让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:From Context to Skills: Can Language Models Learn from Context Skillfully?
-
论文链接:https://arxiv.org/pdf/2604.27660
TL;DR
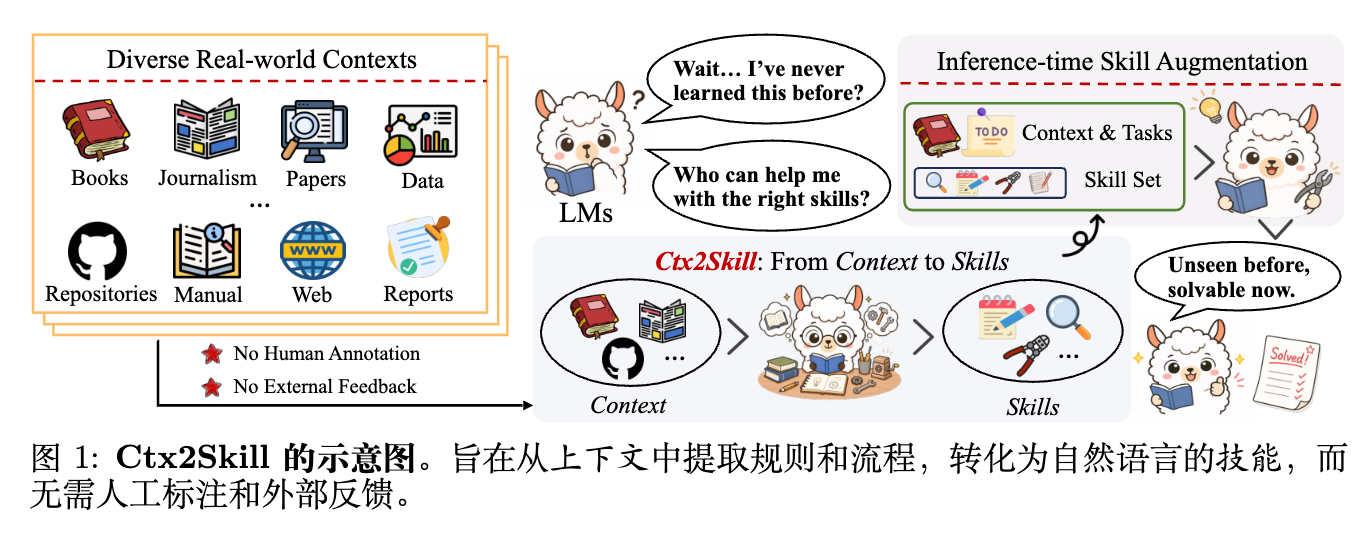
今天解读一篇来自清华大学、DeepLang AI、伊利诺伊大学厄巴纳-香槟分校(UIUC)、复旦大学和香港中文大学等机构的论文《From Context to Skills: Can Language Models Learn from Context Skillfully?》。该研究聚焦于大型语言模型(LLMs)在处理复杂、冗长且超出其预训练参数知识的特定领域上下文时所面临的挑战,即上下文学习(Context Learning)能力。直观的解决方案是在推理阶段进行技能增强,将上下文中的规则和程序提取为显式的自然语言技能。然而,这面临两个根本性障碍:针对长且技术密集的上下文进行人工技能标注的成本过高,以及自动化技能构建过程中缺乏外部反馈信号。
为了解决上述问题,作者提出了 Ctx2Skill,这是一个无需人类监督或外部反馈即可自主发现、微调和选择特定上下文技能的自我进化框架。该框架的核心是一个多智能体自对弈循环,包含生成探测任务和评分细则的挑战者(Challenger)、利用不断进化的技能集尝试解决任务的推理者(Reasoner),以及提供二元反馈的中立裁判(Judge)。通过专门的提议者(Proposer)和生成者(Generator)智能体分析失败案例并综合出针对性的技能更新,挑战者和推理者得以共同进化。
此外,为了防止由于任务生成日益极端和技能过度专业化而导致的对抗性崩溃(Adversarial Collapse),该研究引入了跨时间重放(Cross-Time Replay)机制,以识别在代表性案例中取得最佳平衡的技能集,确保技能演进的鲁棒性和泛化性。在 CL-bench 的四个上下文学习任务上的评估表明,Ctx2Skill 能够一致地提升各类基座模型的任务解决率,例如将 GPT-4.1 的解决率从 11.1% 提升至 16.5%,将 GPT-5.1 从 21.1% 提升至 25.8%。
1. 引言
当前的大型语言模型在处理其大规模预训练期间遇到过相关知识的问题时,已经展现出优异的性能,例如竞赛级别的数学问题和竞争性编程挑战。然而,许多现实世界中的任务要求语言模型从复杂的上下文中学习,并利用新知识而不是参数化知识来有效地进行推理和解决问题。先前的研究将这种能力称为上下文学习(Context Learning)。有效的上下文学习使得模型能够超越其预训练知识的局限,通过直接从丰富的上下文信息中学习来解决复杂的、特定领域的任务,其过程类似于人类的学习方式。例如,它允许语言模型快速利用以前未见过的产品文档来生成逐步的操作程序或排除故障。
尽管上下文学习在解决现实世界任务中占据核心地位,但它在当前的研究中很大程度上被忽视了。一个关键的障碍是现实世界上下文的多样性:上下文知识可以通过书籍、实验数据、搜索结果等多种形式传达,使得上下文学习从根本上变得困难。一种直观的范式是推理时技能增强(Inference-time skill augmentation),即从上下文中提取规则和程序,转化为自然语言技能(Skills),为语言模型编码可复用的程序性知识。这种方法在许多智能体任务(如编码智能体和网页导航)中已被证明是有效的。
然而,在上下文学习场景中,这种范式面临两个根本性的挑战:
-
人工技能标注的成本过高:现有的智能体技能库主要通过人工标注构建。但在上下文学习场景中,上下文通常很长、技术密集且具有领域特定性。策划高质量的技能需要标注者完全内化复杂的多部分文档,这一过程在认知上要求极高且在经济上不可行,导致人工策划的技能构建无法规模化。 -
自动化技能构建缺乏外部反馈:与编码或数学推理等可以通过执行反馈或真实值比较来评估技能质量的可验证任务不同,上下文学习任务缺乏自动反馈来评估提取的技能是否忠实且完整地捕获了特定上下文的知识。在仅给定上下文的情况下,没有外部反馈信号来判断生成的技能是否有用,或者是否遗漏了关键知识。这种无反馈的性质使得自动化技能构建流水线无法直接应用。
基于此,作者提出了 Ctx2Skill,旨在通过技能优化的自对弈,直接从复杂的上下文中自主发现、微调和选择技能,既不需要人工标注,也不需要外部反馈。
2. 问题形式化
一个上下文学习任务由以下部分组成:一个给定的上下文 ,其内容可能位于语言模型的预训练语料库之外;一组任务 ,其正确答案依赖于 ;以及一组二元评分细则 。给定语言模型 产生的答案 ,只有当所有评分细则都通过时,该任务才被视为已解决。作者将任务 的解决指示器(Solving Indicator) 定义为:
公式中, 表示指示函数,当条件 成立时取值为 1,否则为 0。连乘符号 确保了评分的严格性:只要有一个细则未通过,整体解决指示器 即为 0。 表示答案 是由策略 在给定上下文 和任务 的条件下生成的。
该研究的目标是使语言模型 能够在没有任何参数更新或外部反馈的情况下,解决关于先前未见过的上下文 的任务。为此,作者引入了一个自然语言技能集 ,这是一个在推理时预置于语言模型系统提示词(System Prompt)之前的简短 Markdown 文件:
在 Ctx2Skill 提出的技能构建过程中, 被实例化为两个独立的技能集:用于推理者(Reasoner)智能体的 和用于挑战者(Challenger)智能体的 。在推理阶段,只有推理者的技能集 会与语言模型一起部署,用于特定上下文任务的评估。
3. Ctx2Skill 核心框架
为未见过的上下文 构建技能集面临两个障碍:人工阅读 并写下其上下文知识的成本高昂,且没有外部反馈信号可以告知提议的技能是否忠实且对 有用。为了解决这两个问题,Ctx2Skill 运行一个多智能体自对弈循环,仅从上下文 中自主发现和微调特定上下文的技能。
Ctx2Skill 的核心思想是通过 次由失败驱动的文本编辑迭代,共同进化两个技能集:推理者的技能集 和挑战者的技能集 。这样,推理者逐渐积累上下文 的知识,而挑战者则不断探测尚未掌握的方面。五个冻结参数的语言模型智能体角色执行此自对弈循环。
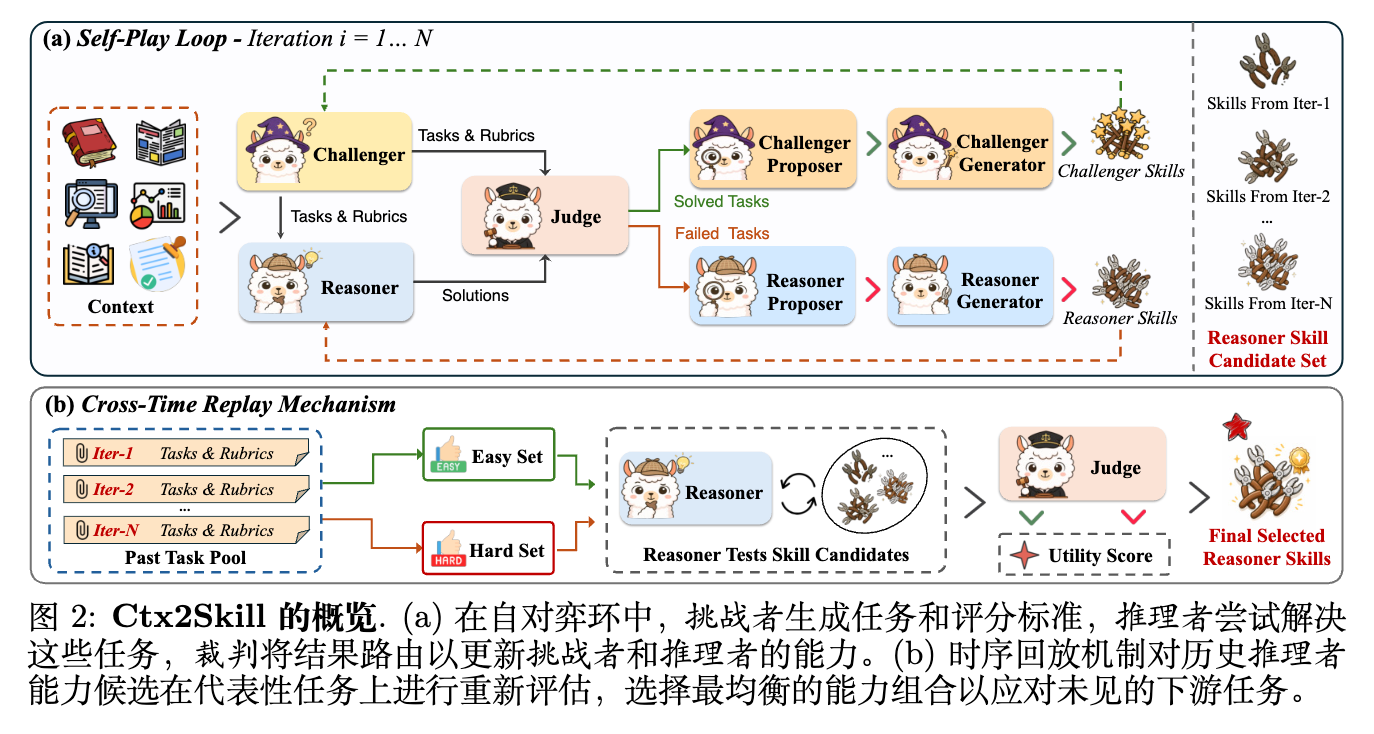
在迭代 时,定义这五个智能体角色如下:
-
挑战者(Challenger):给定上下文 及其当前技能集 ,挑战者生成一批包含 个任务的集合 ,每个任务配备相应的评分细则 。评分细则的设计要求正确答案必须归纳 的规则,而不是仅仅改写表面文本。通过以其技能 为条件,挑战者跨迭代调整其探测策略,随着推理者的进步维持对抗压力。 -
推理者(Reasoner):给定 、任务 及其当前技能集 ,推理者产生一个答案 。虽然原始上下文 包含所有必要的知识,但它通常很长且技术密集;技能集 将 中最相关的规则和程序提炼成简洁、结构化的形式,允许推理者直接应用上下文知识,否则这些知识需要在每个任务中从头开始提取。 -
裁判(Judge):给定挑战者生成的任务和评分细则,以及推理者生成的答案,裁判返回每个细则的二元裁决 和解决指示器 。裁判是一个严格的评估者:当且仅当答案满足所有相关细则时,任务才被认为已解决。 -
提议者(Proposer,每侧一个):裁判的二元裁决确定了哪些任务失败或解决,但没有说明原因。因此,提议者收集其所在侧的所有路由案例,其中每个案例包含挑战者的任务和细则,以及推理者的答案,并针对当前技能集联合分析它们。提议者不是孤立地诊断每个案例,而是将跨案例的常见失败或成功模式综合成高级诊断,指定操作(添加或合并)、目标技能名称、描述和理由。 -
推理者提议者 旨在获取失败案例 以及 ,并通过检查错误答案及其违反的细则,诊断缺失或被误传的上下文知识。 -
挑战者提议者 获取容易解决的案例 以及 ,并通过检查推理者如何利用其现有技能解决这些案例,识别当前任务和细则生成策略中的差距。
-
-
生成者(Generator,每侧一个):提议者的输出是一个高级诊断,描述了应该改变什么以及为什么,但不是具体的技能内容本身。生成者将此诊断物化为实际的技能集。给定诊断和当前技能集,它返回一个完整的替换技能集,该技能集添加或合并条目,同时保留每个不相关的条目。 -
推理者生成者 将诊断出的缺失上下文知识合并到 中,产生新的技能集 。 -
挑战者生成者 收紧 ,以便下一次迭代探测推理者剩余的弱点,产生技能 。
-
更新后的技能集 和 被带入迭代 。任何提示词都不会以对方的技能集为条件,从而保持双方的严格对抗性。
4. 跨时间重放机制
上述框架设计在跨迭代过程中有意加强挑战者,随着推理者的改进维持对抗压力。然而,这种设计引入了一种固有的张力,作者将其称为对抗性崩溃(Adversarial Collapse)。
随着迭代的进行,挑战者生成越来越极端的任务,这些任务集中在推理者残余的弱点上,逐渐偏离上下文 的代表性知识。由于推理者的技能更新是由失败驱动的,其技能过度专业化于这些病态案例,导致冗余的技能积累,从而降低了泛化能力。此外,这种崩溃在循环内是不可检测的:每次迭代的裁判仅评估挑战者新生成的任务,不提供关于早期迭代中掌握的上下文知识是否被后续编辑破坏的信号。因此,无条件地返回最后一次迭代的推理者技能 是不可靠的;作者选择在候选集 中选择最具泛化能力的技能集。
为了解决这个问题,该研究提出了一种跨时间重放机制,使用在自对弈本身期间收集的代表性探针,从候选集 中选择最具泛化能力的技能集。在没有任何外部监督的情况下,逐步策划两个小型探针集:在每次迭代 中,将细则通过率最低的失败任务添加到困难探针集 中,将细则数量最少的已解决任务添加到简单探针集 中,从而捕获每次迭代中观察到的最难的失败和最简单的成功。
一旦自对弈循环终止,推理者 在每个候选技能集 下重新回答两个探针集中的每个任务,并且裁判重新评估每个细则,产生每个探针任务 的解决指示器 (即所有细则是否都通过)。作者定义了拉普拉斯平滑(Laplace-smoothed)的解决率 和 ,分别表示在上下文 和技能 下,困难和简单探针集中解决的任务比例:
公式中,分子部分计算了探针集中被成功解决的任务数量,并加上 1 作为平滑项;分母部分是探针集的总任务数加上 1。拉普拉斯平滑防止了在某些迭代中探针集为空或解决率为 0 时的极端情况。
最终选择的技能集是使这两个解决率的乘积最大化的那个:
乘法形式是必不可少的:一个以在较简单任务上退化为代价来解决后期特殊失败的技能集会在 上受到惩罚并被拒绝;反之,一个解决了所有简单探针但未能解决任何困难探针的技能集会通过 被拒绝。同时,拉普拉斯平滑保持了当给定迭代的探针集为空时乘积的良好定义。
在推理时,最终的技能集 被预置到推理者的系统提示词中,用于处理上下文 上的任何未见任务 ,推理者在条件 下进行回答。由于 编码了 的可复用上下文知识而不是特定于任务的解决方案,因此它泛化到同一上下文上的任意任务。
5. 实验设置
评估基准:上下文学习要求模型从给定的上下文中学习,并应用所学知识来解决任务。CL-bench 包含 500 个复杂的上下文、1899 个任务和 31607 个验证细则,全部由经验丰富的领域专家精心制作。数据分布在四个类别中:领域知识推理(Domain Knowledge Reasoning)、规则系统应用(Rule System Application)、程序性任务执行(Procedural Task Execution)和实证发现与模拟(Empirical Discovery & Simulation)。评分严格遵循全有或全无(all-or-nothing)的原则:只有当所有细则都通过时,任务才被视为已解决。
基线方法:
-
Prompting:直接提示语言模型阅读上下文 并在单次传递中生成技能集;生成的技能在推理期间预置于语言模型。 -
AutoSkill4Doc:AutoSkill 的变体,专为文档级上下文设计:它将上下文 划分为不同的窗口,识别每个窗口内的独立技能,并跨窗口重组技能以产生技能集。
模型:评估了广泛的前沿语言模型,包括 GPT-4.1、GPT-5.1、GPT-5.2、Claude Opus 4.5、Gemini 3 Pro、Kimi K2.5 和 DeepSeek V3.2。对于支持思考模式(thinking mode)的模型,使用默认的推理努力度。
实现细节:每个上下文运行 个自对弈迭代,每次迭代 个任务。挑战者、推理者、提议者和生成者都使用相同的基座模型(例如,在基于 GPT-4.1 的方法中,所有四个智能体都使用 GPT-4.1),而裁判使用 GPT-5.1,这与 CL-bench 的评估协议一致。
6. 实验结果与分析
6.1 主实验结果
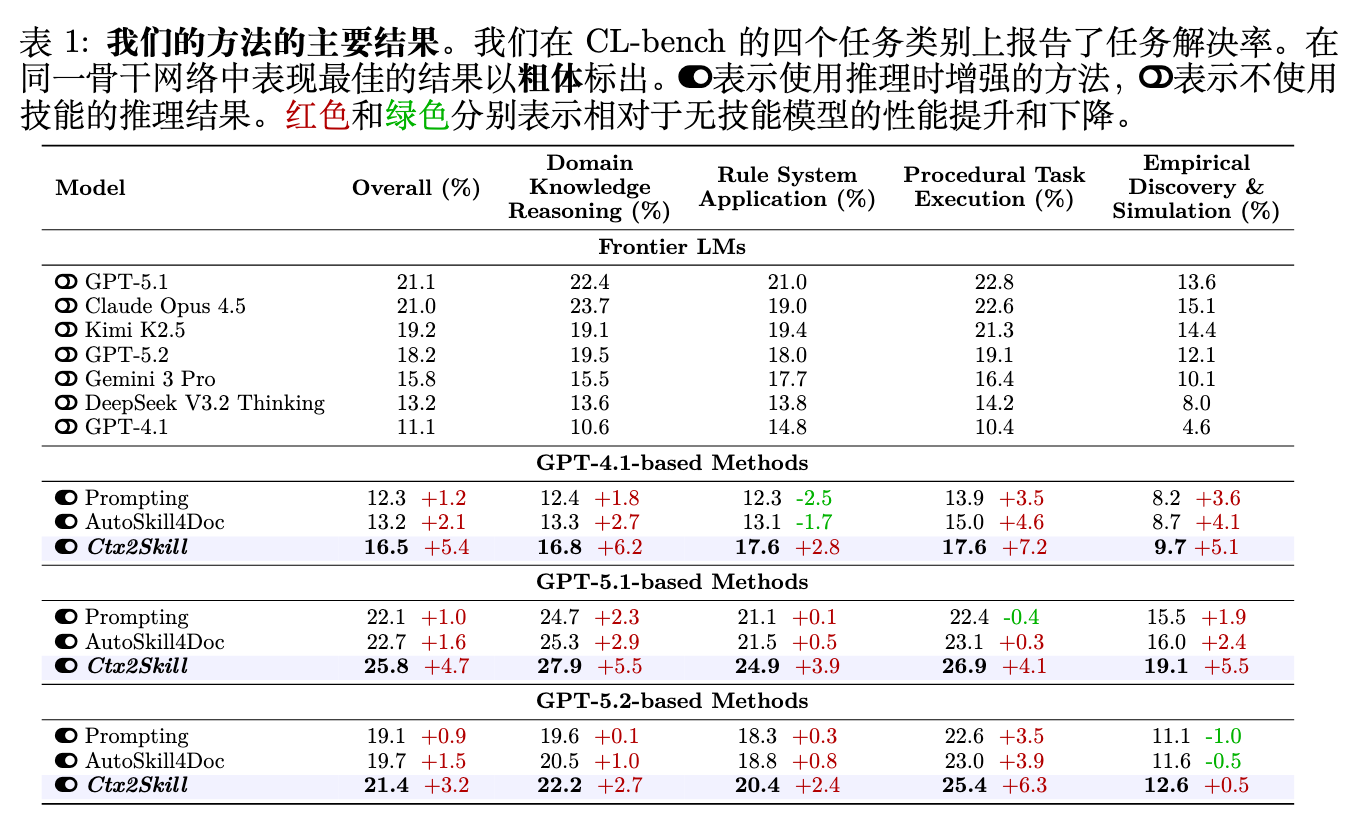
表 1 展示了 CL-bench 上的主要结果。对于当前的前沿语言模型来说,上下文学习仍然具有挑战性:即使是表现最好的模型 GPT-5.1,其整体解决率也仅为 21.1%。
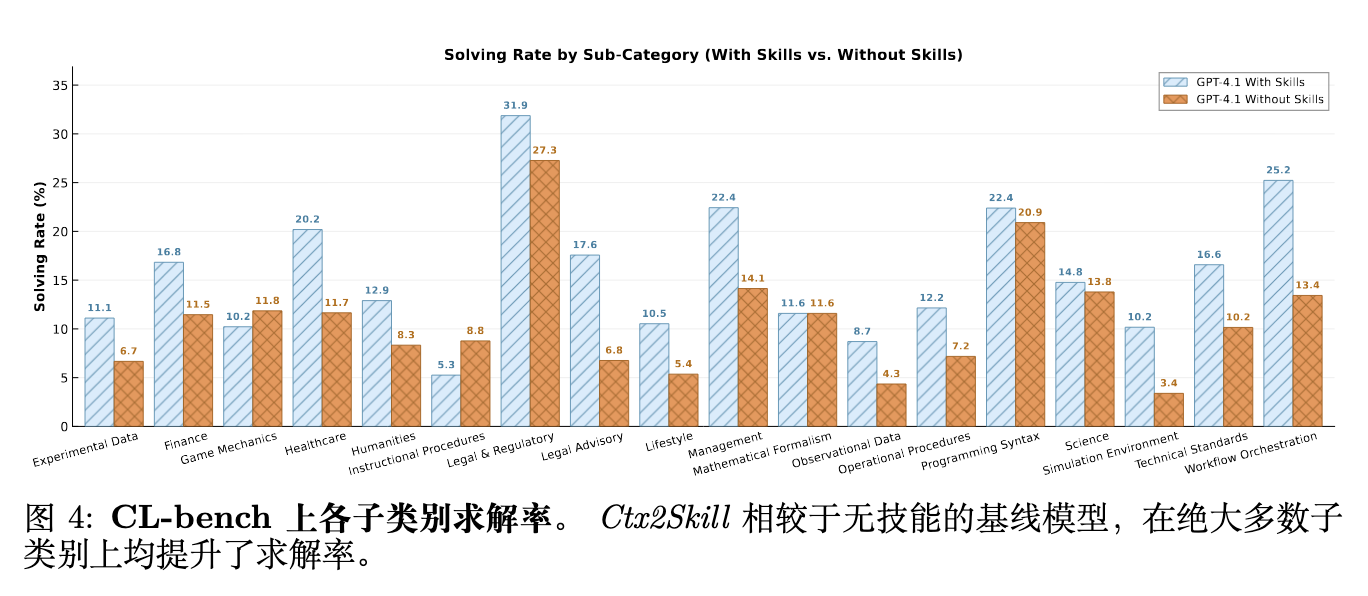
Ctx2Skill 在所有三个基座模型上一致地提高了解决率,将 GPT-4.1 从 11.1% 提升至 16.5%(+5.4%),GPT-5.1 从 21.1% 提升至 25.8%(+4.6%),GPT-5.2 从 18.2% 提升至 21.4%(+3.2%),在所有四个类别中大幅超越了 Prompting 和 AutoSkill4Doc。在程序性任务执行和实证发现与模拟类别中,提升尤为明显,这些类别要求对上下文进行更深层次的程序性和归纳性推理。
相比之下,两个基线方法仅提供了适度的改进,并且偶尔会降低个别类别的性能(例如,Prompting 使 GPT-4.1 上的规则系统应用下降了 2.5%),这表明单次传递的技能提取不足以处理复杂的上下文知识。值得注意的是,配备 Ctx2Skill 技能的 GPT-4.1(16.5%)超越了没有技能的更强前沿模型,例如 Gemini 3 Pro(15.8%),证明特定上下文的技能可以弥合巨大的能力差距。
6.2 生成技能的质量评估
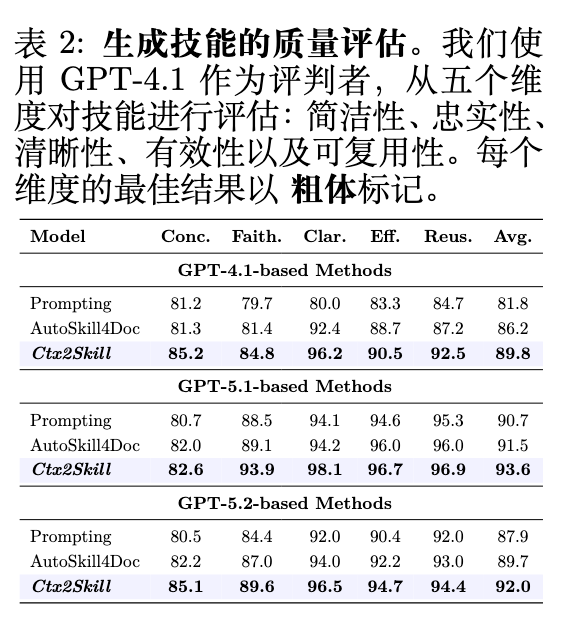
除了解决率之外,该研究还使用 GPT-4.1 作为裁判,从五个维度(简洁性、忠实性、清晰度、有效性和可复用性)评估了生成技能的内在质量(表 2)。Ctx2Skill 在所有三个基座模型上均获得了最高的平均分,在 GPT-4.1、GPT-5.1 和 GPT-5.2 上分别比 AutoSkill4Doc 高出 +3.6、+2.1 和 +2.3 分,其中在忠实性和清晰度方面的改进最为显著。这些结果表明,迭代自对弈循环产生的技能不仅改善了下游推理,而且以结构良好、人类可读的形式呈现了上下文知识,便于检查、编辑和复用。
6.3 消融实验与变体分析
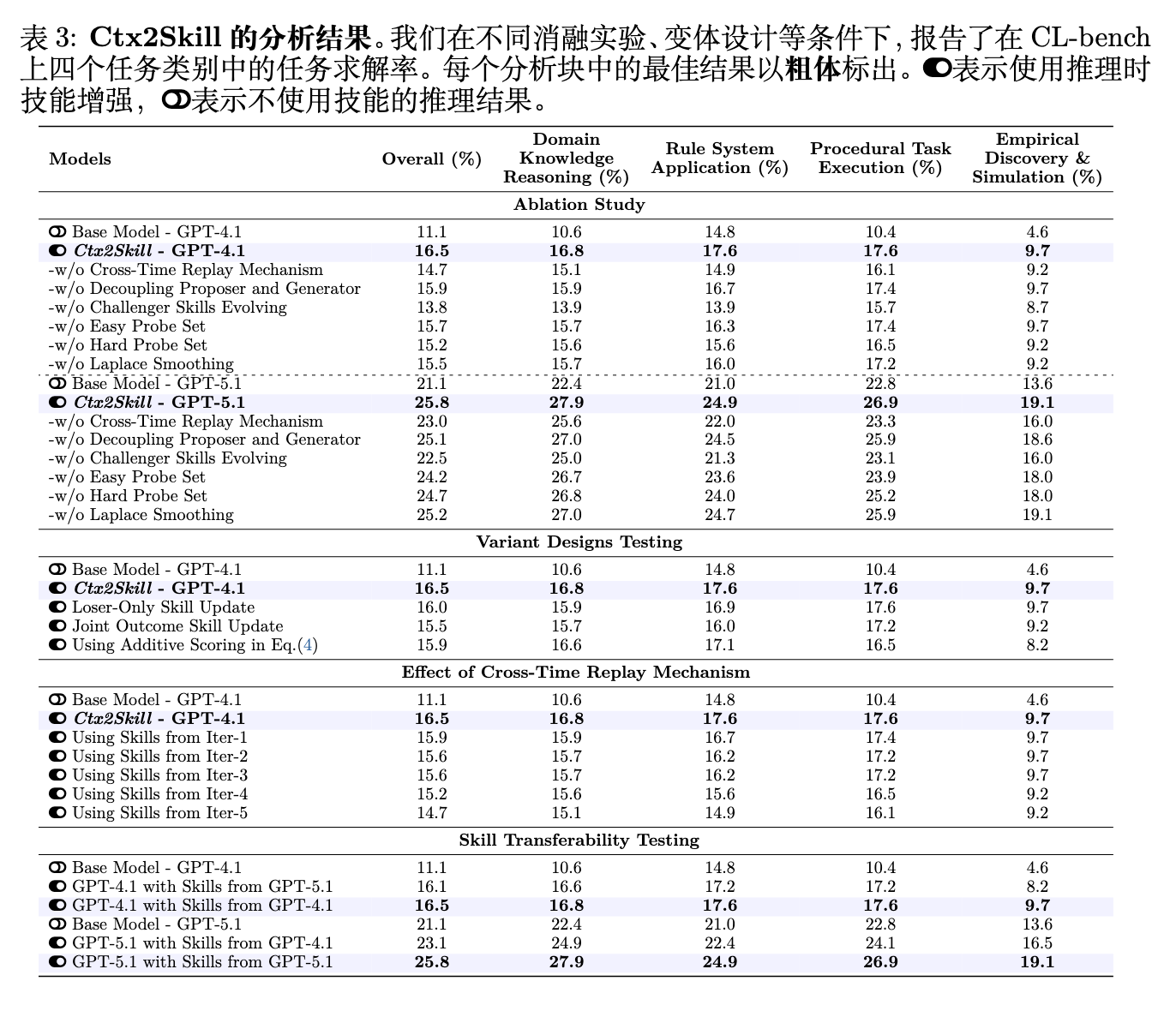
作者在 GPT-4.1 和 GPT-5.1 上对 Ctx2Skill 的每个组件进行了消融实验(表 3,消融研究区块)。
-
移除挑战者技能演进 导致了最大的性能下降,证实了持续的对抗压力对于推理者逐步发现上下文知识是必不可少的。 -
跨时间重放机制 是第二具影响力的组件:如果没有它,最后一次迭代的技能会遭受对抗性崩溃。在跨时间重放中,困难探针集的贡献大于简单探针集,移除拉普拉斯平滑也会降低性能。 -
将提议者和生成者合并为单个智能体会产生适度但一致的下降,支持了将诊断与技能物化解耦的设计。
作者还在 GPT-4.1 上检查了三种替代变体设计(表 3,变体设计测试区块):
-
仅失败方技能更新(Loser-Only Skill Update) 每次迭代仅更新失败方的技能;0.5% 的下降表明更新双方会产生更有效的共同进化。 -
联合结果技能更新(Joint Outcome Skill Update) 将失败和解决的案例同时馈送到双方,允许各方从正负样本中学习;较大的 1.0% 退化表明混合结果稀释了诊断信号。 -
加法评分(Additive Scoring) 将公式 (4) 中的 替换为 ;0.6% 的下降证实了乘法形式能更好地惩罚那些以牺牲简单探针性能换取困难探针收益的技能集。
6.4 跨时间重放机制的深入分析
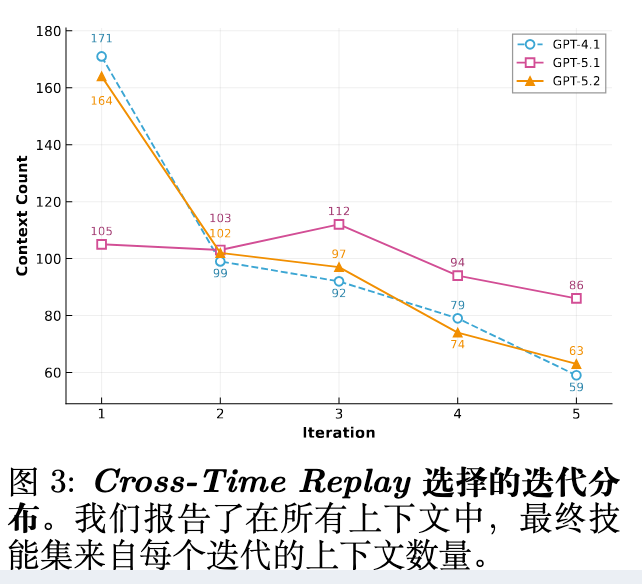
该研究将跨时间重放与使用固定迭代的技能进行了比较。在 GPT-4.1 上,固定迭代的性能从 Iter-1(15.9%)单调下降到 Iter-5(14.7%),证实了后期的迭代遭受了对抗性崩溃现象。跨时间重放(16.5%)通过自适应地为每个上下文选择最平衡的技能集,而不是在所有上下文中承诺单一迭代,超越了每个固定迭代,包括最好的一个(Iter-1,高出 +0.6%)。
图 3 证实了这一模式:在所有三个基座模型中,早期迭代被选择的频率最高,而后期迭代的非平凡比例表明,具有更复杂知识结构的某些上下文确实受益于额外的自对弈轮次。
6.5 技能可迁移性测试
作者探讨了一个基座模型生成的技能是否可以使另一个基座模型受益(表 3,技能可迁移性测试区块)。应用于 GPT-4.1 的 GPT-5.1 生成的技能产生了 16.1% 的解决率,几乎与 GPT-4.1 自己的技能相匹配;反之,应用于 GPT-5.1 的 GPT-4.1 生成的技能产生了 23.1% 的解决率,有 +2.0% 的提升,但明显低于 GPT-5.1 自己技能的 +4.6%。这种不对称性表明,更强的模型产生的技能可以很好地转移到较弱的模型,而较弱的模型缺乏发现更强模型可以利用的知识的能力。
7. 深入分析:自对弈动态与案例研究
为了更深入地理解 Ctx2Skill 的工作机制,作者在附录中提供了大量关于自对弈过程的量化指标和具体的案例分析。
7.1 跨迭代轮次的任务级与细则级动态
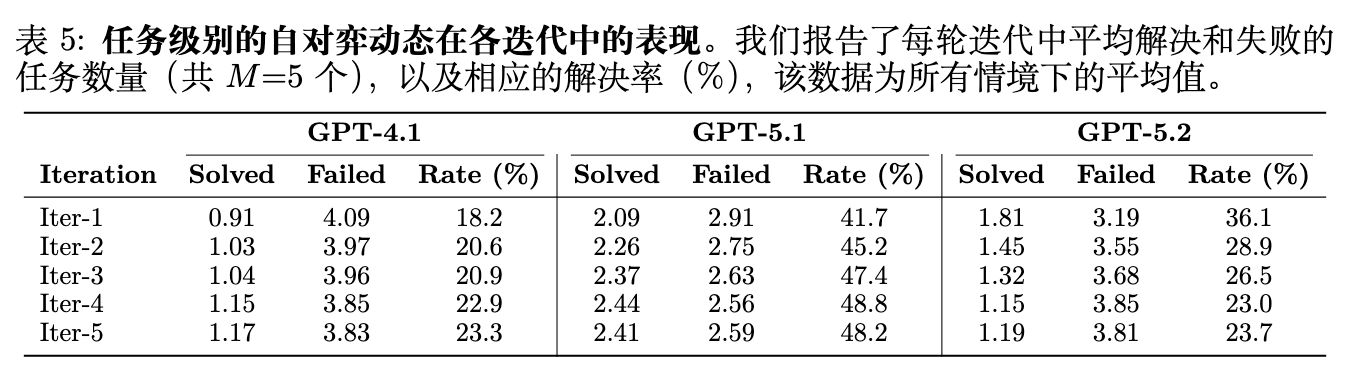
表 5 报告了在自对弈期间每次迭代平均解决和失败的任务数(满分 )。在 GPT-4.1 上,解决率从 18.2%(Iter-1)逐渐增加到 23.3%(Iter-5)。这表明推理者不断发展的技能逐步提高了其处理挑战者生成任务的能力;然而,在所有迭代中,失败率始终保持在 76% 以上,证实了挑战者的共同进化保持了持续的对抗压力,并防止了推理者饱和。
在 GPT-5.1 上,更强的基座使得推理者从一开始就能解决更多的任务(Iter-1 时为 41.7%),并且解决率在 Iter-4 时逐渐上升到 48.8%,然后在 Iter-5 时略微下降到 48.2%。后期迭代的近乎平衡表明挑战者和推理者达到了竞争平衡。GPT-5.2 表现出不同的模式:解决率从 Iter-1 的 36.1% 下降到 Iter-4 的 23.0%,表明挑战者的技能演进超过了推理者的改进,产生了越来越困难的任务,即使使用更新的技能,推理者也难以解决。这一观察结果与对抗性崩溃现象一致,并进一步激发了对跨时间重放机制的需求。
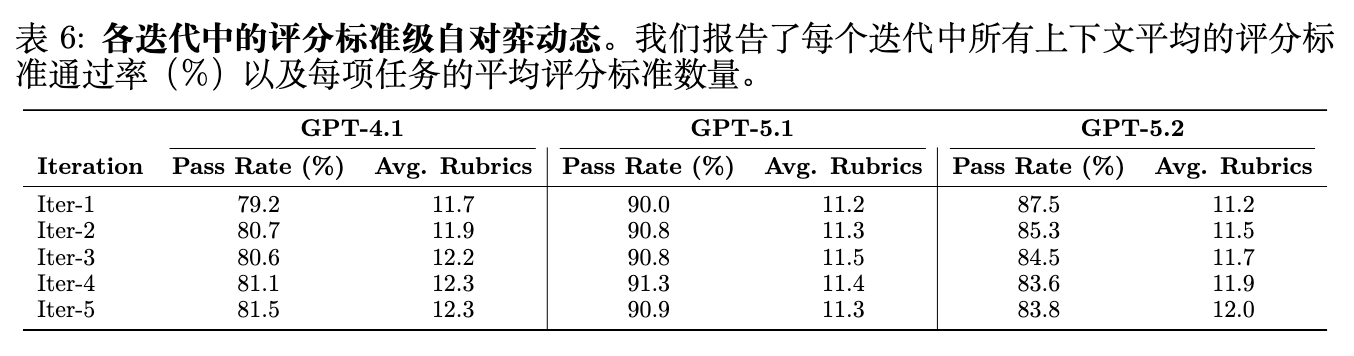
表 6 报告了每次迭代的细则通过率和每个任务的平均细则数。与任务级解决率相比,所有基座模型的细则通过率都明显更高(79%–91% vs. 18%–49%),证实了 CL-bench 中全有或全无评分的严格性:推理者通常通过了大部分细则,但由于一两个遗漏的要求而导致任务失败。
7.2 挑战者与推理者输出长度的变化
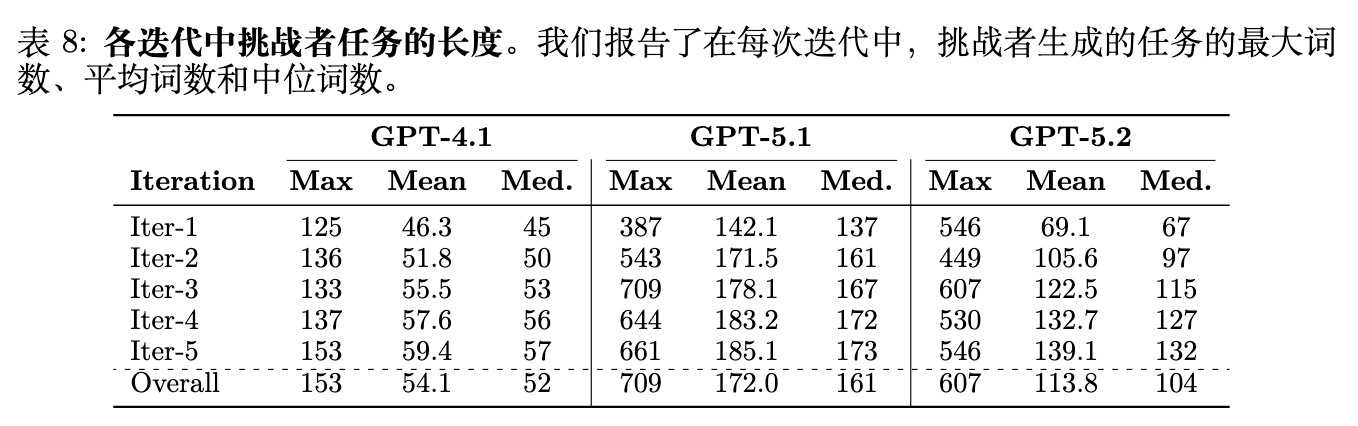
观察表 8 中挑战者生成任务的长度变化趋势,可以发现一个跨越所有基座模型的一致性规律:随着迭代轮次的推进,任务的平均词数呈现单调递增的态势。在 GPT-4.1 上,平均词数从 Iter-1 的 46.3 个词上升到 Iter-5 的 59.4 个词(+28%),反映了任务具体性的适度增加。GPT-5.2 显示出更显著的增长,平均词数几乎翻倍,从 69.1 增加到 139.1 个词,表明其挑战者迅速学会生成更精细和详细的任务描述以维持对抗压力。
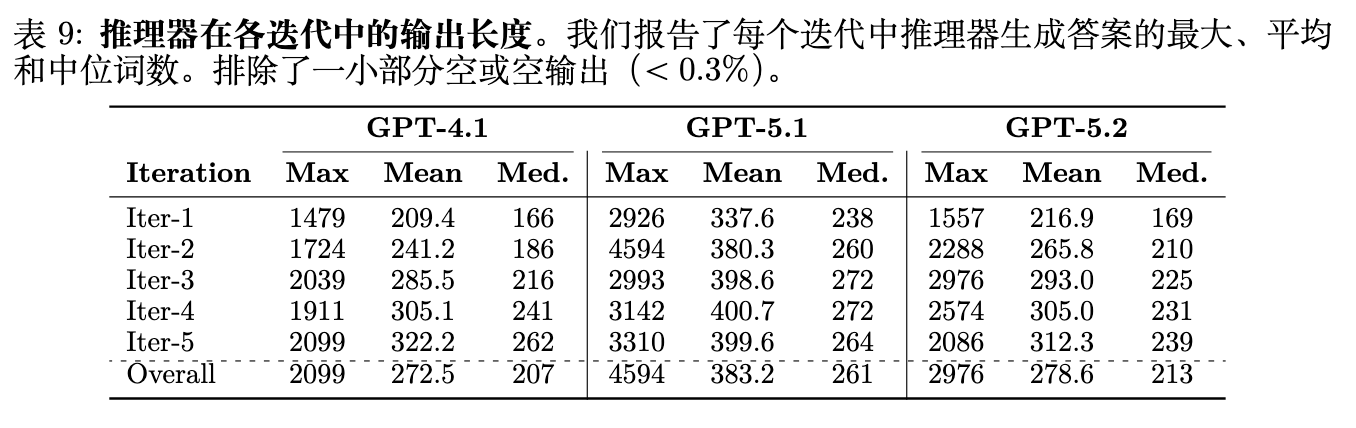
表 9 报告了跨迭代的推理者生成答案的字数分布。与挑战者任务长度类似,所有三个基座模型的平均推理者输出长度跨迭代单调增加:GPT-4.1 从 209.4 增加到 322.2 个词(+54%),GPT-5.2 从 216.9 增加到 312.3 个词(+44%)。这种与挑战者任务长度的共同增长是预期的:随着挑战者生成更精细和要求更高的任务,推理者必须产生相应更长和更详细的答案以满足不断增加的细则数量。
7.3 案例研究:规则系统应用(D&D 游戏场景)
在附录的案例研究中,作者展示了 Ctx2Skill 如何通过生成具体的技能来纠正模型在复杂规则系统中的失误。
在一个模拟《龙与地下城》(D&D)游戏之夜的场景中,系统提示词要求智能体扮演一个“害怕冲突、渴望社交认可的治疗者(Healer)”。任务要求智能体输出五个特定的区块(如 <social_assessment>、<decision> 等),并在复杂的战斗局势中做出决定。
没有技能的模型表现:模型能够正确理解社交动态(队友 Tank 正在催促治疗),并决定施放“Cure Wounds”法术。然而,在评估细则中,有一条是“智能体是否表现出意识到治疗法术消耗有限的法术位(spell slots)?”。没有技能的模型在输出中仅仅写了“cast Cure Wounds (level 1, touch)”,完全没有表现出对法术位这一核心游戏机制资源的意识,因此未能通过该细则,导致整个任务失败。
Ctx2Skill 生成的技能:经过自对弈,Ctx2Skill 为该上下文生成了一个名为 rigorous-constraint-and-format-compliance 的技能。该技能强制要求模型在回答前建立一个包含所有显式和隐式约束的检查表(Checklist),并在输出前进行逐项自我验证。
应用技能后的表现:在应用该技能后,模型在决策区块中明确加入了战术理由,并在输出中写道:“...Cure Wounds (1st-level spell), healing him for 1d8+mod HP.” 这种表述不仅做出了正确的社交妥协,还隐式地将选择与队伍的紧急需求联系起来,而没有将法术视为无限资源。更重要的是,技能的自我验证步骤强制模型检查“是否提到了资源限制”,从而将一个在社交上合适但在游戏机制上不完整的答案,转化为一个既尊重社交和谐又遵守所有显式规则约束的答案,成功通过了所有严苛的细则。
8. 讨论与相关工作
上下文学习(Context Learning):当前的语言模型在预训练期间遇到过相关知识的任务上表现出色。然而,许多现实世界的任务要求模型从复杂的上下文中学习,并利用新知识进行有效推理,这种能力被称为上下文学习。先前的研究发现语言模型尚未掌握这种能力,核心困难在于上下文知识跨越了不同的格式,并且相关的规则和程序通常隐含在其中,需要深度的理解而不是表面的检索。Ctx2Skill 直接针对这一挑战,通过自主发现可复用的特定上下文技能,使任何语言模型都能更好地从复杂的上下文中学习并进行推理。
语言模型的技能(Skills for LMs):技能是编码可复用程序性知识的自然语言模块,用于在推理时增强语言模型。早期的技能库主要通过人工标注构建,这虽然有效但无法规模化,特别是对于上下文长、技术密集且领域特定的上下文学习场景。最近的工作转向了自动化技能构建,例如 AutoSkill、CoEvoSkills 和 SkillX。然而,这些方法依赖于外部反馈信号(如执行反馈、真实值比较或任务完成奖励)来评估和提高技能质量,而这些信号在没有自动反馈的上下文学习场景中是不可用的。Ctx2Skill 提出了一个自我进化的框架,旨在仅从复杂的上下文中直接发现和进化技能,它不需要人工标注,不需要外部反馈,也不需要参数更新。
9. 总结
该论文提出了 Ctx2Skill,这是一个自我进化的框架,能够自主地从复杂的上下文中发现、微调和选择特定上下文的技能,而无需人工标注或外部反馈。通过技能优化的自对弈循环,挑战者和推理者通过失败驱动的文本编辑共同进化其技能集,而跨时间重放机制通过在迭代中选择最具泛化能力的技能集来防止对抗性崩溃。在 CL-bench 上的实验表明,Ctx2Skill 一致且大幅地提高了多个基座模型和任务类别的上下文学习性能,并且生成的技能可以在模型之间转移。Ctx2Skill 提供了一个实用且可扩展的范式,为语言模型配备了从复杂、以前未见过的上下文中巧妙学习的能力。
更多细节请阅读原文。

