让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Missing Old Logits in Asynchronous Agentic RL: Semantic Mismatch and Repair Methods for Off-Policy Correction
-
论文链接:https://arxiv.org/pdf/2605.12070
TL;DR
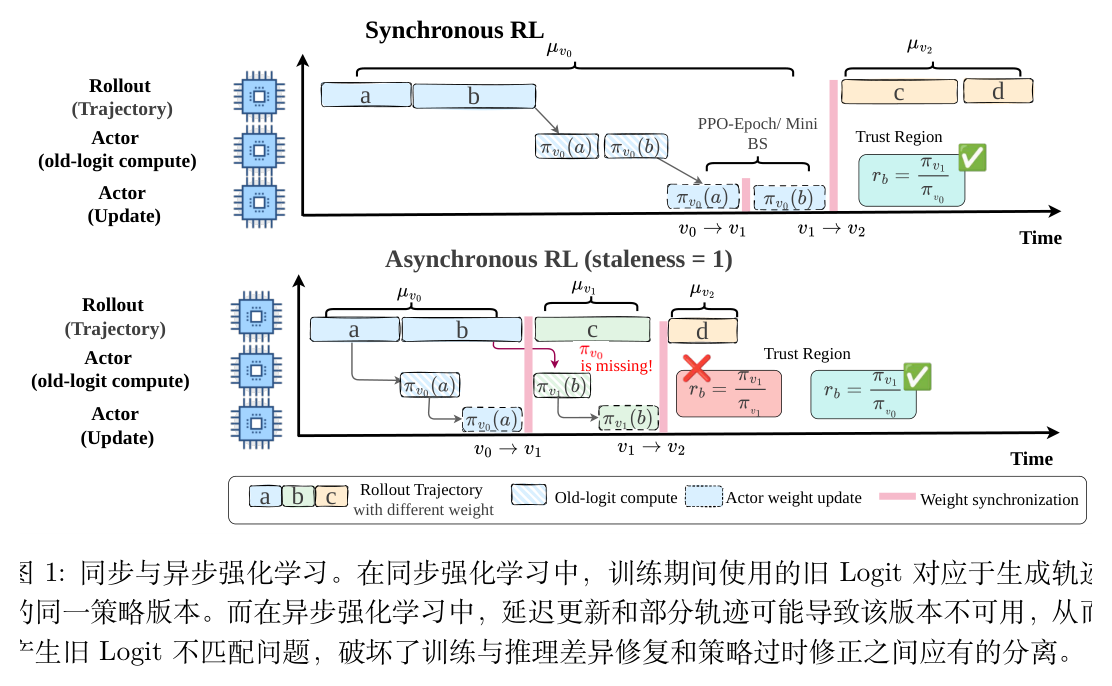
今天解读一篇来自天津大学、清华大学、北京大学与京东科技 AI Infra 团队的论文《Missing Old Logits in Asynchronous Agentic RL: Semantic Mismatch and Repair Methods for Off-Policy Correction》。在面向大语言模型(LLMs)的大规模强化学习中,为了提升吞吐量,研究人员通常采用异步架构,将样本生成的推理引擎与策略优化的训练引擎解耦。然而,这种架构引入了一个关键的失效模式:缺失旧对数概率(Missing Old Logits)。当轨迹数据到达训练端时,生成该轨迹的旧版本策略参数往往已被丢弃,导致用于修正离线策略(Off-Policy)的参考分布缺失。
本文提出了一个统一的分析框架,指出理想的离线校正应解耦为两个语义不同的约束:用于对齐训练端与推理端数值分布的训练-推理差异项(Training-Inference Discrepancy),以及用于限制策略更新幅度的策略滞后项(Policy-Staleness)。作者通过数学推导证明,现有基于策略插值的代理方法并未真正恢复缺失的参考分布,而仅仅是重新参数化了裁剪边界。
为了解决这一问题,作者从系统和算法两个维度给出了方案。在系统层面,探讨了快照版本追踪、独立旧对数概率模型以及局部中断同步三种精确获取策略,并量化了它们的系统开销。在算法层面,提出了一种低成本的近似替代方案:修正版 PPO-EWMA。该方法引入了感知滞后窗口的衰减因子与自动重置机制,在不增加额外系统开销的前提下,有效保留了解耦校正的优势,并在密集模型与 MoE 模型的 Agentic 基准测试中取得了与精确恢复相近的优化性能。
1. 引言
大语言模型(LLMs)的大规模强化学习日益依赖于分布式的采样(Rollout)与训练流水线。近端策略优化(Proximal Policy Optimization, PPO)及其变体(包括 GRPO)被广泛使用,因为它们提供了一种稳定且易于实现的策略改进机制。在标准的同步或近同步设置中,重要性采样比率具有明确的物理意义:它将当前策略与生成采样 token 的行为策略进行对比,并通过裁剪(Clipping)机制在更新幅度与优化稳定性之间取得平衡。
然而,在现代智能体强化学习(Agentic RL)系统中,为了最大化吞吐量,采样和训练通常在物理上是分离的。采样由高度优化的推理引擎(如 vLLM 或 SGLang)执行,而梯度更新则由训练引擎(如 Megatron-LM 或 FSDP)完成。这种异构的异步架构引入了两个维度的偏差:
-
训练-推理差异(Training-Inference Discrepancy):即使推理端和训练端名义上使用的是同一个模型版本,底层数值算子、精度缩放、量化、张量并行以及路由实现的差异,也会导致两者计算出的 token 概率不同。 -
策略滞后(Policy Staleness):异步采样、庞大的采样队列、部分轨迹收集以及多次 Actor 更新,使得生成数据的行为策略相对于当前正在优化的策略变得陈旧。
在理想情况下,总的重要性比率可以分解为两个具有不同语义的项:
公式中, 为提示词, 为响应。 表示当前训练端的策略, 表示推理端的行为策略, 表示与行为策略同版本的训练端策略。 衡量训练-推理差异,而 衡量策略滞后。这种分解在逻辑上是自洽的:差异修复()应该过滤或降低数值不一致 token 的权重,而滞后校正()应该使用依赖于优势函数符号的 PPO 裁剪规则来约束策略更新。
但是,异步 Agentic RL 引入了一个系统级的实践障碍:当轨迹数据到达 Actor 时,旧的训练端策略值 可能已经不可用。在部分采样收集(Partial Rollout Collection)机制下,一条轨迹可能跨越多个参数版本,Actor 可能已经迭代到了比生成早期 token 的版本更新的状态。一旦这些旧对数概率缺失,上述等式中的分解便失去了语义上的有效性。现有的解耦目标往往将差异修复与滞后校正混合成一个代理比率,导致裁剪和掩码机制相互干扰。
2. 离线策略校正的统一分析
为了理解缺失旧对数概率带来的影响,作者首先将现有的 PPO 风格目标统一到一个包含双重约束的掩码重要性采样(Masked Importance Sampling, MIS)框架中,并从数学上剖析了为何现有的代理策略无法真正替代缺失的参考分布。
2.1 PPO 风格的离线策略校正基础
给定 token 级别的比率 ,PPO 的裁剪代理目标可以表示为:
公式中, 是优势估计值, 是裁剪超参数。等价地,PPO 裁剪引入了一个依赖于优势符号的活跃区域。在 token 级别,上述目标的梯度贡献可以改写为掩码重要性采样(MIS)的形式 ,其中 PPO 侧的活跃掩码定义为:
这里 表示指示函数。这种依赖于优势符号的掩码主要用于执行策略更新约束,防止策略更新步长过大。
2.2 差异修复为何不能替代滞后校正
在现代系统中,如果试图分离控制训练-推理差异,一种做法是对差异比率应用严格的掩码阈值 。这可以公式化为:
公式中,掩码函数定义为 。
作者指出,上述双侧校正不能简单地用标准的 PPO 裁剪来表达。原因有两点:
-
PPO 主要通过基于优势符号的非对称过滤器来防止过大的更新步长,而训练-推理差异修复需要一个以 1 为中心的严格对称约束。 -
将这些分解项混合成单一比率并强制使用共享阈值,会从根本上损害优化过程。差异修复针对的是数值一致性,需要严格的约束来稳定过滤错误;而滞后校正控制的是更新幅度,较宽松的约束可以加速早期训练。如果用单一阈值,严格的阈值会严重阻碍学习,而宽松的阈值则会将策略暴露在噪声中,增加崩溃风险。
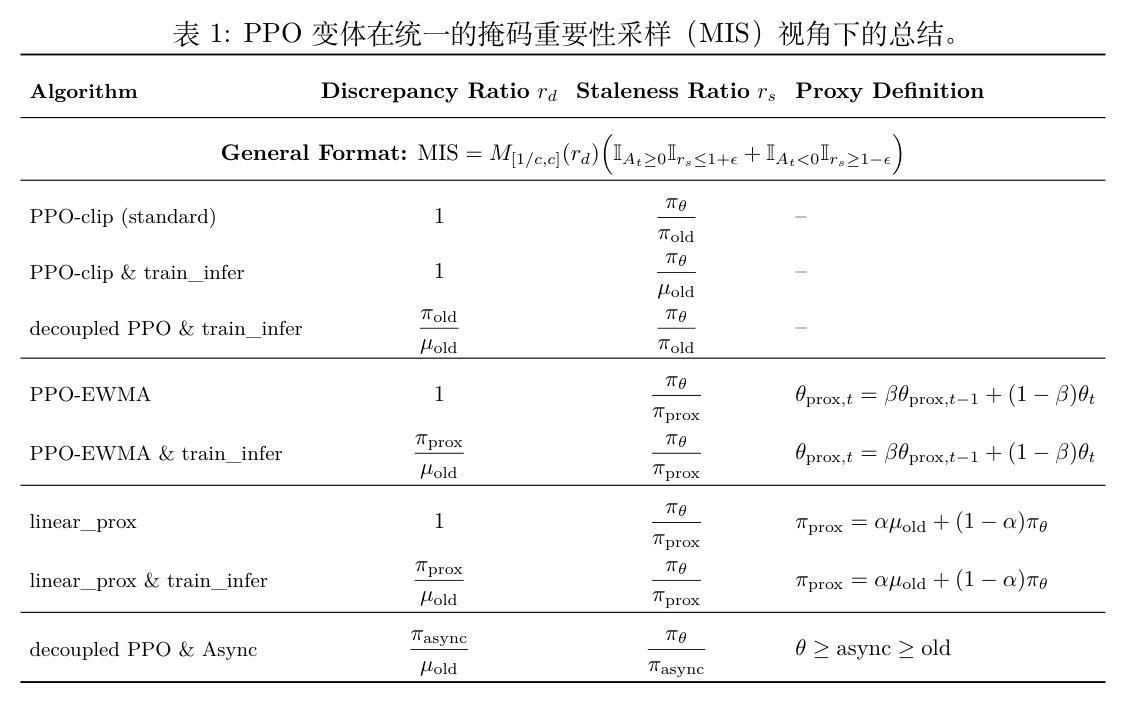
2.3 基于插值的代理策略的数学本质
由于 缺失,现有框架(如 A-3PO)常通过在当前策略 和行为策略 之间进行插值来构建一个概率空间的代理策略 。然而,作者通过推导证明,这种方法并未真正解决差异问题,而仅仅是重参数化了总比率 的裁剪边界。
假设解耦目标对差异项应用掩码 ,对 PPO 侧应用裁剪 。
情况一:对数线性插值(Log-linear interpolation)
考虑 token 级别的对数线性插值:
此时,差异比率为:
掩码条件限制 在区间 。
PPO 侧比率为 。结合优势符号 :
-
当 时,裁剪要求 ,即 。结合掩码, 的活跃区域上限由两者中较紧的一项决定。 -
当 时,裁剪要求 ,即 。结合掩码, 的活跃区域下限由两者中较紧的一项决定。
通过一阶泰勒展开可知,有效阈值 ,。这表明对数线性插值仅仅是改变了原始比率 的活跃区域参数。
情况二:算术插值(Arithmetic interpolation)
考虑线性代理:
差异比率为 。掩码条件转化为:
PPO 侧比率为 。
-
当 时,求解 得到 。 -
当 时,求解 得到 。
利用 展开,同样可以发现有效半径 。
结论:插值操作只是转移了有效边界,并没有恢复精确的参考分布。因此,它无法真正解耦训练-推理差异与策略滞后。
3. 恢复与近似旧对数概率的方法
既然插值代理无法从语义上解决问题,作者探索了两个截然不同的方向:一是通过系统基础设施支持直接获取精确的旧对数概率;二是承认系统开销的限制,构建一个更可靠的低成本近似参考策略。
3.1 精确旧对数概率获取策略
作者设计并对比了三种在异步系统中获取训练端旧对数概率 $\pi_{old}(y_t|x, y_{
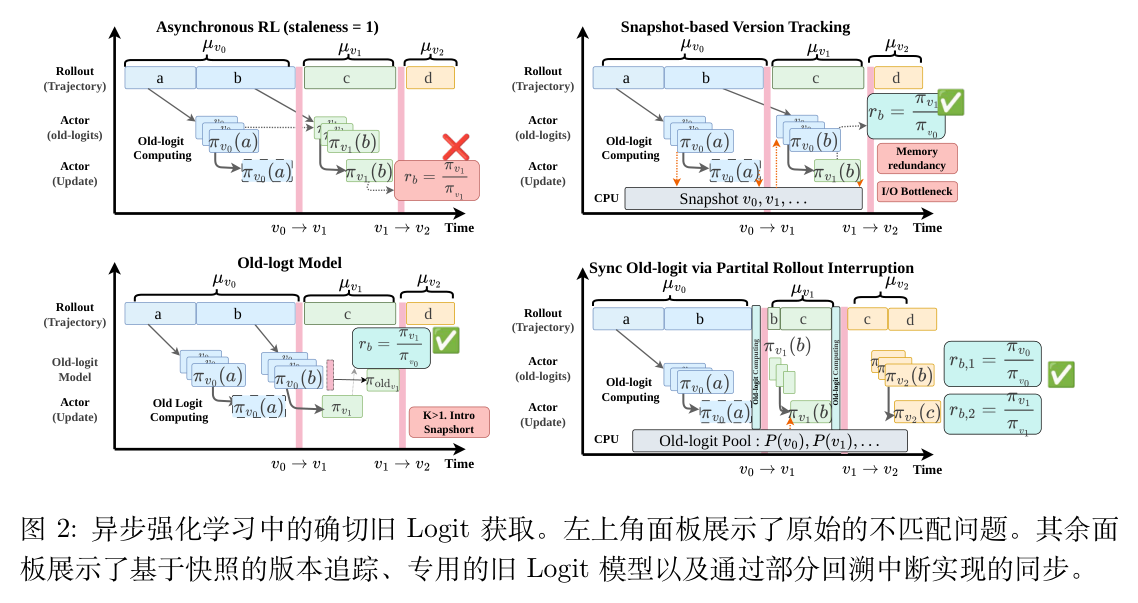
1. 基于快照的版本追踪(Snapshot-based version tracking)
最直接的解决方案是保留历史参数快照,并在需要时重新加载生成特定 token 或轨迹的版本。这种方法提供了最纯粹的 估计,完全恢复了理想的语义分解。
其缺点在于系统开销。保留快照需要额外的 CPU 或主机内存。在部分采样收集模式下,单个样本可能跨越多个版本,这需要频繁的 Actor 端版本切换,大幅增加 I/O 开销。
2. 独立的旧对数概率模型(Dedicated old-logit model)
第二种选择是维护一个单独的模型实例,专门用于计算旧对数概率,而主 Actor 继续进行训练。这可以减少 Actor 路径上的资源竞争,并允许旧对数概率计算与梯度更新重叠执行。它将旧对数概率计算与更新训练解耦,从而通过重叠减少 Actor 阶段的端到端时间。代价是需要划分集群资源来部署这个额外的模型。
3. 通过局部采样中断进行同步(Synchronization via partial rollout interruption)
第三种方案在策略版本消失之前计算旧对数概率。在将参数从版本 更新到 之前,系统中断采样 Worker 并返回部分轨迹。由于在此期间采样停止,系统可以使用 Ray 调度器释放采样端的资源放置(Placement),并将相同的资源临时切换到 Actor 端进行旧对数概率计算。计算完成后,系统将资源切换回采样执行并恢复生成。
这种设计避免了存储旧权重,且能提供精确的对数概率,但它引入了同步停顿、资源重配置开销,并破坏了采样的并行性。
3.2 低成本参考策略:修正版 PPO-EWMA
考虑到精确获取旧对数概率对于大规模异步 Agentic RL 而言可能过于昂贵,作者采用了一种基于指数加权移动平均(PPO-EWMA)的参考策略作为低成本近似。目标不是声称精确恢复了 ,而是构建一个比当前策略或静态插值代理更平滑的参考,使其更好地跟踪异步版本窗口的中心。
在更新步 之后,给定 Actor 参数 ,代理参数 维护为:
对应的比率定义为 和 。作者对标准 EWMA 进行了两项关键调整:
改进一:感知滞后的衰减因子选择
作者没有使用固定的较大衰减因子,而是根据预期的滞后窗口 来设置 。在平稳极限下,EWMA 历史的质心(Center of Mass)为:
为了将该质心与宽度为 的异步版本窗口的中点对齐,令 ,得到:
这使得 EWMA 参考策略保持在异步版本窗口的中间附近,防止其落后于采样队列。
改进二:自动重置机制(Automatic Reset)
为了避免在 EWMA 参考中积累过度陈旧的版本,作者添加了自动重置功能。随着 对更多历史 Actor 状态进行平均,它可能会偏离最近采样所使用的策略版本。这会导致差异比率 偏离 1,触发训练-推理掩码拒绝大量 token。
因此,系统监控训练-推理掩码值 (定义为在差异掩码和 PPO 裁剪后保持活跃的 token 比例)。当 时(实验中 设为 0.9),触发重置:
这清除了陈旧的历史,并将代理参考重新集中在当前 Actor 周围。
4. 实验设置
为了评估上述方法,作者在 Agentic RL 任务上进行了实验。
-
模型基座:包含密集模型 Qwen3-4B 和混合专家(MoE)模型 Qwen3-30B-A3B。 -
基准测试:涵盖 -Bench 的 Retail、Airline、Telecom 领域,以及 VitaBench 的 In-store 和 Delivery 划分。报告任务级别的平均成功率(avg)和通过率(pass)。 -
异步设置:采用显式控制采样 Worker 和 Actor 之间最大版本差距的异步 RL 设置,最大滞后版本上限设为 3。 -
对比基线: -
Decoupled PPO:采用解耦目标,但依赖可用的异步参考而不是真实的 。 -
Linear_prox:轻量级线性插值代理策略。 -
PPO-EWMA:本文提出的带有感知滞后衰减和可选重置的增强型 EWMA。 -
Snapshot:理想化设置,通过版本追踪获取精确的旧对数概率。
-
5. 实验结果与分析
5.1 主实验结果
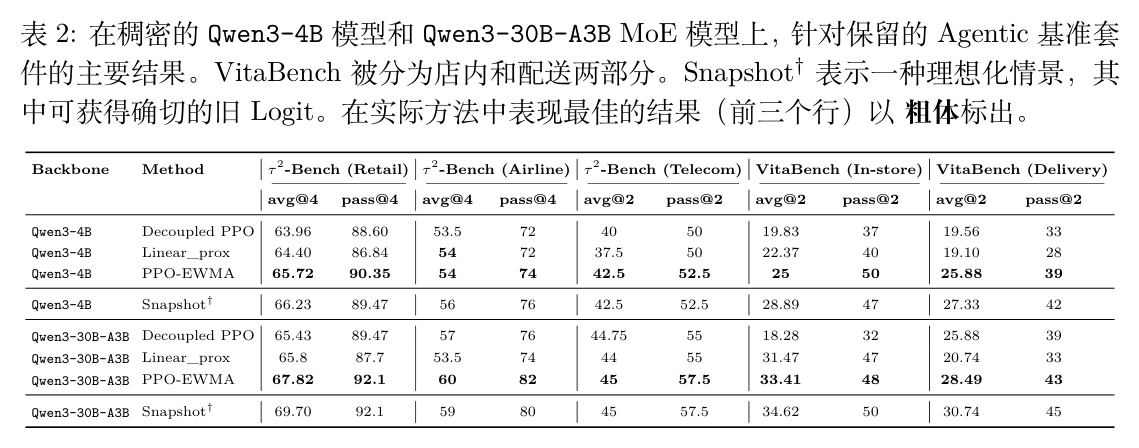
表 2 展示了在保留的 Agentic 基准测试上的对比结果。Snapshot 作为理想化参考,代表了精确旧对数概率可用时的性能上限。
在实用方法中,PPO-EWMA 表现最为突出。在 Qwen3-4B 密集模型上,PPO-EWMA 在 Retail 上的 pass@4 达到 90.35,在 VitaBench In-store 上的 pass@2 达到 50,均取得最佳成绩,并在 Telecom 领域并列第一。在 Qwen3-30B-A3B MoE 模型上,PPO-EWMA 在 Airline 划分上表现最强(avg@4 达到 60),并在 Retail 和 Telecom 上并列最佳。
这些结果表明,一个维护良好的 EWMA 参考策略能够恢复精确校正的大部分收益,而无需付出精确获取旧对数概率的高昂代价。Decoupled PPO 和 Linear_prox 的表现相对较弱,印证了前文理论分析中关于语义错配和插值局限性的推论。
5.2 精确获取的系统开销分析
虽然 Snapshot 性能优异,但其系统开销不容忽视。作者详细测量了精确获取方案的代价。
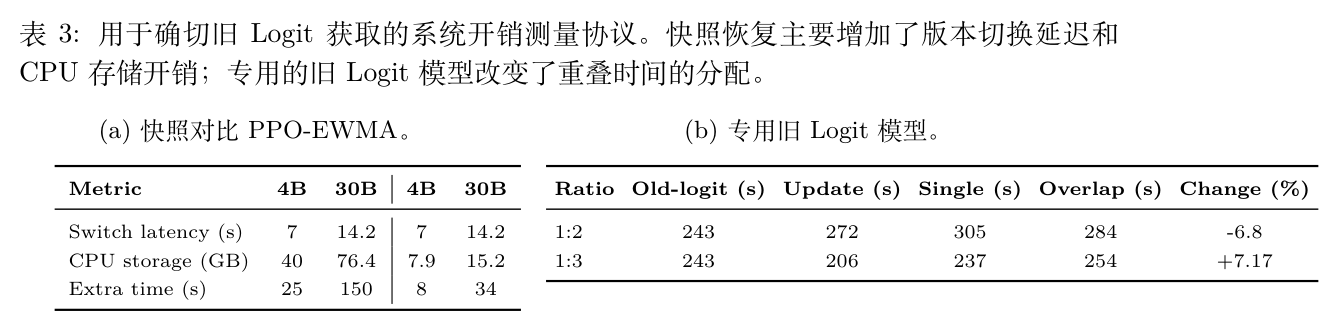
表 3(a) 对比了 Snapshot 与 PPO-EWMA 的开销。Snapshot 需要版本切换、快照存储以及额外的恢复时间。在 30B MoE 模型上,Snapshot 导致单步额外耗时增加 150 秒,CPU 存储增加 76.4 GB。相比之下,PPO-EWMA 仅维护一个轻量级代理参考,在 30B 模型上 CPU 存储仅需 15.2 GB,额外耗时仅 34 秒。
表 3(b) 分析了独立旧对数概率模型的开销。虽然该模型可以与主更新过程重叠计算,但其收益高度依赖于资源划分比例。在 1:2 的资源比例下,重叠时间为 284 秒,整体时间减少 6.8%;但在 1:3 比例下,反而导致整体时间增加 7.17%。
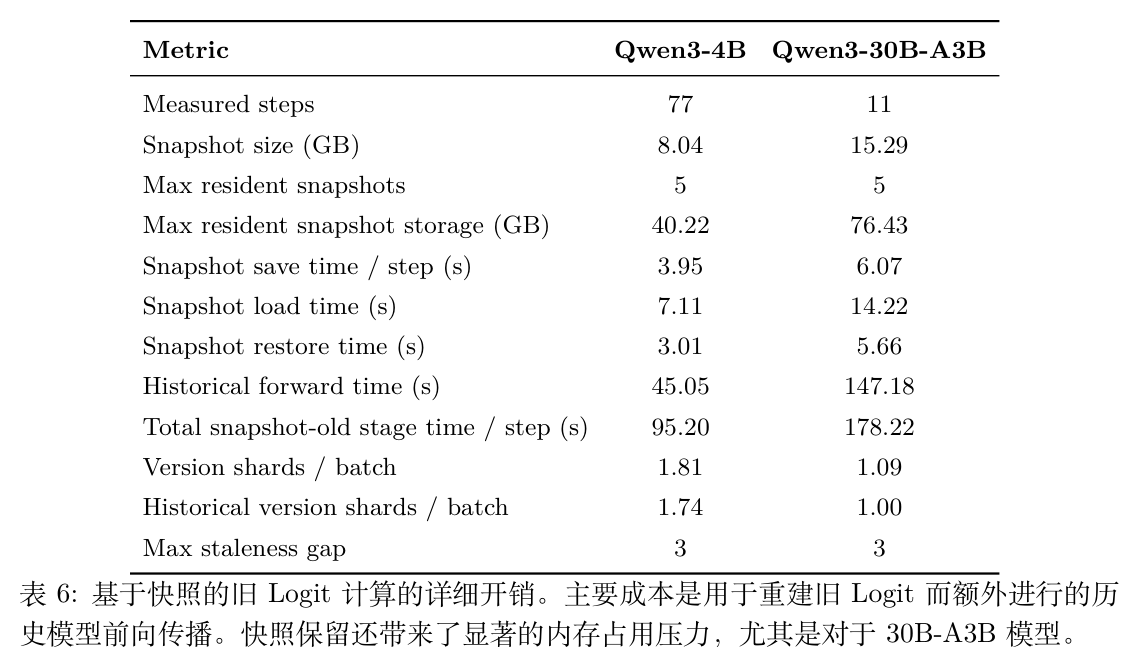
附录中的表 6 进一步拆解了 Snapshot 的开销来源。在 Qwen3-30B-A3B 上,除了 76.43 GB 的最大常驻快照存储外,历史前向计算时间(Historical forward time)高达 147.18 秒/步,成为主导成本。这表明精确恢复在显存压力和 Actor 端计算负载上都施加了实质性的负担。
5.3 精确旧对数概率下的阈值权衡
在使用 Snapshot 获取精确旧对数概率的前提下,作者研究了差异阈值和滞后策略阈值如何影响优化过程。
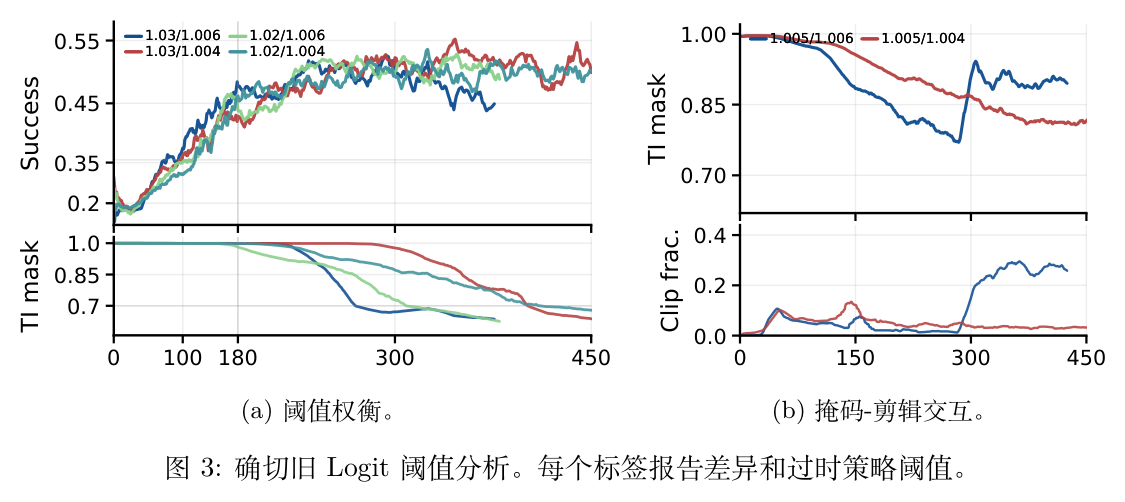
图 3(a) 展示了阈值的权衡关系。较宽松的差异阈值(如 1.03)在早期保留了更多的活跃 token,从而提升了早期学习速度;但它也容纳了更多有偏差的离线 token,可能导致训练后期的轨迹不稳定。相反,更严格的差异阈值(如 1.02)在初期学习较慢,但保留 token 的动态更加平滑,减少了后期的崩溃风险。
图 3(b) 揭示了差异掩码与 PPO 裁剪之间的耦合关系。在相同的差异阈值下,较宽松的滞后策略阈值允许更多有问题的 token 在早期存活,导致训练-推理掩码(TI mask)下降得更低;在后期,更强的 PPO 裁剪限制了剩余的更新幅度,帮助掩码数值恢复。这说明即使恢复了语义正确的分解,阈值调整仍需考虑两种约束的联合行为。
5.4 PPO-EWMA 深入分析与消融
作者通过任务成功率、训练-推理掩码和 PPO-CLIP 比例三个信号,深入分析了修正版 PPO-EWMA 的行为。
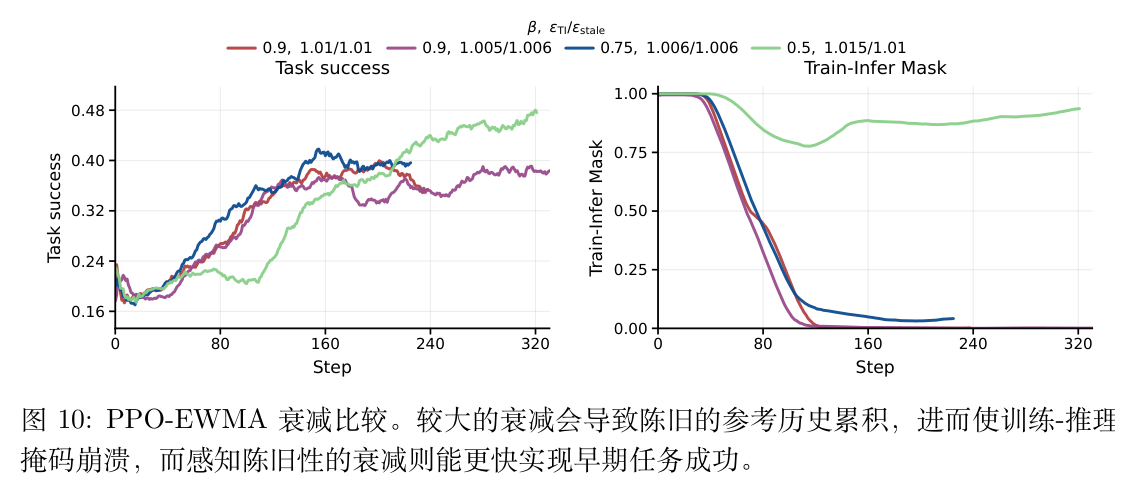
衰减因子的影响:图 10 对比了不同 值的表现。当 时,EWMA 参考具有较长的记忆,受到早期 Actor 版本的强烈影响。随着训练进行, 与近期采样策略的错位加剧,导致差异比率偏离 1,训练-推理掩码最终跌至接近零的水平(掩码崩溃)。而基于理论推导的 设置将 EWMA 质心与异步窗口中点对齐,在早期获得了最快的成功率提升。
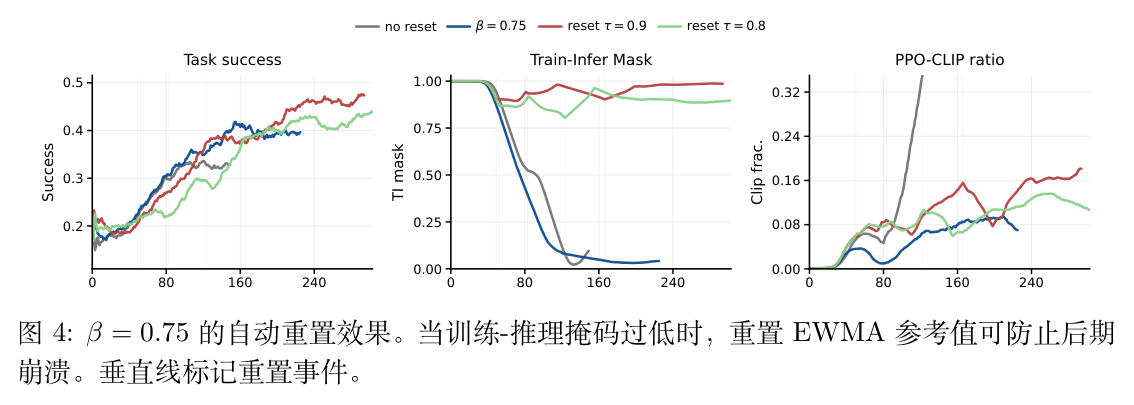
自动重置的作用:尽管 早期表现好,但如果不加干预,它在后期依然会面临掩码崩溃的风险。图 4 展示了自动重置机制的效果。当掩码值低于 (如 0.9 或 0.8)时触发重置。实验表明,整个训练过程中仅需触发两到三次重置,就足以清除 中积累的陈旧历史,恢复高水平的训练-推理掩码,同时保留了 带来的大部分早期成功率增益。这证明了自动重置作为一种低频干预手段的有效性。
6. 讨论与局限性
本文的研究揭示了异步 Agentic RL 中一个被忽视的系统与算法交叉问题。通过明确区分训练-推理差异与策略滞后,并指出代理插值方法的局限性,作者为离线策略校正提供了一个更清晰的理论框架。
从工程实践来看,本文展示了一个典型的性能-成本权衡:
-
如果基础设施允许且对校正保真度要求极高,基于快照的精确恢复是最佳选择,但需承受高昂的 I/O 和显存开销。 -
对于大多数追求高吞吐量的大规模训练任务,引入感知滞后衰减和自动重置的 PPO-EWMA 提供了一个极具性价比的替代方案。
局限性:作者在论文中也坦诚了当前研究的局限性。首先是模型规模,实验在 4B 和 30B 级别的模型上进行,尚未在千亿参数规模上验证。在超大规模下,显存压力、通信开销和路由行为可能会发生质变。其次,系统开销分析主要集中在快照、版本切换和局部中断等核心环节,尚未对调度器行为、网络通信、内存交换等进行细粒度的端到端系统级剖析。最后,PPO-EWMA 仍然是一种近似,在高度非平稳的滞后或极端的版本差距下,可能变得不可靠。
7. 总结
本文系统性地识别并分析了异步大语言模型强化学习中的"缺失旧对数概率"问题。该问题破坏了解耦离线策略校正的预期语义,导致掩码和裁剪机制失效。作者证明了常规的插值代理方法仅仅是重参数化了裁剪边界,并未真正恢复缺失的分布。为此,本文不仅在系统基建层面探讨了三种精确获取旧对数概率的实现路径及其开销,还在算法层面提出了一种修正版的 PPO-EWMA 参考策略。通过在真实 Agentic 基准测试上的详尽实验,证明了修正版 PPO-EWMA 能够在不显著增加系统负担的前提下,有效稳定异步训练轨迹,为大规模 LLM RL 系统设计提供了有价值的实践指导。
更多细节请阅读原论文。

