让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents
-
论文链接:https://arxiv.org/pdf/2604.24005v1
TL;DR
今天解读一篇来自阿里通义实验室(Tongyi Lab)和香港中文大学的论文《TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents》。该研究主要探讨了大语言模型(LLM)在多轮交互智能体(Multi-turn Autonomous Agents)场景下进行同策略蒸馏(On-Policy Distillation, OPD)时面临的核心挑战与解决方案。
在静态的单轮任务(如数学推理、问答)中,同策略蒸馏已经展现出将前沿模型或领域专有模型的推理能力转移给小参数学生模型的潜力。然而,作者发现,当直接将基础的同策略蒸馏应用于需要基于不断增长的历史信息进行连续推理和行动的多轮智能体时,会引发一种被称为轨迹级KL散度不稳定(Trajectory-Level KL Instability)的失效模式。随着交互轮数的增加,学生模型累积的错误会将其推向教师模型有效支持范围之外的状态,导致KL散度激增、任务成功率崩溃,监督信号变得不可靠。
为了解决这一问题,作者提出了时序课程同策略蒸馏(TCOD, Temporal Curriculum On-Policy Distillation)框架。该框架通过控制暴露给学生模型的轨迹深度,并根据设定的课程进度从短轨迹逐步扩展到长轨迹,从而缓解了复合错误带来的影响。实验表明,TCOD 在 ALFWorld、WebShop 和 ScienceWorld 等多轮智能体基准上,不仅有效缓解了KL散度激增,稳定了训练过程,还将学生模型的成功率相较于基础同策略蒸馏提升了最高 18 个百分点。更重要的是,在教师模型自身表现不佳的困难任务集上,TCOD 能够超越教师模型的能力边界,展现出更强的泛化性,同时还能减少高达 32% 的整体训练时间。
1. 引言
大型语言模型作为多轮智能体在具体任务规划、网页导航和交互式环境中的应用日益广泛。通常,这类系统采用 ReAct 等框架,交替生成推理过程(Chain-of-Thought)和可执行动作。然而,训练这类多轮智能体面临着长视野信用分配、记忆管理以及在稀疏奖励设定下强化学习样本效率低下等挑战。
近期,同策略蒸馏(On-Policy Distillation, OPD)作为一种替代稀疏标量奖励的方案受到关注。OPD 通过最小化学生模型生成的轨迹(Rollouts)与教师模型给出的词元级(Token-level)概率分布之间的 KL 散度,提供了密集的蒸馏信号,从而提高了样本效率。现有的改进工作主要集中在目标函数设计、优化启发式方法(如奖励裁剪)和替代监督源上。
然而,这些方法本质上是为静态、单轮推理任务设计的。多轮智能体环境具有动态性和长视野特性,模型必须基于不断增长的序列交互历史进行推理和行动。基础的 OPD 能否安全地泛化到这种环境中,是一个尚未充分探索的关键问题。
本文的动机正是源于对这一问题的实证观察。作者发现,在多轮机制下盲目应用基础 OPD 会导致严重的训练不稳定。具体而言,多轮交互中的复合错误(Compounding Errors)会逐渐将学生模型推向分布外(Out-of-Distribution, OOD)状态,在这些状态下,教师模型无法提供有效的支持。结果是,教师模型对学生生成的响应赋予极低的概率,表明 KL 散度在每一轮都在增加,最终导致监督信号失效。基于这一发现,作者引入了课程学习(Curriculum Learning)的思想,提出了 TCOD 框架,通过控制训练期间智能体交互的轨迹深度,逐步从简单(短视野)过渡到困难(长视野),从而在保留 OPD 密集信号优势的同时,避免了长视野交互中累积错误导致的系统失稳。
2. 预备知识与问题定义
在深入探讨本文发现的现象和提出的方法之前,需要先明确多轮智能体交互和同策略蒸馏的数学形式化定义。
2.1 多轮智能体的历史状态
研究考虑的是多轮自主智能体在有限视野(Finite Horizon)内与环境的交互过程。设定 表示轨迹内的交互轮次数索引,其中 是最大交互步数。
在每一轮 ,智能体接收到一个环境观察 ,生成一个响应 ,随后环境返回下一个观察 。按照当前主流的智能体框架,每个响应 包含一段思维链(Chain-of-Thought)推理轨迹,紧接着是一个可执行的动作。
由于环境通常是部分可观察的,作者将智能体的状态定义为截至当前观察的完整交互历史:
在这个定义下,一个完整的轨迹可以表示为 。该轨迹会在智能体采取终止动作,或者达到最大视野 时结束。
2.2 多轮智能体的同策略蒸馏
给定一个参数化的教师策略 和一个参数化的学生策略 ,同策略蒸馏的目标是在学生模型自身的状态分布下,将学生策略与教师策略对齐。其优化的目标函数定义为:
其中, 是用于衡量在给定历史状态 下,教师策略 和学生策略 之间差异的 KL 散度。
在这个公式中,期望 表明轨迹数据是由当前的学生策略采样生成的,这正是“同策略(On-Policy)”的核心特征。这种设定的初衷是让学生模型在其自身可能探索到的状态空间中学习,从而纠正自身的错误。然而,正如后文所述,这种设定在多轮长视野任务中引发了严重的问题。
3. 多轮同策略蒸馏中的轨迹级KL散度不稳定现象
为了检验基础 OPD 在多轮设定下的行为,作者在 ALFWorld 具身导航基准上进行了一项先导研究。实验系统地评估了 Qwen3 和 Qwen2.5 模型系列中的不同师生配对。对于 Qwen3,使用 Qwen3-30B-A3B-Instruct 作为教师,Qwen3-{0.6, 1.7, 4}B 作为学生;对于 Qwen2.5,采用经过 GRPO 训练的 Qwen2.5-7B 模型作为教师,Qwen2.5-{0.5, 1.5, 3, 7}B 作为学生。
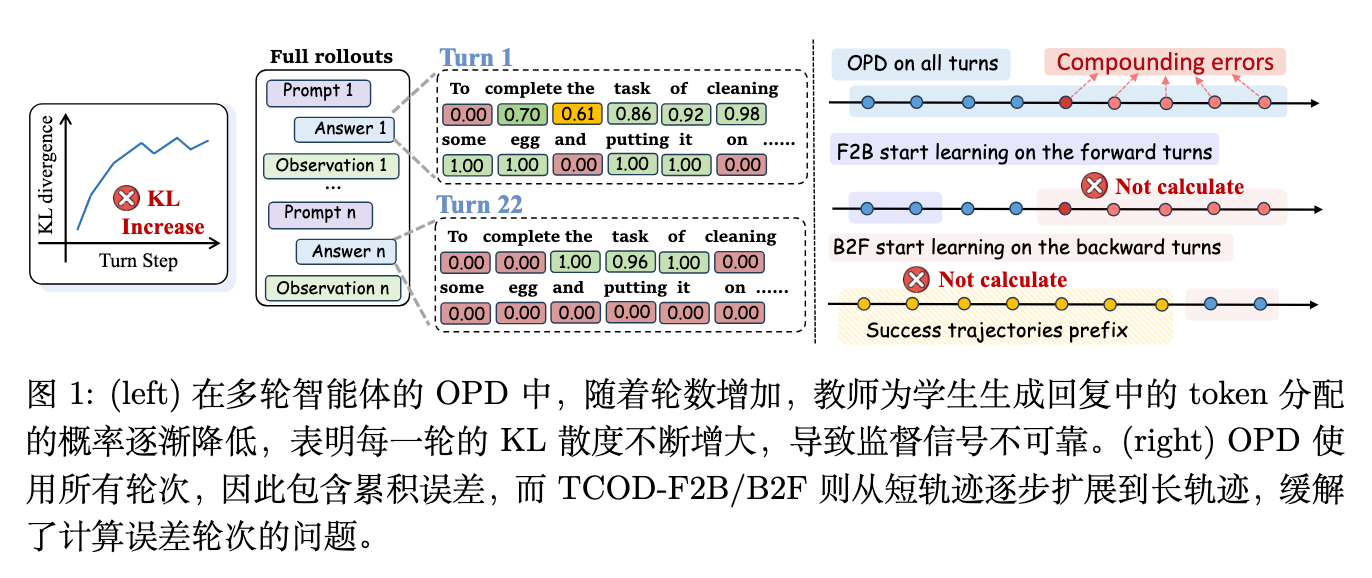
3.1 观察结果 1:KL散度激增与成功率崩溃同时发生
在单轮任务(如数学解题或单轮问答)的现有研究中,KL 散度通常会在整个训练过程中持续收敛并下降。然而,作者在多轮智能体场景中观察到了截然不同的现象:KL 散度随着训练步数的增加而激增。
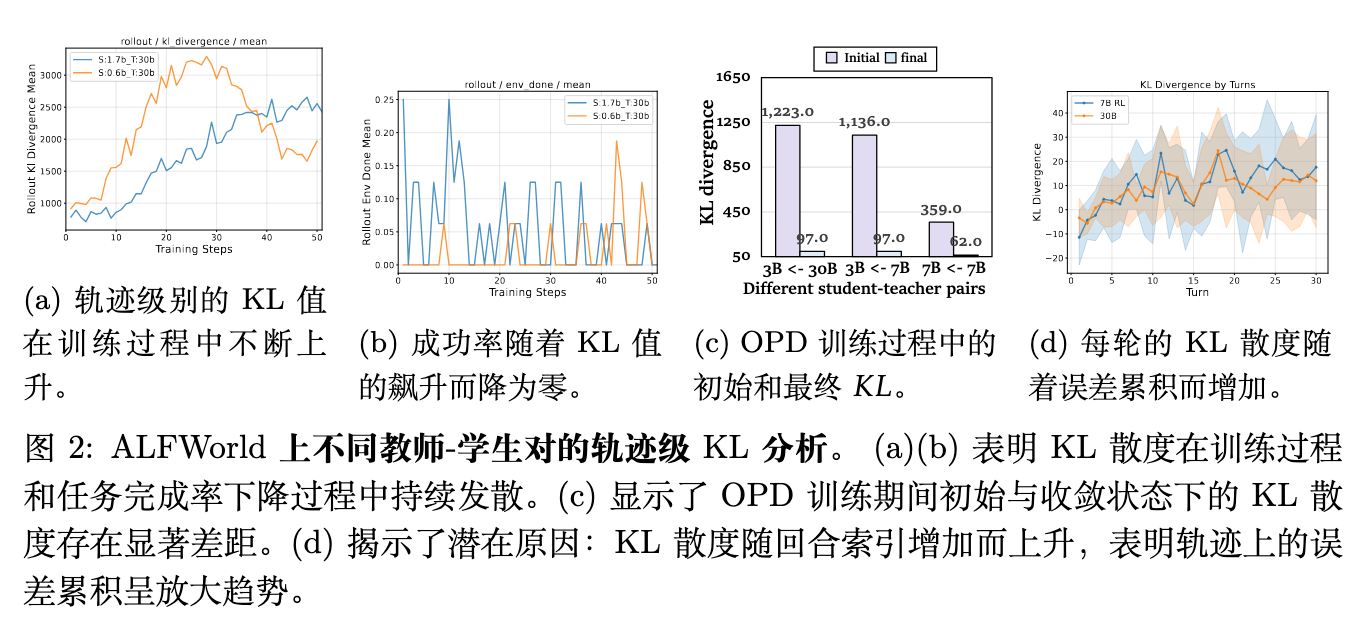
如论文图 2a 和图 2b 所示,当使用基础 OPD 训练学生模型(例如 Qwen3-0.6B 或 1.7B),并由一个强大的教师模型(Qwen3-30B-A3B-Instruct)提供监督时,轨迹级的 KL 散度在训练初期迅速攀升,与此同时,任务的成功率骤降至接近零的水平。这种现象表明,学生模型在训练过程中不仅没有学到教师的能力,反而失去了原本的基础能力。
3.2 观察结果 2:初始KL散度过高且收敛困难
即便对于参数量较大的学生模型,虽然其 KL 散度最终能够收敛,但它们在训练初期会经历一个极高的 KL 散度阶段。论文图 2c 展示了不同师生配对下的初始和最终 KL 散度对比。例如,在由 Qwen3-30B-A3B-Instruct 蒸馏至 Qwen3-3B,以及由 GRPO 训练的 Qwen2.5-7B 蒸馏至 Qwen2.5-{3, 7}B 的实验中,初始的 KL 散度值(约 1000)通常比其最终收敛值(约 60)高出几个数量级。这种巨大的初始偏差表明多轮 OPD 训练过程存在严重的不稳定性。
3.3 潜在机制:轨迹上的复合错误放大
上述两个观察结果促使作者探究为何直接将 OPD 应用于智能体会导致 KL 激增和训练不稳定。论文图 2d 可视化了 Qwen2.5-3B 在不同教师监督下,每一轮(Per-turn)的 KL 散度变化。数据清晰地显示,KL 散度随着交互轮次索引的增加而持续上升。
无论这种增加的 KL 散度是反映了学生模型模仿教师能力的不足,还是因为学生模型进入了教师模型不确定的分布外(OOD)状态,根本问题都在于轮次间的错误累积(Error Accumulation over Turns)。
这是长视野多轮智能体固有的特性:学生生成的动作和环境返回的观察被不断追加到历史状态 中,导致跨轮次的因果耦合。如果在第 1 轮发生了一个微小的动作偏差,环境会返回一个偏离预期的观察结果,这个错误的观察结果又作为第 2 轮的输入,进一步放大误差。随着轮次增加,学生模型所处的环境状态完全偏离了教师模型在训练数据中见过的状态分布。在这种未知的状态下,教师模型给出的动作概率分布变得不可靠,从而产生了持续上升的 KL 散度趋势。对于小参数学生模型,这种复合错误是灾难性的;对于大参数模型,虽然能部分容忍,但训练效率依然极低。
补充说明(Remark 1):长思维链(Long-CoT)虽然也会增加响应长度,但它是在同一个环境状态下进行的。而多轮智能体在每次交互时都会通过结合新的观察和动作来更新环境状态,这使得复合错误在轨迹上的放大效应更加显著。
4. TCOD:时序课程同策略蒸馏框架
面对长视野交互中累积错误导致的失稳问题,作者引入了课程学习(Curriculum Learning)策略,提出了时序课程同策略蒸馏(TCOD, Temporal Curriculum On-Policy Distillation)。该方法的核心思想是在训练过程中控制智能体交互的轨迹深度,让模型先在简单(短轨迹)问题上训练,然后逐步暴露于困难(长轨迹)问题。
作者设计了两种具体的 TCOD 变体:前向到后向(TCOD-F2B)和后向到前向(TCOD-B2F)。
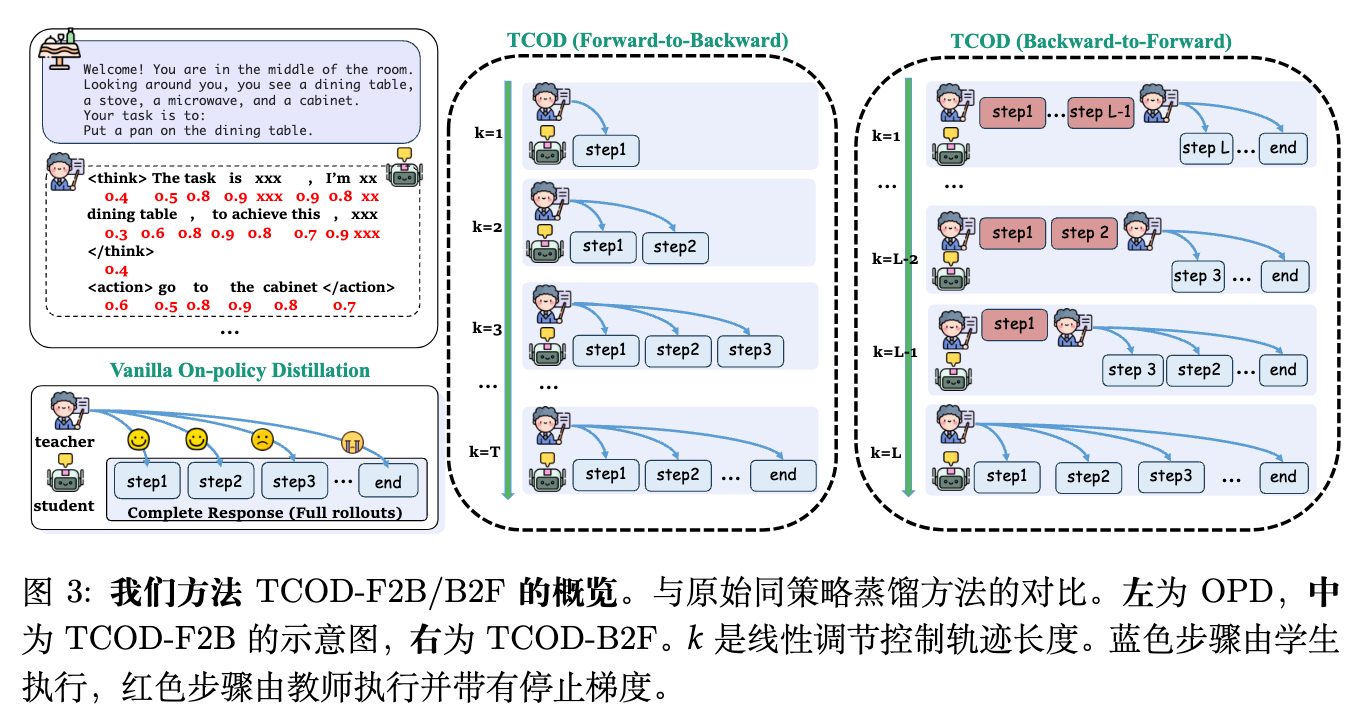
4.1 前向到后向的时序课程同策略蒸馏 (TCOD-F2B)
TCOD-F2B 实现了一种“由浅入深(Shallow-to-deep)”的课程策略,通过在训练过程中限制轨迹的最大交互步数来控制难度。
如论文图 3 中间部分所示,在 TCOD-F2B 中,学生策略 最多执行 步来完成任务。 的值从一个较小的数字开始,并逐步增加到更大的值。其目标函数定义为:
在这个机制下,学生模型首先专注于早期轮次的学习信号。因为早期轮次距离初始状态较近,累积的错误较少,教师模型提供的监督信号最为准确。随着 的增加,学生模型逐步完成端到端的任务。这种渐进式的暴露有效地缓解了复合错误,防止了由长视野引发的 KL 崩溃。
为了控制 的增长,作者采用了一种基于训练步数的线性步调(Linear Pacing)策略:
其中, 代表当前的训练步数, 是总训练步数, 定义了初始的交互步数, 控制课程的增长率(即每经过 步,最大视野 增加 1)。这种方法实现简单,只需要对基础代码进行极小的修改。
算法流程简述:在每个训练步骤 ,计算当前的最大步数 。初始化环境状态,学生模型开始采样动作并与环境交互,但强制在第 步停止。收集这 步的轨迹数据,计算与教师模型的 KL 散度并更新学生模型参数。
4.2 后向到前向的时序课程同策略蒸馏 (TCOD-B2F)
为了更好地利用教师模型的能力并完全规避早期轮次的错误累积,作者进一步提出了 TCOD-B2F。在这个变体中,教师策略 充当“领航员(Navigator)”的角色。
具体而言,首先需要使用教师模型预先收集一组成功的轨迹集合。对于某个任务的一条长度为 的成功轨迹 ,在训练时,环境首先被初始化为该轨迹的一个中间状态。这个中间状态是通过让教师策略 在环境中执行前 步得到的。如论文图 3 右侧所示,教师执行这前 步时不产生梯度更新(Stop Gradient)。随后,学生策略 从这个中间状态接管,继续进行规划和执行剩余的 步。
TCOD-B2F 的目标函数定义为:
这里的 同样按照前述的线性步调公式进行单调递增,直到学生模型能够在整个训练过程中端到端地完成任务。
这种机制通过确保学生模型只在由成功的、经过教师验证的前缀所引发的轨迹上进行优化,有效地绕过了复合动作错误。关键在于,轨迹中的教师执行步骤不参与梯度计算,它们的作用仅仅是将学生模型放置在“成功的门口(Doorstep of success)”。随着 的增加,学生模型接管的起始点逐渐向后推移(即越来越靠近初始状态),最终独立完成整个任务。
关于训练-测试不匹配的讨论:
在 TCOD-B2F 的训练初期,学生模型从教师导航的检查点开始行动,而在测试时,它必须从头开始端到端地执行。为了解决这种分布偏移,课程设计中逐渐将教师的前缀从 步减少到零。这样可以确保在训练结束时,学生模型在没有任何教师干预的情况下从初始状态执行完整的轨迹,从而完全对齐训练和测试分布。
4.3 异步训练与稳定性设计细节
虽然 TCOD 框架的核心概念直观,但在实际部署中,一些工程设计选择对训练稳定性和效率有着重大影响。作者在 8 张 NVIDIA H20 (96GB) GPU 上进行了实验,并采用了以下关键实现策略:
-
异步采样与训练(Asynchronous Rollout and Training):为了最大化 GPU 利用率,轨迹收集和模型优化被解耦为独立的异步进程。使用一组 Actor 进程进行环境交互以持续采样轨迹,而中央 Learner 进程则从共享缓冲区读取这些轨迹并执行梯度更新。系统采用无锁环形缓冲区(Lock-free ring buffer)以最小化同步开销。 -
感知陈旧度的子轨迹经验回放(Staleness-Aware Sub-trajectory Experience Replay):为了在多轮环境中最大化样本效率,每一条完整的轨迹被分解为一组递归的子轨迹。具体来说,对于长度为 的轨迹,每个前缀序列 作为独立的经验条目存储在回放缓冲区中。为了防止输入上下文超过模型的有效内存限制从而导致训练不稳定,交互历史被封装为结构化上下文。 -
陈旧度过滤(Staleness Filter):在异步设定下,每条轨迹都会标记用于收集它的策略版本号 。系统实现了一个陈旧度过滤器,丢弃任何满足 的经验。经验表明,设置 能够在样本效率和严格的同策略约束之间取得最佳平衡。
5. 实验设置
作者设计了全面的实验来评估 TCOD 的有效性,主要回答以下三个关键问题:
-
Q1:与基础 OPD 相比,TCOD 如何缓解 KL 激增并恢复小模型的性能?它如何增强大模型的训练稳定性和性能? -
Q2:TCOD 能否使学生模型有效地泛化到超出教师自身能力边界的任务上? -
Q3:TCOD 对课程增长率的敏感度如何?在训练效率方面与基础 OPD 相比表现如何?
5.1 基准环境
实验在三个多轮智能体基准上进行,涵盖了从简单到复杂的不同推理层级:
-
ALFWorld:基于文本的具身导航环境,要求智能体在六类家庭任务中进行导航和物体操作。评估包含 seen(可见)和 unseen(未见)划分,其中 unseen 包含训练期间未遇到的房间布局和物体组合,作为分布外(OOD)评估。此外,作者还构建了一个 Hard(困难)集,包含 121 个教师模型在训练集上采用 pass@10 采样仍失败的任务,用于测试学生模型是否能超越教师边界。 -
WebShop:一个电子商务平台环境,要求智能体通过多轮交互搜索并选择符合用户自然语言指令的商品。 -
ScienceWorld:测试科学推理能力的环境,包含 30 种与小学科学课程对齐的任务类型。
5.2 模型与基线对比
-
主实验(ALFWorld):使用 Qwen2.5-3B 和 Qwen2.5-7B 作为学生模型,教师模型是在 ALFWorld 领域上经过 GRPO 微调的 Qwen2.5-7B。 -
跨基准评估:使用 Qwen3-1.7B 和 Qwen3-4B 作为学生模型,通用模型 Qwen3-30B-A3B-Instruct 作为教师。 -
基线方法: -
Zero-Shot 学生模型:作为经验下界。 -
Teacher (Oracle):教师模型直接评估,作为理论上界。 -
SFT (监督微调):标准的离线行为克隆。 -
Vanilla OPD (基础同策略蒸馏):不带时间课程控制的标准多轮 OPD。
-
评估指标主要采用成功率(Success Rate, SR),即成功完成任务的百分比。此外还报告了平均动作轮数(Rounds)。
6. 实验结果与分析
6.1 Q1:缓解KL激增与提升性能
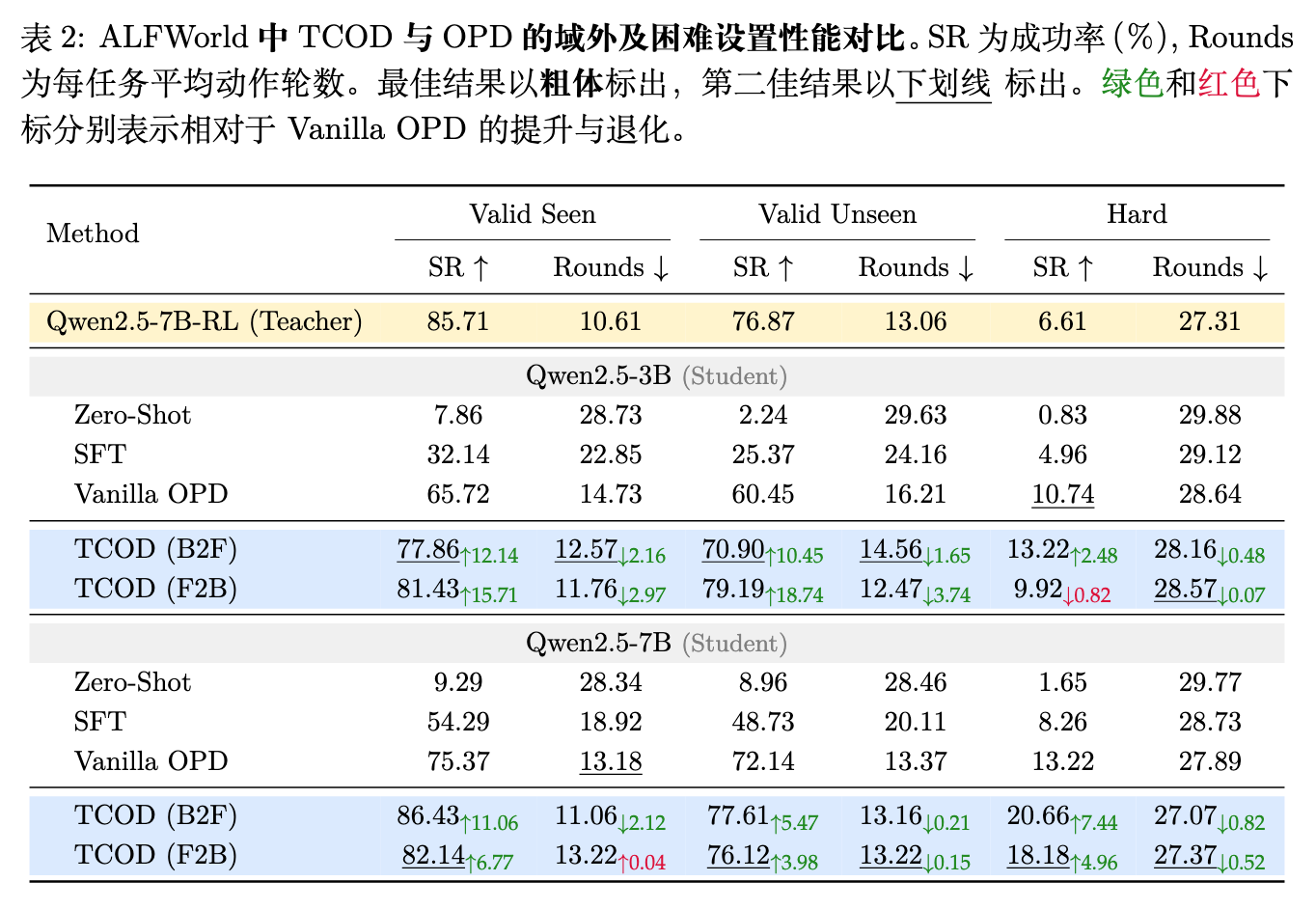
ALFWorld 上的表现:如论文表 2 所示,在 ALFWorld 环境中,以 Qwen2.5-3B 和 Qwen2.5-7B 为学生模型时,TCOD-F2B 和 TCOD-B2F 在各个模型规模上均大幅超越了基础 OPD 和 SFT。值得注意的是,对于 Qwen2.5-3B,TCOD-F2B 将验证集(可见)的成功率从 OPD 的 65.72% 提升到了 81.43%(提升 15.71 个百分点),同时将平均动作轮数减少了 2.97 步。这表明,通过课程学习从教师的轨迹中获取指导,不仅能提高任务完成率,还能促使智能体采取更高效的行动路径。
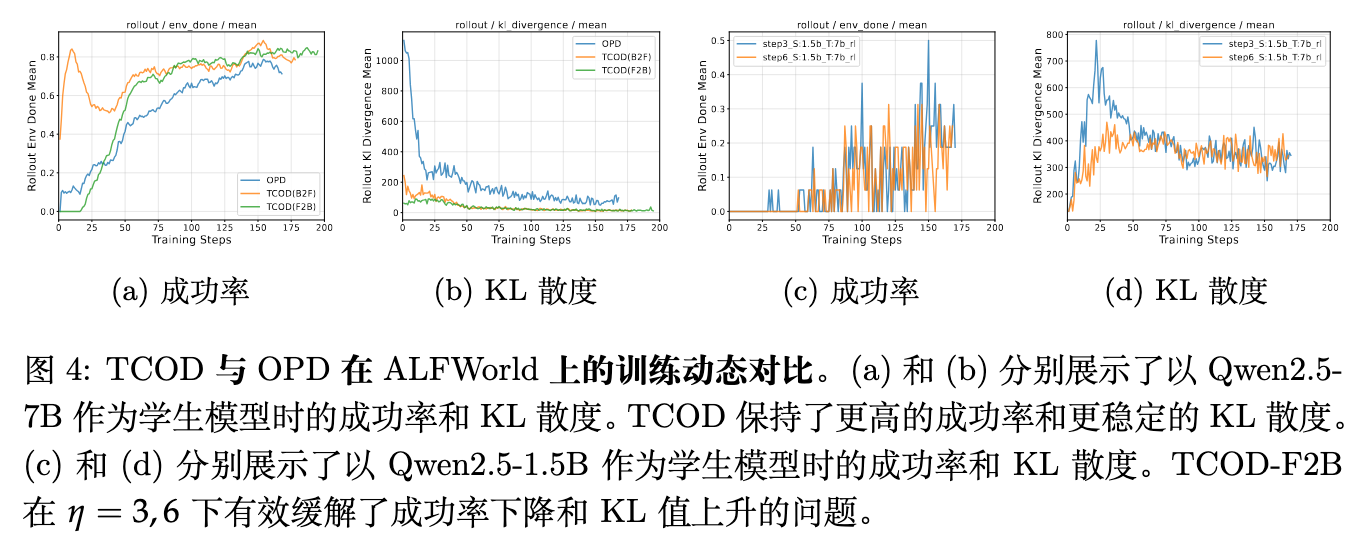
训练动态的稳定性:论文图 4a 和 4b 展示了 Qwen2.5-7B 作为学生模型时的训练动态。与基础 OPD 相比,TCOD 实现了更快的成功率收敛,并在整个训练过程中维持了更加稳定、处于较低水平的 KL 散度。图 4c 和 4d 则展示了在较小的 Qwen2.5-1.5B 模型上,TCOD-F2B(在 时)成功防止了基础 OPD 中出现的成功率崩溃和 KL 激增现象。
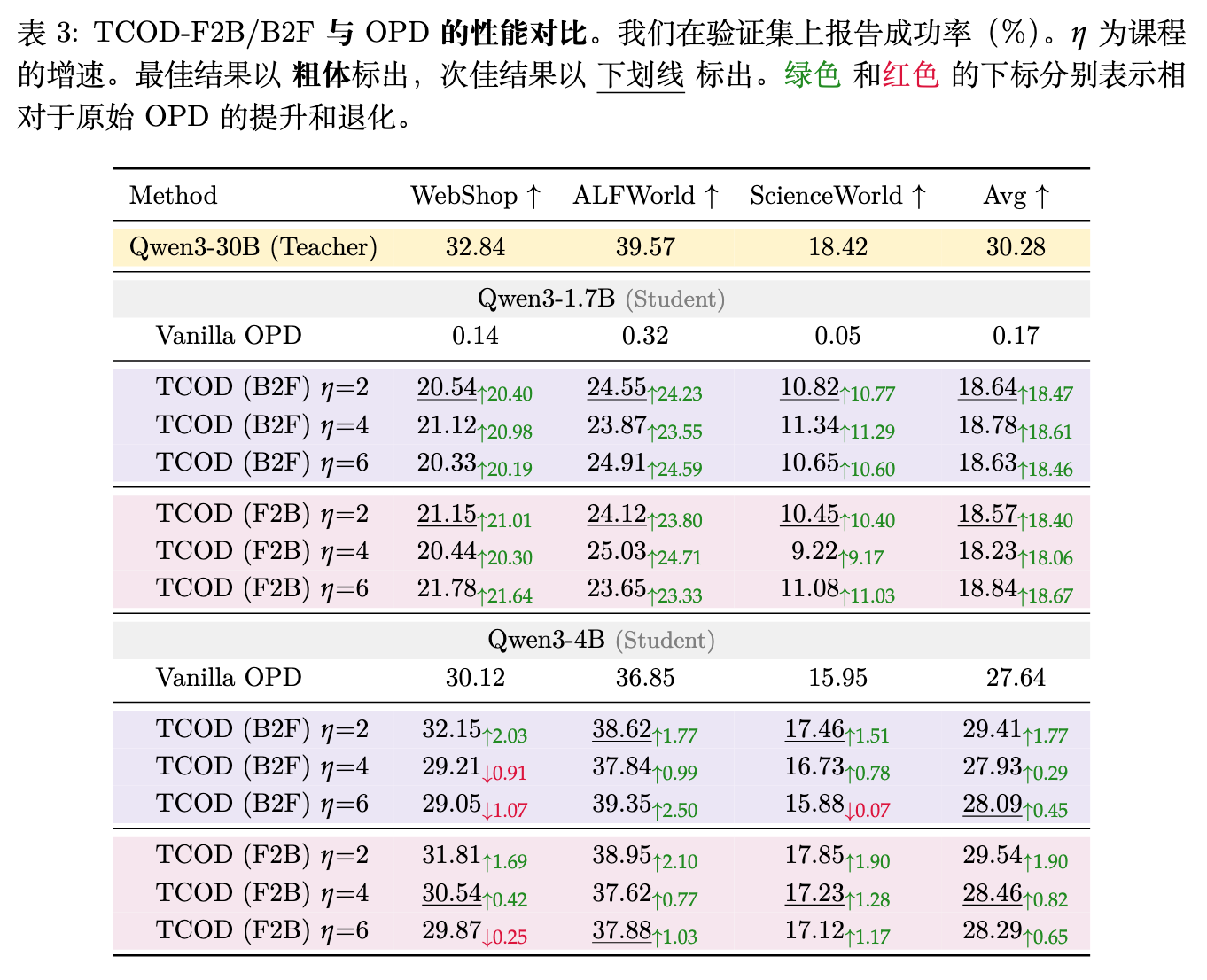
跨基准和不同模型规模的表现:如论文表 3 所示,在使用 Qwen3-1.7B 和 Qwen3-4B 学生模型以及 Qwen3-30B-A3B-Instruct 教师模型的跨基准评估中,TCOD 同样展现出优势。对于极易崩溃的 Qwen3-1.7B 模型,基础 OPD 的平均成功率仅为 0.17%(基本失效),而 TCOD-B2F () 将平均成功率恢复并提升至 18.64%,TCOD-F2B () 提升至 18.84%。这强有力地证明了 TCOD 能够将小模型从多轮交互的灾难性失效中拯救出来。
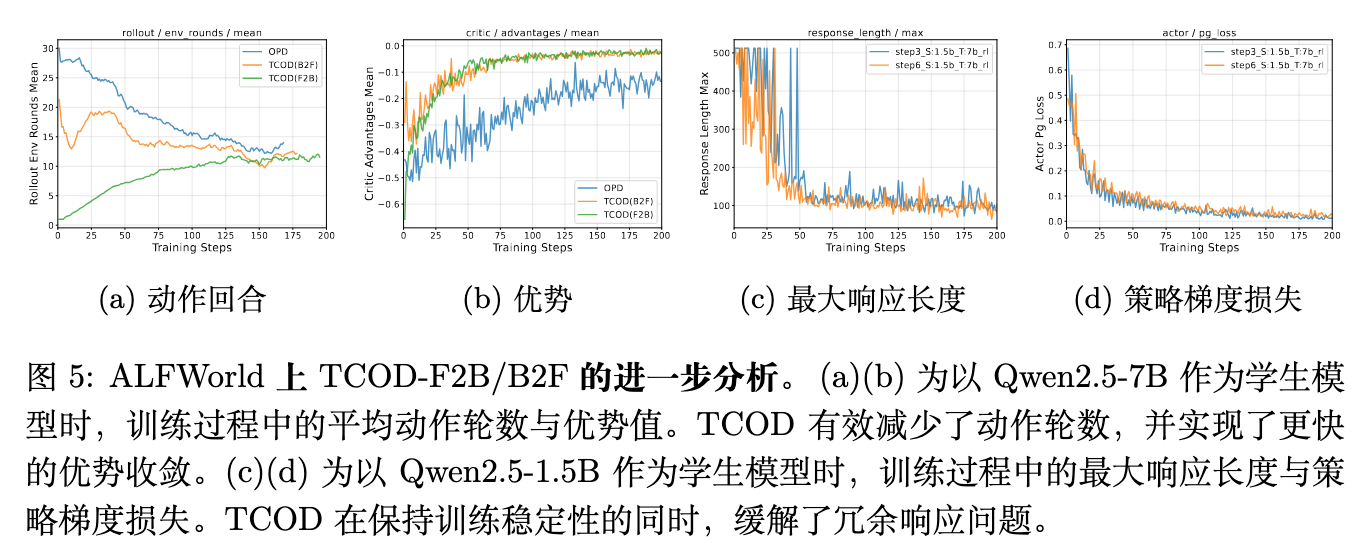
论文图 5c 和 5d 进一步展示了额外的训练指标。对于 Qwen2.5-1.5B 学生模型,基础 OPD 会导致最大响应长度爆炸(表明模型陷入了重复生成或产生冗长无效动作的死循环),而 TCOD 能够从中恢复,并且其策略梯度损失(Policy Gradient Loss)呈现出平滑下降的趋势,证明了训练过程的健康状态。
6.2 Q2:超越教师模型的能力边界
TCOD 带来的不仅仅是性能的逼近和训练的稳定,更令人瞩目的是它赋予了学生模型超越教师的能力。
在论文表 2 中,作者报告了在 ALFWorld 未见环境(Unseen)和困难集(Hard)上的表现。困难集包含了 121 个教师模型自身表现极差的任务。
-
在 Unseen 划分上,TCOD-F2B (Qwen2.5-3B) 达到了 79.19% 的成功率,甚至略高于教师模型的 76.87%。 -
在 Train Hard 划分上,表现更加惊艳。教师模型在该集上的成功率仅为 6.61%。然而,TCOD-B2F (Qwen2.5-7B) 达到了 20.66%,TCOD-F2B 达到了 18.18%。这意味着学生模型在困难任务上的表现超越了教师模型最高达 14 个百分点。
这一结果具有重要意义。它表明,在 TCOD 框架下,学生模型并非仅仅在机械地模仿教师的动作分布。由于同策略蒸馏允许学生模型在自身探索出的轨迹上接收教师的评估(KL散度作为一种软奖励),结合课程学习的稳步推进,学生模型能够发展出比教师自身更为鲁棒的策略,成功泛化到了教师模型的能力边界之外。
6.3 Q3:鲁棒性、敏感性与效率分析
课程增长率 的消融实验:论文表 3 测试了不同课程增长率 对性能的影响。结果显示,在不同基准测试中,TCOD 的表现始终优于基础 OPD,且不同 值导致的成功率波动小于 2%。这种对超参数的不敏感性使得 TCOD 在实际部署中非常容易使用,无需进行昂贵的超参数搜索。不过,正如论文图 4d 所示,较大的 会导致训练期间 KL 散度更加稳定,因为学生模型在课程推进到更长视野之前,有更多的迭代次数来掌握当前的轨迹深度。作者建议在实践中从较小的 开始,如果观察到 KL 散度不稳定,再适当增加 。
领域专有教师与通用大模型教师的对比:对比表 2 和表 3 可以发现,教师模型的质量极大地影响了 TCOD 的上限。在表 2 中,教师是经过 GRPO 针对 ALFWorld 优化的 7B 模型,成功率高达 85.71%,此时 7B 的学生模型在 TCOD 训练下甚至能微弱反超教师。而在表 3 中,教师是通用的 Qwen3-30B,在目标领域表现较弱(39.57%),此时无论是 OPD 还是 TCOD 都未能超越教师。这表明,在多轮蒸馏中,教师模型在目标领域的实际表现比其单纯的参数规模更为关键。
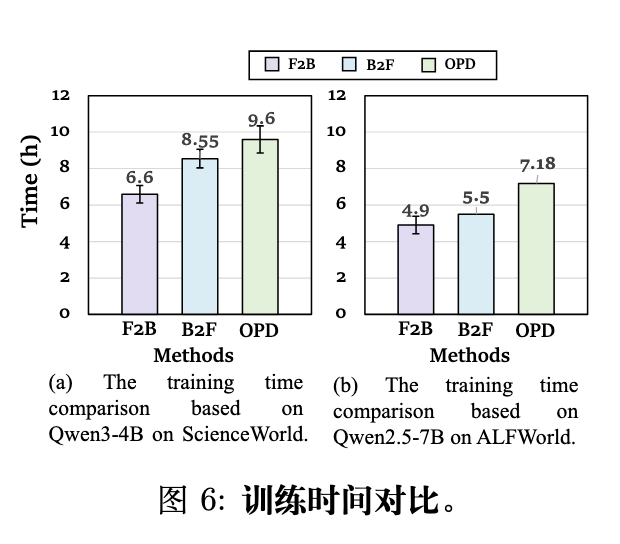
计算效率优势:论文图 6 比较了 TCOD 和基础 OPD 在 ALFWorld 和 ScienceWorld 上的总训练时间成本。在两个基准测试中,TCOD-F2B 和 TCOD-B2F 将总训练时间相较于基础 OPD 减少了近 32%。这种效率提升直接来源于 TCOD 基于步数的课程设计:在训练早期,学生模型执行的步数较少,从而产生了更短的轨迹和更快的数据收集过程。值得注意的是,TCOD-F2B 比 TCOD-B2F 更高效,因为 F2B 严格限制了最大交互步数为 ,而 B2F 虽然从中间状态开始,但学生模型仍可能采取额外的探索性动作,导致轨迹变长。
7. 深入讨论:师生匹配与小模型崩溃(附录补充)
论文附录部分提供了一些非常有价值的额外观察,进一步深化了对多轮蒸馏机制的理解。
小模型 (<3B) 的崩溃现象:在单轮任务中,KL散度通常会下降并稳定。但在多轮环境中,当使用基础 OPD 训练 Qwen3-0.6B/1.7B 或 Qwen2.5-0.5B/1.5B 等小模型时,轨迹级 KL 散度会急剧上升,伴随着成功率降至零。同时,响应长度在各轮次中稳步增长,表明模型陷入了产生越来越偏离分布的冗长输出的恶性循环。这说明在多轮设定下,小模型完全无法在自身的 rollout 分布下保持与教师的对齐。
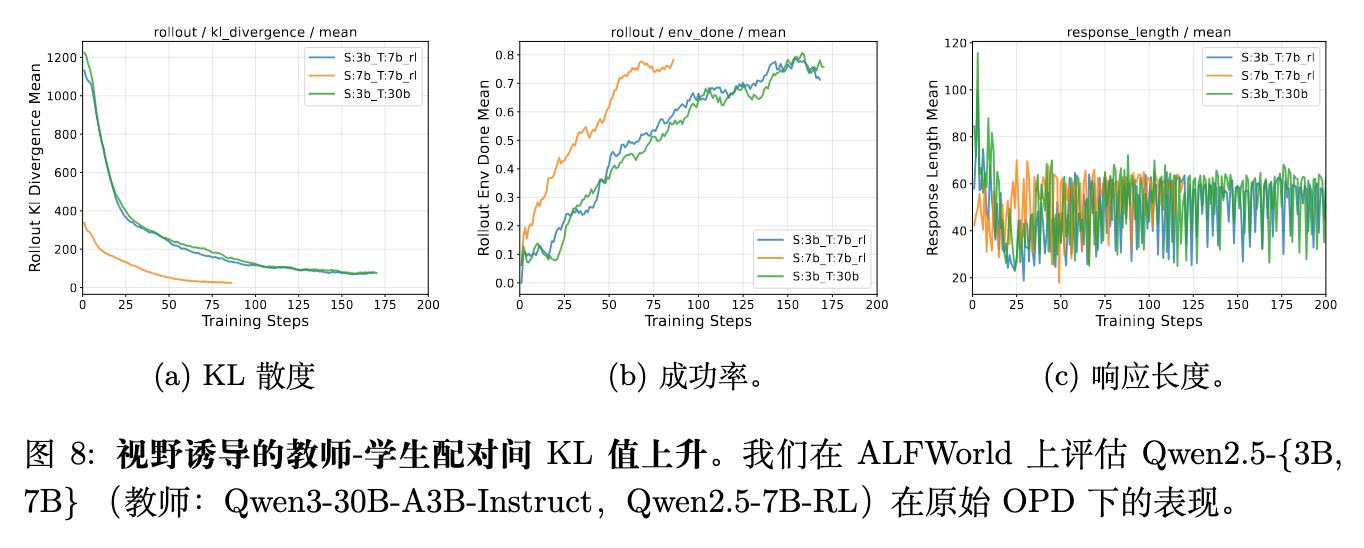
师生能力匹配比绝对的教师强度更重要:论文图 8 考察了不同师生配对的影响。对于一个 3B 的学生模型,无论是在强大的 30B 通用教师还是 7B 强化学习专有教师的指导下,其 KL 散度的下降和成功率的提升速度都非常相似。这表明,超过某个临界点后,单纯增加教师的强度并不会带来额外的收益。相反,当学生模型的容量与教师更为匹配时(例如 7B 学生配 7B 教师),KL 散度收敛得明显更快,成功率上升也更迅速,最终表现超越了 3B 学生在任何教师下的表现。这提示研究者,在多轮蒸馏中,选择容量匹配的师生组合比盲目追求超大参数的教师更为关键,过强的教师甚至可能限制蒸馏效率。
8. 局限性与未来工作
尽管 TCOD 提供了显著的实际收益,但作者也坦诚地讨论了其局限性:
-
对成功轨迹的依赖:TCOD-B2F 变体依赖于预先收集的教师模型成功轨迹,这可能会带来额外的轨迹收集开销。在这种情况下,不需要演示数据的 TCOD-F2B 提供了一个极具竞争力的替代方案。 -
固定的课程进度:虽然实验表明 TCOD 固定的线性课程进度在不同基准和模型规模上都具有鲁棒性,但最佳的推进速度可能会因环境或师生配对的不同而有所差异。未来探索一种自适应机制(例如基于 KL 散度的指数移动平均值自动调整视野长度)可能会进一步提高框架的通用性。 -
环境类型的扩展:目前的评估集中在三个基于文本的多轮基准测试上。将 TCOD 扩展到多模态或物理具身环境,是评估其普适性的重要下一步。
9. 总结
这篇论文敏锐地捕捉到了将同策略蒸馏(OPD)应用于多轮智能体时的一个根本性失效模式——轨迹级 KL 散度不稳定。这种由长视野交互中复合错误引起的不稳定,会导致监督信号失效和模型性能崩溃。
基于这一洞察,作者提出了 TCOD(时序课程同策略蒸馏)框架,通过控制暴露给学生模型的轨迹深度,并设计了前向到后向(F2B)和后向到前向(B2F)两种实用的变体。大量实验不仅证明了 TCOD 能够持续稳定训练过程、挽救小模型免于崩溃、提升大模型成功率,还展示了其在减少训练时间的同时,赋予学生模型超越教师能力边界的潜力。TCOD 为长视野自主智能体的课程引导训练开辟了新的方向,为构建更高效、更强大的多轮 LLM 智能体提供了坚实的实证基础和切实可行的算法方案。
更多细节请阅读原文。

