让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
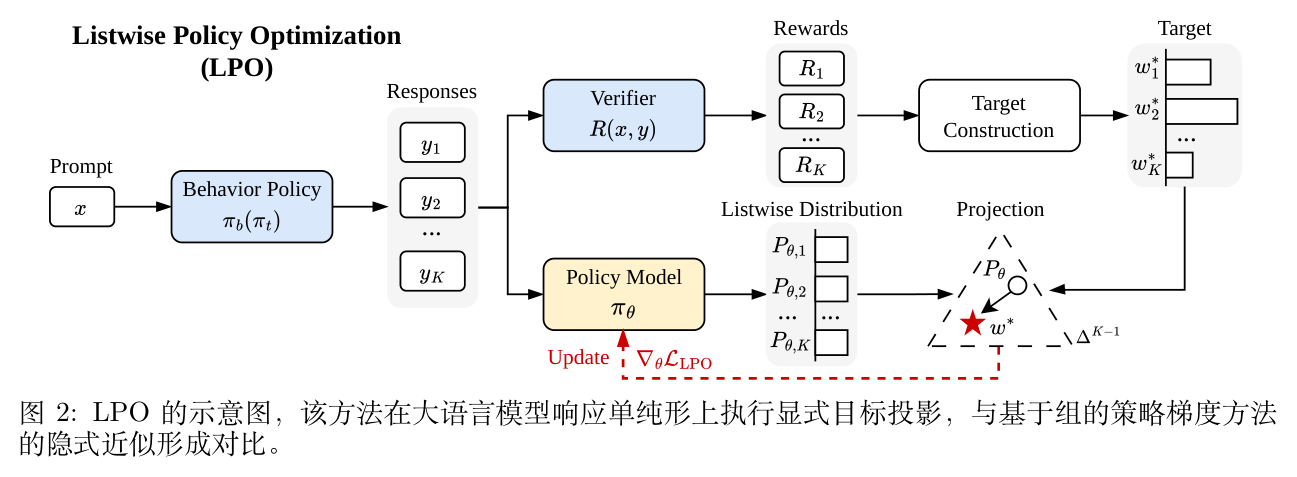
论文标题:Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
-
论文链接:https://arxiv.org/pdf/2605.06139
TL;DR
今天解读一篇来自清华大学和腾讯的论文《Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex》。在提升大语言模型(LLM)复杂推理能力的后训练阶段,基于可验证奖励的强化学习(RLVR)已成为标准范式。当前占据主导地位的是无评论家(Critic-free)、基于组的策略梯度方法(例如 GRPO),这类方法通过对同提示下采样的多个响应计算组内相对优势来进行策略更新。然而,现有研究多从优势函数归一化(如均值中心化、标准差缩放)的工程视角来解释其有效性,掩盖了其内在的优化机制。
作者提出了一种统一的几何视角,指出这些基于组的策略梯度方法实际上共享相同的底层结构:它们都在响应单纯形(Response Simplex)上隐式地定义了一个目标分布,并通过策略梯度执行向该目标的第一阶近似逆向 KL 投影。基于这一发现,论文提出了列表策略优化(Listwise Policy Optimization, LPO)框架,将这种隐式的近似转化为显式的目标投影。LPO 将优化过程解耦为两步:首先在单纯形上通过精确的散度最小化构建一个受控的列表吉布斯目标(Listwise Gibbs Target),随后将策略向该目标进行投影。
理论与实验表明,LPO 框架具有显著优势。理论上,精确的单纯形投影能产生有界、零和且自校正的梯度,从而提供单调的列表目标提升保证;同时,解耦的设计允许灵活选择投影散度(如正向 KL 散度),从而获得模式覆盖(Mode-Coverage)等结构性属性。在逻辑、数学、编程和多模态几何等多个推理任务上的广泛实验证实,在匹配隐式目标温度的严格控制变量下,LPO 在 Pass@1 和 Pass@k 准确率上持续优于典型的策略梯度基线,同时在训练轨迹中内在地保持了更高的优化稳定性和响应多样性。
1. 引言
近年来,基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)在激发大语言模型(LLM)的复杂问题解决能力方面展现出巨大潜力。在这一领域,无评论家模型、基于组的强化学习范式(例如组相对策略优化 GRPO)被广泛采用。这类方法针对每个提示(Prompt)采样一组响应,使用验证器对它们进行评分,并利用组相对优势信号进行策略梯度更新。后续的文献引入了多种关键的改进,主要集中在优势函数的归一化和训练稳定化上。
然而,仅仅从优势归一化的角度来看待这些经验性的改进,会掩盖其内在的优化机制。本文通过在单纯形上联合定义采样响应的列表分布,为基于组的强化学习算法提供了一个统一的几何视角:它们的优势函数公式实际上隐式地构建了一个以奖励加权的 Softmax 目标分布,而目标的平滑度(Sharpness)由归一化方案配置。标准的策略梯度更新仅仅是向这个隐式目标进行逆向 Kullback-Leibler (KL) 投影的第一阶近似。
这种统一的视角不仅阐明了现有方法的工作原理,也激发了对目标投影机制进行显式设计的动机。在经典的强化学习中,显式目标投影已有研究(如 MPO、AWR),但连续动作空间的存在使得这些方法必须依赖函数近似。相比之下,基于组的 RLVR 具有一个独特且理想的属性:针对一个提示采样的响应自然形成了一个有限的单纯形(Finite Simplex),这使得以闭式解精确计算目标分布和投影成为可能。这使得将"以什么分布为目标"和"如何向其投影"这两个目标清晰地分离开来成为现实,从而促成了从隐式近似向精确列表优化的平滑过渡。
基于上述背景,本文提出了列表策略优化(LPO),以在响应单纯形上实现显式的目标投影。LPO 通过将近端强化学习目标限制在采样响应上,给出了具有可控温度的闭式解目标,随后通过散度最小化将策略投影到该目标上。精确的投影带来了有界、零和且自校正的梯度,从而降低了方差并稳定了优化。此外,解耦的结构允许灵活设计投影散度,本文实现了正向和逆向 KL 散度作为两种代表性实例。
2. 核心视角:基于组的策略梯度作为隐式目标投影
本节通过列表分布的视角重新解释了基于组的策略梯度,旨在探究这些更新隐式追求的目标分布,以及不同的优势归一化方案对塑造该目标的影响。
2.1 响应单纯形上的列表分布
在 RLVR 中,设 为提示, 为长度为 的响应,由参数化策略 自回归生成。给定奖励函数 和参考策略 ,标准的 KL 正则化 RLVR 目标为最大化期望奖励减去对参考策略的 KL 惩罚。在本文关注的规则奖励(通常为二元或稀疏的,)设定下,通常不使用显式的参考惩罚(即 )。
在基于组的策略梯度(如 GRPO)中,对于每个提示 ,行为策略 (通常是更新前的快照 )生成一组 个响应 ,每个响应获得奖励 ,形成奖励向量 。这些奖励通过中心化和缩放转化为优势向量 。策略更新通常通过最大化裁剪的代理目标来实现。在精确的同策略(On-policy)点(即 ),代理目标的梯度退化为标准的序列级基于组的策略梯度:
为了形式化,作者将策略对 个采样响应的相对偏好表示为列表分布(Listwise Distribution):
这里 反映了 相对于 对每个响应的优先级。在同策略点(), 退化为均匀分布 。由于 且 ,向量 位于概率单纯形 上,本文将其称为响应单纯形(Response Simplex)。
2.2 策略梯度等价于近似逆向 KL 投影
基于上述列表分布,作者揭示了一个底层的几何属性:标准的基于组的策略梯度隐式地执行了通过逆向 KL 散度最小化的目标投影。
命题 1(同策略下基于组的策略梯度作为逆向 KL):设 为零均值优势向量(即 ),并令 。在同策略点(),策略梯度等于逆向 KL 散度 的负梯度:
推导简述:
逆向 KL 散度为 。引入 Logit 差距 ,其梯度系数可简化为 ,其中 。在同策略点,,。因此 。由于优势向量零均值假设 ,期望差距 。代入系数得到 。这恰好是标准策略梯度的系数 的相反数。
这一观察将 识别为由优势设计在响应单纯形上诱导的隐式目标(Implicit Target)。这种等价性在同策略点是精确的,但随着策略偏离采样分布,近似误差会增加。具体而言,每个响应的系数差异与 成正比,其中 衡量了异策略(Off-policy)漂移的程度。

表 1 总结了现有算法诱导的具体隐式目标。这些方法中的优势形式为 。由于 Softmax 的平移不变性,中心化项 被抵消,目标 简化为 ,其中 充当温度参数。不同的归一化方案因此保留了相同的奖励排序,主要区别在于目标的平滑度。
3. 列表策略优化 (LPO)
既然目标 和列表分布 都位于有限的响应单纯形上,投影就可以以精确的方式执行。这提供了一个新的算法设计视角:精确投影允许使用任何统计散度(例如正向 KL),而这在当前的策略梯度范式下是无法实现的。
LPO 框架将每次迭代解耦为两个相互关联的步骤:
-
目标(Target):确定要追求什么分布 -
投影(Projection):如何向其优化

3.1 响应单纯形上诱导的目标
为了揭示隐式目标的原则性起源,作者在响应单纯形上定义了一个局部近端强化学习目标,该目标在策略周围的信任区域内最大化期望奖励:
其中 是由更新前策略 诱导的列表分布,且 。
定理 1(列表吉布斯目标):上述目标 具有唯一最大值 :
定理 1 表明,目标 将基线 向高奖励响应重新加权, 控制平滑度。在同策略设置下(), 退化为均匀分布, 恢复了现有方法的隐式目标。此时 是一个具有信任区域解释的显式设计参数,而不再是优势归一化的副产品。
单调提升保证:近端目标 作为列表奖励 的代理,建立了性能提升边界:
定理 2(性能提升边界):假设 。如果投影步骤实现了总变差距离 ,则:
在完美投影()下,只要 ,奖励就会严格提升。
3.2 策略优化的投影
有了单纯形 上的目标 和列表分布 ,策略优化简化为在选定散度下的投影。作者推导了正向和逆向 KL 版本。
示例 1(正向 KL):最小化正向 KL 散度 得到梯度:
系数 衡量了当前策略与目标之间的概率差距。与以往独立处理每个响应的逐点投影(Pointwise Projection)不同,LPO 通过共享归一化在响应单纯形上执行投影,这在响应之间产生了耦合,并带来了以下理想属性:
推论 1(梯度系数属性):正向 KL 梯度系数 满足:
(a) 有界性:;
(b) 零和性:;
(c) 自校正性:当 时,。
零和属性充当了内置的控制变量,用于减少方差。有界和自校正属性进一步提高了优化稳定性。
推论 2(模式覆盖):如果 且 ,则 。这提供了防止模式坍塌的对数屏障,确保了响应的多样性。
示例 2(逆向 KL):最小化逆向 KL 散度 得到梯度:
其中 是当前策略与目标之间的 Logit 差距, 是其 加权均值。与正向 KL 类似,系数 也是零和且自校正的。在同策略点,该目标的梯度精确恢复了标准策略梯度。
4. 实验设置
作者在逻辑、数学、编程和多模态几何四个代表性推理领域评估了 LPO。为了评估通用性,基准测试涵盖了不同模型规模(1.5B–14B)和多个 LLM 家族。
-
逻辑推理:使用 Countdown Game(倒计时游戏),要求使用基本运算组合给定数字以匹配目标值。模型主要使用 Qwen3-4B-Base。 -
数学推理:在 MATH 数据集上训练 Qwen3-1.7B-Base 和 8B-Base。在 AIME、AMC23、MATH500 等标准基准上评估。 -
编程:在 PRIME 代码数据集上训练和评估 Qwen3-1.7B-Base。 -
多模态几何:在 Geometry3k 数据集上训练 Qwen2.5-VL-3B-Instruct。
基线与 LPO 变体:
对比了三种具有不同目标温度设计的代表性基于组的策略梯度(PG)方法:GRPO()、Dr.GRPO()和 MaxRL()。
为了确保严格的控制变量比较,作者为每个基线实现了 LPO 变体( 和 ),它们使用与其对应的 PG 方法完全相同的温度 。配对评估确保了任何性能差异都归因于显式的列表投影,而不是温度调参。
5. 实验结果与分析
5.1 训练性能
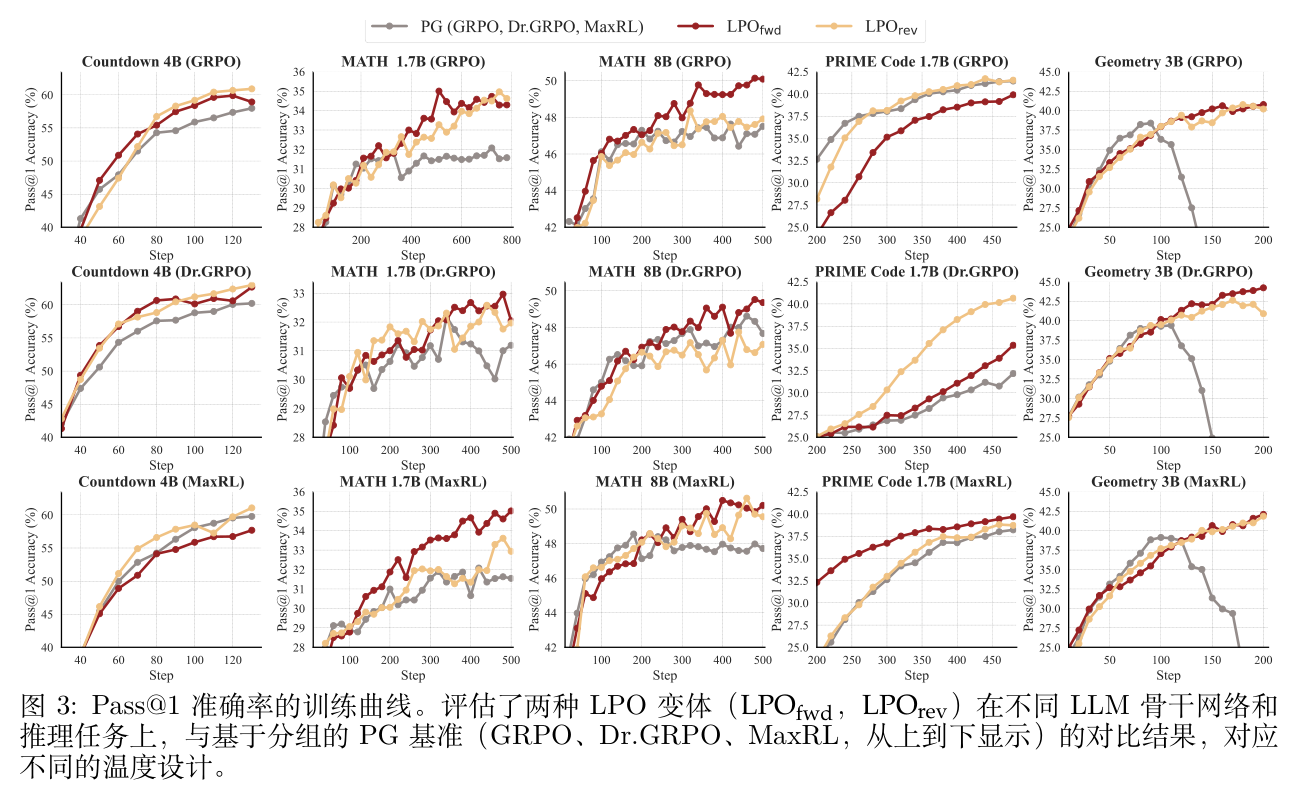
性能提升:在配对的温度配置下,LPO 持续优于基于组的 PG 基线。如图 3 所示的 Pass@1 准确率,两种 LPO 变体在几乎所有设置中( 为 13/15, 为 13/15)都展现出更高且更高效的训练性能。这种优势也延伸到了 Pass@k 评估中。这些一致的收益表明,用响应单纯形上的精确列表投影取代一阶优势近似,是提高 RLVR 训练效率和性能的有效范式。
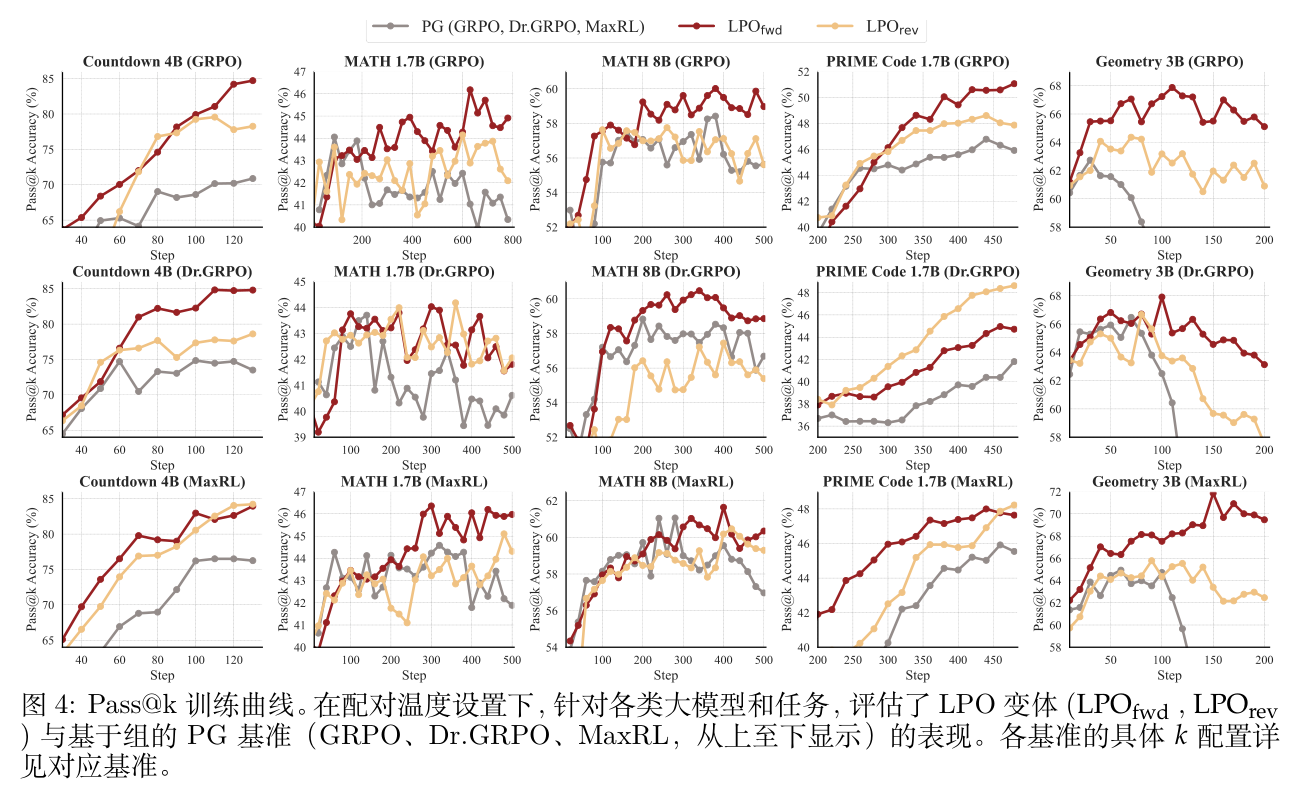
投影散度效应:比较两个变体可以发现一个经验上的区别: 在 13/15 的 Pass@k 场景中优于 。这一观察结果与预期高度一致:正向 KL 固有的模式覆盖(Mode-Coverage)属性主动保留了推理多样性,从而覆盖了更广泛的有效求解路径。
跨温度参数化的鲁棒性:实验观察到,最优的隐式温度策略 高度依赖于任务,没有单一的设计能在所有基准测试中始终占据主导地位。尽管存在这种随任务变化的行为,LPO 在所有测试的 设计下都能提供稳定的性能增益。这表明精确的列表投影提供了一种鲁棒的优化机制,其带来的收益在很大程度上与底层的温度启发式方法正交。
5.2 训练动态与稳定性
为了更好地理解底层的优化行为并验证理论分析,作者跟踪了关键的训练指标:响应熵、梯度范数和响应长度。
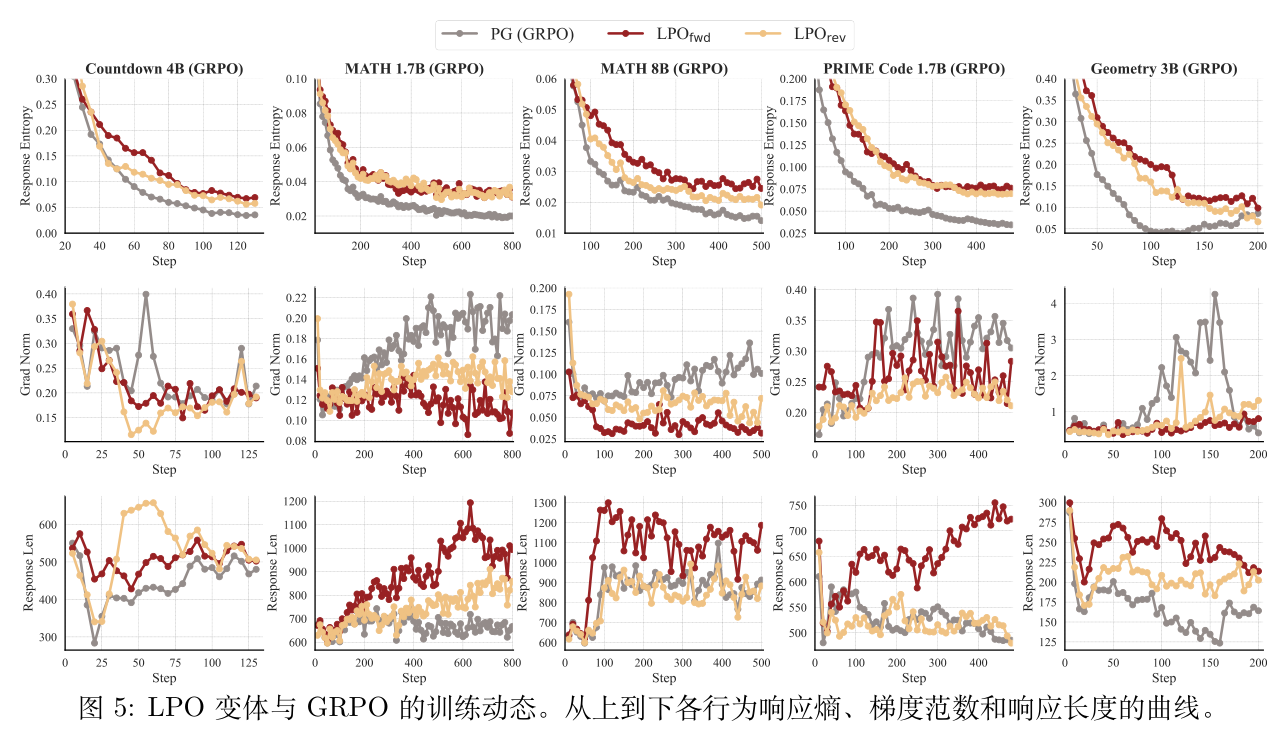
响应熵与探索保留:如图 5(上)所示,两种 LPO 变体通常比 PG 基线保持更高的响应熵。这对应于投影属性: 对应于最大熵目标,而 表现出模式覆盖行为。这种持续的多样性直接解释了 Pass@k 的稳健提升,将列表投影定位为解决 RLVR 中熵坍塌的原则性补救措施。
梯度范数与优化稳定性:图 5(中)显示,与基于组的 PG 方法相比,LPO 变体表现出更低且更稳定的梯度范数。这种经验上的稳定性与推论 1 一致:LPO 在响应单纯形上的精确投影产生了受控的梯度系数,从而导致稳定的优化动态。
响应长度与推理行为:图 5(下)显示 LPO 倾向于生成比 PG 更长的响应。由于长度增加通常与更详细的推理链相关,这与 LPO 鼓励更广泛的探索是一致的。 的最大长度与其促进多样化推理路径的模式覆盖属性相吻合。
5.3 深入分析:列表投影 vs. 逐点投影
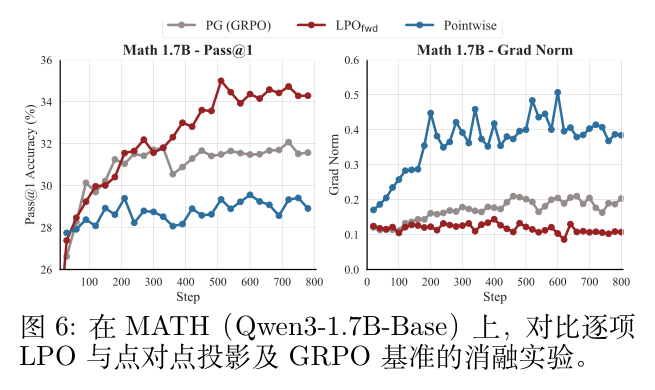
为了突出列表投影的贡献,作者在保持目标分布不变的情况下,消融了列表策略分布,这恢复了逐点投影(Pointwise Projection)(即 )。如图 6 所示,这种逐点变体遭遇了严重的性能下降。这种失败源于逐点更新中缺乏跨响应的耦合竞争机制,导致优化不稳定。相反,基于组的 PG 和 LPO 在本质上都采用了一个内置的控制变量来稳定训练。这表明 LPO 的性能提升不仅仅来自目标设计,而是成功地将精确的目标拟合与列表投影提供的关键结构性方差缩减结合了起来。
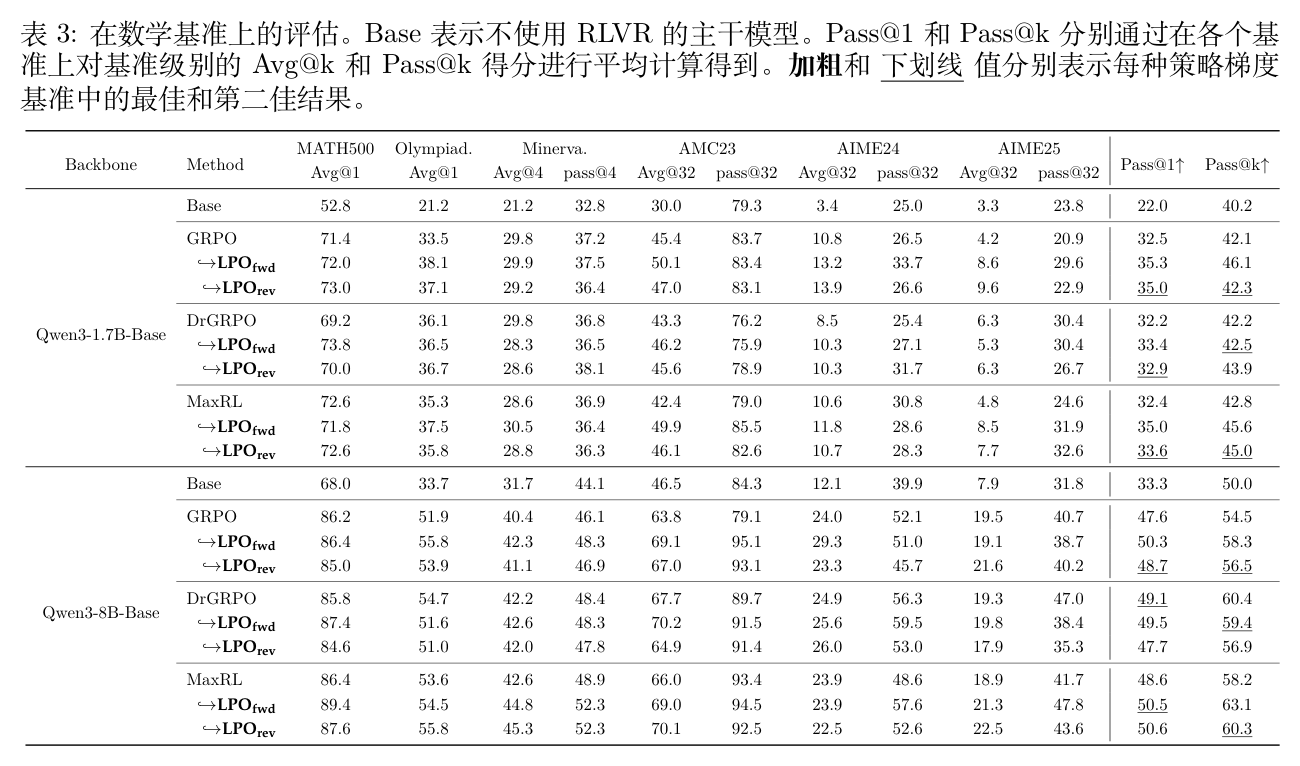
表 3 详细展示了在 MATH 数据集上训练后的各个基准测试结果,可以清晰看到 在 Pass@k 指标上的显著优势。
5.4 扩展性与泛化性验证
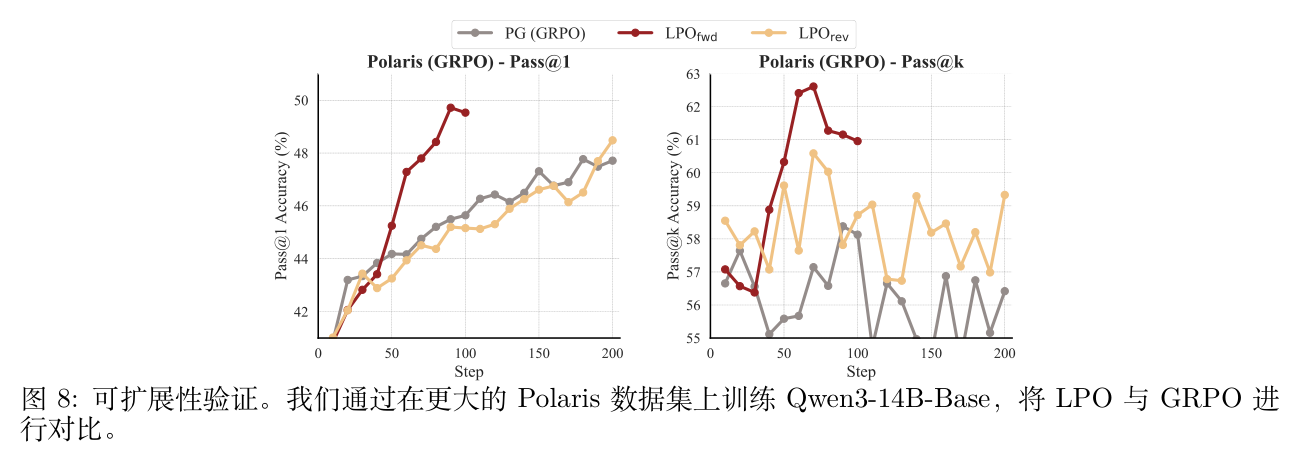
扩展性验证:为了验证 LPO 框架的扩展性,作者在包含约 53k 复杂推理问题的 Polaris 数据集上使用 Qwen3-14B-Base 模型进行了额外实验。如图 8 所示, 展现出卓越的样本效率,仅在 70 步内就达到了 GRPO 在 200 步时达到的峰值性能,同时在 Pass@1 和 Pass@k 指标上都提供了显著的改进。
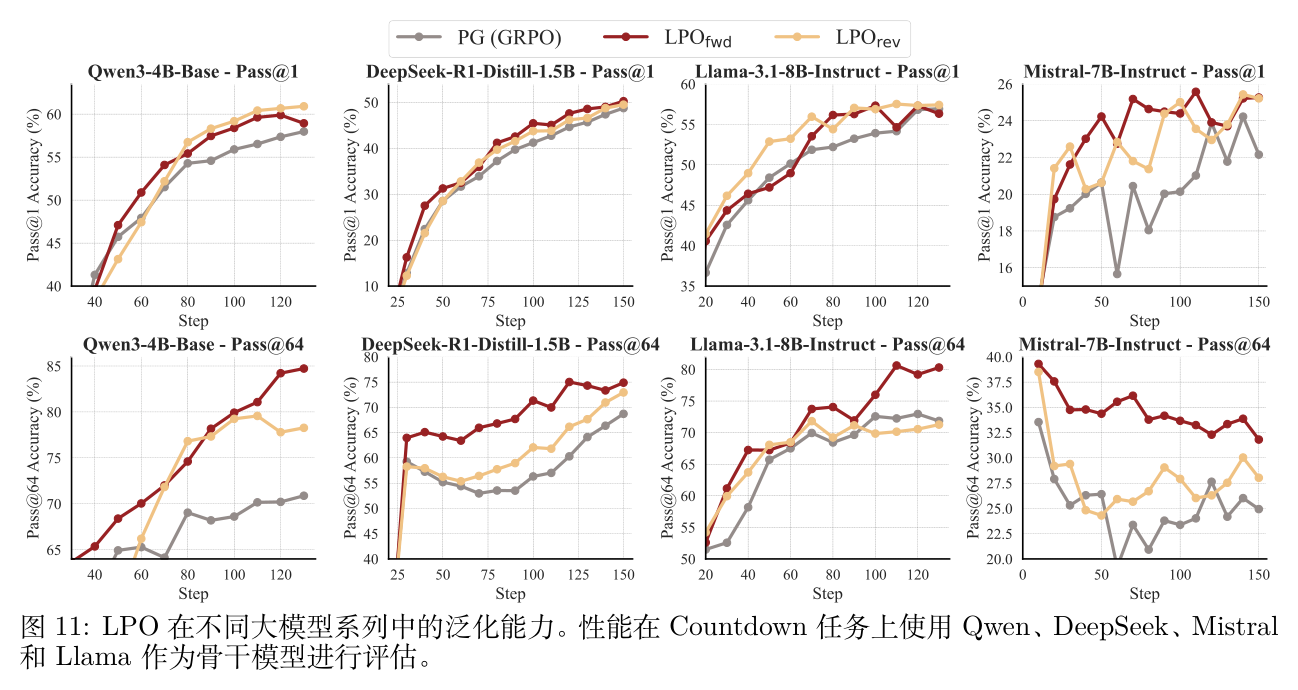
跨 LLM 家族的泛化性:作者在四个著名的 LLM 家族(Qwen, DeepSeek, Mistral, Llama)上进行了实验。如图 11 所示,无论底层的模型架构或训练范式(Base, Distilled, Instruct)如何,LPO 在 Countdown 任务上持续提供性能增益。这表明 LPO 不是对特定模型架构敏感,而是受益于列表投影框架的基础鲁棒性。
6. 讨论与相关工作
与 DPO 及偏好优化的联系:
当 时,LPO 退化为一个与直接偏好优化(DPO)密切相关的成对目标。对于一个奖励为 1 的偏好响应 和一个奖励为 0 的非偏好响应 ,在同策略设置下,正向 KL 目标简化为:
这是一种带有温度控制软目标的二元交叉熵目标。相比之下,DPO 使用成对逻辑目标 。两者共享相同的成对 Sigmoid 结构,但 DPO 运行在静态数据集的离线范式中,且基于 Bradley-Terry 偏好模型推导;而 LPO 是一种在线 RL 算法,其目标源于响应单纯形上的显式散度投影,并使用由 控制的软目标(当 时恢复硬偏好目标)。
扩展与未来方向:
-
步骤级列表投影(Step-level listwise projection):当前框架主要关注序列级奖励。未来可扩展至密集步骤级奖励任务中,通过价值网络或过程奖励模型(PRM)估计期望未来回报,从而在局部响应单纯形上应用 LPO。 -
异策略回放(Off-policy replay):理论上 LPO 可以结合异策略数据以提高样本效率,列表归一化隐式充当了自归一化重要性采样(SNIS)估计器。但在实践中,严重的策略漂移可能会导致概率比极端化,需要开发鲁棒的陈旧度过滤或信任区域缓冲区管理策略。
7. 总结
本文引入了一个统一的几何框架,深入洞察了 LLM 基于组的 RLVR。研究表明,现有的策略梯度方法充当了响应单纯形上的近似目标投影,并提出了 LPO 来显式地执行这种投影。LPO 受益于直接在单纯形上进行优化,这提高了优化稳定性并产生了单调的性能提升。此外,解耦的目标投影视角为开发丰富多样的 LLM RLVR 优化方法打开了灵活的设计空间。
更多细节请阅读原论文。


