让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:Self-Distilled RLVR -
论文链接:https://arxiv.org/pdf/2604.03128
TL;DR
今天解读来自京东的一篇论文《Self-Distilled RLVR》(RLSD)。在大语言模型(LLM)的后训练阶段,基于可验证奖励的强化学习(RLVR,如 GRPO)仅能提供序列级别的稀疏奖励信号,而同策略自蒸馏(OPSD)通过引入特权信息(Privileged Information)生成 Token 级别的密集监督信号。然而,OPSD 存在信息不对称问题,导致特权信息泄露以及训练后期的性能退化。
RLSD 提出将自我蒸馏提取的信号从“优化方向”解耦为“信用分配幅度调节器”,在保持环境奖励决定优化方向的前提下,利用教师模型的密集信号调节每个 Token 的更新幅度。该方法在理论上消除了信息泄露路径,并在多个多模态推理基准测试中展现出较高的准确率与训练稳定性。
1. 背景
大语言模型(LLM)在具备基础生成能力后,通常需要经过后训练(Post-Training)以提升其在复杂推理任务中的表现。当前,基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)成为提升模型推理能力的主要途径。以 GRPO(Group Relative Policy Optimization)为代表的 RLVR 方法通过与环境交互,利用数学问题或代码任务中的确定性正确答案作为环境反馈,对模型进行优化。
然而,RLVR 面临一个固有的信度分配(Credit Assignment)难题:环境只能在模型生成完整序列后提供一个标量奖励(0 或 1)。这意味着在一条包含数百个 Token 的回复中,起决定性作用的推理步骤与毫无意义的格式占位符会获得相同的奖励权重。这种序列级别的稀疏信号限制了模型的收敛速度。
为了提供 Token 级别的细粒度信号,同策略蒸馏(On-Policy Distillation, OPD)被提出。OPD 使用一个更强大的教师模型来评估学生模型生成的轨迹,并提供逐 Token 的对数概率(Logits)作为监督信号。尽管 OPD 能加速收敛,但需要同时维护一个通常体量更大的教师模型,带来了巨大的计算开销。
为降低开销,社区探索了同策略自蒸馏(On-Policy Self-Distillation, OPSD)。在 OPSD 中,单一模型同时充当教师和学生。教师模型通过额外接收“特权信息”(如标准答案或参考推理步骤)来获得超越学生模型的能力,并据此对学生的输出进行评估。
从表面上看,OPSD 结合了高 Token 效率与密集信号。但在实践中,研究人员观察到 OPSD 训练存在明显的缺陷:模型性能在训练初期达到峰值后便开始持续下降。更严重的现象是,模型在推理时(此时无特权信息)会生成类似于“正如参考答案所述”这类文本。这种现象被称为“特权信息泄露”(Privileged Information Leakage)。
本论文的核心贡献在于:
-
从目标函数与梯度结构两个层面,对 OPSD 的失败原因进行了理论层面的严格证明,指出信息不对称会导致不可约减的互信息差距,进而引发泄露。 -
提出了 RLSD(RLVR with Self-Distillation)框架,改变了教师信号的使用方式——从“分布匹配的生成目标”转变为“策略梯度中的幅度评估器”。 -
在理论上证明了 RLSD 具备零泄露保证,并在多模态推理基准上进行了验证。
2. 预备知识与数学定义
在深入探讨之前,我们需要对现有范式的数学形式进行定义。
2.1 GRPO (Group Relative Policy Optimization)
设语言模型为 ,输入问题为 ,模型自回归地生成回复 。在 RLVR 设定中,验证器提供一个二元奖励 ,指示回复是否正确。
GRPO 针对问题 从当前策略中采样一组共 个回复 ,并计算组内相对优势(Advantage):
其中, 和 分别是该组回复奖励的均值和标准差。策略更新通过截断代理目标函数实现:
其中 是当前策略与旧策略之间的重要性采样比率。
GRPO 的局限性在于:同一个回复序列中的所有 Token 均共享同一个标量优势 ,缺乏对 Token 贡献度的区分。
2.2 OPD 与 OPSD
同策略蒸馏(OPD)旨在解决奖励稀疏问题。给定数据集 ,学生模型生成同策略轨迹 ,训练目标是最小化教师与学生在各个 Token 位置上的散度。
在不同的设定中,学生和教师的定义如下:
学生模型:
OPD 教师模型(外部更大模型):
OPSD 教师模型(同一模型,引入特权信息 ):
共享的训练目标函数为:
其中 是散度度量(如广义 Jensen-Shannon 散度或反向 KL 散度)。在优化过程中,只有 产生梯度反向传播,而 仅作为固定的目标。
3. 为什么 OPD 有效而 OPSD 失败?
OPSD 通过引入特权信息 (如正确推理路径)消除了对外部模型的依赖,但其经验表现并不理想。
3.1 经验观察:泄露与性能退化
研究人员观察到,采用 OPSD 训练的模型会系统性地引用推理时不可见的特权信息。

性能监控显示,随着训练步数的增加,特权信息泄露的发生频率单调上升。同时,验证集准确率在最初的 10 至 20 步达到顶峰后开始下降(如图 3 所示)。
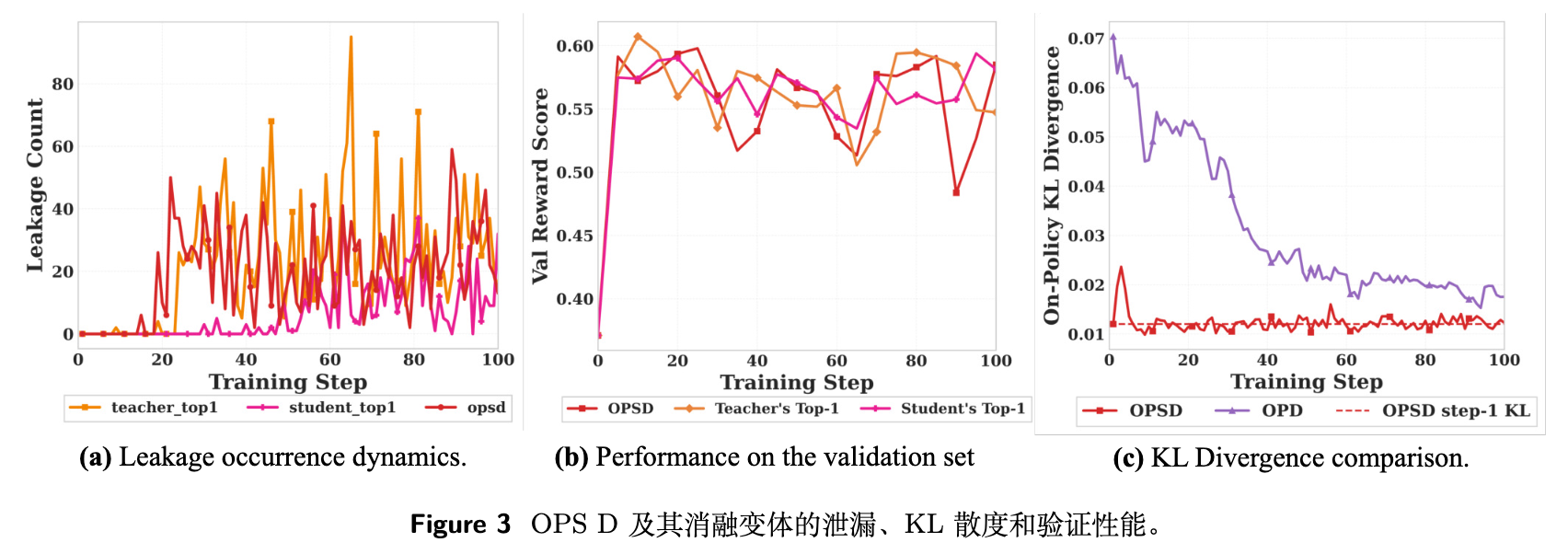
更深层次的诊断对比了 OPD 和 OPSD 训练中教师与学生之间的同策略 KL 散度:在 OPD 下,KL 散度稳步下降,表明学生模型确实在逼近教师模型;而在 OPSD 下,散度在初期短暂下降后便陷入停滞,维持在一个固定水平。这种停滞表明 OPSD 的目标函数中存在一个不可消除的理论鸿沟。
3.2 OPSD 的失败机理:适得其反的优化目标
上述现象源于 OPD 与 OPSD 在结构上的本质差异。在 OPD 中,教师和学生观察到相同的输入(信息对称);而在 OPSD 中,教师观察到了学生无法获取的特权信息 (信息不对称)。
3.2.1 不可约减的互信息差距(Theorem 1)
令 表示特权信息,服从条件分布 。由于一个问题可以有多种语义上合理的推理路径, 包含非零熵。从学生模型的认知角度看, 是一个不可见的潜在变量。
如果学生模型不能直接以 为条件,最优的学生策略应该通过全概率公式恢复教师的边缘分布(Marginal Distribution):
令 表示该边缘分布,理想的蒸馏目标应当是:
然而,当前的 OPSD 目标强行要求对每一个具体的 对进行样本级别的匹配:
这要求一个条件独立的参数化模型( 不输入 )去匹配一个条件依赖的目标( 依赖于 )。这构成了数学上适得其反的要求。论文中给出了 定理 1(KL 散度分解):
此处的 表示在教师分布下,当前 Token 与特权信息 之间的条件互信息。
定理证明解析:
展开 :
在对数项中引入 并分离各项:
第一项正是条件互信息 。对于第二项,由于 不依赖于 ,针对 的期望仅作用于 :
两者相加即得定理结果。
这一互信息项取决于教师模型的条件分布和 ,它完全独立于参数 。因此,学生模型在优化过程中永远无法消除这一间隙。当学生模型达到理论最优点 时,残余损失等于互信息,这是一个严格为正的下界。这解释了为何 KL 散度会在初期下降后发生停滞。更严峻的是,优化器在偏置目标的驱动下,会持续接收非零的损失信号,进而将有害的噪声吸收到模型参数中。
3.2.2 梯度结构:泄漏的发生机制(Proposition 1)
尽管互信息 独立于 ,表明它对期望梯度没有影响,但在实际优化中,我们使用的是具体样本 计算出的单样本梯度。
良性的期望梯度为:
而在实际操作中,具体的单样本梯度为:
命题 1(单样本梯度分解): 对于任意具体的 ,单样本梯度可以分解为:
该分解满足两个性质:
动态演变过程:
上述分解将梯度划分为有益部分 和偏差部分 。它们的相对大小导致了训练过程的两个阶段:
-
早期阶段:学生分布 距离边缘分布 较远,有益梯度占据主导()。模型迅速学习一般的推理能力,表现为准确率的陡峭上升。 -
后期阶段:随着 逼近 ,有益梯度 趋近于零。然而,偏差成分的方差受互信息控制,不随优化进度衰减。参数更新被 主导。由于诸如 Adam 等优化器具有路径依赖性,这些均值为零的扰动并不会在非线性优化中相互抵消。路径依赖导致模型参数编码了 的伪相关性,这是产生信息泄漏的直接数学源头。
3.2.3 泄漏带宽(Leakage Bandwidth)与消融实验
为了验证梯度结构推论,研究者设计了消融实验,改变教师信号进入梯度的范围(即“泄漏带宽”):
-
Full OPSD:使用全词表,带宽最宽。 -
Teacher's Top-1:仅保留教师概率最大的 Token,带宽变窄但包含了高浓度的特权信号。 -
Student's Top-1:将目标限制在学生预测的最大概率 Token,带宽最窄。
实验表明,无论如何压缩目标分布,只要特权评估 参与决定梯度方向,泄漏现象就普遍存在。Teacher's Top-1 表现出最严重的泄漏,而 Student's Top-1 的泄漏率相对较低,但依然无法避免。
4. 深入理解共享参数下的不可能性三难困境
除了单步梯度级别的病态问题外,OPSD 中教师与学生共享同一组参数 的设定引发了宏观级别的训练不稳定性。
在每一步优化中,虽然 使用停止梯度(stop-gradient),但 的更新会同时改变教师和学生的分布。这种参数耦合导致了所谓的不可能性三难困境(Impossibility Trilemma)。
4.1 策略 A:冻结教师模型
如果我们在初始化时固定教师模型参数 ,优化目标变为匹配一个静态目标。根据定理 1,最优点是 的边缘分布。
命题 2(能力上限):当 时,蒸馏信号消失。学生模型的表征能力被严格限制在初始检查点 的水平,即使模型具备学习更好策略的能力也无法进一步提升。
4.2 策略 B:在线教师模型
如果教师与学生同步演化,即每一步 使用 引导学生:
定理 2(在线教师的训练不稳定性):定义联合目标函数 。从第 步到 步的变化分解为:
其中 反映了学生在固定目标下的改善;而 反映了教师的漂移,其符号是不受控的。当 且绝对值大于 时,即使代理目标下降,真实目标函数却在恶化。
4.3 自我强化反馈循环
更严重的是梯度泄漏与教师漂移形成的闭环:
-
样本偏差 驱动参数编码预测 的特征。 -
这些特征被编码入共享参数 中,提升了模型作为教师时利用 的能力。 -
这导致下一时刻模型对特权信息的敏感度上升,互信息增加。 -
互信息增加导致偏差 的方差进一步扩大,加强了步骤 1 的发生。
定理 3(不可能性三难困境):在任何教师与学生共享参数的分布匹配框架中,以下三个属性无法同时满足:
-
(a) 目标稳定性:优化目标在连续步骤之间不漂移()。 -
(b) 持续改进:蒸馏信号不消失()。 -
(c) 无泄漏训练:偏差成分不驱动参数漂移。
采用策略 A 满足 (a) 但违反 (b)。采用策略 B 满足 (b) 但违反 (a) 和 (c)。采用混合策略(如定期更新教师)仅仅是在这些缺陷之间折中。
5. RLSD:将自我蒸馏作为 RLVR 的辅助
既然分布匹配范式在特权信号下必然失败,那么应该如何使用教师模型?论文观察到,证据比率 同样衡量了特权信息修正模型信念的程度。关键在于改变其使用方式。
在优化中,“更新方向”和“更新幅度”具有不对称的要求:方向信号可以稀疏,但必须可靠(错误的方向会破坏策略);幅度信号需要尽可能密集,以实现细粒度的区分。
据此,论文提出了 RLSD (RLVR with Self-Distillation) 。其核心思想是:保留环境奖励决定每个 Token 的更新方向,将教师的信号作为幅度调节器(Magnitude Evaluator),仅用于调整更新的相对大小。
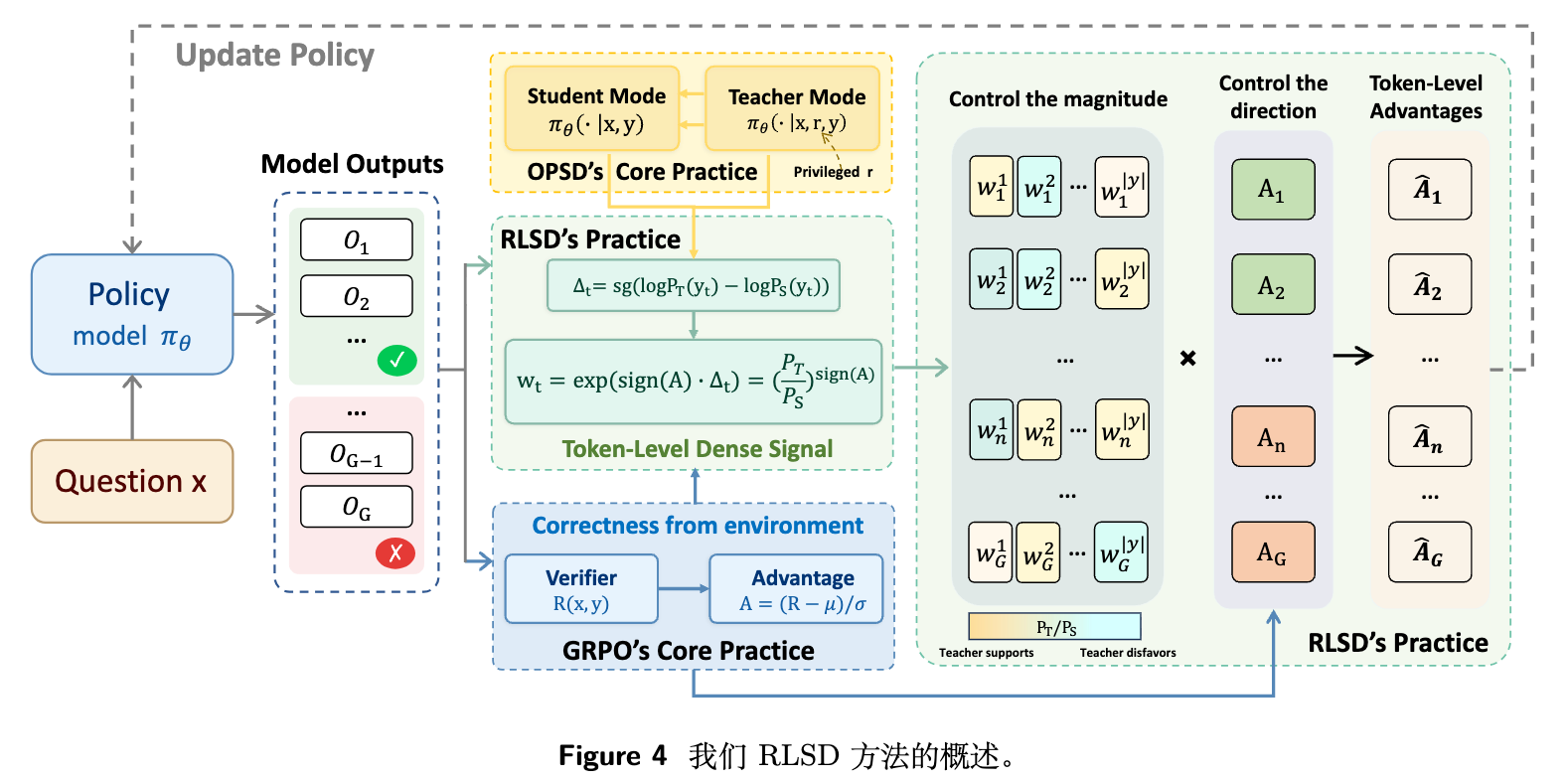
5.1 从分布匹配到信用分配
RLSD 将这一思想实例化为三个步骤:
第一步:特权信息增益(Privileged Information Gain)
给定学生生成的轨迹 ,计算每个 Token 在学生上下文(仅输入 )和教师上下文(输入 和 )下的对数概率。定义每个位置的特权信息增益:
这里 表示停止梯度操作。 隔离了特权信息对 预测的边际贡献。较大的正值表明 强烈支持该 Token,负值表明 不倾向于该 Token。这提供了一个天然的细粒度信用分配基础。
第二步:方向感知的证据重加权(Direction-aware Evidence Reweighting)
利用序列级优势函数的符号调制特权信息增益,构建逐 Token 的权重:
-
当序列答案正确()时,。特权信息支持的 Token 会获得大于 1 的权重,获得了更多的正面奖励; -
当序列答案错误()时,比率翻转 。特权信息不看好的 Token 将承担主要责任(惩罚加剧),而受特权信息支持的 Token 受到较小的惩罚。
由于指数函数恒正,该权重仅调节大小,绝对不会翻转优势信号的原始符号。环境奖励维持对更新方向的完全控制权。
第三步:截断的信用分配(Clipped Credit Assignment)
为防止单个 Token 权重过大导致训练不稳定,引入截断机制约束证据权重:
该机制充当信任域约束,类似于 PPO 和 GRPO 中的重要性比率截断。
5.2 与 GRPO 的无缝集成
修改后的优势函数 可作为标准 GRPO 目标中统一标量优势的直接替代品,无需引入额外的蒸馏损失项。计算仅需要每条回复多进行一次前向传播以获取教师 Logits。
实际应用中,采用退火混合系数 平滑过渡。完整的 RLSD 目标函数为:
算法流程总结:
对于每个训练迭代中的问题 及其特权信息 :
-
模型进行同策略采样,生成 个回复。 -
验证器根据答案正确性给出 0/1 奖励,计算 GRPO 的组内相对优势 。 -
输入 获取教师 Logits,计算每个 Token 的增益 。 -
计算修正后的逐 Token 优势函数 。 -
采用标准的策略梯度更新模型参数 。
5.3 统一的 Token 级别优势函数视角
GRPO、OPSD 和 RLSD 可统一在一个策略梯度模板下:
它们的区别仅在于如何定义 :
-
GRPO:。方向可靠但缺乏区分度。 -
OPSD:。缺乏环境奖励反馈,优化方向脱离正确性验证,导致信息泄漏。 -
RLSD:结合环境符号判定方向,结合教师判定大小,实现了优势互补。
6. RLSD 的贝叶斯解释与理论保证
RLSD 的设计不仅直观,而且在数学层面拥有清晰的物理意义与严格的边界保证。
6.1 贝叶斯信念更新视角
假设模型具有足够的容量,使得 与 能分别近似无 条件和有 条件下的真实预测分布(定理 4):
此处的推导利用了贝叶斯公式。 本质上代表了序列贝叶斯信念更新率。它量化了“生成当前 Token 在多大程度上增加了观测到正确特权信息 的后验概率”。
说明当前生成的 Token 提供了趋向正确答案的正面证据; 说明当前 Token 削弱了推导出正确答案的概率; 说明该 Token(如格式连接词)是信息中性的。
RLSD 实现了逻辑归因(Logical Attribution),而不是 OPSD 所作的行为克隆(Behavioral Cloning)。RLSD 并不强迫学生模型采用教师的特定措辞结构,只要学生生成的 Token 能增加得出正确答案的贝叶斯后验概率,就能获得更高的奖励权重。
6.2 零泄漏保证与解决三难困境
定理 5(RLSD 的零泄漏保证): 在 RLSD 的策略梯度计算中,特权信息 仅通过停止梯度的标量 进入,并在三个层面上被严格隔离:
-
方向隔离:由于 , 无法影响梯度的符号。 -
支撑集隔离:梯度期望仅在学生自采样的轨迹(没有访问 )上计算。任何只在特权模式下出现的偏好 Token 无法进入梯度计算范围。 -
幅度有界: 受到截断函数与衰减系数 的严格约束。当 时,,RLSD 自然退化为标准的 GRPO。
通过这重重隔离,特权信息模式无法被注入到参数更新的几何方向中。由于 RLSD 完全摒弃了分布匹配,三难困境中的偏差方差反馈回路被彻底打破。RLSD 满足环境作为固定优化锚点(目标稳定性),通过退火混合保证了长期的持续改进,并确保了无泄漏训练。
7. 实验评估
7.1 实验设置
训练数据:模型在 MMFineReason-123K 数据集上进行训练,这是一个经过难度过滤的多模态推理语料库,筛选排除了模型容易解答的问题,专注于高难度推理场景。
基准测试:评测包含了 MMMU、MathVista、MathVision、ZeroBench 和 WeMath,涵盖了复杂的大学水平学科、数学推理以及专门设计用于对抗当前前沿模型的高难度压力测试。
基线方法:
-
Base LLM:未经后训练的 Qwen3-VL-8B-Instruct。 -
GRPO:标准的序列级强化学习基线。 -
OPSD:单一模型自蒸馏基线。 -
SDPO:扩展自我蒸馏到结合丰富反馈的强化学习中。 -
GRPO+OPSD:线性插值的混合基线。
7.2 核心结果
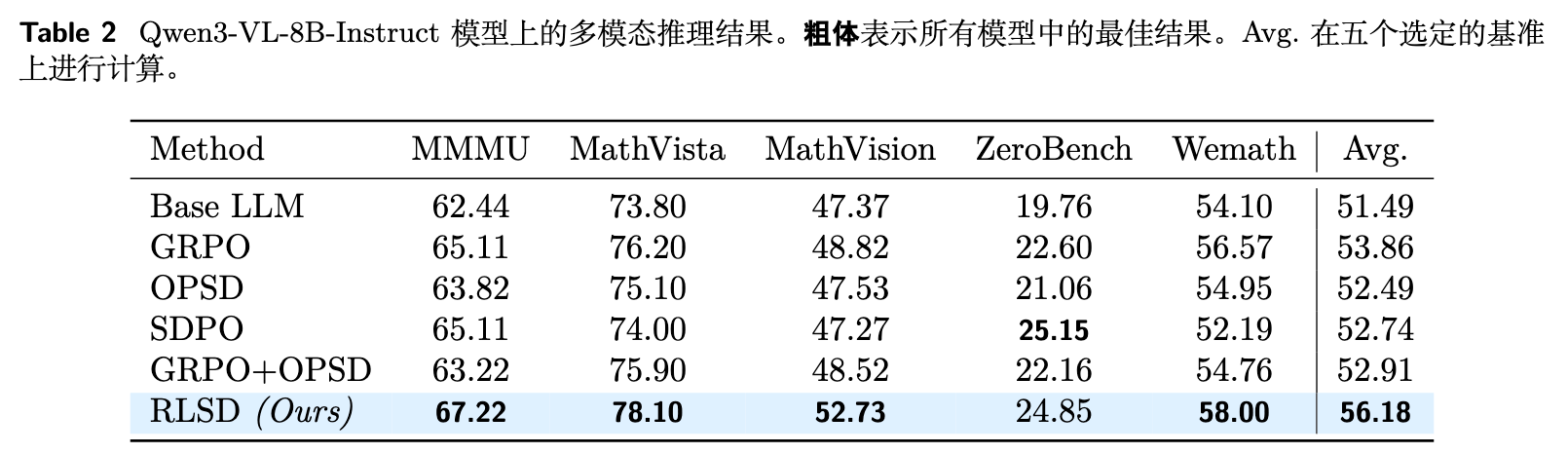
表 2 展示了详细数据。
RLSD 在各项多模态基准测试中达到了较高的平均准确率。相较于仅使用 GRPO,RLSD 表现出显著的性能提升,尤其是在 MathVista 和 MathVision 等对细粒度推理步骤要求较高的数学测试集中。与 OPSD 和 SDPO 等自蒸馏基线相比,RLSD 避免了特权信息的泄漏与退化,展现出了更为鲁棒的推理性能。
7.3 训练动态与案例分析
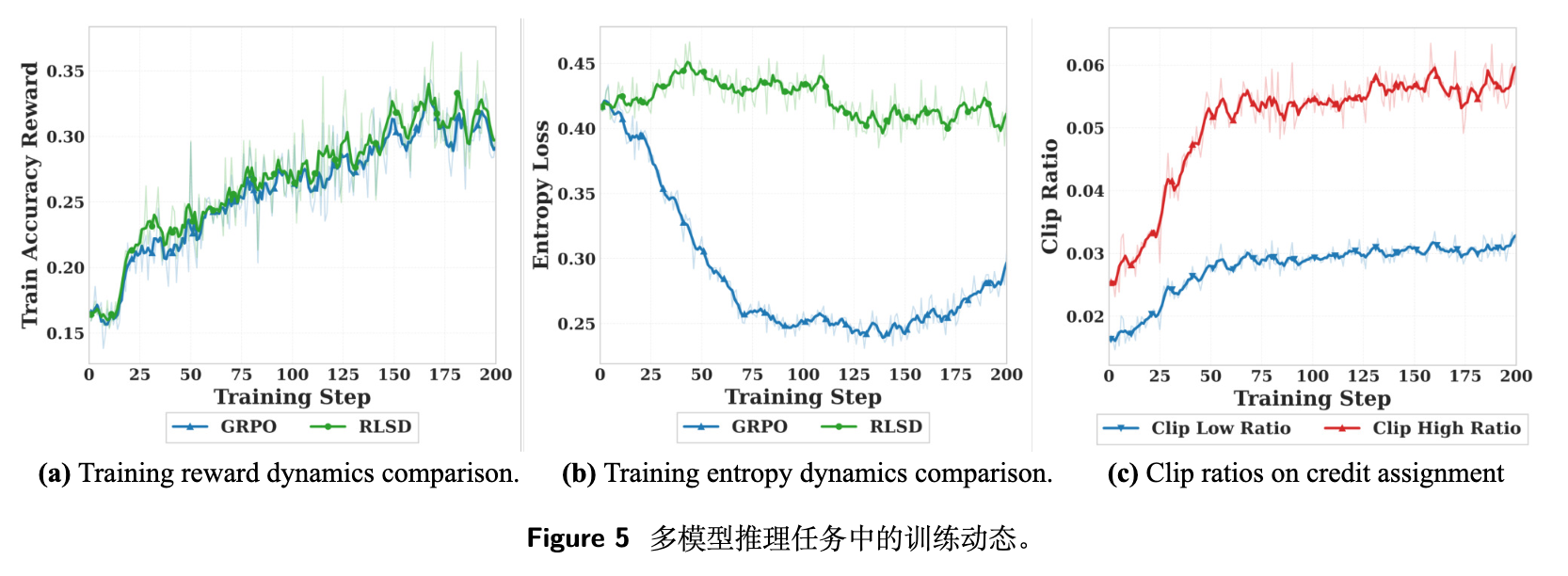
通过监控长达 200 个优化步数的动态变化,观察到:
-
奖励动态:RLSD 在初期展现出比 GRPO 更陡峭的上升趋势,并最终收敛到了更高的奖励上限。相比之下,OPSD 会在训练后期遭遇性能崩溃。 -
熵的变化:由于 GRPO 的序列级同质化惩罚,模型的生成熵坍塌得较快。而 RLSD 通过精确选择性地增强关键推理 Token,避免了所有位置的无差别抑制,从而维持了更健康的熵水平,有助于更好的探索。 -
截断机制:截断比例稳定在 3% 到 6% 之间,表明教师的 Token 级影响被有效约束在了合理的信任域中。

案例研究直观展示了 RLSD 的信用重分配机制:
-
在一个预测正确的立方体计数任务中,RLSD 赋予了关键识别操作和最终减法步骤最大的奖励权重,而弱化了“看图可知”这类模版化表述的权重。 -
在一个预测错误的条形图关系任务中,模型受到了序列级惩罚(负反馈),RLSD 精准地将最严重的惩罚指向了读取错误方程的一步,而不是平均分摊给所有的中间词元。
更多细节请阅读原文。
往期文章:


