让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
-
论文链接:https://arxiv.org/pdf/2605.11739
TL;DR
今天解读一篇来自中国科学技术大学、腾讯、新加坡国立大学等机构的合作论文《Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation》。随着大型语言模型(LLM)在推理能力上的不断推进,在线蒸馏(On-Policy Distillation, OPD)逐渐成为后训练与模型融合的重要范式。虽然已有研究大多将其效率优势归结于更致密、更稳定的监督信号,但 OPD 在参数级别的底层更新机制一直缺乏系统性探讨。
作者提出,OPD 的高效率源于参数更新过程中的一种预见性(Foresight)。这种预见性体现在两个维度:其一是功能冗余回避(Functional Redundancy Avoidance),OPD 能够在训练早期识别出边际效用较低的模块(如嵌入层和顶/底层网络),并抑制这些区域的参数变化,将更新集中于对推理更关键的中间层模块;其二是早期低秩锁定(Early Low-Rank Lock-in),OPD 的更新矩阵表现出更强的低秩集中度,其主导更新子空间在训练早期就与最终收敛方向高度对齐,后续训练主要是在该子空间内放大更新幅度。
基于上述参数演化特性的发现,作者提出了一种即插即用的加速框架 EffOPD。该方法无需引入额外的可训练模块或复杂的超参数调优,仅通过在训练过程中沿早期确定的更新方向进行自适应步长的线性外推,并在包含 50 个样本的小型验证集上进行轻量级验证。在 1.5B 到 32B 规模的模型实验中,EffOPD 在数学和代码基准测试上实现了平均 3 倍的训练加速,且保持了与标准 OPD 相当的最终性能。
1. 引言
在大型语言模型的后训练阶段,为了提升模型在代码生成、数学推理等复杂任务上的表现,基于强化学习(RL)的算法(如 PPO、GRPO)和在线蒸馏(OPD)是两种主流路线。在使用强化学习进行可验证奖励(RLVR)训练时,模型通常只能在完整响应生成后获得标量奖励,这种稀疏性会导致探索效率受限。相比之下,给定一个强能力教师模型,OPD 允许学生模型生成自身的轨迹,并通过逆 KL 散度拟合教师模型在这些轨迹上的输出分布。由于提供了词元(Token)级别的致密监督信号,OPD 通常能够在更短的训练时间内达到与 RL 相当的性能。
然而,目前对于 OPD 效率优势的解释主要停留在宏观的优化层面(如方差更低、监督更密),未能深入到模型内部参数更新的微观物理过程。强化学习与在线蒸馏在改变模型权重时,其参数空间的轨迹有何本质不同?如果 OPD 的监督信号更有效,这种有效性是如何映射到 Transformer 架构的具体层级和特定更新方向上的?
为回答这些问题,作者设计了严格控制初始权重的对比实验,从模块分配(Module-Allocation)和更新方向(Update-Direction)两个维度对 RL 和 OPD 的参数更新动态进行了量化分析,揭示了 OPD 独有的参数级演化结构,并在局部几何近似下提供了理论解释。
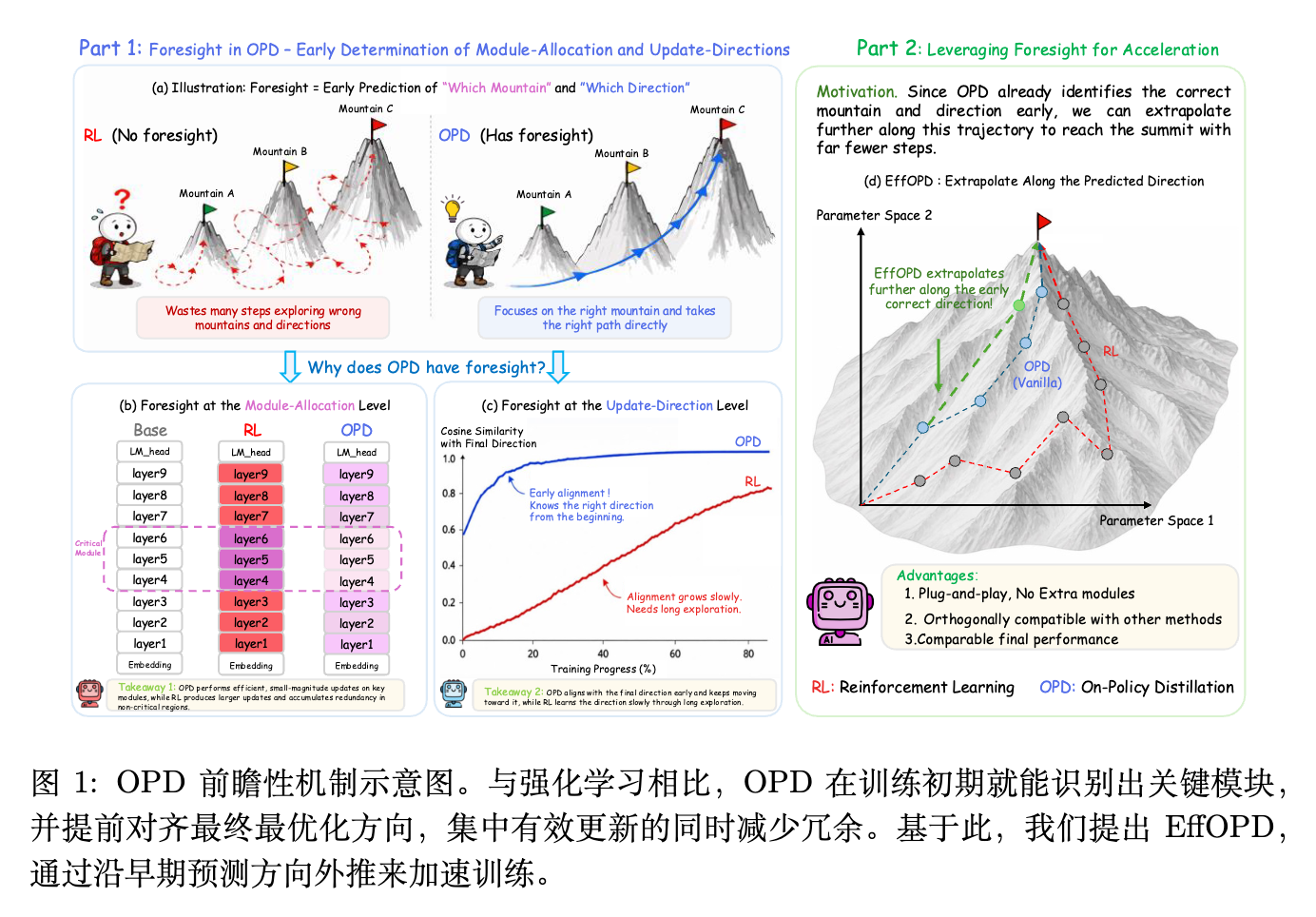
2. 预见性机制之一:模块级别的功能冗余回避
本节探究 OPD 与 RL 在模块层级上的差异。作者固定了 RL 和 OPD 的共同初始权重 ,并将参数更新定义为 。通过控制变量法,分析两种方法在达到相近推理性能时,对不同架构组件的更新依赖度。
2.1 参数更新范数与推理性能收益
为了衡量参数更新的有效性,作者首先对最终检查点的更新方向进行范数缩放(Norm Scaling)。给定最终的更新方向 ,引入缩放因子 ,构造模型 并评估其推理准确率。
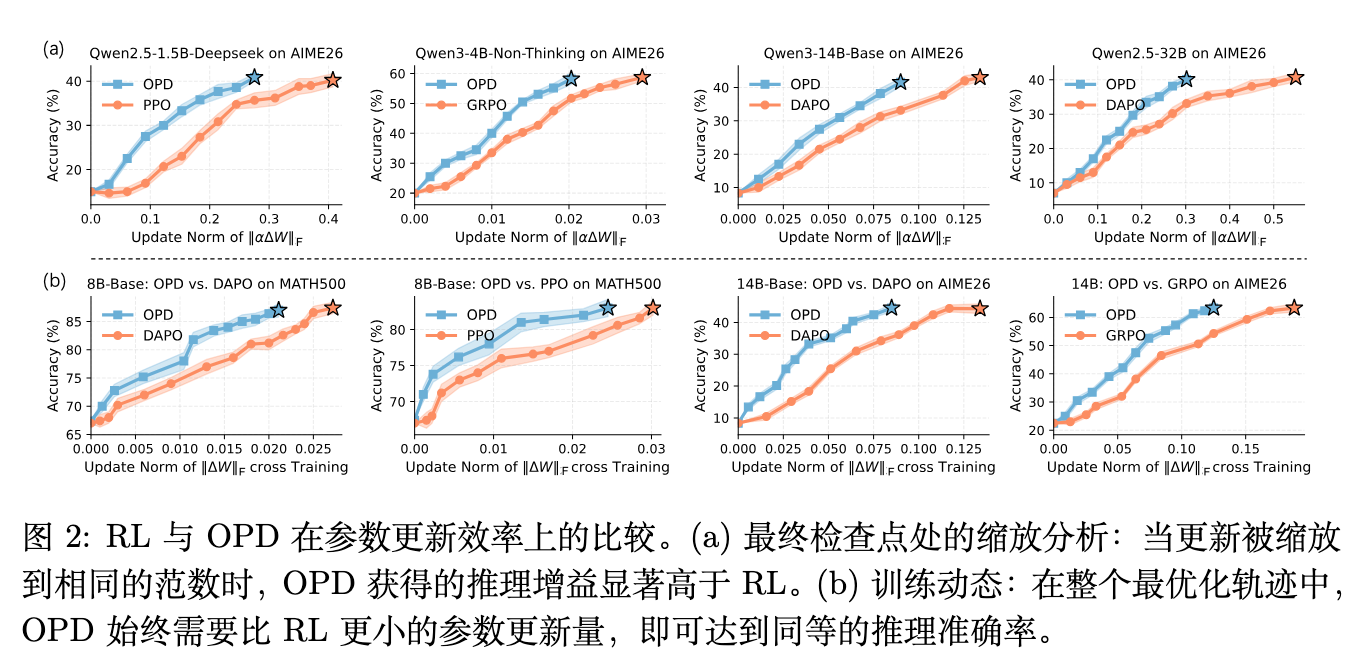
如图 2 (a) 所示,当更新范数被缩放到相同大小时,OPD 模型在数学数据集上的推理增益远高于 RL 模型。这表明 中包含了大量与任务性能弱相关的组件——它们增加了更新范数,但未能转化为对应的推理能力。而 OPD 的参数更新则更为紧凑,承载了比例更高的有效任务信号。图 2 (b) 进一步展示了整个训练轨迹中的动态关系:在达到相同的推理准确率时,OPD 所需的参数更新范数始终小于 RL,证明了这种高效率贯穿于整个优化过程。
2.2 定位冗余更新:滑动窗口干预分析
为确定 RL 中那些"与任务弱相关"的冗余更新发生在哪些具体模块,作者将模型更新解构为嵌入层(Embedding)、多层感知机(MLP)和注意力层(Attention)。
首先,将 OPD 和 RL 训练后模型的嵌入层替换回基础模型(Base Model)的嵌入层,保持其他参数不变。结果显示,这一干预对推理性能的影响微乎其微。这表明嵌入层的参数更新对推理能力增益的贡献极低。
随后,作者采用滑动窗口干预(Sliding-Window Intervention)方法,将局部更新注入到连续的网络层块中,以此隔离不同深度更新的边际功能贡献。对于层数为 的 Transformer,定义目标层 的滑动窗口为:
该公式表示一个以第 层为中心,向两侧各延伸 8 层的局部窗口。针对 MLP 模块的干预模型权重构造如下:
其中,除了窗口内的 MLP 模块使用训练后的更新权重,其余所有层的 MLP 和注意力参数均固定为 。
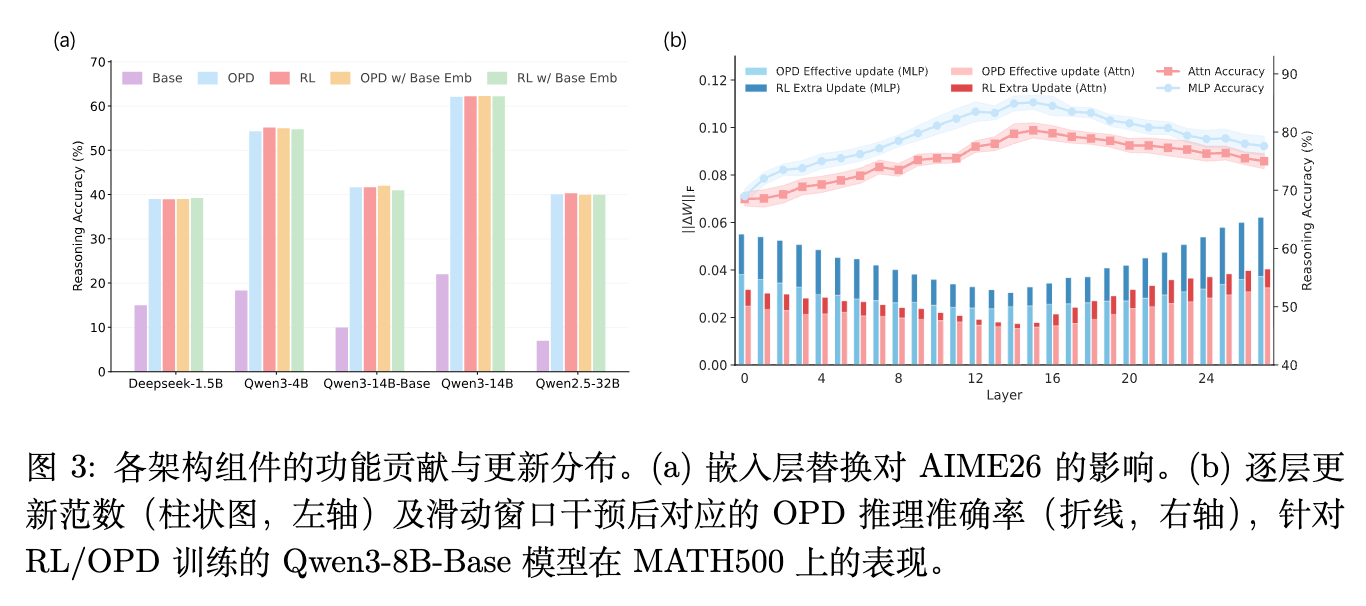
基于该干预方法的评估结果(如图 3 (b) 折线所示)呈现出明显的倒 U 型模式:对中间层模块的干预带来了最大的性能提升,而底层和顶层干预带来的改进较小。此外,MLP 模块的干预敏感度整体高于注意力模块,表明 MLP 是关系推理和知识表示的主要载体。
关键的对比在于层级更新范数(Layer-wise Update Norms)的分布(如图 3 (b) 柱状图所示)。RL 和 OPD 在各层的功能敏感度分布高度一致,说明两者依赖相似的底层功能路径。然而,RL 在低敏感度的底层和顶层引入了大幅度的参数变化;考虑到这些区域的干预收益极低,RL 在此处的更新大概率是与任务奖励弱相关的冗余探索。反观 OPD,其在保持相似功能分布的同时,大幅压制了外围层的参数变化,将更新更集中于高贡献的中间层 MLP。这种表现被作者定义为功能冗余回避(Functional Redundancy Avoidance)。
3. 预见性机制之二:更新方向的早期低秩锁定
除了模块分配上的紧凑性,作者进一步从几何视角剖析了参数更新矩阵的内在结构。
3.1 更新矩阵的谱浓度分析
对参数更新矩阵 进行奇异值分解(SVD):
其中 为奇异值。作者引入了四个互补的几何指标来量化更新结构的低秩特性:
-
谱范数(Spectral Norm, ):表征主导方向上的更新幅度。 -
谱范数与 Frobenius 范数比(Spectral / Frobenius Norm Ratio):,该值越接近 1,表明更新能量越集中于单一方向。 -
有效秩(Effective Rank):,其中 是归一化的奇异值。有效秩越低,表明奇异值衰减越快,能量越集中于低维子空间。 -
Top-1% 子空间范数占比(Top-1% Subspace Norm Ratio):即前 1% 奇异值对应的矩阵近似 的 Frobenius 范数与整体范数之比。
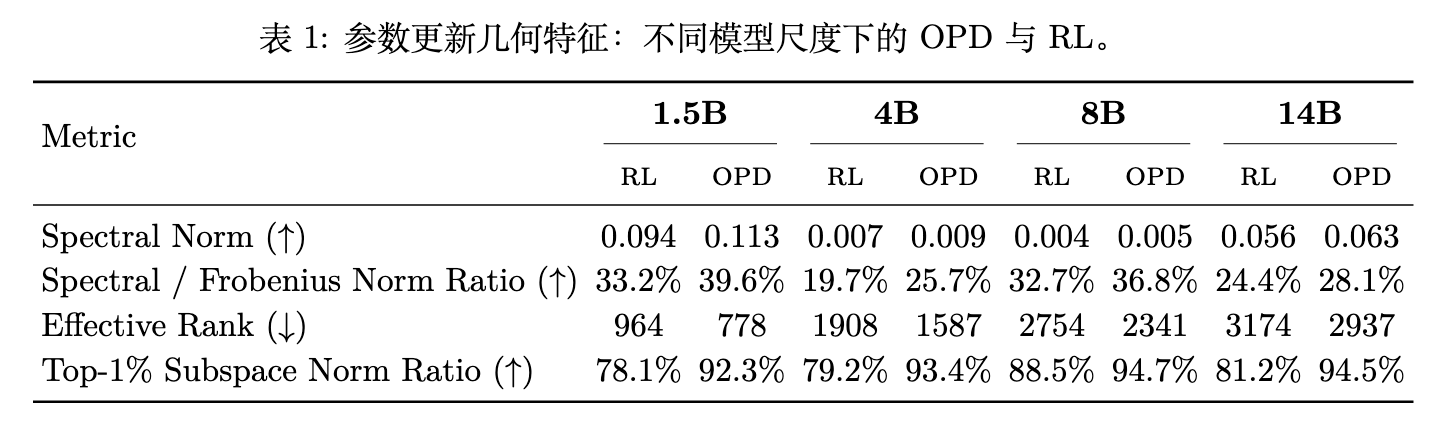
表 1 列出了跨多个模型规模(1.5B 到 14B)的统计结果。在所有规模下,OPD 表现出比 RL 更强的低秩结构。例如在 8B 模型上,OPD 的谱范数/F范数比达到 36.8%(RL 为 32.7%),有效秩降低至 2341(RL 为 2754),Top-1% 占比达到 94.7%(RL 为 88.5%)。这说明 OPD 能够更有效地将有限的更新预算分配到少数主导方向上。
3.2 子空间的截断与演化分析
为了验证低秩空间是否编码了真正的推理能力,作者构造了 Top-k% 和 Bottom-k% 的截断近似更新。对于 Top-k% 分析,在截断后重新缩放其范数,使 RL 和 OPD 的范数预算严格对齐。
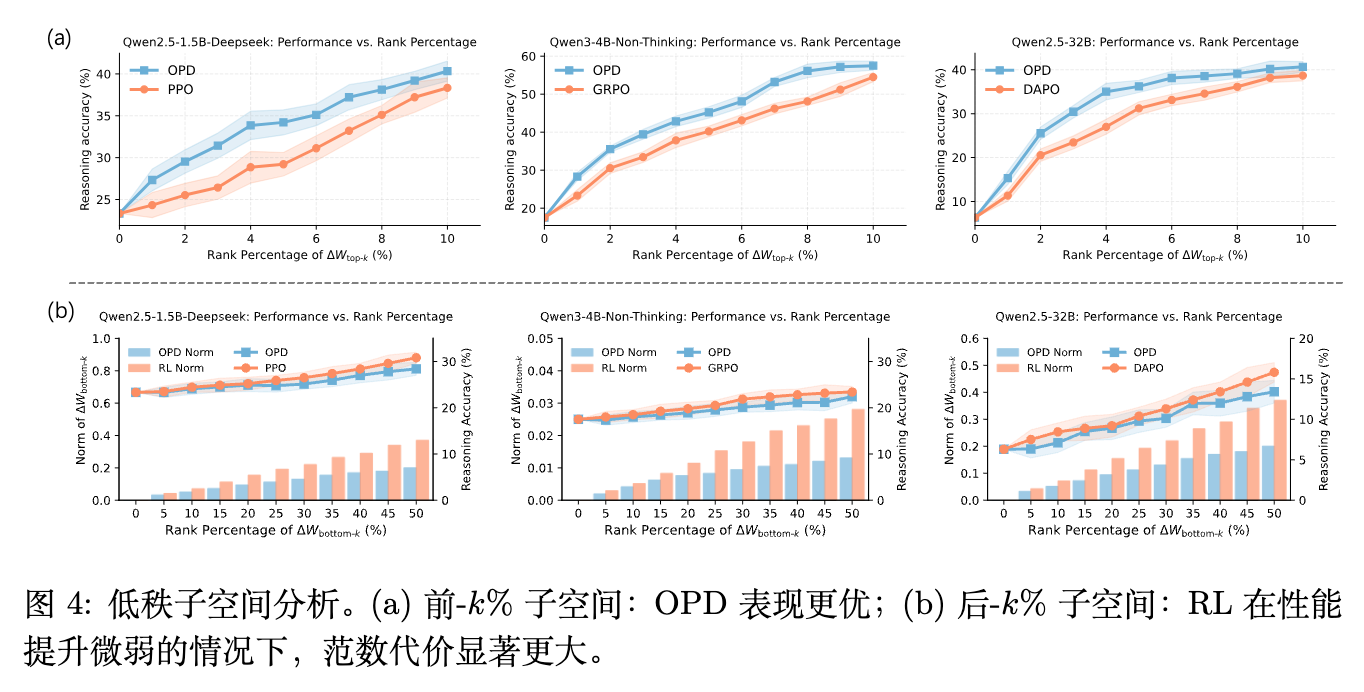
如图 4 (a) 所示,仅保留 10% 秩的 Top-10% 子空间即可恢复 95% 以上的全模型性能,证实了主成分是推理能力提升的核心载体。同时,在同等范数预算下,OPD 的 Top-k% 子空间性能始终优于 RL,说明 OPD 提取的主导方向本身具有更高的方向质量。相反,包含冗余维度的 Bottom-k% 子空间(尾部方向)对性能的边际贡献极低,而 RL 却在这些尾部方向上消耗了大量范数成本。
更重要的是时间维度的演化。作者计算了训练过程中每个中间步的 Top-k 子空间与最终收敛模型子空间的余弦相似度。
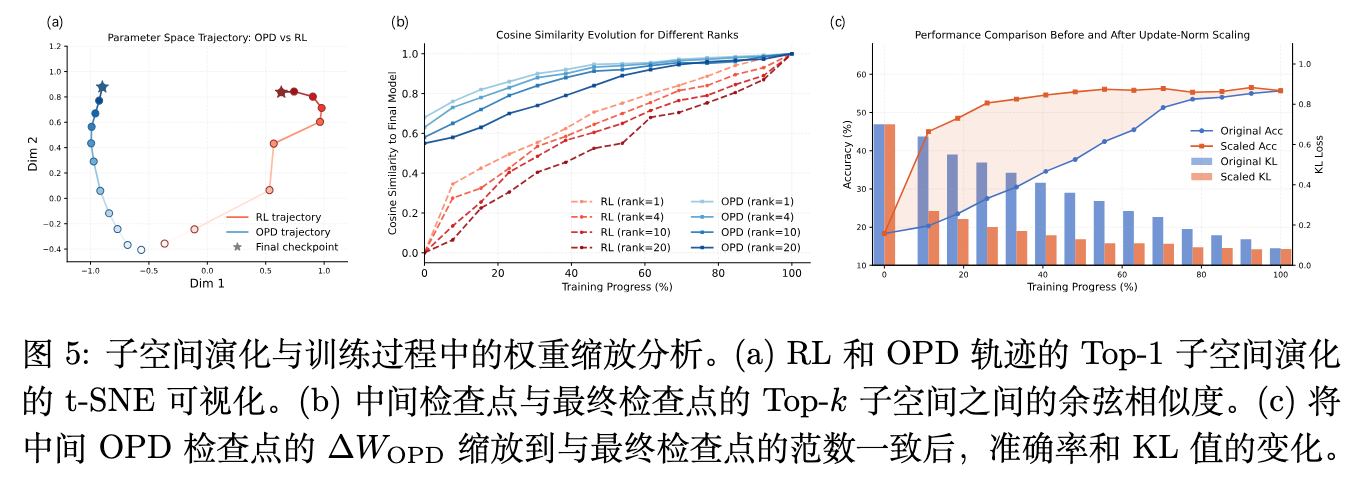
图 5 (b) 显示,OPD 在训练进度仅为 10% 到 30% 的极早期阶段,其前 个主导子空间就已与最终模型高度对齐(余弦相似度迅速攀升并保持稳定),而 RL 的子空间演化则伴随着滞后和剧烈的波动。
结合图 5 (c) 的权重缩放实验:如果在极早期的中间检查点上,保留其模块内部的更新方向,仅仅将 Frobenius 范数强制放大至与最终检查点一致,此时 10% 进度的模型可以直接恢复约 80% 的最终推理性能,同时与教师模型的 KL 散度也会同步下降。这证实了 OPD 的训练轨迹存在早期低秩锁定(Early Low-Rank Lock-in)现象:早期阶段已经找到了正确的方向组合,后续训练不过是在这些方向上积累幅度,而非进行大范围的方向调整。
4. 局部几何视角下的 OPD 动力学解释
为了从理论层面解释为什么 OPD 会自然诱导功能冗余回避和早期低秩锁定,作者在参数空间围绕基础模型进行了局部二次近似(Local Quadratic Approximation)分析。
设输入上下文为 ,学生模型逻辑值为 ,固定教师模型逻辑值为 。在初始权重 附近进行一阶展开:
其中 是逻辑值对参数的雅可比矩阵。定义教师-学生的逻辑值残差为 。
OPD 的优化目标是最小化在线样本上的逆 KL 散度:
通过在逻辑值空间进行二阶泰勒展开,逆 KL 散度局部可近似为一个加权的二次型。由于 KL 散度在 处的 Hessian 矩阵恰好为学生分布的 Fisher 信息矩阵 ,可得局部期望目标函数:
将其展开后,忽略常数项,局部目标成为一个凸二次规划问题:
其中 为曲率矩阵,驱动项 描述了经过 Fisher 矩阵加权后的残差在参数空间的投影。
推论 1:模块级的冗余抑制。 将参数划分为不同模块,如果某模块 (如嵌入层)对应的驱动项 (即该模块的参数梯度与教师需要纠正的残差耦合极弱),那么该模块的更新 将趋近于 0,这就从数学上解释了为什么 OPD 会自动抑制无用模块的更新。
推论 2:方向演化的谱动力学。 对该二次型应用固定步长 的梯度下降,其闭式解的谱分解形式为:
其中 分别是曲率矩阵 的特征值和特征向量, 是驱动项 在方向 上的投影。
从该闭式解可以看出,更新增量由因子 控制。对于曲率 较大的方向(即逻辑值对该方向参数变动极敏感的方向),该因子会以指数级速度快速趋近于 1。这意味着主导特征方向在有限训练步数 的极早期就会被快速激活并锁定。只要驱动信号 集中在低维子空间,后续的梯度下降就不会向无关的高维空间发散,这就解释了早期低秩锁定现象。
而在强化学习中,每步参数更新主要由标量优势函数驱动:
不仅优势函数由于序列稀疏奖励而具有高方差,其驱动向量空间满秩且发散,难以形成 OPD 那样通过 产生的致密、低秩的学习信号。
5. 解决方案:EffOPD 加速框架
前文发现,OPD 在训练早期就能建立高度稳定、指向最终解的更新方向。此时,如果继续使用标准 SGD 进行微调,模型只是在相同的低秩子空间内缓慢积累步长,效率低下。为此,作者提出了 EffOPD(Efficient OPD),一种基于早期方向外推的加速框架。
EffOPD 在指数衰减的训练检查点(例如 )触发外推搜索。设当前第 次外推点的参数为 ,其前一次为 ,定义当前的局部近似更新方向为:
由于 OPD 更新方向的高度稳定性, 可作为后续全局更新方向的良好估计。EffOPD 沿该方向生成 5 个具有递增步长外推尺度的候选参数组:
为了防止过激的外推损害模型性能,EffOPD 引入了一个仅包含 50 个训练集样本的小型验证集 。在生成这些候选权重后,算法会在验证集上计算其验证得分(如困惑度或奖励得分)。按 从大到小测试,一旦找到使得 的最大步长 ,算法就会立即接受该参数并覆盖当前模型,从而跳过大量中间训练迭代:
如果 都未能通过验证,算法则直接退化为标准的 Vanilla OPD 步骤。这使得 EffOPD 兼顾了激进加速与训练稳定性。
6. 实验结果与分析
作者在代码生成(Eurus-RL-Code)和数学推理(DeepMath-103K)数据集上开展了大规模实验。基础模型覆盖从 1.5B 到 32B 的多个尺度(Qwen2.5-1.5B/7B/32B, Qwen3-4B/8B/14B)。作为基线的教师模型则是各自经过 RL 训练对齐的版本。参与对比的基线方法包括 Vanilla OPD、AlphaOPD 以及 ExOPD。
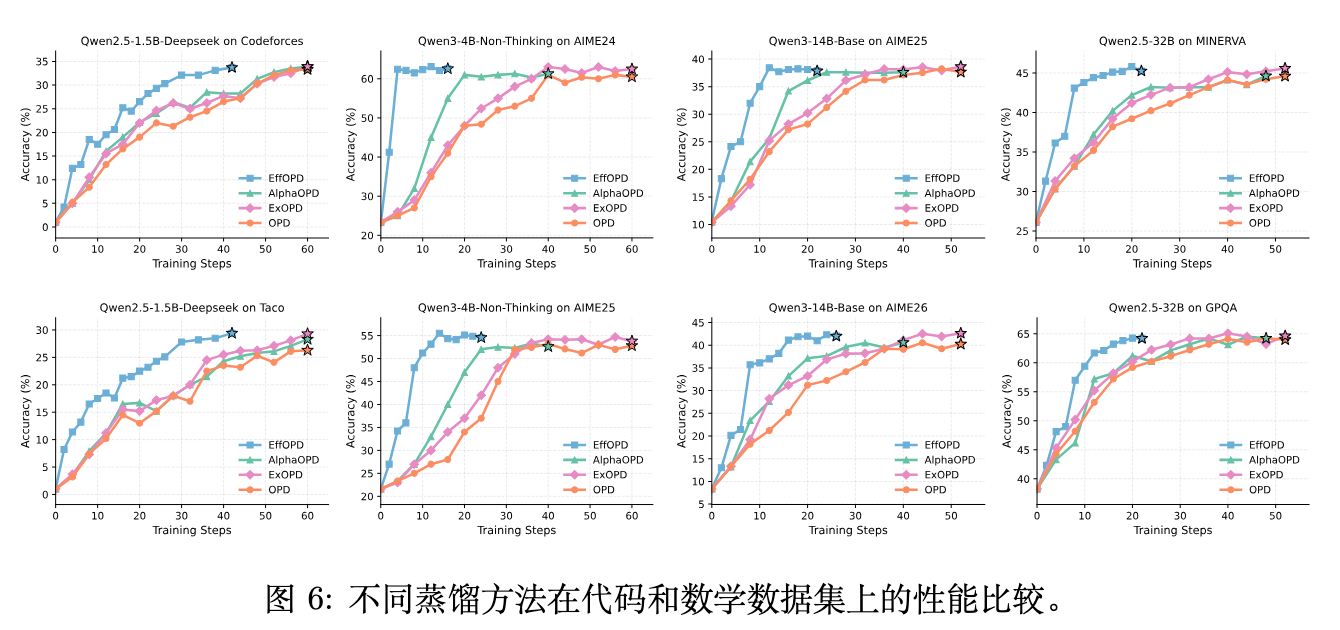
训练加速结果: 如图 6 所示,EffOPD 在所有模型规模和数据集上均展现出一致的训练效率提升。在数学推理任务上,标准 OPD 通常需要 30 到 40 个步骤才能收敛,而 EffOPD 仅需大约 10 个训练步数即可达到同样的性能平台,实现了超过 3 倍的加速比。在 Qwen3-4B 等模型上,其在第 4 步就已获得极高的推理性能,进一步佐证了"有效方向在早期形成"的假设。并且,EffOPD 在大部分任务上达到了更高的性能上限,原因在于长周期的标准蒸馏可能会导致过度优化(Over-optimization)或语义漂移,而 EffOPD 的快速外推规避了这一风险。
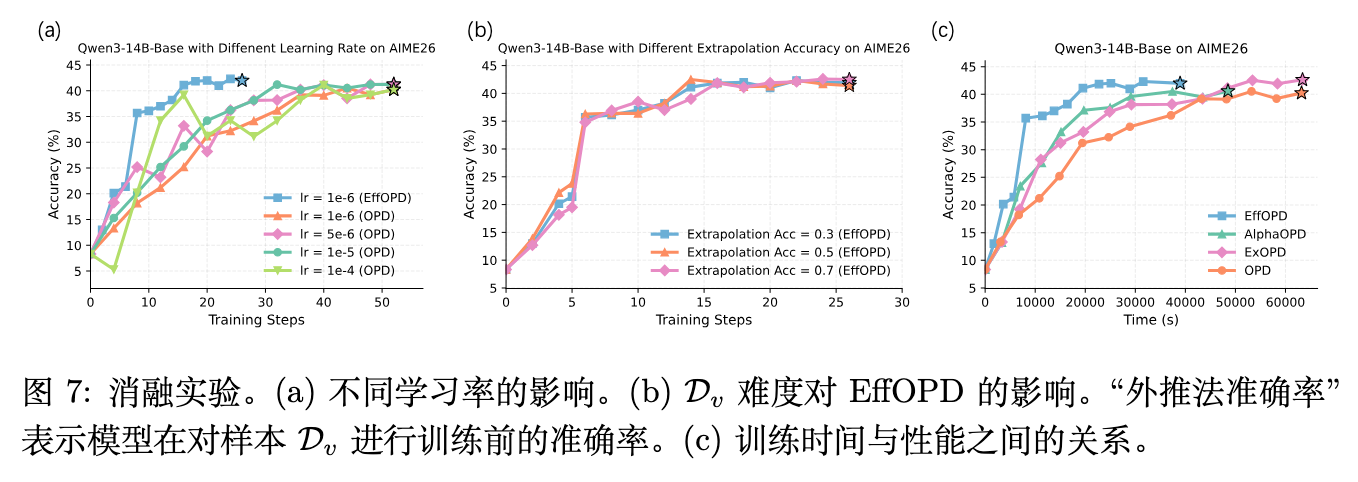
消融与稳定性分析: 为了验证组件必要性,图 7 对 EffOPD 进行了详尽消融。图 7 (a) 表明,强行调大标准 OPD 的学习率虽然能加快早期收敛,但会导致严重的指标震荡与不稳定。相反,EffOPD 借助轻量级的验证集自适应过滤掉激进外推,保证了稳定加速。图 7 (b) 探讨了轻量验证集难度的影响,结果显示使用不同难度的验证集依然能给出一致的方向信号反馈,这说明验证过程的本质是检查当前更新方向是否仍然有效,而非提供极其精确的全量监督。图 7 (c) 则展示了真实墙上时间(Wall-clock time)的对比。虽然额外评估 50 个验证样本带来了轻微的计算开销,但由于跨越了大量训练迭代,EffOPD 在相同的计算时间预算内性能大幅领先。
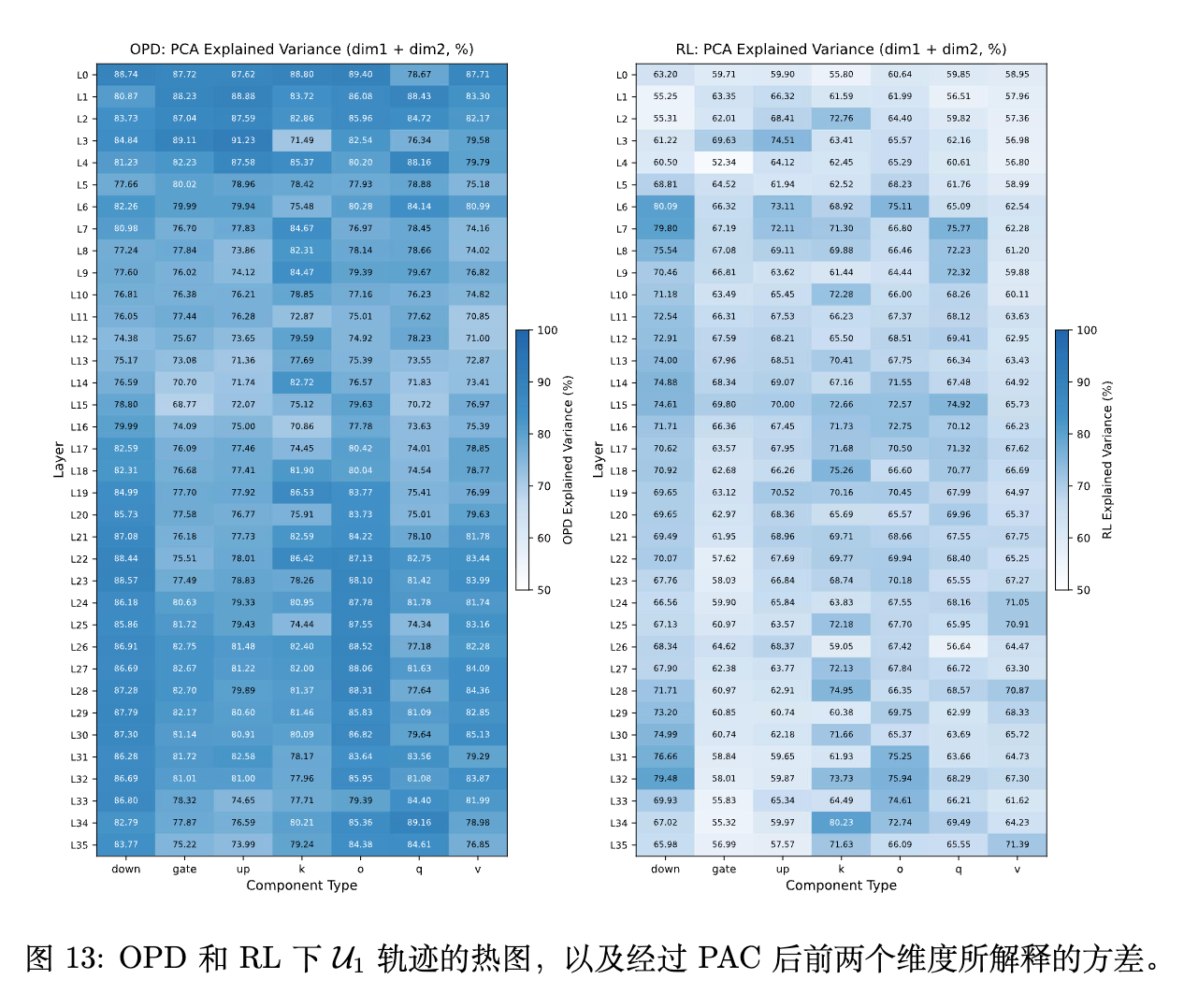
(注:论文附录提供的 PCA 轨迹可视化量化了 OPD 演化轨迹的高度集中性,相较于 RL 更平滑、更集中。)
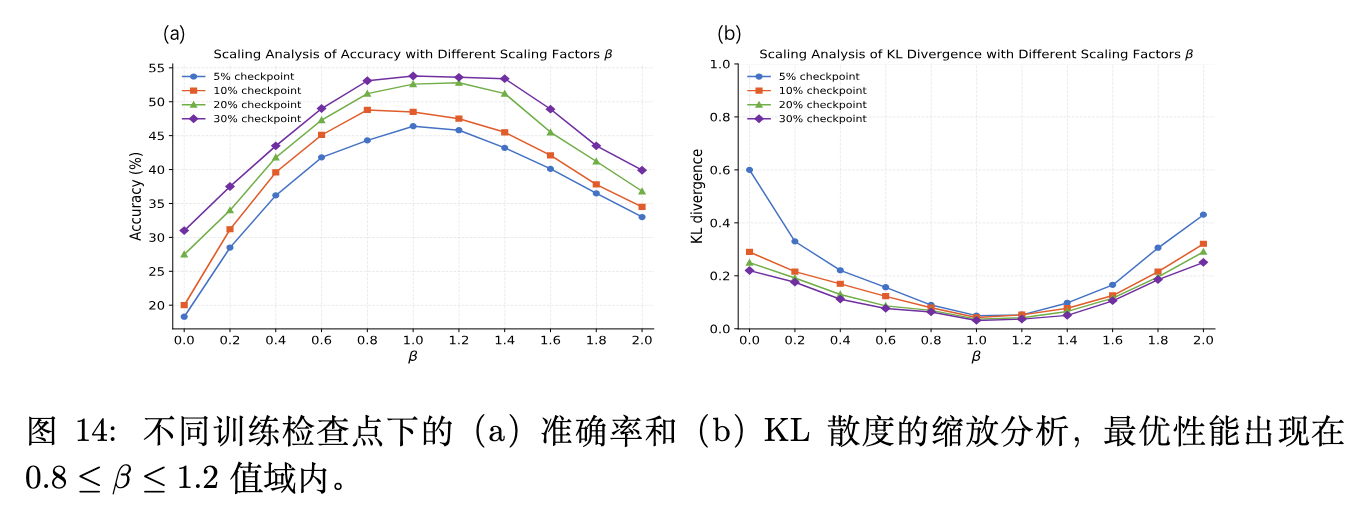
(注:缩放系数验证了在适度范围内放大早期模型权重,准确率上升且 KL 散度下降;过度缩放则放大噪声导致崩溃。)
7. 讨论与总结
本文从微观参数更新动态的视角,重新审视了大型语言模型中在线蒸馏(OPD)优于强化学习(RL)的物理本质。研究发现,OPD 具备独特的前瞻性预见机制:在模块级别,它自动回避功能冗余区域,向推理关键层倾斜;在方向级别,它能在早期锁定正确的低秩子空间并持续巩固。得益于这种结构化演化,作者提出的 EffOPD 仅通过低成本验证加方向外推,便实现了 3 倍的即插即用加速。
局限性与未来工作探讨:
正如论文在附录中所述,目前的理论分析依然建立在基础模型邻域的局部几何近似(Local Quadratic Approximation)上,未能完全捕捉大语言模型参数空间中非凸优化的全局行为。同时,在多轮智能体任务(Multi-turn Agent Tasks)以及多模态推理场景下,分布偏移和残差结构可能更加复杂,OPD 的低秩锁定属性是否能完美迁移,还有待进一步验证。然而,这一从"参数演化谱特征"来优化后训练效率的视角,无疑为设计更透明、更自适应的对齐算法指出了新的路径。
更多细节请阅读原论文。

