
其它5
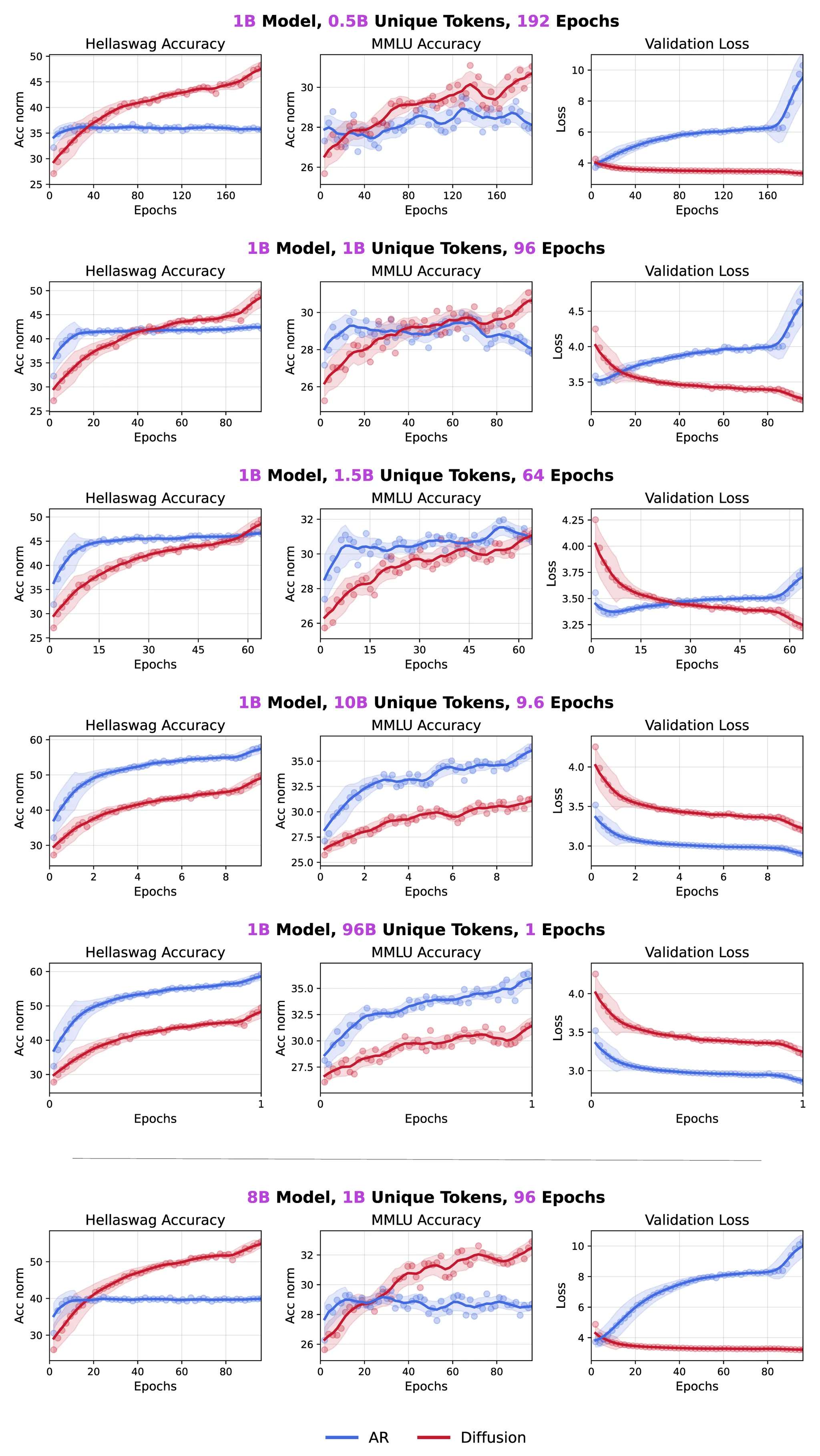
Diffusion:真正的王牌不是“快”,而是“超级数据学习者”
近期,扩散语言模型(Diffusion Language Models, DLMs)的研究热潮凸显了其巨大的潜力。得益于并行的解码设计,DLMs 能够以每秒数
...
Leetcode 出题频率 [4014 道题]
支持标签、难度、频率筛选,文档链接放在公众号底部菜单啦~
...
蒙特卡洛法近似KL散度的艺术:从有偏估计到零方差优化
在强化学习和概率建模的世界里,KL散度如同一位沉默的裁判,默默地衡量着两个概率分布之间的差异。然而,当面对高维空间或复杂分布时,KL散度的计算常常令人望而却步。本文将揭示一种优雅的近似方法,利用蒙特卡
...
Ripro V5主题增加推广用户送会员
最近在用这个主题,想加强一下推广功能。随手记录一下Ripro V5主题增加推广用户送会员功能,每满5人送一个月会员。
代码在ripro-v5/inc/template-admin.php中修改
//
...
Self-Attention中Dot-Product为什么要Scale(为什么要除以根号d)
在自注意力机制(Self-Attention)中,缩放点积(Scaled Dot-Product Attention)用于计算查询(Query)和键(Key)之间的相似性得分。缩放点积的公式如下:
其
...