让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? -
论文链接:https://arxiv.org/pdf/2603.24472
TL;DR
今天解读一篇来自微软的论文《Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?》。该研究探讨了自我蒸馏(Self-Distillation)技术在大型语言模型(LLMs)后训练过程中的表现。研究表明,尽管自我蒸馏在化学问答、代码生成等领域能够缩短推理路径并提升模型性能,但在数学推理领域,该方法会导致模型性能出现较大幅度的下降。
研究指出,这种性能下降的核心原因在于自我蒸馏过程抑制了模型内部的“认知不确定性表达”(Epistemic Verbalization)。在数学等需要高度泛化和试错探索的领域,模型在推理过程中生成的表示不确定性的词汇(如“wait”、“hmm”、“perhaps”等)起到了维持假设分支、支持错误纠正的关键作用。当教师模型被赋予标准答案等高信息量上下文时,其生成的推理过程变得确定且简短,导致学生模型在蒸馏过程中盲目模仿这种高度自信的输出风格,剥夺了其自我探索的能力。
本文的主要结论包括:
-
教师模型的条件上下文信息越丰富,语言模型输出的认知不确定性表达越少。 -
即使训练数据完全由正确的推理轨迹构成,过度抑制认知不确定性表达也会导致推理性能下降。 -
在在线自我蒸馏算法(如 SDPO)中,随着教师上下文信息量的增加,认知不确定性表达被进一步抑制,从而影响分布外(OOD)评估任务的表现。 -
认知不确定性标记的价值与任务泛化需求呈正相关:在任务覆盖度小、重复性高的场景中,抑制冗余表达能提升效率;而在任务多样性高、需要广泛泛化的场景中,保留不确定性表达是维持性能的必要条件。
1. 背景
1.1 大模型后训练阶段的演进
大型语言模型的性能提升逐渐依赖于后训练(Post-Training)阶段的对齐与能力强化。传统方法主要包括监督微调(SFT)和基于人类反馈的强化学习(RLHF)。近期,基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards, RLVR)受到研究群体的广泛关注,特别是在数学、编程等具有明确答案验证机制的领域。通过使用基于组内相对优势优化的策略(如 GRPO 算法),模型能够通过不断采样和验证来提升其复杂推理能力。
1.2 自我蒸馏(Self-Distillation)的引入
在利用 RLVR 提升推理能力的过程中,模型往往倾向于生成越来越长的推理轨迹。这种长轨迹虽然能够带来性能增益(即测试时计算 Test-Time Compute 的增加),但也带来了高昂的推理成本。为了在保持性能的同时压缩推理过程,研究界引入了自我蒸馏(Self-Distillation)范式。自我蒸馏的核心机制是利用同一个模型的两个实例:一个实例作为教师,在条件反射更丰富的上下文(如标准答案、环境反馈)中生成高质量、确定性强的响应;另一个实例作为学生,在只有原始问题的条件下,通过最小化两者的输出分布差异来进行优化。
这种方法在部分基准测试(如化学、物理问答以及具有较小规模问题的代码任务集)中取得了积极效果。相关工作指出,经过自我蒸馏优化后的模型能够在输出长度显著缩短的情况下,维持甚至超越原始长推理模型的准确率。
1.3 核心疑问:自我蒸馏在数学推理中的负面表现
然而,该论文的研究人员在将相同的自我蒸馏范式应用于数学推理任务时,观察到了截然不同的现象。实验显示,在数学领域中,尽管自我蒸馏能够如预期般持续缩减模型的回复长度,但其推理准确率却出现了明显的下降。这就引发了一个核心问题:“为什么当模型被训练向正确答案靠拢时,其性能有时反而会退化?”
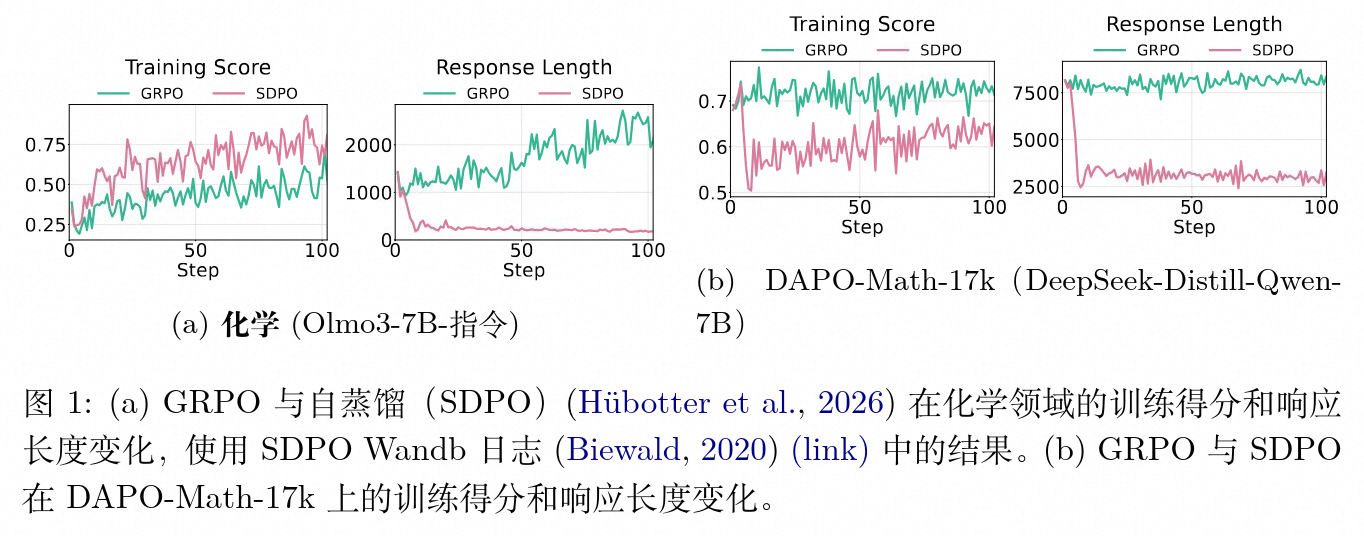
上图展示了具有代表性的在线自我蒸馏算法(SDPO)与基线强化学习算法(GRPO)在不同领域的表现对比。在化学领域,SDPO 在缩短回复长度的同时快速提升了分数;而在数学领域(DAPO-Math-17k 数据集),SDPO 随着训练步数的增加,其评估分数却低于持续增长的 GRPO。这一现象促使研究人员从模型内部推理行为的角度展开深度解析。
2. 数学推理的本质与认知不确定性表达
2.1 语言模型中的自我贝叶斯推理
在自回归大型语言模型中,数学推理可以被抽象为一种自我贝叶斯推理(Self-Bayesian Reasoning)过程。与事实性问答或固定模式的逻辑推演不同,数学问题的解决通常需要多步复杂的推导。在每一步生成时,模型仅基于输入的问题和之前生成的历史词元(Tokens)计算下一个词元的概率分布。
模型需要在各种中间假设之间迭代地更新其置信度。由于预训练阶段的数据包含大量的试错、草稿和推理跳跃,模型在生成复杂数学解答时,会通过显式的文本输出来体现其内在的信念状态(Belief State)的转移。
2.2 认知不确定性标记的定义与分类
在推理过程中,模型对特定假设的不确定性常通过特定的词汇进行表达,研究中将其统称为“认知不确定性表达”(Epistemic Verbalization)。为实现量化分析,研究人员定义了一个包含 10 个常见标记的集合 作为观测指标:
这些词汇在生成序列中承担了不同的认知功能:
-
触发重估(如 wait, actually):通常表明模型在其计算图的当前路径上识别到了潜在的矛盾,准备回退或修改之前的假设。 -
扩展计算时间(如 hmm):作为填充词汇,为模型争取额外的自回归步骤,以便计算更复杂的潜在状态。 -
假设检验(如 perhaps, maybe, seems, might, likely):表示模型提出了一种可能的解法,但尚未赋予高置信度,从而在逻辑语义上保持开放性。 -
分支建立(如 alternatively):引入并行的推理路径进行对比评估。 -
验证机制(如 check):显式触发对中间结果的重新计算与核对。

在包含这些标记的推理轨迹中,模型具有更宽泛的容错空间。一旦去除了这些认知不确定性信号,模型往往会过早地将高概率权重分配给可能错误的假设,导致陷入逻辑死胡同且无法自我修正。
3. 信息论视角下的语言模型推理行为
为了系统性地探究自我蒸馏为何会导致认知不确定性表达的缺失,研究人员引入了信息论的理论框架,量化条件上下文的丰富度对模型行为的影响。
3.1 条件互信息与上下文丰富度
在语言模型生成任务中,设输入问题为 ,目标生成序列为 。在自我蒸馏中,教师模型会被提供额外的上下文信息 (例如标准答案)。上下文 对于目标序列 所提供的信息量可通过条件互信息(Conditional Mutual Information)进行度量:
其中 表示在给定问题 时序列 的条件熵。该公式衡量了在引入额外信息 后,模型对生成目标 认知不确定性的减少程度。
3.2 四种生成设置的实验设计
为了观察信息量的递增如何改变模型的推理特征,研究人员基于 DeepSeek-R1-Distill-Qwen-7B 模型,在 DAPO-Math-17k 数据集的一个难度适中的子集(100道题)上,设计了四种具有严格信息量偏序关系的生成设置。
定义完整解答为 (包含 <think> 标签内的思考过程),移除思考过程的精简解答为 ,由全解答引导生成的再生回复为 。四种设置及其信息量度量如下:
-
无引导生成(Unguided generation):,此时模型只能依靠自身参数和问题 生成推理。定义上 。 -
基于不包含思考过程解答的引导(Solution-guided without think):。由于 仅包含最终步骤,信息量有限。 -
基于再生回复的引导(Regeneration-conditioned):。根据信息论中的数据处理不等式(Data Processing Inequality),再生回复是对原解答的有损压缩,因此 。 -
全解答引导生成(Solution-guided generation):。模型获得了最大的外部指引,产生了最大的条件互信息 。
这四种设置下的条件互信息满足如下偏序关系:
3.3 实验结果分析
研究人员针对上述四种设置分别统计了模型的平均分数、平均回复长度()以及不确定性标记的平均出现次数()。
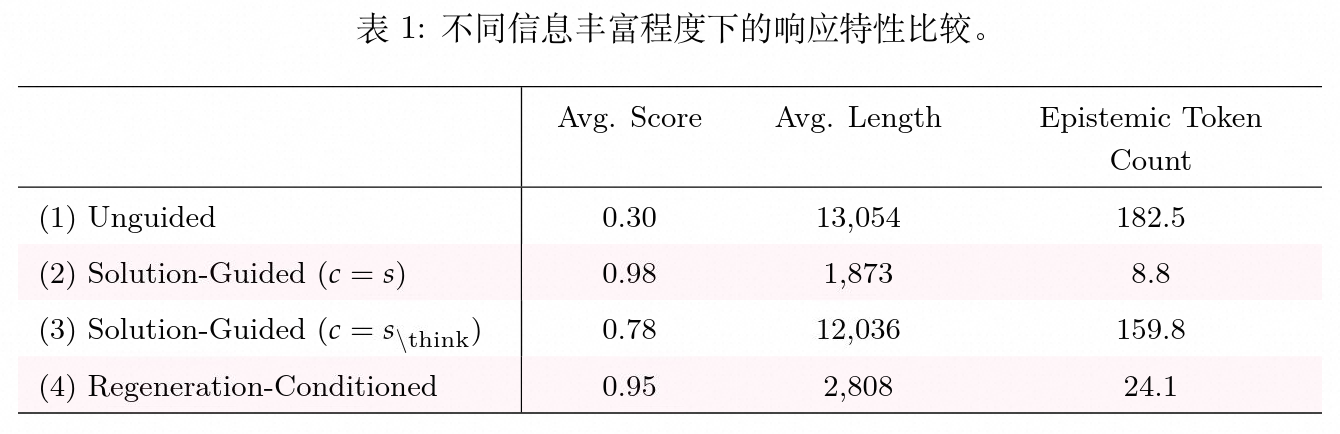
从结果数据可以观察到一种严格的单调递减趋势。随着条件互信息 的增加,模型的平均长度和不确定性标记数量呈现一致下降:
这一结果说明,当给定具有明确指引的上下文 时,语言模型会将信息内化,从而产生更加自信、简短的回复,相应的认知不确定性表达则被大量抑制。无引导设置(1)生成了长达约 13,000 个词元的回复,且不确定性标记达到 182.5 次;而在全解答引导(2)下,由于答案就在上下文中,模型直接输出了确定性结论,长度骤降至 1,873 个词元,标记数仅为 8.8 次。
4. 离线自我蒸馏(SFT)对推理能力的影响
确认了丰富信息会抑制认知不确定性表达后,下一个需要探究的核心问题是:这种抑制是仅仅改变了模型的文风(Stylistic),还是对模型的实质推理能力产生了损伤?
4.1 实验设置
研究人员设计了两组离线自我蒸馏(Supervised Fine-Tuning, SFT)实验。两组实验基于相同的基座模型(DeepSeek-R1-Distill-Qwen-7B),并构建了两个同样包含 800 条正确答案轨迹的数据集,唯一的区别在于轨迹生成时受到的上下文引导程度:
-
:基于无引导回复构建,包含大量的认知不确定性标记,平均长度约为 12,000 个词元。 -
:基于全解答引导回复构建,标记数量少,回复简短,平均长度约为 2,000 个词元。
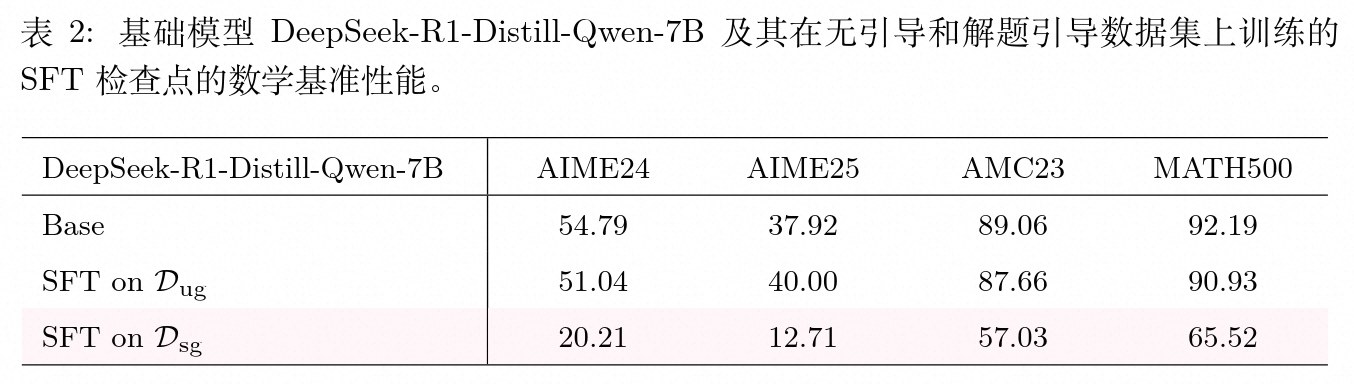
4.2 结果分析与认知冗余探讨
对上述两个微调后模型在 AIME24、AIME25、AMC23 和 MATH500 上的评估显示:
在包含丰富不确定性表达的 数据集上微调,模型的表现与基础模型基本持平甚至在特定指标上有微小波动,未出现显著退化。
而在抑制了不确定性表达的 数据集上微调,模型的性能在所有基准测试上均出现了大幅下降。例如在 AIME24 上,准确率从基础模型的 54.79 下降至 20.21。
这一现象揭示了自我蒸馏中潜在的训练错位(Training Misalignment)。当模型在 上进行训练时,由于目标序列是在有外部答案引导的情况下生成的,其表现出的高度自信和简洁逻辑是依赖于其未被包含在输入中的额外信息。迫使学生模型模仿这种缺失了试错和反思过程的“结论性”推理风格,直接剥夺了其在推理时依赖自主探索进行纠错的能力。这证明了认知不确定性表达并非纯粹的冗余输出,而是维持泛化推理能力的必要条件。
5. 在线自我蒸馏实验分析:算法与模型对比
除了离线 SFT 形式,研究进一步对使用强化学习策略的在线自我蒸馏算法进行了深度解剖。实验对比了 GRPO(无教师指导,依赖结果验证)与 SDPO(引入在不同条件上下文下的教师模型计算 KL 散度约束)在相同数据集(DAPO-Math-17k)上的表现。
在线自我蒸馏的目标函数包含策略优化的奖励机制,并增加了一项分布匹配约束:
在线蒸馏的动态变化受两个因素制约:(1) 基础模型本身的认知不确定性表达基线水平;(2) 教师上下文 的信息丰富度。
5.1 DeepSeek-R1-Distill-Qwen-7B 实验分析
该基座模型预训练时已经展现出在 <think> 标签内大量生成认知不确定性词汇的能力。
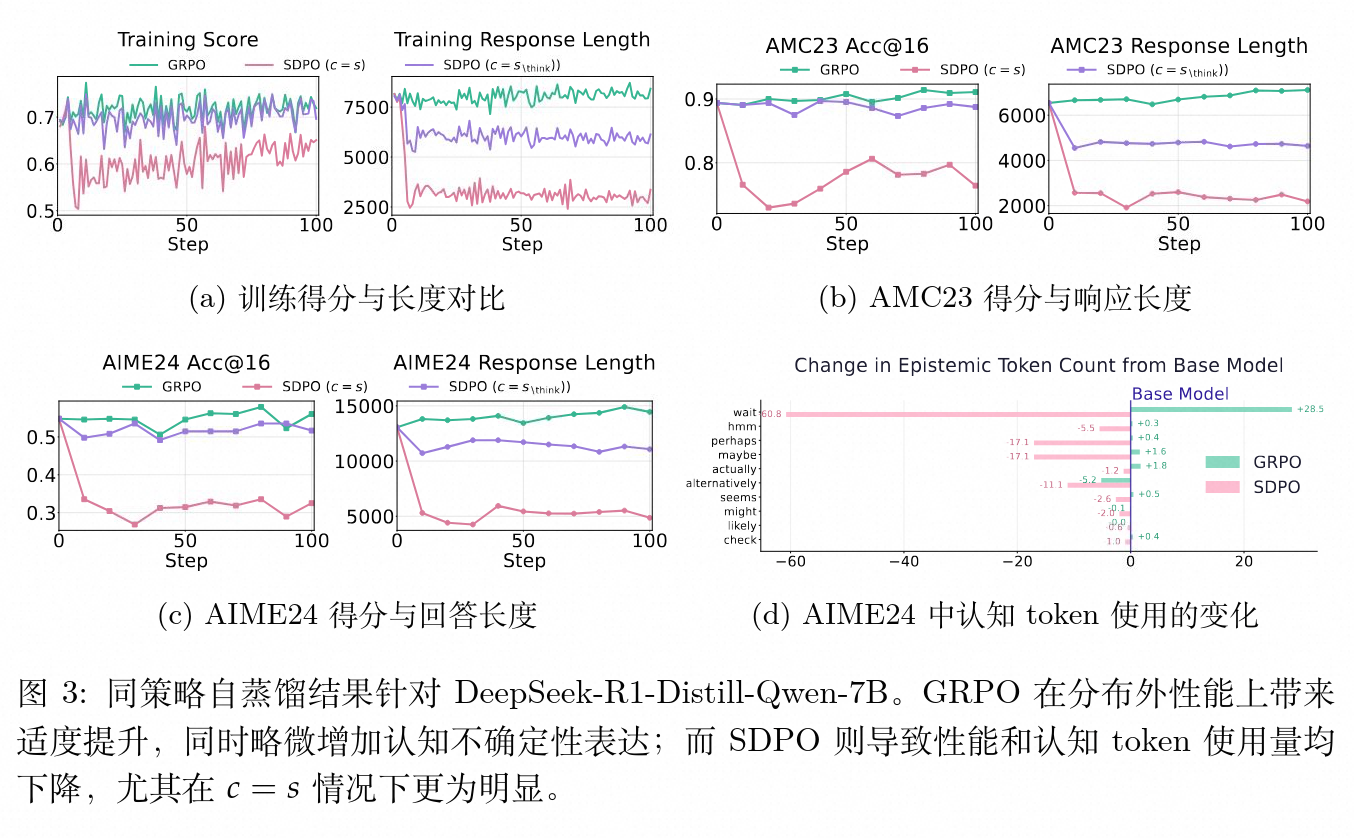
实验发现,使用标准 GRPO 训练时,模型的平均回复长度平缓增加,不确定性标记数量亦随之小幅上升,这带来了模型在分布外测试集(AIME24、AMC23)上分数的稳步提升。
然而,当应用 SDPO 且设置 (完整解答作为上下文)时,在训练初期,模型生成长度和训练分数均出现断崖式下跌。尽管在后续训练中分数有所回升,但始终未能达到 GRPO 的水平。分布外测试结果表明,SDPO () 在 AIME24 上造成了约 40% 的性能下降。
如果通过设置 减少教师模型的参考信息量,长度与分数的下跌现象会被明显缓解。这进一步验证了之前信息论的推论:教师提供的信息越具指示性,学生受到的压缩越严重,泛化性能退化越大。
5.2 Qwen3-8B(开启思考模式)实验分析
为了验证现象的普适性,研究使用了原生 Qwen3-8B 并在提示中强制其进入思考模式(包含 <think> 标签)。在此模式下,模型初始生成的序列甚至长于 DeepSeek,表现出高密度的不确定性标记。
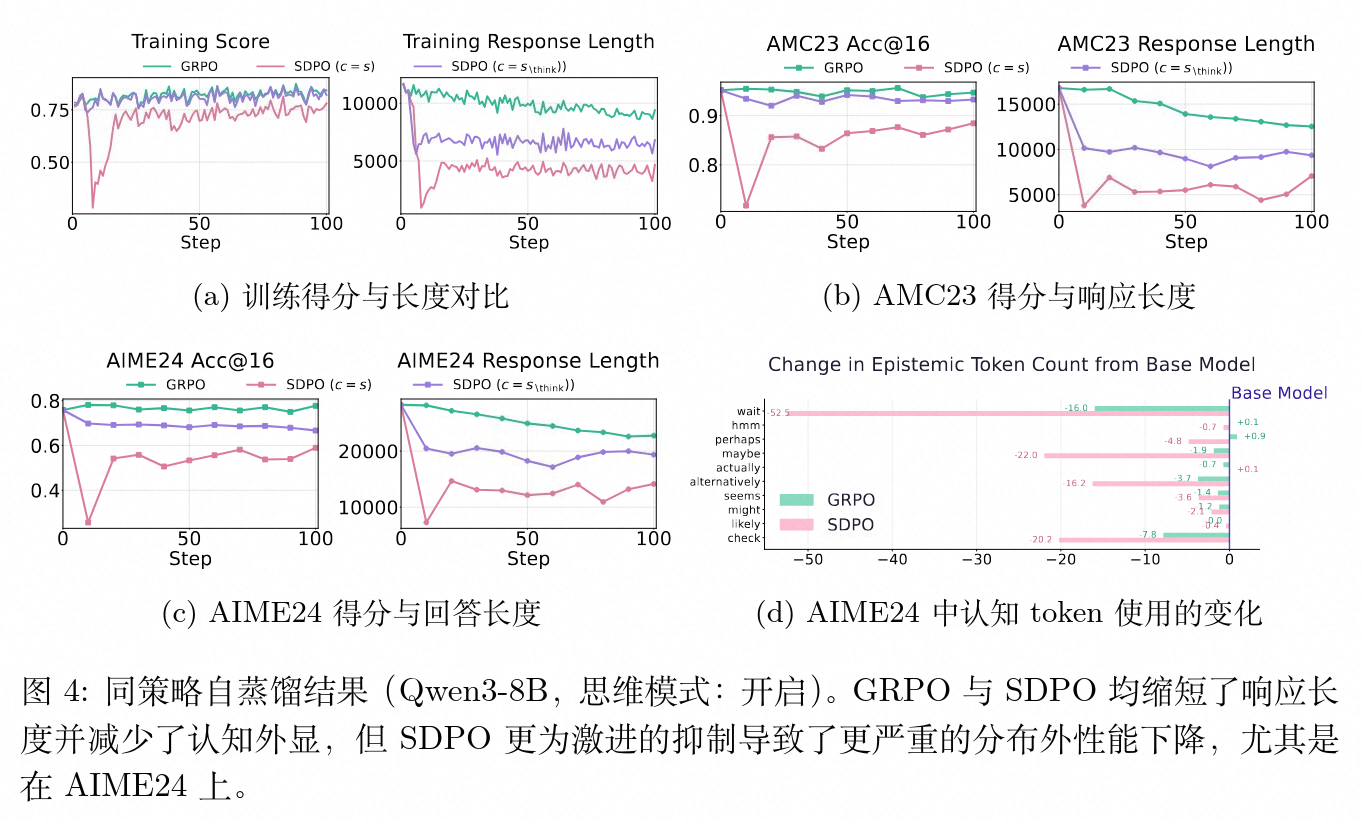
在此模型上,无论是 GRPO 还是 SDPO,均出现了回复长度下降的趋势。这表明该基座模型初始的推理可能包含部分无用的冗余长序列,GRPO 能够在这种情况下通过强化信号有效过滤掉非信息性冗余,同时保持 AIME 和 AMC 的性能平稳。而 SDPO 则呈现出更具攻击性的压缩,导致不确定性表达数量骤降。虽然在训练数据上 SDPO 和 GRPO 的性能相近,但在具有挑战性的 AIME24 OOD 测试中,SDPO 展现了不断恶化的性能指标,表现出明显的过拟合现象。
5.3 Qwen3-8B(关闭思考模式)实验分析
当 Qwen3-8B 不使用 <think> 标签时,模型起初生成的答案短促且表现较弱。
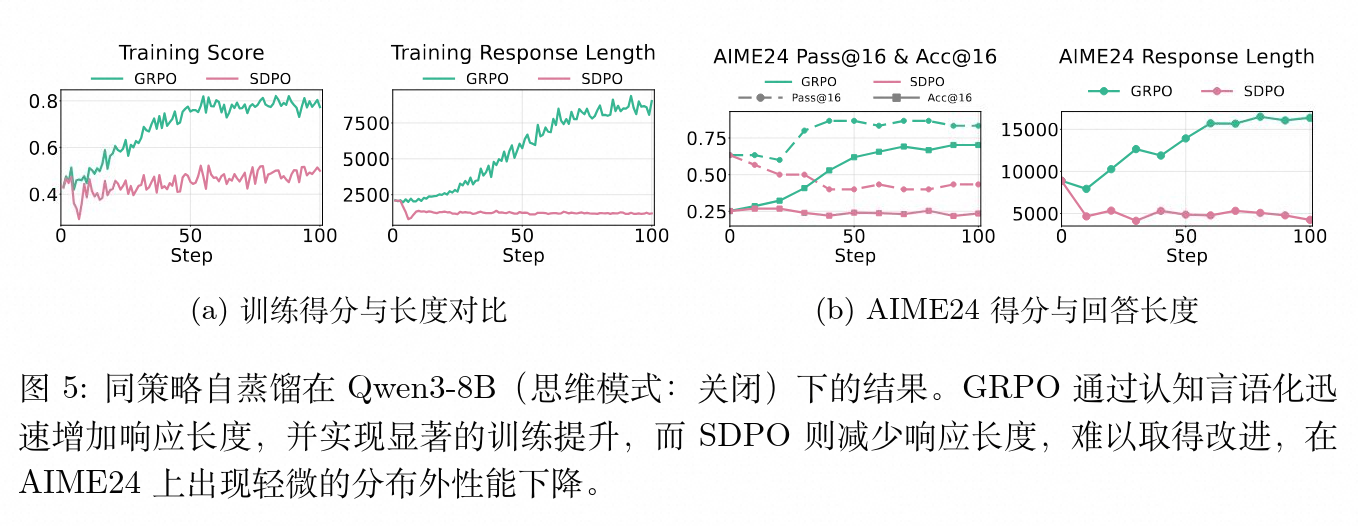
由于缺失了思考过程的训练偏置,GRPO 算法在训练开始后迅速驱动模型通过拉长回复并大量植入认知不确定性标记来提升推理准确率。相反,SDPO 则因为教师模型的制约,持续压缩长度,改进十分缓慢。即便 SDPO 的训练集得分出现了轻微上涨,其在 AIME24 等测试上的表现依旧略有衰退。这证实了在模型尚未建立充分的试错推理习惯时,自我蒸馏的截断效应会锁死其探索正确推理空间的路径。
5.4 OLMo-3-7B-Instruct 模型扩展
为排除现象特定于单一模型架构的怀疑,研究人员在完全不同的 OLMo 系列模型上复制了实验。
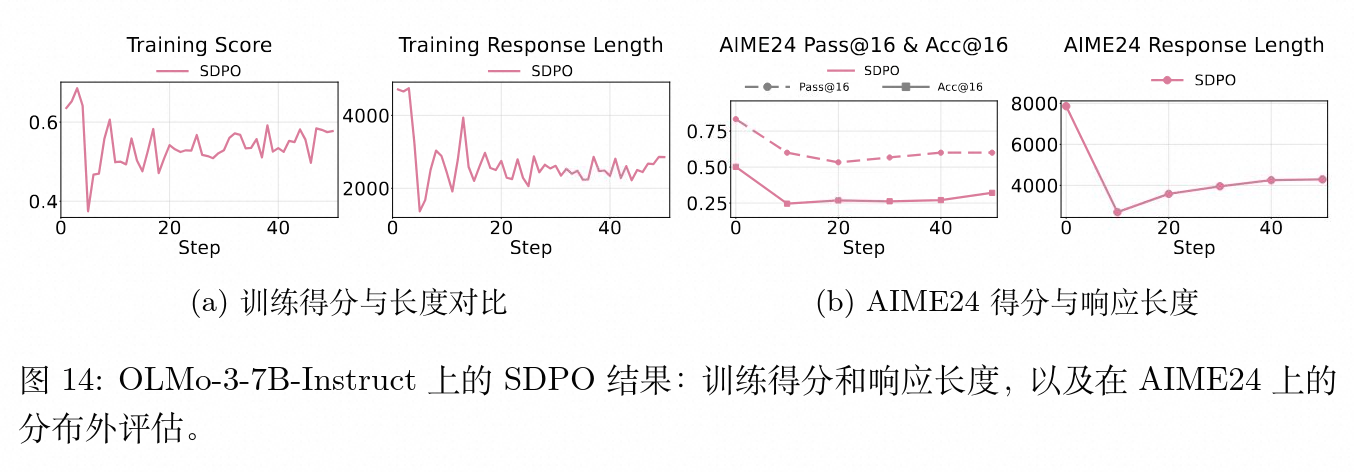
评估结果一致表明,SDPO 同样损害了 OLMo 模型的分布外数学推理性能。这证明了抑制不确定性表达对逻辑泛化能力的破坏是跨模型体系系别存在的普遍特性。
6. 任务覆盖度如何调节自我蒸馏的效果
如果自我蒸馏确实会由于压缩认知不确定性而损害推理能力,为什么在之前的研究中,SDPO 在化学、代码生成等领域却取得了缩短长度与提升准确率的双赢?研究人员将其归结为训练和评估分布间的“任务覆盖度”(Task Coverage)差异。
6.1 各领域数据集结构差异对比
为了探究根本原因,研究对比了不同领域基准数据集的结构特性。
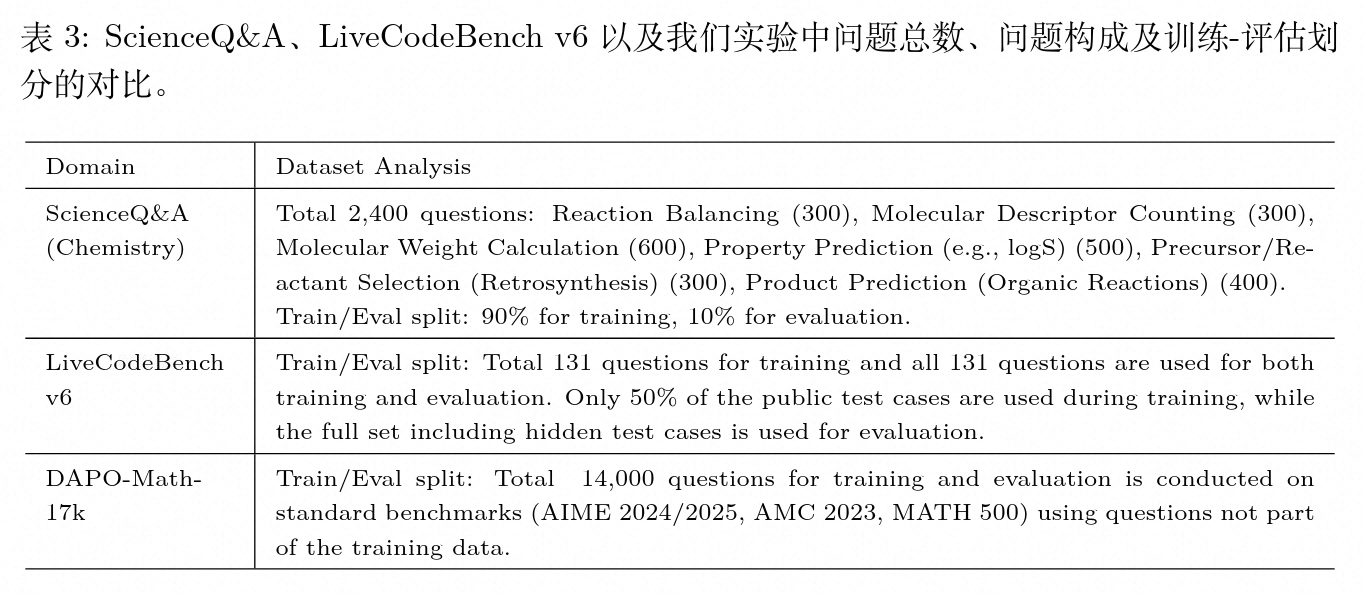
-
化学领域(ScienceQ&A):拥有 2400 道训练题,但这些题目仅源自 6 个基本问题模板(如计算相对分子质量、反应配平等)。这些问题底层结构同质化高,变动仅存在于表面参数的替换。 -
代码领域(LiveCodeBench v6):包含多样化的代码编写问题,但总问题数量仅为 131 题。在相关的 SDPO 研究中,训练集和评估集甚至使用相同的题目范围。 -
数学领域(DAPO-Math-17k):包含 14,000 道不同的数学题,涵盖几何、代数、数论、组合等多重领域,并且测试集(AIME、AMC、MATH)考查的是在结构和难度上完全未见过的组合推理能力。
基于此,研究提出了一个核心假说:当领域任务覆盖度狭窄、存在大量重复结构时,模型可以依靠参数化记忆来实现快速求解。此时,长推理序列确实是效率低下的冗余(Stylistic redundancy),自我蒸馏将其压缩有助于优化;但当领域具有高度异构的复合性需求(如广泛的数学题库)时,保留试错和回溯能力变得至关重要。
6.2 任务规模()消融实验
为了通过实证检验这一假说,研究人员使用 DAPO-Math-17k 数据集的一个不断扩大的子集进行了控制变量实验。设置训练题目数量 ,并分别运行 GRPO 和 SDPO 算法。
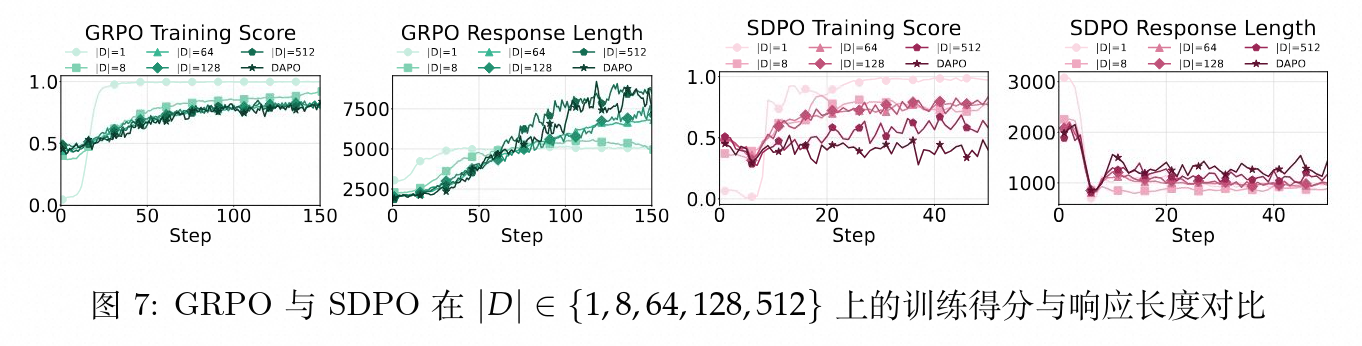
实验日志呈现出高度具有启示性的动态演化:
当 时,SDPO 展现了更高的训练效率,其分数攀升快于 GRPO,并将输出长度压缩了近 8 倍。这表明在小型任务集上,自信且简短的模式更有利于针对有限模式的优化。
然而,当 时,任务的逻辑广度超出简单的记忆范畴。此时 SDPO 长度的进一步压缩开始导致训练分数的下滑。相较之下,GRPO 在面对扩展的任务集时,自适应地增加了回复长度(表现为不确定性标记用量的增加),从而维持了分数的上涨趋势。
6.3 OOD 泛化性能的交叉现象
这种任务覆盖度导致的差异在分布外基准评估(如 MATH500 和 AIME24)上体现得更为彻底。
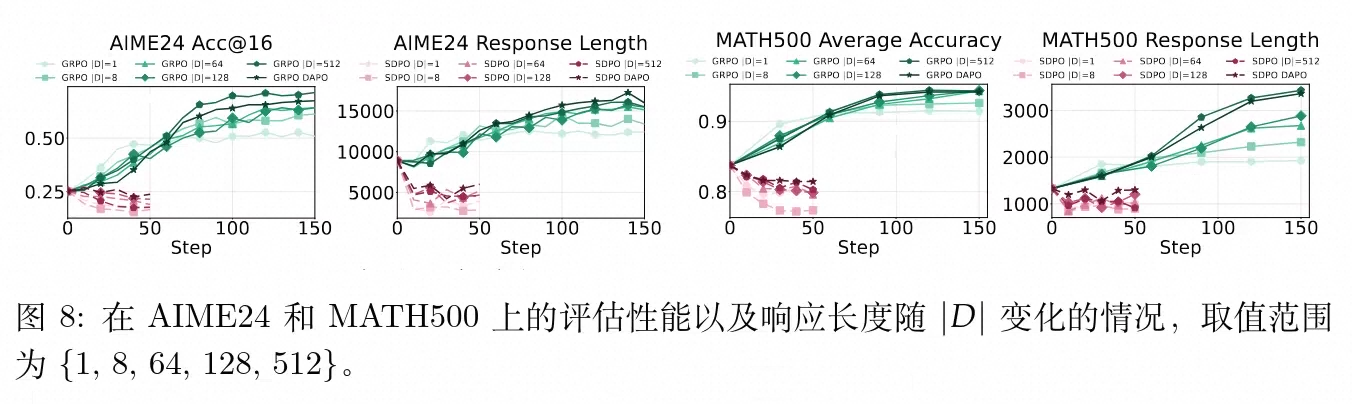
对于 GRPO,模型的分布外性能与 呈现显著的正相关扩展(Scaling)。较大的 不仅引导模型生成更长的探索序列,也实现了更好的泛化。
反观 SDPO 出现了相反的规律:任务数越少,性能衰退越严重;虽然扩大数据集使得性能损失有所减缓,但即使在全量数据集中,SDPO 的泛化表现也无法追平基础模型。
实验总结出一个关键规律:认知不确定性表达的价值取决于任务环境对泛化能力的需求。面对熟悉且重复的问题,这种试错式思考是可舍弃的冗余;但在面对超出预见范围的新异数学问题时,这部分看似无关紧要的思考正是保证正确率的核心引擎。
7. 消融实验与模型训练稳定性探讨
为了验证结果并非由于某些特定超参数设置造成的偶然现象,研究中包含了一系列消融实验。
7.1 教师策略更新频率(固定与移动目标)
在标准的在线自我蒸馏实现中,往往采用指数移动平均(EMA)或者定期同步的方式更新教师模型,这意味着教师是一个不断向学生靠近的“移动目标”。
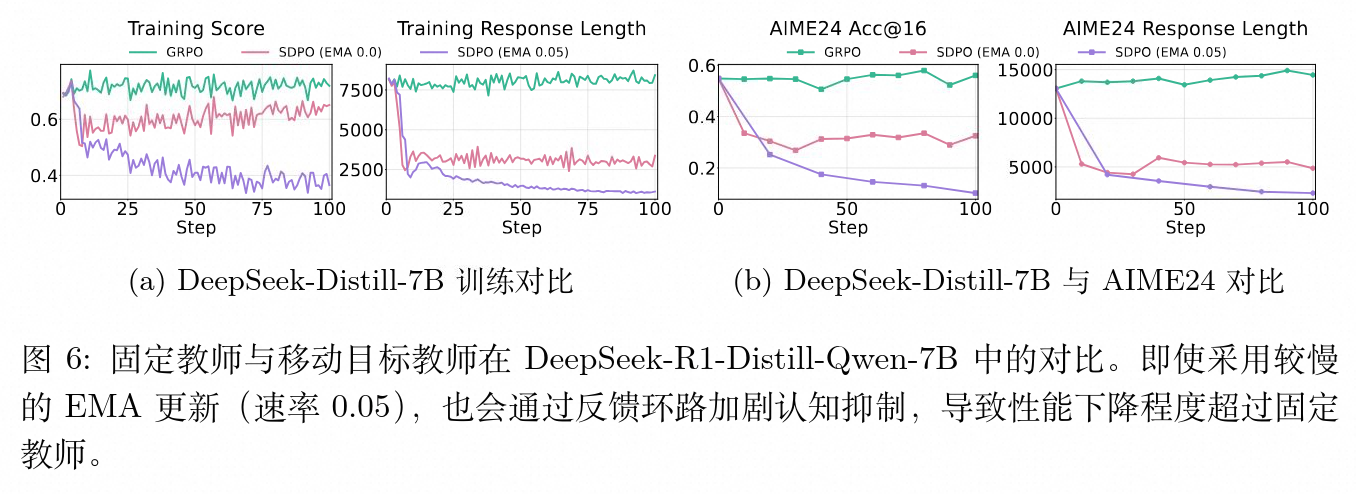
研究对比了设定 EMA 更新率为 0.05 与 EMA 更新率为 0.0(即固定初始策略为教师)的实验结果。观测表明,即使是 0.05 这种非常缓慢的更新率,也会在训练中引起恶性反馈循环:模型在某一步被训练变得更加自信并缩短了回复,而更新后的教师在处理相同输入时又会生成比此前更加短促、更加缺乏不确定性的轨迹,进一步教导学生加剧这种压缩。这种正反馈回路最终造成了比采用固定目标教师更为剧烈的性能滑坡。
7.2 Top-K 截断与学习率的影响
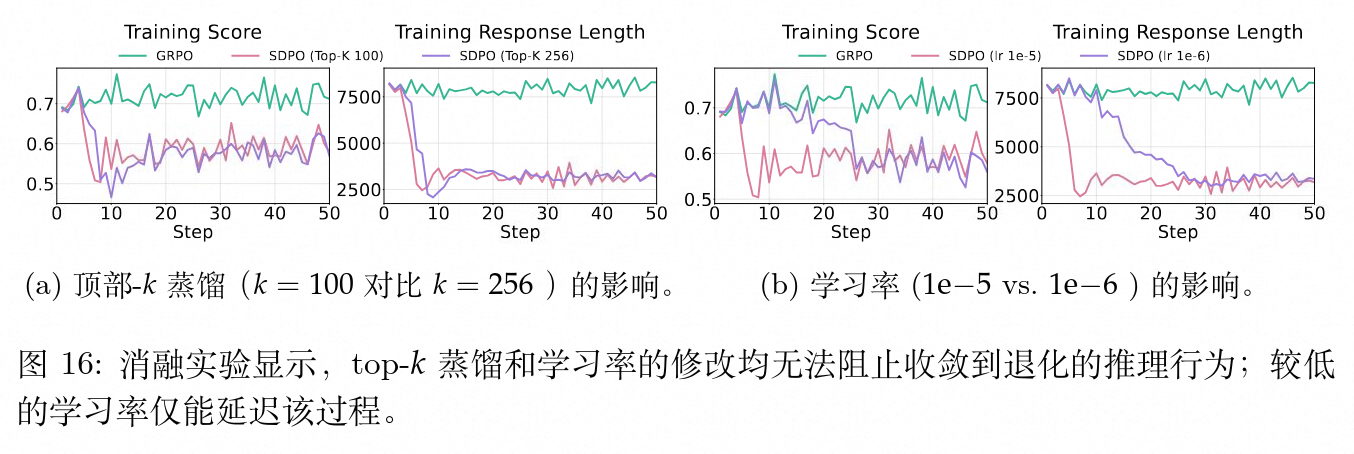
在使用 Jensen-Shannon 散度匹配教师和学生分布时,为避免计算整个词表概率分布的开销,通常采用 Top-K 截断。对比 和 发现,这一参数对最终性能衰退幅度无明显影响。同时,将学习率从 1e-5 调整为 1e-6,仅仅起到了延缓退化发生时间的作用,随着优化步数的推进,模型无可避免地汇聚到了过度自信和性能下降的终点。
7.3 OPSD 混合配置探讨
在近期的文献中,OPSD(On-Policy Self-Distillation for Large Language Models)等工作提出了一种混合结构配置:教师模型开启思考模式(保证高质量推理),而学生模型关闭思考模式进行拟合,且仅对生成的前缀进行训练。
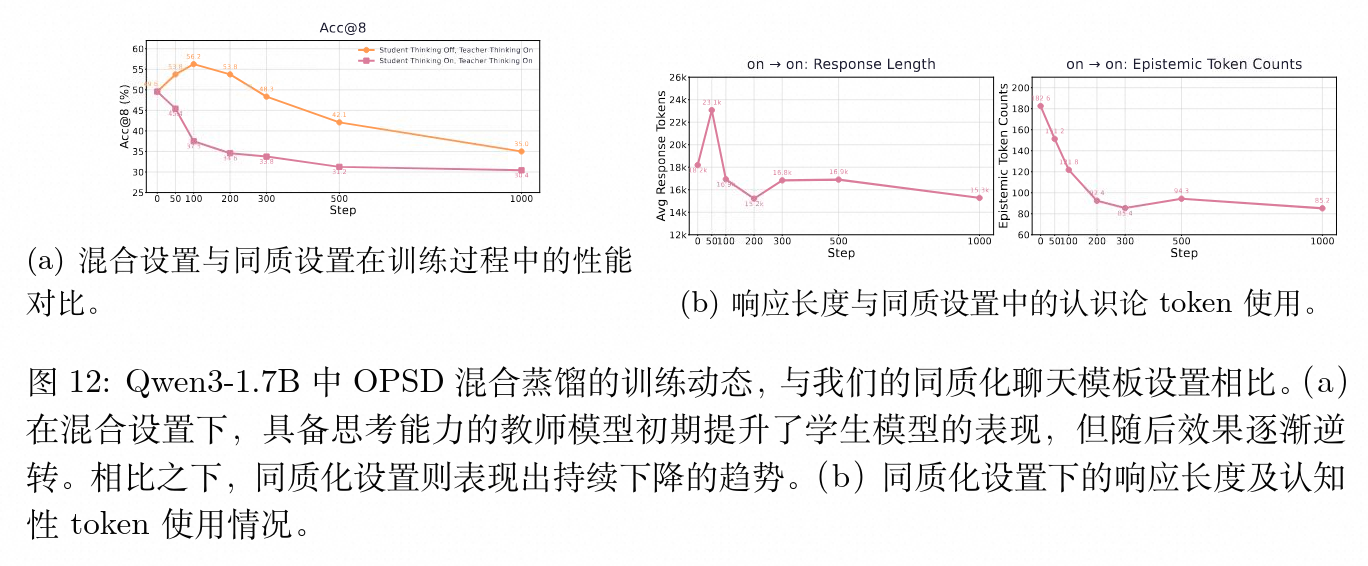
该论文在 Qwen3-1.7B 上的复现指出,在这一特定的混合机制下,训练初期教师生成的高包含不确定性表达的序列确实暂时引导学生生成了较长输出并提高了分数。但在中后期,长度和精度仍然开始同步下跌。并且,此类特定配置无法拓展至那些没有显式系统层面“思考模式”开关的模型族类。这一现象为未来的不匹配配置下的蒸馏动力学研究提供了方向。
8. 附录
8.1 个体词汇级别的分布变化
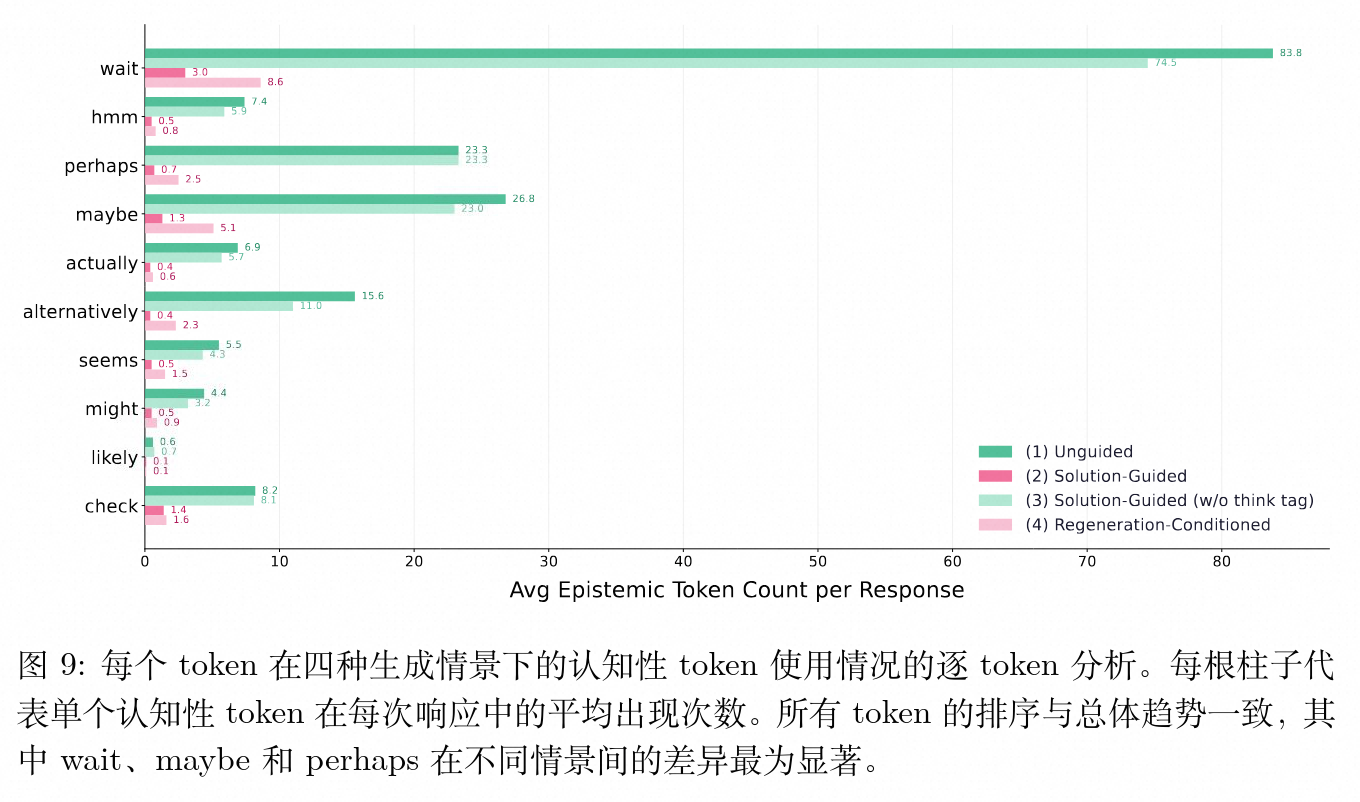
对 10 个特定认知标记的独立统计显示,“wait”、“perhaps”和“maybe”这类标记对条件上下文的丰富度最为敏感。在无引导生成中,“wait”经常被用来打断模型正在生成的某个错误逻辑闭环;而当标准答案被提供后,模型不再具备向错误方向滑落的前提条件,因此“wait”这类纠错触发器的频率断崖式下降。
8.2 模型间不确定性表达偏好的差异
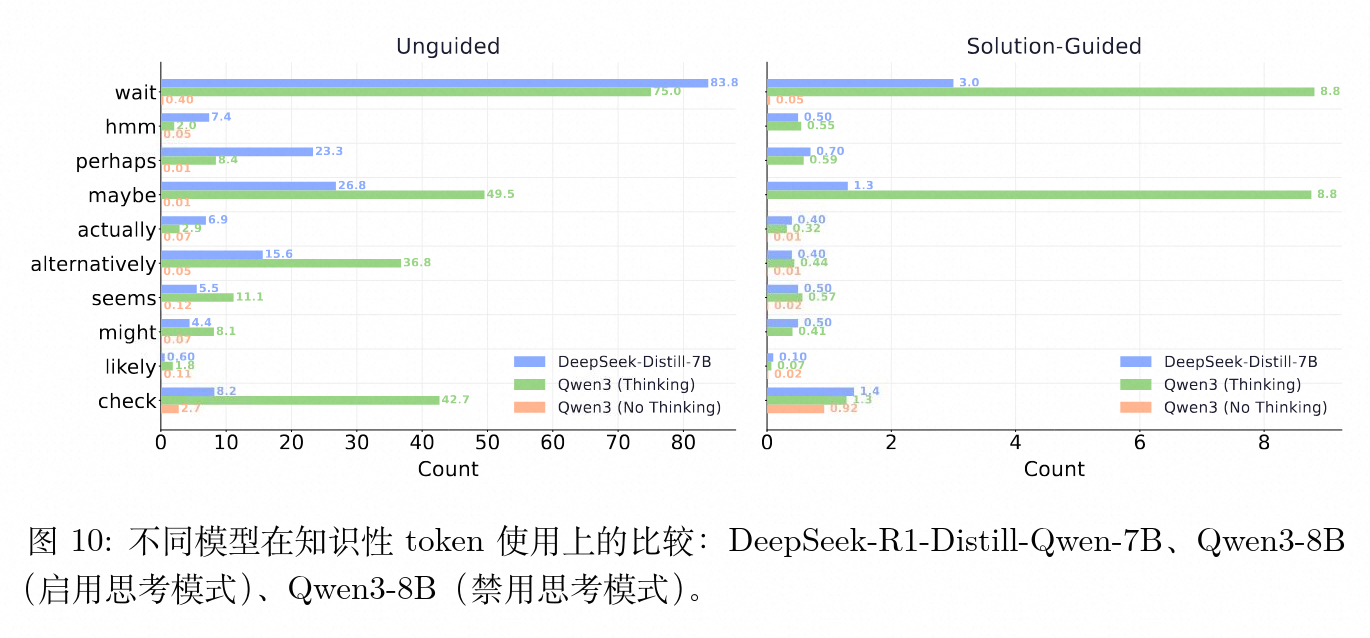
深入对比基础模型可以发现各模型具有不同的内部“思考词汇”。DeepSeek-R1-Distill 倾向于使用“wait”和“perhaps”来表征迟疑;而开启思考模式的 Qwen3-8B 对“maybe”、“alternatively”和“check”的使用更为频繁。这证明了表达不确定性并不是某一家模型的工程 Trick,而是一种随着自回归语言模型扩大规模、进行 RLHF 优化后,自然涌现的共性行为。
8.3 Pass@16 与 Acc@16 评估指标
除了展示多轮采样中的 Acc@16 准确率,研究还统计了 Pass@16。
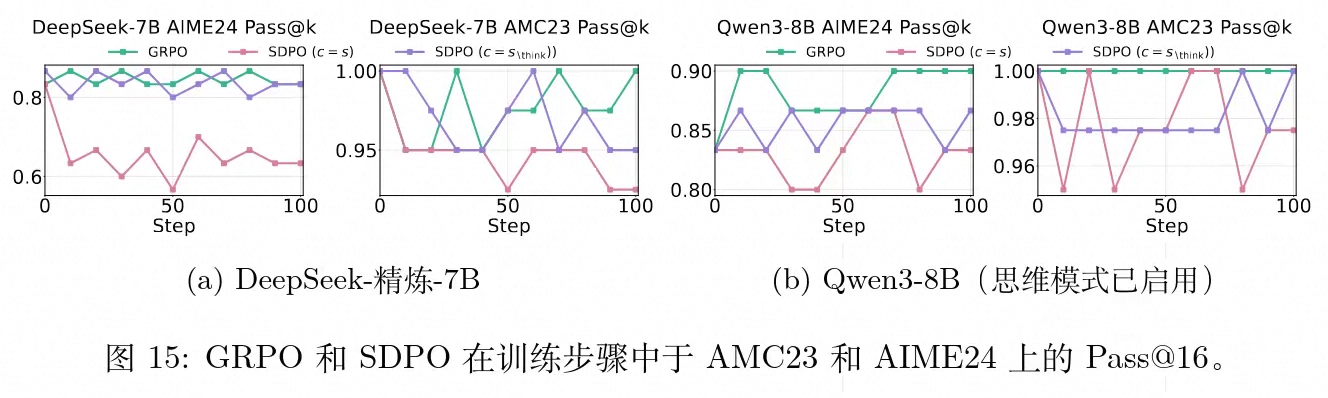
数据表明,自我蒸馏在压缩推理长度的同时不仅降低了单次生成的准确期望,也明显减少了多次采样的通过率上限。这说明在抑制了认知不确定性后,模型产生的多样性大幅收敛,丧失了在多条不同分支上进行探索搜索的能力。
9. 一些启示
9.1 测试时计算(Test-Time Compute)的内在机制
随着 o1、R1 等推理模型的出现,“通过增加测试时计算量换取性能提升”被视为一种核心扩展定律(Scaling Law)。许多后训练优化的目的是想将这部分漫长的计算过程蒸馏进模型权重之中。然而,该文的发现表明,这部分额外的长度往往承载着维持计算灵活性和多分支动态剪枝的关键步骤。简单地约束输出长度或者匹配无错误的高效路径,会剥夺支撑数学推理的核心机制。在对复杂推理模型进行蒸馏时,不仅要学习其结论和主干路径,更要有效保留其在面对陌生结构时的挣扎(Struggle)、反思(Reflection)与纠错过程。
9.2 强化学习目标函数的设计缺陷与改进方向
在目前的大量强化学习从反馈优化过程中,无论是 PPO 还是使用外部奖励模型,其目标常常仅聚焦于最终答案的绝对准确与否。这种稀疏反馈下,如果在此基础上引入任何压缩向的正则项(例如长度惩罚或 KL 分布强制约束),极易产生负面效果。未来目标函数设计必须将“探索行为的质量”作为维度之一。这需要将单纯评估“答案正确性”的奖励延伸至对“认知不确定性暴露”行为本身的适当包容乃至鼓励,避免模型形成盲目确定的捷径倾向(Shortcut learning)。
9.3 高质量数据合成与自我反思机制的结合
由于 SFT 使用的 会导致崩溃,生成用于合成训练的轨迹时不能图方便仅让教师模型直接生成短促答案。相反,在使用更强大模型(如 GPT-4 或 o1)生成合成数据(Synthetic Data)以训练小规模模型时,必须刻意在 Prompt 中取消直接的解法引导,甚至需要主动构造包含试错死胡同、并包含“wait, let me check”随后进行修正的迂回轨迹,才能使得小模型真正学到处理长程逻辑的能力。
10. 结论
该研究揭示了后训练中一个隐秘且重要的机制漏洞,指出,对于自我贝叶斯推断特性极强的数学推理而言,语言模型输出中的认知不确定性表达是支持其执行纠错和寻找解答的核心组成部分。
自我蒸馏算法尽管在特定情境下提供了高效的推理压缩途径,但由于其内生机制倾向于通过提供丰富上下文来训练模型产生简短、过度自信的响应,在任务具有广泛性且高度要求分布外泛化时,其实际效果会适得其反。模型因此失去了试错的宽容度,导致准确率下滑。
更多细节请阅读原文。
往期文章:

