让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
-
论文链接:https://arxiv.org/pdf/2603.17024
TL;DR
今天解读由 Qwen 团队和清华大学发表的论文《HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning》。该研究针对视觉-语言模型(VLMs)在长思维链(CoT)推理中出现的感知、推理、知识和幻觉等复合错误问题,提出了一种名为 HopChain 的多跳视觉-语言推理数据合成框架。该框架通过四个阶段(类别识别、实例分割、多跳查询生成、人工与模型验证)自动生成具有逻辑依赖关系的训练数据,使模型在推理过程中必须反复在图像中进行视觉定位(Visual Grounding)。使用带有可验证奖励的强化学习(RLVR)与软自适应策略优化(SAPO)算法,研究团队在 Qwen3.5-35B-A3B 和 Qwen3.5-397B-A17B 模型上进行了实验。结果表明,加入多跳合成数据后,模型在 24 个基准测试中的 20 个上取得了得分提升,尤其在超长 CoT 推理场景中表现明显。
1. 引言
在当前的大模型研究领域,视觉-语言模型(Vision-Language Models, VLMs)通过整合视觉编码器与大型语言模型(LLMs),已经在多模态基准测试中展现出基础的感知与对话能力。先前的模型如 LLaVA、InternVL、Qwen-VL 等,确立了将视觉特征投影到语言模型嵌入空间的标准架构。在此基础上,研究社区开始将自然语言处理领域中行之有效的对齐与强化学习技术引入多模态领域。
带有可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)近期成为提升模型推理能力的重要技术路径。与依赖人类反馈的强化学习(RLHF)不同,RLVR 不需要额外训练一个奖励模型(Reward Model),而是通过客观可验证的答案(例如数学题的最终数字、选择题的固定选项)来提供确定性的奖励信号。这种范式在 DeepSeek-R1 等纯文本大语言模型中诱发了长链条的推理(Chain-of-Thought, CoT)能力,随后也被扩展应用到 VLMs 中。
然而,视觉-语言模型在执行细粒度的多步推理时依然存在结构性障碍。正确的答案往往需要模型多次、准确地关注图像中的多个视觉元素及其空间与逻辑关系。当前大多数用于 RLVR 训练的视觉-语言数据并没有包含依赖持续视觉证据的复杂推理链条。这就导致现有的训练范式难以充分暴露并修正模型在长推理链条下的弱点。HopChain 论文正是为了填补这一数据层面的空白而提出的。
2. 核心动机:长思维链推理中的复合故障模式分析
要理解 HopChain 的设计逻辑,首先需要分析当前 VLMs 在多模态推理中的失败原因。论文在第 3 节中提出了一个核心观察:视觉-语言模型在进行长链条推理时,会暴露出多维度的复合故障模式。
2.1 故障的分类
在长链条推理中,模型需要不断地回到图像中寻找正确的对象、属性、关系或数值证据。一旦在中间某个步骤出现错误,后续的推理虽然在语言逻辑上可能保持连贯,但其实是建立在错误的中间证据之上的。论文将这些错误归纳为以下几类:
-
感知错误(Perception Errors):这是占比最高的一类错误。模型可能无法正确识别图像中的细粒度物体、颜色、形状或位置。例如,未能正确清点密集排列的小物体,或者误判了图表中的线条走向。 -
推理错误(Reasoning Errors):模型在感知正确的情况下,未能应用正确的逻辑关系。包括空间位置推理错误、数学计算错误、时间或因果关系推理错误等。 -
知识错误(Knowledge Errors):模型缺乏与图像内容相关的外部常识或专业背景知识。 -
幻觉错误(Hallucination Errors):模型在长文本生成过程中,脱离了图像提供的视觉依据,编造了不存在的对象或属性。这种现象在多模态语境下常被称为“视觉错觉”或“对象幻觉”。
2.2 故障的级联与复合
论文中给出了三个典型的错误案例(参见图 3),这些案例涵盖了自然图像、图表和科学示意图:

-
瓢虫计数案例:模型需要计算所有瓢虫身上的斑点总数。基准模型在中间某一个区域(如左下角、右下角)的斑点计数出现了偏差(感知错误)。尽管其最终的加法计算逻辑是正确的,但由于中间数值输入错误,导致最终结果错误。 -
天文图表案例:图表中存在多条弧线和箭头指示。基准模型误判了箭头所指的具体弧线位置(感知错误),导致后续对季节的判断完全基于错误的前置条件。 -
斑马条纹案例:模型被问及斑马水平条纹的比例。基准模型在观察局部区域后,直接判断垂直条纹为主导模式,忽视了其他部位的水平条纹(推理/感知截断错误),最终得出 0% 的错误结论。
这些案例表明,长思维链错误具有耦合性而非孤立性。一个微小的视觉判断失误会触发错误的推理推导和无根据的推断。
2.3 现有训练数据的局限性
当前开源或常见的视觉-语言训练数据(包括早期的 RLVR 数据)大多只包含单步或浅层推理问题。模型可以通过捕捉语言上的快捷方式(Shortcuts)或仅凭一次粗略的图像感知就能猜出答案。这种数据结构无法强迫模型在生成思维链的每一步都去重新对齐视觉证据(Visual Re-grounding)。因此,单纯增加现有类型数据的数量,无法从根本上解决模型在长链条推理中的视觉漂移和幻觉放大问题。
3. 什么是多跳视觉-语言推理?
为了构建能够解决上述问题的数据,论文明确定义了“多跳视觉-语言推理”的结构。该定义将推理过程划分为不同的层级,并对问题生成施加了严格的约束。
3.1 推理层级定义
论文定义了三个推理层级:
-
Level 1(单对象感知):涉及读取文本、识别单个对象的属性(如颜色、形状、大小、位置、类别)。这是一个基础的视觉提取步骤。 -
Level 2(多对象关系感知):涉及多个对象之间的空间关系、比较关系或满足特定条件的计数任务。例如“比较 A 和 B 的大小”、“计算位于 C 左侧且满足条件的物体数量”。 -
Level 3(多跳推理):将多个 Level 1 和 Level 2 的步骤串联成一个单一的查询(Query)。这是本文的核心生成目标。
3.2 多跳推理的两个维度
在一个 Level 3 的查询中,连续的跳跃(Hops)必须在以下两个维度上建立联系:
-
感知层级的跳跃(Perception-level hop):下一步的推理任务需要改变感知类型。例如,从 Level 1 的单对象属性判断切换到 Level 2 的多对象比较,再切换回单对象属性读取。这种跳跃需要模型在不同类型的认知任务间灵活切换。 -
实例链条的跳跃(Instance-chain hop):这是一种明确的依赖链条(如实例 A B C)。下一步需要操作的实例,必须且只能通过前置步骤确立的实例、集合或条件来定位。这意味着模型不能一开始就找到所有对象,必须按照步骤去图像中按图索骥。
3.3 针对 RLVR 的结构约束
由于生成的数据将用于强化学习,最终答案必须是客观可验证的。因此,HopChain 规定所有的查询必须满足以下条件:
-
必须结合感知层级跳跃和实例链条跳跃。 -
早期步骤确立的实例或条件必须是后续步骤的先决条件。 -
每一个查询必须以一个具体的、无歧义的数字作为最终答案。
数字答案的约束使得 RLVR 的奖励函数易于实现。同时,由于推理步骤之间存在逻辑依赖,只有在所有中间推理步骤都正确的情况下,模型才能得出正确的最终数字。这种机制有效地阻断了模型试图通过语言捷径(Language-only shortcuts)绕过视觉感知的可能性。
4. HopChain 数据合成框架深度剖析
基于上述定义,研究团队开发了一个可扩展的四阶段数据合成流水线。该流水线输入原始图像,输出带有确定性数字答案的多跳推理数据集,流程参见图 1。
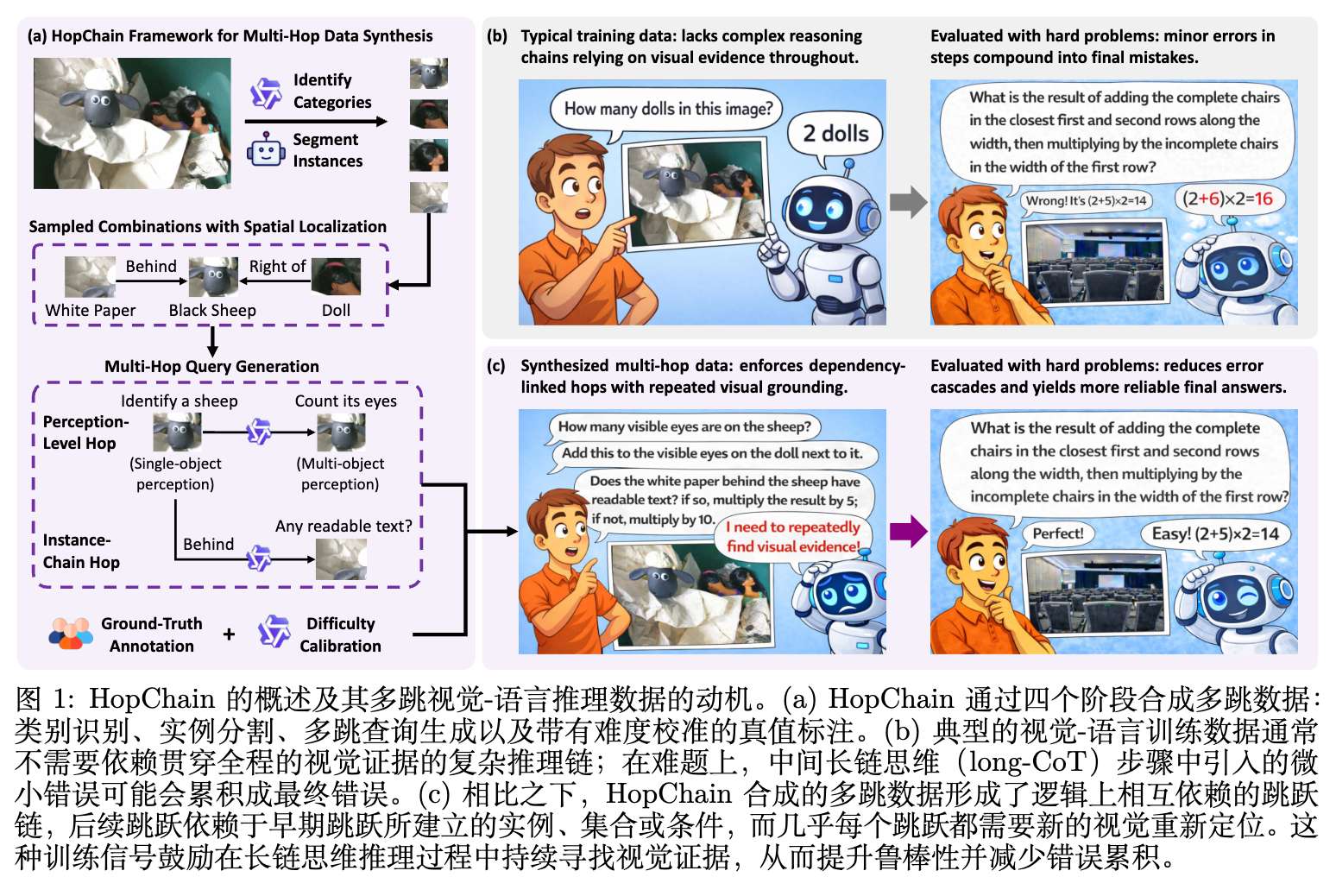
4.1 阶段一:类别识别
在构建复杂查询之前,系统需要知道图像中存在哪些可以作为推理节点的实体。
-
操作方式:将输入图像输入给 Qwen3-VL-235B-A22B-Thinking 模型。 -
目标:识别图像中存在的语义类别。 -
输出:一个语义类别的列表(例如:“car”, “person”, “sign”),此时不需要进行空间定位。
4.2 阶段二:实例分割
多跳推理必须锚定在具体的对象上,而不能仅仅依赖宽泛的类别标签。
-
操作方式:利用 Segment Anything Model 3 (SAM3) 处理阶段一提取出的语义类别。 -
目标:为图像中的候选实例生成分割掩码(Segmentation Masks)和边界框(Bounding Boxes)。 -
输出:一组具有明确空间定位的独立实例集合。此时,系统掌握了图像中各个实体的具体坐标和像素范围。
4.3 阶段三:多跳查询生成
这是该框架的核心步骤。系统需要将识别出的孤立实例转化为能够强制执行链式视觉推理的训练问题。
-
输入准备:系统从阶段二获取的实例中组合出 3 到 6 个实例。对于选定的组合,提取原图以及每个实例的裁剪图块(Cropped patches)。这些裁剪图块仅在生成阶段提供给大模型,帮助其确认每个实例的外观和位置,但在最终训练时,正在训练的模型只能看到原图,无法看到这些裁剪图块或边界框。 -
生成模型:采用 Qwen3-VL-235B-A22B-Thinking。 -
约束条件:论文在生成提示(Prompt)中施加了多重约束,以避免合成数据出现缺陷: -
尽可能多地包含选定组合中的实例。 -
所有的查询必须仅基于原图回答。 -
只能通过空间关系、上下文关系或视觉属性来描述对象,不能在题目中出现任何关于分割掩码、边界框坐标或图像块的文字引用。这防止了数据泄露捷径。 -
必须以一个具体、无歧义的数字结束。 -
必须形成逻辑依赖链,前置步骤确立条件,后续步骤加以应用。图 4 展示了合成数据的典型样貌。例如,查询要求模型首先定位左侧的黑羊玩具并计算其眼睛数量,然后找到位于其后方的白纸判断是否有文字,接着寻找右侧的娃娃,读取其前方的英文字符,最后进行一系列的数学运算得出最终数字。这种查询迫使模型在长文本生成过程中,不断将注意力焦点在图像的不同区域间转移。
-

4.4 阶段四:人工标注与难度校准
为了保证 RLVR 训练信号的纯净性,必须剔除低质量的生成数据,并确保标注绝对准确。
-
人工标注过滤:由数据标注团队的四名标注员独立解答每一个生成的查询。如果查询存在指代不明或其他质量问题,标注员会上报并废弃该查询。对于通过验证的查询,只有当四名标注员独立得出的数字答案完全一致时,该答案才会被采纳为最终标签。 -
基于模型的难度校准:保留下来的查询会在一个较弱的模型上进行测试,每个查询采样 8 次响应。如果该弱模型对某个查询的 8 次采样全部正确(准确率 100%),则认为该查询过于简单,从数据集中剔除。剩下的查询构成了最终带有难度验证和可靠标签的数据集。
4.5 图像过滤预处理流水线
并非所有图像都适合用来合成复杂的多跳推理数据。在进入阶段一之前,团队实施了一个两阶段的图像过滤流程:
-
初始筛选:设计特定的 Prompt,利用 Qwen3-VL-235B-A22B-Thinking 对少量图像子集进行打分。偏好的图像包含遮挡、密集但可分析的物体、不寻常的姿态、复杂的交互、细粒度的区分或具有挑战性的光照;剔除分辨率过低或过于混乱无法标注的图像。 -
小模型蒸馏与过滤:将上述初步筛选的图像及大模型输出作为监督微调(SFT)数据,训练一个专门用于过滤图像的小模型(Qwen3-VL-30B-A3B-Thinking)。使用该小模型对海量图库进行粗筛。粗筛保留下来的图像再送入 235B 的大模型进行二次精细筛选。这种方法平衡了筛选质量与计算吞吐量。
最终,该流水线为 Qwen3.5 系列模型生成了约 6k 到 8k 的高质量多跳 RLVR 样本。
5. 强化学习与训练设置
论文利用合成的多跳数据对模型进行强化学习微调。在此过程中,采用了带有软自适应策略优化(SAPO)的强化学习算法。
5.1 RLVR 的目标函数
对于视觉-语言模型的强化学习,模型接收图像 和文本查询 作为输入,生成包含思维链的文本响应 。最终基于答案 计算奖励信号。优化目标为最大化预期奖励:
其中,奖励函数 的定义如下:
这里 是数据集分布, 是以 和 为条件的生成策略。由于 HopChain 生成的问题以确定的数字结尾,is_equivalent 函数可以直接通过匹配最终的数字输出与真实标签来评判对错,无需额外的奖励模型。
5.2 软自适应策略优化
传统的强化学习算法如 PPO 及其变体,常使用硬裁剪(Hard Clipping)机制来限制策略更新幅度。近期的算法如 GRPO 和 GSPO 利用组内优势估计。为了缓解硬裁剪可能带来的训练不稳定性与低效性,论文采用了 SAPO 算法。SAPO 使用温度控制的软门控(Soft Gate)机制替代硬裁剪,其优化目标可表示为:
在这个公式中,涉及到以下几个关键组成部分:
-
概率比率 :
衡量当前策略 与旧策略 之间的概率比:
-
优势估计 :
在组内(Group size 为 )计算标准化的奖励优势。由于是最终状态奖励,所有 token 共享相同的序列优势 :
-
软门控函数 :
通过 Sigmoid 函数 实现软截断。温度参数 根据优势函数的正负进行调整( 或 ):其中,
这种设计允许梯度在偏离时平滑衰减,而不是生硬地截断,有助于模型在探索长思维链推理空间时保持稳定。
5.3 模型配置与训练超参数
实验选取了两个规模的模型作为验证基础:
-
Qwen3.5-35B-A3B(较小规模,便于快速迭代) -
Qwen3.5-397B-A17B(超大规模参数,用于验证方法的上限)
训练设置了三个对比版本:
-
Before RLVR:仅经过 SFT,尚未进行强化学习的版本,作为基线。 -
RLVR w/o Multi-Hop:仅使用原始 RLVR 数据(通常包含数学、科学等结构相对简单的视觉任务数据)进行训练。 -
RLVR w/ Multi-Hop:使用原始 RLVR 数据 + HopChain 合成的多跳数据组成的混合数据进行训练。
在超参数方面:
-
对于 35B 模型:每个 query 采样 16 个响应,batch size 为 64,训练 1000 步。 -
对于 397B 模型:由于算力考量,batch size 设置为 128,训练 800 步。 -
学习率统一设定为 。 -
除了合成的 6k-8k 图像多跳数据外,还混合了等量的数学 RLVR 数据。
6. 实验设计与核心结果解读
研究团队在 4 大类,总计 24 个基准测试集上进行了全面的评估。这四大类包括:
-
STEM and Puzzle:例如 MathVision, MMMU Pro, MMMU, Mathvista(mini) 等。这类任务需要深度逻辑与数学推导。 -
General VQA:例如 MMBench, RealWorldQA, MMStar 等,涵盖广泛的视觉问答场景。 -
Text Recognition and Document Understanding:如 CharXiv, DocVQA, InfoVQA 等,考察模型对密集文本和文档结构的解析。 -
Video Understanding:如 VideoMME, VideoMMMU, MVBench 等,测试跨模态和时序信息理解能力。
6.1 主实验结果分析
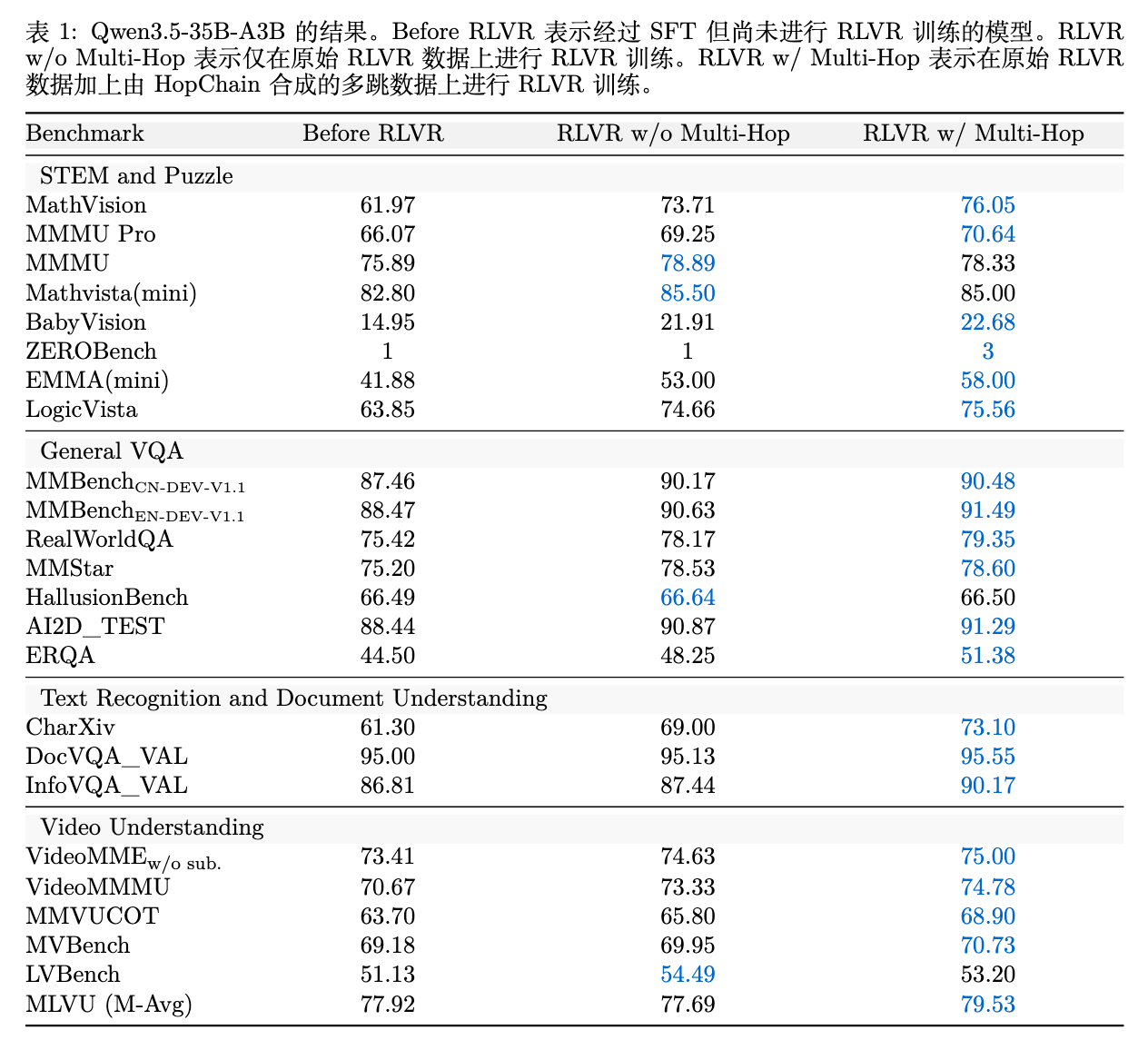
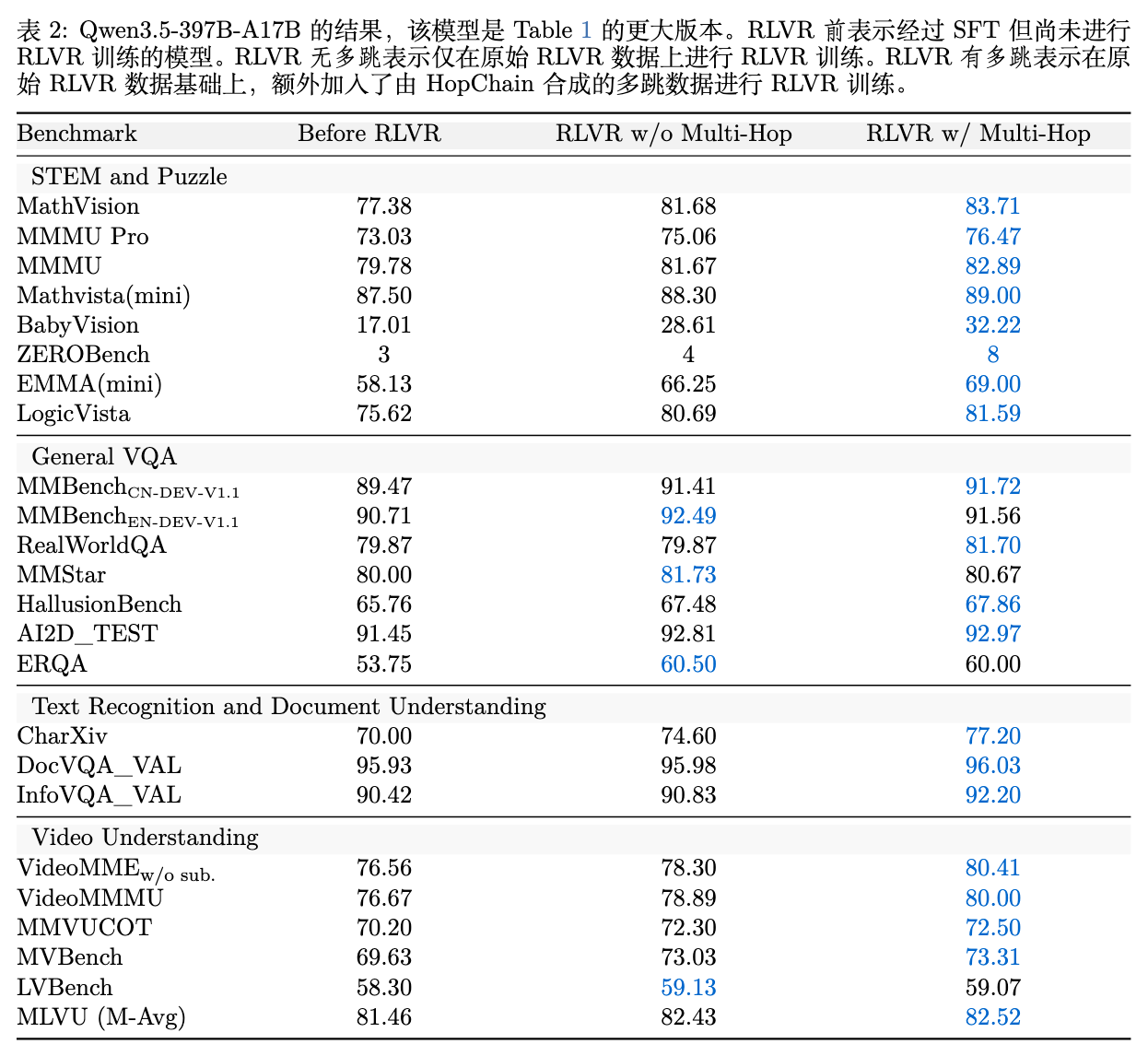
表 1 和表 2 展示了完整的数据。
-
广泛的通用性提升:与 RLVR w/o Multi-Hop相比,添加了多跳数据的RLVR w/ Multi-Hop在两个规模的模型上,均在 24 个基准测试中的 20 个取得了得分提升。值得强调的是,HopChain 合成的数据并未针对任何特定的下游 Benchmark 进行适配(Benchmark-agnostic),这种提升表明该数据切实增强了模型底层的通用视觉-语言推理能力,而非过拟合特定任务。 -
STEM 与复杂推理任务的进步:对于 35B 模型,STEM 类的 8 个测试中有 6 个获得提升(对于 397B 模型则是 8 个全部提升)。比如在 MathVision 上,35B 模型从 73.71 提升至 76.05,397B 模型从 81.68 提升至 83.71。 -
跨模态迁移能力:一个值得关注的结果是,在视频理解(Video Understanding)任务中,该方法在 6 个视频基准中提升了 5 个。虽然 HopChain 的合成数据完全来源于静态图像,但其强化模型持续寻找视觉证据(Grounding)的训练信号,成功迁移到了视频帧的时序推理中。 -
文档理解能力:CharXiv(图表解析)得分在 35B 模型上从 69.00 提升至 73.10,397B 模型上从 74.60 提升至 77.20。这种任务通常需要模型多次在图例与数据轴之间横跳,与多跳数据的结构高度契合。
7. 消融实验与深度分析
为了证明 HopChain 提出的复杂结构约束是必要的,团队进行了细致的消融实验。
7.1 跳数结构的消融(Ablation on Hop Structure)[图 5 训练查询设置在五个基准测试上的对比] 展示了保留不同长度查询带来的影响。研究人员比较了三种训练数据构造方式:
-
RLVR w/ Single Hop:将每一个多跳查询简化,剥离所有前置推理,仅保留最终一跳的问题。 -
RLVR w/ Half-Multi-Hop:截断查询,删去前半部分的推理链,只保留后半部分。 -
RLVR w/ Multi-Hop:保留完整的长链条复杂查询。
这三个模型在 MathVision, MMMU Pro, RealWorldQA, ERQA 和 VideoMMMU 这五个代表性基准上进行了评测。结果显示存在清晰的性能阶梯:完整的多跳查询表现最好(平均 70.4),其次是一半多跳(平均 66.7),单跳结构最差(平均 64.3)。
这从侧面证实了,压缩训练查询会导致模型失去处理复杂跨步依赖(cross-hop dependencies)的训练信号。长链条强制要求模型维持中间状态并依据中间结果继续探索图像,这正是性能增益的核心来源。
7.2 按推理长度的分析
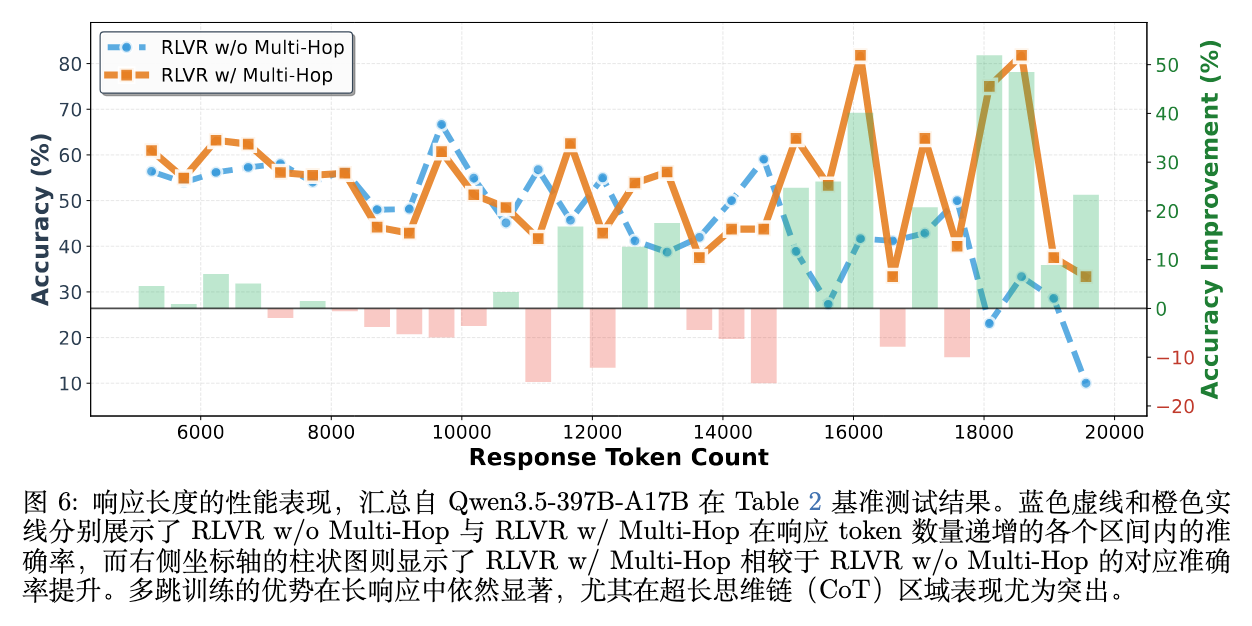
如果 HopChain 确实强化了长思维链能力,那么在生成较长响应的场景下,它的优势应该更为明显。
在图 6 中,研究者根据模型输出的 Token 数量对样本进行了分组。蓝色虚线(未加多跳)与橙色实线(加多跳)的对比清晰表明:在短响应区间,两者的差距不大;但随着响应 Token 数量的增加(例如 10,000 到 20,000 Token 的超长 CoT 区间),RLVR w/ Multi-Hop 保持了更高的准确率,其相对提升幅度(图中的柱状图)也达到峰值(部分区间提升超过 50 个百分点)。这一数据证实了该方法能有效降低模型在漫长生成过程中的视觉漂移率。
7.3 模型难度的覆盖度
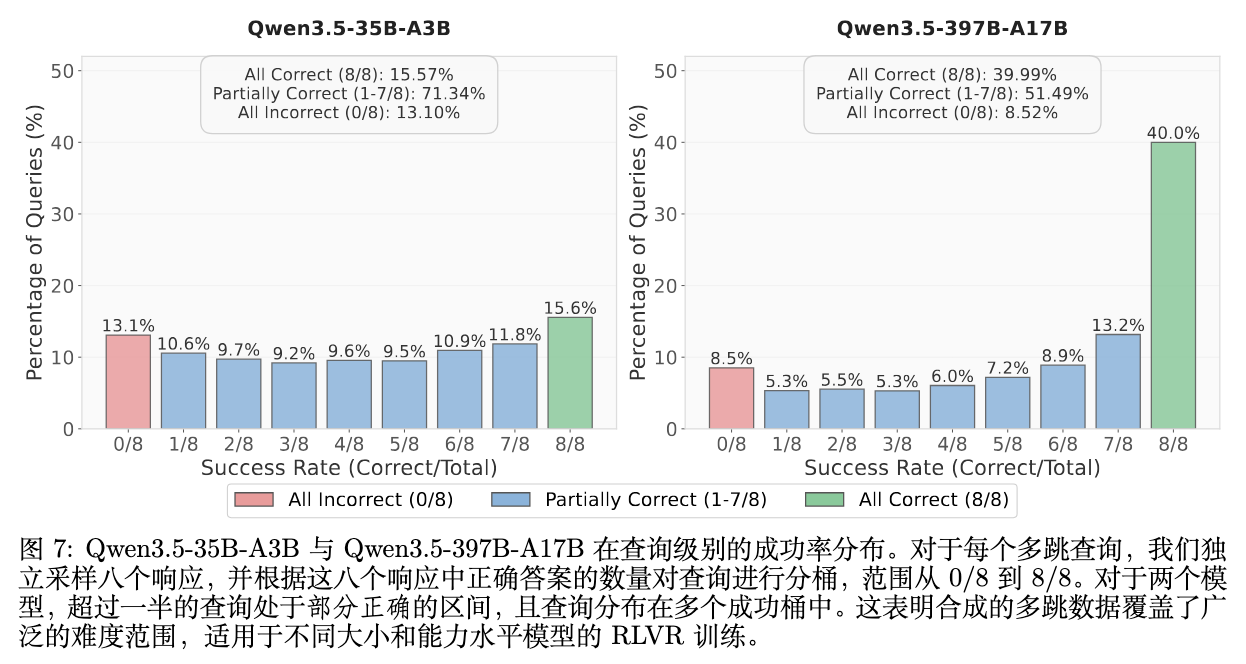
合成的数据如果不加筛选,可能要么过于简单(所有模型都能答对),要么过于困难(成为噪声)。图 7 分析了模型在处理这些合成查询时的表现。
对于每一个多跳查询,模型独立采样 8 次回答。图表横坐标是从 0/8 成功到 8/8 成功的分组。结果显示,对于 35B 和 397B 两个模型,均有超过一半的查询落入了“部分正确(Partially Correct,即 1/8 到 7/8)”的区间,并且分布相对平缓。这种宽泛的难度跨度确保了模型既能从简单的样本中建立初步的关联能力,又能从困难的样本中获得持续探索的梯度信号。
7.4 错误类型修复分析(Error-Type Analysis)
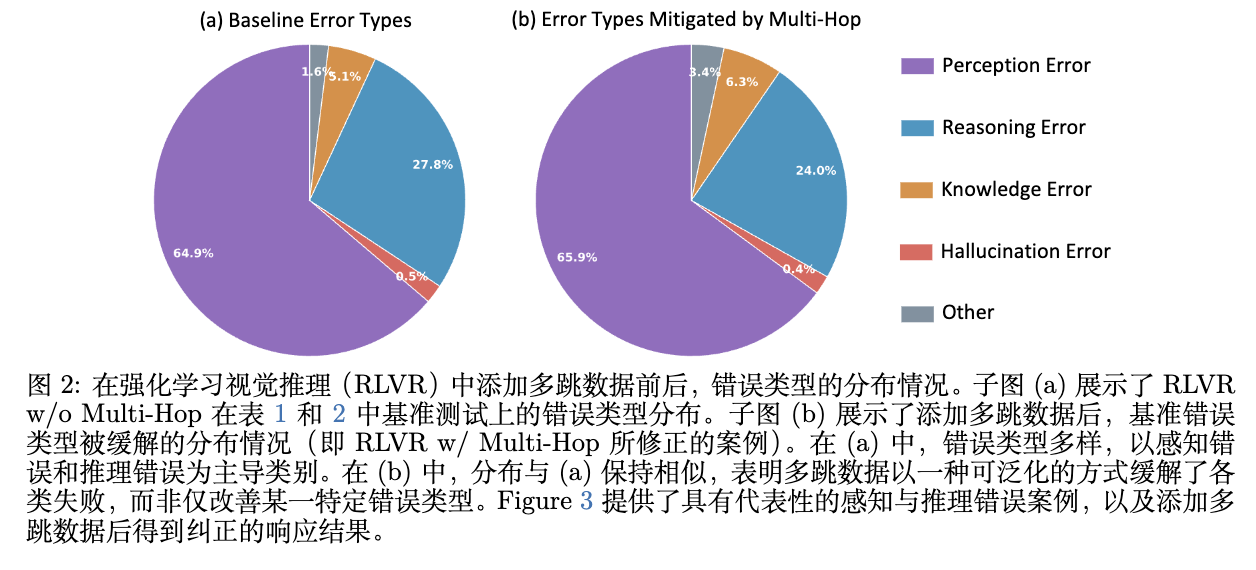
加入 HopChain 数据后,模型到底修复了哪些错误?图 2 与图 8 展示了人工抽样分析的结果。在没有引入多跳数据前,主要的错误类型是感知错误(64.9%)和推理错误(27.8%)。在引入多跳数据后被修复的样本中,错误类型的分布呈现类似的比例(感知占 65.9%,推理占 24.0%)。
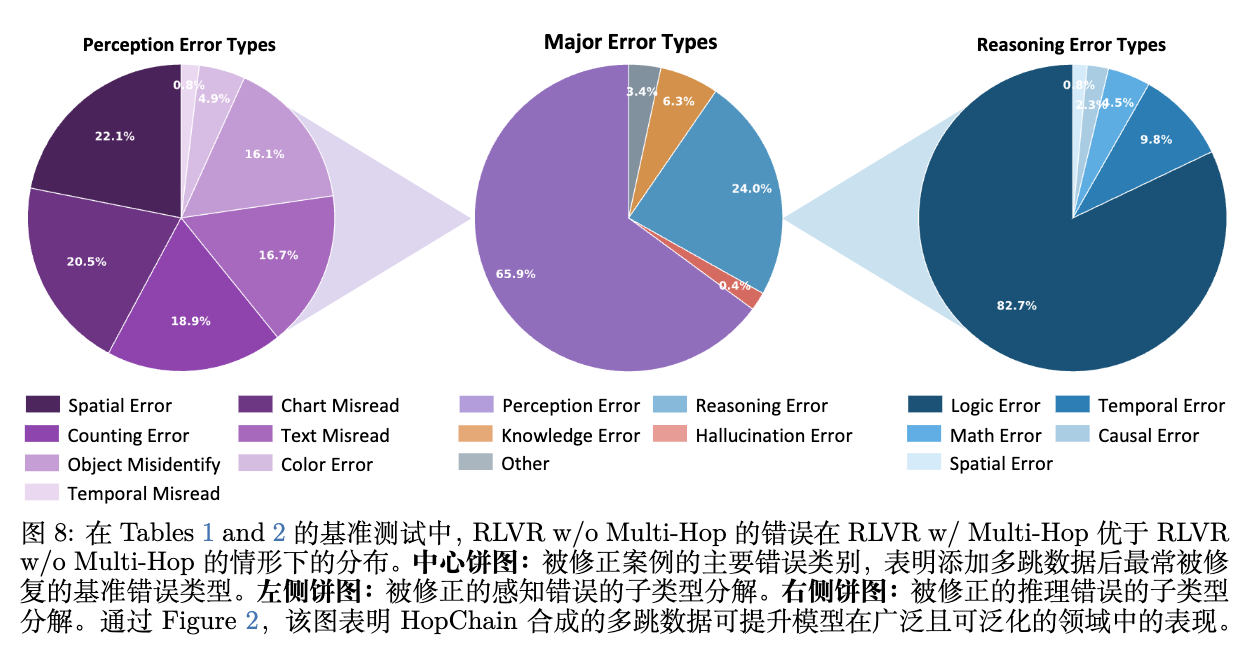
更细粒度的分析(图 8 左侧和右侧的饼图)揭示了修复范围的广泛性:
-
感知层面的修复:包括图表误读(Chart Misread)、计数错误(Counting Error)、物体识别错误(Object Misidentify)、颜色错误和空间定位错误(Spatial Error)。 -
推理层面的修复:涵盖了逻辑错误(Logic Error)、数学计算错误(Math Error)、时间与因果推理错误。
这种分布的高度一致性表明,HopChain 并不是以类似补丁的形式仅仅修复了某一两个特定类型的 Bug(例如,并不是专门教模型怎么数数),而是从根本上提升了每一步推理中视觉定位的可靠性,从而降低了各种不同错误沿着逻辑链传播的概率。
8. 相关工作与宏观视角讨论
论文将本项研究放置于当前几个技术前沿的交汇点。
8.1 视觉-语言模型的发展瓶颈
现有的研究(如 LLaVA 系列、Qwen-VL)通过指令微调提升了模型的可用性,但诸多诊断研究指出,即使是当前最先进的模型也容易受到幻觉和视觉错觉的影响。特别是当进入“思考模式”(生成长 CoT)时,模型容易变得“多想少看”(More thinking, less seeing)。这种现象的本质在于模型内部语言先验的权重逐渐压倒了视觉输入的约束。HopChain 采用“以毒攻毒”的方式,用比实际任务还要漫长和复杂的结构化查询,强制模型对抗这种视觉漂移。
8.2 语言模型与多模态模型的强化学习
在纯文本大模型领域,RLHF(基于人类反馈)和 RLVR(基于规则校验)取得了显著成功,如 DeepSeekMath 和 OpenAI 的推理模型。近期的迁移工作试图将 RL 引入 VLM。然而,以往的 VLM RLVR 工作主要依赖于已有的学术基准数据集(如几何题、物理题),这些数据集的规模有限且分布偏向特定的学术考试场景。相比之下,HopChain 提供的是一个领域无关(Domain-agnostic)、基于真实自然图像的代理任务(Proxy task)合成流水线。其价值在于不受限于现成的数据集,而是无限合成出能锻炼模型基本功的训练材料。
8.3 数据合成机制的演进
过去针对组合式视觉推理(Compositional visual reasoning)的研究多依赖于完全合成的图像与问题(如 CLEVR),或者通过人工标注产生的 GQA 数据集。在 LLM 时代,Self-Instruct 和 Alpaca 开创了用强模型合成指令数据的先河。视觉领域的 ShareGPT4V 进一步推动了视觉问答的合成。HopChain 的独特贡献在于融合了开放词汇的检测技术(SAM3)和强推理大模型(235B VLM),在真实的、复杂的图像分布上合成了依赖严格拓扑关系(A B C)的多步问题。
9. 结论与未来工作展望
9.1 结论总结
本文确立了长链条推理中复合错误模式对 VLM 泛化能力的阻碍。基于这一洞察,作者提出了 HopChain 框架。该框架不依赖特定领域知识,而是通过构建包含特定跳数、约束对象关联、最终收敛于数值答案的数据,强制模型在训练过程中进行反复的视觉回溯。实验验证了这一方法在 Qwen3.5 两个主流参数量级上均带来了跨域的、广泛的性能提升,有效强化了超长文本输出情况下的推理鲁棒性。
9.2 现有局限性与未来展望
论文坦诚地指出,当前的 HopChain 流水线高度依赖实例分割模型(即阶段二的 SAM3)。这意味着对于那些无法被清晰分割出边界框的抽象场景,或者没有具体可数对象的图像,当前的框架无法生成多跳数据。这些图像因此被排除了合成工作流之外。
自然延伸的下一个研究方向是:如何减少对传统检测/分割掩码的依赖。未来可能会探索在没有可分割对象的情况下补充构建数据的路径,例如基于场景的全局属性转变、抽象纹理特征的对比等,同时继续保持“强制长链条视觉重定位”这一核心设计理念。
10. 附录深度解析:Prompt 工程实践拆解
这篇论文在附录 A 中公开的 Prompt 具有极高的参考价值。这个 Prompt 负责控制 235B 大模型生成既复杂又合规的多跳数据。我
10.1 角色设定与概念界定
Prompt 一开始将模型设定为“顶尖 AI 多模态能力评估专家”,随后清晰界定了感知能力的三个层级:单对象感知(Level 1)、多对象与关系感知(Level 2)以及多跳推理(Level 3)。其中,要求跳跃必须在两个维度上发生:
-
感知类型间的跳跃(Perception-Level Hops)。 -
实例到实例的跳跃(Instance-to-Instance Hops),特别强调了前一个实例的信息是定位下一个实例的“必由之路”(DEPENDS ON)。
10.2 生成类型的分类与倾向
Prompt 给出了三种推理类型:
-
Type A(最重要的类型):实例依赖链(Instance Dependency Chain)。给出了反面教材(如找最大的车,再找最高的树——没有依赖)和正面教材(找到最大的车,然后找到距离这辆车最近的树——存在依赖)。 -
Type B:感知层级的切换。 -
Type C(期望的类型):上述两者的强结合。
10.3 严苛的输出约束(Constraints)
为确保生成的题目可以用于客观评测且不发生数据泄露,Prompt 中设计了大量的防御机制:
-
黑盒视角约束:警告模型,裁剪好的对象图片块(Patch Images)仅在生成设计时可见,对于最终解答题目的模型是不可见的。 -
覆盖率要求:要求生成的题目必须涵盖传入组合列表中的所有(ALL)或绝大部分实例。避免生成只用到 2 个物体的简单问题。 -
禁止作弊词汇:明令禁止(MUST NEVER mention)在题干中出现边界框、检测框、坐标(0-1000 range)或裁剪块的字眼。 -
无歧义指代(Unambiguous References):这是最核心的一条。要求对象描述必须结合“空间位置 + 视觉属性 + 上下文关系”以确保其唯一性。并在 Prompt 中内置了“心智验证(Verify uniqueness)”环节,即假设有另一个人只看原图,是否会产生误解。
10.4 复杂性与逻辑要求
-
逻辑控制流:要求包含条件逻辑(if-then-else)。为了避免统计偏差,特别嘱咐“如果对象是红色的,那就设计一个‘如果它是蓝色的’的条件判断,迫使推理走 'else' 分支”,以此平衡正例和负例。 -
确定性数字输出:不管中间怎么绕,最终输出必须是一个可计算的具体数字(Numerical Answer)。
10.5 JSON 结构化的返回格式
Prompt 要求返回规范的 JSON 格式,其中必须清晰呈现 instance_chain(例如 "A B C D E" 的数据流说明),以及逐步解析的 reasoning_hops 列表。每一跳都需要说明从哪个实例出发,到达哪个实例,涉及了哪些物体,输出了什么局部结论。这种高度结构化的设计使得生成的数据在解析和后续步骤控制上具备了工程上的稳定性。
通过这种详尽、几乎是防御式的 Prompt 设计,研究团队成功将拥有巨大世界知识和推理能力的大语言模型,限制在了一个只能依靠观察当前图像像素来构建逻辑谜题的框架中。这种合成数据的方法论,不仅适用于本篇论文的特定任务,对于如何构造高质量的指令微调数据集,或是自动化评估基准,都有着深远的启发意义。
更多细节请阅读原文。
往期文章:


