
-
论文标题:Adam’s Law: Textual Frequency Law on Large Language Models -
论文链接:https://arxiv.org/pdf/2604.02176
TL;DR
今天解读来自 FaceMind 的一篇论文《Adam’s Law: Textual Frequency Law on Large Language Models》。该论文提出并探讨了“文本频率定律”(Textual Frequency Law, TFL),即在保持语义不变(互为复述)的前提下,大型语言模型(LLMs)在提示(Prompting)和微调(Fine-tuning)阶段应优先使用句子级别频率较高的文本数据。
为解决闭源模型训练数据不可见的问题,作者提出了“文本频率蒸馏”(Textual Frequency Distillation, TFD)方法来优化频率估计,并进一步提出“课程文本频率训练”(Curriculum Textual Frequency Training, CTFT),让模型按频率从低到高的顺序进行微调。作者构建了专属数据集 TFPD,在数学推理、机器翻译、常识推理和工具调用等任务上进行了验证。附录提供了基于 Zipf 定律的理论证明,从数学角度解释了高频文本导致更低负对数似然损失的原因。
1. 引言
大型语言模型(LLMs)展现了众多的能力,包括思维链推理(Chain-of-thought)、机器翻译和空间推理等。当前研究主要集中在模型参数规模扩展、增加推理过程的长度等方向。在数据层面,数据量和数据质量是通常被关注的焦点。在模型训练顺序方面,基于数据难度(从易到难)或数据长度(从短到长)的课程学习(Curriculum Learning)已有较多探讨。
然而,在语义保持不变的情况下,“应优先使用何种特征的文本数据”是一个相对被忽视的研究话题。先前的自然语言处理(NLP)研究中,复述(Paraphrasing)常用于缓解数据污染、评估生成任务和数据增强。研究表明,输入具有相同含义但表达不同的提示词,大模型给出的结果质量存在差异。同时,认知科学领域的研究指出,文本频率与人类阅读速度和神经激活程度相关联。
基于上述背景,本文作者提出了一个明确的研究方向:研究文本数据频率对大语言模型的影响,并提出“文本频率定律”(Textual Frequency Law, TFL)。
2. 认知科学与文本频率的先验研究
理解这篇论文的动机,需要回顾文本频率在人类认知和早期人工智能研究中的作用。
-
神经激活与阅读理解:Desai 等人(2020)和 Alexandrov 等人(2011)的研究表明,在阅读任务中,高频词汇和低频词汇会引起不同的神经激活模式,高频词汇通常会引发更强的神经反应。 -
语义检索与相似度:Heylen 等人(2008)发现,高频目标词与其最近邻词具有更高的语义相似度,这表明词频影响语义关系的检索。 -
语言模型的词频偏好:Oh 等人(2024)观察到参数量较大的模型在预测罕见词(低频词)时表现更好。这侧面表明,预测低频词项比预测高频词项是一项难度更高的任务。
结合上述观察,作者假设:由于高频数据在预训练阶段出现的次数多于低频数据,大模型更容易理解高频文本。因此,当我们需要模型执行特定任务时,将输入转化为高频表达,或者在微调时使用高频表达,理论上能够降低模型的处理难度。
3. 任务定义与公式化
大语言模型通常可以被视为一个序列到序列(Seq2Seq)的神经网络。模型通过最大化以下似然函数来遵循指令处理输入并执行任务:
其中:
-
表示生成输出的长度。 -
表示在位置 推理出的词。 -
表示引导 LLMs 处理输入的指令(Instruction)。 -
表示源句子(Source sentences)。
根据具体任务,输入的格式会有所不同。在数学推理任务中,指令本身通常包含了具体问题,因此可以视作没有单独的 。而在机器翻译(MT)任务中, 通常是要求模型将源句子 翻译成目标语言的指令。为简化后续推导,本文将指令和实际输入的拼接统一记作 。
4. 核心方法论:频率定律、蒸馏与课程训练
本框架由三个核心单元组成:文本频率定律(TFL)、文本频率蒸馏(TFD)和课程文本频率训练(CTFT)。
4.1 文本频率定律 (Textual Frequency Law, TFL)
TFL 的核心主张是:无论是进行提示(Prompting)还是微调(Fine-tuning),在备选的复述集合中,应当选择句子级别文本频率最高的那一个。
其中, 对应文本输入, 代表包含相同含义的复述文本集合(Paraphrases), 表示评估句子级别文本频率的函数, 是用于统计频率的语料库。
作者提出,无需获取 LLMs 实际的预训练数据,可以使用任意的大型开源文本语料库来估算该频率。句子级别的频率是通过词级别频率的逆归一化乘积来估算的(忽略位置信息):
其中 是用于估计句子级频率的词级频率计算器, 为句子中的单词总数。使用几何平均的形式是为了消除句子长度对频率计算的绝对影响,确保不同长度的复述文本可以在同一尺度下比较。
-
Prompting 应用:在向 LLMs 输入提示时,应优先使用计算出的 更高的 。 -
Fine-tuning 应用:在微调时,应使用较高频率的 与对应的真实标签 组合作为训练数据。
4.2 文本频率蒸馏 (Textual Frequency Distillation, TFD)
上述公式中的频率基于外部在线资源估算。然而,多数先进的 LLMs 的训练数据是闭源的,外部语料的词频分布与模型内部学到的特征分布可能存在偏差。为修正这种偏差,作者提出了文本频率蒸馏(TFD)。
TFD 的做法是让目标 LLMs 进行“故事补全(Story Completion)”任务。给定指令如下:
Please conduct story completion on the following data:
其中 <textual data> 代表训练集中的数据。将模型生成的补全数据记为蒸馏数据集 。基于该生成数据,可以获得一个新的频率估计:
我们将原始的外部语料频率估计记为 。最终的频率计算公式 将二者结合:
其中 、 和 为超参数。 是指示函数,当原语料库中某些词频为 0 时(即未登录词或极其罕见词), 作为强化因子,用于放大蒸馏频率的作用。计算得到的 用于替代公式 2 和公式 3 中的原始频率,以此筛选最高频的复述文本。这一步骤需要调用大模型生成文本,计算成本相对较高,属于可选步骤。
4.3 课程文本频率训练 (Curriculum Textual Frequency Training, CTFT)
低频表达通常具有更高的多样性。参考课程学习(Curriculum Learning)的先例,通常主张先让模型学习简单的、多样性高的模式。作者提出了 CTFT,在微调阶段,将训练集 (包含 个实例)按句子级频率从低到高进行排序训练。对于每个 Epoch,训练顺序由下式决定:
其中 是排序函数,将样本 按 的升序排列。在此场景中,训练实例为常规的机器学习数据集,不必须互为复述对。
5. 数据集构建:TFPD
由于当前缺乏针对此类研究的现成数据集,作者构建了“文本频率配对数据集”(Textual Frequency Paired Dataset, TFPD)。
作者选取了 GSM8K(数学推理)、FLORES-200(机器翻译)和 CommonsenseQA(常识推理)作为原始数据来源。使用 GPT-4o-mini 对英文句子进行复述生成。为了引导模型生成不同频率的复述,设定的 Prompt 要求模型必须生成两类句子:
-
10 个使用较少见、更复杂词汇的句子。 -
10 个使用更常见、更简单词汇的句子。
生成 20 个句子后,使用公式 1 选出频率最低和频率最高的两个句子。为防止复述过程中发生语义偏移(Semantic Drift),作者聘请了三位具备英语语言学相关学位的人类标注员进行人工验证。标注员判断原始句子与两句复述是否保持相同含义(分为“相同”、“可能相同”、“不相同”三档)。只有三位标注员均确信含义完全相同(The same meaning)的样本才会被保留。
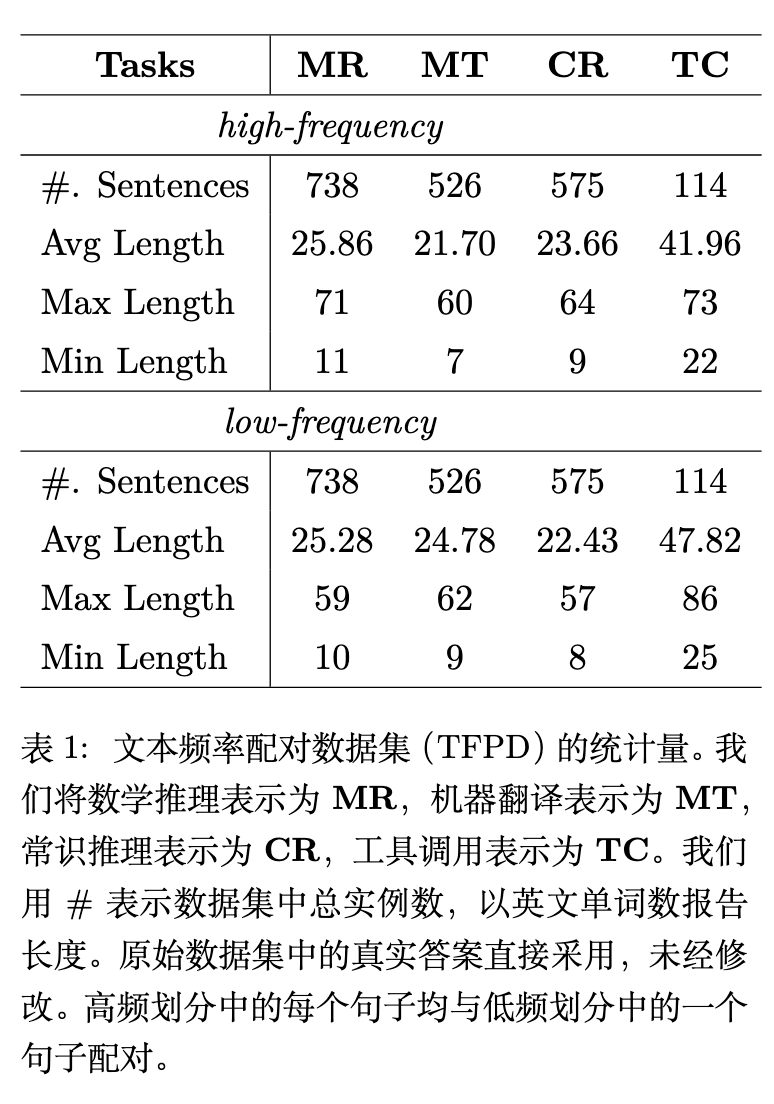
表格展示了最终筛选出的数据统计情况。数学推理(MR)保留了 738 对,机器翻译(MT)保留了 526 对,常识推理(CR)保留了 575 对,工具调用(TC)保留了 114 对。高频(high-frequency)与低频(low-frequency)部分在句子数量上对齐,表中列出了平均长度、最大长度和最小长度等信息。所有原始数据集中的 Ground-truth 答案未作修改直接沿用。
6. 实验设置
6.1 评估指标
-
数学推理 (MR): 使用准确率(Accuracy)。 -
机器翻译 (MT): 采用 sacreBLEU 提供的 chrF 和 BLEU 分数。此外,还使用了基于神经网络的 COMET 指标(wmt22-comet-da 模型)。该模型支持本文 100 种语言中的 37 种。 -
常识推理 (CR) 和 工具调用 (TC): 使用准确率。
6.2 基座模型与对比基线
为了保证实验的可复现性,实验覆盖了闭源模型和开源模型:
-
闭源模型: GPT-4o-mini 和 DeepSeek-V3(671B 参数的 MoE 模型),两者在多语言翻译方面具备能力。对于翻译实验,还添加了 doubao-1.5-pro-32k。 -
开源模型: Llama-3.3-70B-Instruct(用于数学推理实验)和 qwen2.5-7b-instruct(用于机器翻译和微调实验)。
微调实验全局使用 LoRA(Low-Rank Adaptation)。在评估 CTFT 时,对比了反向设置(从高频到低频)以及传统的课程学习(从易到难)。在“从易到难”的基线中,难度函数定义为句子的“最大依赖树深度”(Max Dependency Tree Depth)。
6.3 频率估计资源与语言选择
外部频率估计采用 Zipf frequency 资源(基于 wordfreq 库和 ParaCrawl 等项目)。
在机器翻译的 Prompting 实验中,从 FLORES-200 数据集中随机选取了 100 种语言。根据相关定义,其中一半以上的语言属于相对低资源语言(Class 0 或 Class 1)。在 CTFT 微调实验中,使用了四种语言:Kabuverdianu (kea_Latn)、Kikuyu (kik_Latn)、Pangasinan (pag_Latn) 和 Standard Latvian (lvs_Latn)。
7. 实验结果与分析:Prompting 提示阶段
7.1 数学推理
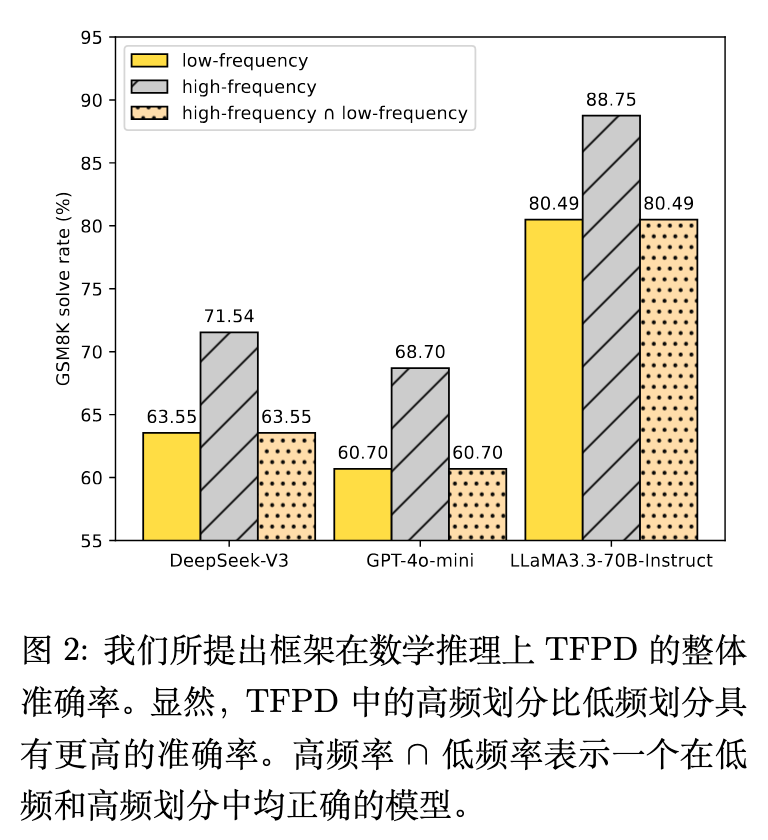
图 2 展示了模型在数学推理任务上的整体准确率。结果表明:
-
在 DeepSeek-V3 上,高频部分的准确率为 71.54%,低频部分为 63.55%。 -
在 GPT-4o-mini 上,高频部分为 68.70%,低频部分为 60.70%。 -
在 LLaMA3.3-70B-Instruct 上,高频部分为 88.75%,低频部分为 80.49%。
进一步的交集分析显示,如果一个样本的低频版本能够被模型正确回答,那么其高频版本依然能够被正确回答。换句话说,使用高频复述输入,能够纠正那些在低频输入下原本被回答错误的样本,而原本回答正确的样本不会因为切换到高频输入而发生性能下降。附录表明,这种增益在参数规模从 0.5B 到 72B 的各个 Qwen-2.5 模型变体中均有效。对于原因,分析指出高频输入改善了模型的思维链(Chain-of-Thought)过程。
7.2 机器翻译
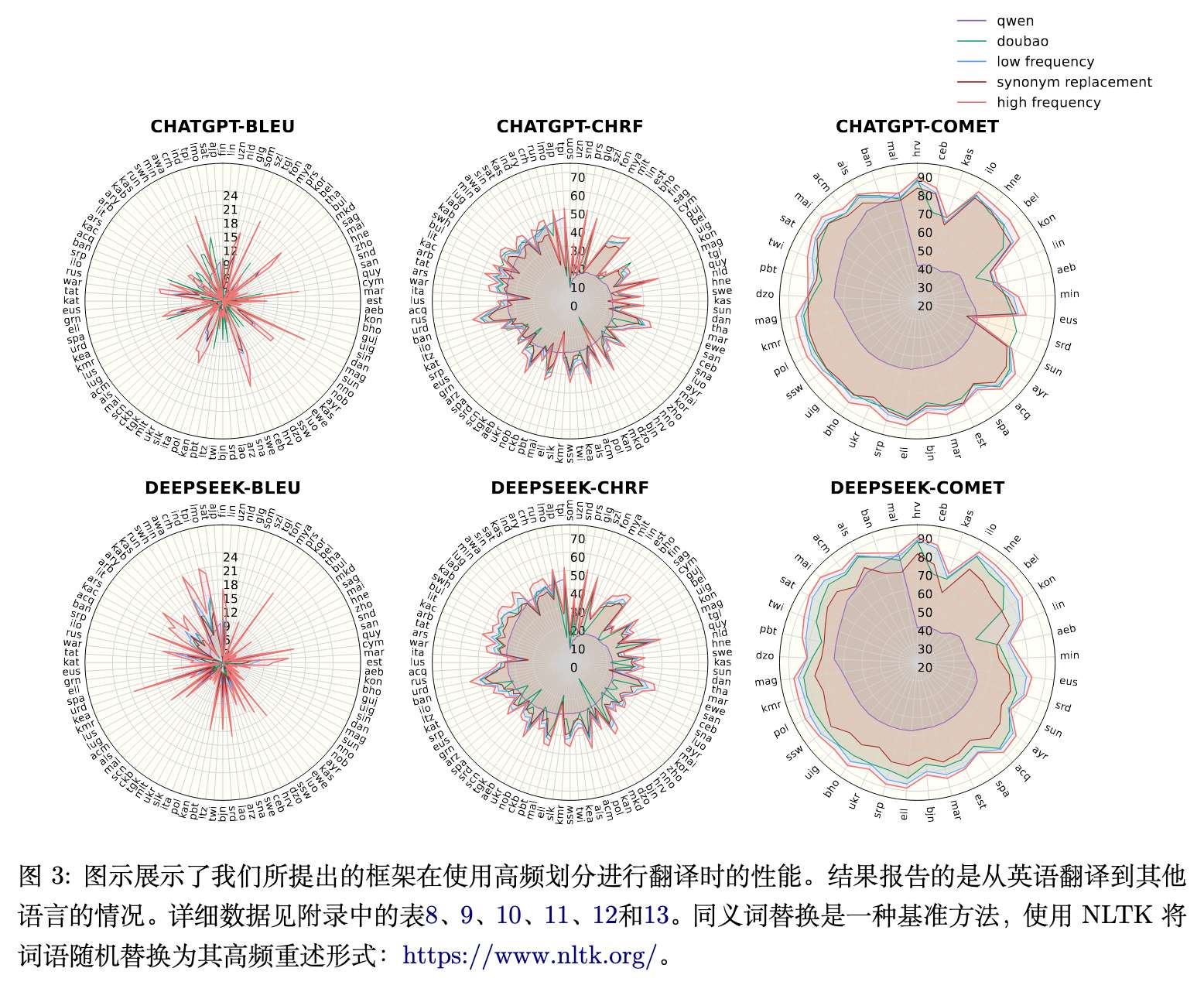
图 3 展现了基于高频和低频分区在 ChatGPT 和 DeepSeek 模型上的翻译性能分布。高频分区的曲线总体覆盖在低频分区之上。此外,ChatGPT 和 DeepSeek 在这些语向上的表现轮廓具有相似性。[表 3 BLEU, chrF, 和 COMET 指标变化统计表]
表 3 汇总了将输入从低频替换为高频后的性能改善数量。以 DeepSeek-V3 的 BLEU 分数为例:
-
在 100 个语向中,有 99 个语向得到了改善。 -
其中 63 个语向改善超过 1 分。 -
31 个语向改善超过 3 分。 -
12 个语向改善超过 5 分。
只有 1 个语向出现了轻微退化,且退化幅度小于 1 分。在 chrF 和 COMET 指标上观察到了相似的趋势,且对于 GPT-4o-mini 同样适用。在支持的 37 种语言的 COMET 评估中,所有语向均得到了改善,证实了 TFL 在机器翻译 Prompting 上的广泛适用性。
7.3 常识推理与工具调用

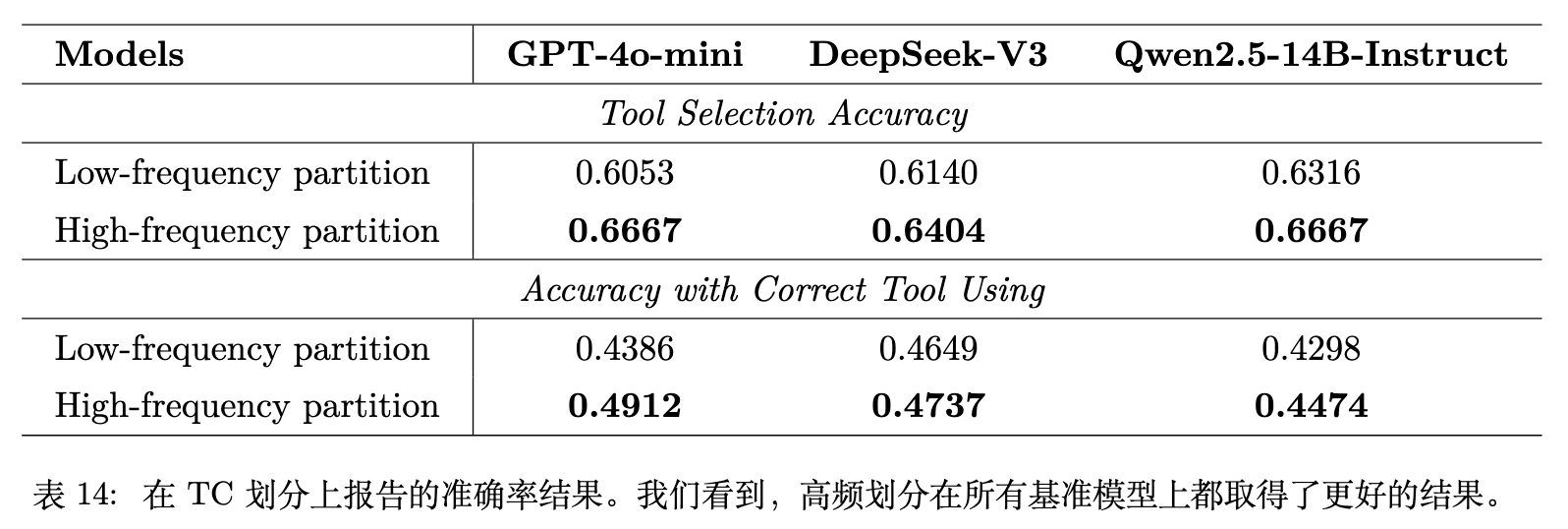
常识推理任务中,GPT-4o-mini、DeepSeek-V3 和 Llama-3.3-70B-Instruct 在高频数据分区上的准确率均高于低频数据分区。这在实验层面进一步验证了频率定律在不同理解任务中的普适性。
8. 实验结果与分析:Fine-tuning 微调阶段
在微调实验中,作者评估了不同数据切分和训练顺序组合对模型翻译性能的影响。
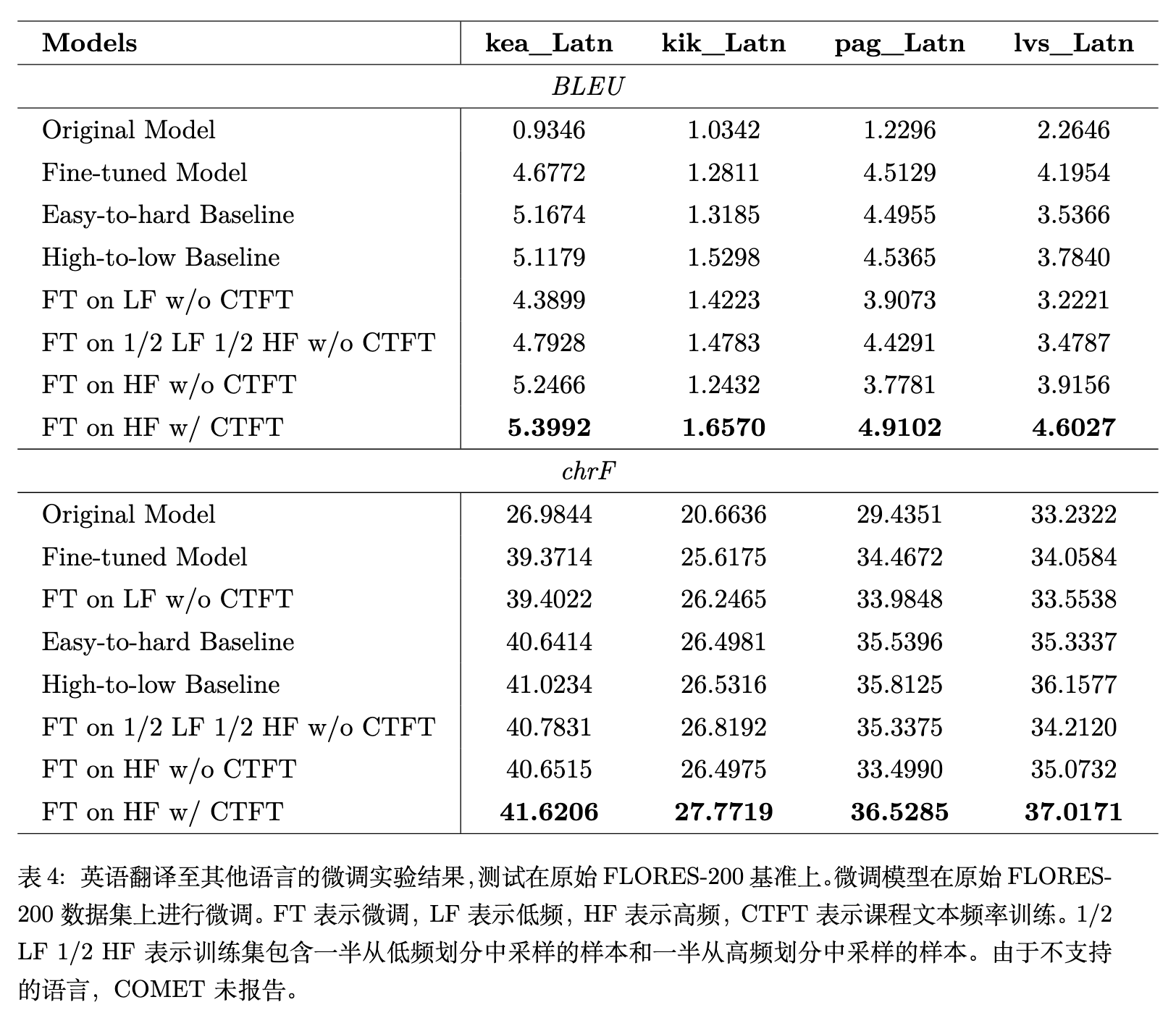
表 4 展示了目标语言为 kea_Latn, kik_Latn, pag_Latn, lvs_Latn 的微调结果。主要结论如下:
-
高频数据优于原始 Ground-truth 数据:基线 Fine-tuned Model使用完整的 FLORES-200 数据进行微调,而FT on HF w/o CTFT使用了经过筛选的高频数据分区进行微调(不使用 TFD 和 CTFT)。结果表明,高频数据的微调效果超过了原始数据。例如在 kea_Latn 上,BLEU 从 4.6772 提升到 5.2466。 -
高频分区优于低频分区:对比 FT on LF w/o CTFT(使用低频数据)和FT on HF w/o CTFT(使用高频数据),后者的表现全面占优。即使是混合数据FT on 1/2 LF 1/2 HF w/o CTFT,其表现也优于纯低频数据。例如在 pag_Latn 上,BLEU 从 3.9073 提升到 4.4291。 -
CTFT 顺序微调的有效性: FT on HF w/ CTFT表示使用高频数据并结合“由低频到高频”的课程顺序进行微调。该方法在四种语言的 BLEU 和 chrF 上取得了 8 个最佳指标。例如在 pag_Latn 上,BLEU 进一步从 3.7781 提升至 4.9102。
9. 深入分析与消融实验
9.1 TFD 的消融研究
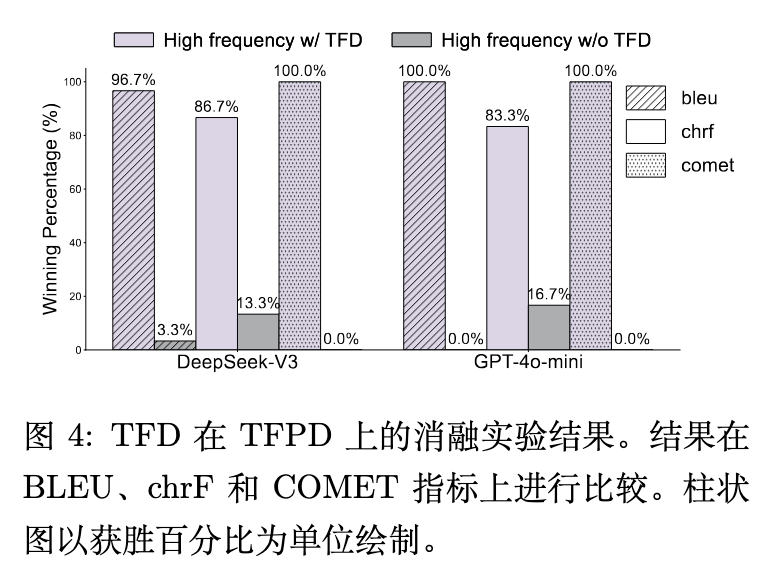
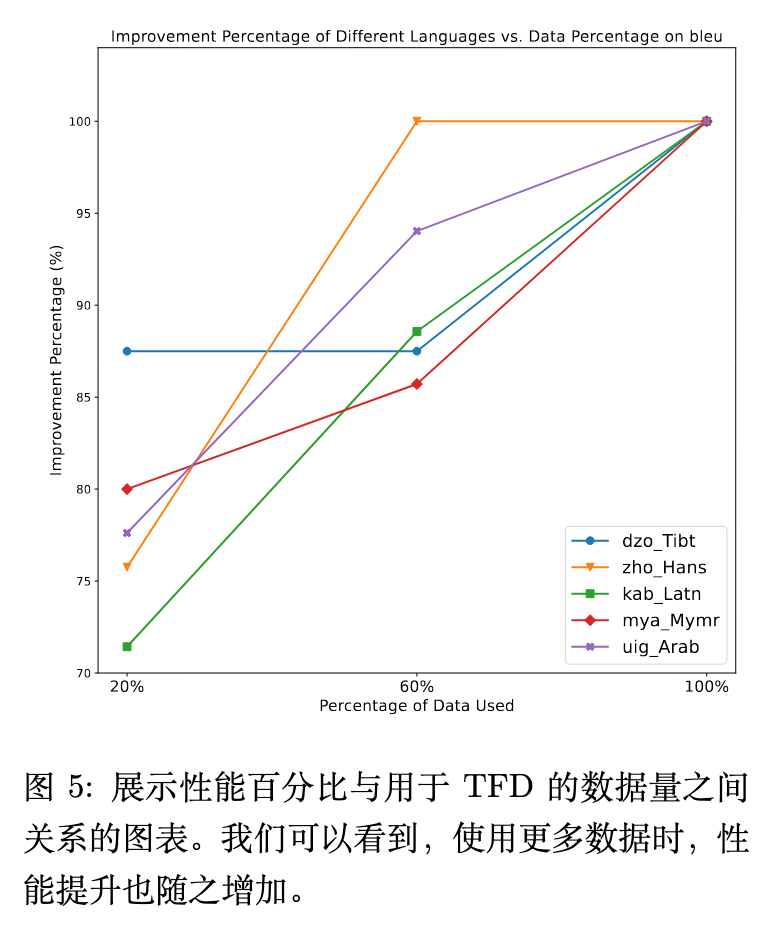
图 4 显示了移除文本频率蒸馏(TFD)后的性能损失。例如在 DeepSeek-V3 的 COMET 指标上,移除 TFD 会导致性能下降。图 5 展示了用于计算 TFD 的生成数据量与最终性能提升之间的关系。整体趋势表明,使用更多的数据用于 TFD 估计,模型性能的增益越大,证明了调用模型获取内在频率分布信息的合理性。
9.2 频率与文本复杂度的相关性
是否高频文本仅仅是因为句子结构更简单(例如语法树更浅)才表现更好?作者对文本复杂度指标与频率进行了相关性分析。
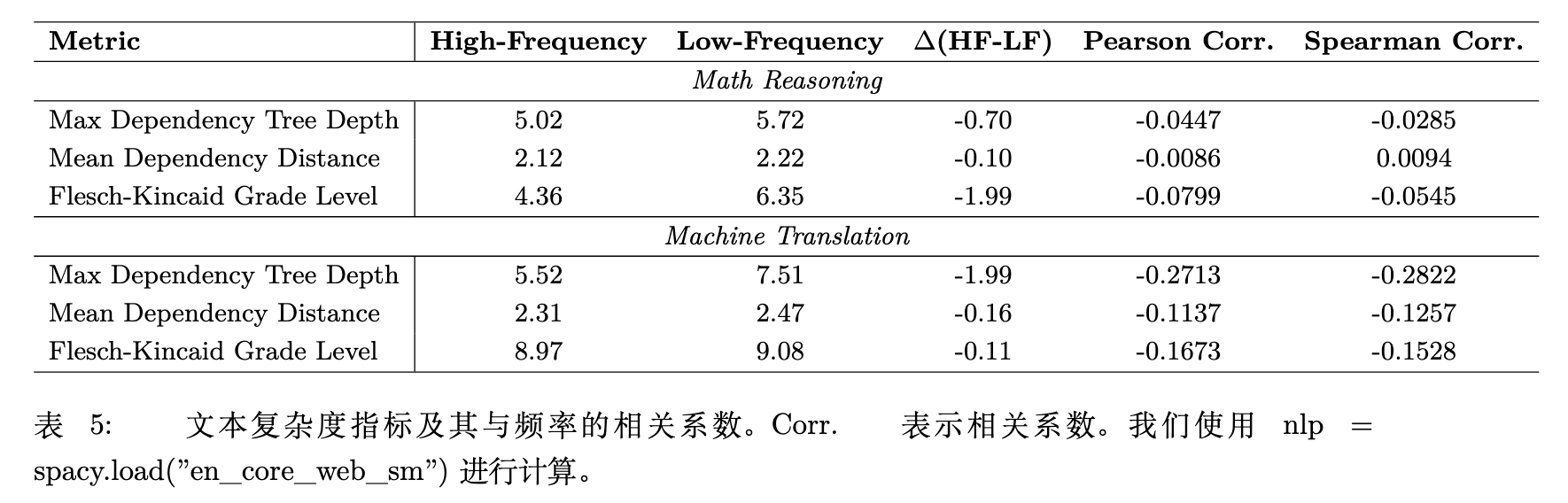
作者计算了最大依赖树深度(Max Dependency Tree Depth)、平均依赖距离(Mean Dependency Distance)和 Flesch-Kincaid 阅读等级等指标。结果表明,这些传统的复杂度指标与文本频率之间的皮尔逊和斯皮尔曼相关系数均接近于 0。这说明频率特征独立于传统的文本复杂度结构,凸显了 TFL 与传统课程学习(通常基于长度或语法深度)的区别。
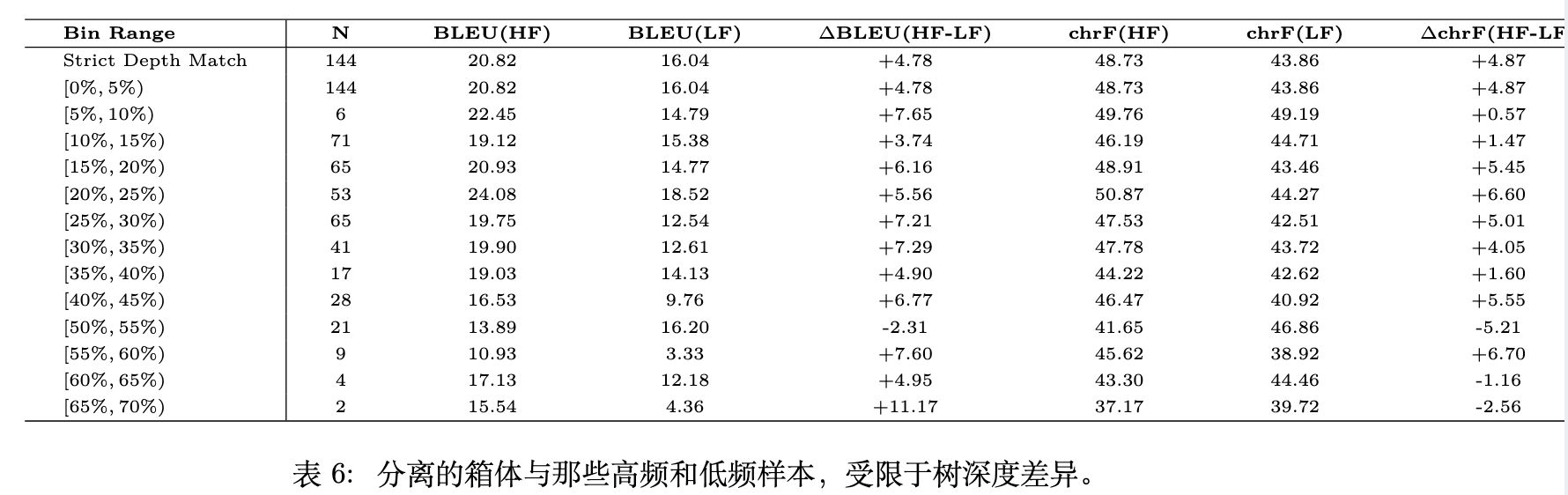
表 6 进一步控制变量:将高频和低频样本按照严格的树深度差异进行分箱。在绝大多数分箱区间中,高频提示的效果依然优于低频提示。
10. 附录深度解析:文本频率定律的理论证明
该论文最大的学术亮点之一在于附录提供了一套完整的数学理论框架,用以证明为何具有相同语义的高频句子在经过交叉熵训练的语言模型中会产生更低的负对数似然(NLL)损失。以下对此进行详细推导解读。
10.1 核心主张与符号定义
主张:当两个文本序列表达相同的含义(互为复述)时,句子级频率较高的一方倾向于在经交叉熵最小化训练的语言模型下产生较低的负对数似然损失。
符号系统:
-
:词表。 -
:在训练分布中频率排名为 的词( 为最高频词)。 -
:词 在训练分布中的真实边缘概率。 -
:参数为 的模型分配给词 的边缘概率。 -
:自回归模型中给定上下文 的条件概率。 -
:边缘 Token 级 NLL 损失。 -
:条件 Token 级 NLL 损失。 -
:句子的平均条件 NLL 损失(即模型实际计算的值)。
10.2 理论假设
证明依赖于四个形式化假设:
假设 1(Token 频率的齐普夫定律,Zipf's Law):
排名为 的词的边缘概率满足:
Zipf 定律是自然语言语料库中公认的经验规律。
假设 2(依赖于排名的对数域近似,Rank-Dependent Log-Domain Approximation):
在训练之后,对于每个词 ,存在一个依赖于排名的误差界 ,使得:
解读:这是一个逐点的界限,比仅仅控制预期交叉熵损失更为严格。高频词在训练中出现频繁,梯度信号强,因此 较小;而低频词由于训练样本少, 预期会变大。大模型的输出分布在经验上被证实服从 Zipf 定律,这是该假设合理的依据之一。
假设 3(有界的边缘-条件偏差,Bounded Marginal–Conditional Discrepancy):
定义上下文偏差:
$$\eta_{x_k} \triangleq \ell^c_\theta(x_k \mid x_{
解读:当 时,说明上下文使得 比仅看其边缘概率更容易预测。高频词(如连词、介词)在可预测的语境中通常倾向于有负的偏差。为确保严谨性,证明中使用了绝对值界限 。
假设 4(句子频率定义):
句子频率定义为其组成词的边缘频率的几何平均值(在对数空间中即为算术平均):
这是一个基于 Unigram 的近似,忽略了词序。对于比较结构相似、仅词汇替换的复述文本,这是一个可行的代理指标。
10.3 证明第一部分:Token 级别的半对数线性关系
首先,结合假设 1(Zipf's Law),计算词 的自信息(理想的 NLL):
令 ,则有:
即理想的 NLL 与 呈截距为 、斜率为 的仿射关系。
接着,引入假设 2。模型输出概率与真实概率的偏差可写为:
且满足 。将该偏差代入,得到模型的边缘 NLL 损失:
定理 1:在半对数平面(x轴:,y轴:)上,Token 级别的边缘 NLL 损失与排名呈现斜率为 的线性关系,误差带由 决定。
为保证严格的单调性(即高频词的损失严格小于低频词),对于排名 (即 ),需要:
当词频排名靠近分布长尾时,如果排名差距不大,该不等式可能无法满足,这解释了为何模型在预测低频区极其罕见词时会出现性能波动。
10.4 证明第二部分:句子级别的推导
考虑句子 ,其模型平均损失为 。
根据假设 3,将条件损失分解为边缘理想损失、模型近似误差和上下文偏差三项:
将对所有 Token 取平均:
代入假设 4 的句子频率定义,即得出定理 3:
其中总误差界限受限于模型对于词表的逼近能力 以及上下文偏差界限 。
定理 4(文本频率定律的充分条件):
设 和 是两句复述,且 。若要使高频句的损失严格小于低频句的损失,即 ,只需满足下述充分条件:
解读:只要两个句子的对数频率差大于上述各种误差界的总和,模型评估高频句的负对数似然损失就必然更低。由于最坏情况的界限较为保守,在实际的 Token 序列平均效应下,误差会相互抵消(根据中心极限定理,误差通常在 量级)。这就从理论框架上论证了为什么经验实验中高频数据普遍表现更好。
10.5 损失下降与下游任务性能改善的联系
上述理论证明了高频输入具有更低的 NLL 损失(更低的困惑度,模型分配了更高的概率)。为何这会带来更好的下游任务执行结果?
-
对于 Prompting 而言:较低的 NLL 损失意味着输入处于模型内部表征校准度更高的区域。这些区域的数据在预训练时见过的次数更多,模型对其模式“理解”更透彻。因此,面对此类输入,模型更容易激活正确的推理路径。 -
对于 Fine-tuning 而言:如果模型已经赋予输入 Token 更高的概率,由此计算得出的梯度信号会更加稳定,输出映射的有效学习率会更高。此外,使用更贴近预训练分布的高频输入进行微调,能降低灾难性遗忘的风险。
11. 局限性探讨
作者诚恳地讨论了理论与实验框架中存在的局限性,以便读者客观评估:
-
假设 2 并非通过训练目标直接推导得出:交叉熵训练只能控制预期的损失,并不能保证针对每个 Token 的逐点对数域误差都微小。尽管实验上支持大模型具有 Zipf 定律特征,但这仍是一个基于训练结果的假设。 -
上下文偏差 难以精确估计:它取决于具体的句子上下文和模型学习到的条件分布,难以给出一个与数据无关的普遍界限。 -
基于 Unigram 的句子频率定义是近似的:它忽略了词序和词间依赖。对于因为句法结构大幅变动产生的复述,该代理指标可能无法完全反映文本的“常见程度”。 -
句子长度的相互作用:当两个复述句子长度不一致时,平均误差界的宽松度会发生变化。目前的定理仅将界限视为定值,未明确建立长度的交互模型。 -
损失排序并未形式化地等价于任务性能排序:定理证明了 NLL 损失的降低,而任务性能的提升(如更高的准确率或 BLEU 分数)是在大量的基准测试中通过实证支持的,而非在数学框架内得出的必然推论。 -
语义等价性是默认假设:论文比较的前提是“同义复述”。在实际操作中,GPT 生成的复述难免会带来微小的语义偏移。尽管使用了人工校验过滤,但这超出了纯基于频率定理的约束范畴。 -
Zipf 定律在分布尾部的失效:幂律模型适用于词汇的主体部分,但对于极其罕见的词组会有偏差,这部分误差被迫吸收到了 之中。
12. 总结
本文通过实验与数学推导的结合,指出在语义等价的前提下,文本特征的频率层级在 LLMs 的推理和微调中扮演了不可忽视的角色。作者提供的 TFL(文本频率定律)为提示工程提供了一个简明但具有理论支撑的指导原则:用更常见、更高频的词汇表达相同的指令,模型表现会更好。
其伴随提出的 TFD(频率蒸馏)解决了在不可见的预训练数据下进行频率估计的问题;而 CTFT(频率排序课程训练)则补充了关于微调数据输入顺序的方法论。TFPD 数据集的发布,也为未来探讨模型语言表征内部规律的学者提供了有价值的工具。
者提示我们在构建评测集、设计 Prompt 模板或者组装微调数据时,不仅要关注数据的长短和逻辑难度,还应当将文本频率作为一个独立的优化维度。
更多细节请阅读原文。
往期文章:


