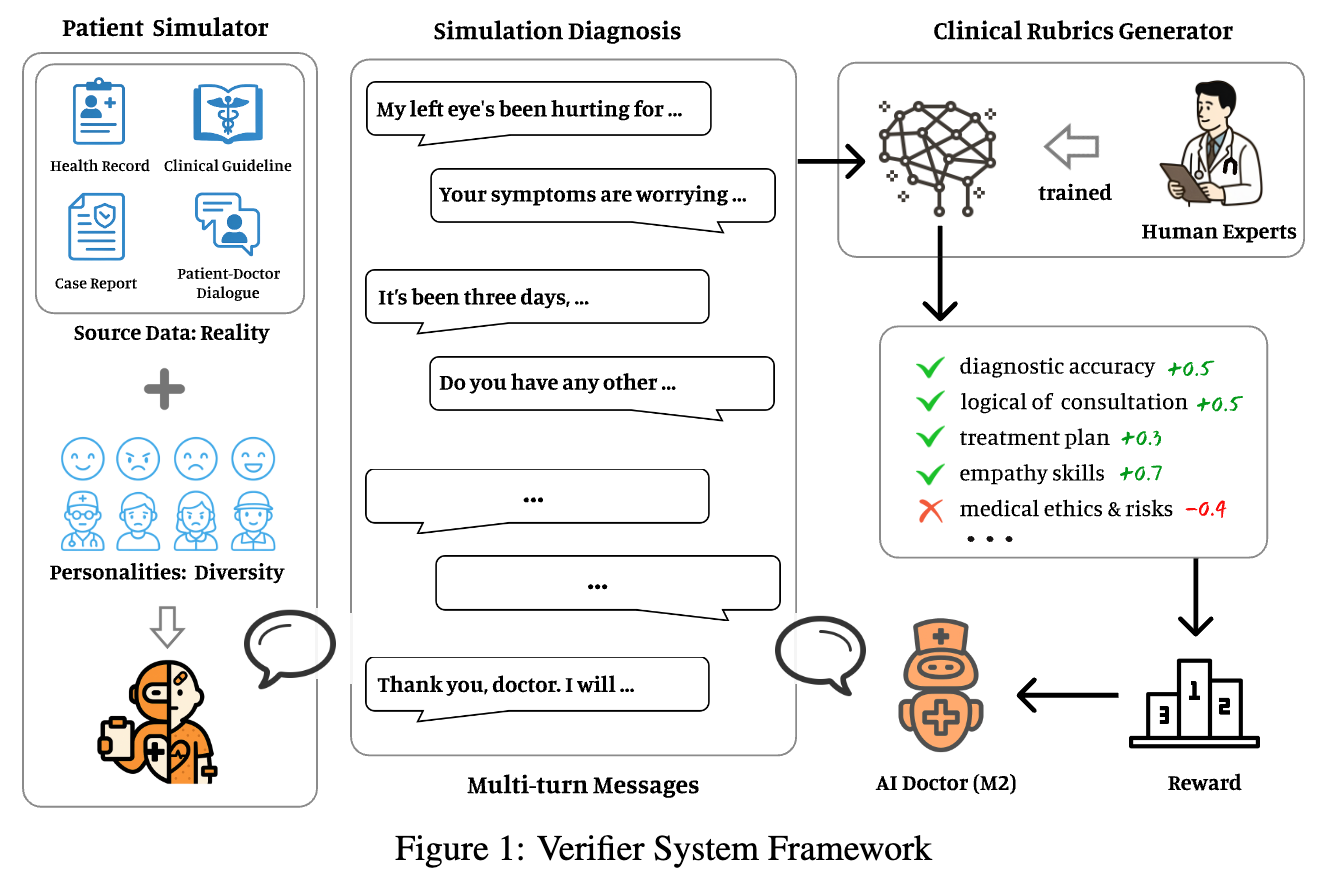
大型语言模型(Large Language Models, LLMs)的能力日益增强,但一个挑战始终顽固地存在,即“幻觉” (hallucination) 问题。所谓幻觉,是指模型自信地生成了与事实不符的陈述。这一问题,即便是最先进的系统也无法幸免,它严重侵蚀了我们对AI系统的信任。2025年9月4日,来自OpenAI和佐治亚理工学院的研究人员 Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, 和 Edwin Zhang 联合发表了一篇开创性论文——《Why Language Models Hallucinate》(为什么语言模型会产生幻觉),系统性地剖析了幻觉产生的根源,并指明了可能的解决方向。

-
论文标题:Why Language Models Hallucinate -
论文链接:https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
这篇论文的核心论点是:语言模型之所以产生幻觉,是因为其训练和评估程序奖励“猜测”,而非承认“不确定性”。论文通过严谨的统计学分析和理论推导,揭示了幻觉并非什么神秘现象,它本质上源于二元分类的错误,并在当前的训练和评估范式下被持续强化。
1. 背景
在深入探讨原因之前,我们首先需要明确论文语境下的“幻觉”是什么。
1.1 什么是幻觉?
论文将幻觉定义为由语言模型生成的、看似合理但实际上是错误的陈述 (plausible but false statements) 。这种错误模式与人类的感知经验有着根本的不同,但它持续地困扰着整个领域。
为了直观地展示幻觉现象,论文给出了一个生动的例子。当研究人员向一个先进的开源语言模型询问论文作者之一 Adam Tauman Kalai 的生日时,并要求“如果你知道,请只用DD-MM的格式回答”,模型在三次独立的尝试中给出了三个完全不同的错误日期:“03-07”、“15-06”和“01-01”。尽管提示明确要求只有在“知道”的情况下才回答,模型还是选择了“猜测”。

更有甚者,当被问及 Adam Kalai 的博士论文题目时,三个主流语言模型(ChatGPT, DeepSeek, Llama)都给出了错误的标题和毕业年份。这表明,即使是对于一些可以查证的事实,最先进的模型也可能自信地“犯错”。
1.2 幻觉的分类
论文中也提及了学者们对幻觉的进一步分类,主要是为了分析的严谨性。通常,幻觉被分为内在幻觉 (intrinsic hallucinations) 和 外在幻觉 (extrinsic hallucinations) 。
-
内在幻觉:指模型生成的内容与用户在提示中提供的信息相矛盾。例如,当被问及“DEEPSEEK”中有多少个“D”时,模型可能会回答“2”或“3”,甚至是“6”或“7”,这显然与提示词本身的信息相悖。 -
外在幻觉:指模型生成的内容与训练数据或外部客观事实相矛盾。上文提到的关于生日和论文题目的例子就属于外在幻觉。
论文的分析框架虽然具有普适性,能够涵盖这两种情况,但其核心洞见在于,幻觉的产生机制并不依赖于具体的错误类型,而是根植于模型训练和评估的底层逻辑。
2. 预训练阶段的误差根源
许多人可能会将幻觉归咎于训练数据中的噪声,即所谓的“垃圾进,垃圾出” (Garbage In, Garbage Out, GIGO)。但论文提出了一个更为深刻的观点:即使在完全不包含错误的、理想化的训练数据上进行预训练,现有的统计学习目标也会不可避免地导致模型产生错误,从而引发幻觉。
2.1 从生成任务到二元分类
论文的第一个核心贡献,是将看似复杂的生成任务 (generative task) 巧妙地归约 (reduction) 为了一个更易于分析的二元分类任务 (binary classification task) 。这种“归约”是计算理论中一种强大的分析工具,它表明如果一个问题B可以被归约为问题A,那么解决问题A至少和解决问题B一样困难。
具体来说,论文构建了一个名为 “Is-It-Valid (IIV)” 的二元分类问题。想象一个分类器,它的任务是判断任意给定的一个句子是“有效的” (valid, 标记为+) 还是“错误的” (error, 标记为-)。

上图左侧展示了一些“有效”和“错误”的例子。IIV分类器的训练数据由两部分构成:一部分是来自预训练语料库的真实、有效的句子(全部标记为+),另一部分是随机生成的错误句子(全部标记为-)。
论文指出,生成有效输出的任务,比简单地判断一个输出是否有效要困难得多。因为生成一个有效的长句子,实际上隐含着对每一个可能的候选句子都进行了“它是否有效”的判断。
2.2 生成误差与分类误差的数学关系
基于IIV这个设定,论文建立了一个关键的数学关系:
这里的生成误差率 (generative error rate) 就是我们所关心的幻觉率,即模型生成错误陈述的概率。而 IIV 分类错误率 (IIV misclassification rate) 是指一个理想的分类器在判断句子有效性时犯错的概率。
这个不等式揭示了一个深刻的联系:导致二元分类产生错误的统计学因素,同样也是导致生成模型产生幻觉的根本原因。几十年来,机器学习领域对分类错误的来源已经有了深入的研究,例如:
-
数据中没有可学习的模式:如图1右下角的“生日”例子,生日和姓名之间没有统计规律可循。对于训练数据中未见过的姓名,任何分类器都只能猜测其生日,错误率会很高。 -
模型能力不足:如图1右中侧的“计数”例子,如果模型(分类器)过于简单,比如一个线性分类器,它就无法学习一个复杂的概念(比如一个圆形区域),从而导致错误。 -
可分离但复杂的模式:如图1右上角的“拼写”例子,拼写是有规律可循的,一个好的模型可以学习到这些规律并做出准确的判断。
因此,当语言模型在预训练中试图学习整个语言分布时,它必然会遇到像“生日”这样缺乏模式、难以学习的事实。由于无法完美地对这些事实进行分类(判断其有效性),根据上述不等式,模型在生成相关内容时也必然会产生错误,即幻觉。
2.3 校准 (Calibration) 与幻觉的必然性
有人可能会反驳:模型可以直接输出“我不知道”(IDK) 来避免犯错。但论文指出,这种“不犯错”的模型,如一个永远只回答IDK的模型,或者一个只会复述训练数据的模型,虽然避免了幻觉,但它们无法完成预训练的核心目标——密度估计 (density estimation) ,即学习并逼近真实的语言分布。
在标准的预训练中,模型通常通过最小化交叉熵损失 (cross-entropy loss) 来进行优化。这一过程会自然地鼓励模型变得“校准” (calibrated)。校准意味着模型对其预测的置信度应该与其预测的准确率相匹配。例如,如果模型对100个预测都给出了80%的置信度,那么其中大约80个预测应该是正确的。
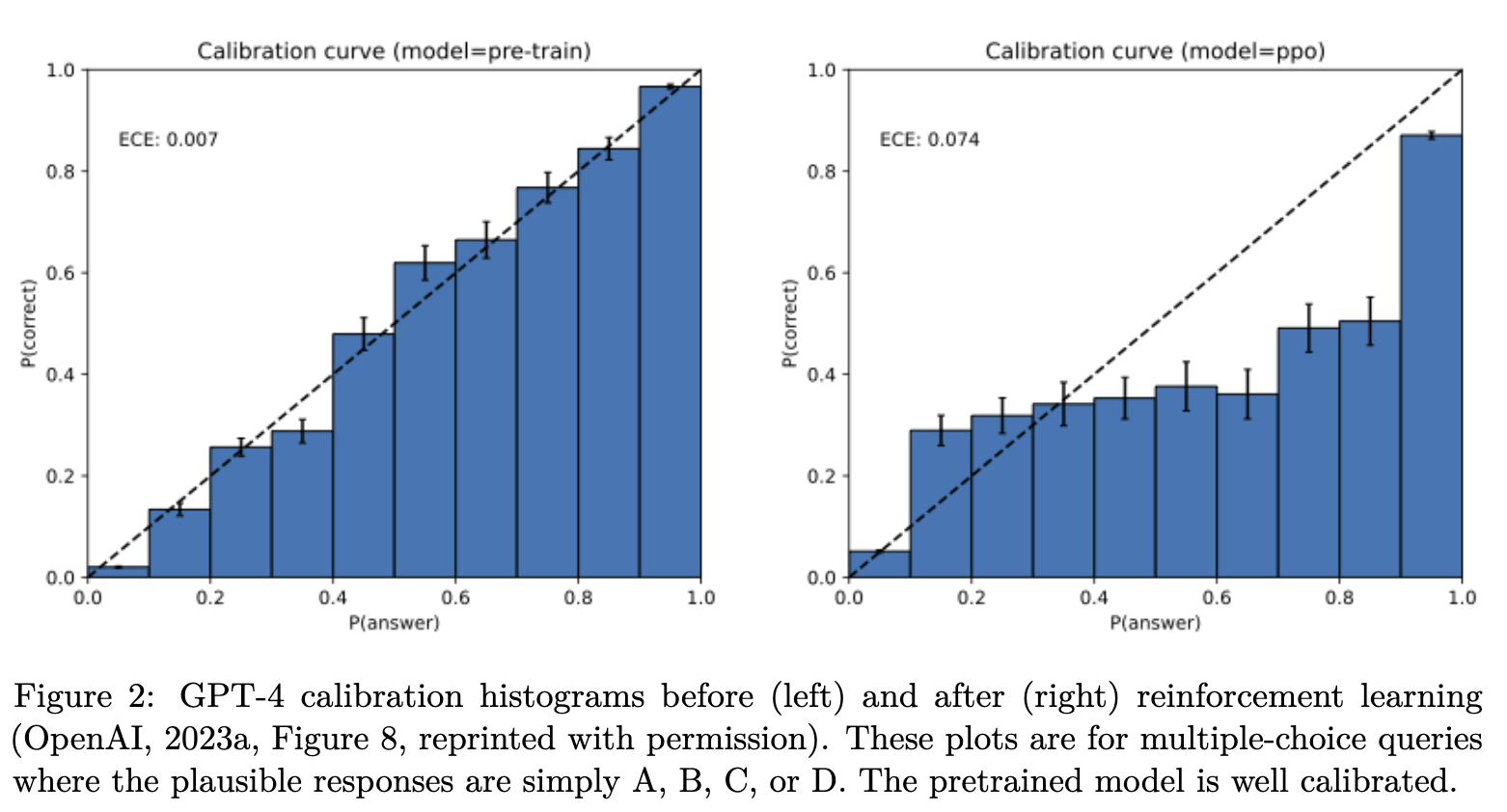
上图显示,预训练后的GPT-4(左图)表现出良好的校准性。论文通过数学推导证明,一个经过良好校准的模型,其生成误差(幻觉)率存在一个下限。换句话说,为了实现良好的校准,模型必须在某些情况下产生幻觉。
小结:预训练阶段的幻觉并非偶然,而是由学习目标本身决定的。当模型试图学习包含大量任意、无规律事实的语言分布时,统计压力会迫使其产生错误。将生成问题归约为分类问题,清晰地揭示了这一内在机制。
3. 后训练阶段幻觉为何持续存在?
预训练产生了基础模型,而后训练阶段(如指令微调和人类反馈强化学习RLHF)旨在优化模型,使其更有用、更无害,其中也包括减少幻觉。尽管经过了后训练,幻觉问题依然顽固存在。论文为此提供了一个深刻的社会技术学 (socio-technical) 解释。
3.1 评估体系的激励错位
论文将语言模型的评估过程比作学生参加考试。想象一下一个多项选择题考试,答对得1分,答错或不答都得0分。在这种评分体系下,一个理性的学生在遇到不确定的题目时,最佳策略就是猜测。因为猜测至少有概率得分,而不答则确定是0分。
当前主流的大型语言模型评估基准 (benchmarks) 和排行榜 (leaderboards),绝大多数都采用了类似的二元评分机制 (binary 0-1 scheme),即只看重准确率 (accuracy) 或通过率 (pass-rate) 。模型给出一个完全正确的答案得满分,而任何不完美的答案,包括表达不确定性(如回答“我不知道”)或给出部分正确但谨慎的答案(如回答“某个秋天的日子”而不是猜测一个具体的生日),都会被判为0分。
这种评估方式创造了一种“惩罚不确定性的流行病 (epidemic of penalizing uncertainty) ” 。为了在这些主流排行榜上取得高分,模型开发者有强烈的动机去优化模型,使其成为一个“优秀的应试者”——即,在面对不确定性时,倾向于去“赌一把”,生成一个看似合理但可能错误的答案,而不是诚实地承认自己的无知。
3.2 系统性的“激励合谋”
论文的观点是,孤立地开发一个更好的幻觉评估基准是不足以解决问题的。即使存在一些专门用于衡量幻觉的评估,只要绝大多数有影响力的、决定模型排名的主要评估体系仍然在奖励猜测行为,那么模型开发者为了追求更高的排名,就依然会训练出倾向于幻公然的模型。
这构成了一个社会技术学层面的困境:
-
技术层面:模型通过优化算法来最大化其在评估基准上的得分。 -
社会层面:研究社区、开发者和用户通过排行榜来评判和选择模型,而这些排行榜普遍采用奖励猜测的指标。
这两个层面相互作用,形成了一个强化幻觉行为的闭环。人类在现实生活中会因为“不懂装懂”而受到惩罚(例如,提供错误的医疗建议会导致严重后果),从而学会了在不确定时表达审慎的价值。然而,语言模型主要通过这些“惩罚不确定性”的考试来接受评估,因此它们始终处于一种“应试模式”中。
小结:幻觉在后训练阶段的持续存在,主要不是技术难题,而是一个由当前评估生态系统驱动的激励问题。整个社区对准确率的过度追求,无意中塑造了乐于猜测而非诚实表达不确定性的模型。
4. 论文核心理论与数学推导
为了让读者更深入地理解论文的论证过程,本部分将详细解析其核心的理论框架和数学公式。
4.1 理论框架:带提示 (Prompt) 的通用模型
论文首先将基础理论从无提示的文本生成,推广到更常见的带提示的问答场景。
-
一个样本 不再是单个文档,而是一个提示-响应对 ,其中 是提示 (context), 是响应 (response)。 -
所有可能的“合理”的提示-响应对构成集合 。 -
被划分为有效的集合 和错误的集合 。 -
模型的生成误差率 err 定义为模型生成一个属于 的响应的概率:。
在此基础上,论文给出了其核心定理。
4.2 核心定理一 (Theorem 1)
定理一:对于任何训练分布 (满足 ,即训练数据都是有效的)和任何基础模型 ,以下不等式成立:
我们来逐一解析这个公式中的每一项:
-
: 模型的生成误差率(幻觉率),我们希望它尽可能小。 -
: 在带提示的 IIV 问题上的分类错误率。它反映了从根本上区分有效响应和错误响应的难度。 -
: 对于给定的提示 ,有效响应的数量。 -
: 对于给定的提示 ,错误响应的数量。 -
: 一个与具体任务相关的常数因子。对于生日问题,有效答案只有1个(忽略IDK),而错误答案有364个,这个比值很小,使得不等式约束更强。 -
: 一个衡量模型校准程度的项。,其中 是模型认为概率高于某个阈值的响应集合。如前文所述,经过预训练的良好模型,其 值通常很小。
定理一的深刻含义:它为任何语言模型的幻觉率提供了一个下限。这个下限主要由两方面决定:一是任务本身的内在难度 (),二是模型的校准程度 ()。在一个经过良好校准( 很小)的模型上,如果任务本身很难区分对错( 很大),那么模型就必然会产生高比例的幻觉。
4.3 应用场景一:任意事实的幻觉 (Arbitrary-fact hallucinations)
论文将上述理论应用于一类特殊且重要的问题:任意事实。这指的是那些事实之间没有统计规律可言的情况,比如名人的生日、书籍的出版日期等。学习这些事实需要大量的记忆,而无法通过推理得到。
对于这类问题,论文引入了 “单例率” (singleton rate, sr) 的概念。
-
单例 (Singleton) :在包含 个样本的训练数据中,某个提示 只出现过一次(且其对应的答案不是IDK)。 -
单例率 (sr) :所有单例在训练数据中占的比例 ,其中 是单例的数量。
单例率源于图灵在二战中提出的“缺失物种问题”的估计方法,它被用来估计在已有样本之外,遇到全新事件的概率。直观上,训练数据中只出现一次的事实,暗示了在整个知识空间中还有大量我们闻所未闻的、类似频率的事实存在。
基于此,论文给出了关于任意事实的第二个核心定理。
定理二 (Theorem 2) :在任意事实的模型下,任何算法训练出的模型 ,其幻觉率 满足以下下限(以 的概率):
定理二的意义:它直接将模型的幻觉率与训练数据的一个可观测属性——单例率——联系起来。如果一个训练数据集中包含了大量低频、只出现一次的事实(即 很大),那么模型在回答这类问题时,几乎必然会产生大量的幻觉。例如,如果一个语料库中20%的生日事实都是只在某个人的讣告中提到过一次,那么可以预期,模型在被问及未见过的生日时,幻觉率至少是这个比例的某个倍数。
4.4 应用场景二:模型能力不足 (Poor models)
除了数据本身无规律,幻觉也可能源于模型自身的能力局限。比如,一个模型家族(如n-gram模型)可能在结构上就无法捕捉某些复杂的语言现象。
论文以经典的三元语法模型 (trigram model) 为例进行了说明。Trigram模型仅根据前两个词来预测下一个词,无法理解长距离的依赖关系。
考虑以下两个句子:
-
: She lost it and was completely out of ... ( = her mind) -
: He lost it and was completely out of ... ( = his mind)
对于trigram模型,"out of" 之后的词只依赖于 "out of"。因此,它无法区分这两个语境,在两种情况下生成 "her mind" 和 "his mind" 的概率是相同的,导致其在至少一半的情况下会犯错。
论文将此推广为定理三。
定理三 (Pure multiple-choice) :对于每个提示都只有一个正确答案的多项选择任务,幻觉率 满足:
其中:
-
: 选项的数量。 -
: 使用该模型家族 的分类器所能达到的最小可能错误率。它反映了模型家族的内在局限性。
对于trigram模型的例子,,,可以得出 。这与我们的直觉得出该模型至少有一半概率出错是一致的。
小结:论文通过严谨的数学理论,从不同角度揭示了幻觉的必然性。无论是源于数据本身的“不可知性”(任意事实),还是源于模型架构的“不能知性”(模型能力不足),幻觉都被证明是现有框架下的一个系统性产物,而非偶然的程序错误。
5. 解决方案:重新校准评估体系
既然问题的根源在于评估体系的激励错位,那么解决方案也必须从这里入手。论文倡导的不是简单地增加更多的幻觉评估,而是对现有的、有影响力的主流评估基准进行系统性的改造。这是一种社会技术学的缓解策略 (socio-technical mitigation) 。
5.1 引入“显式置信度目标” (Explicit Confidence Targets)
论文提出的核心解决方案是,在评估的指令中明确地告知模型评分规则和置信度要求。这借鉴了一些标准化考试(如早年的SAT、GRE考试)的做法,即答错题目会倒扣分,以此来抑制考生的胡乱猜测。
例如,可以将评估问题修改为:
“回答本题,仅当你的置信度高于 t 时。因为错误答案将被扣除 t/(1-t) 分,正确答案得1分,回答‘我不知道’得0分。”
通过调整阈值 (例如 ),评估者可以系统性地考察模型在不同风险偏好下的表现。
这种做法有两大好处:
-
改变激励结构:当错误答案的惩罚足够大时,模型的最佳策略就不再是盲目猜测,而是进行诚实的风险评估。一个简单的计算表明,只有当模型认为自己正确的概率大于 时,回答问题才比回答“我不知道”的期望得分更高。 -
客观公正的评估:通过在指令中明确评分标准,评估就变得客观透明。模型开发者可以针对明确的置信度目标去优化模型,而不是去猜测模糊的、未言明的惩罚标准。一个真正优秀的模型,应该是在所有给定的置信度阈值下都能表现出最佳行为的那个。
5.2 改造现有主流基准
论文强调,这种新的评估范式不应该只停留在专门的幻觉测试中,而必须被整合进诸如 MMLU, SWE-bench 等被广泛使用、决定模型排名的主流评估基准中去。
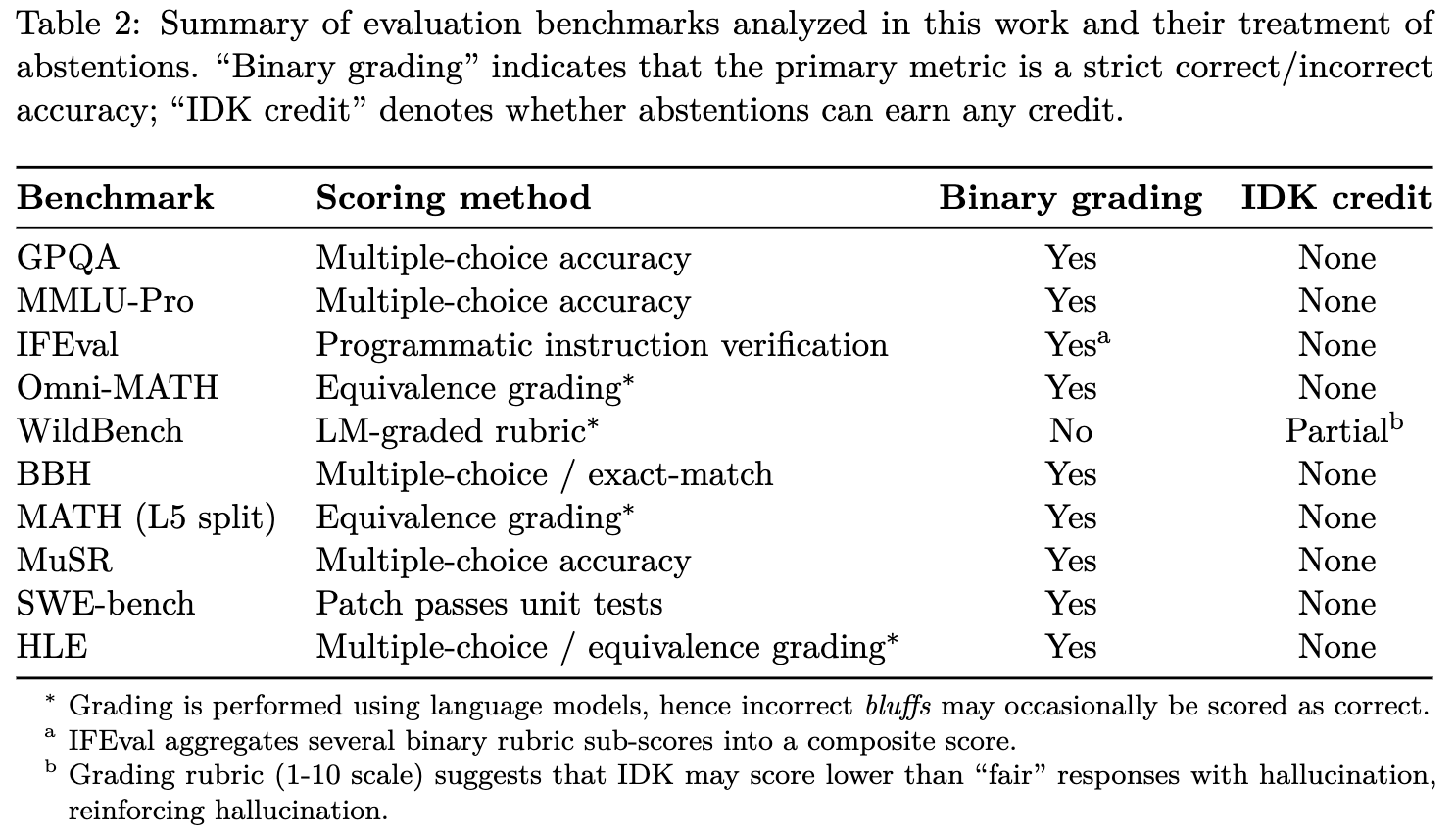
上表总结了多个流行基准的评分方式。可以看出,除了WildBench会给予“不知道”极低的部分分数外,绝大多数基准都对不确定性回答处以0分,是典型的“二元评分”。只有当这些主流评估的“游戏规则”被改变,整个社区的优化方向才会从单纯追求准确率,转向追求一种更审慎、更可信的智能。
5.3 行为校准
这种新的评估目标,实际上是在追求一种论文称之为“行为校准” (behavioral calibration) 的能力。它不要求模型输出一个精确的概率值(如“我有73%的把握”),而是要求模型能够根据给定的风险阈值 ,做出最有利的行为决策(是回答,还是承认不知道)。这种能力可以通过比较模型在不同阈值下的准确率和错误率来进行审计和评估。
小结:解决幻觉问题的关键,是一场自上而下的、针对评估体系的变革。通过引入明确的、带有惩罚机制的置信度目标,并将其实施于主流评估基准中,可以引导整个AI领域从“应试教育”模式转向培养更诚实、更可靠的AI模型。
6. 讨论与局限性
作为一篇严谨的学术论文,作者们也清晰地指出了其理论框架的适用范围和局限性。
-
合理性与无意义输出 (Plausibility and nonsense) :论文的分析主要集中在“看似合理”的错误陈述上,忽略了模型生成完全无意义、不合语法的文本的可能性。不过作者指出,只需稍作修改,其核心定理仍然适用于包含无意义输出的情况。 -
开放式生成 (Open-ended generations) :论文中的例子多为针对单一事实的问答。对于更复杂的开放式生成任务(如“写一篇关于……的传记”),“错误”的定义变得更加复杂。一个可行的做法是将任何包含一个或多个虚假事实的回答都定义为错误,但未来还需要研究如何衡量错误的程度。 -
搜索与推理并非万能药 (Search (and reasoning) are not panaceas) :尽管检索增强生成 (RAG) 等技术可以减少部分幻觉,但它们无法根除问题。因为当检索失败或无法提供高置信度答案时,在二元评分体系下,模型的最佳策略依然是猜测。此外,对于内在幻觉(如错误的数学计算),外部搜索也无能为力。 -
潜在上下文 (Latent context) :有些错误无法仅通过提示和响应来判断,它依赖于未言明的用户意图。例如,用户问“电话”,模型回答了“手机”,但用户想问的是“固定电话”。这种由语境模糊性导致的错误超出了当前框架的讨论范围。 -
错误的“三元划分” (A false trichotomy) :将模型的输出简单划分为“正确/错误/不知道”也是一种简化。现实世界中的错误有严重程度之分,不确定性也有不同等级。尽管如此,提供“不知道”这个选项,至少比强制模型在“对”与“错”之间做选择要好得多,打破了原有的“二元困境”。
附录:对当前主流评估基准的深入分析
为了进一步印证其核心论点,论文的附录F详细分析了多个在学术界和工业界具有广泛影响力的评估基准和排行榜,揭示了它们是如何系统性地奖励猜测行为的。
F.1 HELM Capabilities Benchmark
HELM (Holistic Evaluation of Language Models) 是一个被广泛使用的评估框架。其“旗舰”排行榜包含了五个场景,其中四个明确不为“我不知道”(IDK)提供任何分数。
-
MMLU-Pro 和 GPQA: 均为标准的多项选择题考试形式,没有IDK选项。 -
Omni-MATH: 评估数学问题答案的对等性,不为IDK提供特殊分数。 -
IFEval: 要求模型遵循一系列指令生成文本,没有明确的弃权选项。 -
WildBench: 评估模型对真实用户查询的响应,使用语言模型进行评分。评分标准(1-10分)显示,一个包含事实错误或幻觉的“尚可”回答(5-6分)得分会高于一个没有帮助用户解决问题的IDK式回答(可能被评为3-4分)。这实际上在鼓励模型进行猜测。
F.2 Open LLM Leaderboard
这个由Hugging Face维护的排行榜曾是开源社区最具影响力的基准之一。其评估集同样由多个任务构成,且绝大多数不支持对不确定性的奖励。
-
它包含了 MMLU-Pro, GPQA, 和 IFEval,与HELM重合。 -
BigBench Hard (BBH): 包含23个被设计为多项选择或精确匹配评分的任务,根据其设计初衷,不给IDK部分分数。 -
MATH (Level-5 split) 和 MuSR: 两者都完全基于准确率进行评估,不为IDK提供分数。
F.3 SWE-bench 和 Humanity's Last Exam
这两个是近年来涌现出的、旨在评估顶尖模型极限能力的基准。
-
SWE-bench: 包含数千个来自GitHub的真实软件工程问题。它基于生成的代码补丁是否能通过单元测试来进行评分,这是一个纯粹的二元准确率指标,无法区分一个错误的补丁和一个承认无法解决问题的响应。 -
Humanity's Last Exam (HLE): 包含了从数学到人文社科的2500个高难度问题。其主要指标是二元准确率,不为IDK提供分数。有趣的是,HLE提供了一个辅助的“校准误差”指标,但论文指出这个指标本身有缺陷:一个永远在幻觉但每次都诚实报告0%置信度的模型,其校准误差可以为0;反之,一个从不幻觉但每次都报告0%置信度的模型,其校准误差却是100%。这说明,后处理式的置信度评估不能替代在生成行为层面抑制幻觉。
通过对这些最具影响力的评估基准的剖析,论文有力地证明了其核心论点:当前的评估生态系统构成了一张巨大的、系统性的网络,它持续不断地向模型开发者传递一个明确的信号——猜测优于诚实。 幻觉问题,正是在这张大网的塑造下,才变得如此根深蒂固。
点评
论文超越了“训练数据有噪声”这类浅层解释,直接指出了问题的核心:现有的学习目标(最小化交叉熵)和评估范式(二元准确率)从根本上就激励模型去猜测,而非承认不确定性。这种诊断是开创性的,因为它揭示了幻觉是一个系统性问题,而非零星的程序错误。
本文最巧妙的理论贡献之一,是将复杂的文本生成任务归约 (reduction) 为一个更易于分析的“Is-It-Valid (IIV)”二元分类问题。这一操作不仅在数学上十分优雅,而且极具洞察力。它成功地将幻觉问题与机器学习领域研究了几十年的分类错误问题联系起来,使得我们可以借助成熟的学习理论(如VC维、模型复杂度等)来理解幻觉的统计学成因。
论文提出的“应试教育”类比非常生动且一针见血。它清晰地解释了为什么即使经过RLHF等复杂的后训练,幻觉问题依然顽固存在。因为只要决定模型排名的主流排行榜(MMLU, SWE-bench等)还在沿用“答对给分,不答或答错没分”的模式,模型开发者就有强烈的动机去训练一个“善于应试”而非“诚实可靠”的模型。这成功地将问题从纯技术领域扩展到了社区共识和评估标准这一更宏观的层面。
与许多只提出问题但解决方案模糊的论文不同,本文给出了一个非常具体、可操作的建议:改造主流评估基准,引入带有惩罚机制的显式置信度目标。这个方案直接对症下药,旨在改变驱动模型行为的激励结构。它不是一个需要发明全新算法的空中楼阁,而是呼吁整个社区共同参与的一项务实行动。
局限性:
为了构建其理论框架,论文将幻觉处理为一个二元(正确/错误)问题。但在现实世界中,幻觉存在程度差异。例如,“爱因斯坦出生于1879年3月15日”(错误,实际是14日)和“爱因斯坦是一位17世纪的剧作家”这两种幻觉的严重程度截然不同。论文的框架难以捕捉这种细微但重要的差别。其提出的“正确/错误/不知道”三元划分,虽然优于二元,但仍是一种高度简化。
论文中的核心示例(生日、论文题目)都围绕着事实性知识 (factual knowledge) 的回忆展开。对于其他类型的幻觉,例如推理幻觉(如数学题中看似逻辑通顺但中间步骤错误)或指令遵循幻觉(未能完全满足复杂指令的所有约束),该框架的解释力可能会有所下降。虽然理论上可以把这些都归为“错误”,但其内在的产生机制可能更为复杂,不仅仅是“缺乏可学习模式”或“模型能力不足”所能完全涵盖的。
“改革所有主流评估基准”是一个知易行难的宏大目标。这需要各大公司、研究机构和开源社区达成共识,协调行动,难度极高。谁来设定惩罚阈值t? 不同的应用场景对风险的容忍度不同,一个统一的阈值可能并不普适。评估成本和复杂性增加:引入更复杂的评分规则后,自动化评估将变得更加困难,尤其是依赖语言模型作为裁判(LM-as-a-judge)的评估方法,其本身就可能因无法理解复杂规则而产生新的错误。
论文将主要原因归结为学习目标和评估体系,这无疑是正确的。但这也可能使其在一定程度上低估了模型架构、解码策略和未来新算法的潜力。例如,未来的模型架构(可能不再是Transformer)是否能在内在机理上更好地表征不确定性?是否存在一种新的训练方法,即使在二元评分下也能有效抑制猜测行为?论文的社会技术学解释虽然有力,但不应完全排除算法层面取得突破性进展的可能性。
往期文章: