让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Co-Evolving Policy Distillation
-
论文链接:https://arxiv.org/pdf/2604.27083
TL;DR
今天解读一篇来自中国科学院信息工程研究所、中国科学院大学以及京东的论文《Co-Evolving Policy Distillation》。在大型语言模型的后训练(Post-training)阶段,基于可验证奖励的强化学习(RLVR)已成为提升模型推理能力的主流范式。然而,当研究人员试图将多种专家能力(如文本推理、图像推理、视频理解)整合到一个单一模型中时,传统的训练方法面临着明显的局限性:直接混合多领域数据进行 RLVR 训练会引发“能力分歧(Capability Divergence)”,导致不同能力之间相互干扰;而先分别训练领域专家,再通过多教师同策略蒸馏(MOPD)进行合并的静态流水线,又会因为教师和学生在行为模式上偏离过远,导致吸收效率(Absorption Efficiency)低下。
为了解决这一困境,作者提出了一种名为协同进化策略蒸馏(Co-Evolving Policy Distillation, CoPD)的新范式。CoPD 放弃了传统的“先训练专家,后静态蒸馏”的串行流程,转而采用多分支并行训练的架构。在训练过程中,每个分支交替进行针对特定领域的 RLVR 探索与跨分支的相互同策略蒸馏(Mutual OPD)。这种设计使得各个专家模型在不断深化自身领域能力的同时,互为师生,持续交换新获取的知识。
实验结果表明,CoPD 能够始终将教师与学生之间的行为距离保持在易于吸收的范围内。在文本、图像和视频推理的联合训练中,CoPD 不仅有效避免了跨领域数据混合带来的性能损耗,其最终合并的统一模型在各项基准测试上的表现均优于 Mixed RLVR 和静态 MOPD 基线,甚至在多个维度上超越了专门针对单一领域训练的专家模型。这一方法为多模态大模型的能力扩展提供了一种基于模型并行训练(Model Parallel Training)的有效路径。
1. 引言
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)在大型语言模型(LLM)的后训练中取得了重要进展。通过群体相对策略优化(GRPO)等算法,模型在视觉推理、文本数学推理和视频理解等领域的性能得到了大幅提升。然而,如何训练一个能够同时掌握所有这些能力的单一全能模型,一直是该领域面临的挑战。
当使用包含多种能力要求(如纯文本数学题和多模态图像推理题)的混合数据对单一模型进行 RLVR 训练时,通常会出现“能力权衡(Capability Trade-off)”现象。作者将这种现象称为能力分歧(Capability Divergence):不同的能力倾向于不同的优化方向,导致在单次训练中难以同时推进所有能力。在混合数据训练中,某一项能力的提升往往以牺牲另一项能力为代价。
由于单次 RLVR 训练难以同时精通所有能力,目前的常规做法收敛于一种两阶段的静态流水线:首先,在基础模型(Base Model)的多个副本上,分别使用不同领域的数据进行独立的 RLVR 训练,从而获得多个专业化的“专家(Experts)”;随后,通过同策略蒸馏(On-Policy Distillation, OPD)——在多专家场景下称为多教师 OPD(MOPD)——将这些专家的能力整合到一个统一的策略模型中。这种方法通过物理隔离特定能力的训练,避免了梯度冲突,因此被广泛采用。
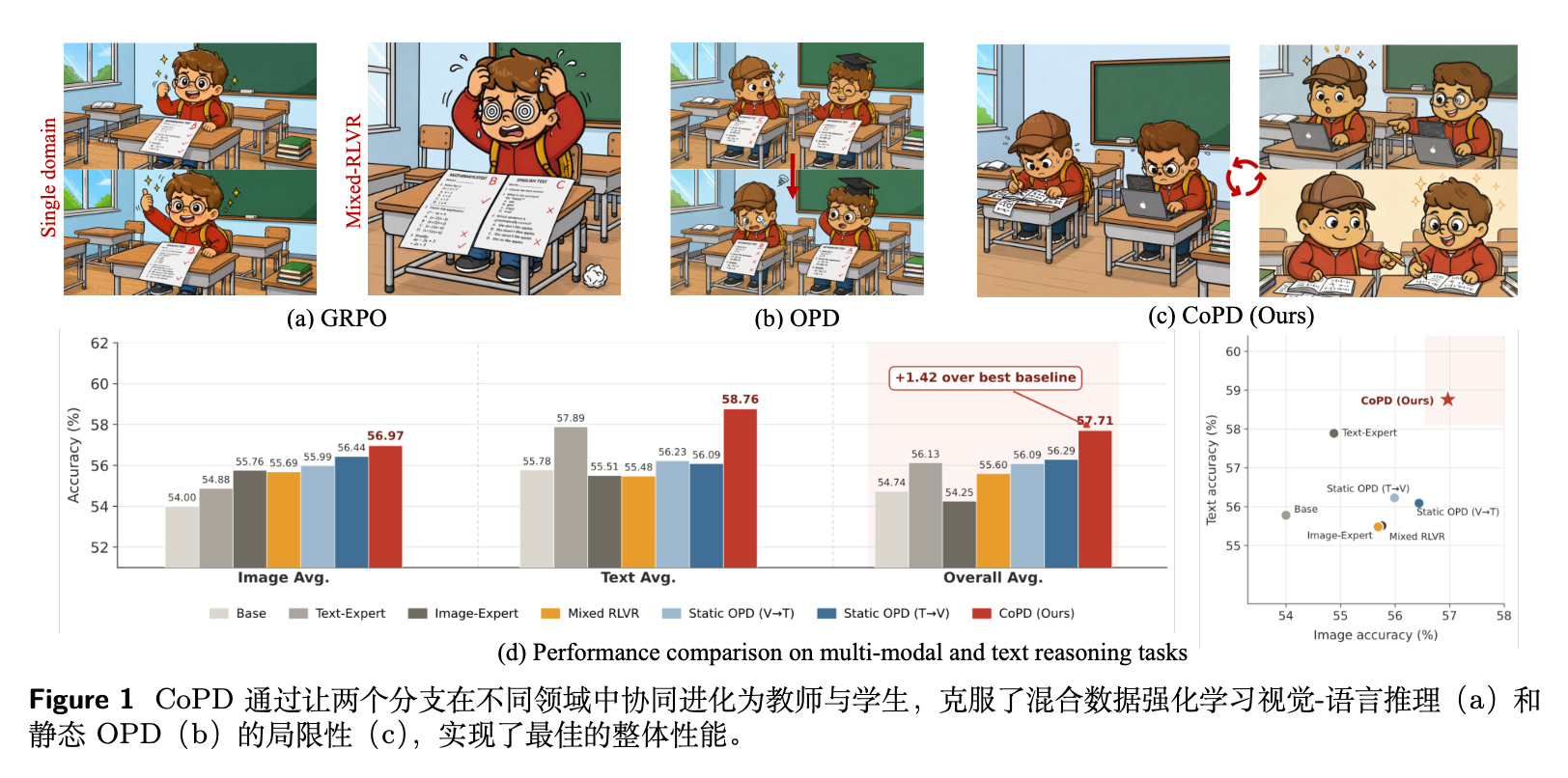
然而,作者指出,当前的 OPD 应用方式存在一个未被解决的关键问题。在现有的静态流水线中,每个专家首先在自己的数据上训练至收敛,然后被冻结为静态教师,用于指导一个独立的学生模型。作者认为,当蒸馏阶段开始时,教师的策略分布已经偏离学生模型太远,导致其提供的监督信号难以被有效吸收。
基于这一洞察,作者提出了 CoPD 框架。CoPD 维护多个并行的训练分支,每个分支对应一种特定能力。与冻结分支作为静态教师不同,CoPD 在整个训练过程中交替进行分支特定的 RLVR 和跨分支的相互蒸馏。这样一来,每个分支在深化自身专业知识的同时,也作为不断进化的教师指导其他分支。这种“协同进化”机制确保了各分支在保持足够知识差异(以提供信息量)的同时,其行为模式始终保持在彼此可吸收的范围内。
2. 现有范式的统一视角与实证分析
为了从理论和经验上论证 CoPD 的必要性,作者首先将混合数据 RLVR 和静态 OPD 流水线置于一个统一的分析框架下,揭示了它们各自在优化信号传递上的结构性损耗。
2.1 现有范式的统一视角
假设需要将两种能力(分别由数据集 和 代表)整合到一个统一策略中。令 表示这两个数据集中包含的总优化信号,即如果两个数据集的信号能够被完美应用于统一策略,所能实现的理想能力增益。作者用以下公式来描述特定范式 的实际效用 :
其中, 衡量范式 将理想信号 转化为实际能力的有效性(吸收率),而 捕获了范式在不完美转化之外引入的额外损失。
混合数据 RLVR:作为冲突的能力分歧
当单一模型在 上联合优化时,每步更新的梯度是两个数据集诱导梯度的平均值。由于不同能力倾向于不同的优化方向,它们的梯度在特定能力的维度上存在分歧,这种分歧表现为参数更新中的梯度冲突。其效用可表示为:
其中 是能力分歧成本,即两种能力优化方向冲突的幅度。混合数据 RLVR 以“跷跷板效应”支付这一成本:无论如何调整数据混合比例,一种能力上的增益总是被另一种能力的干扰所部分或全部抵消。在统一公式中,这对应于 且 。
静态 OPD 流水线:避免了分歧,但吸收率低下
静态流水线通过隔离训练每个专家来避免梯度冲突,因此分歧成本 被消除。代价转移到了整合阶段。在 OPD 步骤中,学生模型在其自身的同策略轨迹 上进行训练,教师模型 在每个访问过的状态 处提供词元级别的监督:
作者指出,当教师和学生在同策略轨迹上表现相似时,上述公式中的监督最为有效。此时,两者的词元分布有大量重叠,教师的预测能够强化学生本来就有可能生成的词元。然而,当专家在隔离状态下训练至收敛时,它们的行为已经偏离了共享的基础模型,其在学生轨迹上的预测与学生自身的预测大相径庭。在这种不匹配下,OPD 信号变得难以吸收,只有一小部分优化信号被传递。其效用形式为:
其中 是依赖于师生行为重叠度 的吸收效率函数, 表示专家在隔离收敛后产生的低重叠度。这对应于 (一个较小的正值),且 。
CoPD 的目标
上述两种范式在相反的方向上牺牲了优化信号。一个理想的范式必须同时满足两个条件:(i) 保持特定能力的优化隔离以消除分歧成本;(ii) 将师生重叠度维持在一个较高的水平,使得 足够大,从而实际吸收优化信号。CoPD 的效用形式为:
其中 是通过交替结构主动维持的中等重叠度。
2.2 行为假设与可测量指标
为了使上述分析可测试,作者提出了行为一致性假设(Behavioral consistency hypothesis):当教师和学生表现出更相似的行为模式时,OPD 信号更容易被吸收,因为它们的同策略轨迹会访问相似的状态,且教师的预测与学生倾向于生成的词元更加一致。
作者通过同策略轨迹上的 Top- 词元重叠度(Top- token overlap) 来实例化这种行为相似性。给定教师 和学生 ,定义如下:
其中 表示预测概率最高的 个词元的集合, 是由学生诱导的状态访问分布。较大的 表明在学生实际访问的状态下,教师和学生对哪些词元可能出现持有相同的看法。
2.3 导向性实验(Pilot Study)
作者设计了两个互补的实验来验证上述假设。
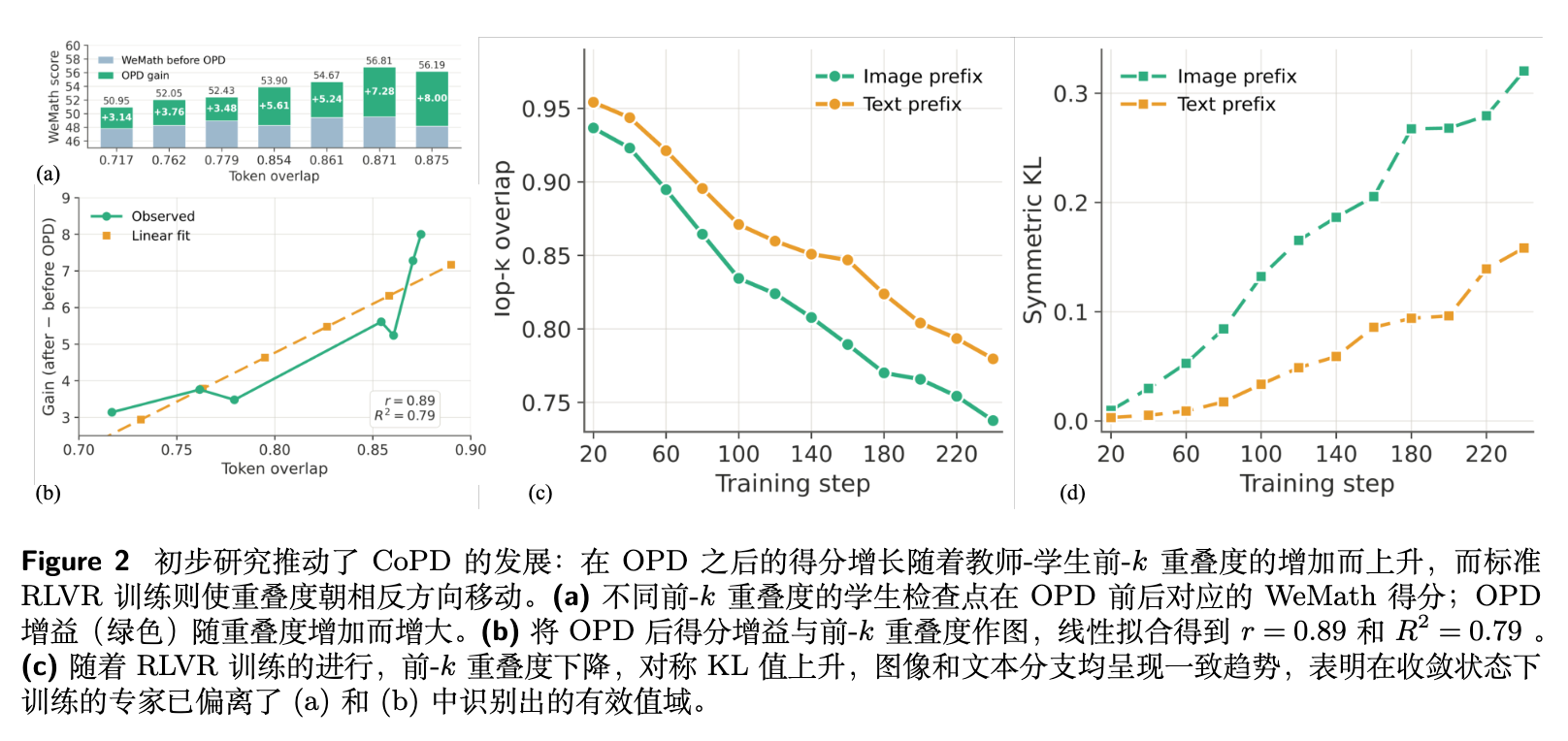
实验 1:吸收效率 随师生重叠度上升
作者固定了一个教师模型(在图像数据 上通过 RLVR 获得的专家),并通过使用不同的采样温度对基础模型进行短期训练,构造了一系列与教师具有不同 值的学生模型。对每个学生,在相同的预算下进行 OPD 训练,并记录蒸馏前后的能力增益。
结果显示,OPD 后的增益随 单调增加,呈现出 的强线性相关性。这直接支持了行为一致性假设:即使教师固定,行为上更对齐的学生也能更有效地吸收 OPD 信号。当然,如果 ,师生变得无法区分,KL 散度趋于零,OPD 增益必然崩溃。因此,有效的范式必须主动维持师生之间非平凡的行为差距,同时防止差距过大。
实验 2:标准 RLVR 会将行为重叠度推向低 区域
作者测试了静态流水线是否能将 OPD 保持在高 区域。他们从共享的基础模型 初始化,分别在文本数据和图像数据上独立训练两个专家。在固定的间隔内,测量每个专家在同策略轨迹上与 的 Top- 重叠度和对称 KL 散度。
结果表明,随着 RLVR 的进行,与共享基础模型的 单调下降,而对称 KL 散度上升了一个数量级。这意味着,当专家收敛时,它们已经远离了共享基础模型,其重叠度远低于实验 1 中 最高的水平。这证实了静态流水线系统性地运行在低 区域。
方法设计的启示:为了提高吸收效率,(i) 蒸馏必须在专家训练期间发生,而不是之后;(ii) 教师必须随着学生的进化而继续进化,以主动维持行为重叠;(iii) 特定能力的训练必须继续推开双方的距离,确保监督信号保留学生尚未掌握的信息。
3. 协同进化策略蒸馏(CoPD)方法设计
基于上述启示,作者提出了 CoPD 框架。以双分支为例,给定基础模型 ,CoPD 初始化两个平行的学习分支 和 ,初始参数 ,分别关联能力数据集 和 。训练在两个阶段之间交替进行。
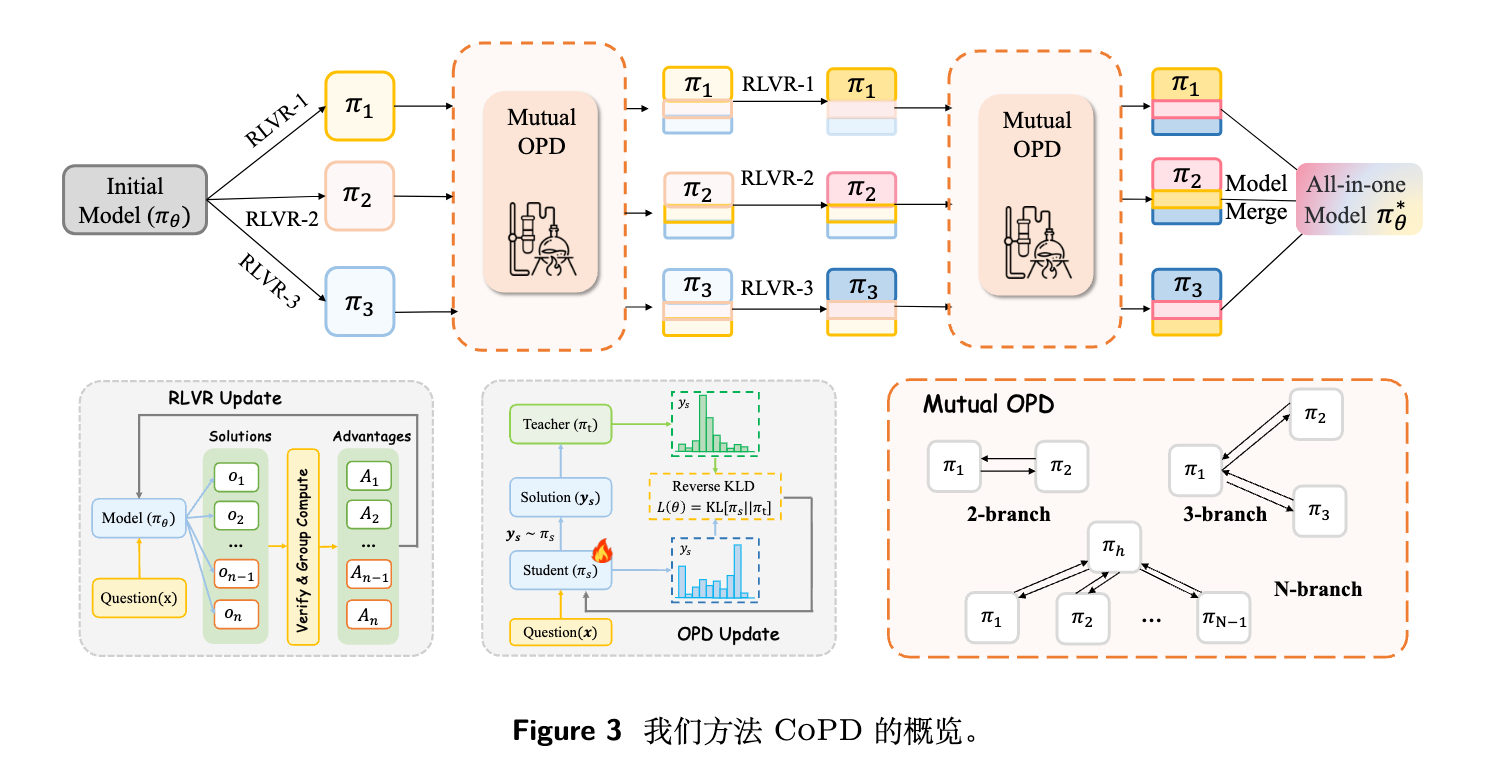
3.1 分支特定的 RLVR 阶段
在 RLVR 阶段,每个分支 独立地在对应能力的数据上执行 GRPO,以深化特定领域的专业知识。对于提示 ,分支 从其当前策略 中采样一组轨迹 ,这些轨迹由特定能力的奖励函数 进行评估。分支 的 RLVR 目标定义为:
其中 是组内标准化的优势值, 是重要性采样比率。这一阶段逐渐将两个分支推向不同的能力前沿,在它们之间打开一个知识差距,供后续的相互蒸馏利用。
3.2 相互 OPD 阶段
在相互蒸馏阶段,每个分支在另一个分支的数据上生成同策略轨迹,并接收来自该分支的词元级监督。由于两个分支从相同的基础模型起步,并定期通过蒸馏对齐,它们的策略在整个训练过程中保持行为上的接近,因此监督信号落在每个分支都熟悉且易于吸收的状态上。
具体而言,分支 从分支 的数据集采样提示 ,并从 生成轨迹。分支 随后在词元级别评估这些轨迹。在位置 ,教师信号定义为:
跨分支更新的词元级优势值为 ,其中 平衡跨分支蒸馏的相对贡献。关键在于,分支特定的 RLVR 在相互 OPD 期间并不暂停,而是交错进行。两个分支在每一步都交替扮演教师和学生的角色。
3.3 交替训练流程
CoPD 将上述两个阶段组织成 个交替周期。在每个周期 中,所有分支依次执行:
阶段 I:分支特定的 RLVR。每个分支 在其自身数据上执行 步 GRPO:
阶段 II:相互 OPD。每个分支 执行 步相互蒸馏:
超参数 和 决定了两个阶段之间的节奏。较大的 允许分支积累更多差异化的发现,较大的 导致更彻底的知识转移。由于所有分支保持紧密耦合,它们的参数不会发生剧烈发散。训练结束后,通过简单的参数合并(Parameter Merging)即可获得最终的统一模型:
对于 的多分支扩展,CoPD 采用中心辐射(Hub-and-spoke)拓扑结构,选择一个分支作为共享枢纽,与每个辐条分支交换相互 OPD,避免了全连接对齐带来的计算开销。
4. 实验设置
训练数据与基准测试
作者在双分支(文本和图像推理)和三分支(引入视频推理)设置下评估了 CoPD。
-
文本推理:使用 Polaris-Dataset-53K,包含高质量数学推理问题。评估基准包括 AIME 2024、AIME 2025、HMMT 2025、MATH-500 和 Minerva Math。 -
图像推理:使用 MMFineReason-123K。评估基准包括 MMMU、MMMU-Pro、MathVista、MathVision、ZeroBench、WeMath 和 MathVerse。 -
视频推理:收集并过滤了 40K 中等难度的样本。评估基准包括 Video-Holmes、MVBench、MMVU 和 VideoMathQA。
模型与基线
实验基于 Qwen3-VL-4B-Instruct 模型。对比基线包括:
-
Text-Expert / Image-Expert / Video-Expert:在各自领域数据上独立通过 RLVR 训练的专家模型。 -
Mixed RLVR:将所有数据混合到一个池中训练单一模型。 -
Static OPD (V→T / T→V) :先独立训练专家,然后将一个专家作为固定教师,向另一个分支进行单向 OPD。 -
MOPD:在三分支设置中,所有领域专家联合蒸馏到一个学生模型中。
实现细节
CoPD 基于 EasyVideoR1 框架实现。最大输入和输出长度均设置为 16,384 个词元。学习率固定为 。Rollout 批次大小为 256,每个提示采样 8 个 rollout,温度为 1.0。裁剪边界设置为 和 。所有基线和 CoPD 使用相同的总训练步数以确保数据吞吐量一致。
5. 实验结果与分析
5.1 文本与图像推理的双分支协同进化
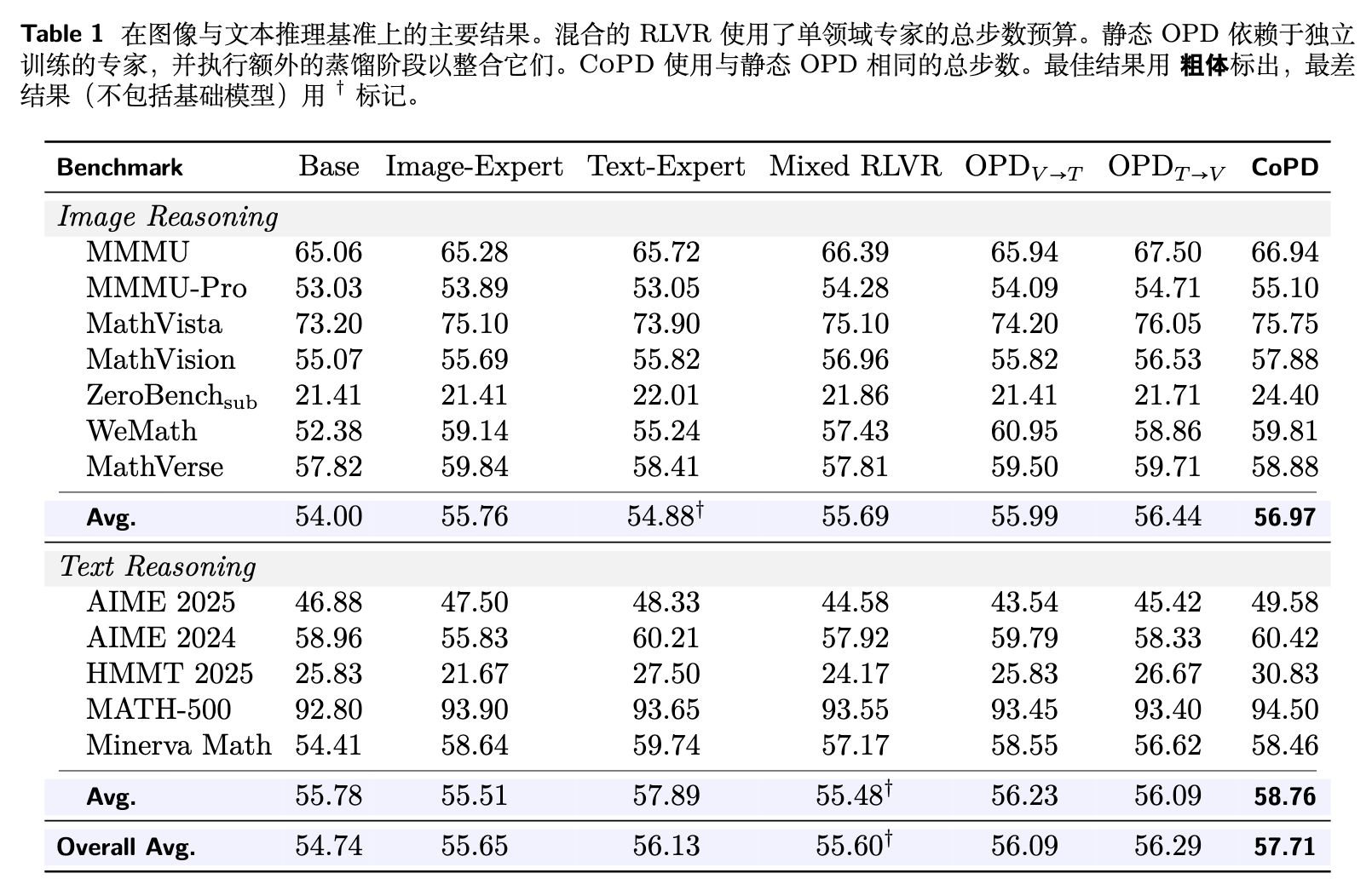
表 1 展示了文本和图像推理的主要结果。CoPD 在所有基线中取得了最佳的整体性能(57.71%)。
-
能力分歧的验证:与 Text-Expert(57.89%)相比,Mixed RLVR 在文本推理上的表现下降至 55.48%,证实了联合优化异构数据会产生跨领域干扰。 -
静态 OPD 的局限性:静态 OPD 避免了这种干扰。在 V→T 方向,图像和文本推理均优于 Mixed RLVR,但文本推理(56.23%)仍远低于 Text-Expert。在 T→V 方向,尽管图像推理受益于文本专家的指导,但 Text-Expert 强大的文本能力在蒸馏后的模型中仅保留了 56.09%。这表明,由于专家偏离学生太远,教师的大部分知识未能通过事后蒸馏传递给学生。 -
CoPD 的优势:相比之下,CoPD 同时提升了图像推理(56.97%)和文本推理(58.76%),在两侧均超越了专门针对单一领域训练的专家模型,实现了真正的互利共赢。
5.2 扩展至文本、图像和视频推理的三分支协同进化
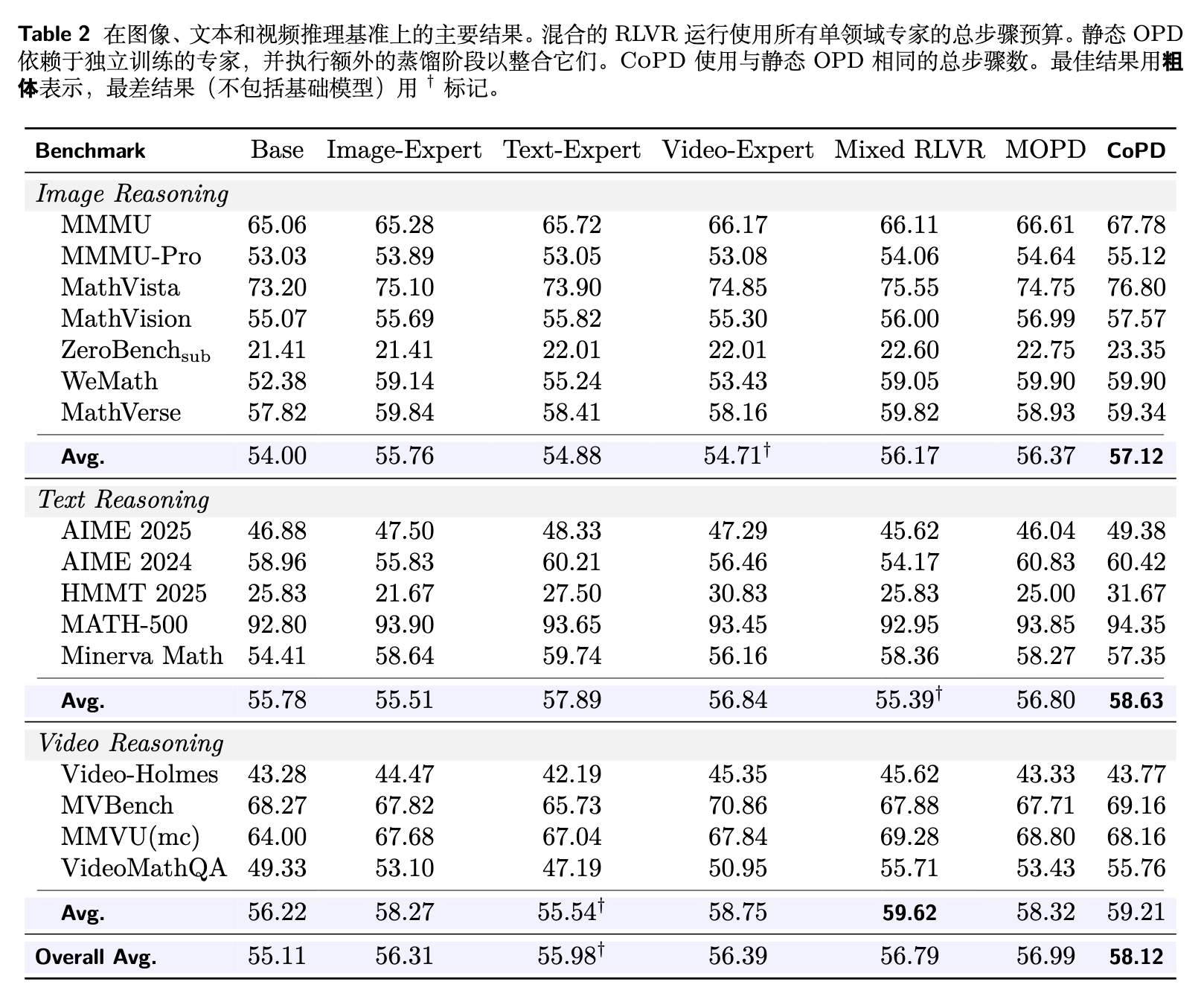
表 2 将 CoPD 扩展到三分支设置。结果趋势与表 1 一致:CoPD 取得了最佳的整体性能(58.12%),并在主要能力组上优于 MOPD。
-
值得注意的是,MOPD 在视频推理上的表现(58.32%)不及 Video-Expert(58.75%),证实了随着能力分支数量的增加,静态多教师蒸馏难以吸收所有专家的知识。 -
Mixed RLVR 在基线中取得了最高的视频平均分(59.62%),但这以牺牲文本推理(55.39%)为代价,再次展现了能力分歧。 -
CoPD 避免了这种权衡,通过共同进化三个分支,在不牺牲任何单一领域的情况下巩固了它们的能力。
5.3 消融实验与动态分析
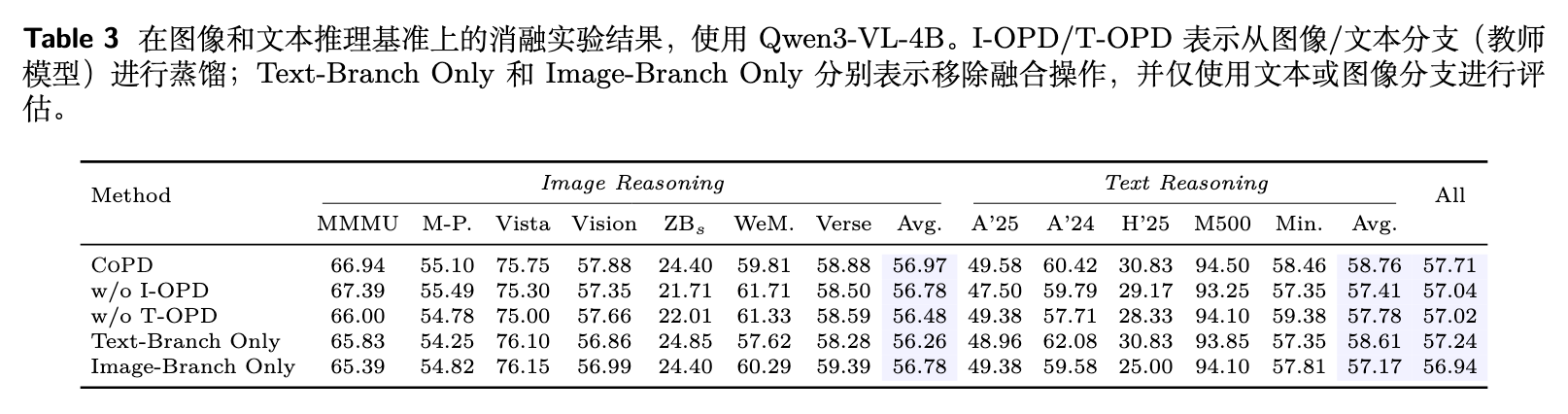
组件消融:表 3 研究了 CoPD 中各组件的贡献。移除 I-OPD(来自图像分支的蒸馏)导致文本推理从 58.76% 降至 57.41%;移除 T-OPD 导致图像推理从 56.97% 降至 56.48%。这证实了双向相互 OPD 的必要性。作者还对合并(Merge)操作进行了消融。即使不进行合并,仅保留文本分支或图像分支,其单分支的整体性能(57.24% 和 56.94%)也已经超越了表 1 中的静态 OPD 变体,表明协同进化本身就能产生能力全面的分支。合并操作进一步巩固了互补优势。
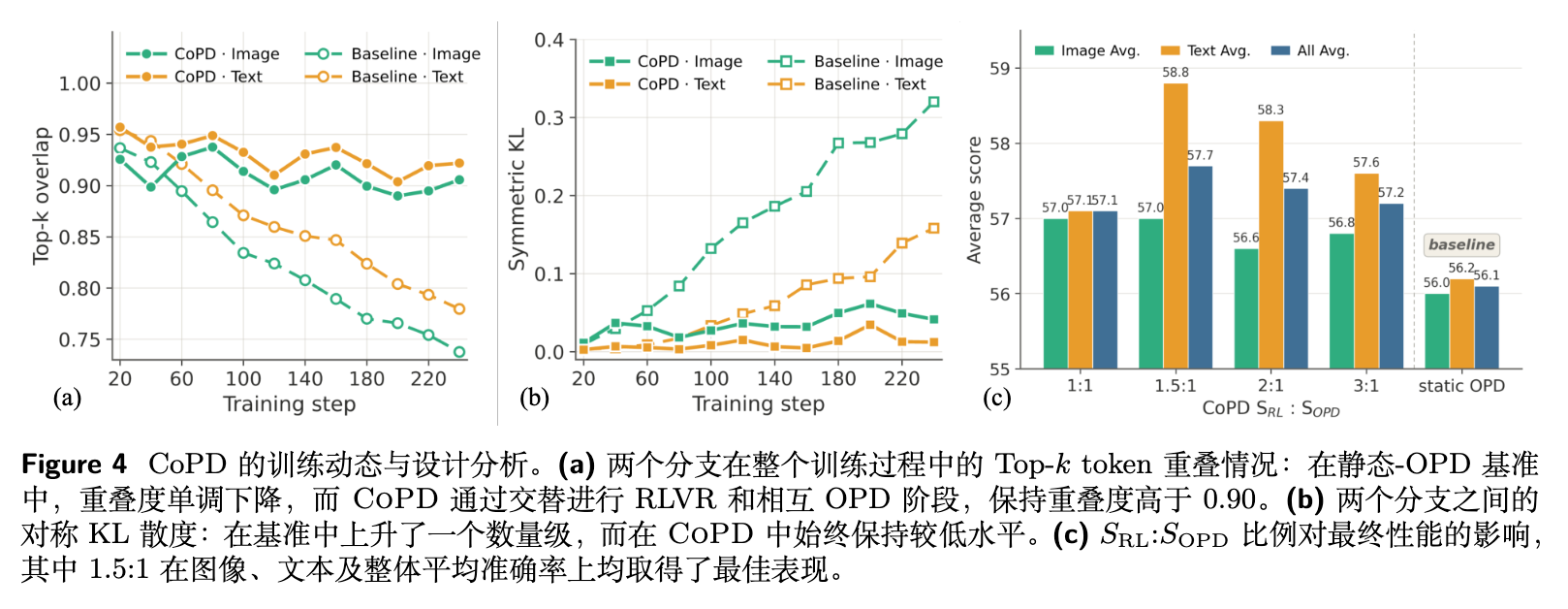
训练期间的行为模式一致性:图 4 (a) 和 (b) 追踪了训练期间两个分支之间的 Top- 词元重叠度和对称 KL 散度。在静态 OPD 基线中,重叠度单调下降,KL 散度上升了一个数量级。而在 CoPD 中,Top- 重叠度在每个 RLVR 阶段下降,但在相互 OPD 期间恢复,整个训练过程中保持在 0.90 以上。对称 KL 散度始终保持在低位。这证实了 CoPD 的核心设计:RLVR 创造了使蒸馏具有信息量的分歧,而相互 OPD 恢复了使其易于吸收的接近度。
比例的影响:图 4 (c) 分析了 RLVR 探索步数与 OPD 巩固步数比例的影响。在不同比例下,CoPD 始终优于静态 OPD。其中, 取得了最佳的整体准确率。这表明需要足够的特定分支探索来创造有用的互补知识,但过长的探索可能会削弱分支之间的对齐,降低后续蒸馏的有效性。
6. 讨论与相关工作
大型模型的 RLVR
基于可验证奖励的强化学习(RLVR)已成为激发大型模型推理能力的主导范式,取代了基于规则的奖励模型。GRPO 消除了对独立价值网络的需求,使得大规模 RLVR 训练变得可行。本文的工作探索了如何在 RLVR 框架内同时容纳多种能力,解决了多领域联合训练中的梯度冲突问题。
同策略蒸馏(On-Policy Distillation)
同策略蒸馏在学生自身生成的轨迹上提供教师监督,缓解了离策略方法固有的训练-推理分布不匹配问题。多教师 OPD(MOPD)被广泛用于基础模型的后训练。本文的导向性实验从学生采样温度控制重叠度的角度,揭示了静态 MOPD 存在行为不匹配的局限性。CoPD 将蒸馏从训练“后”提前到训练“中”,在保持互补知识差距的同时,使师生在行为上保持接近。
Self-Taught RLVR 系列研究
本文是作者团队“Self-Taught RLVR”系列研究的第三部分,旨在探讨 LLM 如何更好地向自身学习并自我进化。第一部分 RLSD 研究了“知情自我(informed self)”;第二部分 NPO 关注“时间自我(temporal self)”;本文则探索了“平行自我(parallel self)”——平行的自我相互传授知识。
7. 总结
本文探讨了一个核心问题:如何更好地将多个专家的能力吸收到一个单一模型中?作者发现,传统的混合数据 RLVR 面临能力分歧成本,而传统的静态 OPD 流水线则面临吸收效率低下的问题。为此,本文提出了协同进化策略蒸馏(CoPD),其核心思想是:专家之间的蒸馏应该在训练期间发生,而不是在训练之后;多个专家模型应该互为师生,协同进化。
每个专家的对应分支在自身数据上执行 RLVR 以探索能力前沿,并穿插来自其他专家的相互 OPD 以拉近行为模式,使其更易于相互学习。实验验证了 CoPD 实现了多专家能力的全能整合,甚至优于各自的专家模型。CoPD 展现出的强大性能提供了一个引人入胜的视角:模型并行训练(Model parallel training)可能成为进一步拓宽模型能力边界的一种极具前景的扩展范式(Scaling Paradigm)。
更多细节请阅读原文。

