让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Efficient Pre-Training with Token Superposition
-
论文链接:https://arxiv.org/pdf/2605.06546
TL;DR
凭借 Hermes Agent (140K Star)火速出圈的 Nous Research 团队,刚刚提出了一种 Token 叠加训练方法:Token Superposition Training (TST),有望把大模型的预训练成本压低一个量级。
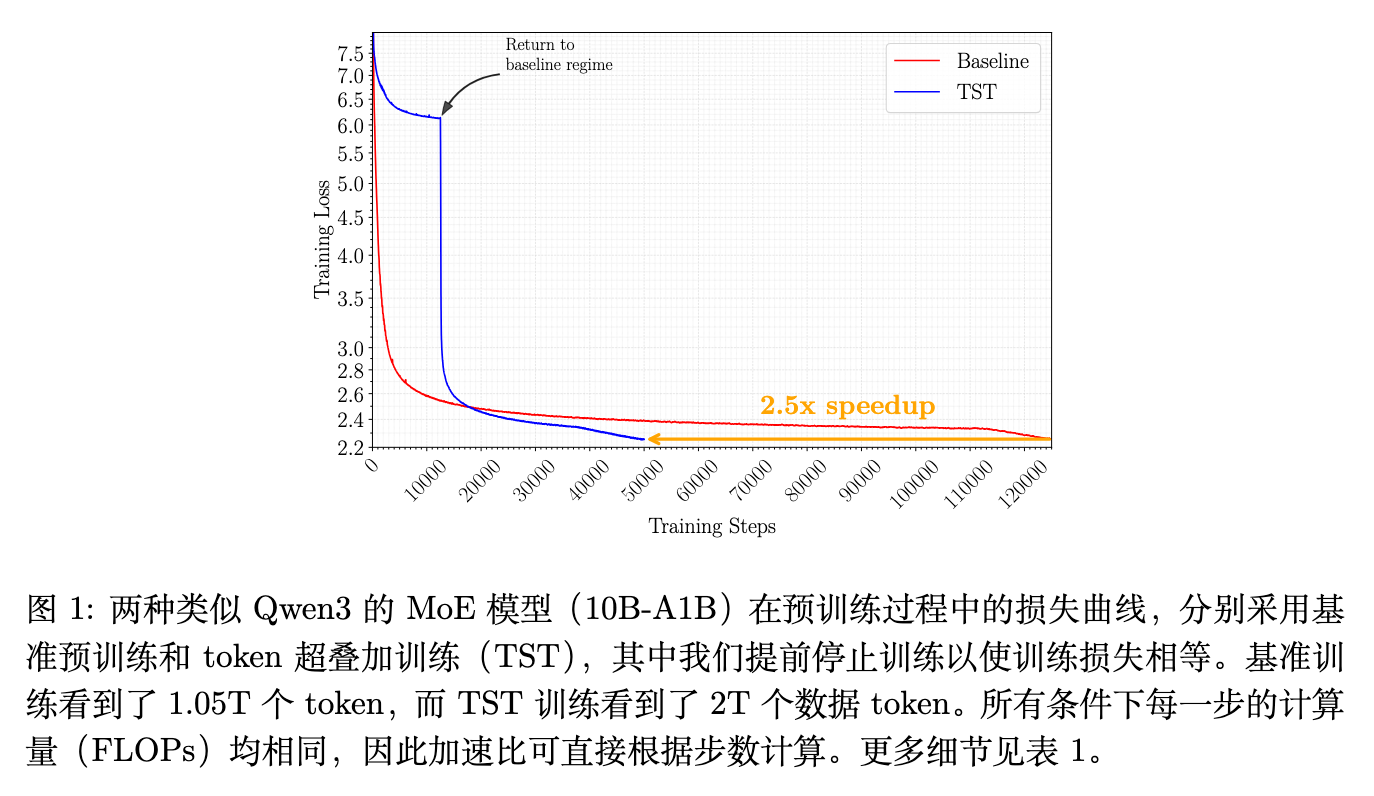
在大型语言模型(LLM)的预训练过程中,如何在给定算力预算下最大化数据吞吐量一直是核心痛点。现有的许多效率优化方法往往需要修改模型的推理架构(如稀疏注意力、MoE),或者引入额外的参数和辅助损失(如多 Token 预测 MTP),这使得训练期效率与推理期效率相互耦合。
针对这一问题,作者提出了一种名为 Token 叠加训练(Token-Superposition Training, TST) 的即插即用方法。TST 的核心机制分为两个阶段:在第一阶段(叠加期),算法将连续的 个 Token 组合成一个“词袋(bag)”,通过对它们的嵌入向量求平均来构建单一的潜在表征,并使用多标签交叉熵(Multi-hot Cross-Entropy, MCE)目标来预测下一个词袋;在第二阶段(恢复期),模型丢弃叠加机制,恢复到标准的自回归单 Token 预测训练。这种设计使得模型在第一阶段能够以 倍的吞吐量消耗数据,而无需增加单步的 FLOPs。
实验数据表明,TST 在不改变模型并行策略、优化器、分词器或底层架构的前提下,展现出稳定的收益。在 10B 参数的混合专家(MoE)模型规模下,为了达到 2.236 的同等验证损失,基线模型需要消耗 12311 个 B200 GPU 小时,而 TST 仅需 4768 小时,实现了约 2.5 倍 的预训练提速。此外,作者的消融实验揭示了输入叠加与输出叠加的解耦效应,以及两阶段训练中保持输入输出层表征对齐的必要性。
1. 引言
现代通用大型语言模型的性能提升,不仅依赖于模型参数规模的扩大,更依赖于激进的数据扩展策略。在当前的计算最优(Compute-optimal)缩放法则下,研究人员经常将模型训练至远超 Chinchilla 推荐的数据量,以最大化模型在推理时的表现。在这种数据密集型的范式中,预训练阶段的核心考量之一是:在固定算力预算下,模型消化原始文本的效率。
回顾近期关于语言模型预训练效率的研究,大致可以归纳为三个方向:
-
信息最大化(Information maximization):通过改进输入先验(如 BPE、Unigram 等更优的分词器)或提供更丰富的训练信号(如多 Token 预测、基于顺序的辅助目标)来增加每个样本包含的信息量。 -
算力稀疏化(Compute sparsity):保持输入表征不变,但通过仅激活部分参数(如稀疏 MoE)或仅关注部分位置(如稀疏注意力)来降低处理每个 Token 所需的 FLOPs。 -
压缩建模(Compressive modeling):在模型内部学习进一步压缩表征,减少流经计算密集型层的表征数量(如 Byte-Latent Transformer、Autoregressive UNet 等)。
作者指出,上述许多方法在提升训练效率的同时,也改变了模型的推理期架构或动态特性。近期的部分研究表明,独立于训练算力来扩展推理算力可以改善下游任务性能。因此,为了最小化混杂因素,有必要探索一种仅在训练期间使用、且保持模型推理架构“原封不动”的效率优化方法。
此外,单体预训练范式正逐渐向多阶段预训练过渡。先前的研究发现,在预训练的初始阶段可以使用更高效的训练方法,随后模型具备足够的弹性,能够快速适应最终期望的行为模式。基于这一观察,作者提出了 Token 叠加训练(TST),旨在通过最大化训练期的数据吞吐量来提升预训练效率,同时为最终的自回归预测任务做好准备。
2. Token 叠加训练(TST)方法解析
Token 叠加训练与标准的下一个 Token 预测(Next-token prediction)相比,主要包含两个层面的修改:输入端的 Token 嵌入叠加,以及输出端的目标函数替换。整个训练过程被划分为两个阶段:叠加期(Superposition phase)和恢复期(Recovery phase)。
2.1 输入叠加:Token 嵌入的词袋化
在标准训练中,模型接收形状为 的 Token 序列(其中 为批次大小, 为序列长度)。在 TST 的叠加期,连续的、已分词的数据序列被分割成大小为 的非重叠连续片段,作者将其称为“词袋(bags)”。
具体而言,形状为 ( 为词表大小)的数据被重塑为 的词袋视图,其中 是叠加的词袋大小, 是潜在的“s-token”序列长度(即 )。
在模型的嵌入层(Embedding layer),算法通过对词袋内所有 Token 的嵌入向量求算术平均,来创建一个单一的潜在“s-token”。这一操作将输入形状转换为 ( 为模型的隐藏层维度)。
由于模型现在处理的是输入文本的粗粒度表征,对于潜在“s-token”上消耗的每一单位 FLOPs,模型实际消化了 倍的数据 Token。为了在训练期间进行等算力(Equal-FLOPs)比较,作者选择在叠加期将输入数据序列长度 增加 倍,从而保证 TST 的每一步计算量与基线训练完全一致。
以下是作者提供的 PyTorch 实现逻辑:
# 假设 tokens 形状为 (bs, sp_seq, superposition_bag_size)
# 在 float32 精度下求和以保证数值稳定性
h = self.tok_embeddings(tokens[..., 0])
h_dtype = h.dtype
h = h.float()
for i in range(1, superposition_bag_size):
h = h + self.tok_embeddings(tokens[..., i]).float()
# 求平均并转换回原始数据类型
h = (h / superposition_bag_size).to(h_dtype)
2.2 输出叠加:多标签交叉熵损失
在输出端,模型不再通过单个输出头预测单一的下一个 Token,而是预测“下一个词袋”。为此,作者将标准的单标签交叉熵(One-hot Cross-Entropy, CE)损失修改为多标签交叉熵(Multi-hot Cross-Entropy, MCE)损失。
给定预测对数(logits) 和标签索引 ,标准的 CE 损失定义为:
对于包含 个有效目标 Token 的词袋 ,MCE 损失的一种直观展开形式是:将每个有效标签的目标概率设定为均等的 (总和为 1)。此时,目标分布 在词袋内的概率为 ,在词袋外为 。带有此目标分布的交叉熵计算如下:
与单标签情况不同,这种均匀目标分布具有非零熵 ,因此标准的交叉熵最小值会停留在 而不是 。为了恢复与标准 CE 相同的“在最优解处消失”的特性,作者减去了目标的熵(即使用 KL 散度):
经过代数重排,可以得到:
在实际训练中,如果仅关注训练动态而不关心损失的绝对数值,可以丢弃常数项 ,因为它的梯度为 0。这就得到了最终使用的简化形式:
为了保证因果性,标准的下一个 Token 预测标签在被分割成非重叠词袋之前,需要向左平移 个位置。这确保了位置 处的 个 Token 构成的词袋,预测的是位置 处的下一个词袋。
这种简化形式允许直接复用主流预训练库中高度优化的 CE 损失算子,而无需对训练代码进行侵入式修改。
2.3 两阶段训练机制
由于 TST 目标是半因果和半自回归的(模型整体上从左到右预测序列,但丢失了词袋内 Token 的顺序),仅使用 TST 训练的模型在推理时会产生混合了未来 个 Token 概率的无意义输出。
为了解决这个问题,作者引入了恢复期。定义 为使用 TST 训练的步数占总步数的比例。在第一阶段(前 比例的步数)使用 TST 后,模型保存检查点,随后在第二阶段(剩余 比例的步数)完全移除 TST 代码,恢复使用标准的自回归下一个 Token 预测目标继续训练。
3. 实验设置与主结果
作者在 270M、600M、3B 以及 10B 参数规模的模型上进行了广泛的实验。训练框架采用 TorchTitan 和 FSDP 并行策略,运行在 NVIDIA B200 GPU 上。数据集使用 DCLM,对于较小的模型,标准批次大小设定为 2M Tokens。

表 1 展示了不同规模模型的主实验结果。在 270M 模型(总步数 20000,TST 步数 6000,词袋大小 6)中,基线模型消耗了 42B Tokens,最终 Loss 为 3.212;而 TST 模型消耗了 105B Tokens,最终 Loss 降至 3.142,同时在 HellaSwag、ARC-E 和 ARC-C 等下游任务上的准确率均有提升。
在 3B 规模下,作者进行了等算力、等损失和等数据的对比:
-
等算力对比:基线模型训练 20000 步(消耗 247 个 B200 小时,42B Tokens),最终 Loss 为 2.808。TST 模型同样训练 20000 步(消耗 247 个 B200 小时,105B Tokens),最终 Loss 降至 2.676。 -
等损失对比:为了达到 2.677 的 Loss,基线模型需要训练 36000 步(消耗 443 小时,75B Tokens);而 TST 模型仅需 247 小时即可达到更低的 2.676 Loss。

图 3 直观地展示了 3B 模型的损失曲线。在图 3a(等算力)中,TST 模型在进入恢复期后,损失值迅速下降并超越基线。在图 3b(等损失)中,TST 曲线在更早的步数截断,表明其以更少的计算步骤达到了与基线相同的收敛水平。
对于 10B 规模的混合专家模型(MoE,激活参数 1B),作者使用了 Qwen3 的架构。基线模型训练了 1.05T Tokens,耗时 12311 个 B200 小时,最终 Loss 为 2.252。TST 模型(词袋大小 16)在等算力步数下训练了 2T Tokens,为了匹配基线的 Loss,TST 提前停止训练,仅耗时 4768 小时便达到了 2.236 的 Loss。这对应于约 2.5 倍的总预训练时间缩减。在下游任务中,TST 模型的 MMLU 达到 39.0,优于基线的 37.4。
4. 机制分析与消融实验
为了理解 TST 的工作原理,作者对叠加机制的各个组件进行了消融研究。
4.1 输入与输出叠加的解耦
作者测试了仅输入叠加、仅输出叠加以及完整叠加的设置。实验在词袋大小 、比例 的条件下进行。
-
仅输入叠加:仅对输入 Token 嵌入进行词袋化平均,但输出端仅预测单一的下一个 Token。 -
仅输出叠加:输入端处理单个 Token,但输出端预测下一个词袋。

图 6 的恢复期损失曲线显示,所有叠加设置均优于基线。然而,单独的输入或输出叠加无法捕捉到完整叠加的全部收益。完整叠加(结合两者)带来了进一步的损失下降,且没有相互干扰的迹象。作者认为,这表明 TST 并非单一的技巧,而是由两个正交机制组成:输入叠加改变了输入粒度和每单位信息的 FLOPs 成本,而输出叠加修改了预测目标和梯度分布。
关于输入叠加为何有效,作者提出一种假设:第一阶段充当了一种“预-预训练(pre-pre-training)”。在学习全分辨率语言之前,模型暴露于一种更简单的分布中,这种分布与自然语言共享粗粒度的统计结构(如局部主题、共现关系),并将这种归纳先验带入第二阶段。另一种解释是,在嵌入空间中求平均隐式地正则化了嵌入几何结构,因为许多随机的 s-gram 在求和后必须保持线性可分。
4.2 叠加窗口大小与比例的选择
作者在 270M 和 600M 模型上,针对不同的词袋大小 和叠加步数比例 进行了网格搜索。

图 4 显示,随着词袋大小 的增加,最终损失呈现 U 型曲线。这表明需要正确调整该超参数以找到最佳设置。当 落在 4 到 8 之间,且 在 0.2 到 0.4 之间时,模型通常能获得最佳的损失收益。

图 5 的下游任务平均准确率评估也印证了这一趋势。在最优参数区间内,TST 模型的零样本(0-shot)评估结果稳定高于基线模型。
4.3 输出词袋的加权策略
在多标签交叉熵损失中,默认策略是对词袋内的每个 Token 给予均匀的权重(即目标概率均等)。作者尝试了不同的加权方案,特别是幂律(Power-law)加权。
幂律加权函数定义为 ,其中 是 Token 在词袋中的位置。这种设计的灵感来源于文本中 Token 对之间互信息的衰减规律。

如图 10 所示,作者计算了 DCLM 数据集中采样的 Token 对之间的互信息,发现其随距离的衰减服从幂律分布(拟合公式为 ,其中 )。这表明距离当前上下文越远的未来 Token,其预测难度越高,包含的互信息越少。

图 8 对比了均匀加权和幂律加权在不同词袋大小下的表现。实验发现,在较小的词袋大小(如 )下,均匀分布表现更优;但在较大的词袋大小()下,幂律加权产生的最终损失低于均匀平均,且表现更加稳定。这印证了在预测较远的未来时,根据互信息衰减进行相对权重调整是合理的。
4.4 两阶段表征对齐假设
在多阶段预训练的现有文献中,通常会引入一个“对齐阶段(Alignment phase)”:冻结主模型,仅训练一个小型适配器(Adapter),然后再解冻全部参数进入恢复期。TST 并没有采用这种设计。
作者假设,LLM 的内部电路对其输入和输出表征高度敏感。TST 能够在叠加期和恢复期之间共享输入嵌入和输出 LM 头,避免了先前方法中出现的表征不匹配问题。

为了验证这一假设,作者进行了一项 3B 规模的消融实验(见表 2)。在“Dense TST /w Randomization”设置中,模型在恢复期开始时,随机重新初始化了输入嵌入层和输出 LM 头。结果显示,这种扰动彻底消除了 TST 的收益,其最终 Loss(2.938)甚至劣于完全不使用 TST 的基线(2.808)。这表明,TST 步骤在这种情况下被完全浪费。这一结果支持了作者的假设:两个阶段之间的表征对齐是 TST 能够成功免除显式对齐训练的关键原因。
5. 讨论与相关工作对比
在探讨辅助预测目标时,多 Token 预测(Multi-token prediction, MTP)是近期备受关注的方法。MTP 使用 个独立的预测头同时预测未来的 个 Token。
作者指出,TST 与 MTP 占据了设计空间中的不同位置。MTP 并没有增加训练时的吞吐量:它在每单位 FLOP 下处理的 Token 数量与基线相同,同时还增加了额外的参数和辅助损失项。MTP 报告的收益主要体现在推理期的投机解码(Speculative decoding)加速上,且已知在较小模型上可能会降低性能。
相比之下,TST 严格增加了训练期间的 Token-per-FLOP 吞吐量,保持了推理期架构不变,并在从 270M 到 10B 参数规模上观察到了稳定的收益。因此,作者认为 TST 与辅助损失方法是正交的,将两者结合是未来一个自然的研究方向。
另一个相关工作是未来摘要预测(Future summary prediction),该方法预测未来 Token 的压缩表征。其主要区别在于架构层面:它在常规的下一个 Token 目标之上附加了一个带有二元交叉熵损失的辅助头。而 TST 保持了单一主头和单一交叉熵损失,仅替换了预测目标。
6. 局限性与未来方向
论文也坦诚地讨论了 TST 的局限性及未来的研究空间:
-
数据消耗与算力约束的权衡:TST 实际上是在给定的计算成本下,通过消耗更多的数据来换取更低的损失。其潜在假设是 LLM 预训练受限于算力瓶颈(Compute-bound)而非数据瓶颈(Data-bound)。如果未来的趋势转向数据受限,这种假设可能不再成立。在这种情况下,仅使用“输出叠加”可能更具优势,因为它在不增加数据消耗的前提下优于基线。 -
长上下文性能:将初始序列折叠为词袋序列,使得 TST 在叠加期的有效上下文长度增加。这可能会对长上下文性能产生积极影响,因为对原生长上下文数据的截断或分割会减少。作者将此留作未来工作进行评估。 -
扩展定律(Scaling Laws):受限于算力资源,作者未进行更大规模的消融实验。未来的工作可以研究 Token 叠加的扩展定律,以预测更大模型规模(包括工业级预训练)下的最佳 TST 设置。 -
可解释性机制:虽然作者提出了关于“预-预训练”和嵌入空间正则化的假设,但深入的可解释性研究将有助于更好地理解 Token 叠加的底层机制。
7. 总结
本文提出了一种新颖的 LLM 训练范式:Token 叠加训练(TST)。在叠加期,算法在不改变单步 FLOPs、并行策略、模型架构、分词器或数据分布的情况下,将样本吞吐量提高了 倍。随后的恢复期使模型平滑过渡回标准的 LLM 预训练机制,展现出快速的恢复能力,并在等算力条件下迅速超越基线预训练的损失。
实验证明,TST 显著提高了同等计算成本下的预训练效率。或者说,达到相同损失所需的计算成本可降低至原先的一半左右(例如在 10B MoE 规模下实现 2.5 倍提速)。总体而言,该范式在合理的超参数范围内(叠加词袋大小 ,比例 )表现出良好的鲁棒性,为提升大规模语言模型训练效率提供了一条无需修改底层架构的实用路径。
更多细节请阅读原论文。

