让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
-
论文链接:https://arxiv.org/pdf/2605.03677
TL;DR
今天解读一篇来自浙江大学和腾讯混元的论文《Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe》。在大型语言模型(LLM)和多模态大型语言模型(MLLM)的后训练阶段,将特定领域专家的能力整合到单一学生模型中是一个核心挑战。On-Policy蒸馏(OPD)作为一种结合了强化学习(RL)在线采样和监督微调(SFT)Token级监督优势的范式,近年来受到关注。然而,作者指出,当前的OPD方法面临两个根本性瓶颈:学生模型对信息丰富状态的探索不足,以及教师模型对学生生成轨迹的监督信号不可靠。
为了解决这些问题,作者提出了 Uni-OPD,这是一个统一的OPD框架,适用于LLM和MLLM。该框架的核心是一个双视角优化策略(Dual-Perspective Optimization Strategy)。从学生视角出发,引入了离线难度感知和在线正确性感知的数据平衡策略,以促进模型在训练期间对多样化轨迹的探索;从教师视角出发,作者发现可靠的监督依赖于Token级指导的聚合结果与最终结果奖励保持顺序一致。为此,提出了一种结果引导的边界校准机制(Outcome-guided Margin Calibration),通过掩码或偏移操作修复正确与错误轨迹之间的顺序一致性。
在包含5个领域和16个基准测试的广泛实验中,Uni-OPD 在单教师蒸馏、多教师能力合并、强到弱蒸馏以及跨模态蒸馏(结合纯文本和多模态任务)设置下均表现出稳定的性能提升。实验数据表明,Uni-OPD 能够以比传统RL更少的优化步数实现收敛,并有效缓解了教师信号在分布外区域退化的问题,为构建可扩展且可靠的蒸馏框架提供了实证基础。
1. 引言
在大型语言模型(LLM)和多模态大型语言模型(MLLM)的后训练阶段,注入复杂的推理能力、领域知识和人类偏好是提升模型实用性的关键。传统的后训练方法通常遵循两阶段范式:首先进行监督微调(SFT),然后进行强化学习(RL)。
SFT利用专家数据进行训练,但其本质上是一种Off-Policy(离线策略)方法。模型在训练时只被动地模仿给定的专家轨迹,这引入了暴露偏差(Exposure Bias)。在推理阶段,一旦模型进入其在训练中很少覆盖的错误状态,就容易产生复合错误。相比之下,诸如GRPO等On-Policy(在线策略)的强化学习方法通过在线采样缓解了分布偏移问题。然而,RL主要依赖于序列级别或终端的奖励信号,这使得细粒度的信用分配(Credit Assignment)变得困难,限制了长序列训练的稳定性。
近期,On-Policy蒸馏(OPD)作为一种有效的后训练范式出现。OPD结合了RL和SFT的优势:它允许学生模型在自身采样的轨迹上进行训练(在线采样),同时接受来自更强教师模型的Token级反馈(细粒度监督)。尽管在经验上取得了成功,但当前关于OPD的研究主要局限于纯文本的LLM蒸馏。虽然有少数工作将OPD扩展到MLLM,但通常局限于单一模态内的特定任务子集(如视频或语音)。
除了缺乏统一的框架,作者提出了一个更基础的问题:是什么因素决定了OPD成为一种可靠的优化范式?作者认为,有效的OPD取决于两个关键因素:
-
学生视角的探索:学生模型必须充分探索信息丰富的状态,即生成具有适当难度且多样化的自我生成轨迹。 -
教师视角的监督可靠性:当教师的Token级监督应用于学生的Rollout(展开轨迹)时,必须保持可靠。特别是,当教师的Token级指导在轨迹级别聚合后,能够与结果奖励(Outcome Reward)保持顺序一致性(即正确的轨迹应获得比错误轨迹更高的聚合分数)时,监督的可靠性会得到保障。结果奖励因此提供了一个全局锚点,用于校准不可靠的教师监督。
基于上述观察,作者提出了 Uni-OPD。该框架通过离线和在线的数据平衡策略促进学生探索,并引入结果引导的边界校准机制来获取可靠的教师监督。
2. 预备知识与问题剖析
在深入介绍 Uni-OPD 之前,首先回顾标准 OPD 的数学形式,并剖析教师监督在实际应用中为何会失效。
2.1 On-Policy 蒸馏的数学形式
OPD 保留了优化的 On-Policy 特性,同时提供了 Token 级别的信用分配。在训练期间,学生策略 对其自身的轨迹进行采样,并通过最小化这些样本上与教师策略 的反向 Kullback-Leibler (KL) 散度来进行优化:
在这里, 是输入的提示(问题), 是由学生模型采样的轨迹, 是在时间步 生成的 Token, 是轨迹的长度。 表示训练数据集。
通过对上述目标函数求导,可以得到 OPD 的梯度形式:
其中 表示在时间步 之前的前缀序列。这个梯度公式自然地诱导出了在时间步 的 Token 级奖励,类似于标准强化学习中的优势函数(Advantage):
这个公式为模型提供了细粒度的信用分配信号。当教师模型对某个 Token 的预测概率高于学生模型时, 为正,鼓励学生模型增加该 Token 的生成概率;反之则为负,抑制该 Token 的生成。
2.2 剖析 OPD 中的教师监督失效模式
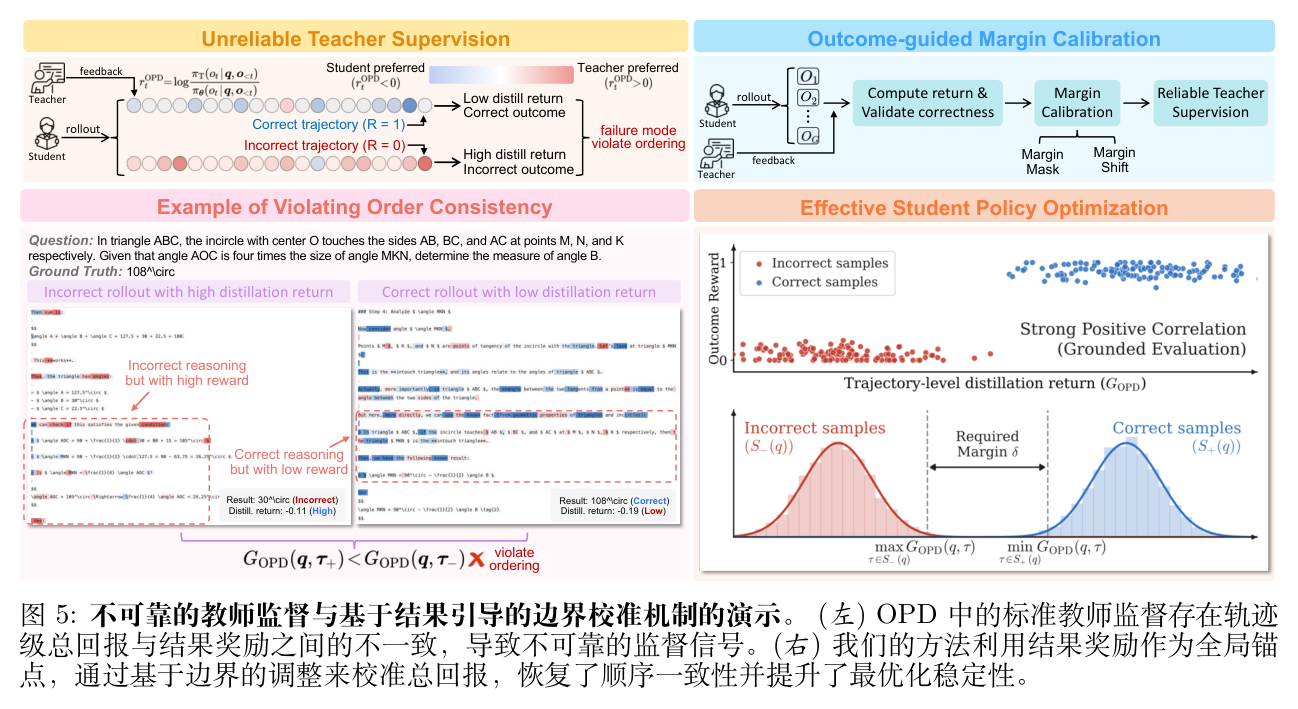
如上述公式所示,OPD 依赖教师模型为学生生成的轨迹提供细粒度的监督。为了使优化有效,这种信号在宏观上应该与整体轨迹的正确性对齐。然而,作者观察到,在实际操作中,这种对齐并不能得到保证,通常会以以下几种典型方式失效:
-
分布外(OOD)退化:当学生的 Rollout 进入相对于教师模型而言稀疏或分布外的区域时,教师的对数概率 可能会变得充满噪声,从而破坏正确轨迹与错误轨迹之间的排名关系。 -
错误轨迹的高估:错误的轨迹可能会获得异常高的分数。这种情况通常发生在错误轨迹的局部 Token 模式碰巧与教师模型的高置信度区域一致时(例如,推理过程的格式很完美,但逻辑是错的)。 -
正确轨迹的低估:正确的轨迹可能会获得异常低的分数。当正确轨迹的生成路径偏离了教师模型的主导区域(例如,学生采用了一种非传统的、但同样正确的解题思路)时,教师模型可能会给出低概率,从而抑制了有用的推理路径。
这些现象表明,单纯依赖教师模型的对数概率是不够可靠的。这构成了本文的核心动机:引入一个客观的“结果奖励(Outcome Reward)”作为全局锚点,在轨迹级别对不可靠的教师监督进行校准。
3. Uni-OPD 方法详解:双视角优化框架
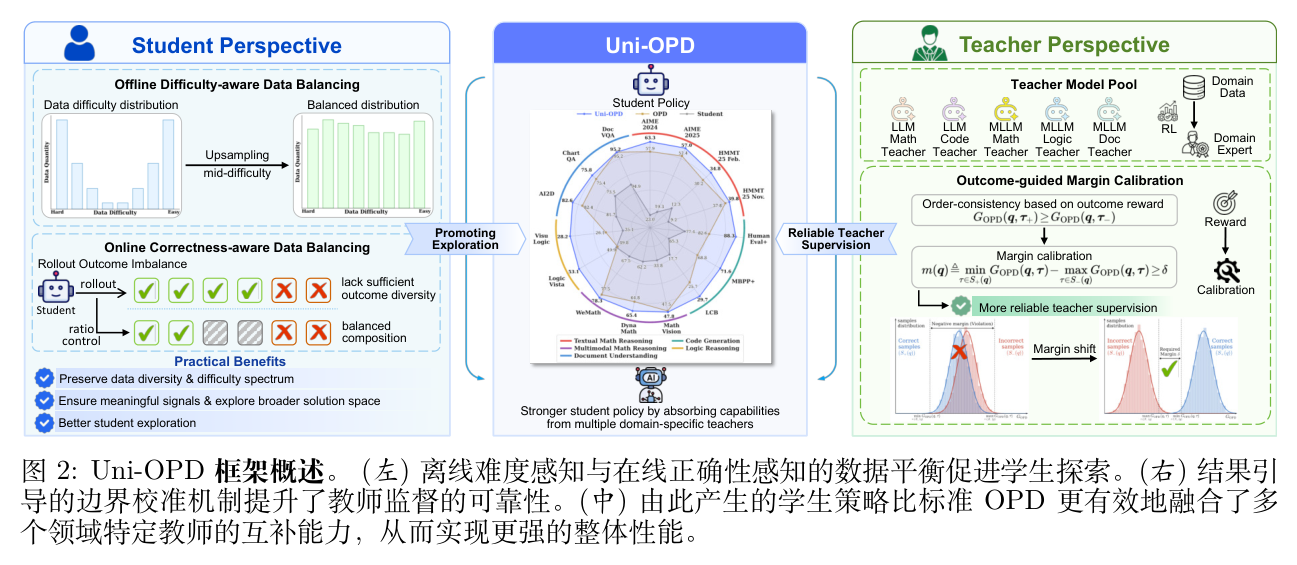
基于对探索不足和监督不可靠这两个瓶颈的分析,作者提出了 Uni-OPD 框架。给定一个专家教师池 ,其中每个教师专精于不同的领域。设 为分配给教师 的权重,Uni-OPD 的总体优化目标定义为:
这个公式为单教师和多教师蒸馏提供了一个统一的目标。在此基础上,Uni-OPD 从学生和教师两个基本角色出发进行优化设计。
3.1 学生视角:联合离线与在线的数据平衡策略
从学生视角来看,生成的轨迹必须具备足够的多样性和适当的难度水平。为此,作者提出了在离线数据构建和在线采样阶段互补的数据平衡策略。
3.1.1 离线难度感知数据平衡 (Offline Difficulty-aware Data Balancing)
在强化学习的常规实践中,通常会通过多次 Rollout 来估计提示(Prompt)的难度,然后过滤掉那些过于简单(即每次都答对)或过于困难(即每次都答错)的样本。原因是这些样本提供的学习信号(Advantage)往往接近于零。
然而,作者在小规模模型上的实证研究表明,训练数据的难度分布通常呈现出镜像的 J 型或 U 型。如果严格移除这些简单或困难的样本,会大幅降低数据的多样性,限制学生对信息丰富状态的探索。实验发现,这种数据过滤会导致 OPD 性能的下降。
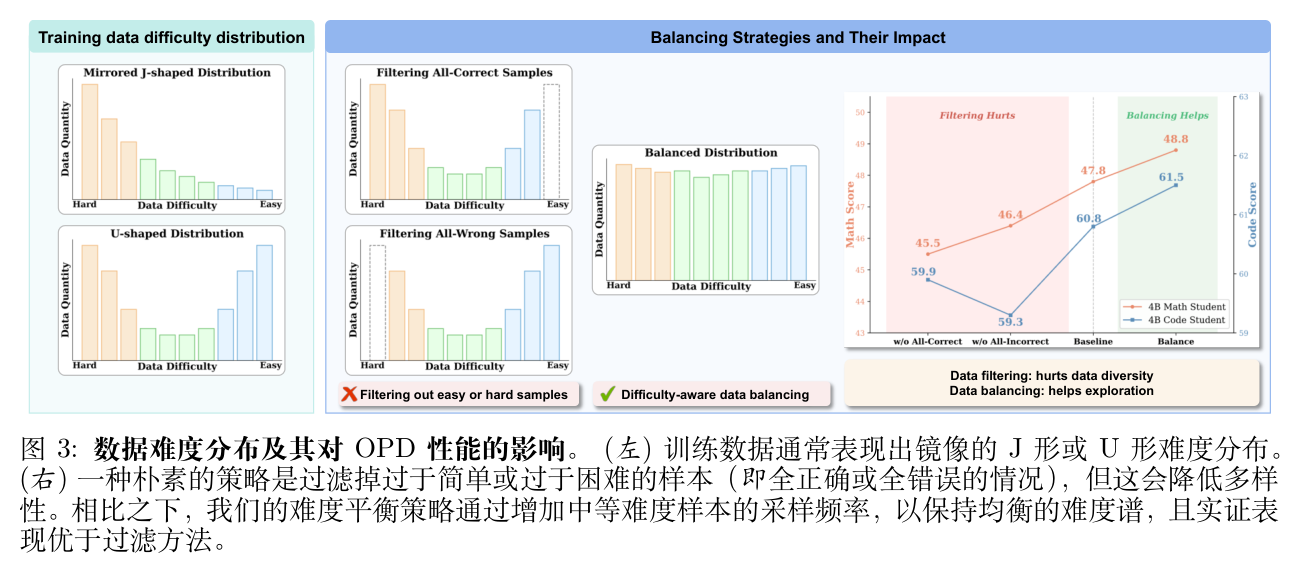
基于这一观察,Uni-OPD 采用了一种难度感知的平衡策略:选择性地上采样中等难度的样本(即在多次 Rollout 中只有部分正确的样本)。这种策略将数据分布重塑为更均匀的形式,同时保留了多样性和难度跨度。实验结果显示,保持数据多样性和平衡的难度谱能够使学生生成更具信息量的轨迹,从而探索更广阔的解空间。
3.1.2 在线正确性感知数据平衡 (Online Correctness-aware Data Balancing)
在应用了离线的难度平衡之后,作者进一步观察到,在训练过程中,如果 Rollout 组内缺乏足够的结果多样性(例如,针对某个 Prompt 采样出的轨迹全部是错误的),模型容易陷入局部最优。
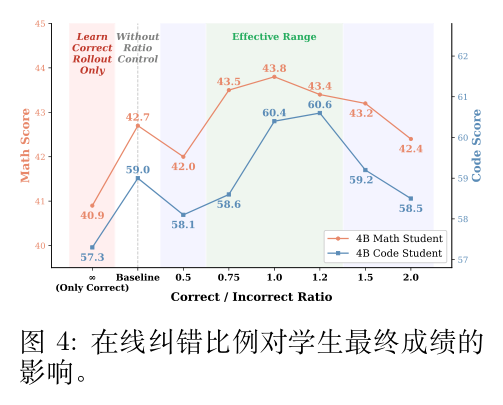
为了缓解这个问题,Uni-OPD 在训练期间显式地强制每个 Rollout 组内正确和错误轨迹的组成保持平衡。具体而言,设定一个目标正确率 。在每一步训练中,如果当前批次中某类轨迹(正确或错误)占比过高,则通过在组内均匀子采样的方式对其进行降权,使整体比例拉回 附近。这防止了所有样本共享相同结果从而产生无信息梯度的退化情况,确保学生模型始终接收到有意义的对比信号。
3.2 教师视角:结果引导的边界校准
在教师视角,核心任务是确保 Token 级监督信号在聚合后与最终的正确性对齐。
3.2.1 轨迹级蒸馏回报 (Trajectory-level Distillation Return)
为了表征沿 Rollout 轨迹的整体监督信号,作者将“轨迹级蒸馏回报”定义为教师和学生之间的平均对数概率差:
这个量衡量了教师模型相对于学生模型在整条轨迹 上的平均对数似然偏好。当 时,表示教师的平均置信度高于学生,鼓励学生向该轨迹移动;反之则抑制。除以轨迹长度是为了确保不同长度轨迹之间的可比性。
3.2.2 作为轨迹级标准的顺序一致性 (Order Consistency)
对于给定的问题 ,令 表示轨迹 的结果奖励,其中 表示最终答案正确。定义正向和负向轨迹集为:
如果将整个生成轨迹视为一个宏观动作(Macro-action),那么结果奖励自然充当了单步的轨迹级回报,即 。这诱导出了一个理想的排序:
基于蒸馏的前提,轨迹级蒸馏回报 应该保留与 相同的结果诱导排序。即对于任何提示 ,期望满足:
然而,正如前文所述,教师的打分可能会出现异常。这种不匹配通常集中在少数极端样本上:一个过度自信的错误轨迹或一个被严重低估的正确轨迹,就足以扭曲整个 Prompt 组的监督信号。
3.2.3 结果引导的边界校准 (Outcome-guided Margin Calibration)
为了强制执行上述顺序一致性约束,作者考察了得分最低的正确轨迹与得分最高的错误轨迹之间的边界(Margin),这直接反映了在最具对抗性的情况下排序是否被破坏。定义 Prompt 级别的边界为:
当 时,表示严格的顺序一致性。为了提高鲁棒性,进一步要求:
其中 定义了一个安全边界,用于抵抗估计噪声和有限样本波动。基于这个标准,作者提出了两种校准策略:
-
边界掩码 (Margin Mask) :这是一种保守的策略。它只保留满足 的 Prompt 组,并丢弃其余的组。在具体实现中,作者采用了一种贪婪的变体,即在组内迭代地移除最破坏排序的轨迹(得分最高的错误轨迹或得分最低的正确轨迹),直到边界恢复或达到最小保留比例。 -
边界偏移 (Margin Shift) :这是一种修复策略,通过最小的加性修正来恢复不可靠组的排序。对于 的组,定义所需的偏移量为 ,并对轨迹回报进行调整:
这种偏移保留了 内部和 内部的相对排序,同时保证了校准后的边界正好等于 。在实际应用中,偏移量 可以分配给正样本(提升)、负样本(抑制)或在两者之间平分(扩散)。
4. 实验设置
为了全面评估 Uni-OPD 的有效性,作者在文本和多模态领域进行了广泛的实验。
模型选择:
对于文本实验,使用 Qwen3-4B 和 Qwen3-1.7B 作为学生模型。在同等规模设置下,对 Qwen3-4B 应用特定领域的 RL 以获得专门的教师模型。在强到弱(Strong-to-weak)设置中,使用 Qwen3-30B-A3B-Instruct-2507 作为强教师。
对于多模态实验,使用 Qwen3-VL-2B-Instruct 和 Qwen3-VL-4B-Instruct 作为学生模型,并通过特定领域 RL 获得多模态教师。
训练数据:
文本任务使用从 DeepMath 过滤的 57K 数学推理样本(难度级别 )和来自 Eurus-2-RL-Data 的 25K 代码生成样本。多模态任务使用来自 OpenMMReasoner-RL-74K 的数学推理、逻辑推理和文档理解数据。
基线方法:
对比了 SFT、ExPO(权重空间外推)、ExOPD(奖励级别外推)以及原生的 OPD。
评估基准:
涵盖 5 个能力轴的 16 个基准测试:
-
文本数学推理:AIME24, AIME25, HMMT25。 -
文本代码生成:HumanEval+, MBPP+, LiveCodeBench。 -
多模态数学推理:MathVision, DynaMath, WeMath。 -
多模态逻辑推理:LogicVista, VisuLogic。 -
多模态文档理解:AI2D, ChartQA, DocVQA, InfoVQA。
5. 实验结果与分析
5.1 单教师与多教师蒸馏性能
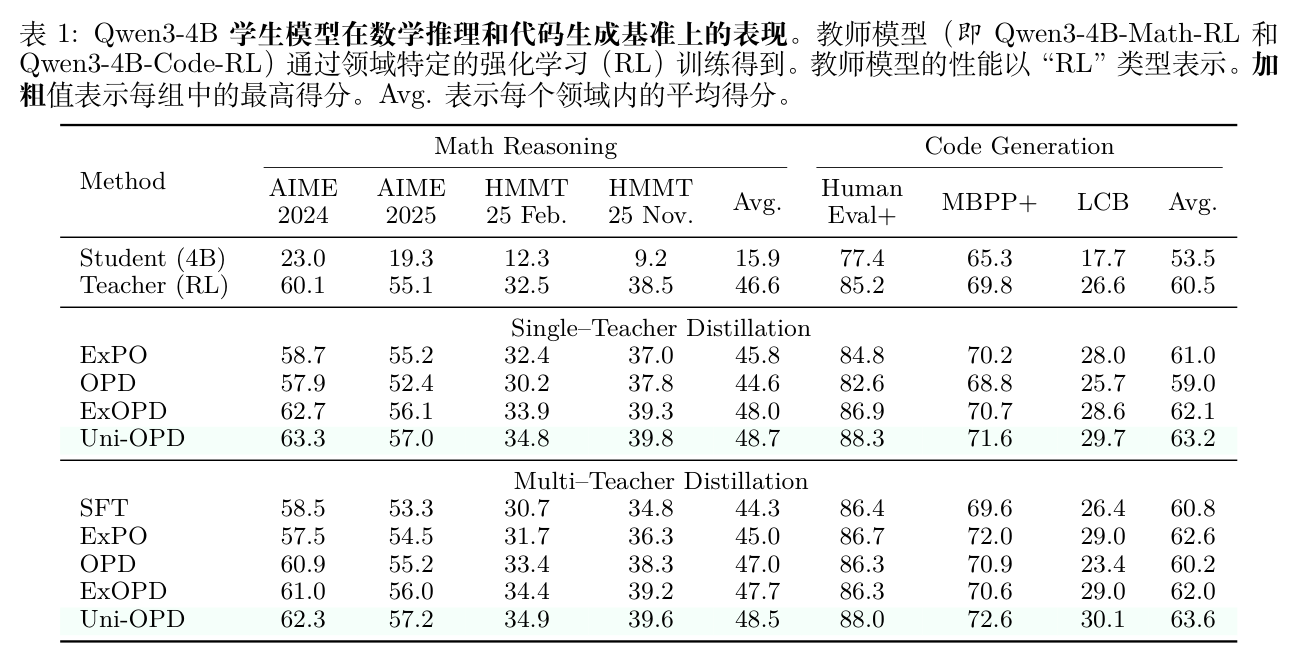
表 1 展示了在 LLM 上的结果。在单教师蒸馏中,Uni-OPD 一致优于原生 OPD 和 ExOPD,在数学推理上获得 48.7 的平均分,在代码生成上获得 63.2 的平均分。更重要的是,在多教师蒸馏设置下,Uni-OPD 有效地将多个教师的独特能力合并到单一学生模型中,相比原生 OPD 在数学和代码上分别获得了 1.5 和 3.4 的提升。
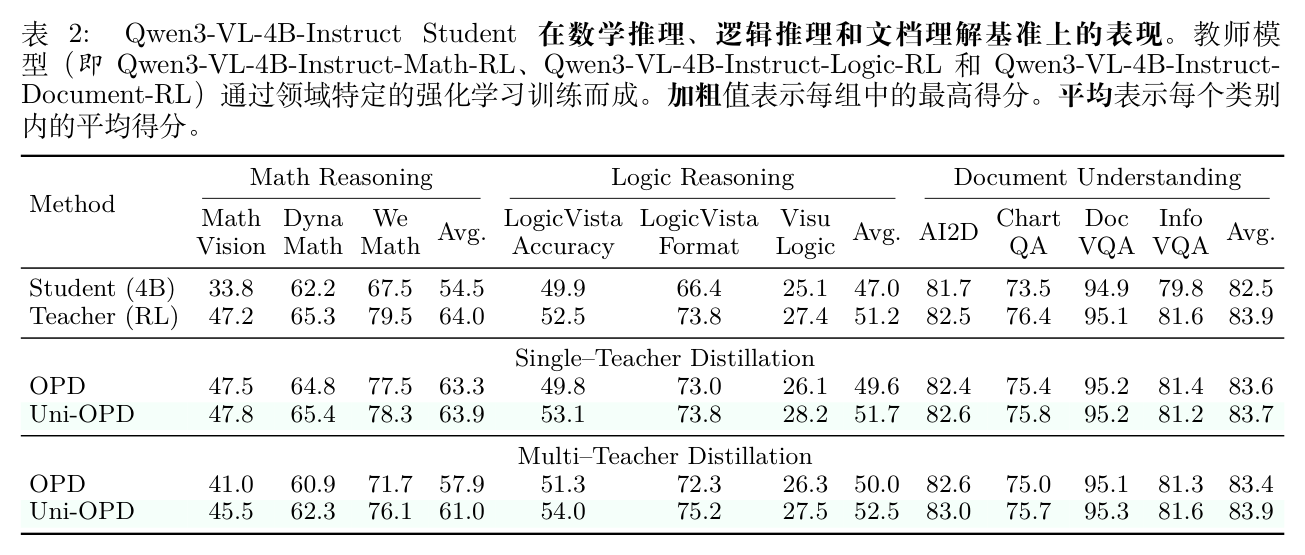
表 2 展示了在 MLLM 上的趋势。在单教师蒸馏下,Uni-OPD 在三个领域均达到最佳平均性能(数学 63.9,逻辑 51.7,文档 83.7)。在多教师蒸馏中,Uni-OPD 同样一致优于 OPD,证明了其在多模态场景下合并专门能力的有效性。
5.2 强到弱蒸馏 (Strong-to-Weak Distillation)
强到弱蒸馏对于小模型的实际后训练具有重要意义。作者测试了 Uni-OPD 是否能更好地促进推理能力从 30B 的强教师转移到 4B 和 1.7B 的小规模学生模型中。在这个设置中,学生同时在数学和代码数据上训练,并接受来自两个领域的教师反馈。
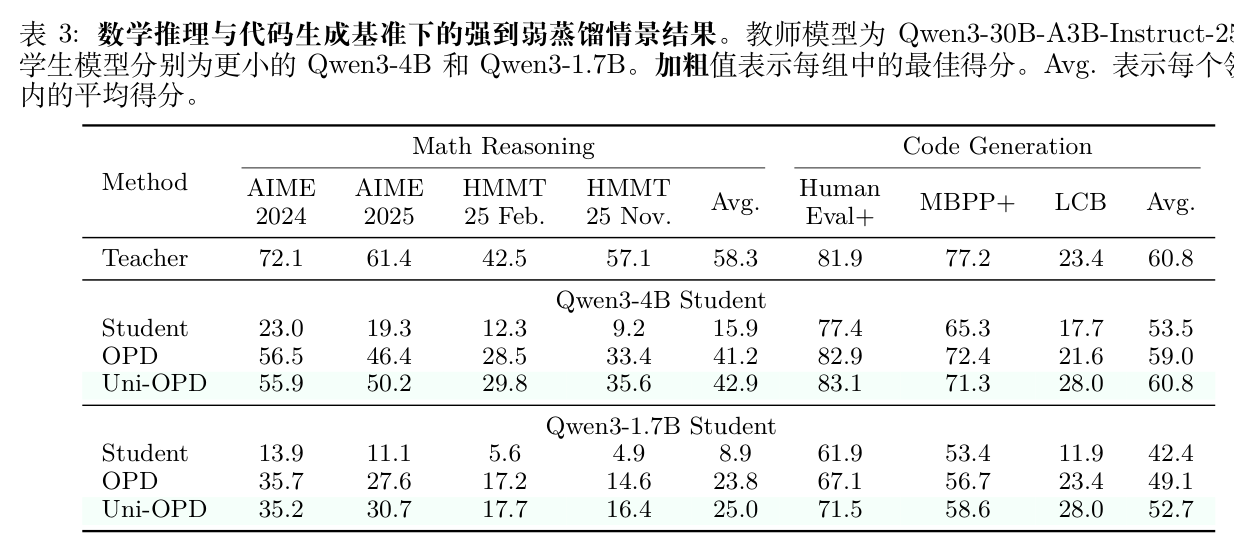
如表 3 所示,当从高能力的 30B 教师进行蒸馏时,Uni-OPD 在 4B 和 1.7B 学生设置中均产生了显著的性能提升。对于 4B 学生,Uni-OPD 在数学和代码上的平均得分分别为 42.9 和 60.8,超过标准 OPD 1.7 和 1.8 分。即使在容量受限的 1.7B 学生上,Uni-OPD 也将性能提升至数学 25.0 和代码 52.7。这表明 Uni-OPD 能够有效弥合容量差距,使小模型更好地吸收高级推理行为。
5.3 跨模态蒸馏 (Cross-Modal Distillation)
跨模态蒸馏是 OPD 中一个尚未充分探索的领域。作者研究了文本能力和多模态能力是否可以统一到单一的学生策略中。具体而言,使用 Qwen3-VL-4B-Instruct 作为学生模型,并分别在纯文本代码数据和多模态数学数据上构建特定领域的教师。
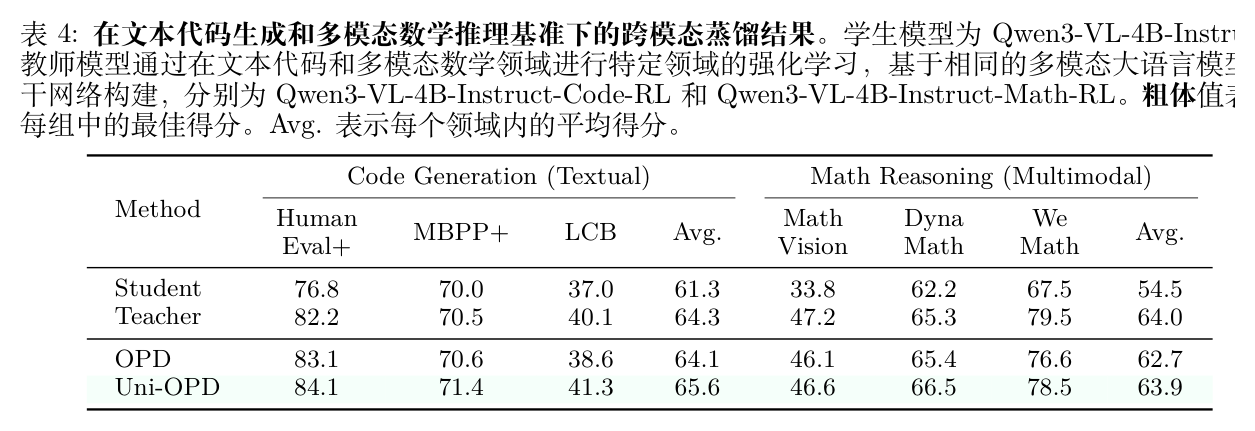
表 4 显示,Uni-OPD 在文本代码生成和多模态数学推理上均实现了相对于标准 OPD 的一致提升。代码生成的平均分从 64.1 提升至 65.6,数学推理从 62.7 提升至 63.9。这表明 Uni-OPD 能够有效吸收和协调来自文本和多模态领域的不同能力,而不会以牺牲一个领域为代价来提升另一个领域。
5.4 消融实验与定性分析
为了评估 Uni-OPD 中各个策略的独立贡献,作者在 Qwen3-4B 学生模型上进行了消融实验。
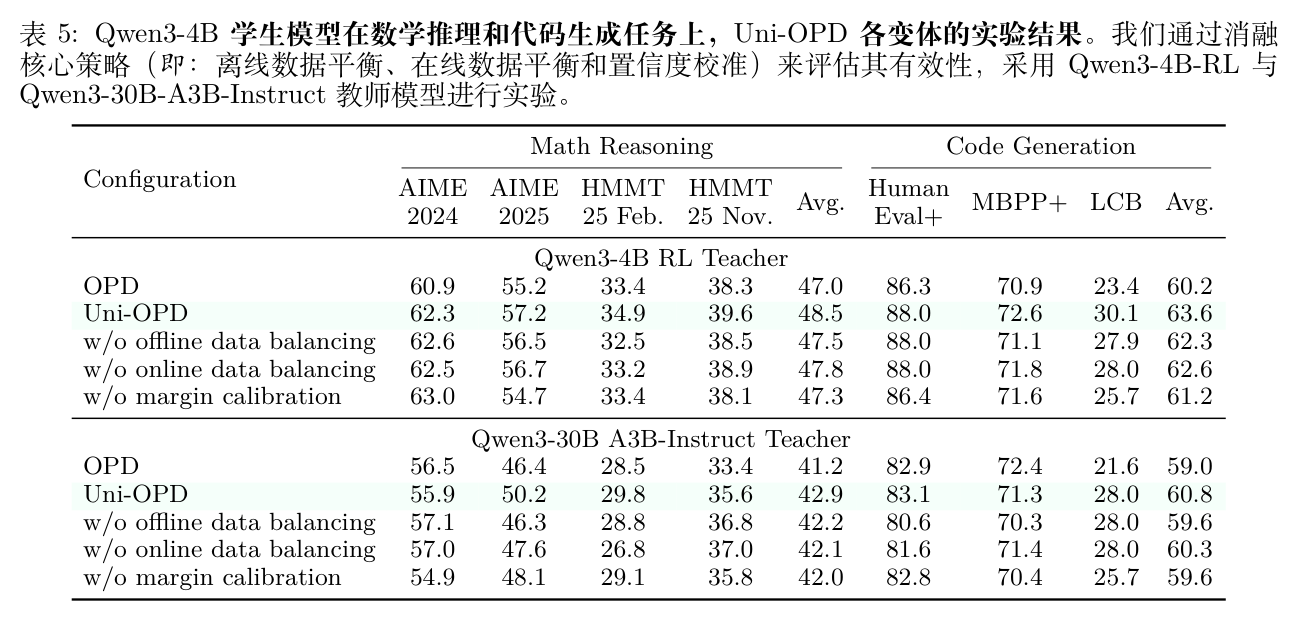
表 5 的结果表明,移除任何一个核心组件都会导致性能下降。
-
离线和在线数据平衡解决了探索不足的问题:如果没有它们,学生策略很难接触到多样化和具有挑战性的轨迹,导致性能下降。 -
边界校准提高了监督的可靠性:如果没有它,Token 级的反馈可能会与结果奖励错位,导致训练不稳定和次优的性能。

图 6 通过 Token 级奖励热力图直观地展示了结果引导的边界校准的有效性。在左侧,展示了标准 OPD 的失败模式:一个错误的轨迹(上)积累了高蒸馏回报(大量红色 Token,表示教师偏好),而一个正确的轨迹(下)获得了低蒸馏回报(颜色较淡)。右侧展示了应用 Margin Shift 后的相同轨迹:每个 Token 的奖励被均匀平移,使得轨迹级别的聚合排序与最终的结果奖励恢复了一致,从而提供了正确的优化方向。
6. 讨论与相关工作
多模态大语言模型与强化学习:随着 LLM 和 MLLM 推理能力的提升,如何通过后训练进一步对齐模型成为研究热点。强化学习(如 GRPO)通过在线采样缓解了分布不匹配,并使用基于结果的奖励来优化模型。然而,纯粹的 RL 往往面临信用分配困难的问题。
On-Policy 蒸馏的发展:早期的 OPD 工作(如 MiniLLM、GKD)确立了在反向 KL 目标下使用教师反馈的基本范式。近期的研究进一步扩展了这一范式,包括自蒸馏、黑盒 OPD、以及提高优化效率的方法(如 ExOPD)。OPD 也开始向多模态扩展(如 VOLD、Video-OPD)。与这些工作相比,Uni-OPD 的独特之处在于它提供了一个统一的框架和开放的配方,同时适用于 LLM 和 MLLM,并且深入剖析并解决了数据探索和监督可靠性这两个根本性瓶颈。
计算开销讨论:值得注意的是,Uni-OPD 引入的组件(在线数据平衡和边界校准)在计算上是非常轻量级的。相比于 OPD 中昂贵的模型 Rollout 和教师前向传播,Margin Shift 仅涉及标量比较和加法。实测表明,启用所有三个组件带来的额外挂钟时间(Wall-clock time)开销不到 1%,却换来了稳定的精度提升,展现出极佳的性价比。
7. 总结与未来展望
本文提出了 Uni-OPD,一个泛化于 LLM 和 MLLM 的统一 On-Policy 蒸馏框架。作者识别了有效 OPD 的两个关键瓶颈:学生对信息丰富状态的探索不足,以及教师对学生 Rollout 的监督不可靠。为了解决这些问题,提出了双视角优化策略:
-
通过离线难度感知和在线正确性感知的数据平衡,促进学生探索。 -
通过结果引导的边界校准,强制轨迹级蒸馏回报与客观结果奖励保持顺序一致,从而修复不可靠的教师监督。
在 16 个基准测试上的广泛实验证明了 Uni-OPD 在多教师、强到弱和跨模态设置下的有效性和多功能性。
未来展望:
作者的发现为未来的研究指出了几个有希望的方向:
-
将 Uni-OPD 扩展到更大规模的教师蒸馏设置中。 -
将 Uni-OPD 应用于更广泛的能力合并场景,如智能体规划(Agentic Planning)、工具使用和长视距决策。 -
进一步揭示 OPD 的机制原理,特别是它如何塑造训练动态和参数几何结构。
更多细节请阅读原文。

