
-
论文标题:Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning -
论文链接:https://www.arxiv.org/pdf/2512.07461
TL;DR
北京通用人工智能研究院(BIGAI)NLCo Lab 团队提出了一种名为 Native Parallel Reasoner (NPR) 的框架,旨在使大型语言模型(LLM)能够在不依赖外部教师模型(Teacher-free)的情况下,自主演化出原生的并行推理能力。
NPR 通过三个渐进阶段将模型从顺序推理转换为并行推理:
-
冷启动(Cold-start):利用格式跟随强化学习(Format-follow RL)在无监督情况下发现并行结构。 -
并行预热(Parallel Warmup):通过自蒸馏数据的拒绝采样和监督微调(SFT),引入严格的拓扑约束(并行注意力掩码和位置编码)。 -
原生并行 RL(Native-Parallel RL):提出并行感知策略优化(PAPO)算法,直接在并行执行图中优化分支策略。
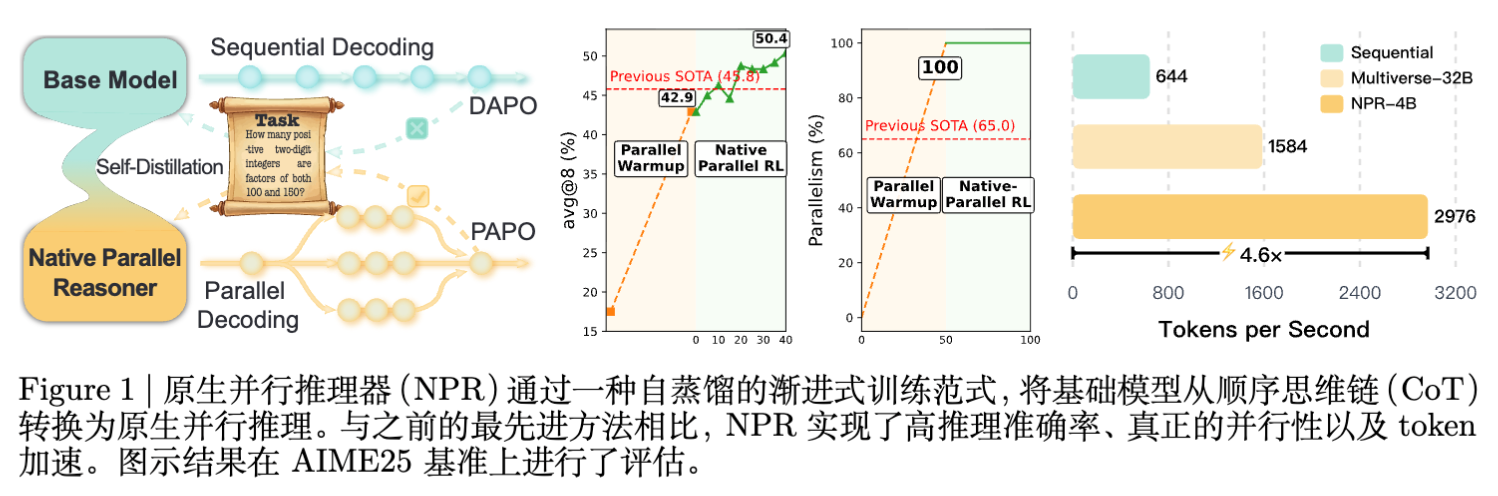
此外,为了支持大规模并行 RL 训练,研究团队重构了 SGLang 的底层逻辑,开发了 NPR Engine,解决了并行生成中的 KV Cache 内存泄漏和流控制问题。实验表明,在 Qwen3-4B 上,NPR 在多个推理基准上取得了显著的性能提升(最高 +24.5%)和推理加速(最高 4.6 倍),并实现了 100% 的原生并行触发率。
1. 引言
随着 Gemini 3、GPT-5 和 DeepSeek-V3.2 等超大规模语言模型的出现,AI 的前沿已经从语义流畅性转向了深度、多步的代理推理(Agentic Reasoning)。目前的测试时扩展(Test-time Scaling)主要集中在“更深”的思考(Chain-of-Thought),但为了处理复杂的任务,探索多样化轨迹的“更宽”的并行推理能力变得愈发重要。
类似于分布式计算中的 MapReduce 范式,理想的 LLM 应具备将任务分解、并行处理并聚合结果的能力。然而,现有的开源 LLM 缺乏这种原生的并行架构。
目前实现并行推理的尝试主要面临三个缺陷:
-
算法与架构不兼容:现有的推理引擎(如 vLLM, SGLang)难以精细控制并行分支与聚合;标准的 RL 算法(如 PPO, GRPO)容易对控制分支的特殊 Token 进行梯度裁剪,导致无法学习到严格的结构。 -
低效的手工并行:早期的并行尝试通常依赖手工设计的“分而治之”规则,且分支间无法共享 Key-Value (KV) 状态,导致计算冗余,延迟成本高昂。 -
依赖监督蒸馏:如 Multiverse 等框架虽然实现了并行,但严重依赖于从更强的教师模型(Teacher Models)蒸馏出的数据。这限制了学生模型只能模仿教师的顺序推理拓扑,形成了“智能天花板”,难以演化出模型内在的并行策略。
针对上述问题,NPR 提出了一套完整的解决方案,探索 LLM 在不依赖外部监督的情况下自演化并行推理能力的潜力。
2. NPR 框架总览
NPR 的核心思想是通过一个三阶段的课程学习(Curriculum Learning),逐步诱导、稳固并增强模型的并行推理能力。
如图所示,NPR 的训练流程包含以下三个阶段:
-
阶段一:格式跟随强化学习(Format-follow RL)。使用 DAPO 算法,通过格式奖励诱导模型输出结构化的并行格式(NPR-ZERO)。 -
阶段二:拒绝采样与并行预热(Parallel Warmup)。基于 NPR-ZERO 进行自蒸馏,构建数据集,通过并行 SFT(引入并行注意力掩码和位置编码)训练得到 NPR-BETA。 -
阶段三:原生并行强化学习(Native-Parallel RL)。使用提出的 PAPO 算法和 NPR Engine,直接对并行策略进行优化,得到最终的 NPR 模型。
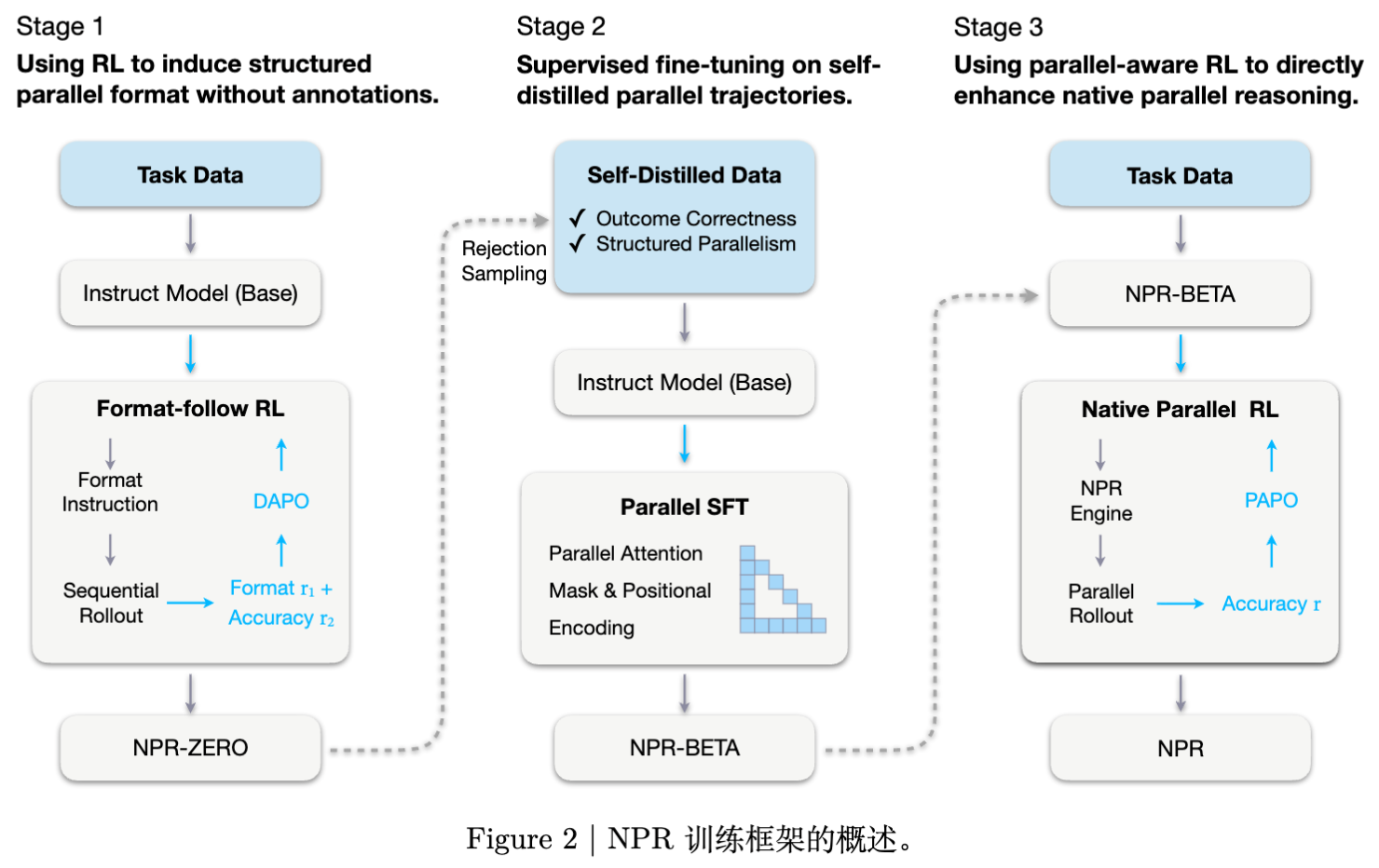
下文将详细解析每个阶段的技术细节。
3. 格式跟随强化学习
要实现并行推理,首先需要模型能够生成支持分解和聚合的结构化输出。NPR 采用了简化版的“Map-Process-Reduce”范式。
3.1 结构化输出 Schema
NPR 定义了一套明确的 Tag 体系来引导并行生成:
-
<guideline> ... </guideline>:包含多个<plan>,定义 Map 阶段的任务分解。 -
<step> ... </step>:Process 阶段,每个 step 块独立且并行地执行一个 plan。 -
<takeaway> ... </takeaway>:Reduce 阶段,汇总所有 step 的结果。
为了在没有外部教师数据的情况下让模型掌握这种格式,NPR 从一个预训练的指令微调模型(如 Qwen3-4B-Instruct)开始,应用 DAPO 算法。
3.2 奖励函数设计
此阶段的奖励函数由两部分组成:
-
格式奖励: -
输出符合 Schema 检查:奖励为 0.0。 -
输出不符合 Schema:给予 (0.0, -2.0] 区间的惩罚。
-
-
准确率奖励: -
格式正确且答案正确:+1.0。 -
格式正确但答案错误:-1.0。
-
通过这种方式,模型(NPR-ZERO)首先学会了“如何生成并行格式”,但这时的并行在底层仍然是顺序生成的(Simulated Parallelism),即模型在生成第 个 step 时仍然可以看到第 () 个 step 的内容。
4. 拒绝采样与并行预热
阶段一得到的 NPR-ZERO 虽然具备了格式,但缺乏真正的并行执行所需的拓扑约束。阶段二的目标是将这种顺序模拟转化为真正的并行执行。
4.1 结构化轨迹的自蒸馏
为了获取高质量的训练数据,NPR 采用自蒸馏(Self-Distillation)策略。对于数据集中的每个问题 ,使用 NPR-ZERO 采样 个回复。
采样后的轨迹需通过两个过滤器:
-
结果正确性:预测答案 必须匹配标准答案 。即 。 -
结构并行性:轨迹必须严格遵守 Schema 定义。即 。
被接受的样本集合表示为:
这些数据构成了后续监督微调(SFT)的基础。
4.2 并行注意力掩码与位置编码
这是实现“原生并行”的关键技术。在 SFT 阶段,NPR 引入了特定的注意力掩码(Attention Mask)和位置编码(Positional Encoding),强制模型在生成不同的 <step> 时无法相互“看见”,从而在物理层面上实现并行。
并行注意力掩码 (Algorithm 1)
标准 Transformer 使用因果掩码(Causal Mask),即下三角矩阵。而在 NPR 中,掩码矩阵 被修改以阻断并行分支间的注意力。
假设一个序列包含 tag tokens 。
对于属于不同分支的 step 区间 和 (其中 ),掩码被设置为:
这确保了分支 在生成时无法关注到分支 的内容,反之亦然。它们只能关注到共享的 <guideline>(父节点)和之前的 Context。
并行位置编码 (Algorithm 2)
为了让模型理解这些分支是“同时”发生的,位置编码也需要调整。并行的 tokens 共享相同的位置索引。
当遇到 <step> 标签时,位置索引 会被重置回 <guideline> 结束的位置。
具体逻辑如下:
-
遇到 <guideline>结束,记录当前位置 。 -
进入 <step>,将当前生成的 token 的位置索引回退:。 -
并在结束时更新最大长度,确保后续的 <takeaway>能够接在最长分支之后。
通过在 上应用这种并行 SFT,模型(NPR-BETA)学会了在严格的拓扑约束下进行推理。
5. 原生并行强化学习
虽然 SFT 赋予了模型并行原语,但模仿学习(Imitation Learning)受限于训练数据的分布,且 SFT 产生的轨迹在结构多样性上往往不足。为了进一步泛化并优化并行策略,NPR 引入了第三阶段:Native-Parallel RL。
在此阶段,团队发现现有的 RL 算法(如 PPO, GRPO)直接应用于并行生成时存在严重问题,因此提出了 Parallel-Aware Policy Optimization (PAPO) 。
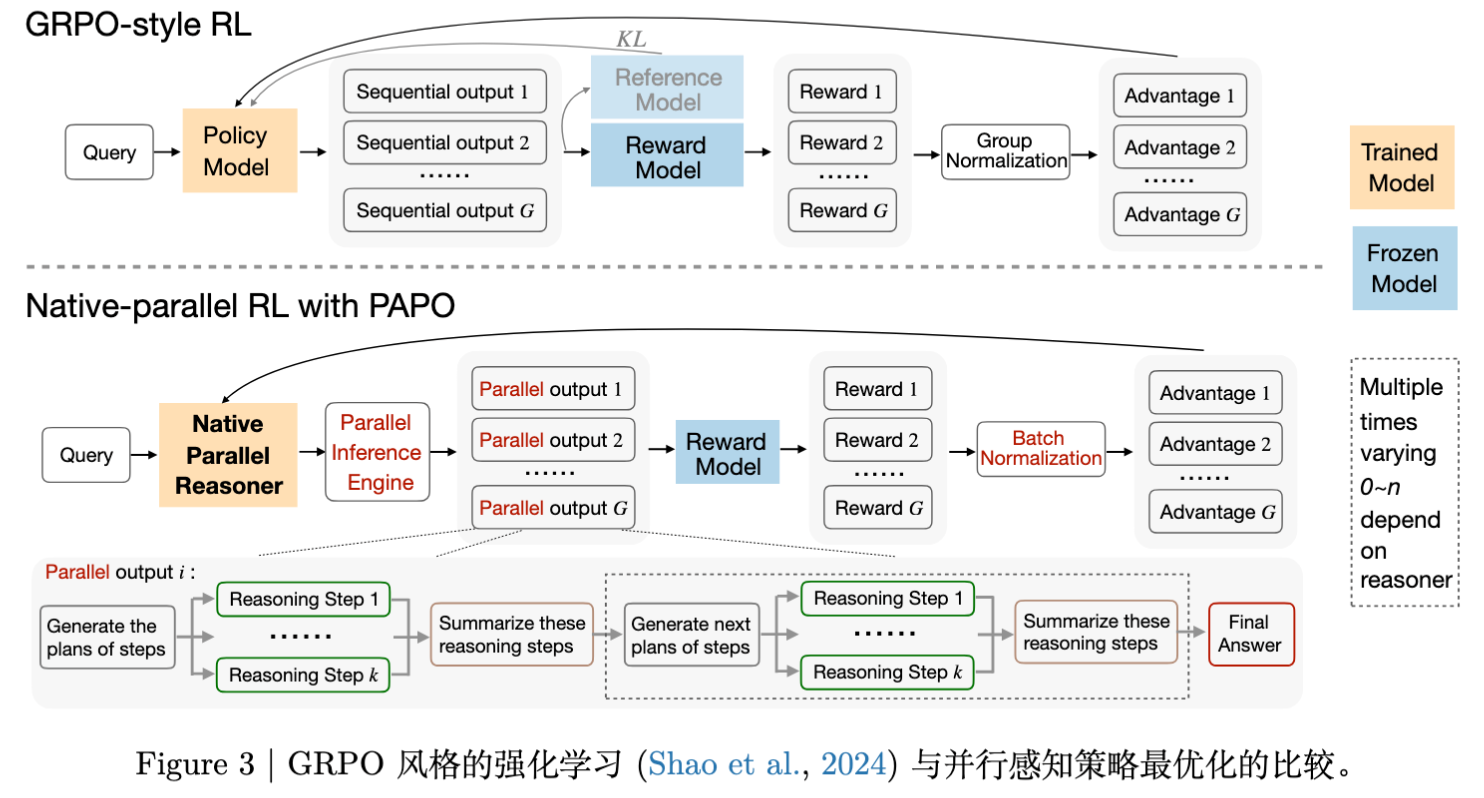
5.1 现有 RL 的问题
-
梯度裁剪问题:PPO 等算法通常会对 token 级别的概率比率(Probability Ratio)进行裁剪(Clip),以防止策略更新过大。然而,控制并行结构的特殊 token(如 <step>)对于维持并行语义至关重要。如果这些 token 的梯度被裁剪,模型很容易丢失结构信息,导致并行崩塌。 -
优势估算问题:在并行生成中,常常需要过滤掉格式错误的样本。这导致基于组(Group-based)的优势估算(如 GRPO)失效,因为组内的样本方差被破坏了。
5.2 PAPO 算法详解
PAPO 针对上述问题进行了三点核心改进:
1. 批次级优势归一化 (Batch-level Advantage Normalization)
由于格式过滤导致组内样本减少,PAPO 放弃了组内归一化,转而使用批次级归一化。对于样本 的第 个 token,其标准化优势 计算如下:
其中 是准确率奖励(正确 +1,错误 -1)。
2. 保护特殊 Token 的梯度
为了维护并行语义,PAPO 移除了 对特殊 token 的 Clip 掩码,确保这些 token 始终接收完整的梯度信号。
然而,移除 Clip 会导致重要性采样(Importance Sampling)的比率不稳定。为了解决这个问题,PAPO 采取了 Strict On-Policy 的策略,即不使用重要性采样,直接使用当前策略采集的数据进行一次更新。这不仅稳定了训练,还避免了重新计算历史对数概率的计算开销。
3. 目标函数
结合上述改进,PAPO 的目标函数 定义为:
注意,这里通过 stop-gradient (sg) 操作来模拟 On-policy 的梯度流,避免了不稳定的重加权。
6. NPR Engine:工程实现与优化
在实际的大规模并行 RL 训练中,团队发现 Multiverse 提供的并行生成引擎(基于 SGLang)在生产环境下存在严重的不稳定性。为此,NPR Engine 对底层进行了重构。
6.1 KV Cache 双重释放与内存破坏
问题:在高并发分支下,SGLang 的 Radix Attention 机制可能会在缓存容量超限时,错误地多次回收同一个共享节点的 KV Cache。这会导致上下文损坏,甚至 GPU 内存泄漏。
解决方案:NPR Engine 引入了显式的、预算感知的回收策略。当检测到 KV 使用量即将超限时,不再进行机会主义的回收,而是强制执行缓存刷新和确定性的块重分配。
6.2 全局 Token 预算低估
问题:原有的长度统计只追踪最长的一条分支。但在并行解码中,总 Token 消耗量是所有分支之和。这导致实际生成的 Token 数远超 max_new_tokens 设定,引发 OOM 或计算超时。
解决方案:引入分支感知的长度统计。引擎在每次扩展分支时记录分支因子(Branching Factor),并更新全局 Token 账本。
6.3 非法并行 Schema 的未定义状态
问题:某些模型生成的并行结构(如嵌套错误)可能落在引擎条件逻辑的盲区,导致未定义行为。
解决方案:在扩展前增加轻量级的预分支格式验证器(Pre-branch Format Validator)。这一检查成本极低,但能确保只有结构合法的分支进入计算图。
6.4 <step> 内部的局部重复
问题:细粒度的并行流容易出现局部重复生成。
解决方案:针对 <step> ... </step> 上下文施加轻微的重复惩罚(系数 1.02),而保持 <guideline> 和 <takeaway> 不变。
通过这些工程优化,NPR Engine 成为了首个能够支持大规模、高吞吐并行 RL 训练的稳定后端。
7. 实验设置
7.1 数据集与模型
-
数据集:使用 ORZ 数据集(Hu et al., 2025)中的 8k 样本子集,涵盖数学和逻辑推理任务。 -
基座模型: -
Qwen3-4B-Instruct-2507 -
Qwen3-4B (Non-Thinking):非 Thinking 模式的 Base 模型。 -
注意:未选用 Thinking 模式模型,因其特殊的 Token 难以进行 SFT。
-
7.2 基线对比 (Baselines)
-
开放顺序推理模型:Qwen2.5-32B-Instruct, Qwen3-4B-Instruct 等。 -
现有并行推理模型:Multiverse (MV-32B, MV-4B)。 -
顺序变体:SR-BETA, SR (纯顺序训练版本)。
7.3 评估指标
-
Accuracy (avg@k) :对于生成 个候选答案的问题,计算期望正确率。 -
Speedup:相对于自回归(AR)解码的挂钟时间加速比。 -
Parallel Rate:并行推理触发率。
8. 实验结果与分析
8.1 总体推理性能
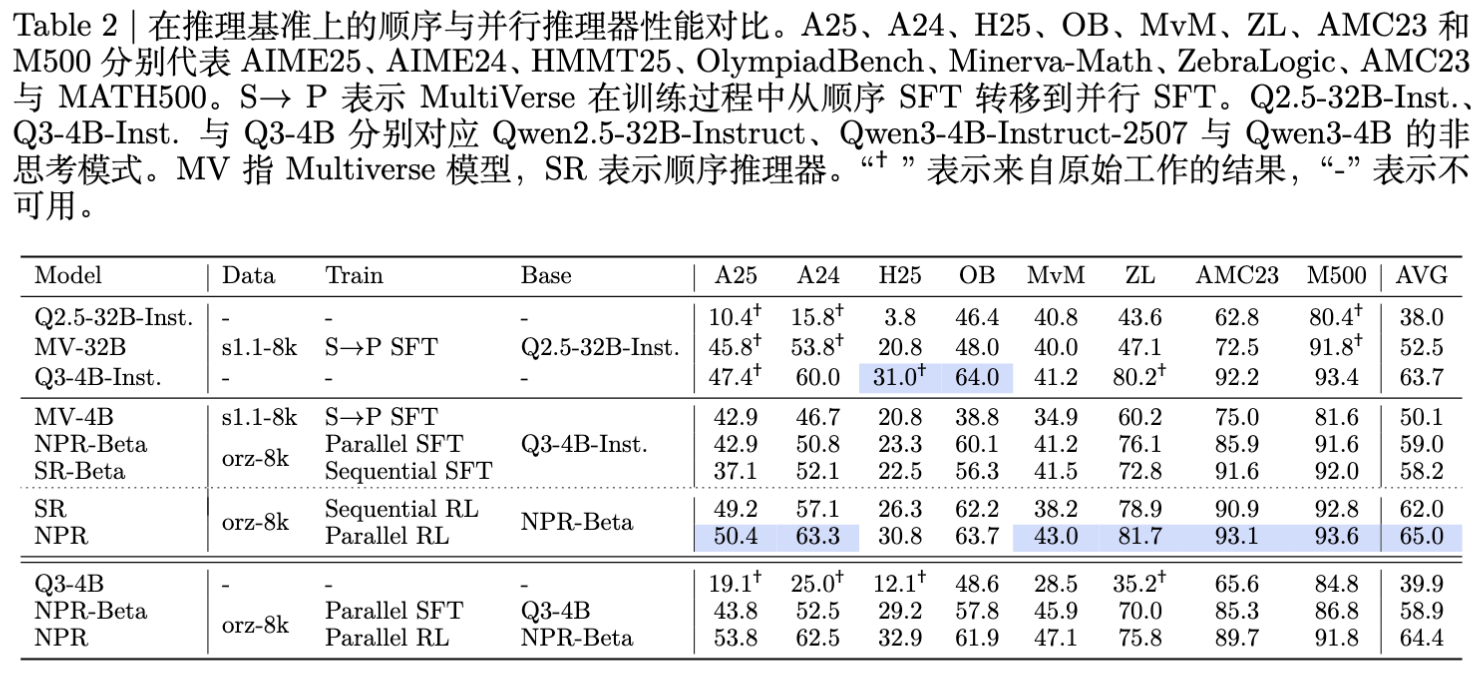
实验结果显示,NPR 在所有基准测试中均超越了基线模型。
-
NPR-4B vs Multiverse-4B:在 AIME 25 上提升 +14.9% ,在 AIME 24 上提升 +12.5% 。 -
NPR-4B (Non-Thinking) :相比基座模型,平均性能提升超过 24.5% 。 -
NPR vs 顺序 RL (SR) :并行 RL 带来的收益是系统性的,在 AIME 24 上提升 +6.2,HMMT25 上提升 +4.5。这证明了自适应的并行策略提供了比单一路径搜索更优的解空间探索机制。
8.2 推理加速与效率
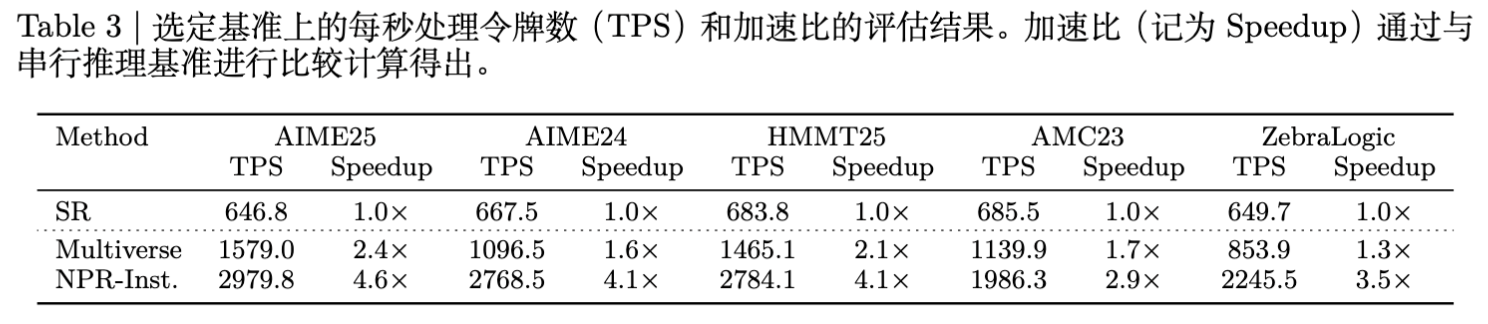
NPR 不仅提升了准确率,还显著提高了推理速度。
-
最高加速比:在 AIME25 上达到 4.6倍 加速。 -
任务难度相关性:有趣的是,加速比与任务难度呈正相关。在较难的 AIME25 和 HMMT25 上加速比更高(>4x),而在较简单的 AMC23 上加速比约为 2.9x。这表明模型在面对困难问题时,倾向于展开更深、更宽的并行探索。
8.3 100% 原生并行

这是 NPR 的一大亮点。
-
Multiverse:并行触发率在 45.8% 到 76.0% 之间波动,且在逻辑任务(ZebraLogic)上表现不佳。这意味着它经常回退到顺序推理。 -
NPR:在所有八个基准测试中均保持 100.0% 的并行触发率。这证明了 NPR 的三阶段训练范式成功地将并行推理内化为模型的默认认知模式,而非简单的模仿。
8.4 测试时扩展性 (Test-time Scalability)
使用 best@8 指标评估。
对于 Non-thinking 模型,NPR 将 AIME 25 的 best@8 从 SFT 的 36.7 提升至 76.7。这表明 NPR 产生的多样化路径是高质量且互补的,极大地提升了覆盖正确答案的概率。
9. 定性分析与案例研究
NPR 具体是如何进行并行推理的?论文提供了详细的案例分析。
案例 1:函数定义域求解
问题:求函数 的定义域。
NPR 的执行流:
-
Guideline:制定 3 个 Plan。 -
Plan 1: 确定分母非零且对数有意义。 -
Plan 2: 分解内层和外层对数的不等式。 -
Plan 3: 综合所有约束。
-
-
Parallel Steps: -
Step 1: 计算出 需要排除。 -
Step 2: 计算出定义域区间 。 -
Step 3: 验证 。 -
Self-Correction: 在 Takeaway 中,模型通过回顾不同分支的结果,进行了交叉验证,发现逻辑一致。
-
-
Takeaway:汇总得到最终区间。
在这个过程中,并行性主要体现在任务分解(将复杂的约束条件拆解验证)和独立执行。
案例 2:几何证明
问题:三角形垂心角度计算。
NPR 的执行流:
-
策略多样性:模型在不同的 <plan>中提出了完全不同的解题思路。-
Plan 1: 利用垂心角度性质。 -
Plan 2: 利用四点共圆(Cyclic Quadrilateral)进行角度追溯。 -
Plan 3: 直接利用公式 。
-
-
并行验证:三个 Step 并行计算,最终在 Takeaway 中发现三种方法殊途同归,得出了相同的结果。
这种多视角交叉验证(Multi-angle Verification)极大地提升了推理的鲁棒性。
10. 总结与展望
Native Parallel Reasoner (NPR) 是一项扎实的工作,它通过精心设计的自蒸馏强化学习流程,解决了 LLM 原生并行推理面临的数据匮乏、训练不稳定和引擎不兼容等核心挑战。
主要贡献总结:
-
Teacher-free 范式:不依赖 GPT-4 或 DeepSeek 等更强模型的蒸馏,仅凭自身演化出并行能力。 -
PAPO 算法:专为并行结构设计的 RL 算法,有效解决了梯度裁剪导致的结构崩塌问题。 -
NPR Engine:解决了并行推理在生产环境下的稳定性问题,为社区提供了可用的基础设施。 -
性能全面提升:在准确率、速度和并行稳定性上均优于现有基线。
往期文章:


