让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:mSFT: Addressing Dataset Mixtures Overfitting Heterogeneously in Multi-task SFT -
论文链接:https://arxiv.org/pdf/2603.21606
TL;DR
今天解读一篇来自KAIST的论文《mSFT: Addressing Dataset Mixtures Overfitting Heterogeneously in Multi-task SFT》。该研究针对多任务监督微调(SFT)阶段中存在的“异构过拟合”问题提出了解决方案。传统的SFT方法在所有子数据集上应用相同的计算预算(即全局同质计算),这导致学习速度快的任务提早过拟合,而学习速度慢的任务处于欠拟合状态。
为此,作者提出了mSFT(Multi-task SFT)算法,这是一种迭代的、具备过拟合感知能力的数据混合搜索算法。mSFT通过设定固定的计算预算进行训练(Roll-out),识别并排除最早出现过拟合的子数据集,随后将模型参数回滚(Roll-back)至该数据集达到最佳泛化性能的检查点,再继续对剩余数据进行训练。
实验表明,mSFT在6个基础模型和10个基准测试中提升了平均准确率,对超参数(计算预算)表现出鲁棒性,并在降低计算预算时减少了训练的FLOPs(浮点运算次数),同时通常能实现更低的训练损失。
1. 引言
自从Transformer架构被提出以及缩放定律(Scaling Laws)确立以来,基于多样化数据训练的通用基础模型在自然语言处理领域占据了主导地位。在模型训练的整个生命周期中,多任务监督微调(Supervised Fine-Tuning, SFT)是一个必要的阶段。在这个阶段,从业者通常将多样化的子数据集随机混合在一起进行训练,以避免顺序训练带来的灾难性遗忘问题。
在当前的SFT范式中,研究人员通常遵循一种基于经验的方法:给定固定的数据规模,分配一定的计算量(通常以Epoch计算),并在训练过程中将中间检查点(Checkpoints)保存在内存或磁盘中。训练结束后,通过在保留的验证/测试集上评估泛化性能,挑选出表现得分最高的检查点。
然而,当前的开源权重模型(如Magistral、OLMo、DeepSeek、Qwen等系列模型)在SFT阶段内在地采用了一个假设:全局最佳计算预算与各个底层子数据集的最佳计算预算是一致的。也就是说,模型对所有的子数据集都应用了同质的(Homogeneous)计算量。具体情况见下表:
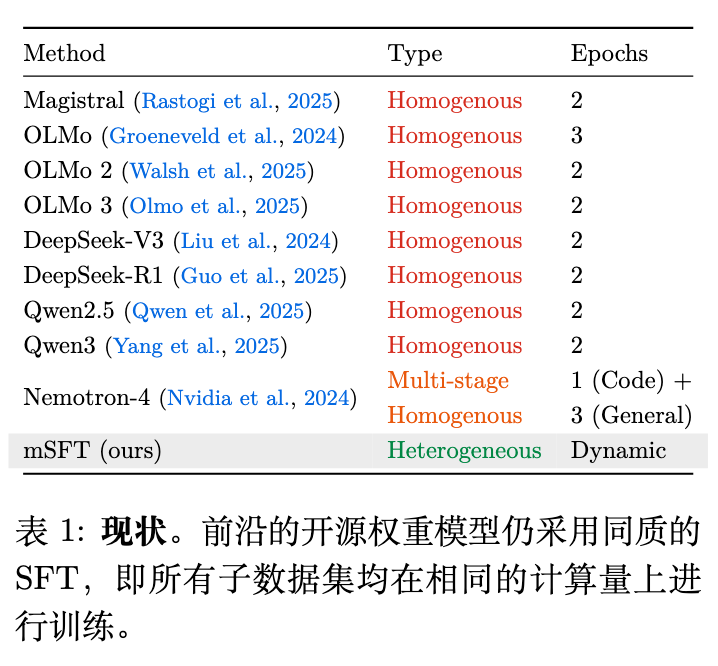
如上表所示,前沿模型在多任务SFT中基本都采用了相同的Epoch数进行训练。作者提出假设:这种事实上的通用方法是次优的。因为多任务混合数据中的每一个子数据集都包含不同的数据分布,这必然导致不同的学习动态和泛化动态。虽然部分模型(如Nemotron-4)已经表明其代码(Code)子数据集需要的计算量少于其他子数据集,并实施了多阶段同质训练(Multi-stage Homogeneous),但这种计算量的分配粒度依然较粗。
此外,从整个端到端的语言模型训练流程来看,SFT阶段占据的计算量比重偏低。根据文献以及对OLMo 2模型的公开数据推算,SFT阶段大约只占用整个训练流程总计算量的0.01%。
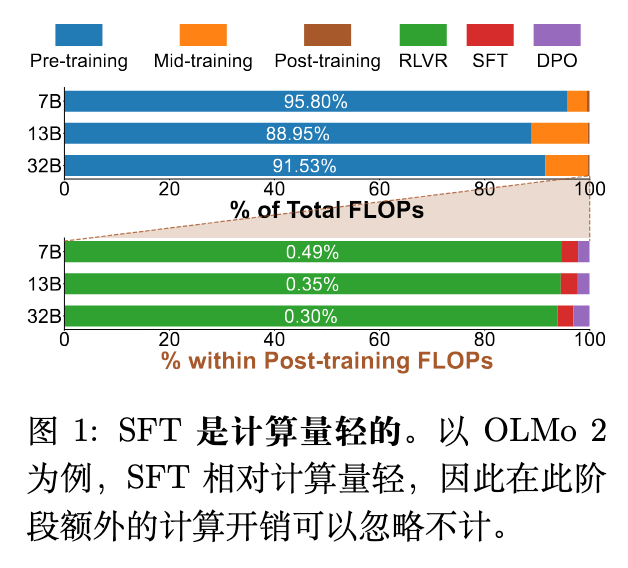
因此,即便在SFT阶段为了寻找每个子数据集的最佳计算量而引入一些额外的计算成本,相对于整个预训练和后训练(Post-training)过程而言,这些开销是可以接受的。
2. 动机:数据集混合的异构过拟合现象
多任务SFT存在一个根本性的错位:个体任务多样化的学习动态与标准训练范式僵化的全局计算分配之间存在矛盾。
为了将这一问题形式化,我们考虑一个语言模型(LM),其参数为 ,在多任务数据集混合 上进行监督微调。该数据集混合由 个不同的任务(子数据集)组成:
我们使用连续的计算变量 来衡量训练进度。变量 是传统训练轮数(Epochs)的细粒度泛化形式(例如可以使用小数形式的轮数,如0.25个Epoch)。对于给定的任意任务 ,存在一个最佳计算量 。这个最佳计算量被定义为模型在该任务的保留测试集上达到最大泛化性能的停止点:
在标准的同质(Homogeneous)训练范式下,各个任务在最佳停止点上的内在差异被忽略了。模型在整个数据集混合 上按照固定的全局计算预算 进行训练。这施加了一个刚性约束,即每一个任务 都被迫遵守完全相同的训练计算量:
由于不同任务在数据分布和复杂性上存在差异,它们的收敛速度和最佳计算水平有着明显的不同(即 )。强制使用单一的全局计算预算不可避免地会在整个混合数据上产生次优的训练结果。这是由于异构学习动态(Heterogeneous learning dynamics)引起的。
在实证观察中,单个子数据集达到峰值泛化性能的计算量水平相差甚远。这种差异导致了一个内在的优化冲突:当全局计算量超过某个快速收敛任务的最佳点()时,该任务开始过拟合;而当全局计算量还未达到某个慢速学习任务的最佳点()时,该任务仍处于欠拟合状态。
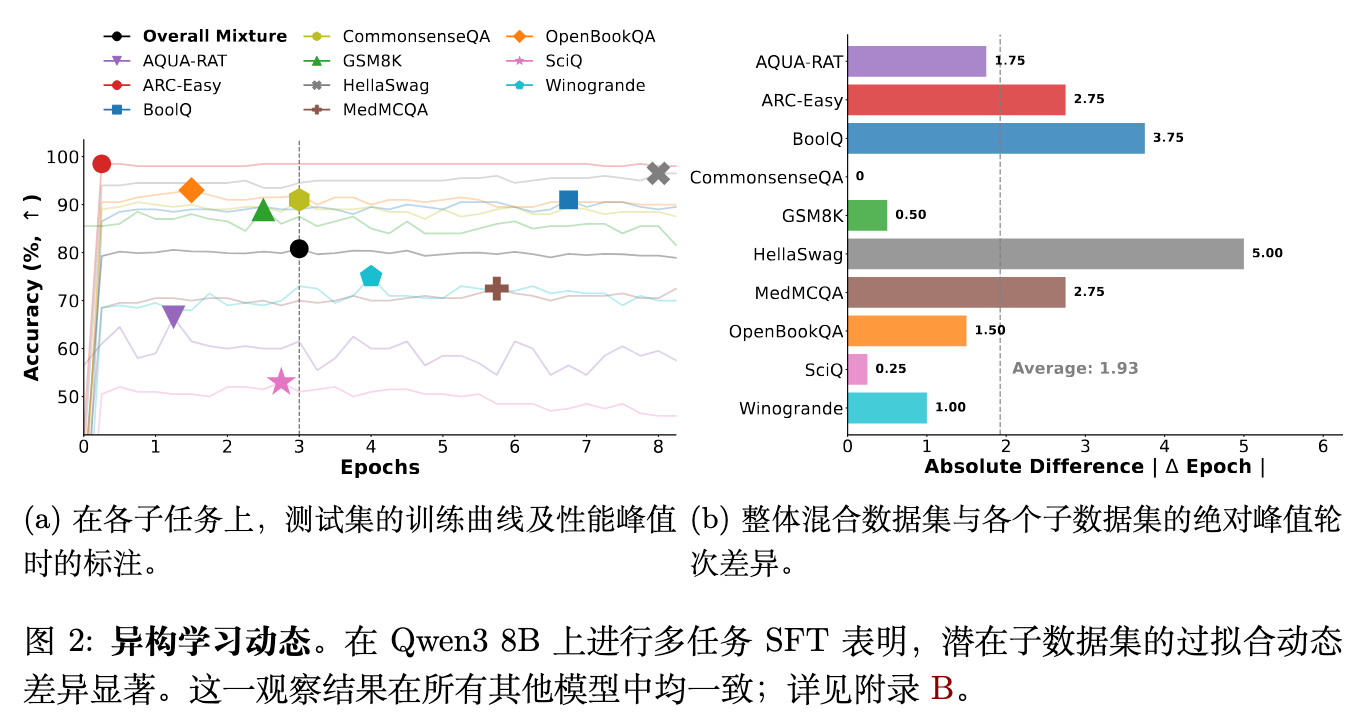
图 2 展示了在 Qwen3 8B 模型上进行多任务SFT时的现象。底层子数据集的过拟合动态差异明显。例如,某些子数据集在1.5个Epoch左右就达到了性能峰值,而另一些子数据集则需要持续训练到近5个Epoch甚至更久。这种观察在不同的模型规模和架构中是一致的。
3. 朴素解决方案的局限性
面对上述图 2 中可视化的异构过拟合问题,一个直接且朴素的解决方案是:利用搜索找到每个子数据集的 ,并在新的训练轮次中,当达到这些特定的计算点时,将相应的子数据集从训练混合中剔除。作者将这种方法命名为单次试探搜索SFT(Single Roll-out Search SFT, 简称 SRO SFT)。
SRO SFT 包含两个阶段:
-
单次试探搜索(Single roll-out search):正常训练模型并记录每个子数据集达到峰值性能的计算量 。 -
带异构排除的从头训练(Train from scratch with heterogeneous exclusion):重新初始化模型进行训练,根据第一阶段记录的 时间表,在相应的节点将子数据集剔除。例如,若 AQUA-RAT 的最佳节点是 1.25 Epoch,SciQ 的最佳节点是 2.75 Epoch,则在第二阶段训练至 1.25 Epoch 时停止输入 AQUA-RAT 数据,在 2.75 Epoch 时停止输入 SciQ 数据。
然而,SRO 搜索方法存在一个关键的局限性:在搜索阶段找到的所谓“最佳计算量”,在第一个子数据集被排除后,仅仅是一个近似值。
我们可以通过梯度的形式化定义来解释这一点。令模型在步骤 的参数更新由当前活跃数据集混合的聚合梯度驱动。在搜索阶段(阶段 1)中,排除集为空(),因此参数更新是所有 个任务 的加权梯度之和:
其中 是子数据集 的权重。因此,在搜索阶段确定的任意特定任务 的最佳计算预算 ,是在完整的、未删减的混合数据集所产生的梯度交互条件下得到的。
但是,在 SRO 训练阶段(阶段 2)中,一旦某个达到了最佳点的子数据集 被添加到排除集 中,此时模型参数的更新规则就发生了改变:
由于去除了 的梯度贡献,优化轨迹开始发生偏移()。随着时间推移,排除集 的规模增大(越来越多的任务被剔除),当前的活跃梯度总和与原始搜索阶段的梯度动态之间的偏差会越来越大。这导致预先计算出的 对于后期的任务变得不再准确。
为了从经验上验证这一参数发散()是否会导致最佳计算量的偏移,作者构建了一个包含 个子数据集的等权重混合物。模型在完整的混合数据集 上训练,直到第一个子数据集(记为 )出现过拟合。在这个确切的检查点,作者将训练过程分为两个分支:
-
分支一:继续在完整的混合数据集 上训练。 -
分支二:在排除了 的缩减混合数据集 上继续训练。
对于剩下的 9 个任务(),作者比较了在完整混合数据上达到的最佳计算量()与在缩减混合数据上达到的最佳计算量()。偏移量定义为 。
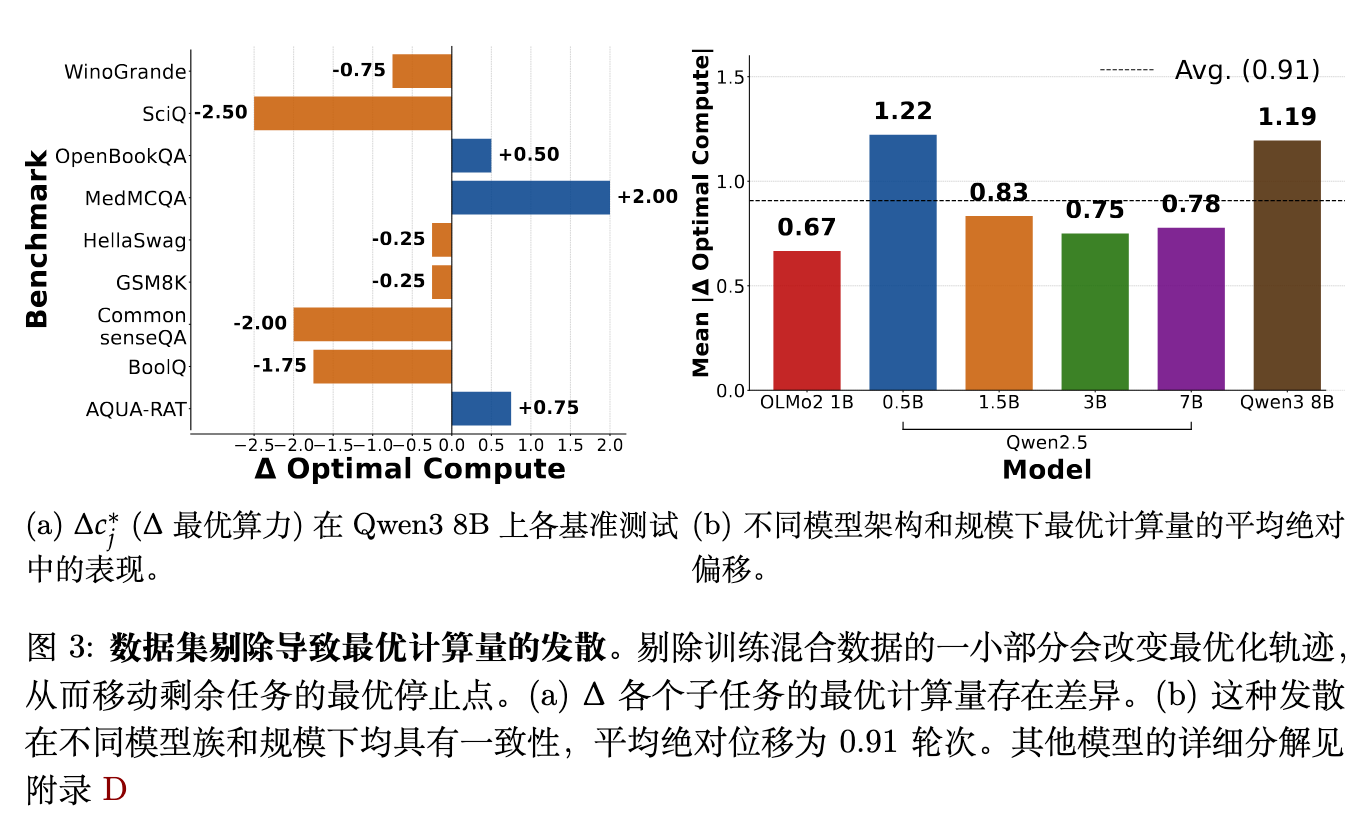
结果表明,即使仅排除训练数据的一小部分(例如1/10),也会明显改变剩余任务的最佳停止点,这证实了先前的假设,即 。
4. mSFT 算法:多任务数据混合的异构早停
针对 SRO 算法中搜索阶段和训练阶段不一致的问题,作者提出了 mSFT(Multi-task SFT)算法。该算法确保了搜索阶段和训练阶段是对齐的。mSFT 遵循一种迭代的 试探(Roll-out) 和 回滚(Roll-back) 搜索机制。
4.1 算法流程详解
mSFT 的执行逻辑如下(参考算法 1):
初始化 (Initialization):
首先,算法初始化一个排除集 ,用于记录已经被排除的子数据集(初始为空 )。同时将当前活跃的模型参数 设置为基础模型参数 。只要还有一个活跃的子数据集未被排除(即 ),算法就会持续进行循环。
试探 (Roll-out):
对于每一个尚未被排除的活跃子数据集 ,模型 会根据一个预先定义的计算预算超参数 进行训练。这里的 类似于传统文献中的 Epoch,但为了捕捉更细粒度的过拟合行为,作者使用了小数级别的计算预算(例如 1/4 个 Epoch 作为评估步长)。
在试探训练期间,算法会记录当前活跃子数据集在验证集上的最佳表现和对应的最佳计算量 。在预算 范围内,最早发生过拟合的子数据集将被标记为待排除对象 ,其对应的过拟合发生点记为 。
如果在一个试探阶段内,没有任何子数据集在预算 内发生过拟合(即 ),算法更新当前模型参数 ,并直接进入下一个循环,无需回滚。
回滚 (Roll-back):
如果发现了最早发生过拟合的子数据集,该子数据集 会被加入排除集 ,在未来的训练中将不再作为活跃数据参与梯度更新。关键的是,模型参数 会被回滚(重置)到它发生过拟合的那个精确的中间检查点 。随后,基于这个回滚后的检查点,对剩余的活跃数据集开启下一轮的试探。

通过这种设计,mSFT 避免了朴素方法中的梯度轨迹偏移问题。在决定剥离某个数据集之前,模型的状态都是确切发生的,不存在近似导致的后续轨迹偏差。
5. 实验研究设置
5.1 基础模型选择
为了覆盖不同规模和家族的模型,作者在实验中采用了以下 6 种开源模型:
-
OLMo 2 1B -
Qwen2.5 0.5B, 1.5B, 3B, 7B -
Qwen3 8B
5.2 对比基线 (Baselines)
作者将 mSFT 与以下四种基线方法进行了比较:
-
标准 SFT (Standard SFT) :目前的事实标准,将所有子数据集混合并在固定的计算预算内进行同质训练。 -
持续 SFT (Continual SFT) :按顺序依次对每个子数据集进行训练,允许每个数据集达到其最佳的早停点,然后再切换到下一个数据集。 -
DynamixSFT :一种优化数据集混合比例的算法,使用带有 1 步前瞻(1-step roll-out)的多臂老虎机(Multi-armed bandits)机制动态调整混合比例。 -
实例依赖早停 (Instance-dependent Early Stopping, IES) :该方法计算每个数据实例的二阶导数,并通过一个阈值超参数排除那些已经“掌握”的实例。
5.3 训练与评估设置
为了公平对比,所有重叠的训练配置在不同方法之间均保持一致。重叠的超参数是在标准 SFT 下进行调优确定的(如学习率 ,恒定学习率调度,批次大小 64,随机种子 20,各子数据集抽取 1800 个样本等)。
实验使用了 个子数据集,涵盖了科学与知识、常识与语言、数学与定量推理等领域,包括:CommonsenseQA, OpenBookQA, AQUA-RAT, GSM8K, SciQ, ARC-Easy, HellaSwag, Winogrande, BoolQ, 和 MedMCQA。
所有方法均在测试集上采用 5-shot 贪心解码进行评估,评估间隔为 1/4 个 Epoch,报告表现最佳的检查点的分数。
6. 主要结果与发现
6.1 整体性能与鲁棒性
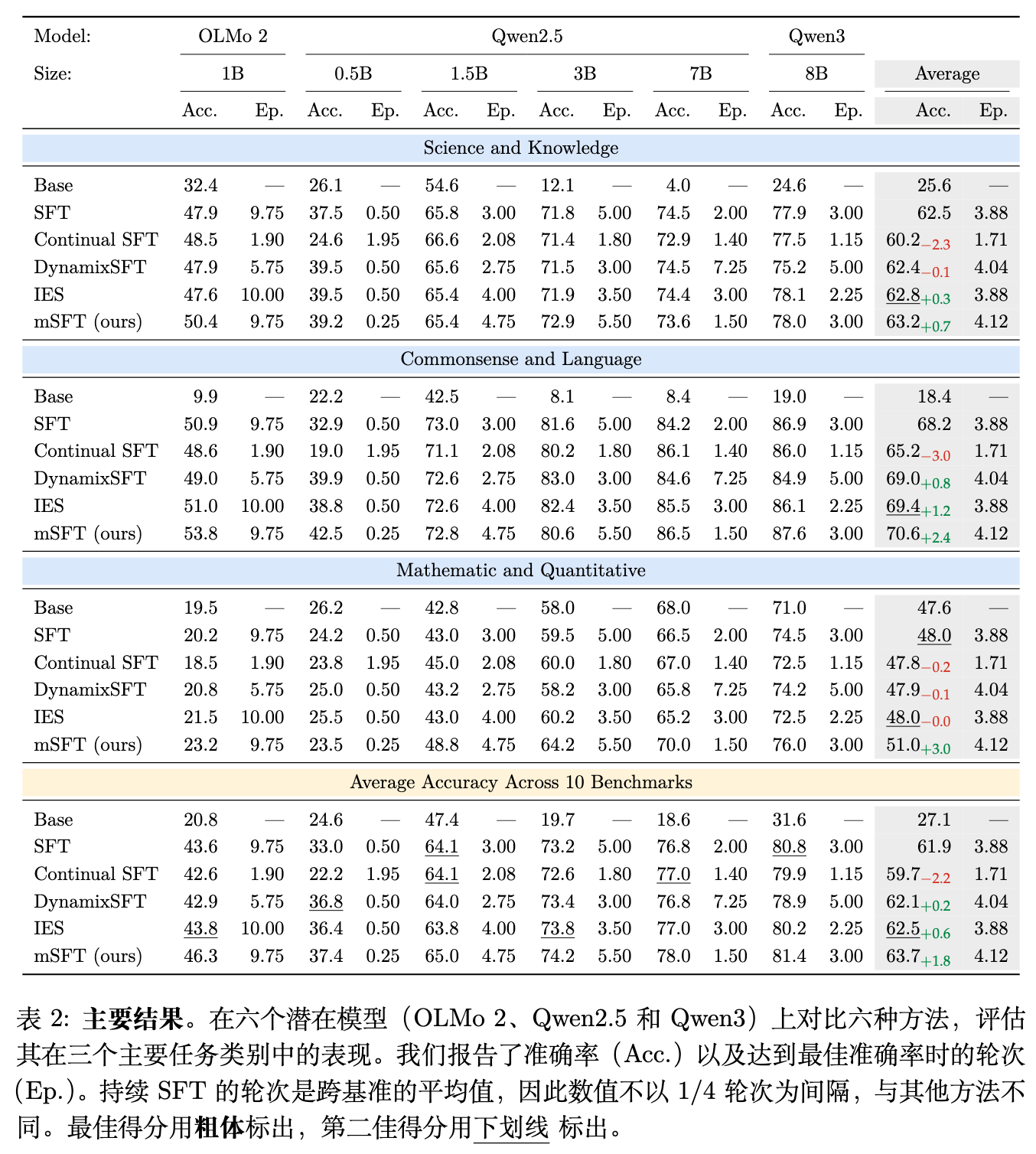
根据表 2 呈现的六种底层模型上的平均结果:
-
mSFT 始终超越所有基线方法,在 10 个基准测试上获得了最高的平均准确率(63.7%)。 -
DynamixSFT(62.1%)和 IES(62.5%)等高级基线虽然相比标准 SFT(61.9%)产生了边缘增益,但幅度有限。 -
持续 SFT(59.7%)因为灾难性遗忘遭遇了明显的性能下降(-2.2%)。 -
mSFT 在三个主要任务领域中展现了独特的稳健性,它是在所有主要领域都实现一致提升的唯一方法:科学与知识类(+0.7%),常识与语言类(+2.4%),数学与定量推理类(+3.0%)。
6.2 一致性与异常值分析
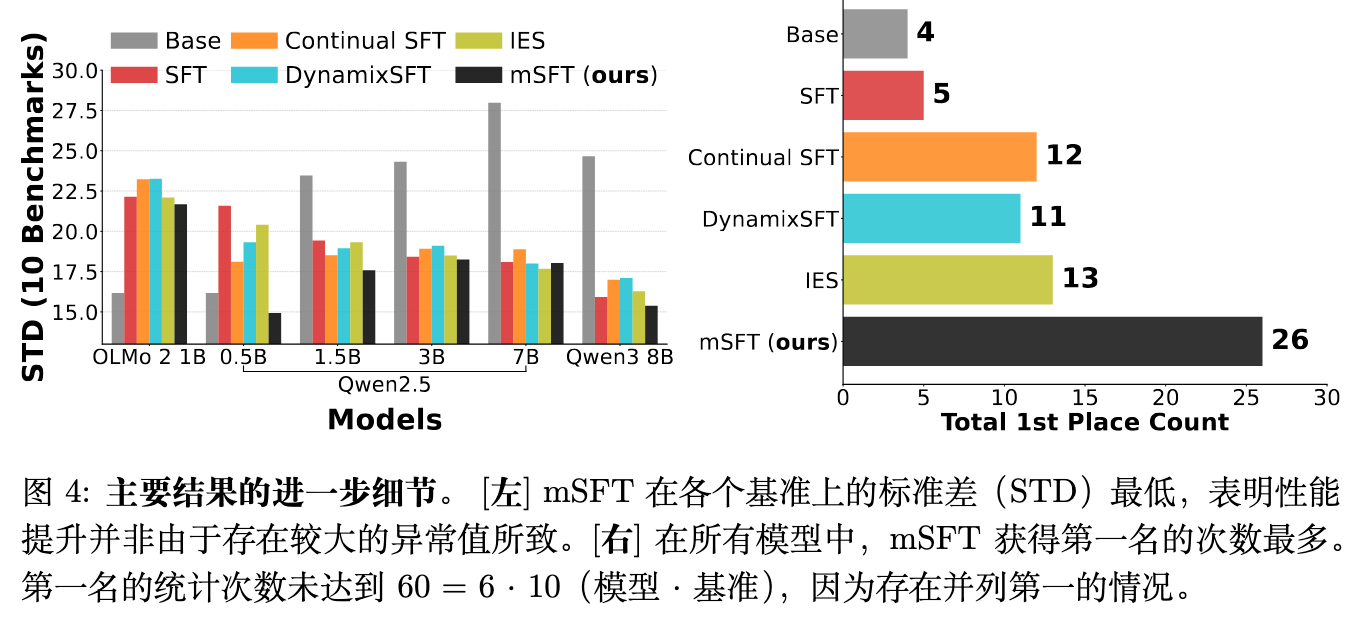
除了聚合准确率的提升,mSFT 还表现出系统级的稳定性。
-
低标准差:图 4 的左侧显示,mSFT 在各基准测试中通常维持最低的标准差(STD)。这表明,平均性能的提升来源于广泛分布的一致性增长,而不是由少数离群任务的异常高分拉高的。 -
单项冠军次数:图 4 的右侧显示,在所有的模型配置中,mSFT 在单个基准测试上获得第一名的总次数达到 26 次,是排名第二的基线方法(IES,获得 13 次第一名)的两倍。这证明 mSFT 在多样化的任务集合中能可靠地提升性能下限和上限。
6.3 朴素早停方案的消融实验
为了验证 SRO 方法的局限性,作者进行了消融实验。除了前面提到的 SRO SFT,还引入了 Soft SRO SFT。Soft SRO SFT 旨在通过调整混合比例(Mixture ratios)而非强硬排除(Hard exclusions)来复制 SRO SFT 的效果,以期减少灾难性遗忘。
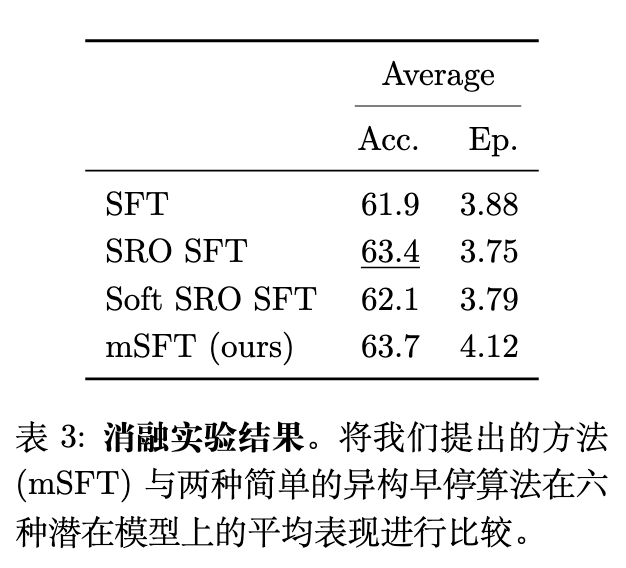
结果表明,mSFT 的平均性能(63.7%)优于 SRO SFT(63.4%)和 Soft SRO SFT(62.1%)。这验证了通过单次试探搜索获得近似最佳计算量 的朴素方法在面对多任务混合时确实是次优的,mSFT 的动态回滚机制不可或缺。
7. 深入分析
为了严谨评估 mSFT 的实际效用,作者使用 Qwen2.5 3B 模型进行了额外的多维分析。对比对象设定为最广泛采用的标准 SFT 和在前期实验中表现最强的基线 IES。
7.1 mSFT 对数据集规模的鲁棒性
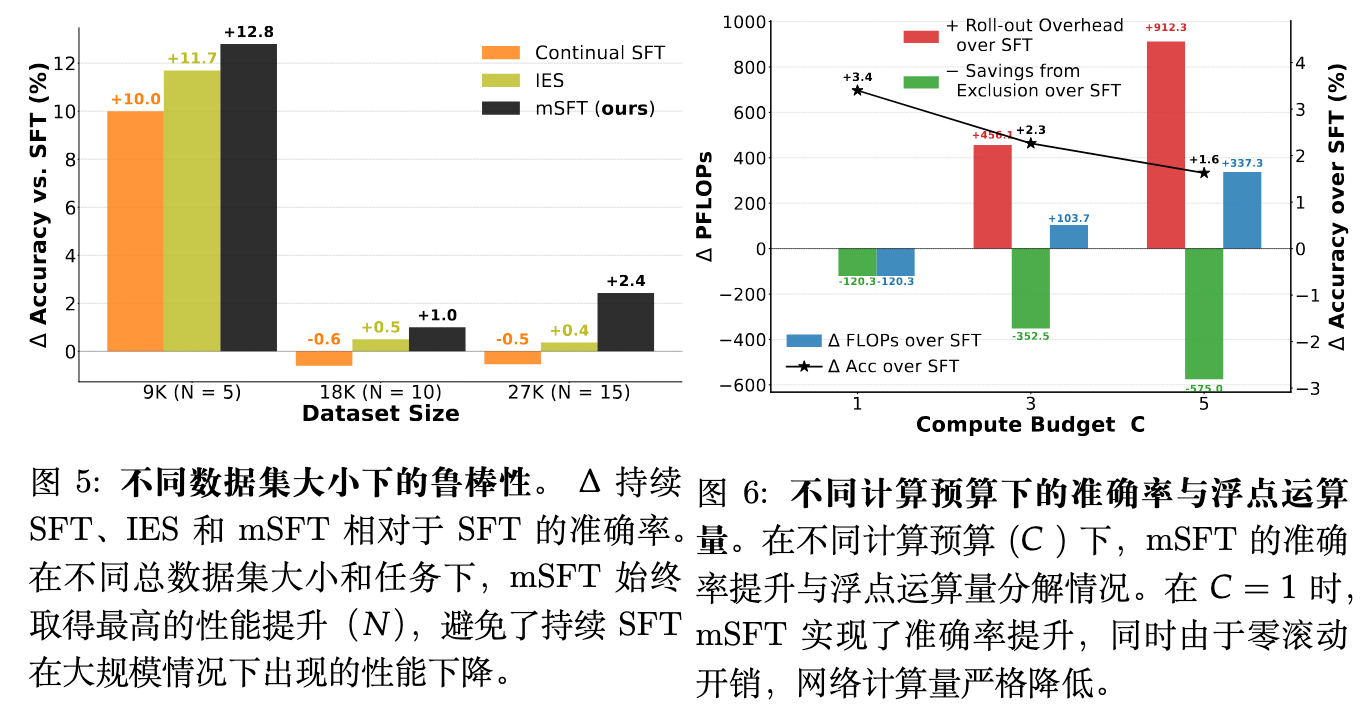
作者改变了数据集的总规模和任务数量()。图 5 实验发现,无论在何种配置下,mSFT 始终优于标准 SFT,平均性能提升达到 +5.4%。此外,mSFT 有效避免了持续 SFT 在面临较大规模任务序列时出现的遗忘退化问题。
7.2 计算预算 C 的不敏感性及 FLOPs 节约
在实际的计算预算受限情况下,作者测试了缩小试探超参数 的影响。图 6 当设置 时,mSFT 依然实现了 +3.4% 的准确率提升,同时相比标准 SFT,平均节约了 120.3 PFLOPs 的计算量。这种效率提升的原因在于:当 较小时,mSFT 不会产生多余的试探(Roll-out)开销,而在训练过程中随着子数据集动态被排除,活跃计算量减少,从而直接导致总计算量的下降。值得注意的是,随着预算 的减小,mSFT 的性能收益并未出现衰减。
7.3 在更细粒度任务划分上的有效性
为了测试 mSFT 在高度细粒度层面的表现,作者将其应用于 MedMCQA 数据集,该数据集预先定义了 21 个子类别(按学科分类)。
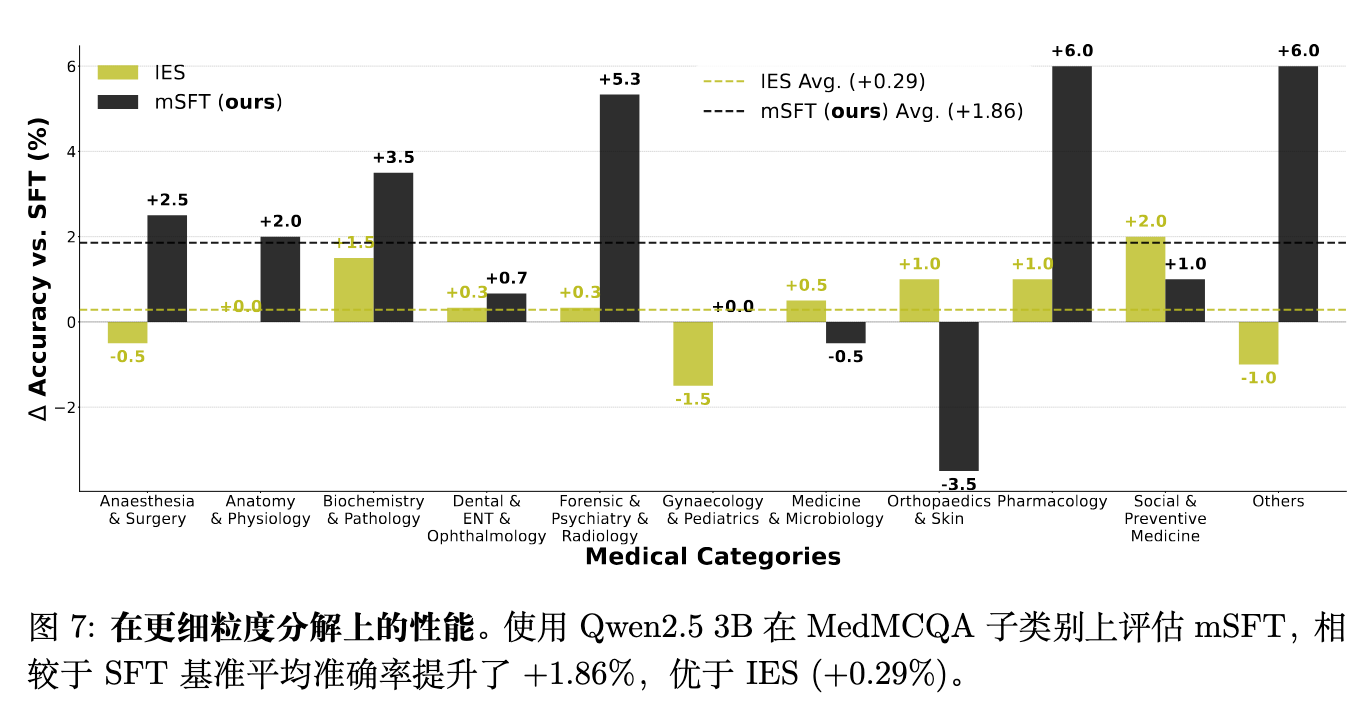
图 7 结果显示,在 Qwen2.5 3B 上,mSFT 相较于标准 SFT 平均准确率提升了 +1.86%,优于 IES(+0.29%)。在诸如药理学(Pharmacology, +6.0%)和法医、精神病学与放射学(Forensic, Psychiatry & Radiology, +5.3%)等高度专业化领域,性能提升尤为显著。尽管存在特定主题的波动,mSFT 在大多数子类别上均实现了一致的改进。
7.4 预防过拟合与灾难性遗忘的效果分解
为了更好地理解避免过拟合与引入硬排除(Hard exclusion)可能带来的灾难性遗忘风险之间的权衡,作者对 mSFT 相对于 SFT 的性能增益进行了量化分解。
数据集排除带来的遗忘(或迁移)效应定义为:
其中 表示 SFT 全局最佳检查点,而 表示试探搜索中识别到的局部最佳性能检查点。
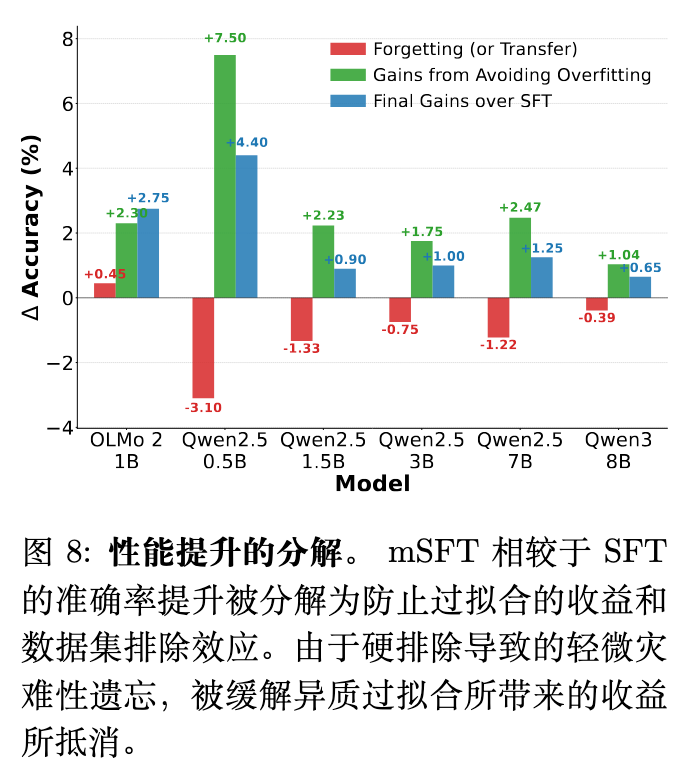
如果公式 4 的结果为负值,则表明硬排除引发了遗忘,这是实证中最常见的结果。相反,偶尔出现的正值表明,在移除该数据集后,继续在剩余混合数据上训练触发了正向迁移。
通过从整体性能增益中减去这部分效应,孤立出了防止异构过拟合所带来的纯收益。分析表明,尽管硬排除平均会带来轻微的遗忘惩罚,但缓解异构过拟合所带来的巨大增益足以盖过这些损失,从而驱动了 mSFT 整体的优越性。
7.5 mSFT 通常能获得更低的训练损失
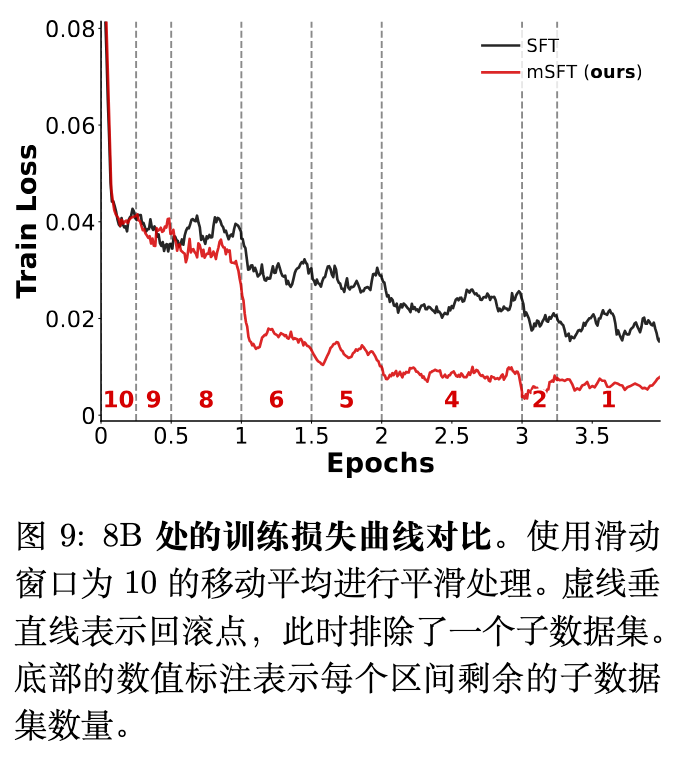
作者观察到,mSFT 通常比标准 SFT 能够实现持续更低的训练损失。在 Qwen3 8B 模型的曲线上,偶尔会出现一种阶梯式的急剧下降现象。这通常发生在过拟合的子数据集刚刚被排除之后(虚线处)。
作者提出了一种假设:这反映了梯度冲突的缓解。在标准 SFT 中,同步的更新可能会导致对某些任务的优化对其他任务造成干扰;尤其是当一个学习速度快的数据集越过了它的最佳点后,它很可能会开始引入充满噪声的、过度专业化的梯度。通过动态过滤掉这些跨过峰值的数据集,mSFT 减轻了优化器的负担,使得模型能够重新分配容量,更加高效地最小化剩余的、学习较慢任务的损失。
8. 讨论与总结
在多任务学习和语言模型微调相关的广泛文献中,已有诸多关于数据混合比例、基于梯度的任务重加权(如 GradNorm、PCGrad 等)的研究。然而,这些动态调整任务权重的方法往往需要在前向/反向传播中进行持续的梯度干预,或者引入多个敏感的超参数(如历史窗口长度、预热步数、温度参数)。
相比之下,本文提出的 mSFT 算法严格作用于数据调度层和执行硬排除(Hard exclusions)。它完全避免了基于步的(per-step)梯度级别干预带来的巨大计算开销,也没有引入复杂的重新加权系统。
总结而言,mSFT 指出了 SFT 阶段长期存在的一个默认假设——同质计算分配——的局限性,证明了不同任务间过拟合动态的异构性。通过简单的试探与回滚机制,mSFT 为语言模型多任务微调建立了一个具备过拟合感知能力的实用训练框架。这不仅能够跨模型、跨数据集规模稳定地提升模型能力,更在特定计算约束条件下证明了其节约训练算力的实际价值。对于正在微调大规模语言模型的研究员和工程师来说,关注子数据集层面的差异化收敛行为,并采用类似于 mSFT 的早停退出策略,是进一步压榨模型潜能和算力效率的可行路径。
更多细节请阅读原文。
往期文章:


