让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
-
论文链接:https://arxiv.org/pdf/2604.13016
TL;DR
今天解读一篇来自清华的一篇论文《Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe》。该论文系统性地研究了大型语言模型(LLM)在策略蒸馏(On-Policy Distillation, OPD)过程中的训练动态、内在机制以及工程实践方案。
研究表明,较强的教师模型并不必定带来较好的蒸馏效果,OPD 的成败取决于两个核心条件:一是学生与教师之间需具备一致的思维模式(Thinking-pattern consistency);二是教师必须具备学生在训练中未曾见过的新知识。在 token 级别的机制上,成功的 OPD 表现为学生和教师在学生访问状态下的高概率 token 上发生渐进对齐,且这部分重叠 token 集中了 97% 至 99% 的概率质量。
基于上述发现,论文提出了两种恢复失败 OPD 任务的策略:离策略冷启动(Off-policy cold start)与教师对齐的提示词选择(Teacher-aligned prompt selection)。最后,论文探讨了 OPD 稠密奖励在长序列轨迹中的质量退化问题,指出了全局奖励信号与局部优化几何特征之间的张力。
1. 背景
在大型语言模型的后训练(Post-training)阶段,知识蒸馏与强化学习(RL)是提升模型能力的常规手段。传统的离策略蒸馏(Off-Policy Distillation)采用固定的教师生成序列来训练学生模型。这类方法虽然实现简单,但面临暴露偏差(Exposure Bias)问题。因为学生模型在训练时依赖于教师生成的理想轨迹,而在推理时只能依据自身的输出进行自回归生成。这种训练与推理阶段的数据分布不匹配,会导致错误在长文本生成中不断累积。
为了解决这一问题,在策略蒸馏(On-Policy Distillation, OPD)逐渐成为一种核心技术。在 OPD 的框架下,学生模型根据自身的当前策略生成轨迹(Rollouts),教师模型则在学生实际访问的这些状态上提供 token 级别的对数概率(Log-probabilities)作为稠密的奖励信号。通过这种方式,学生模型能够直接获得关于其自身行为边界的反馈,从而进行行为纠正。近期的工业界模型如 Qwen3、MiMo 以及 GLM-5 都在其后训练流程中采用了 OPD,并取得了可观的性能提升。同时,OPD 也被扩展到自蒸馏(Self-distillation)设定中,通过向同一个模型提供特权信息(Privileged information)使其充当自身的教师,推动模型的持续自我改进。
尽管取得了广泛应用,OPD 在实践中的训练动态依然缺乏系统的解释。一个具体的反直觉现象是:一个性能更强的教师模型有时会完全无法提升学生模型的表现,而一个性能较弱但初始对齐度更高的教师却能取得成功。以往的研究大多侧重于证明 OPD 的有效性或提出新的算法变体,少有文献深入剖析教师的 token 级别信号是如何引导学生分布向预期方向演化的,以及在何种具体条件下这一机制会发生失效。
作者团队通过设计控制变量实验,从现象学(Phenomenology)、机制(Mechanism)和实践配方(Recipe)三个维度对 OPD 进行了深度剖析,并在讨论环节对长视野推理(Long-horizon reasoning)场景下 OPD 的局限性给出了定量分析。
2. 预备知识与数学定义
在深入探讨现象与机制之前,有必要先明确 OPD 的数学形式化定义。论文考察了三种常见的 OPD 变体,它们在监督粒度上存在差异。
2.1 符号说明
设 为输入的提示词(Prompt), 为生成的响应(Response)。用 表示截至第 步的前缀。定义学生模型为 ,教师模型为 ,它们在词表 上定义了下一个 token 的概率分布 。
记 为学生模型自回归生成的响应,其中 为生成的总长度。给定提示词集合 ,在每一步 ,基于学生生成的前缀 ,学生和教师分别输出下一个 token 的分布,定义为:
其中 。
知识蒸馏的核心是最小化这两个分布之间的散度。通常选择 Kullback-Leibler (KL) 散度,对于词表 上的两个分布 和 ,KL 散度定义为:
2.2 在策略蒸馏的目标函数
在策略蒸馏(OPD)计算的是在学生当前策略采样的轨迹上的监督信号。标准的形式化是在学生生成的轨迹上最小化序列级别的反向 KL 散度(Reverse KL Divergence):
利用自回归分解,上述序列级别的目标函数可以精确分解为 token 级别的 KL 散度之和:
反向 KL 散度()具有“寻求模式”(Mode-seeking)的特性,即它倾向于让学生模型 的概率质量集中在教师模型 认为概率较高的区域。如果 的某个区域概率接近于 0,反向 KL 会对 在该区域的概率分配施加巨大惩罚。这与前向 KL 散度(Forward KL, 即标准的离策略蒸馏交叉熵目标)的“覆盖模式”(Mean-seeking/Mode-covering)特性不同。
在工程实践中,由于计算完整词表的 KL 散度代价较高,研究者们提出了多种不同的实现变体。论文总结了三种常见的监督粒度:
1. 采样 Token OPD (Sampled-Token OPD)
这是最轻量级的变体。它仅评估学生模型在第 步实际采样出的那个 token 的散度。单步损失定义为 ,总体目标为:
由于 ,因此 是 token 级别反向 KL 散度的无偏单样本估计量。这种方法内存占用小,是许多开源框架的首选。
2. 全词表 OPD (Full-Vocabulary OPD)
处于另一个极端,这种方法在每个前缀下计算整个词表的散度:
全词表 OPD 提供了最密集的梯度信号,但付出了 的内存代价,其中 是批次大小, 是序列长度, 是词表大小。
3. Top-k OPD
作为折中方案,Top-k OPD 将散度计算限制在词表的子集 上。本文主要关注学生 Top-k 变体,即选择在学生分布下概率最高的 个 token,定义为 。在 上重新归一化学生和教师的分布:
然后通过最小化子集 KL 散度来进行蒸馏,得到轨迹级别的目标函数:
此方法丢弃了 之外的概率质量,因此是全词表反向 KL 的近似,但它保留了对学生高概率区域的多 token 监督,同时显著降低了对教师模型的查询成本。
2.3 核心动态指标定义
为了量化训练过程中的动态变化,论文定义了以下几个在整个训练过程中持续监控的指标。记学生和教师在第 步的 top- 集合分别为 和 。
重叠率 (Overlap Ratio)
该指标量化了学生与教师候选空间之间的对齐程度,定义为同时出现在学生和教师 top- 集合中的 token 比例的期望值:
较低的重叠率表明学生的概率质量集中在与教师不相交的 token 集合上,暗示策略存在散度或“模式错配”。重叠率趋近于 1.0 表明学生成功锁定了教师的支持区域。
重叠 token 优势 (Overlap-Token Advantage)
为了衡量重叠 token 内部的分布一致性,定义 ,其中 是在 上的重新归一化分布。该指标是此量的平均值:
该值接近零表示高质量对齐,即学生以适当的置信度将概率质量置于教师偏好的 token 上。较大的负值表示在交集内,学生相较于教师表现得过度自信( 高但 低)。
熵与熵差 (Entropy and Entropy Gap)
跟踪学生分布的熵 和教师在学生生成轨迹上的分布熵 ,定义熵差为:
是模式对齐的特定状态指标。较大的差距表明学生和教师在相同访问状态下的置信度和多样性存在明显错配,而向零收敛表明学生在生成的轨迹上匹配了教师的不确定性轮廓。
3. 决定 OPD 成败的两大核心条件
在探究 token 级别机制之前,论文提出了一个宏观问题:究竟是什么条件决定了 OPD 的有效性?人们通常自然而然地假设,更强的教师模型总是能带来更好的蒸馏结果。然而,作者在受控实验中观察到了与此相悖的配置。通过对比实验,论文识别出决定 OPD 结果的两个相互作用的条件。
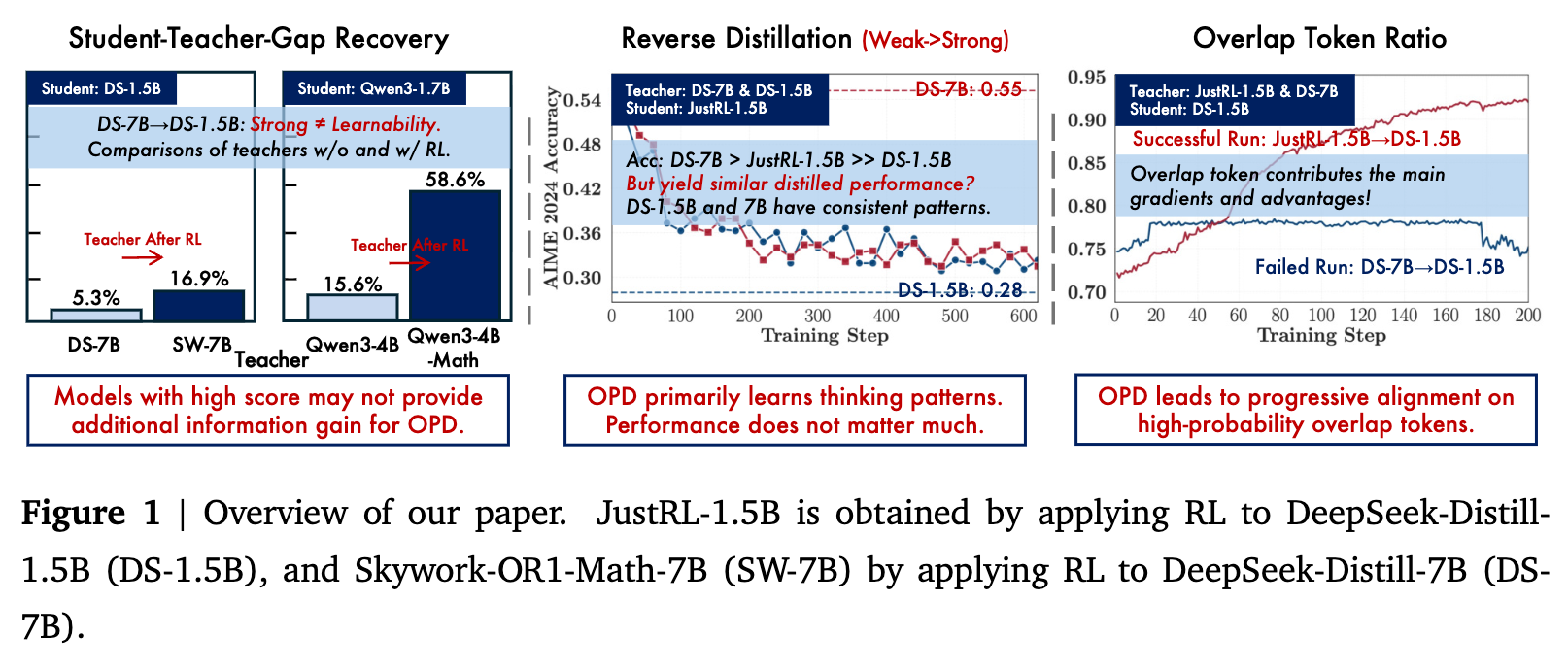
3.1 条件一:思维模式一致性 (Thinking-Pattern Consistency)
论文首先研究了 OPD 是否需要学生和教师之间具备兼容的思维模式。实验发现,更强的教师并不保证更好的蒸馏效果:推理模式上的较大错配会削弱蒸馏信号,无论教师在基准测试中的优势有多大。
实验设置
研究选取 Qwen3-1.7B-Base 作为学生模型,并比较两位教师:
-
Qwen3-4B (Non-thinking):未经过复杂推理增强的模型。 -
Qwen3-4B-Base-GRPO:使用 GRPO 算法在 Qwen3-4B-Base 上通过零强化学习(Zero-RL)获得的模型。
由于学生模型本身是 Base 模型,其初始的思维模式预期会更接近经过 GRPO 训练的 Base 模型衍生出的教师。实验使用 DAPO-Math-17K 数据集进行两次 OPD 运行,除教师模型外,所有设置保持完全一致。评估指标为 AIME 2024、AIME 2025 和 AMC 2023 的 avg@16 准确率。
实验结果与分析
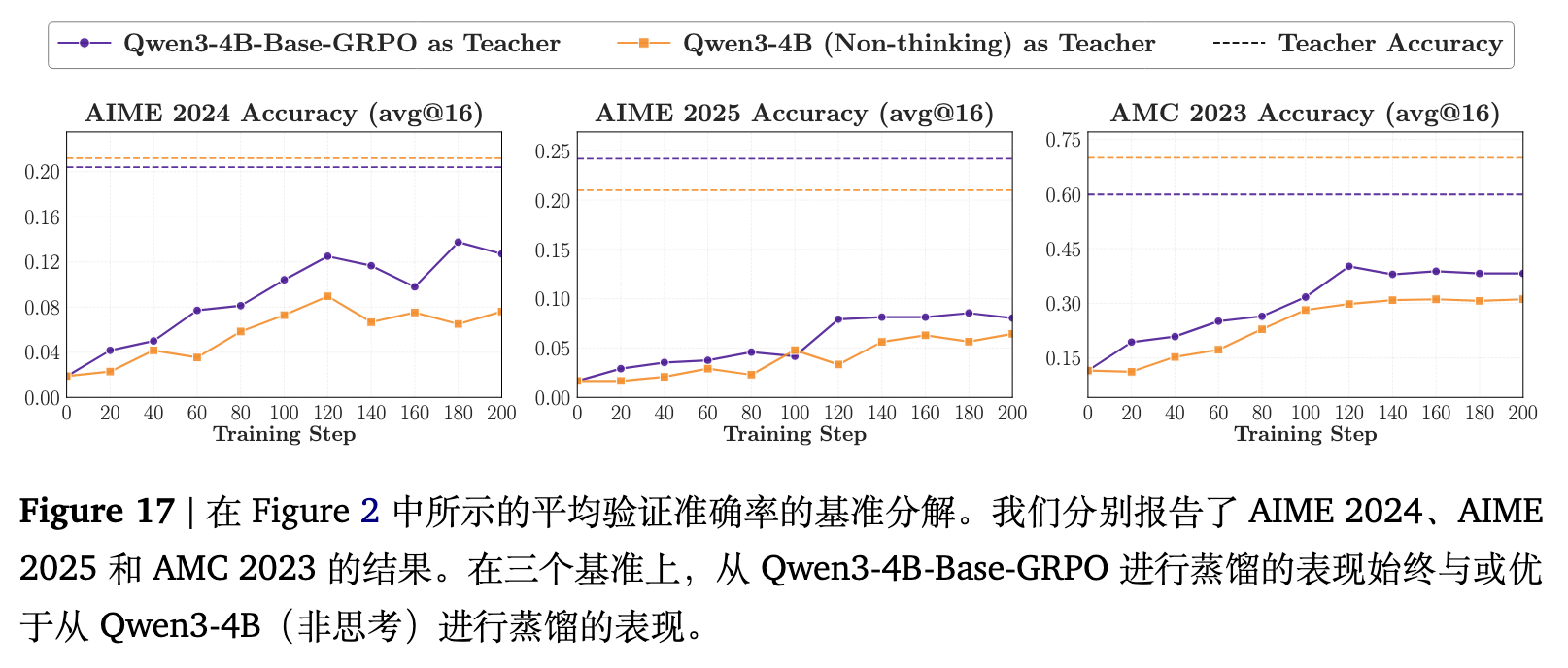
如图 2 和 图 3 所示,两位教师在独立评测时表现出大致相当的性能,但使用 Qwen3-4B-Base-GRPO 作为教师时的蒸馏结果稳定且明显优于 Qwen3-4B (Non-thinking)。
尽管 GRPO 教师在某些基准测试上的绝对分数相对有限,但其在训练初期的“重叠率”较高,这表明其思维模式与学生更加契合。尽管在训练的中后期,两组实验的重叠率曲线发生收敛,但性能差距依然存在。这一现象说明,训练早期的思维模式错配会导致蒸馏收益受损,且这种损失在后续阶段无法被完全弥补。这一结论在多个基准测试的分解结果中均保持一致。
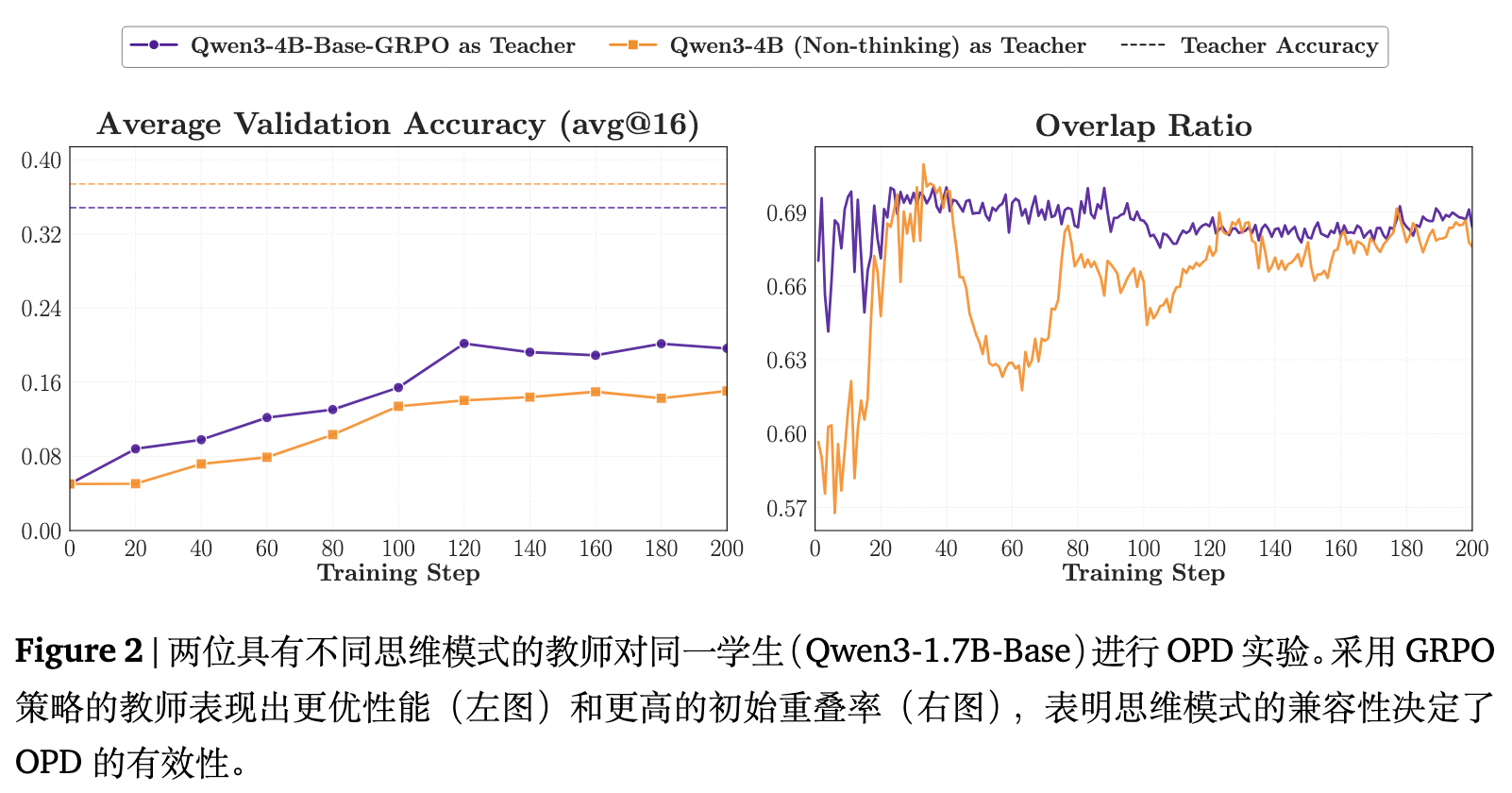
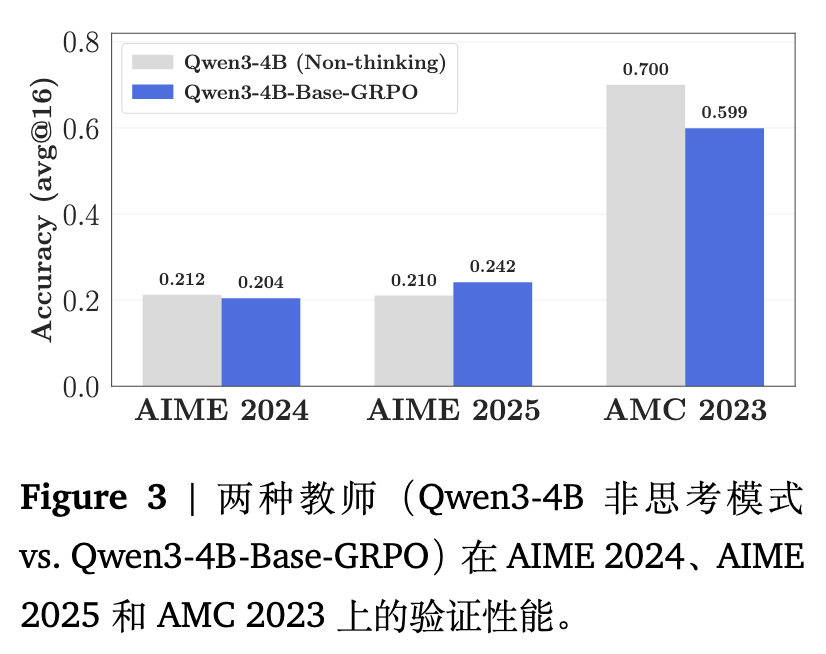
3.2 条件二:较高分数 新知识 (Higher scores new knowledge)
仅凭思维模式一致性无法解释所有观察结果。即使教师模型得分更高且与学生模型具有一致的思维模式,OPD 仍然可能失效。
实验设置
为了控制变量,论文在两个不同的模型家族中构建了对比。
-
DeepSeek 家族:使用 DeepSeek-R1-Distill-Qwen-1.5B (R1-Distill-1.5B) 作为学生。对比两位教师:DeepSeek-R1-Distill-Qwen-7B (R1-Distill-7B) 和 Skywork-OR1-Math-7B。后者是通过对 R1-Distill-7B 进一步施加 RL 后训练得到的。 -
Qwen 家族:使用 Qwen3-1.7B (Non-thinking) 作为学生。对比两位教师:Qwen3-4B (Non-thinking) 和 Qwen3-4B-Non-Thinking-RL-Math,后者是对前者在 DeepMath 数据集的一个 57K 子集上应用 RL 得到的。
在两组实验中,核心差异在于:一位教师与学生来自完全相同的训练流水线(仅规模不同),而另一位教师则通过额外的 RL 训练获得了新能力。所有运行均使用相同的 DAPO-Math-17K 数据集和默认训练配方。
实验结果与分析
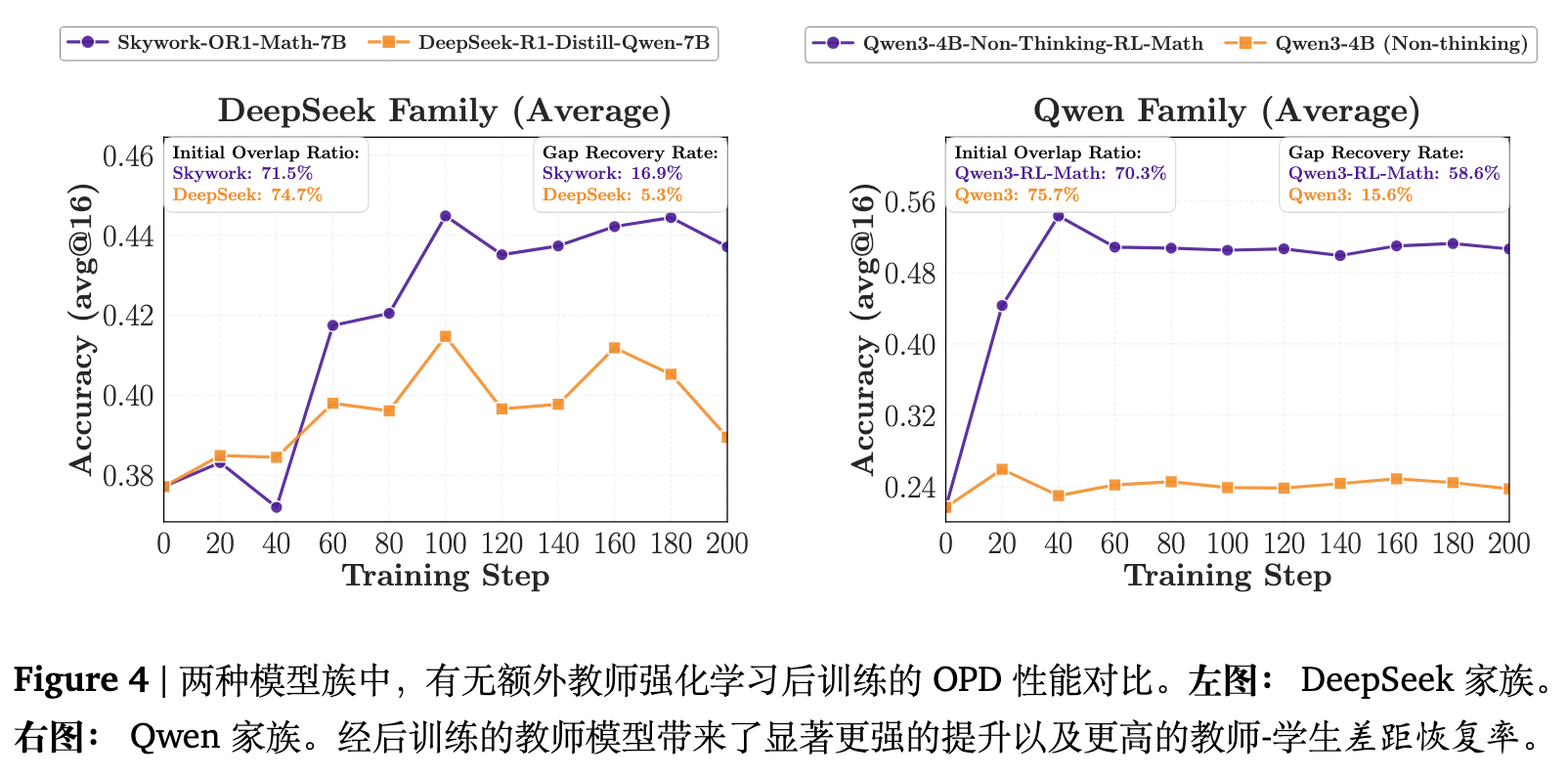
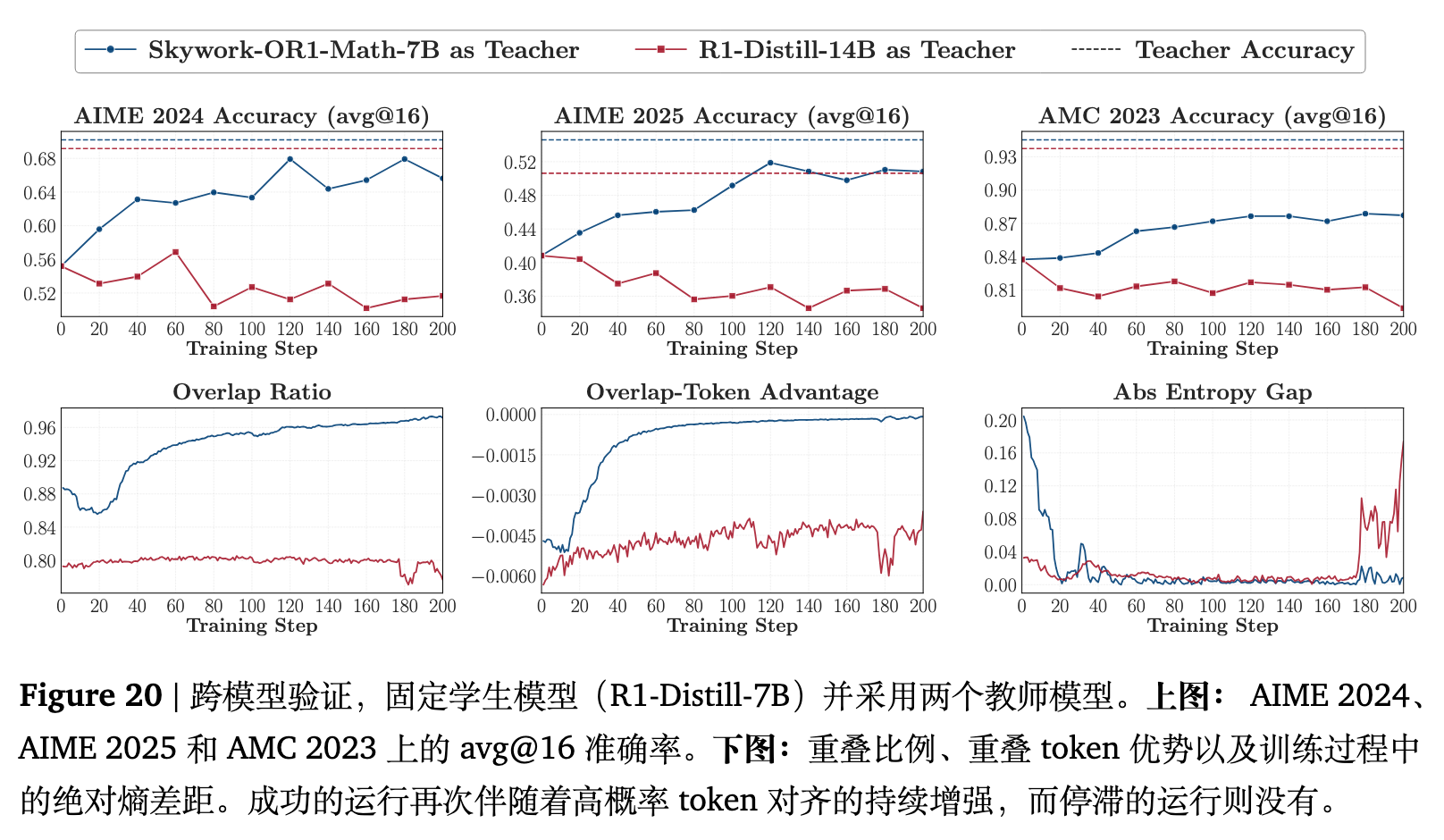
如图 4 所示,两个家族展示了高度一致的模式。“同流水线教师”(Same-pipeline teachers)带来的性能提升十分有限;而“经过后训练的教师”(Post-trained teachers)在所有基准测试中均产生了更明显的收益。
更关键的是,后训练教师不仅实现了更高的绝对性能,还恢复了更大比例的师生差距,这通过差距恢复率(Gap Recovery Rate)来衡量。这表明这些教师通过 RL 获得的附加能力更具可迁移性。由于后训练教师派生自相同的基础检查点,它们的思维模式大致保持一致(这也可以从重叠率动态中观察到)。因此,真正的提升源于教师通过 RL 获得的、学生之前未见过的新知识。
3.3 反向蒸馏的验证 (Validation via Reverse Distillation)
为了同时验证上述两个条件并揭示 OPD 的本质,论文设计了一组反向蒸馏(Reverse-distillation)实验。
实验设置
JustRL-DeepSeek-1.5B (JustRL-1.5B) 是对 R1-Distill-1.5B 进行 RL 训练得到的。现在调转方向,将 JustRL-1.5B 作为学生,尝试向其 RL 前的检查点 R1-Distill-1.5B 进行蒸馏。作为对比对照组,实验还使用了 R1-Distill-7B 作为教师。需要注意的是,R1-Distill-7B 在基准测试中的得分略高于 JustRL-1.5B,而 R1-Distill-1.5B 则弱于学生。
实验结果与理论推导
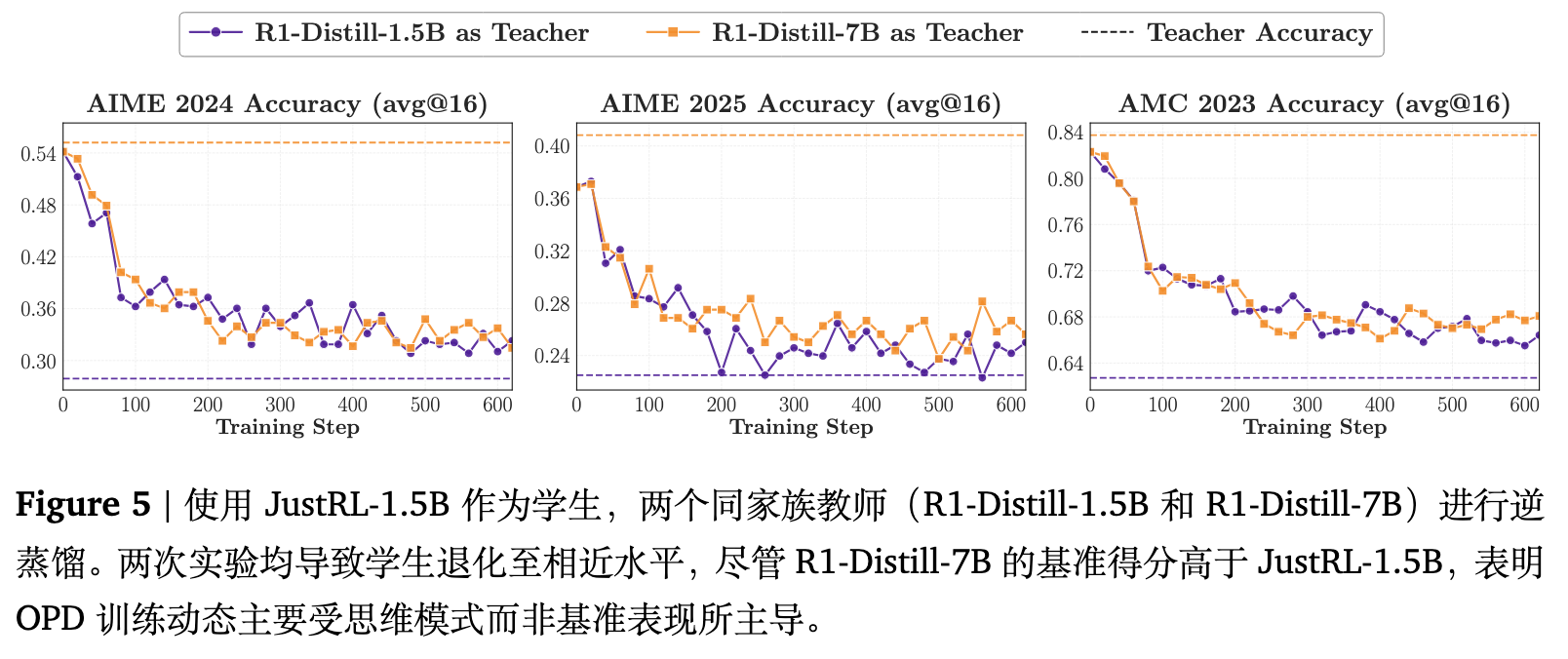
图 5 揭示了两个值得注意的现象。
首先,将 JustRL-1.5B 蒸馏回其自身的预 RL 检查点(R1-Distill-1.5B),会导致学生几乎完全倒退到其 RL 前的性能水平,抹去了通过 RL 获得的所有收益。
其次,当把教师替换为同一家族中规模更大、性能甚至略强的 R1-Distill-7B 时,训练轨迹几乎无法区分。尽管 R1-Distill-7B 在基准测试中优于 JustRL-1.5B,但它驱使学生倒退到了与较弱的 1.5B 教师相同的基础水平。
这一反直觉结果得出了以下结论:
-
思维模式至关重要,OPD 本质上是在学习思维模式。学生模型会主动获取教师的思维模式并覆盖自身的模式。这就是为什么思维模式的一致性如此重要:如果差距过大,学生可能无法进行有效学习。 -
基准测试性能无法预测 OPD 的结果。尽管 R1-Distill-7B 的评分更高,但蒸馏过程并没有带来改善,反而导致了衰退。这证明 OPD 的训练动态可以完全独立于教师的基准测试得分。 -
更高的分数并不意味着包含适用于 OPD 的新知识。R1-Distill-7B 和 1.5B 属于同一家族,区别仅在于参数规模。它们对学生的不可区分的影响印证了:规模更大带来的分数提升可能仅仅反映了对同一数据集的不同拟合程度,而不是真正新颖的能力。教师必须具备学生尚未掌握的新知识,且不脱离基础模式,才能产生收益。
4. 高概率 token 的渐进对齐
现象学分析明确了决定 OPD 有效性的宏观条件。本节将深入探究这些条件在训练过程中是如何转化为具体的 token 级别机制的。通过对比成功与失败的 OPD 运行,论文揭示了有效的蒸馏由高概率 token 上的渐进对齐驱动。
4.1 高概率 Token 的渐进对齐现象
研究者比较了在相同设定下,单一学生从两位不同教师处进行蒸馏的动态,其中一组产生明显的改善,另一组则毫无建树。
实验设置
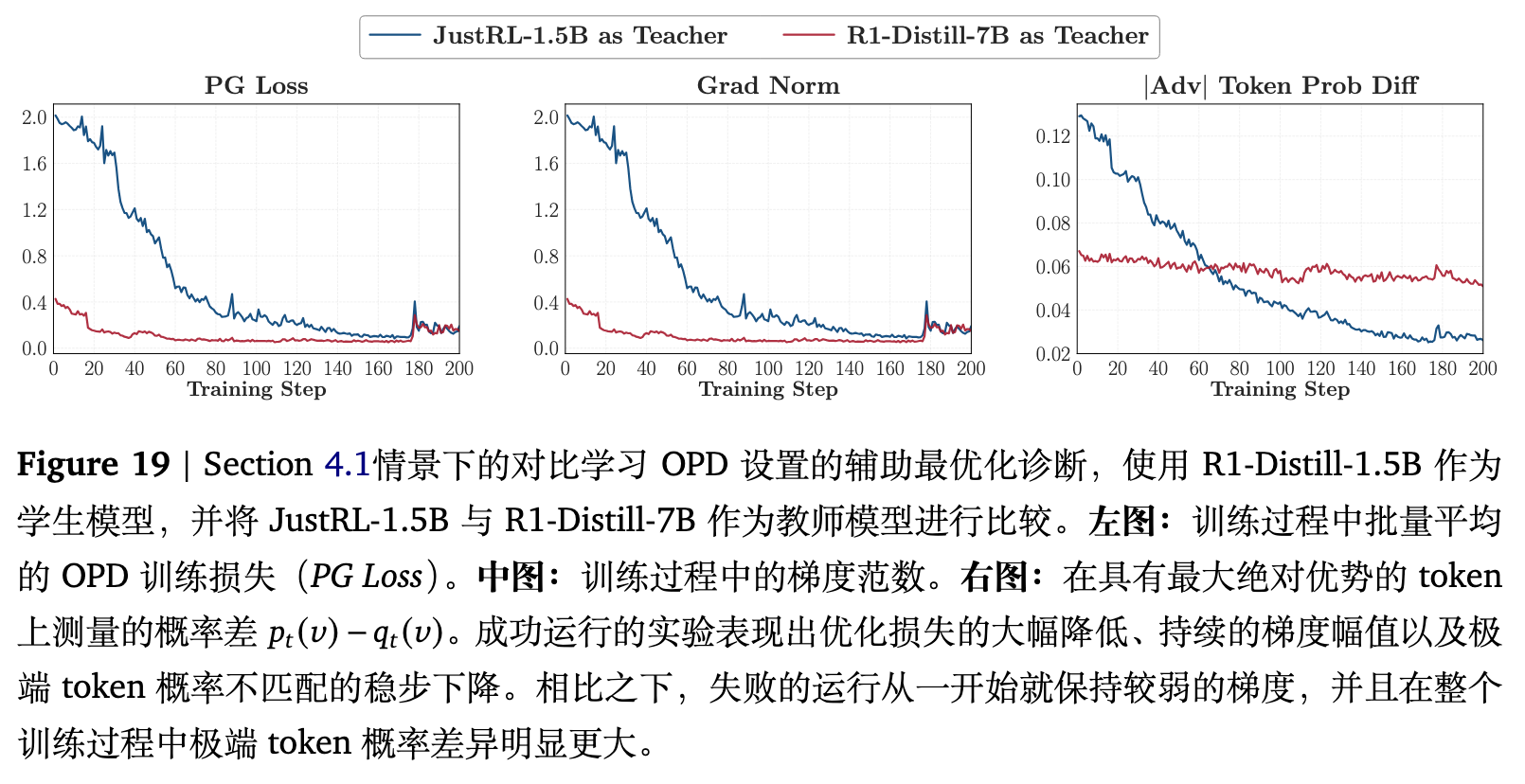
选择 R1-Distill-1.5B 作为学生模型,并比较两位教师:JustRL-1.5B 和 R1-Distill-7B。这两位教师在数学任务表现上具有可比性,后者略强。使用相同的 DAPO-Math-17K 数据集,在 OPD 训练期间监控前述的三个动态指标。
实验结果与分析
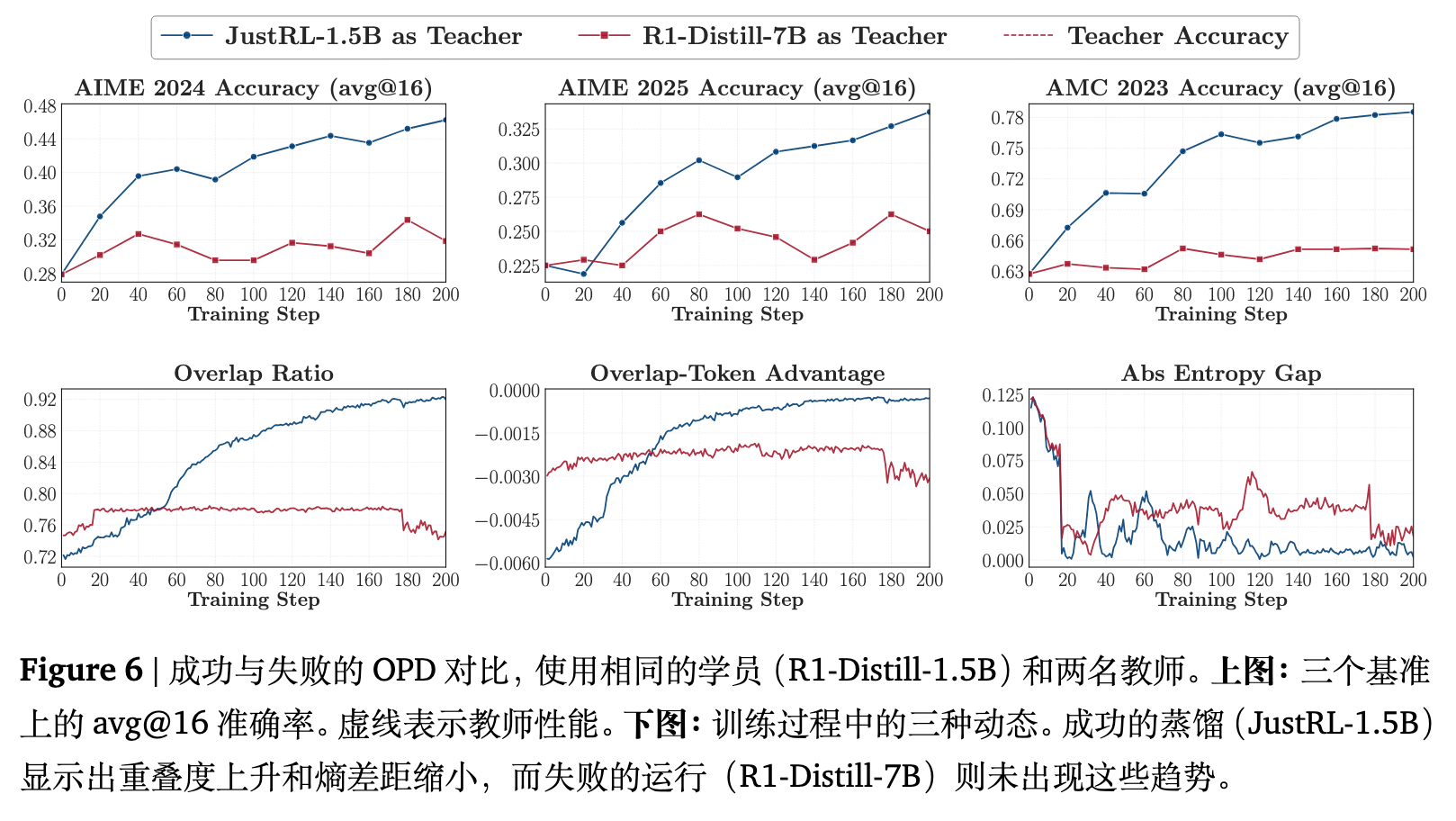
图 6 展示了截然不同的结果。向 JustRL-1.5B 蒸馏产生了持续的收益,最终学生恢复了超过 80% 的与教师的性能差距;而向 R1-Distill-7B 蒸馏不仅未能产生改进,反而出现了倒退。
底层机制在训练动态指标中显露无遗。在成功的运行中,重叠率稳步上升,重叠 token 优势逐渐向零改善,且熵差不断缩小。这说明学生渐进式地定位到了教师的高概率区域,并在该区域内校准了概率质量分布,最终在局部置信度上与教师达成匹配。而在失败的运行中,这三个指标从一开始就呈现停滞状态。
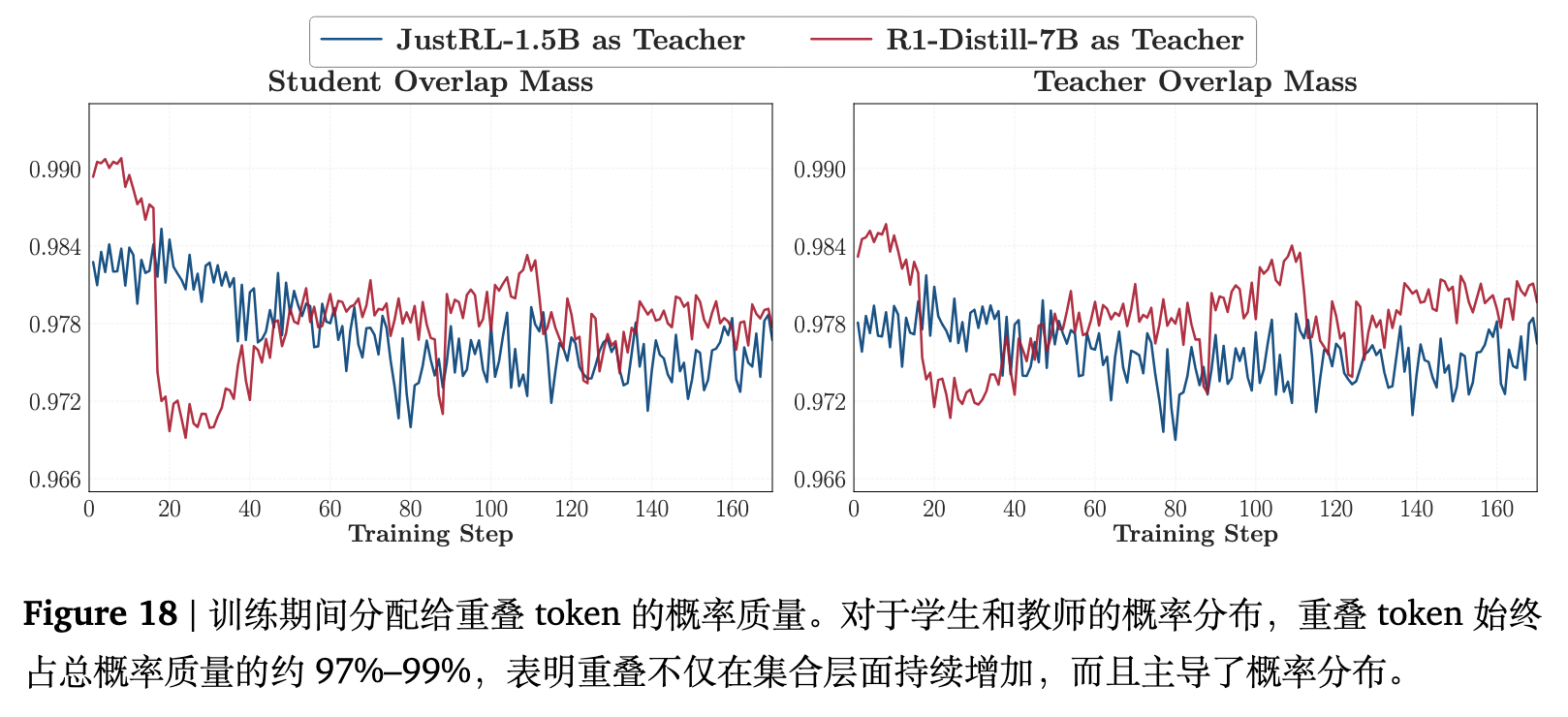
深入分析(附录 B.1 中的额外质量计算,见图 18)表明,无论是学生模型还是教师模型,其在训练的各个阶段,top-k 重叠集合都占据了其概率分布总质量的 97% 至 99%。因此,重叠率的上升反映了概率主导 token 上的分布对齐,而非纯粹数学集合层面的重合。重叠 token 优势的改善进一步表明,OPD 的主要优化信号存在于对重叠区域内部概率权重的重新分配。
对于辅助优化指标的分析(附录 B.2)也佐证了这一点。在成功的设定下,训练损失下降,梯度范数保持稳定;而在失败的设定下,梯度幅度微弱且分布差异持续存在。这意味着如果一开始未能进入教师的高概率模式区域,学生模型接收到的更新信号将由于方向不一致等原因发生抵消,导致有效梯度过小。
4.2 仅优化共享 Token 足以达到全量效果
上述分析表明,高概率 token 的对齐与 OPD 的成功密切相关。为了确认这一相关性是否具备因果性,即重叠区域是否就是驱动模型优化的唯一核心来源,论文设计了一项具体的消融实验。该实验将 top-k 支持集分解为重叠部分和非重叠部分,并在训练时进行隔离。
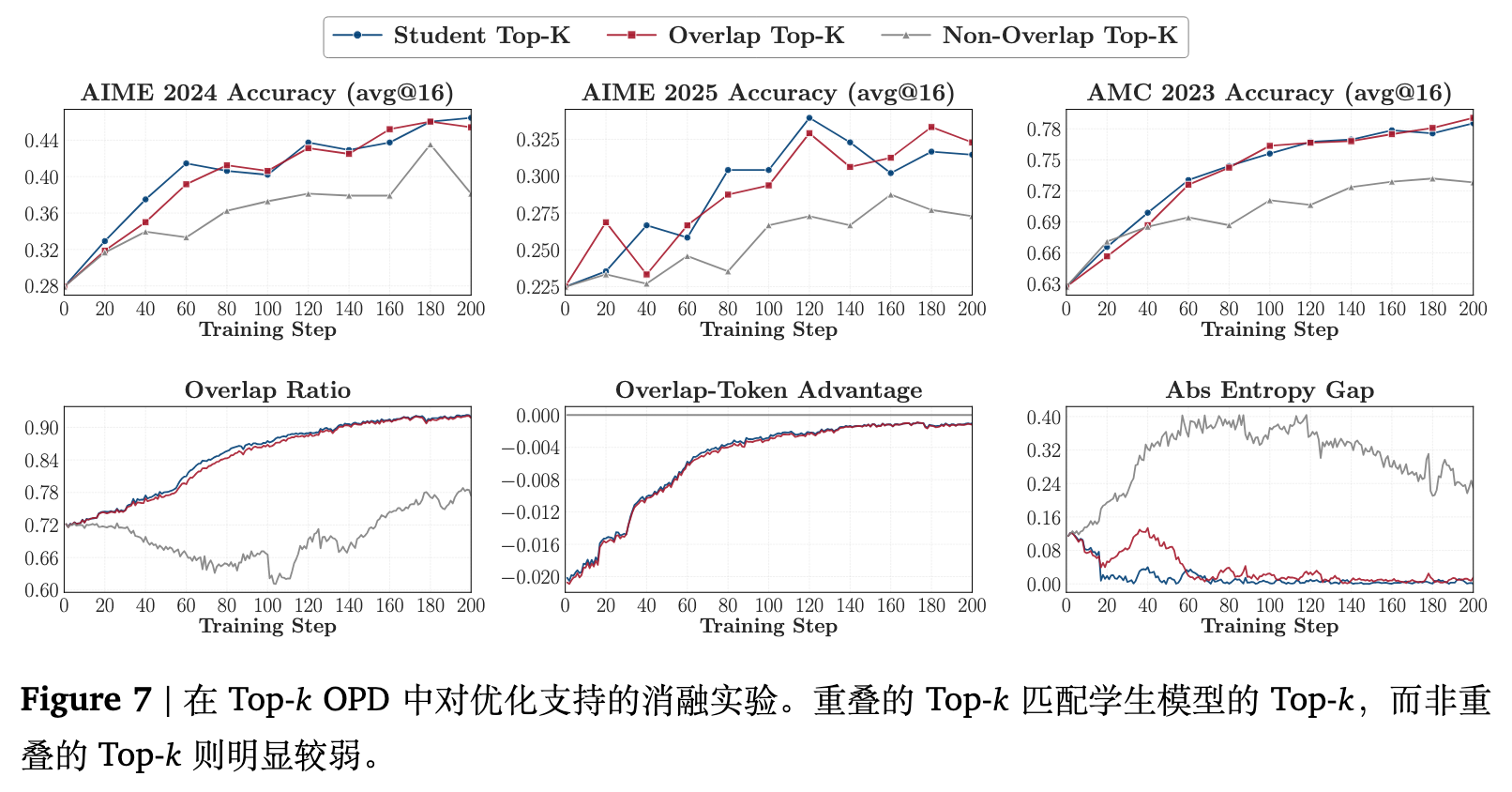
实验设置
利用 4.1 节中成功的配置(JustRL-1.5B R1-Distill-1.5B),比较三种变体,它们在计算蒸馏损失所涵盖的 token 范围上有所不同:
-
Student Top-k:在学生 top- 的全集 上进行优化。 -
Overlap Top-k:将优化范围限制在学生和教师 top- 集合的交集 上。 -
Non-Overlap Top-k:将优化范围限制在对称差集 上。
设定 。
实验结果与分析
图 7 显示,仅在交集重叠区域进行优化,足以恢复所有基准测试中标准 Student Top- OPD 的几乎全部收益,而 Non-Overlap Top- 的性能则始终较弱。这证明,OPD 的核心增益来源于共享的高概率区域上的梯度,而不是非重叠 token。
这也解释了为什么 Student Top- 和 Overlap Top- 行为如此相似。在学生支持集中额外多出的那些非重叠 token 承载的概率质量微乎其微。Student Top- 和 Overlap Top- 的重叠 token 优势曲线几乎无法区分,而 Non-Overlap Top- 的幅度则小得多,表明非重叠 token 上的有效梯度较弱。
重叠优化的自我强化(Self-reinforcing)机制
Student Top- 和 Overlap Top- 均使重叠率稳步上升(从约 72% 升至 91% 以上),而 Non-Overlap Top- 则是先下降随后部分恢复。这揭示了一种“自我强化”的动态过程:一旦某个 token 进入了共享的高概率区域并受到教师的青睐,反向 KL 散度引起的更新规则便会向其集中更多的概率质量,这反过来又将竞争性的非重叠 token 排挤出学生的 top- 集合。因此,重叠区域的扩大不仅是优化的结果,也是优化能够持续进行的动力源。
总之,这些结果共同勾勒出一个统一的机制视图:OPD 的主要作用,是在学生访问到的状态下,逐步提纯并校准学生在教师支持的高概率 token 上的分布。非重叠区域的贡献微乎其微。当满足现象学章节中指出的两大宏观条件时,这一自我强化机制便能顺畅运转,驱动模型持续进步;当条件未满足时,重叠停滞,训练失去焦点。
5. 挽救失败 OPD 的两种策略
基于前文确立的机制和现象,本节提出了两种可以在原本注定失败的配置下恢复 OPD 有效性的实践策略。既然教师模型本身的新知识是一种固有属性无法轻易改变,那么缩小师生之间初始的思维模式差距便成为破局的关键。
5.1 从教师生成的轨迹进行离策略冷启动 (Off-Policy Cold Start)
当学生和教师具备明显差异的思维模式时,直接运行纯粹的 OPD 往往是无效的,因为学生初始的生成策略很难触及到教师提供有价值信号的区域。为了缓解这一错配,论文考虑了一种两阶段框架:先对学生进行基于教师展开轨迹的监督微调(SFT)冷启动,使其向教师的思维模式靠拢,随后再继续进行标准的 OPD。
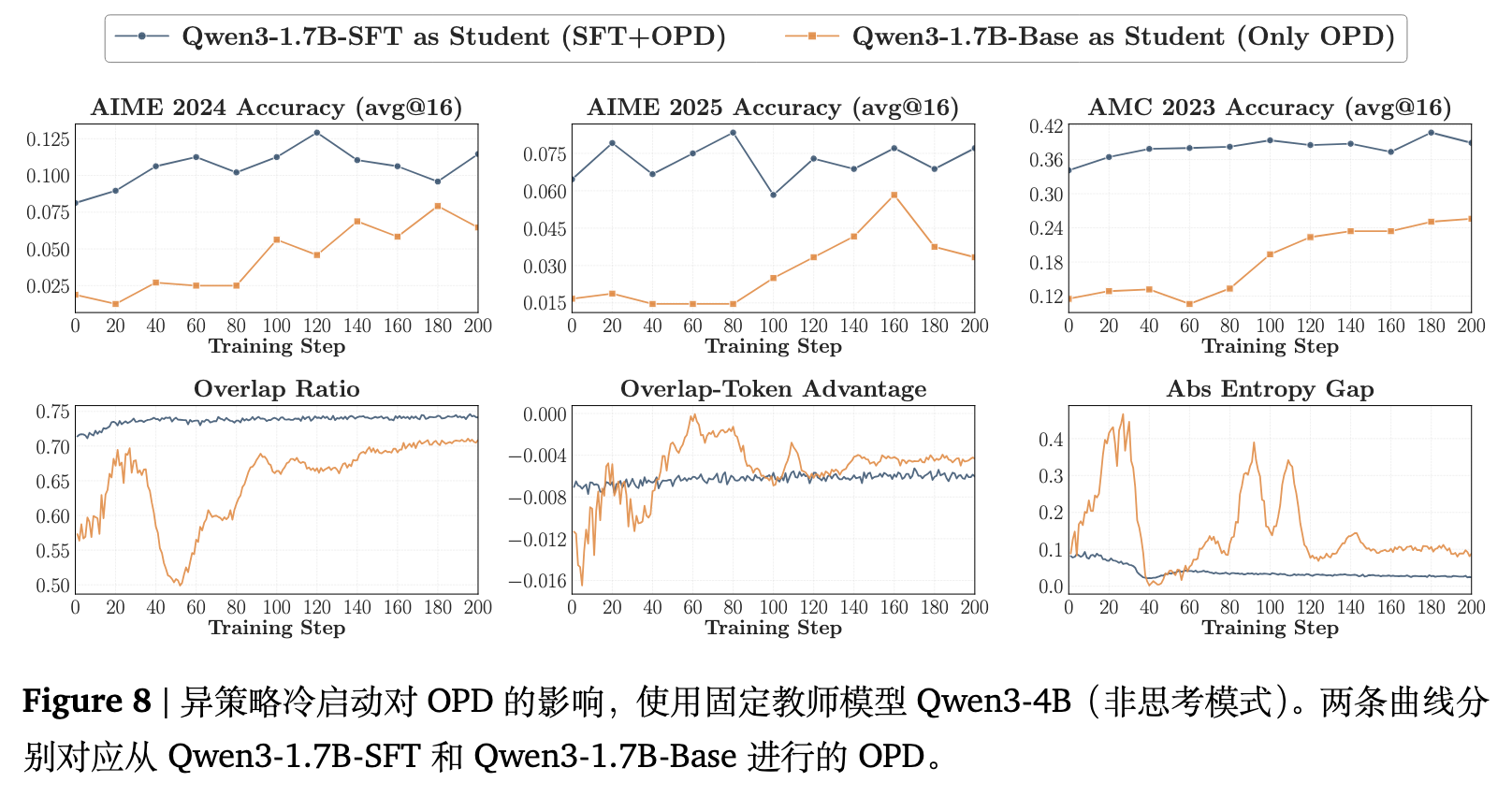
实验设置
选取 Qwen3-1.7B-Base 作为学生,Qwen3-4B (Non-thinking) 作为固定的教师。从 OpenThoughts3-1.2M 数据集中选取数学子集作为提示词源。教师在数据子集上生成 200K 条响应,使用这些离线轨迹对学生进行 SFT 冷启动,得到中间模型 Qwen3-1.7B-SFT。随后,使用数据集中剩余的约 30K 条去重提示词从 SFT 检查点继续进行 OPD。作为控制组对比,纯 OPD 基线直接从 Qwen3-1.7B-Base 开始,使用相同的教师和相同的 30K OPD 提示词,但不进行前置的 SFT。
实验结果与分析
如图 8 所示,两阶段策略明显优于纯粹的 OPD。从 Qwen3-1.7B-SFT 开始的运行在验证性能上持续超过直接从基座模型启动的对比组。不仅初期优化更快,最终达到的性能天花板也更高。
考察其底层的重叠动态可以得到同样的结论。经过 SFT 初始化的学生在一开始就具有高得多的重叠率,并在整个训练过程中维持了一条平滑稳定的轨迹。与之相反,直接初始化的学生起点较低,并在逐渐恢复前表现出明显的抖动。此外,SFT 初始化的熵差也要小得多,表明从一开始学生的置信度轮廓就与教师更为贴合。附录 C.2(图 21)中关于概率质量分布的进一步分析显示,冷启动后的学生在共享 token 上囊括了双方更多的高概率质量。这印证了离策略冷启动有效地缩小了初始模式差距,使得在 OPD 开始的那一刻起,教师的信号就能被立刻并稳定地利用。
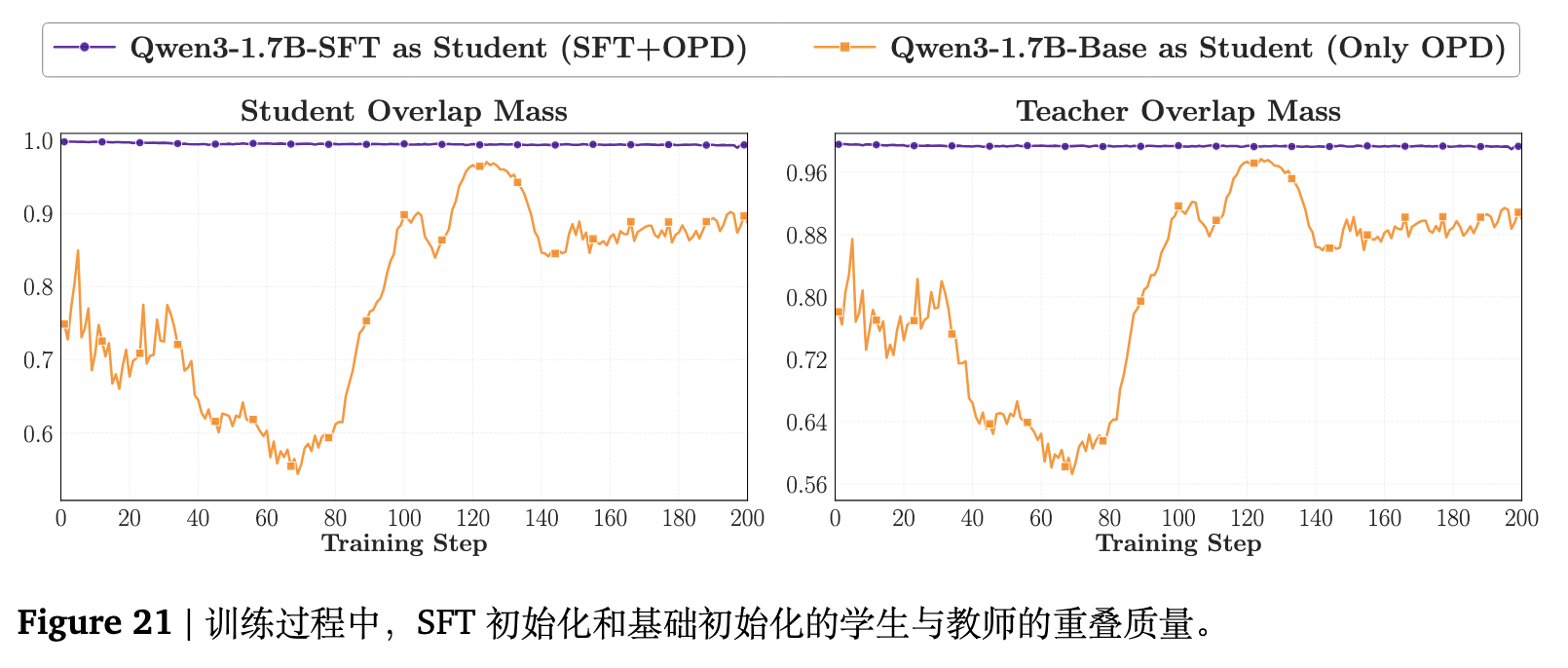
5.2 充分利用教师的后训练提示词 (Teacher-aligned Prompts)
除了通过 SFT 移动学生模型的分布外,另一种提高对齐度的思路是从数据端入手。因为教师模型的最终策略本质上是被其后训练阶段见过的提示词所塑造的,论文发现如果在 OPD 中采用与教师对齐的提示词,能获得更有效的监督信号。
研究在两个粒度上进行了测试:提示词模板(Prompt template)匹配,以及提示词内容(Prompt content)匹配。
1. 提示词模板对齐
-
设置:教师为 JustRL-1.5B,学生为 R1-Distill-1.5B。使用 DAPO-Math-17K 题目集,仅在模板格式上存在区分。“原始 DAPO 模板”是前文使用的标准格式;而“教师对齐模板”则完全复刻了 JustRL 后训练期间使用的指令格式。 -
原始 DAPO 模板示例: Solve the following math problem step by step... {Question}... -
教师对齐模板示例: {Question} Please reason step by step, and put your final answer within \boxed{}.
图 9 显示,仅仅切换到教师对齐的提示模板,就能全面提升三个基准测试上的验证性能。重叠率动态曲线也解释了原因:对齐的模板使得运行起点具备更高的重叠率,并逐渐收敛到更高的终点水平。这表明即使是模板上的细微调整,也能通过使学生的生成状态与教师更加兼容,实质性地改善 OPD。
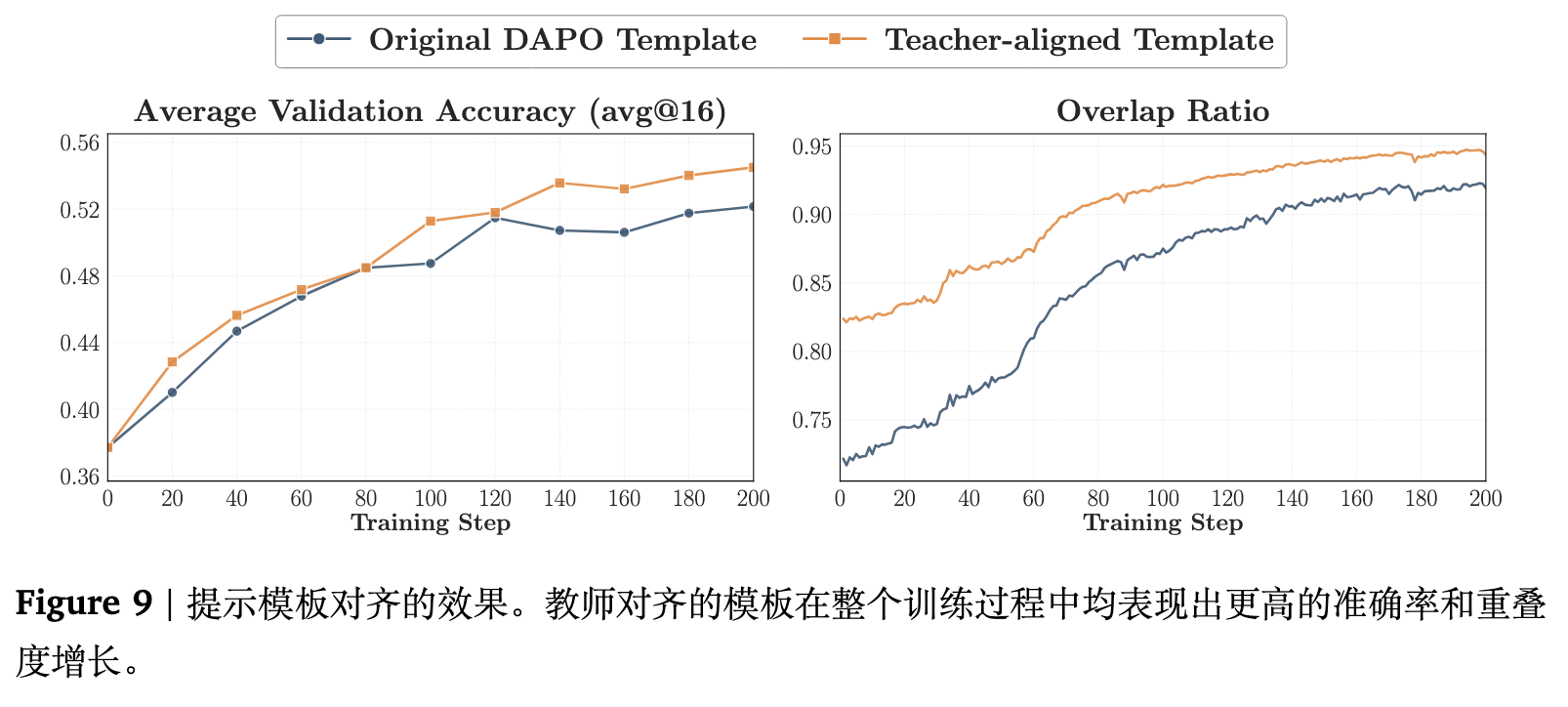
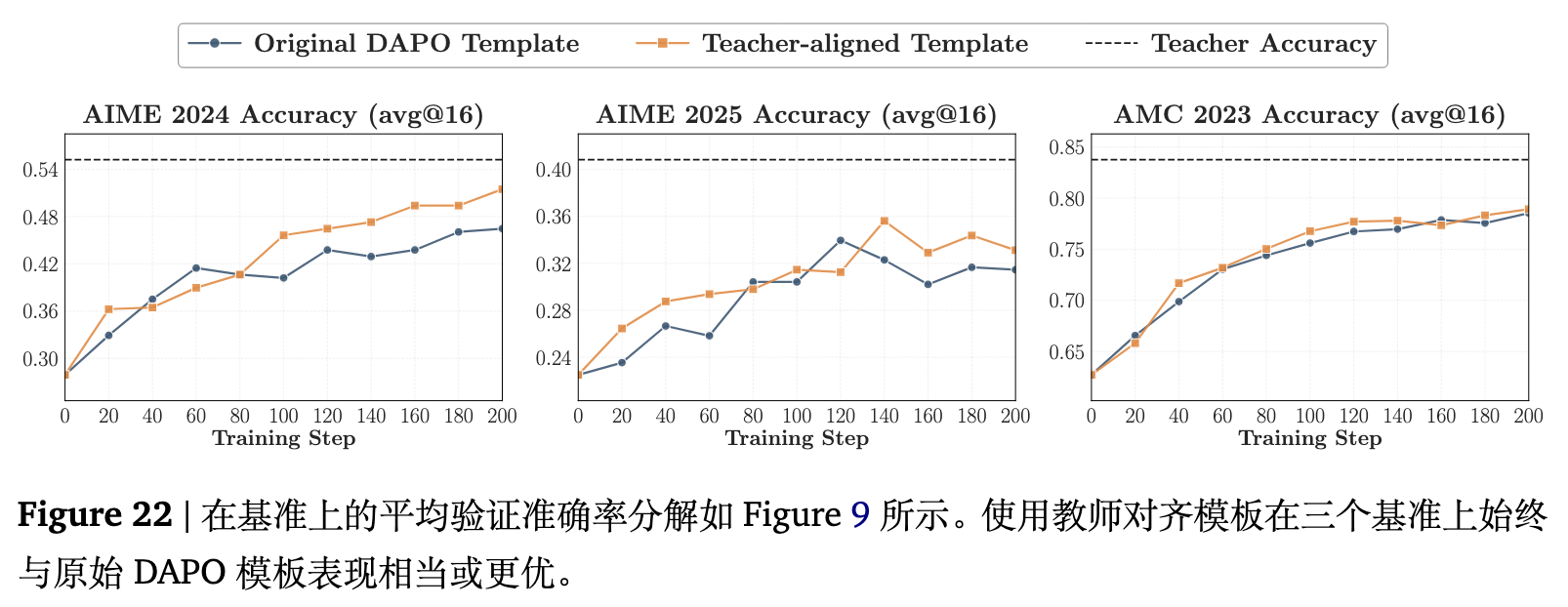
2. 提示词内容对齐
-
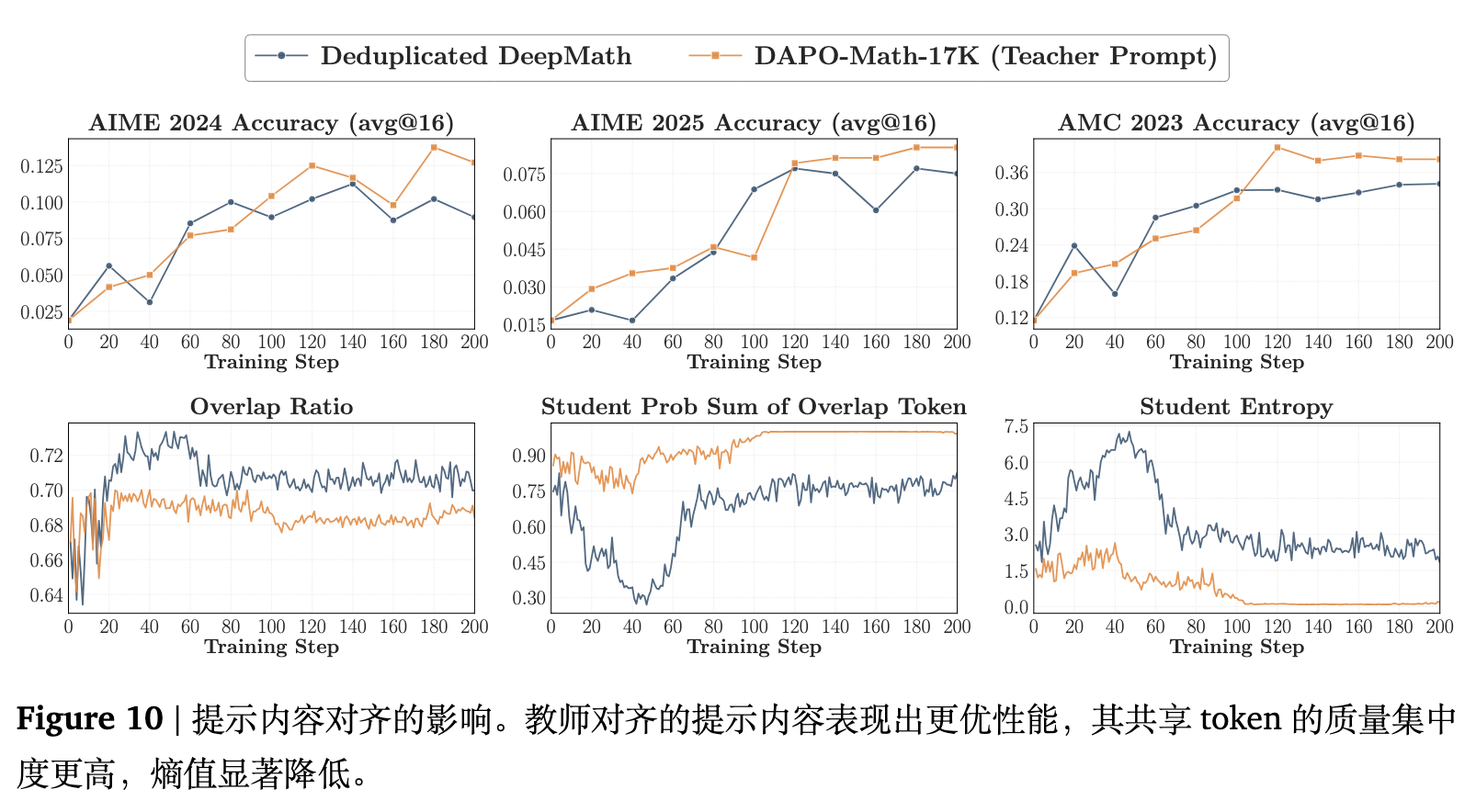
设置:教师使用经过 GRPO 训练的 Qwen3-4B-Base,学生为 Qwen3-1.7B-Base。对比两组规模相同的提示集:一个是与教师强化训练集强对齐的 DAPO-Math-17K;另一个是从 DeepMath 中抽取的子集,并经过了严格的去重过滤(详见附录 C.3,去除精确匹配和语义相似度过高的项)。该设计旨在测试 OPD 是否能从完全属于教师后训练分布的特定问题中获益。
图 10 展示的下游优势具有类似的趋势,但蕴含着一定的细微差别。虽然教师对齐的提示词在整个训练过程中导致的“重叠率”指标更低,但学生在该重叠子集上的累积概率质量总和却显著更高。这意味着学生将概率质量集中在数目更少、但重合程度更高的核心 token 上。实际的有效对齐因此变得更强。
然而,需要警惕的是,使用教师对齐的提示词会导致训练期间学生模型的策略熵产生断崖式下跌。这表明如果完全在教师见过的后训练提示词上进行 OPD,有引发策略过早坍缩的风险。在实际应用中,更为稳健的方案可能是混合使用分布内和分布外的提示词,既保持对重点对齐区域的敏感性,又兼顾学生维持必要的探索熵。
6. 讨论与局限性探究
OPD 的核心吸引力在于其提供密集的 token 级别监督:模型在每一步都能接收到来自教师的奖励信号,这与强化学习中稀疏的结果级奖励形成了鲜明对比。然而,这种密集监督在带来丰富学习信号的同时,也是需要付出代价的。前述的章节隐式地建立在一个假设之上,即教师在学生生成状态上提供的逐 token 信号应当始终是可靠和客观的。但研究发现这一假设并非在所有情况下均成立。
6.1 奖励质量随轨迹深度的增加而退化
首先探究教师提供的奖励质量是如何随着响应长度发生变化的。
响应长度存在一个“甜点区间”(Sweet spot)
在解码位置 处获取的监督信号取决于条件概率 。这里的条件是学生生成的前缀 。随着生成过程不断推进,如果学生的策略偏离了教师熟悉的流形区域,累积的漂移将导致教师产生的评分出现偏差。
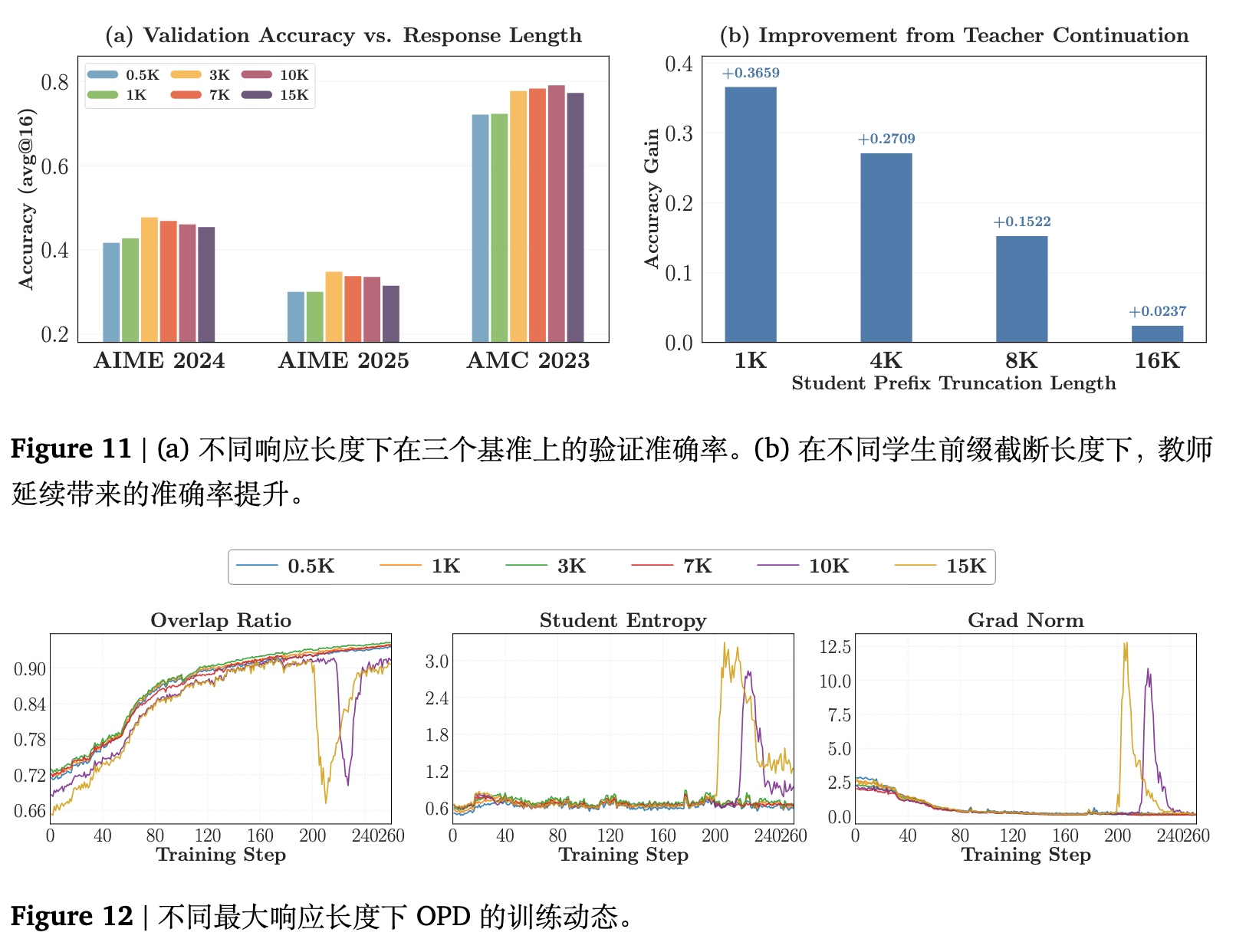
论文以 R1-Distill-1.5B 为学生,JustRL-1.5B 为教师,在六种最大响应长度设定下进行对比(0.5K 到 15K Token)。图 11 (a) 和图 12 显示了相关的表现动态:
-
极短响应(0.5K 和 1K):提供的监督 token 总量过少,导致学习曲线平缓,难以获得样本高效的提升。 -
中等长度(3K 和 7K):产生最强的基准测试效果,且重叠动态表现平稳,梯度范数无异常波动。 -
过长响应(10K 和 15K):在训练的中后期出现停滞或性能倒退的现象。特别是 10K 和 15K 组表现出晚期坍缩:重叠率急速下滑,伴随着学生策略熵和梯度范数的剧烈峰值波动。
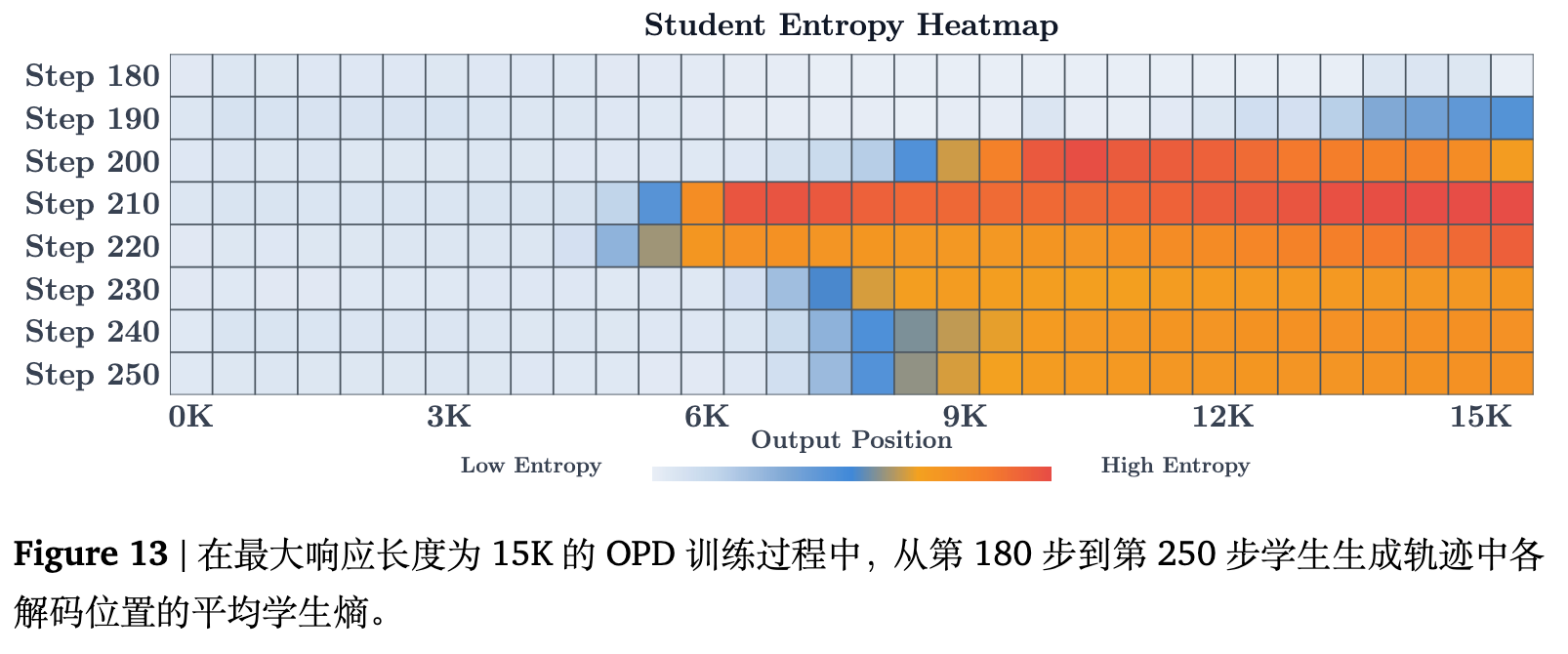
不稳定性源于序列后端的后缀-到-前缀(suffix-to-prefix)传播
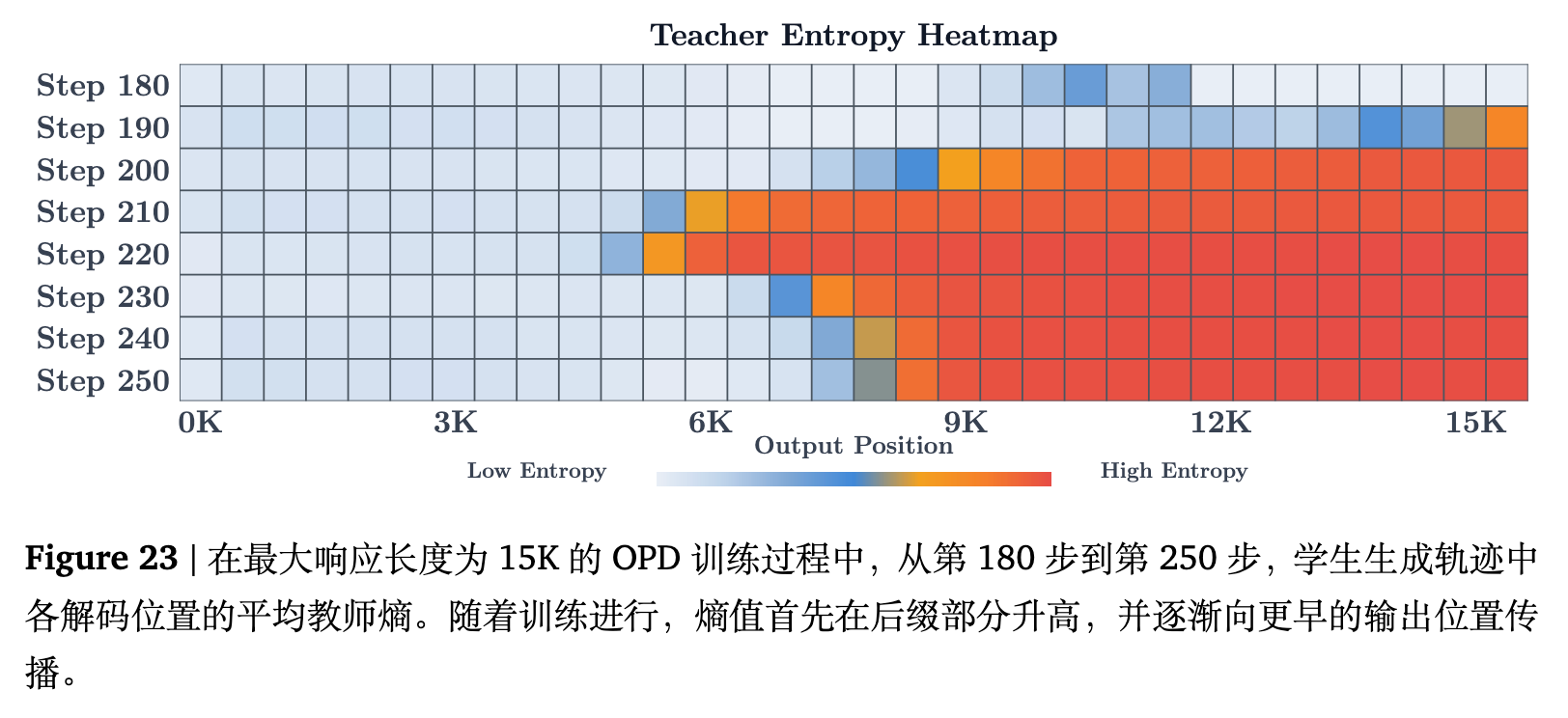
为了探明崩溃从何处开始,论文针对 15K 设置绘制了不同解码位置处的平均学生熵热力图。如图 13 所示,高熵的异常区域首先出现于长序列响应的末端(即尾部位置)。随着训练步数的推进,这种不稳定性逐渐向前沿位置逆向传播。结合附录 D.1 中(图 23)的教师熵热力图,可以发现教师在序列后端的概率分布也呈现出相同的高不确定性。这是因为在深度位置,教师面临越来越陌生的前缀,产生的带有噪声的奖励反过来又破坏了学生的局部稳定性。
论文进一步通过“前缀截断与续写验证”揭示了这一现象。测试基于不同截断长度的学生生成前缀让教师续写,结果显示教师的准确率优势从 1K 前缀时的 +0.3659 单调下降到 16K 前缀时的微乎其微(+0.0237),见图 11(b)。这确凿地揭示了 OPD Token 级别监督的基本张力:在适中长度的推理轨迹上,密集奖励极为有效;但在具有长视野的长思维链场景下,其可靠性将急剧衰退。
6.2 全局信息丰富的奖励并不保证具备局部可利用性
既然轨迹深度的增加会退化奖励,那么在那些失败的 OPD 任务中(例如使用更强大的 7B 模型作为教师时),是否是因为教师提供的整体奖励信号从根本上讲缺乏信息量?
实验设置与分析
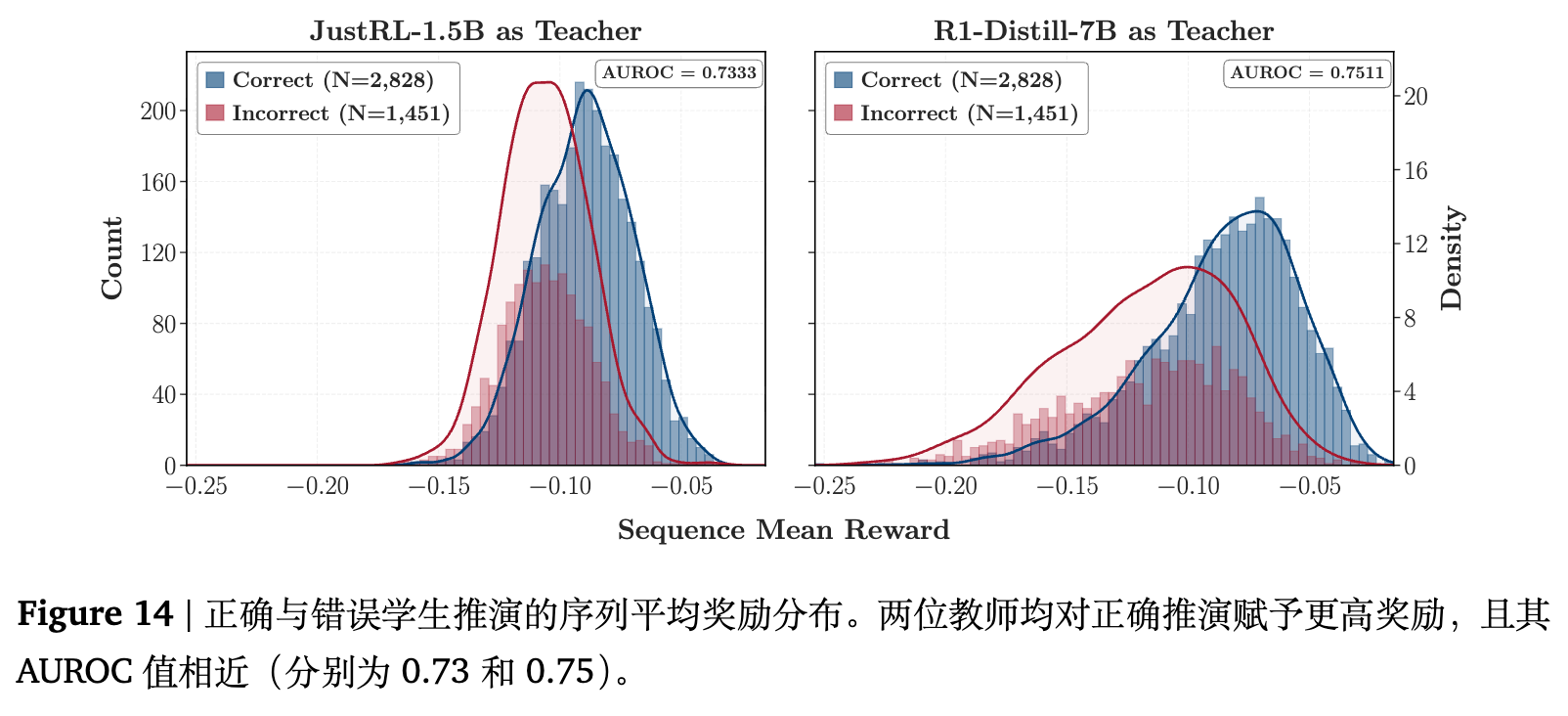
回到 4.1 节设定的 R1-Distill-1.5B 学生,分别对照成功教师 JustRL-1.5B 与失败教师 R1-Distill-7B。论文针对每条展开轨迹计算了序列的平均奖励 ,并比较了答对与答错的轨迹的奖励分布差异。
如图 14 所示,两种设定下,全局奖励结构均保持良好。无论是哪位教师,对正确的轨迹始终给出了更高的平均奖励,AUROC 值分别为 0.73(JustRL)和 0.75(7B)。这意味着失败的 7B 教师在识别整体输出好坏方面一点也不弱,甚至在全局区分度上略胜一筹。
关于局部优化几何的一项假设
既然奖励在全局层面上都是具有信息量的,为何用 7B 教师会导致 OPD 失败?在 4.1 节图 6 中,当 R1-Distill-7B 为教师时,其“重叠 token 优势”指标的绝对幅值在训练后期甚至大于成功的 JustRL,但其产生的梯度范数却持续维持在很小的水平(见附录 B.2 图 19)。
论文提出了各向异性(Anisotropy)的假设:7B 教师在每个独立 token 上的优势反馈虽然很大,但这些反馈在同一个序列的不同位置上方向分散、各向异性。当这些存在异质性的信号被聚合为参数梯度时,它们在反向传播过程中相互抵消,导致在参数空间中产生的是极小的有效梯度。相反,JustRL-1.5B 与学生拥有兼容的思维模式,可能其提供的优势信号集中在结构更为连贯的子集上。虽然其单点的 token 级别信号更小,但聚合后的梯度指向具备一致性,反向 KL 通过其模式寻求特性放大了这一趋同方向,完成了有效的迭代。
虽然这一推论仍有待通过计算海森矩阵等复杂操作来加以直接验证,但它点出了一个重要的事实:一个在全局统计层面有效并与基准正确性相关的奖励信号,不等于在一个具体参数局部优化几何空间内是一个具有有效可利用性(Exploitability)的梯度源。
6.3 采样单一 Token 作为奖励已经足够
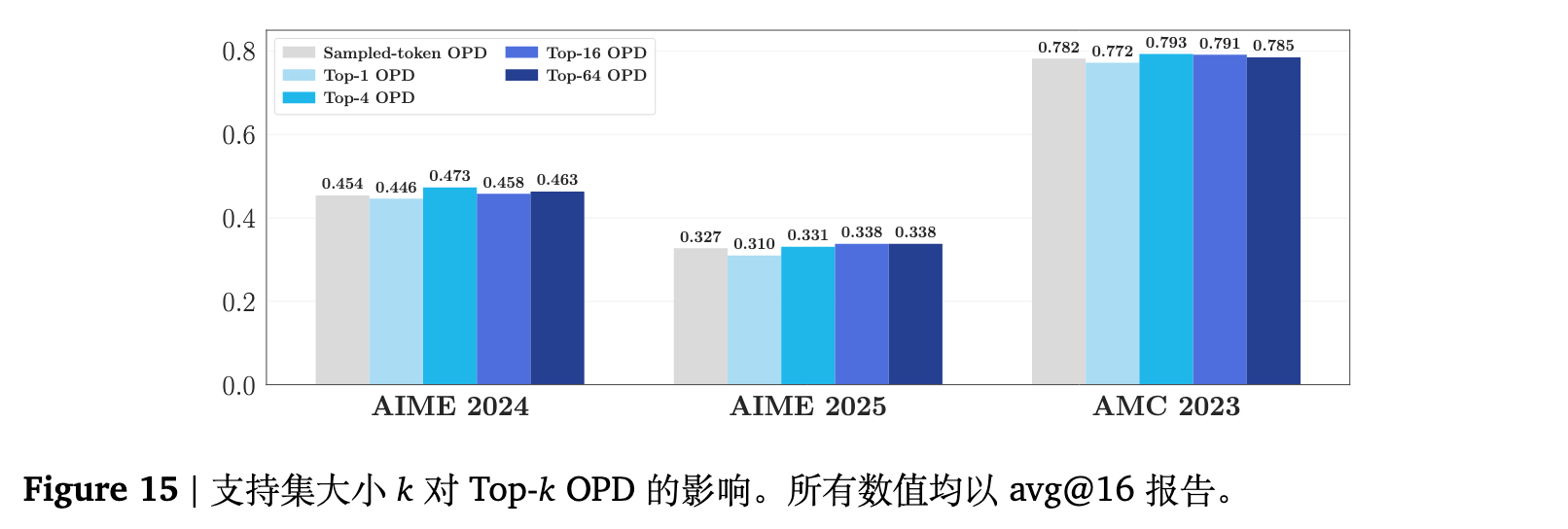
最后一个实践关注点是每一步需要利用多少个 token 的奖励来构建有用的梯度信号。Top- OPD 通过在每一步聚合最高概率的 个 token 提供支持。直觉上较大的 应该带来更好或更平稳的学习。论文测试了 的配置,并将其与极端简单的情况——仅使用模型自然采样出的单一 token(Sampled-Token OPD)进行了对比验证。
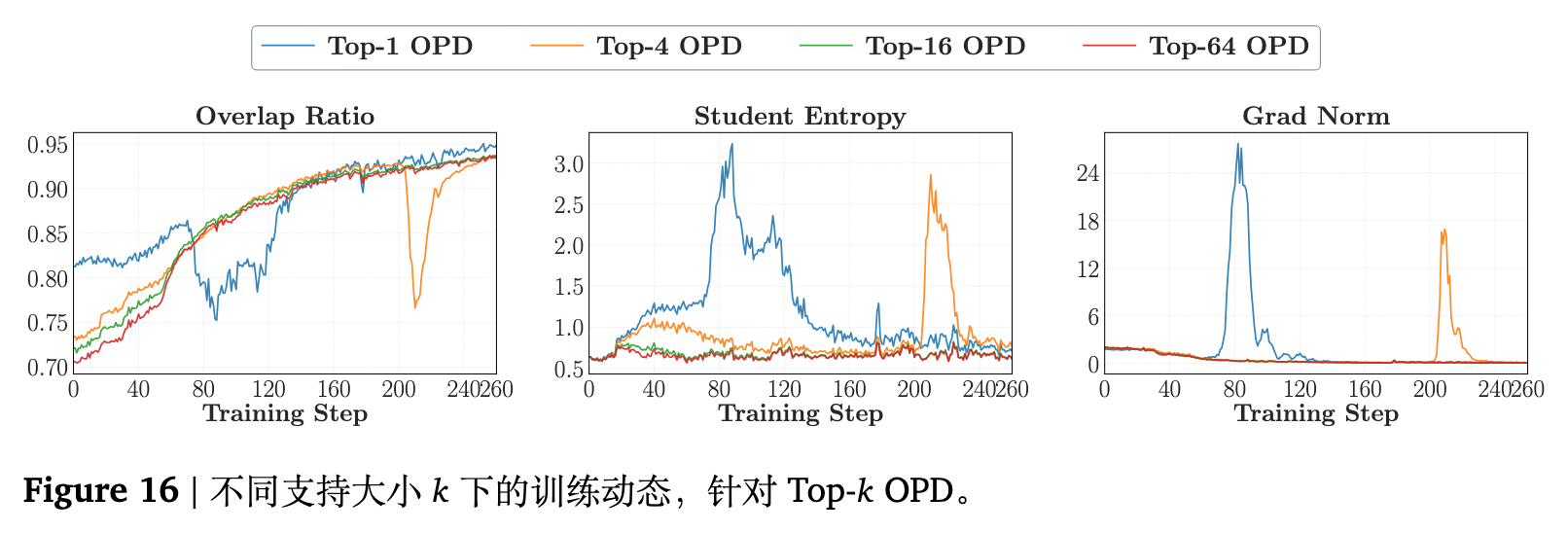
图 15 显示,Sampled-Token OPD 在三个基准上的平均得分完全可以媲美设置了各类 值的 Top- 方法。在各配置中,唯独 Top-1 OPD 表现不佳,远远落后于其他选项。将 增大到 4 以上仅仅带来计算开销的线性增长,并未获得显著的额外性能回馈。动态监测图 16 呈现了其内在特征:Top-1 引发了不稳定的重叠率增势,伴随熵与梯度范数的刺透尖峰。Top-1 的失败并非是因为“取样数量过少”,而是因为它的选择规则带有严重的模式集中偏差(永远选取 argmax token),从而破坏了优化的平稳性。
综合而言,在 OPD 中,由于学生模型在不同训练步是在自身的自回归分布中执行加权采样,单次的采样过程从大数定律上已对高概率区域进行了无偏覆盖。因此,极其轻量的单样本 Sampled-Token OPD 已经可以达到令人满意的效果,是实际系统部署时的优选设计。
更多细节请阅读原文。
往期文章:

