引言:为什么大模型需要更长的“记忆”?
在人工智能的浪潮之巅,大型语言模型(LLM)无疑是最耀眼的明星。从回答复杂问题到创作诗歌剧本,它们展现出的强大能力正深刻地改变着我们的世界。然而,即便是像GPT-4这样顶尖的模型,也存在一个普遍的“痛点”——上下文窗口(Context Window)长度有限。
想象一下,你正在与一个学识渊"渊"博但记性不太好的专家对话。无论你之前与他讨论了多少内容,他只能记住最近的几千个词。当你试图让他总结一本厚厚的PDF报告,或者让他联系数小时前的对话内容时,他便会“失忆”,无法理解完整的语境。这就是当前大多数LLM面临的困境。
这个限制的根源在于高昂的训练成本和技术瓶颈。要让模型支持更长的上下文,通常需要在包含海量长文本的数据集上进行微调或从头预训练。这不仅需要惊人的计算资源(动辄成百上千的GPU),还需要高质量的长文本训练数据,而这类数据的稀缺性进一步加剧了问题的复杂性。
有没有一种方法,可以不经过昂贵的再训练,就能让现有的LLM“记忆力”倍增,轻松处理长篇大论呢?
来自清华大学等机构的研究者们在ACL 2025(计算语言学顶级会议)上发表了一篇引人注目的论文——《通过自适应分组位置编码扩展LLM上下文窗口:一种免训练方法》(Extending LLM Context Window with Adaptive Grouped Positional Encoding: A Training-Free Method)。 他们提出了一种名为AdaGroPE(Adaptive Grouped Positional Encoding)的创新方法,它如同一剂“记忆增强剂”,能够以“即插即用”且无需任何训练的方式,显著扩展现有LLM的上下文窗口。

-
论文标题:Extending LLM Context Window with Adaptive Grouped Positional Encoding: A Training-Free Method -
论文链接:https://aclanthology.org/2025.acl-long.28.pdf
本文将带你深入解读这项令人兴奋的技术。我们将从其核心原理出发,剖析它如何巧妙地“欺骗”模型处理从未见过的长序列,并通过详实的实验数据,见证它在各类任务上超越基线甚至优于专门为长文本设计的模型的惊人表现。准备好,让我们一起探索LLM摆脱上下文长度束缚的未来。
背景知识:位置的“魔咒”与RoPE的困境
要理解AdaGroPE的精妙之处,我们首先需要了解Transformer模型(当今LLM的基础架构)是如何理解文本顺序的。
1. 位置编码:让模型理解“谁先谁后”
与循环神经网络(RNN)不同,Transformer的自注意力机制(Self-Attention)本身是无法感知序列中单词顺序的。对于它来说,“我爱你”和“你爱我”在没有位置信息的情况下,可能看起来没什么不同。为了解决这个问题,研究者引入了位置编码(Positional Encoding)。
位置编码的本质是为序列中的每个位置(或token)赋予一个独特的数学“签名”(一个向量),并将其融入到词嵌入中。这样,模型不仅知道了每个词是什么,还知道了它在句子中的确切位置。
2. 旋转位置编码(RoPE):相对位置的优雅表达
在众多位置编码方案中,旋转位置编码(Rotary Position Embedding, RoPE)因其卓越的性能和良好的特性,成为Llama、PaLM等主流LLM的标配。
RoPE的核心思想非常优雅:它不再是简单地将位置向量“加”到词向量上,而是通过旋转的方式将位置信息融入其中。具体来说,对于处于位置 的token,其Query向量 和Key向量 会被一个与位置 相关的旋转矩阵 进行旋转。
当计算两个不同位置 和 的token之间的注意力得分时,由于旋转的数学性质,最终的得分只与它们的相对距离 有关,而与它们的绝对位置无关。这使得RoPE能够天然地捕捉相对位置关系,并且理论上具有一定的外推能力,即处理比训练时更长的序列。
3. RoPE的“外推”困境
然而,理想很丰满,现实很骨感。研究发现,直接将使用RoPE训练的LLM用于处理远超其预训练长度的文本时,性能会急剧下降。 这就是所谓的“分布外(Out-of-Distribution)”问题。
模型在训练期间只“见过”特定范围内的相对位置(例如,对于一个4k窗口的模型,相对距离在0到4095之间)。当推理时遇到一个前所未见的、更大的相对距离(比如5000),模型就会感到困惑,无法正确计算注意力,导致理解能力崩潰。
为了解决这个问题,社区提出了多种方案,如位置插值(Position Interpolation, PI)等,但这些方法通常需要对模型进行额外的微调,再次回到了高成本的老路上。
那么,有没有可能在不微调的前提下,让模型巧妙地绕过这个“外推”的诅咒呢?这正是AdaGroPE试图解决的核心问题。
核心方法:自适应分组位置编码 (AdaGroPE) 深度解析
AdaGroPE的 brilliance 在于它提出了一种动态、自适应地“重用”和“分组”位置编码的策略。其设计灵感来源于一个深刻的洞察,即人类在理解长文本时,对不同距离的词语位置的敏感度是不同的。
1. 设计理念:模拟人类的距离感知
想象一下你在阅读一篇长文。对于当前句子中的词语,你会非常关注它们的精确相对顺序和距离,因为这直接影响语法和局部语义。但对于几页之前的某个词,你可能只记得它的大致位置(比如在文章开头部分),而不会在意它和当前词之间精确的距离是5327个词还是5328个词。
AdaGroPE正是借鉴了这种人类感知的特性。它认为:
-
近距离的token:对模型理解至关重要,需要保留其精确的相对位置信息。 -
远距离的token:其精确位置相对不那么重要,我们可以对它们的位置进行一种“模糊化”或“分组”处理,将多个相邻的远距离位置映射到同一个预训练过的位置编码上。
基于这个理念,AdaGroPE在构建相对位置矩阵时,遵循了三大核心指导原则。
2. 三大指导原则
当需要将一个长序列(长度为 )适配到一个预训练窗口较小(最大相对位置为 )的模型时,AdaGroPE遵循以下三个原则来调整位置编码:
-
最小化重用(Minimizing Reuse):尽可能少地重用位置编码。只有当序列长度 超出预训练范围 时,才启动重用机制。这最大限度地保留了原始位置信息的保真度。 -
优先重用远距离位置(Prioritizing Distant Relative Position Reuse):当必须重用时,优先从最远的token开始。这保证了与当前token最邻近的token们的位置信息仍然是精确的,符合我们上面提到的人类感知模型。 -
从近到远,重用数递增(Progressively Increasing Reuse Count from Close to Distant):随着与当前token的距离增加,分组的大小(即共享同一个位置编码的token数量)也随之增加。这意味着越远的token,其位置信息被“模糊化”的程度越高。
这三个原则共同构成了一个智能、动态的策略,使得位置编码的扩展既高效又符合模型处理信息的内在逻辑。
3. 技术实现:动态构建相对位置矩阵
现在,让我们深入技术细节,看看AdaGroPE是如何通过数学公式实现上述原则的。整个过程的核心是动态地构建一个修改后的相对位置矩阵 ,其中 是当前查询(query)token的索引, 是键(key)token的索引。
(1) 基础设置
在开始之前,我们需要定义几个关键参数:
-
:目标扩展的上下文长度。 -
:模型预训练时能处理的最大相对位置。通常小于预训练窗口大小 。 -
:邻居窗口大小。在这个窗口内的token,位置信息将保持不变,不进行任何分组。 -
:重用率系数,一个超参数,用于控制保留位置的数量。
(2) 逐步扩展与分组
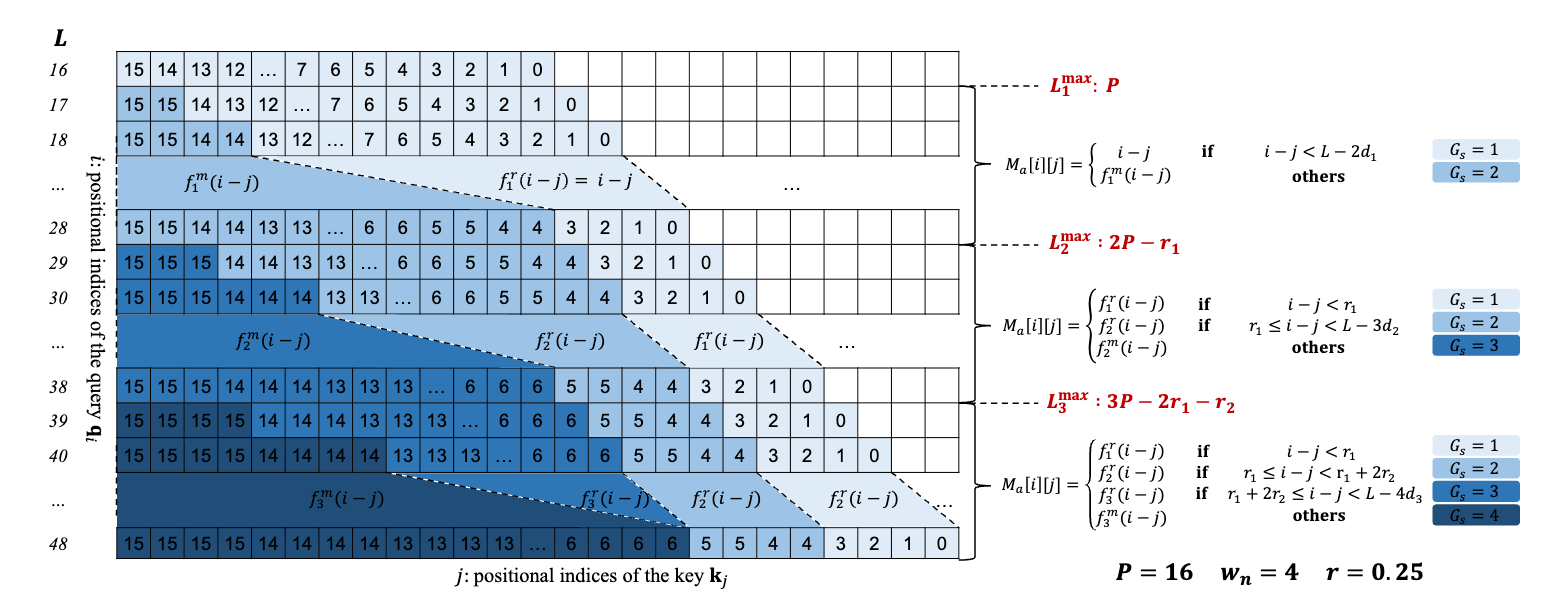
AdaGroPE的策略是根据目标长度 的增加而逐步演化的。我们可以通过一个例子来直观理解,如上图所示。假设一个模型预训练窗口为4k,我们设定 ,,。
-
当 时:一切正常,没有超出预训练范围。相对位置 ,与原始RoPE完全相同。
-
当 略微超过16(例如 ):此时需要启动重用机制。根据“优先重用远距离位置”原则,AdaGroPE会找到最远的位置,并让它和旁边的位置共享一个编码。例如,位置15和16可能都会被映射到预训练的位置15。
-
当 继续增大时:需要重用的位置越来越多。此时“从近到远,重用数递增”原则开始发挥作用。AdaGroPE会动态计算出不同距离范围的分组大小(Reuse Count, )。
-
近距离(例如,相对距离 < 4):,不分组,保留精确位置。 -
中距离: 可能为2,即每2个相邻的token共享一个位置编码。 -
远距离: 可能为3或更高,模糊化程度更高。
-
(3) 核心数学公式
论文中给出了一套完整的数学框架来精确地计算这个过程。其核心是定义一个映射函数 ,它能将原始的相对位置 映射到经过AdaGroPE调整后的新位置。
当序列长度 处于某个范围内,例如 ,此时最大的重用分组大小为 。相对位置矩阵 的计算可以概括为:
其中 表示不分组,而 表示分组大小为 的映射。例如,一个简单的分组映射可以表示为对位置进行整除操作。论文中的公式(8)给出了一个更精确的映射方式:
此公式确保了最远的 组token每组 个共享一个位置,同时满足了“最小化重用”和“优先重用远距离”的原则。
符号定义:

在解码过程中计算相对位置的完整伪代码:
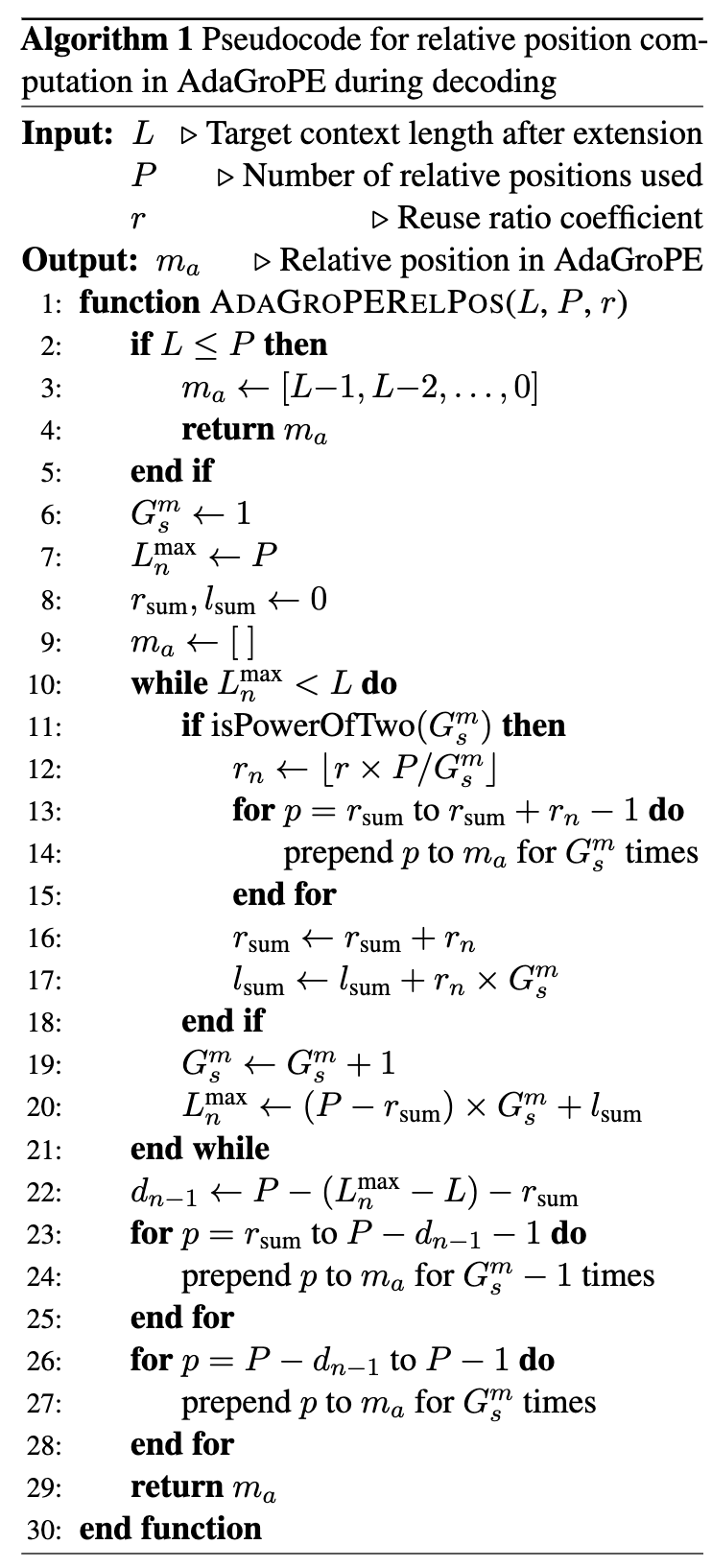
4. 自适应调整策略
AdaGroPE最强大的地方在于其自适应性。对于任何给定的目标长度 ,它都能通过公式(15)和(16)直接计算出所需的最大重用数 以及每一层的分组策略,而无需手动调整参数。这使得AdaGroPE成为一个真正意义上的即插即用、对不同输入长度高度自适应的框架。
总而言之,AdaGroPE通过一套精心设计的、模拟人类感知机制的动态分组策略,巧妙地将超出预训练范围的“未知”长距离位置,映射回模型“已知”的短距离位置编码上,从而在不进行任何训练的情况下,成功“解锁”了LLM处理长文本的潜力。
实验验证:AdaGroPE的卓越表现
理论上的优雅设计最终需要通过严苛的实验来验证。论文作者在多个维度、多个基准测试上对AdaGroPE进行了全面评估,结果令人印象深刻。
1. 实验设置
-
模型:涵盖了当前主流的开源LLM,包括Llama-2 (7B, 13B), Llama-3 (8B), Mistral (7B), SOLAR (10.7B), 和 Phi-2。 -
基线方法:对比了其他两种先进的免训练长上下文扩展方法:DCA (Dual Chunk Attention) 和 SelfExtend。此外,还包括了一些需要微调的方法如Longlora、CodeLlama等作为参考。 -
评测基准: -
语言建模 (Language Modeling):使用PG19数据集,通过困惑度(Perplexity, PPL)来衡量模型对长文本的建模能力,PPL越低越好。 -
合成长上下文任务 (Synthetic Long Context Tasks):采用经典的“大海捞针”(Passkey Retrieval)任务,测试模型在超长、充满干扰信息的文本中定位一个随机数字密码的能力,直接考验模型的长距离信息检索能力。 -
真实世界长上下文任务 (Real-world Long Context Tasks):使用了两大权威长文本评测基准 LongBench 和 L-Eval ,它们包含问答、摘要、代码理解等多种真实应用场景。
-
2. 语言建模任务(PG19)
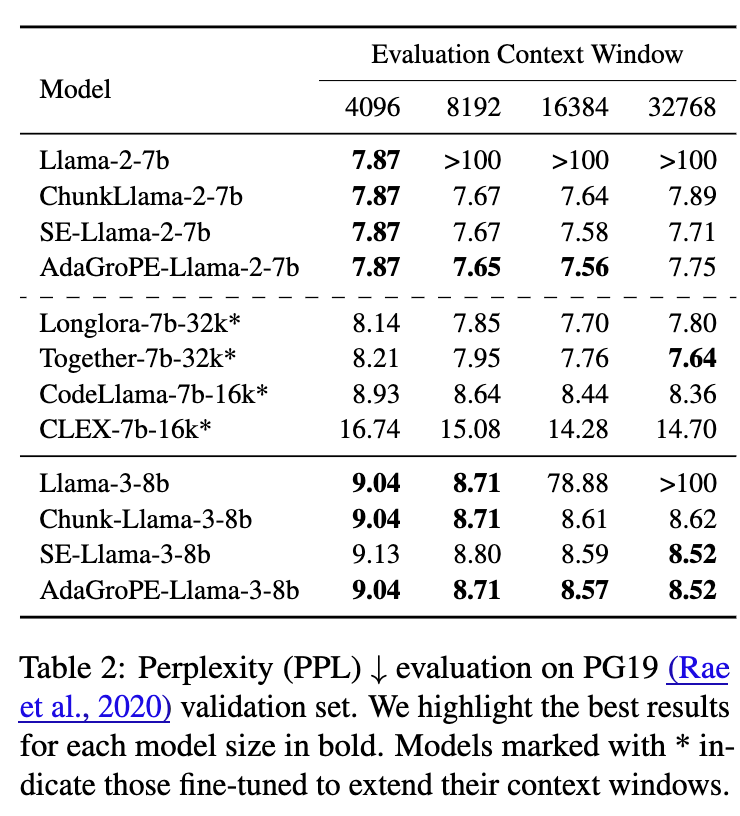
在语言建模任务上,AdaGroPE展现了其强大的基础能力。如表2所示:
-
对于Llama-2-7b,在上下文长度扩展到16k时,AdaGroPE的PPL(7.56)是所有免训练方法中最低的,甚至优于需要微调的Longlora-7b-32k(7.70)和CodeLlama-7b-16k(8.44)。 -
对于Llama-3-8b,在32k的窗口下,AdaGroPE同样取得了与SelfExtend并列的最佳性能(8.52),远超基线模型。
这些结果表明,AdaGroPE不仅成功扩展了上下文窗口,而且在扩展后依然保持了对文本序列的强大建模能力。
3. 合成长上下文任务(大海捞针)
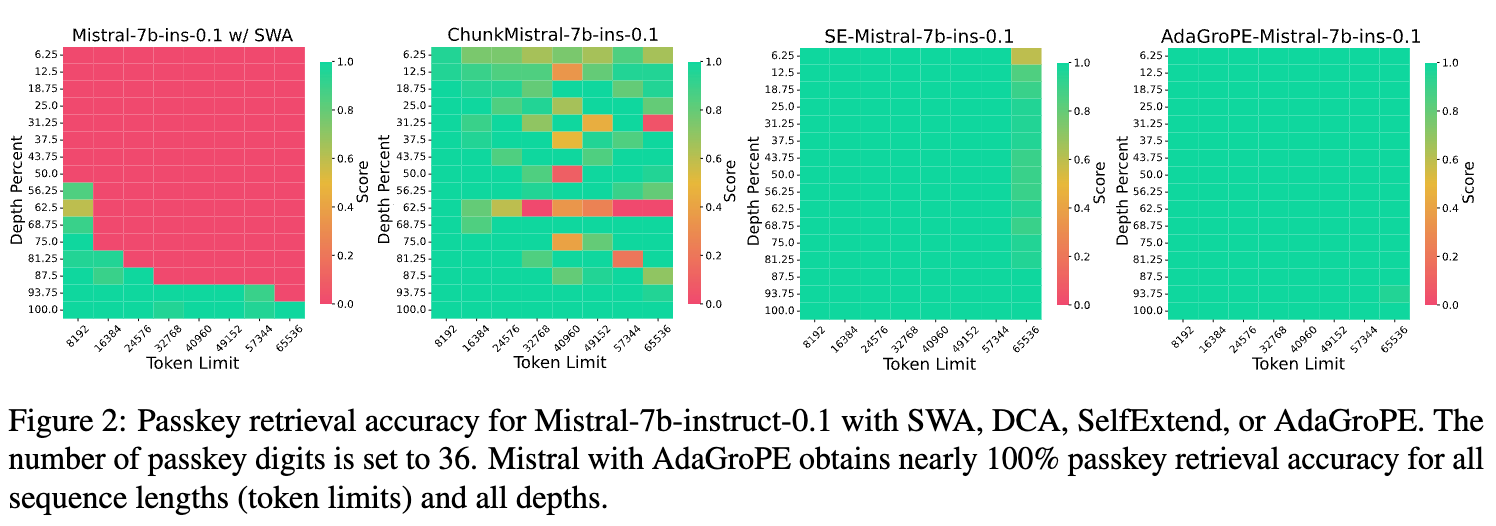
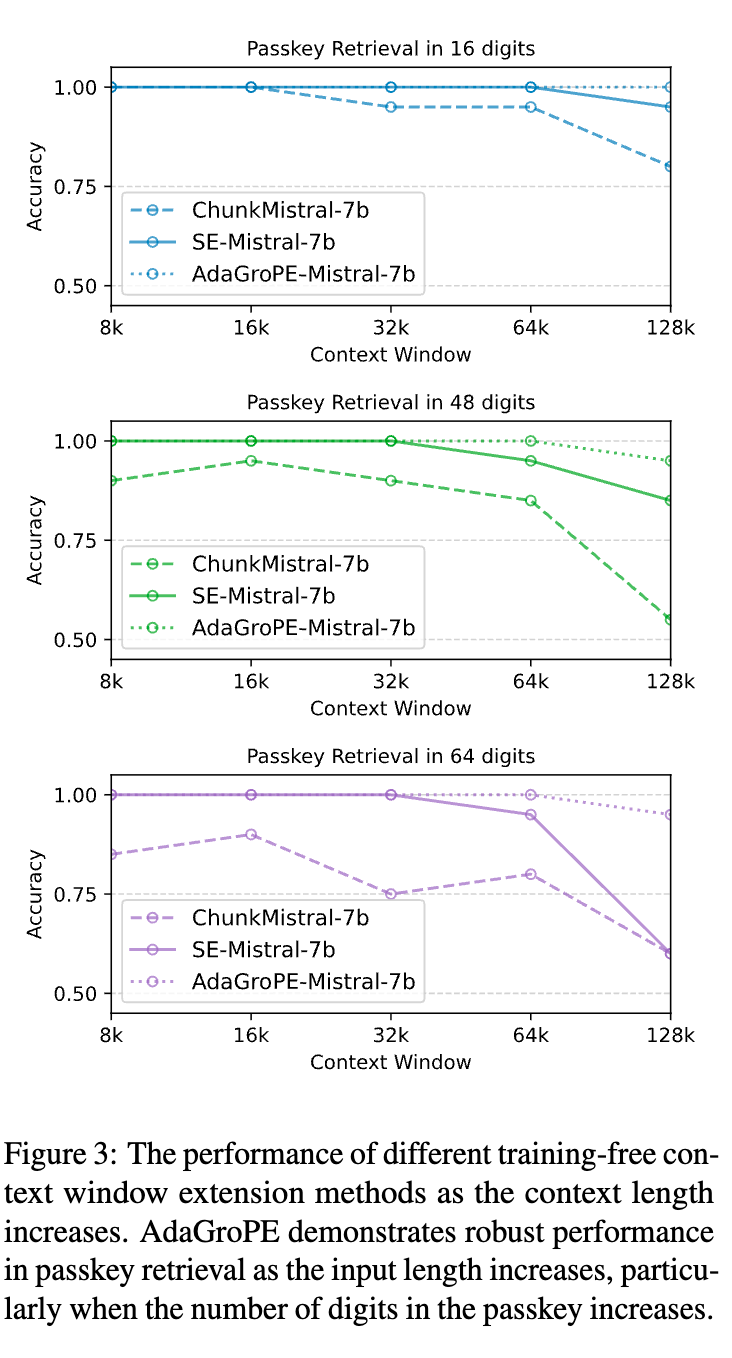
“大海捞针”任务是检验长文本处理能力的试金石,图2中的结果堪称惊艳:
-
原始的Mistral-7b模型在上下文变长后,准确率迅速降至0。 -
其他免训练方法如DCA和SelfExtend虽然有所改善,但在更长的上下文(如65k)或特定深度下会出现性能波动或下降。 -
AdaGroPE-Mistral-7b 则表现出了近乎完美的性能,在从8k到65k的所有上下文长度和所有深度上,几乎都达到了100%的准确率。
这充分证明了AdaGroPE所采用的、优先保留近处信息、模糊化远处信息的策略,对于在长文本中保持对关键信息的注意力非常有效。图3进一步展示了当密码位数增加(任务变难)时,AdaGroPE的性能下降也远比其他方法平缓,展现了其鲁棒性。
4. 真实世界长上下文任务(LongBench & L-Eval)
真实世界的任务更能体现方法的实用价值。
-
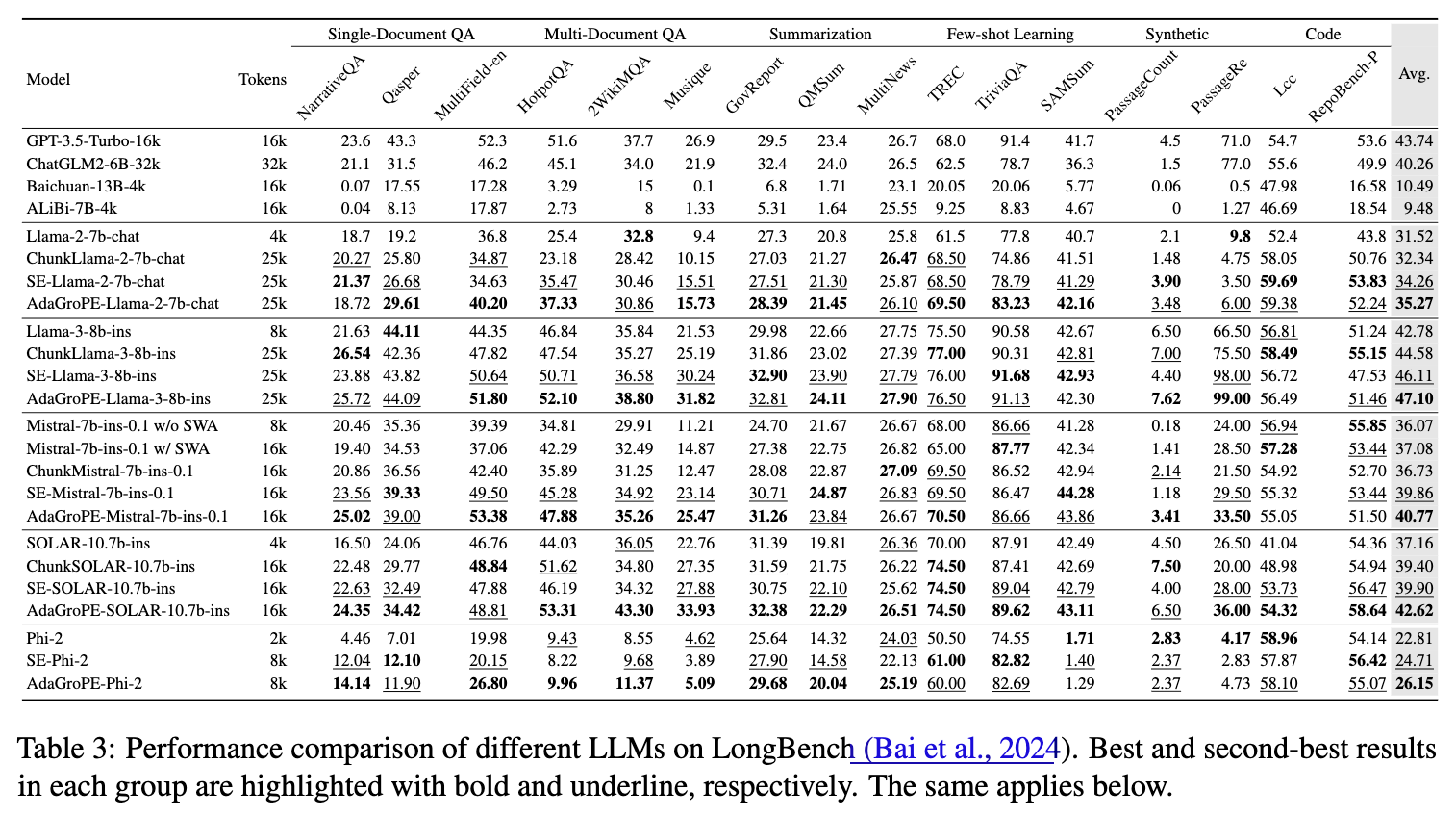
LongBench 评测 ( 表3):在涵盖单/多文档问答、摘要、代码等多个任务的LongBench基准上,AdaGroPE在多个模型上都取得了最佳的平均分。例如,AdaGroPE-Llama-3-8b-ins的平均分达到了47.10,超过了SelfExtend(46.11)和DCA。值得注意的是,它在多文档问答(Multi-Document QA)和代码(Code)等极具挑战性的任务上表现尤为突出。
-
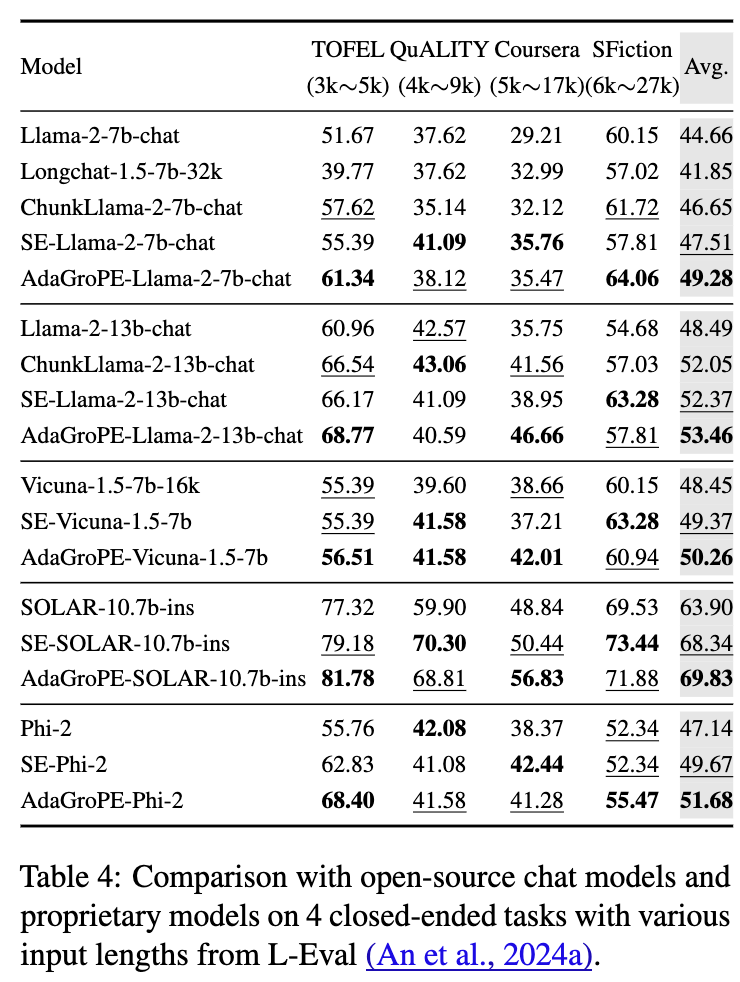
L-Eval 评测 ( [表4]):L-Eval专注于闭卷问答任务。结果同样显示,应用了AdaGroPE的模型性能普遍得到了显著提升。例如,AdaGroPE-Llama-2-13b-chat的平均分从原始的48.49提升到了53.46。一个更引人注目的发现是,一个基础窗口为4k的模型,在应用了AdaGroPE之后,其性能甚至可以超越一个原生支持16k或32k上下文的、经过专门微调的模型。例如,AdaGroPE-Llama-2-7b-chat(4k基础模型)的平均分(49.28)超过了Longchat-1.5-7b-32k(41.85)。
这些实验结果雄辩地证明了AdaGroPE的有效性和优越性。它不仅仅是一个理论上可行的方法,更是在实践中能够稳定、高效地提升现有LLM长文本处理能力的强大工具,其“免训练”的特性使其具有极高的性价比和实用价值。
深入分析与讨论
除了展示优异的性能,论文还对AdaGroPE的行为和特性进行了更深入的分析。
1. 消融实验:超参数P和r的影响
AdaGroPE有两个关键的超参数:
-
:用于外推的预训练最大相对位置。 -
:重用率系数。
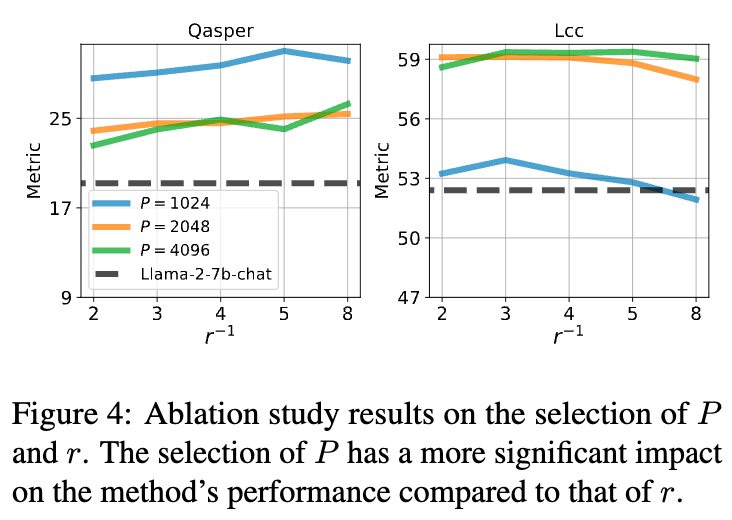
上图中的消融研究揭示了它们的影响。研究发现, 的选择对性能影响较大。选择一个合适的 (通常是预训练窗口大小 的一半或四分之一)可以在利用预训练知识和避免外推错误之间取得最佳平衡。而 的影响相对较小,默认值0.25在大多数任务上都能取得稳健的性能提升。这表明AdaGroPE对超参数不敏感,易于使用。
2. 与其他扩展方法的集成
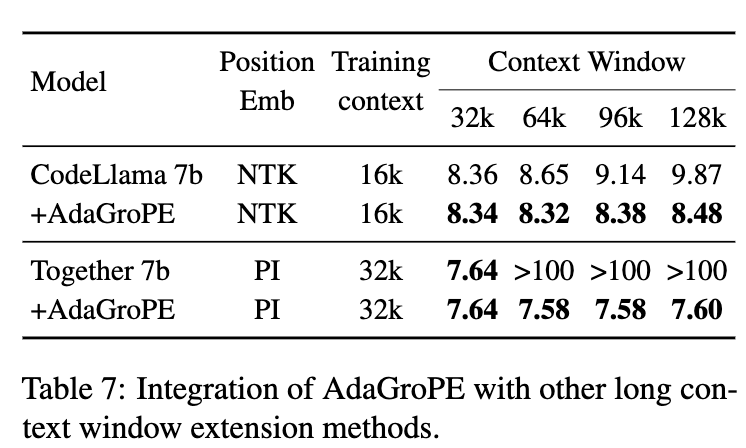
AdaGroPE作为一种位置编码的扩展策略,可以与其他长上下文扩展技术(如NTK、PI)相结合。表7的实验结果表明,将AdaGroPE应用于已经使用其他技术扩展了窗口的CodeLlama和Together模型上,依然能够进一步降低其PPL。这证明了AdaGroPE的正交性和互补性,它可以作为一种通用的增强模块,集成到现有的长上下文解决方案中,实现强强联合。
3. 局限性与未来展望
尽管AdaGroPE表现出色,但作者也坦诚地指出了其局限性:
-
代码任务的挑战:在表3中可以看到,虽然AdaGroPE在代码任务上表现不俗,但相对于自然语言任务,代码对token间的相对位置精度要求极高,结构和层次关系远比相对距离重要。AdaGroPE这种模糊化远距离位置的假设在代码上可能不是最优的。 -
复杂推理任务:在需要跨越超长距离进行复杂逻辑推理和信息整合的问答任务中,AdaGroPE虽然能让模型“看到”全文,但并不能完全解决模型固有的、在精确推理上的短板。
这些局限性也为未来的研究指明了方向。例如,开发针对代码等特殊数据类型的、更精细化的位置重用策略,或者将AdaGroPE与更强的推理模块相结合。此外,对AdaGroPE背后的理论原理进行更深入的分析,以及将其扩展到图像、视频等多模态领域,都是极具价值的研究方向。
结论:迈向“无限”上下文的重要一步
清华大学等机构提出的AdaGroPE方法,为打破这一枷锁提供了一条极具创新性和实用性的路径。通过模拟人类对距离的感知,AdaGroPE设计了一套动态、自适应的分组位置编码策略。它遵循最小化重用、优先重用远端、渐进增加重用三大原则,在无需任何额外训练和微调成本的情况下,就能让现有的LLM有效处理远超其预训练长度的文本。


