resolution)的搜索接口:一旦智能体到达一个有用的文档,它可以直接探测特定术语,打开完整文件,提取新实体或约束,并立即启动基于局部证据的后续搜索。
为了在过程层面表征这些差异,作者引入了两个轨迹级别的指标:覆盖率(Coverage)和定位度(Localization)。
4.1 覆盖率 (Coverage)
覆盖率衡量轨迹是否触及了相关的(黄金)文档,反映了广泛的证据访问能力。
形式上,设 表示问题 的 Golden 文档集合,设 表示沿轨迹 浮现的 Golden 文档。在这里,当一个文档明确出现在记录的轨迹中时(无论是作为检索到的片段还是作为工具调用返回的文件),即被视为"浮现(Surfaced)"。
作者报告了三个覆盖率聚合指标:
-
衡量轨迹是否至少浮现了一个 Golden 文档。 -
是每个 Golden 文档是否浮现的平均值(即传统的召回率 Recall)。 -
衡量是否浮现了完整的黄金集合。
经验上,这些覆盖率得分是"触达(Reach)"指标,它们反映的是广泛的证据访问,而不是浮现文档内细粒度的证据使用。
4.2 定位度 (Localization)
定位度衡量轨迹在每个浮现的 Golden 文档中,缩小到一个小而可用的证据跨度的效率,反映了文档内的证据隔离能力。
设轨迹 包含一系列观察结果。对于每个观察结果 ,定义 ,其中 是观察结果 中暴露的项数, 是相应的文档, 是为 暴露的片段, 是其字符长度。
定位度基于以下归一化函数构建:
并规定 。这里 将字符长度映射到固定宽度的字符段(Segment)数量(段长度 ),而 在 相对于 较小时分配较高的分数。
对于观察结果 中与 Golden 文档 对齐的第 个候选者 ,定义段级别得分(Seg-score):
该分数衡量暴露的片段在完整 Golden 文档中的定位程度,当暴露的跨度相对于文档较小时,分配较高的值。
对于每个浮现的 Golden 文档 ,设 为轨迹 中对齐候选者的集合。定义 上的最佳定位度为:
然后对浮现的 Golden 文档进行聚合:
简而言之, 是每个浮现的 Golden 文档所达到的最佳段级别得分的轨迹级平均值。高定位度得分表明智能体不仅到达了相关文档,而且从中提取了集中的证据。
5. 实验设置
作者在三个基准测试系列上评估了 DCI 智能体:
-
智能体搜索(Agentic Search):使用 BrowseComp-Plus 评估智能体的深度研究能力。该基准包含闭源语料库,要求检索和综合多个文档中的证据。对于检索智能体基线,使用基于 Qwen3-Embedding-8B 构建的 FAISS 索引作为离线搜索引擎。对于 DCI,智能体通过终端工具访问同一语料库,没有任何索引。 -
知识密集型问答(Knowledge-Intensive QA):包括 NQ、TriviaQA、Bamboogle、HotpotQA、2WikiMultiHopQA 和 MuSiQue,用于评估通过语料库搜索进行的多跳 QA。语料库使用 2018 年的维基百科转储。 -
信息检索排序(IR Ranking):包括 BRIGHT 基准测试中的四个数据集(生物、地球科学、经济和机器人)和 BEIR 基准测试中的两个数据集(ArguAna 和 SciFact)。
对比基线分为两类:
-
检索智能体(Retrieval Agents):在 BrowseComp-Plus 上,使用配备 BM25 和 Qwen3-Embedding-8B 的官方智能体搜索流水线,搭配 GPT-5.2、o3、GLM-4.7、Claude Sonnet 4.5 和 Claude Sonnet 4.6。在知识密集型 QA 上,对比 R1-Searcher、Search-R1、ZeroSearch、Verl-Tool-Search 和 ASearcher。 -
稀疏与稠密检索(Sparse & Dense Retrieval):在 IR 排序上,对比 BM25、OpenAI-text-embedding-3-large、GTE-Qwen2-7B-Instruct,以及面向推理的重排器 Rank-R1、Rank1 和 ReasonRank。
6. 主要实验结果
核心问题 1:成熟的 DCI 智能体是否已经能取得强劲的性能?
答案是肯定的。作者在三个代表性设置中提供了一致的证据。
6.1 智能体搜索结果
在 BrowseComp-Plus 上,用 DCI 替换传统的检索器带来了实质性的收益。具体而言,使用相同的 Claude Sonnet 4.6 基座,用 DCI 替换 Qwen3-Embedding-8B 将准确率从 69.0% 提高到 80.0%(提升了 11.0 个百分点),同时将成本从 1440 美元降低到 1016 美元(降低了 29.4%)。
值得注意的是,DCI-Agent-CC 不仅优于其匹配的检索对应物,而且超越了整体最强的检索基线(GPT-5.2 + Qwen3-Embedding-8B,准确率 71.7%),高出 8.3 个百分点。同时,DCI-Agent-Lite(GPT-5.4 nano)在性能和成本之间取得了良好的平衡:它以仅 93 美元的成本实现了 62.9% 的准确率,与 o3 + Qwen3-Embedding-8B(66.0%)等强检索智能体保持竞争力,同时降低了 647 美元的成本。
6.2 知识密集型 QA 结果
如表 1 所示,DCI 智能体在知识密集型 QA 上始终超越检索智能体基线。DCI-Agent-CC 达到 83.0% 的平均准确率,超过最强基线 ASearcher-Local-14B(52.3%)达 30.7 个百分点。DCI-Agent-Lite 也具有竞争力,达到 68.0%。
在多跳基准测试中,收益尤为明显:相对于 ASearcher-Local-14B,DCI-Agent-CC 在 HotpotQA 上提升了 30 个百分点,在 2Wiki 上提升了 26 个百分点,在 MuSiQue 上提升了 50 个百分点。在所有六个数据集中,DCI-Agent-CC 和 DCI-Agent-Lite 占据了前两名,表明 DCI 是传统 RAG 流水线在复杂多步证据聚合和推理方面的强大替代方案。
6.3 信息检索排序结果
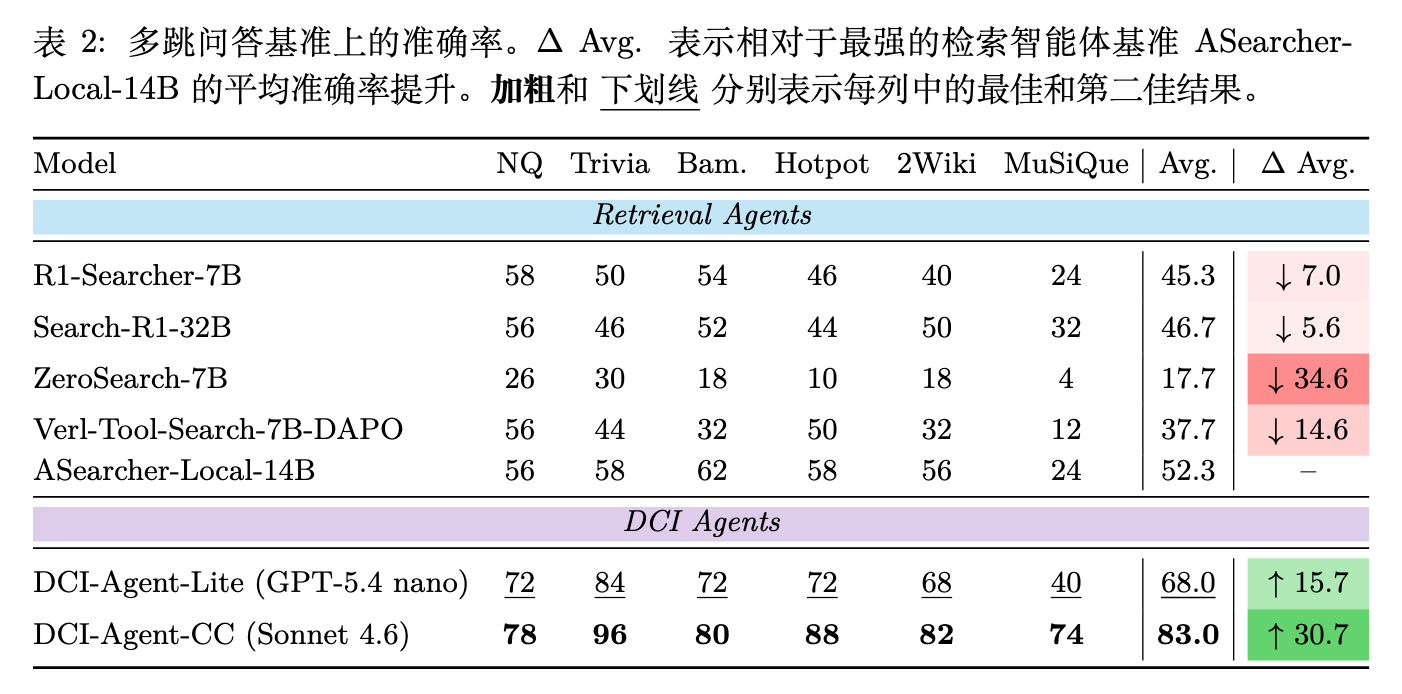
如表 2 所示,DCI 智能体在 IR 排序方面比传统的检索基线表现出明显的优势。DCI-Agent-CC 在所有六个数据集上均获得了最佳的 NDCG@10 分数(平均 68.5%),超过了最强的检索基线 ReasonRank-32B(47.0%)达 21.5 个百分点。DCI-Agent-Lite 保持高度竞争力,以 56.7 的平均 NDCG@10 排名第二,仍比最强检索基线高出 9.7 个百分点。
综合来看,这些结果表明 DCI 是一种极具前景的运行机制,在多样化的检索和推理任务中将强大的性能与有利的成本效率结合在一起。
7. 机制分析与消融实验
为了弄清楚 DCI 为什么有效,作者进行了细致的轨迹分析和消融实验。
7.1 为什么 DCI 有效?(RQ2)
作者发现,DCI 的优势较少来源于更高的 Golden 文档召回率,而更多来源于通过灵活的、可组合的 bash 命令对证据进行细粒度的发现、组合和使用。
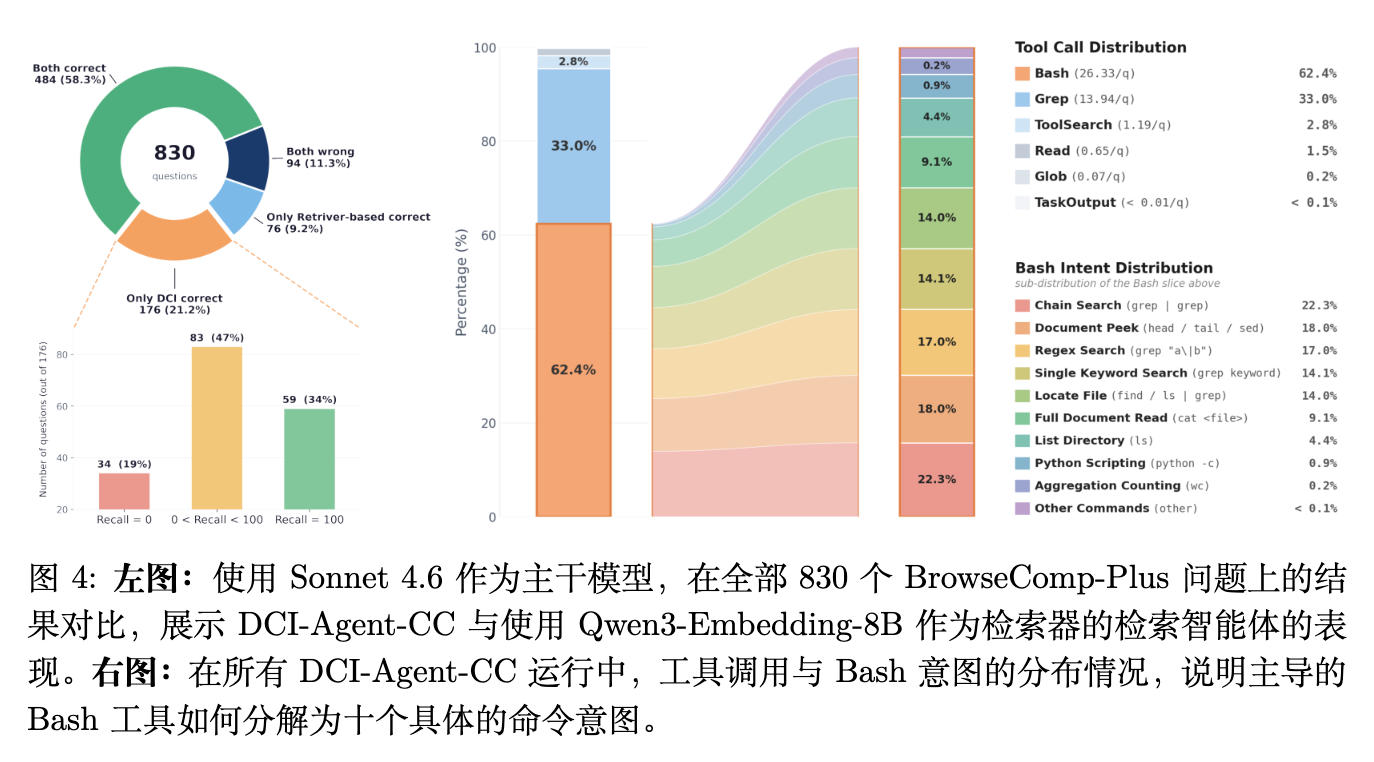
如图 4 左侧所示,在相同的 Sonnet 4.6 基座下,DCI-Agent-CC 正确回答了 176 个匹配检索智能体遗漏的 BrowseComp-Plus 问题,而只有 76 个案例呈现相反的模式。关键在于,这种差距主要不是由于彻底的检索失败造成的:在 176 个 DCI 获胜的案例中,只有 34 个案例是检索智能体没有召回任何 Golden 文档的,而其余 142 个案例检索智能体已经至少浮现了一个 Golden 文档。
这 142 个错误分为两种情况:部分链失败(83 个案例,召回率大于 0 但小于 100%),即检索暴露了一些证据但不足以桥接下一步;以及检索后失败(59 个案例,召回率等于 100%),即所有 Golden 文档都已浮现但未被成功利用。
图 4 右侧的工具分布强化了这一解释。DCI-Agent-CC 主要依赖 Bash(62.4%)和 Grep(33.0%)。在 Bash 中,使用集中在链式搜索(22.3%)、局部上下文窥探(18.0%)、正则匹配(17.0%)和文件定位(14.0%)上,而全文档阅读仅占 9.1%。这些模式表明,DCI 的收益来自于利用 bash 交互的表达性和可组合性来构建词汇约束、验证精确跨度,并选择性地将有希望的片段扩展为证据。
7.2 DCI 与检索的行为权衡 (RQ3)
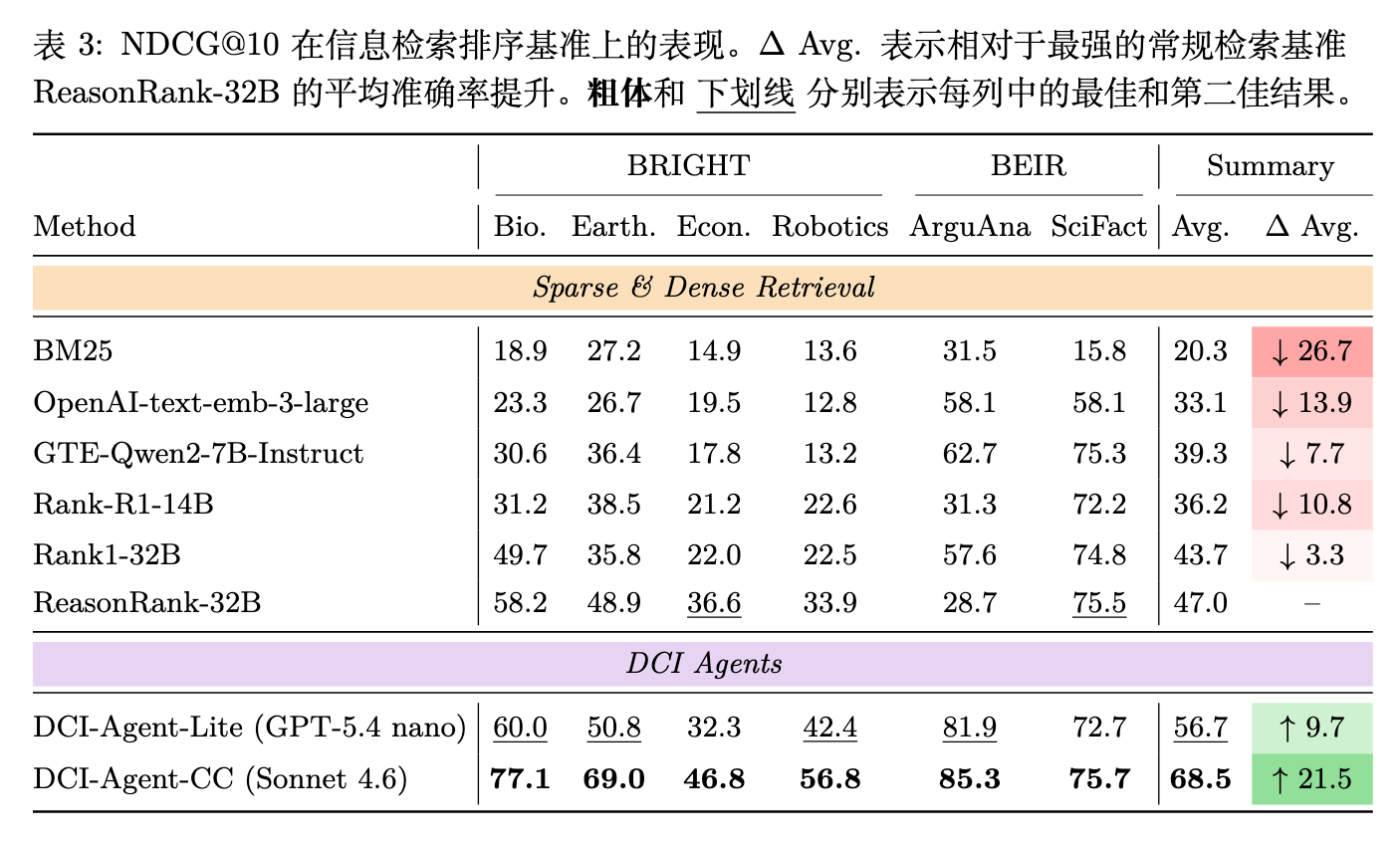
表 3 阐明了 DCI 的代价和收益。关键模式是:DCI-Agent-Lite 并不是通过详尽地恢复更多 Golden 文档来获胜的。它的平均 Golden 文档覆盖率()远低于 Qwen3-Embedding-8B(28.0 对 56.7),但它的 得分相当(70.0 对 74.0),而它的定位度得分()则大幅提高(48.4 对 21.7)。
这一点很重要,因为 BrowseComp-Plus 问题通常只有 1-4 个 Golden 文档。在这种机制下,一旦 DCI 浮现了一个有用的 Golden 文档,它就可以从广泛的检索转向细粒度的检查和验证。实际上,DCI 用详尽的黄金链恢复换取了高分辨率的局部进展:它足够频繁地找到相关文档,然后从它已经到达的文档中提取出多得多的价值。
7.3 语料库规模扩展的影响 (RQ4)
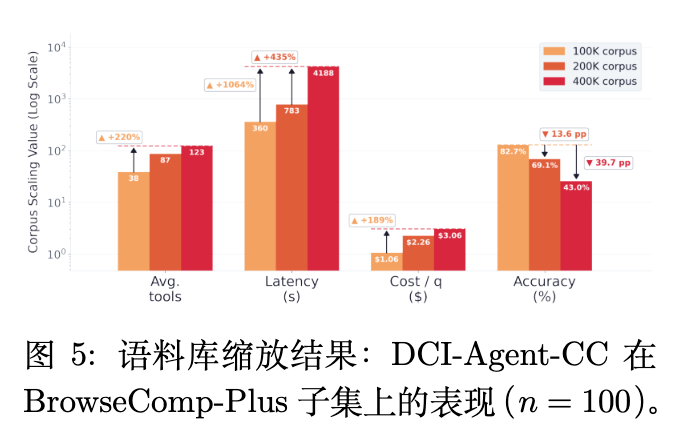
如图 5 所示,DCI 具有明确的运行包络线(Operating Envelope):它在搜索深度上扩展良好,但在搜索广度上会产生快速上升的成本。作者通过向原始集合中注入额外的干扰项,将 BrowseComp-Plus 语料库从 10 万个文档扩展到 20 万个文档。在这种变化下,DCI-Agent-CC 每个问题需要更多的工具调用(38.5 增加到 86.9),延迟增加了一倍多,成本增加了一倍多,准确率下降了 13.6 个百分点。
在 40 万个文档时,退化更为严重:准确率降至 37.5%,平均工具使用量升至 122.4 次调用,20 个示例在达到最大工具预算后终止。简而言之,一旦智能体到达一个有希望的文档,高分辨率接口仍然强大,但随着候选空间的扩大,定位第一个有用锚点的成本会急剧增加。
7.4 工具集表达能力的影响 (RQ6)
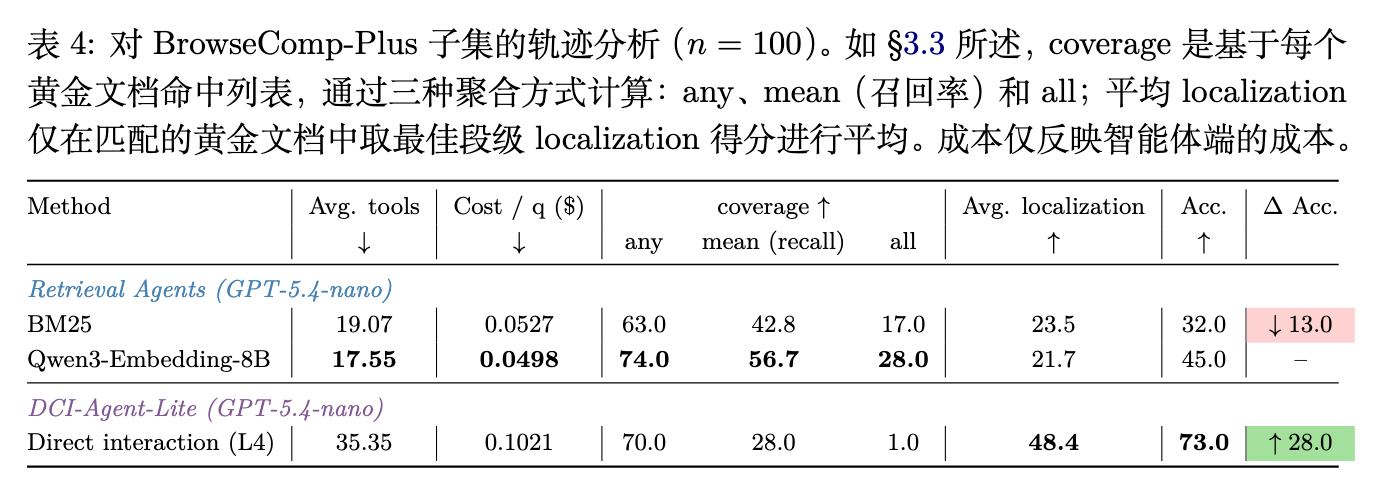
DCI 的收益是来自于 DCI 范式本身,还是仅仅因为获得了像不受限制的 Shell 这样高度表达性的工具?表 4 的消融实验给出了双重答案。
首先,即使在高度受限的接口下,优势也已经显现:仅使用 read + grep(将智能体限制为文件检查和基于精确/模式的搜索),智能体在 BrowseComp-Plus 上达到了 61% 的准确率,超过了使用 Qwen3-Embedding-8B 的检索智能体基线(45%)达 16 个百分点,同时保持了几乎相同的工具调用强度。
其次,启用完整的 bash 命令集带来了额外的 12 个百分点的提升(达到 73%),但代价是工具使用量、延迟和计算量的大幅增加。总体而言,这些结果表明,一小部分核心命令足以解锁大部分改进,而额外的表达能力则以降低效率为代价产生增量收益。
7.5 上下文管理策略的影响 (RQ5)
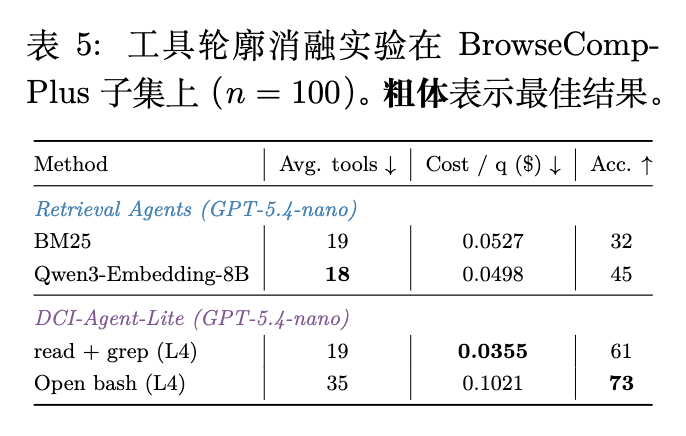
作者在极简脚手架下评估了表 5 中的五种上下文管理策略。模式明显是非单调的:更激进的管理并不简单地产生更好的结果。L1(仅截断)速度最快,并在最终状态中保留了最多的黄金证据(31.3),但 L3(截断+压缩)在较低的保留覆盖率(27.0)下实现了最佳的答案准确率(77)。这表明,保留更多逐字证据并不等同于维持继续搜索的正确工作状态。
同时,L2 成本最低但准确率最差(69),L4(摘要)在 L3 达到峰值后再次下降。总体而言,存在一个最佳平衡点:选择性遗忘的策略有利于维持多步假设修正,而太弱的压缩会导致漂移,太生硬的压缩(如强制摘要)会丢弃有用的中间结构。
8. 案例分析 (Case Study)
为了更直观地理解 DCI 智能体如何工作,我们来看一个 BrowseComp-Plus 中的复杂多跳推理案例(对应论文附录 D.2)。
问题:20世纪下半叶在英格兰举行了一场足球比赛。比赛中出现了一张黄牌,双方各换人两次。比分是1-0。球场建于50多年前,观众不到35,000人。三名裁判国籍不同。进球球员在18岁开始职业生涯,距比赛不到10年。他在采访中说进球靠的是"技术"而不是力量。他在下一场比赛中也进球了。输球方首发中有两名球员与进球球员同年出生,相差不到一个月。这两名球员中较年长的一位在同一篇文章中被进球球员的队友提到。请问这名较年长球员当时效力于哪家俱乐部?
DCI-Agent-CC 的推理与搜索轨迹(节选):
-
线索解析:智能体首先分解了 12 个约束条件(如 1950-1999年间、1-0、黄牌数、换人规则、观众数、裁判国籍、进球者年龄等)。 -
初步探索:智能体推断这可能是世界杯或欧洲杯比赛,并使用 bash列出 ESPN 目录下的文件ls browsecomp-plus-corpus/espn.co.uk/ | head -30。 -
定位比赛:它发现了一个名为 England_1-0_Belgium__26_Jun__1990__Final_Score.txt的文件,并使用cat读取。文件中确认了比分 1-0、1990年(20世纪下半叶)、观众 34,520 人(低于 35,000)、裁判国籍(丹麦、意大利、南斯拉夫)、黄牌数(英格兰1,比利时0)和换人数(各2人)。进球者是 David Platt。 -
验证"技术"引用:智能体使用 cat读取了卫报关于 David Platt 的文章,找到了原话:"There wasn't a great deal of power. It was all technique." 同时文章中队友 Paul Parker 提到了比利时球员 Enzo Scifo,Chris Waddle 也说 "I'd seen him do it at Auxerre a lot."。 -
验证出生日期约束:智能体需要确认比利时队中与 David Platt(1966年出生)同年出生且相差不到一个月的两名球员。它通过读取维基百科文件,确认了 Stéphane Demol(1966年3月11日)和 Enzo Scifo(1966年2月19日)。两人相差 20 天。 -
得出结论:较年长的是 Enzo Scifo(2月出生)。结合之前队友提到的 "Auxerre",智能体最终得出正确答案:AJ Auxerre。
分析:这个案例完美展示了 DCI 的高分辨率优势。如果使用传统的 Top- 检索,这 12 个极其琐碎和具体的约束条件(如裁判国籍、换人数)很难被转化为有效的向量表示,极易在第一步就被过滤掉。而 DCI 智能体通过 ls 发现文件,通过 cat 读取局部统计数据,再通过交叉比对不同文件中的出生日期,像人类研究员一样完成了极其严密的逻辑闭环。
9. 讨论与相关工作
本文的研究结果指向了智能体系统中关于检索的更广泛视角:核心问题不仅仅是使用哪个检索器,而是哪种接口最符合智能体的推理方式。
当模型能够像人类研究员一样进行搜索(例如,提出假设、测试精确模式、阅读局部上下文和修改查询)时,压缩的相似度索引就成了瓶颈,使得高分辨率接口变得更有价值。从这个角度来看,DCI 不仅仅是另一种方法,它证明了能力强大的智能体的检索应该被重新构建为一个接口设计问题(其粒度决定了智能体可以观察、验证和采取行动的内容),而不仅仅是一个检索器设计问题。
当然,稠密和稀疏检索对于大型静态语料库仍然具有可扩展性和有效性,但它们只占据了语料库接口更广阔设计空间中的一个点。在真实的智能体工作空间中,语料库可能是本地的、异构的且不断发展的。通过标准的 bash 终端进行 DCI 不需要离线嵌入或索引,自然适应不断变化的文件,并允许智能体直接在其进行推理的环境中操作。
这与近期崛起的编码智能体(Coding Agents)(如 SWE-agent, OpenHands)形成了呼应。这些系统证明了 CLI 原语足以进行精确的代码定位和编辑。本文的工作将 CLI 定位为智能体搜索的新型检索媒介,将通用的终端工具(如 grep、文件读取和 Shell 命令)视为语料库的高分辨率接口。
10. 总结
本文将直接语料库交互(DCI)形式化为智能体搜索的一种替代检索范式,其中智能体使用通用的终端工具而不是传统的检索器在原始语料库中进行搜索和验证。在面向排序的 IR、多跳 QA 和端到端智能体搜索基准测试中,DCI 在没有任何离线索引的情况下,已经展现出作为一种极具竞争力的操作模式的潜力。
受控消融和轨迹级分析表明,DCI 的优势源于检索接口分辨率:DCI 的成功往往不是通过恢复更多的 Golden 文档链,而是通过将浮现的初步证据转化为更高价值的局部检查、验证和组合搜索步骤。
局限性与未来工作:正如 RQ4 所揭示的,DCI 在面对海量语料库时,其"广度"搜索成本会急剧上升。未来的工作可以探索混合接口:利用轻量级的稠密检索器进行低成本的广度召回(找到最初的锚点文档),随后无缝切换到 DCI 接口进行高分辨率的深度验证和多跳推理,从而结合两者的优势。
更多细节请阅读原文。

