如何有效地训练 Agent 仍然是一个开放且充满挑战的研究领域,特别是在许多现实场景中,例如网页浏览、软件工程或复杂的知识检索,环境的奖励信号是稀疏的——代理只有在完成整个任务后才能获得一个最终的成败反馈。这种稀疏性使得经典的强化学习(RL)方法在信用分配(Credit Assignment)上面临严峻挑战:我们难以判断一长串决策序列中,哪些步骤是关键的,哪些是无效甚至有害的。
近期,一篇来自 ByteDance Seed 团队的论文《Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents》提出了一种名为“熵调制策略梯度”(Entropy-Modulated Policy Gradients, EMPG)的新框架,为解决这一问题提供了新的视角。该工作不试图去创造密集的外部奖励,而是将目光投向模型内部,利用模型在决策过程中的“不确定性”作为一种内在的、丰富的学习信号,来动态地重新校准和塑造策略梯度。

-
论文标题:Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents -
论文链接:https://arxiv.org/pdf/2509.09265
1. 背景
要理解 EMPG 的价值,我们必须先明确其试图解决的问题的根源。LLM Agent 在执行长时序任务时,本质上是在进行一个序列决策过程,这与强化学习的框架天然契合。然而,经典的 RL 算法在应用于 LLM Agent 时,面临着几个独特的挑战。
1.1 稀疏奖励与信用分配难题
正如开篇所述,最核心的挑战是稀疏奖励(Sparse Rewards)。在一个需要几十甚至上百步交互才能完成的任务中(例如,在电商网站上根据复杂指令找到特定商品并加入购物车),最终的成功奖励就像是沙漠中的灯塔,它能告诉你最终到达了终点,但无法照亮你走过的曲折路径。
这直接导致了信用分配(Credit Assignment)难题。假设一个 Agent 成功完成了任务,我们应该奖励序列中的所有步骤吗?这显然不合理,因为其中可能包含了一些无用的探索。如果任务失败了,我们应该惩罚所有步骤吗?这同样不合理,因为也许 Agent 在前 99 步都做对了,只是在最后一步犯了错。
这种“一荣俱荣,一损俱损”的粗糙反馈机制,使得学习效率低下且训练过程不稳定。
1.2 现有解决方案及其局限性
为了应对稀疏奖励问题,研究界主要沿着两个方向进行了探索:
方向一:创造密集的外部奖励信号
这个方向的核心思想是,既然环境不给奖励,我们就自己“造”奖励。
-
逆向强化学习 (Inverse Reinforcement Learning, IRL) :通过专家示例轨迹来学习一个奖励函数。但这种方法需要大量的专家数据,且学习出的奖励函数在新状态下的泛化能力存疑。 -
奖励塑造 (Reward Shaping) :根据一些启发式规则或领域知识来设计中间奖励。例如,在网页导航中,每当 Agent 点击一个可能相关的链接时,就给予一个小的正奖励。这种方法高度依赖人工设计,难以扩展到复杂和多样化的任务中。 -
过程奖励模型 (Process Reward Models, PRMs) :这是近年来在 LLM 领域比较成功的一种方法。它不再奖励最终结果,而是训练一个模型来评估每一步决策的“正确性”。例如,在数学解题任务中,PRM 会判断每一步推理是否合理。然而,PRM 的构建成本高昂,需要大量的人工标注,并且同样面临泛化性和噪声问题,尤其是在交互式、非结构化的 Agent 任务中,定义“正确的”单一步骤本身就是一个难题。
方向二:利用模型内在信号进行指导
这个方向认为,LLM 自身在生成过程中就蕴含了丰富的信息,可以作为学习的监督信号。其中,策略熵(Policy Entropy) 是一个被广泛研究的信号。熵在信息论中度量不确定性,在 RL 中,它通常被用来平衡“探索”与“利用”(Exploitation vs. Exploration)。
-
熵作为奖励:一些工作将低熵(高确定性/自信度)作为奖励目标,认为正确的推理过程通常伴随着模型的高度自信。这种无监督的熵最小化方法在某些推理任务上有效,但它有一个致命缺陷——“自信的犯错”(Hallucinated Confidence)。模型可能会对自己错误的输出变得越来越自信,陷入一种自我强化的恶性循环。 -
熵作为正则项或调制器:另一些工作则不直接将熵作为奖励,而是用它来调制学习过程。例如,鼓励模型在探索时保持较高的熵。这些工作大多集中在单轮的生成式推理任务上,它们在 token 层面或整个回复层面进行调制,但没有系统性地解决长时序、多步骤决策中的信用分配问题。
总结来说,现有的方法要么代价高昂、难以泛化,要么对模型内在信号的利用方式存在缺陷。这正是 EMPG 试图切入的空白地带:我们能否不依赖外部标注,仅利用模型内在的、每一步决策时的不确定性,来为稀疏的最终奖励信号提供一个动态、精细的信用分配方案?
2. 动机
EMPG 的出发点是一个深刻的理论洞察:在标准的策略梯度方法中,梯度的大小与策略的熵是内在耦合的。 这句话听起来有些抽象,我们来逐步拆解它。
2.1 策略梯度方法回顾
首先,我们简单回顾一下策略梯度(Policy Gradient)方法。其目标是优化一个参数为 的策略 ,以最大化期望回报 :
其中 是一个从策略 采样得到的完整轨迹(trajectory), 是该轨迹的总回报。根据策略梯度定理,目标函数对参数 的梯度可以表示为:
这里的 通常被称为得分函数(score function),它指出了在状态 下,为了让动作 的概率上升,参数 应该朝哪个方向更新。 是优势函数(advantage function),它衡量了在状态 下采取动作 相对于平均水平的好坏。在稀疏奖励场景下,对于一个完整的轨迹,所有步骤的优势函数通常被简化为该轨迹的最终回报 。
2.2 问题的核心:梯度大小与不确定性的纠缠
现在,我们来看问题的关键。得分函数的 L2 范数(即 )决定了单次更新的“步长”或“幅度”。EMPG 论文的核心洞察(在 Proposition 1 中被形式化)是,这个范数的大小与策略在该状态下的熵(即不确定性)是单调相关的。
论文中给出了如下的命题(Proposition 1):
对于一个由 logits 经过 softmax 参数化的策略 ,得分函数关于 logits 的期望平方 L2 范数是策略 Rényi-2 熵 的一个直接函数:
虽然这里用的是 Rényi-2 熵(Rényi-2 是指Rényi 熵(Rényi Entropy)中阶数为 2 的一种特殊情况。它是一个用来衡量概率分布不确定性或随机性的指标,与我们更熟悉的香农熵(Shannon Entropy)是近亲。
),但它与其他熵度量(如香农熵)在趋势上是一致的。这个公式揭示了一个深刻的问题:
-
当策略熵很低时(Low Entropy):模型对某个动作非常“自信”,此时 接近 1,导致期望梯度范数接近 0。这意味着,即使这个自信的动作是正确的(即 ),它能获得的更新信号也非常微弱。这极大地拖慢了对正确且自信的决策的强化学习速度。
-
当策略熵很高时(High Entropy):模型对下一步非常“不确定”,此时 接近 0,导致期望梯度范数接近 1。这意味着,如果这一步只是一个不确定的探索性步骤,它反而会产生一个巨大的梯度。如果这个梯度恰好来自一个最终失败的轨迹(),它可能会对策略产生剧烈的、不稳定的负向更新,从而惩罚了必要的探索。
这种内在的耦合关系导致了学习动态的“错配”:
-
对于本应大力强化的“自信且正确”的步骤,更新幅度过小,学习效率低。 -
对于本应谨慎处理的“不确定”的探索步骤,更新幅度过大,训练不稳定。 -
对于需要严厉惩罚的“自信且错误”(即幻觉)的步骤,更新幅度同样过小,无法有效纠正。
因此,EMPG 认为,我们必须打破这种耦合,对学习信号进行显式的重新校准(Re-calibration)。
3. EMPG
基于上述理论动机,EMPG 提出了一套完整的解决方案,其核心是引入一个新的调制优势函数(Modulated Advantage) ,来替代原始的优势函数 。对于轨迹 中的第 步,其调制优势函数定义为:
这个公式清晰地展示了 EMPG 的两大核心组件:自校准梯度缩放 (Self-Calibrating Gradient Scaling) 和 未来清晰度奖励 (Future Clarity Bonus) 。我们来逐一解析。
3.1 自校准梯度缩放 (Self-Calibrating Gradient Scaling)
这一部分直接解决了前述的“熵-梯度耦合”问题。它的目标是根据每一步决策的不确定性 来动态地调整(re-weight)来自最终任务回报 的学习信号。
1. 如何量化步级不确定性 ?
EMPG 采用了一个简单而有效的方法:将一个“思考-行动”步骤内所有 token 的平均熵作为该步骤的熵 。
其中,一个步骤由 个 token 组成, 是模型在生成第 个 token 时,词汇表 中 token 的概率。 越低,表示模型在生成这一整步回复时越“自信”和“流畅”。
2. 缩放函数 的设计
缩放函数 是整个机制的核心。它的作用是:当 低时,放大梯度;当 高时,缩小梯度。EMPG 设计了一个基于指数函数的缩放因子,并引入了“自校准”机制。
首先,定义一个基础的指数函数:,其中 是一个超参数, 是经过批次内归一化(min-max scaling)后的熵值。这个函数满足了“低熵高权重,高熵低权重”的基本要求。
关键在于自校准。EMPG 强制要求在一个 mini-batch 内,所有步骤的 的均值为 1。
这意味着 不是简单地放大或缩小整个 batch 的梯度,而是在 batch 内部进行学习信号的重新分配。具体的实现方式是将基础指数函数除以其在 mini-batch 内的均值:
这个设计带来了几个好处:
-
自适应性: 的效果是相对于当前 batch 的平均不确定性而言的。如果整个 batch 的步骤都非常自信,那么只有最自信的那些步骤才会被显著放大。 -
稳定性:它避免了梯度的整体膨胀或消失,保持了学习过程的稳定。 -
效果: -
对于自信且正确的步骤 ( 低, ),,学习信号被放大,加速收敛。 -
对于自信且错误的步骤 ( 低, ),,惩罚信号也被放大,有效抑制幻觉。 -
对于不确定的探索步骤 ( 高),,学习信号被衰减,避免了不稳定的更新,保护了有益的探索。
-
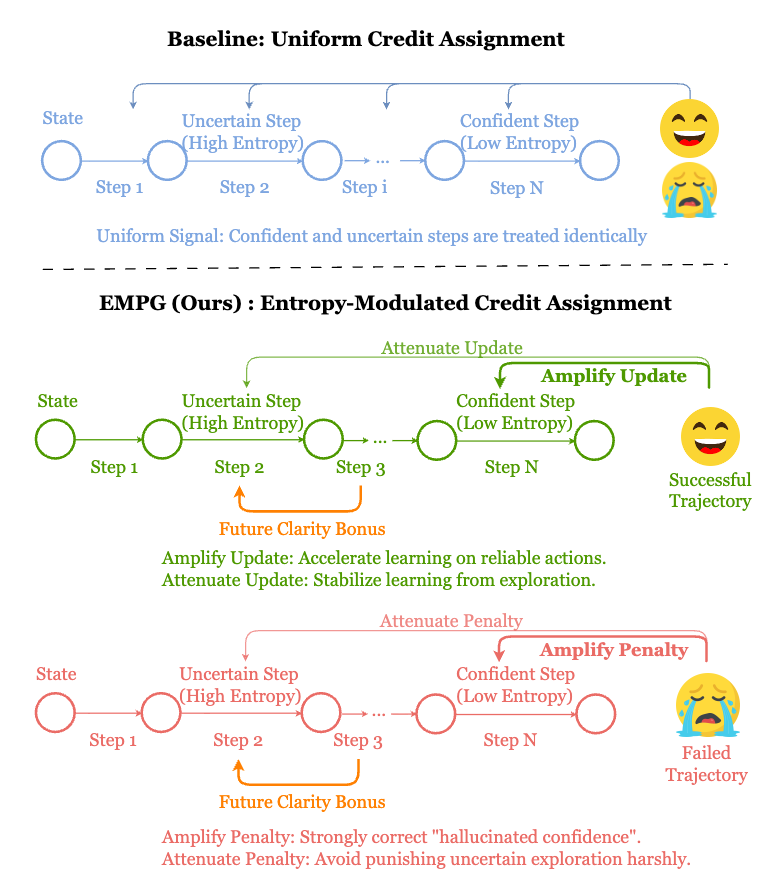
上图直观地展示了这一机制。对于成功的轨迹,EMPG 放大自信步骤(Confident Step)的更新,衰减不确定步骤(Uncertain Step)的更新。对于失败的轨迹,它会放大对自信错误步骤的惩罚。
3.2 未来清晰度奖励 (Future Clarity Bonus)
仅仅重新校准梯度的大小是不够的,一个好的学习信号还应该能指导 Agent 的探索方向。EMPG 的第二部分——未来清晰度奖励——正是为此设计的。
它的核心思想是:一个好的动作,不仅要对当前任务有益,还应该能将 Agent 引导到一个更加“清晰”、“可预测”的未来状态。 换言之,Agent 应该学会主动寻求那些能减少未来不确定性的路径。
这个奖励项被设计成一个正的 bonus,其大小与下一步的确定性(即低熵)成正比:
其中 是一个控制该奖励项权重的超参数。这个内在奖励(intrinsic reward)为 Agent 提供了一个密集的、步步为营的引导信号:
-
它鼓励 Agent 采取那些能让模型在下一步更有把握的行动。 -
它引导 Agent 避开那些可能导致模型陷入“迷茫”或“混乱”状态的路径。 -
从信息论的角度看,这可以被理解为鼓励 Agent 采取能最大化关于未来最优路径的信息增益(Information Gain)的行动。
这个组件与梯度缩放形成了完美的互补:
-
梯度缩放 关注于如何利用过去的经验(即最终回报),通过调整更新幅度来优化信用分配。 -
未来清晰度奖励 关注于如何指导未来的探索,通过增加内在动机来塑造 Agent 的行为偏好。
3.3 算法流程与实现细节
EMPG 的完整算法流程可以概括如下:

-
初始化:初始化策略网络 。
-
循环训练:在每次迭代中:
a. 数据收集:使用当前策略 与环境交互,收集一个批次(batch)的轨迹。
b. 计算优势:根据每个轨迹的最终回报,计算一个初步的、轨迹共享的优势值 。
c. 计算步级熵:遍历 batch 中的所有轨迹的所有步骤,计算每个“思考-行动”步骤的平均 token 熵 。
d. 熵归一化:在整个 batch 范围内,对所有步级熵进行 min-max 归一化,得到 。
e. 计算调制组件:根据归一化的熵,计算出自校准缩放因子 和未来清晰度奖励 。
f. 计算调制优势:应用 公式,为 batch 中的每一步计算其专属的调制优势。
g. 最终归一化:为了进一步稳定训练,对整个 batch 的 进行零均值化处理。
h. 策略更新:使用最终的调制优势和得分函数,通过策略梯度方法更新模型参数 。
这是一个优雅且高效的实现。它没有引入任何额外的需要训练的模型(如价值网络或奖励模型),只在标准的策略梯度训练循环中增加了基于熵的计算步骤,计算开销小,易于集成到现有的 RL 训练框架中。
4. 实验
理论上的优雅需要通过实验来证明其在实践中的价值。EMPG 团队在三个具有挑战性的长时序 Agent 基准上进行了详尽的实验,并与强大的基线方法进行了比较。
4.1 实验设置
-
任务基准: -
WebShop:一个模拟真实电商网站的环境,需要 Agent 根据指令完成搜索、筛选、点击、购买等一系列操作。 -
ALFWorld:一个基于文本的交互式环境,融合了指令遵循和常识推理。 -
Deep Search:一个多步信息检索与综合任务,需要 Agent 使用搜索引擎和网页阅读工具来回答复杂问题。该任务被进一步分为域内(ID)和域外(OOD)评估集,以测试泛化能力。
-
-
基础模型:实验使用了不同规模的 Qwen2.5-Instruct 系列模型(1.5B, 7B, 32B),以验证方法的可扩展性。 -
基线方法: -
GRPO (Group Relative Policy Optimization) :一种通过批内比较来估计优势的方法。 -
DAPO (Decoupled Clip and Dynamic Sampling Policy Optimization) :一个在 GRPO 基础上改进的、更强的策略优化算法。
-
-
实施方式:EMPG 作为一个优势调制模块,被直接应用在 GRPO 和 DAPO 之上。这使得比较非常公平,任何性能提升都可以归因于 EMPG 模块本身。
4.2 主要结果分析
实验结果展示了 EMPG 稳定且显著的性能提升。
在 ALFWorld 和 WebShop 上的表现:
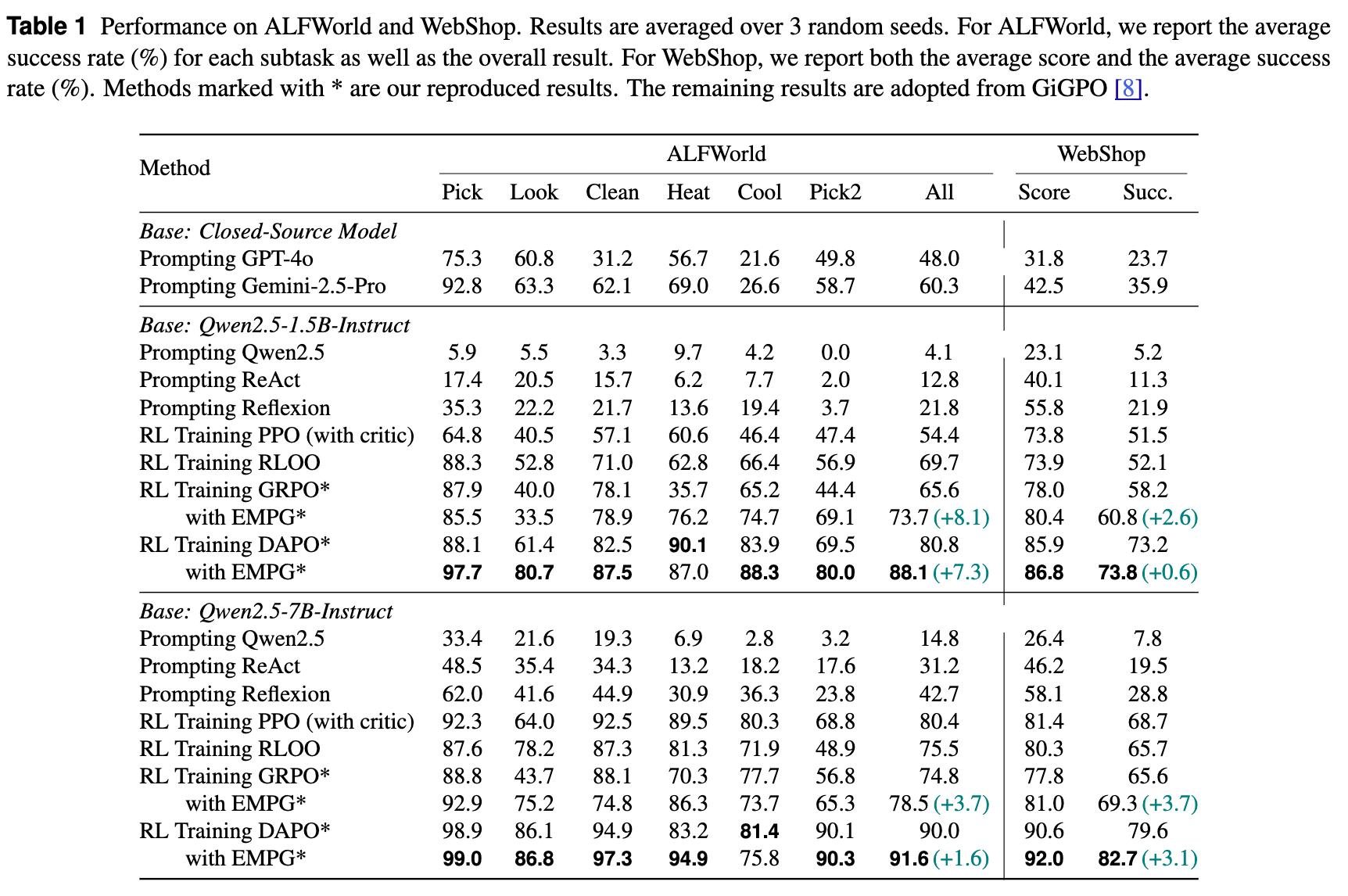
-
从表 1 可以看出,无论是在 1.5B 还是 7B 模型上,也无论是结合 GRPO 还是 DAPO,EMPG 都带来了正向的性能增益。 -
在 Qwen2.5-7B + DAPO 的配置下,EMPG 将 WebShop 的成功率从 79.6% 提升到了 82.7% (+3.1),将 ALFWorld 的成功率从 90.0% 提升到了 91.6% (+1.6)。这些提升是在一个已经很强的基线之上取得的。
在更复杂的 Deep Search 任务上的表现:
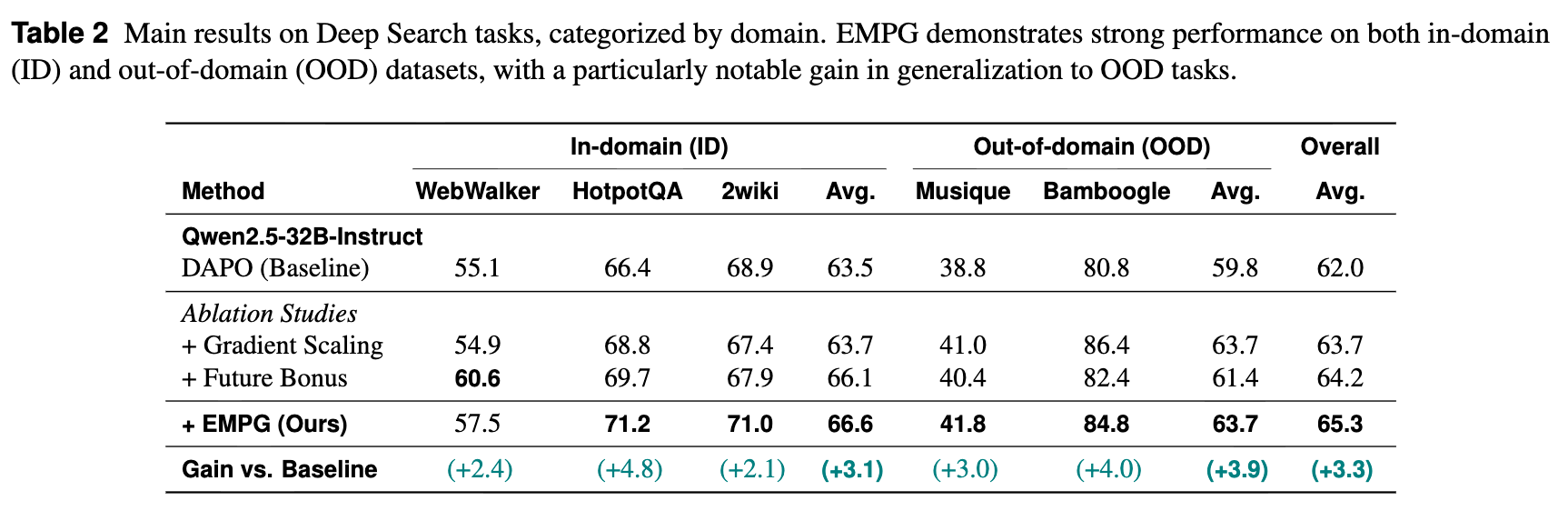
-
在更强大的 Qwen2.5-32B 模型上,EMPG 依然有效。它将 DAPO 基线的平均分从 62.0 提升到了 65.3 (+3.3)。 -
EMPG 在泛化能力上表现出了尤为出色的效果。在 OOD 数据集上,性能提升达到了 +3.9,高于 ID 数据集上的 +3.1。这有力地说明,EMPG 学到的不仅仅是拟合训练数据,而是一种更通用的、处理不确定性的能力。
4.3 深度分析:EMPG 为何有效?
除了最终的性能数字,论文还进行了一系列深入的分析性实验,来探究 EMPG 成功的内在原因。
1. 消融研究:两大组件的互补作用
通过单独测试“梯度缩放”和“未来清晰度奖励”这两个组件,论文揭示了它们之间有趣的二元互补关系:
-
未来清晰度奖励 (Future Bonus) 主要提升了域内(ID) 性能。这符合直觉,因为它通过强化已知的、通往清晰状态的路径来增强对训练数据的利用(Exploitation)。 -
梯度缩放 (Gradient Scaling) 主要提升了域外(OOD) 性能。这是因为它教会了模型在面对不确定性时如何“表现得体”(通过衰减高熵步骤的更新)。这是一种正则化机制,使得最终策略更加鲁棒,从而在遇到新情况时表现更好。
这两者结合起来,使得模型既能充分利用已知信息,又具备了应对未知情况的稳健性。
2. 训练稳定性分析
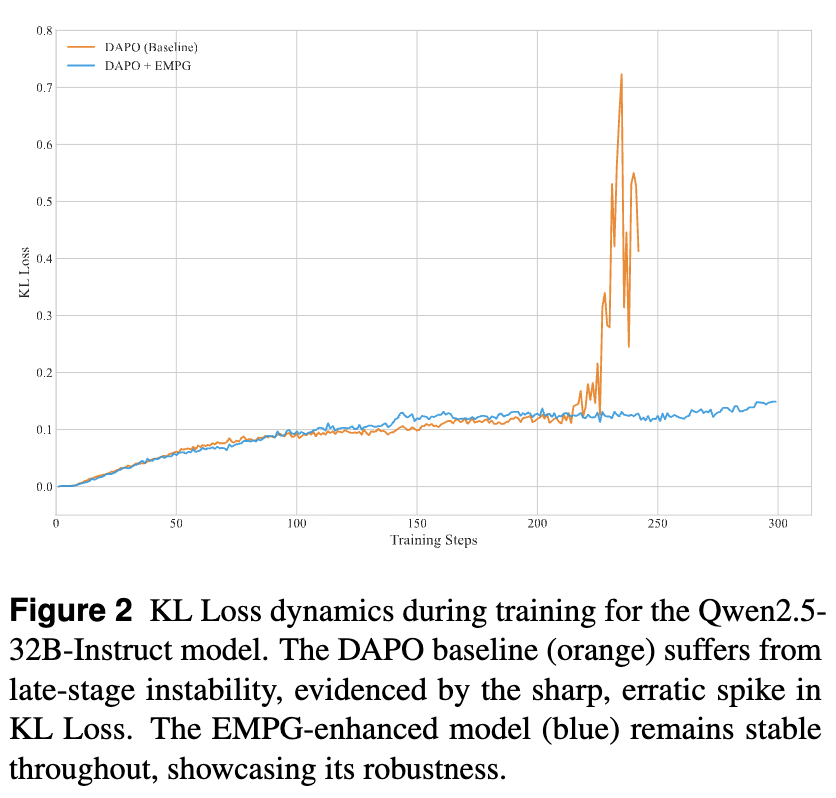
在线 RL 微调中,一个常见的失败模式是“策略崩溃”(Policy Collapse),即 Agent 的策略在训练后期突然发散,导致性能急剧下降。论文通过追踪训练过程中的 KL 散度(衡量新旧策略差异的指标)来可视化这一现象。
-
结果显示,DAPO 基线在训练后期出现了剧烈的 KL 散度尖峰,表明策略变得不稳定。 -
而加入了 EMPG 的模型,其 KL 散度在整个训练过程中都保持在较低的水平,表现出优异的稳定性。这主要归功于梯度缩放机制对高熵探索步骤的“降噪”和“平滑”作用。
3. 步级 vs. Token 级熵动态分析
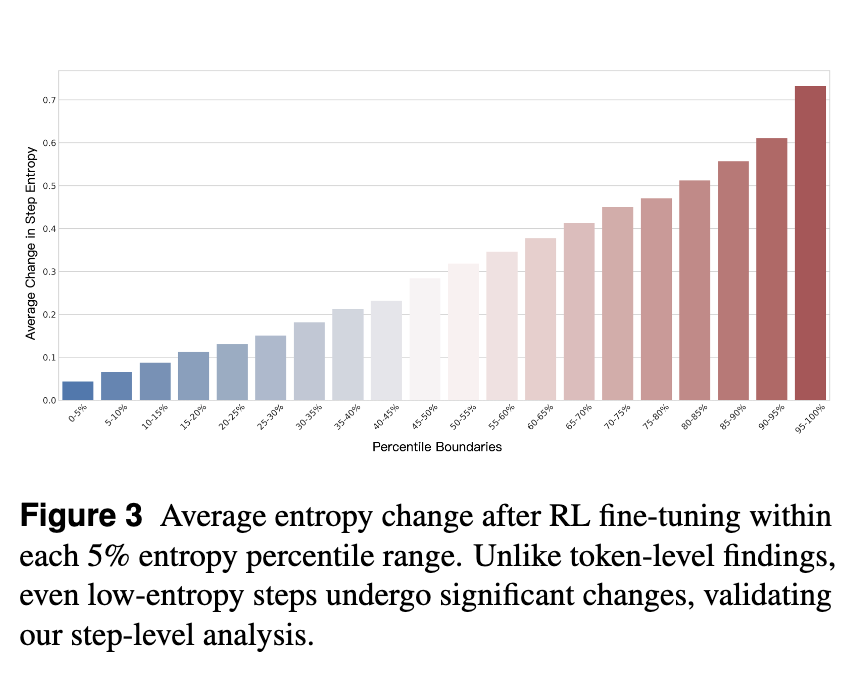
先前有工作指出,RL 更新主要影响高熵的 token。EMPG 的分析则在步级(step-level) 层面提出了新的见解。他们将 ALFWorld 任务中的数千个步骤按初始熵分为不同的区间,并观察 RL 更新后各区间的熵变化。
-
结果发现,即使是初始熵非常低的步骤(例如 15%-20% 百分位),在 RL 更新后也经历了显著的熵变化。 -
这一发现挑战了“只有高熵部分才需要学习”的简单假设,说明一个看似“自信”的完整步骤,其内部的策略空间仍然有很大的优化余地。这为 EMPG 在整个熵谱上进行调制提供了有力的支持,证明了其在步级层面进行分析和操作的必要性。
4. 学习动态分析:突破性能瓶颈
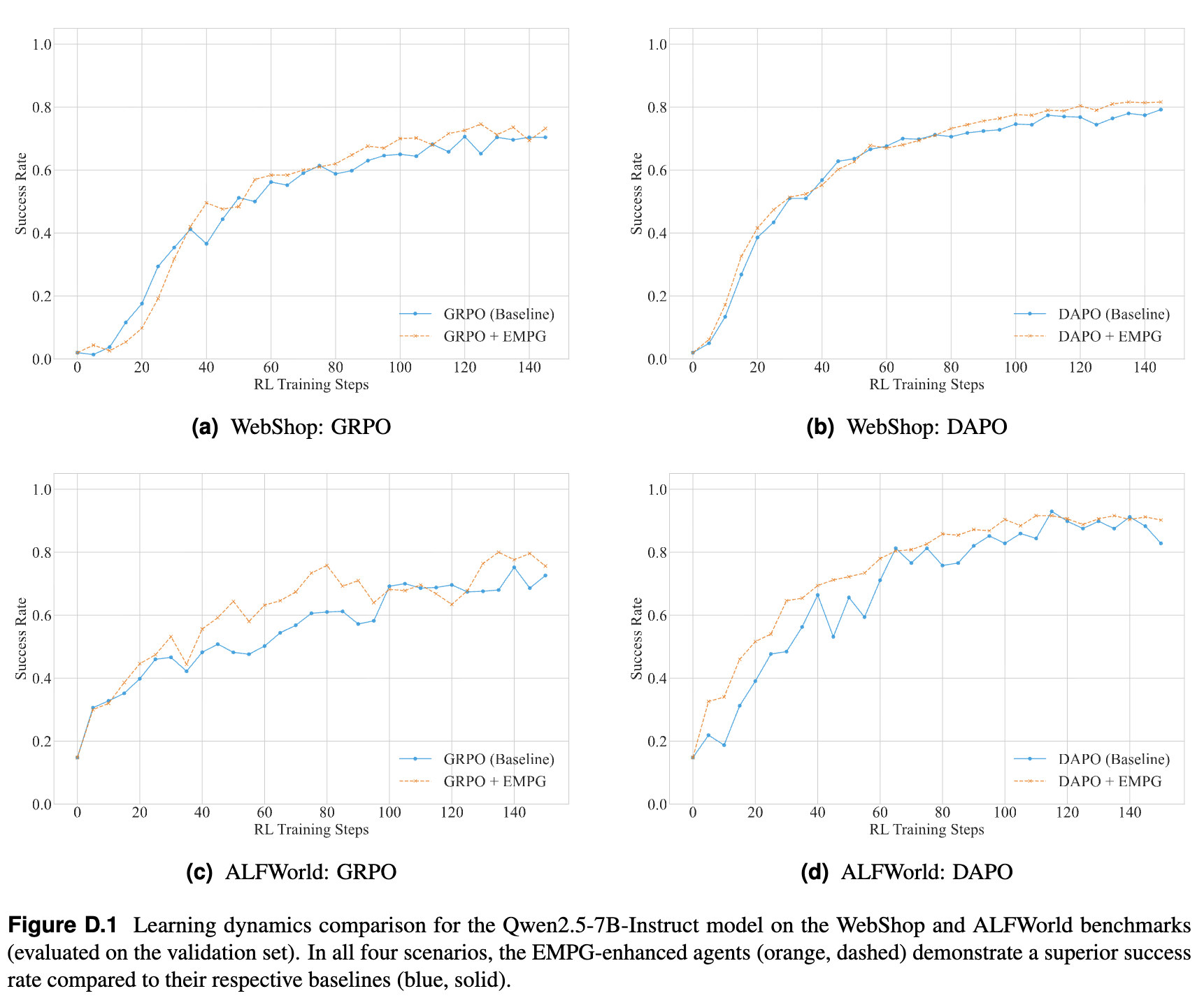
通过观察学习曲线,我们可以发现一个一致的模式:
-
基线方法(GRPO, DAPO)在训练初期能够快速提升性能,但很快会达到一个性能平台期(plateau),成功率停滞不前。 -
而 EMPG 增强的 Agent 则能够决定性地突破这个平台期,持续学习,并最终收敛到一个显著更高的性能水平。
这表明,EMPG 不仅仅是加速了学习,更重要的是,它通过提供一个更丰富、更有效的学习信号,引导 Agent 发现了基线方法无法进入的、更优的策略空间,有效帮助 Agent 逃离了局部最优解。
往期文章:


