对于大型语言模型(Large Language Models, LLMs)而言,表格推理能力是其逻辑与分析能力的重要体现。目前,学界在表格问答(Table Question Answering)、事实核查(Fact Verification)以及代码生成(Text-to-SQL)等方向已取得显著进展。然而,一个在工业界具有迫切需求、却在学术研究中相对滞后的领域是表格到报告的生成(Table-to-Report Generation)。这项任务要求模型不仅能理解表格中的数据,更要能从中提炼洞见、分析趋势,并最终以一篇结构完整、逻辑清晰、观点明确的分析报告形式呈现出来。这种从结构化数据到深度分析文本的转换,对 LLMs 的综合能力提出了更高的要求。
现有的研究范式在应对这一挑战时,面临两个核心瓶颈:
-
基准(Benchmark)的缺失与错位:目前主流的表格处理基准,如
WikiSQL、TAT-QA、TableBench等,其设计目标主要集中在表格问答任务上,即根据一个具体问题从表格中定位或计算出简短的答案。它们的表格源大多来自维基百科等学术数据集,结构相对单一,规模有限。这与工业应用中常见的复杂、多表关联、超大规模的表格形态存在巨大鸿串。更重要的是,这些基准的设计初衷并非评估长篇、分析性报告的生成质量,导致它们无法有效衡量模型在 table-to-report 任务上的真实能力。 -
评估(Evaluation)的困难与片面:对于 table-to-report 任务,传统的文本生成评估指标,如
BLEU和ROUGE,显得力不从心。这类指标通过计算生成文本与参考文本之间的 n-gram 重叠度来衡量质量,但一篇高质量的分析报告允许多种有效的表达方式和逻辑组织结构,单一的参考答案无法覆盖所有可能性。因此,基于n-gram的匹配很容易错判一篇语言风格不同但分析内容同样精准的报告。另一方面,新兴的“LLM-as-a-Judge”方法虽然能更好地评估文本的流畅性和逻辑性,但在评估报告中关键的数值准确性(Numerical Accuracy)和信息覆盖度(Information Coverage)方面存在短板,难以保证报告中的每一个数据和结论都源于原始表格并准确无误。
这两个瓶颈共同构成了一个关键的研究空白:我们如何构建一个能真实反映工业界需求的基准,并设计一套能全面、准确评估模型在该任务上表现的评价体系?
来自中国电信人工智能研究院(TeleAI)、重庆大学和北京航空大学的研究者在自然语言处理顶会 EMNLP 2025 发表的长文《T2R-bench: A Benchmark for Generating Article-Level Reports from Real World Industrial Tables》,为解决这一问题提供了坚实的一步。他们提出了 T2R-bench,这是首个专注于从真实世界工业表格生成文章级报告的双语基准。

-
论文标题:T2R-bench: A Benchmark for Generating Article-Level Reports from Real World Industrial Tables -
论文链接:https://www.arxiv.org/pdf/2508.19813
该工作不仅填补了高质量、工业级 table-to-report 基准的空白,还创造性地设计了一套包含数值准确性、信息覆盖度和报告综合质量三个维度的自动化评估框架。实验结果表明,即便是当前先进的 LLMs,在 T2R-bench 上也面临巨大挑战,这为未来该领域的研究指明了方向。
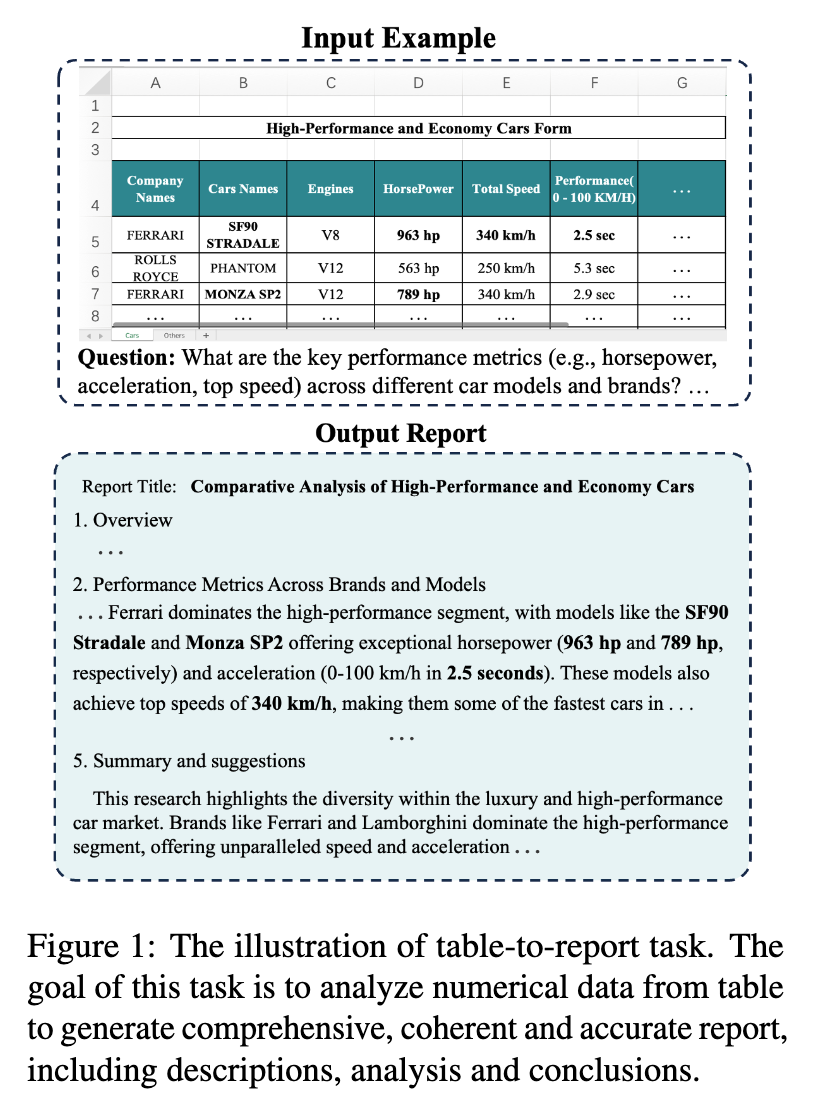
1. T2R-bench
T2R-bench 的核心价值在于其数据的真实性和任务的实用性。它旨在模拟工业数据分析师的日常工作,即将复杂的业务表格转化为具有洞察力的分析报告。其构建过程严谨,主要分为三个阶段:表格数据收集、表格问题标注和报告参考标注。
1.1 表格数据收集
为了真实反映工业场景的复杂性,T2R-bench 的数据源自公开的互联网资源,包括市政开放数据平台、国家统计局、行业协会官网以及开源表格数据集等。研究团队通过一个两阶段的筛选流程来确保数据质量:
-
初步筛选:基于行业主题进行预筛选,确保领域的覆盖面和相关性。 -
质量筛选:剔除包含乱码或单元格空值超过60%的文件,以保证表格含有足够的信息密度用于统计分析。
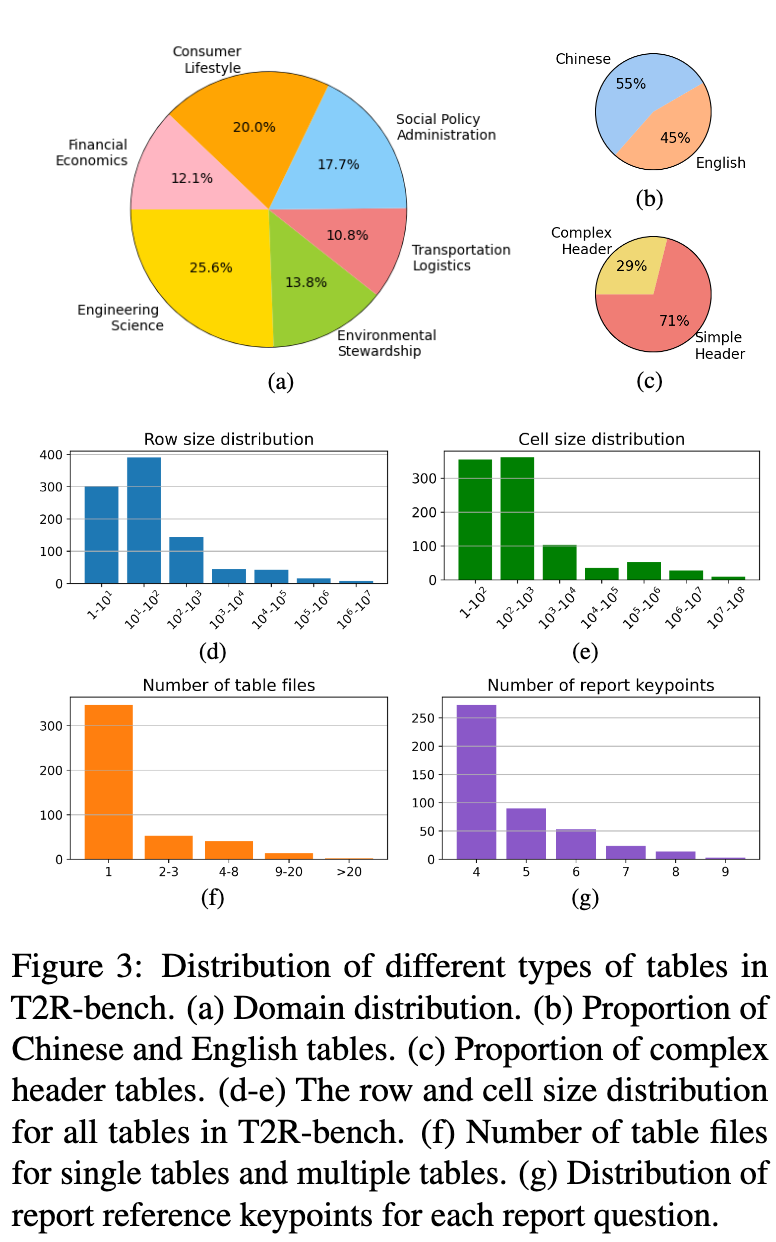
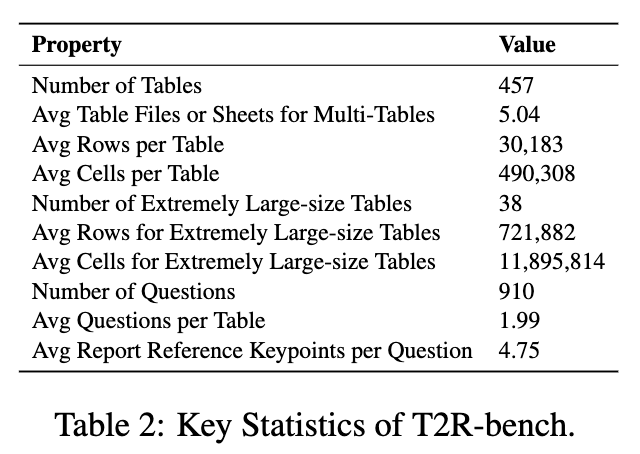
最终,T2R-bench 收集了 457 个独特的工业表格,涵盖了6个主要领域和19个二级行业类别,包括工程、制造、金融、教育、医疗、交通等。这些表格被分为中文(252个)和英文(205个)两部分,构成了一个双语基准。
与现有学术基准相比,T2R-bench 在表格类型上实现了全面的覆盖,包含了四种在工业界常见但学术基准中稀缺的表格类型:
-
单一表格(Single Tables):标准的二维表格。 -
多表(Multiple Tables):包含多个相互依赖的文件或工作表(sheets),要求模型具备跨表理解和信息整合的能力。T2R-bench 中 23.6% 的表格属于此类。 -
复杂结构表格(Complex Structured Tables):具有层级索引、合并单元格、非均匀单元格结构等特点,对模型的表格结构理解能力构成挑战。T2R-bench 中 28.9% 的表格属于此类。 -
超大规模表格(Extremely Large-size Tables):单元格数量超过5万的表格,考验模型在长上下文环境下的信息处理能力。T2R-bench 中超过 8.3% 的表格属于此类,平均行数达到72万行,平均单元格数接近1200万。
1.2 表格问题标注
为了引导 LLM 生成有深度的分析报告,每个表格都配有相应的问题。这些问题并非简单的查询,而是开放式的分析任务。研究团队采用了一种半自动化的启发式方法来生成这些问题:
-
种子问题与提示模板库构建:首先,团队雇佣了24名在数据分析和报告撰写方面具有丰富经验的标注员。他们精心设计了10个种子问题和5个多样化的提示模板。这些模板指导模型从不同角度(如趋势分析、分布特征、对比基准等)提出高质量的分析问题。
-
Self-Instruct 生成问题池:利用
GPT-4o和精心设计的提示模板,通过 Self-Instruct 方法为每个表格自动生成一个问题候选池。 -
人工标注与筛选:每个生成的问题由两名标注员根据三个标准进行独立评估和筛选:
-
表格可回答性(Tabular Answerability):问题必须仅基于表格数据就能回答,不能依赖外部知识。 -
结论聚焦性(Focused Conclusions):问题应针对单一的分析维度,以便得出明确的结论。 -
互补独特性(Complementary Uniqueness):同一表格的多个问题应探讨不同的方面,避免重复。
当两位标注员意见不一致时,由一位资深标注员进行最终裁决。通过这个严谨的流程,T2R-bench 最终获得了 910 个高质量、高信息量的分析问题。
-
1.3 报告参考标注
对于 table-to-report 任务,提供一份完整的报告作为“黄金标准”参考答案是不切实际的,因为不同分析师可能会写出风格迥异但同样高质量的报告。为了解决这个问题,研究团队提出了一个创新的概念——报告关键点(Report Keypoints)。
关键点是指一篇报告中最核心的内容的提炼,包括核心观点、分析结论、关键支撑数据和建议等。它们构成了报告的分析骨架,不受具体措辞和表达方式的影响。无论报告如何撰写,其核心的关键点应该是稳定和一致的。
基于这一理念,报告参考的标注流程设计如下:
-
报告生成:对于每个 <表格, 问题>对,使用三个不同的 LLMs 生成三份独立的分析报告。 -
关键点提取:使用 GPT-4o从每份报告中提取 5-10 个关键信息点,形成三组候选关键点。 -
人工标注与精炼:同样采用双人标注、资深仲裁的模式,对候选关键点进行审核、合并、修正和提炼。标注员确保最终的关键点准确反映了表格内容,并与分析问题紧密相关。
通过这个流程,T2R-bench 为910个问题共标注了 4,320 个报告关键点。这些关键点为后续的自动化评估(特别是信息覆盖度评估)提供了稳定可靠的基准。
2. 评估体系
T2R-bench 的另一大贡献是提出了一套全新的、自动化的评估体系,从三个互补的维度全面衡量模型生成报告的质量。
2.1 数值准确性准则 (Numerical Accuracy Criterion, NAC)
分析报告的生命线在于数据的准确性。报告中出现的任何数值——无论是直接从表格中提取的,还是经过计算(如求和、平均)得出的——都必须绝对准确。NAC 的设计目的就是为了检验这一点。其实现流程如下:
-
数值语句提取:首先,使用 NLTK(英文)和Jieba(中文)对生成的报告进行分句。然后,通过正则表达式提取所有包含数值(整数或浮点数)的句子或句子簇。 -
逆向问题生成:将提取出的数值语句作为“答案”,逆向生成一个验证性问题。例如,如果报告中写道“A部门的总销售额为5,280万元”,则逆向生成的问题是“A部门的总销售额是多少?”。 -
代码生成与执行:将逆向生成的问题、原始表格数据一同输入给三个专门用于代码生成的 LLMs( Qwen2.5-32B-Coder-Instruct、Deepseek-Coder、CodeLlama-70B-Instruct)。这三个模型会生成 Python 代码来从表格中计算答案。 -
共识机制:执行生成的代码,并采用多数投票机制来确定最终的计算结果。至少需要两个模型达成一致,不一致的结果(包括代码执行失败)将被丢弃,以减少噪声。 -
分数计算:最后,将代码计算出的结果与报告中原始的数值进行比较。如果一致,则该数值语句被认为是准确的。NAC 分数是所有数值语句中准确语句的比例。
这个流程通过代码执行的方式,为报告中的每一个数值声明提供了基于表格源数据的“硬核”验证,从而保证了评估的客观性和可靠性。
2.2 信息覆盖度准则 (Information Coverage Criterion, ICC)
一篇好的报告不仅要数据准确,还要能全面地覆盖分析任务所要求的核心信息。ICC 旨在量化生成报告与参考“报告关键点”之间的语义对齐程度。其灵感来源于机器翻译评估中互信息(Mutual Information, MI)的应用。
具体计算过程如下:
假设生成的报告被切分为 个句子簇 ,而参考的关键点集合为 。
-
构建语义相似度矩阵:使用 BERTScore计算每个句子-关键点对 之间的语义相似度,得到一个 的相似度矩阵 ,其中元素 。 -
计算联合概率和边缘概率:基于相似度矩阵 ,可以估算出联合概率 以及边缘概率 和 :
-
计算归一化互信息:ICC 被定义为归一化的互信息(Normalized Mutual Information, NMI)。互信息 的计算公式为:
为了消除关键点数量不同带来的影响,使用关键点的信息熵 对其进行归一化,得到最终的 ICC 分数:
ICC 的取值范围在 之间。分数越高,表明生成的报告在语义上更好地覆盖了所有的参考关键点。
2.3 综合评估准则 (General Evaluation Criterion, GEC)
除了数值准确性和信息覆盖度这两个“硬”指标外,报告的整体质量,如逻辑性、可读性、洞察深度等,同样重要。GEC 采用 LLM-as-a-Judge 的方法,对报告进行综合性的“软”评估。
研究团队借鉴了长文本生成的评估方法,确定了五个最能有效区分报告质量的维度:
-
推理深度(Reasoning Depth):分析是否超越了表面观察,揭示了数据背后的深层机制或原因。 -
人类化风格(Human-like Style):语言风格是否自然流畅,像人类专家撰写,而非机器生成的刻板文本。 -
实用性(Practicality):分析和建议是否具有实际可行性,能否为决策提供有价值的参考。 -
内容完整性(Content Completeness):是否全面地覆盖了当前状况和未来机会,是否存在明显的分析盲点。 -
逻辑连贯性(Logical Coherence):报告结构是否清晰,论点之间衔接是否自然,结论是否从证据中合乎逻辑地导出。
评估时,一个作为“裁判”的 LLM 会根据这五个维度对生成的报告进行打分,最终的 GEC 分数是这五个维度分数的平均值。
这三个准则(NAC、ICC、GEC)共同构成了一个多维度、互为补充的评估框架,使得对 table-to-report 任务的评估既有对事实准确性的严格把控,也有对内容覆盖度和文本质量的全面考量。
3. 实验
研究团队在 T2R-bench 上对 25 个当前主流的 LLMs 进行了全面的评估,包括开源模型(如 Qwen 系列、Llama 系列、Deepseek 系列、Mistral 等)和闭源模型(如 GPT 系列、Claude-3.5-Sonnet、豆包、Moonshot 等)。
3.1 总体性能分析
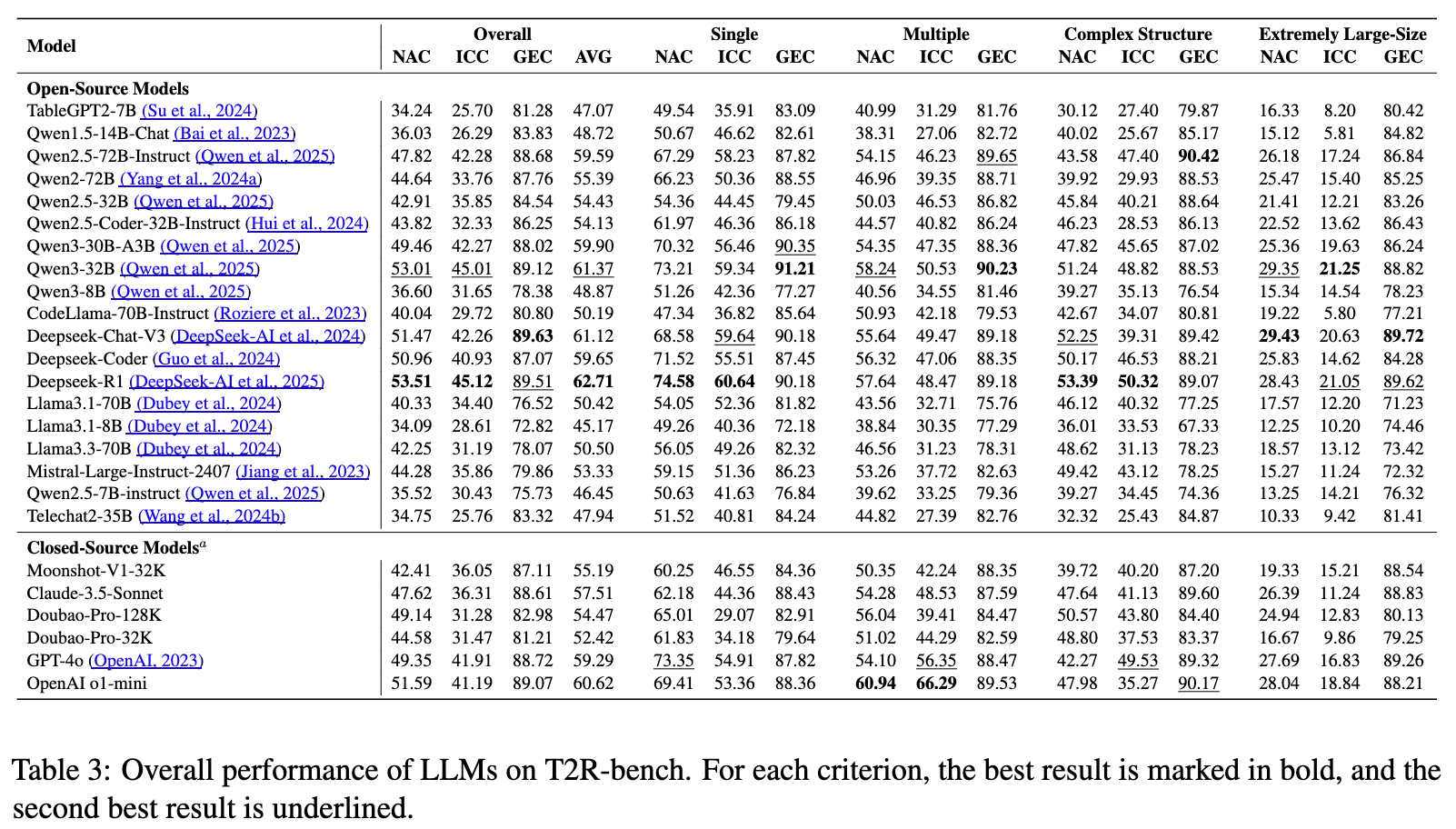
实验结果揭示了几个重要的发现:
-
Deepseek 系列表现突出:在所有被评估的模型中, Deepseek-R1取得了 62.71% 的最高平均分,在单一表格、多表和复杂结构表格任务上均表现出较强的综合能力。这显示了其在表格到报告生成领域的领先地位。 -
数值计算能力分化: Qwen3-32B在 NAC(数值准确性)上得分最高,甚至超过了规模更大的Qwen2.5-72B-Instruct,展示了其优异的数值计算和推理能力。 -
跨表理解能力是瓶颈:实验观察到,大多数模型在从单一表格任务过渡到多表任务时,性能出现显著下降。例如,GPT 系列在多表任务上的 ICC 分数(66.29%)相对较高,但整体性能下降明显,这表明跨表格的信息整合与理解仍然是一个普遍的挑战。 -
超大规模表格构成严峻挑战:在处理超大规模表格时,所有模型的性能都出现了急剧下滑。这可能是由于长上下文窗口的限制导致信息被截断,或是模型在海量数据中进行有效推理的能力不足。
即便是表现最好的 Deepseek-R1,其总体得分也仅为 62.71%,其中 NAC 和 ICC 两项关键指标均低于65%。这清晰地表明,当前最先进的 LLMs 在满足真实世界 table-to-report 任务的需求方面,仍有巨大的提升空间。
3.2 表格大小对性能的影响分析
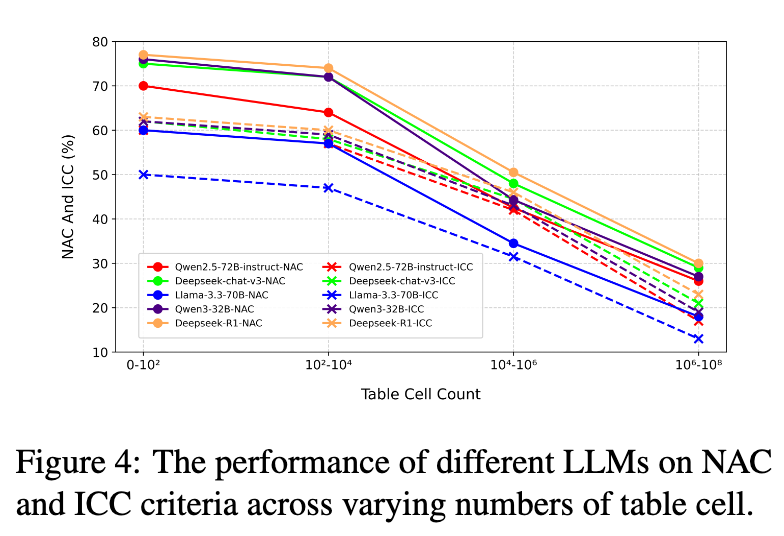
为了进一步探究模型处理长上下文的能力,研究团队分析了输入表格的单元格数量对模型性能的影响。如图 4 所示,随着表格大小的增加,所有被评估的 LLMs 在 NAC 和 ICC 上的性能都呈现出明显的下降趋势,尤其是在处理超大规模表格时,性能衰减尤为严重。这一发现首次在表格相关的基准测试中提供了实证证据,证明了当前模型在理解和处理大规模、复杂结构化数据方面存在根本性的局限。
3.3 人工评估验证
为了验证所提出的自动化评估体系的可靠性,研究团队进行了一项人工评估。他们随机抽取了50个问题,并招募了6位有丰富数据分析经验且未参与基准构建的专家来撰写报告,作为“人类基线”。同时,另外6位独立的标注专家对5个代表性 LLM 生成的报告以及人类撰写的报告,按照 NAC、ICC、GEC 的标准进行打分。
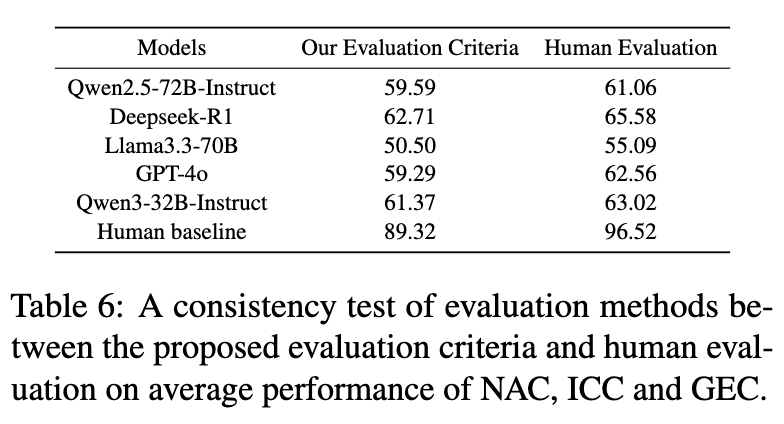
结果显示,自动化评估指标与人类专家的判断表现出高度的一致性,皮尔逊相关系数(Pearson's r)达到了 0.908。这充分证明了 T2R-bench 提出的 NAC、ICC、GEC 评估框架是可靠和有效的,尽管其打分标准比人类评估更为严格(导致绝对分数偏低)。
3.4 案例分析与错误分析
通过对50个随机错误案例的手动分析,研究团队揭示了 LLMs 在 table-to-report 任务中面临的持续性挑战。
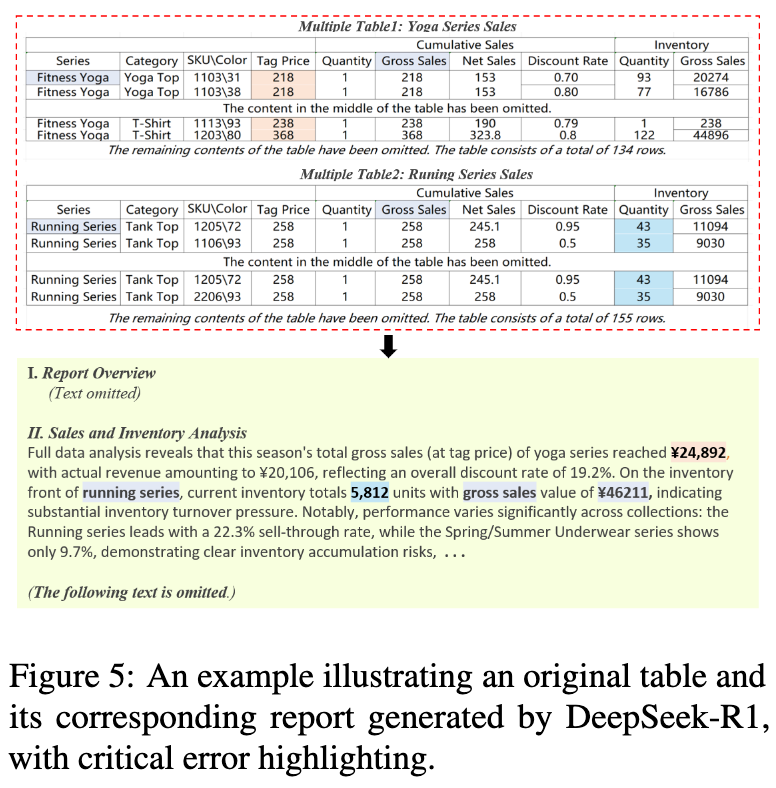
如图 5 所示,即使是表现最好的 Deepseek-R1,在处理多表任务时也出现了严重错误:
-
数值幻觉(Numerical Hallucination):例如,错误地计算了表1中“Tag Price”的总和。 -
表格选择错误(Table Selection Error):例如,错误地引用了表1而非表2的“Gross Sales”数据。
这些错误,连同由复杂表格结构、描述性幻觉和多变的误解所带来的挑战,揭示了尽管模型能生成表面上流畅、类似人类的报告,但其深层推理能力仍存在根本性的局限。
错误分析统计显示,主要的错误类型包括:截断错误(25%)、数值事实错误(22%)、生成错误(20%)、关键点缺失(17%)和表格结构理解错误(16%)。这些错误直接导致了 NAC 和 ICC 分数的降低。
总结
T2R-bench 的提出,为“表格到报告生成”这一重要而又被忽视的研究领域,提供了一个坚实的基石。它不仅是第一个源于真实工业场景、覆盖多种复杂表格类型的双语基准,更重要的是,它带来了一套全面、可靠、自动化的评估框架。通过数值准确性(NAC)、信息覆盖度(ICC)和综合质量(GEC)三个维度的协同评估,研究者可以更精准地诊断模型的能力短板。
在 T2R-bench 上的大量实验清晰地揭示了当前大型语言模型的能力边界。即便最强大的模型,在面对真实世界的复杂表格和分析需求时,其表现也远未达到理想状态,尤其是在跨表推理、大规模数据处理和保证数值准确性方面。
这项工作也指出了未来的研究方向。论文中提到的局限性,本身就是未来工作的起点:
-
扩展基准:需要将 T2R-bench 扩展到更多样化的表格类型和行业领域,以更全面地覆盖工业界的需求。 -
发展专用模型:当前的通用 LLMs 在此任务上表现不佳,这凸显了为 table-to-report 任务设计专门模型的必要性。未来的研究可以探索如何通过特定的架构设计或预训练任务,来增强模型对结构化数据的深度理解和分析报告的生成能力。
往期文章:


