大模型(LLMs)如今这么强了,如何实现可持续的自我进化?
现有的无标签学习方法,如最小化置信度不确定性、或基于自洽性(self-consistency)的多数投票(majority-vote)机制,为这个问题提供了一些初步的解决方案。这些方法通过内在信号来稳定学习过程,例如,一个被多次独立生成的答案更有可能是正确的。然而,这些方法也暴露出了一个深层次的困境。它们在追求“稳定”的同时,往往会系统性地扼杀模型的“探索”能力,导致一种被称为“熵坍塌”(Entropy Collapse)的现象。具体来说,模型会逐渐倾向于生成更短、更多样性更低、更“安全”的回答,其思维链条(Chain of Thought)变得越来越趋同和脆弱。这种模式下的“学习”更像是一种短视的“适应”(Adaptation),模型只是在当前任务上找到了一个局部最优解,却以牺牲其通用性、鲁感性和解决更广泛问题的潜力为代价。长此以往,模型非但没有进化,反而陷入了退化。
这个困境反映了探索(Exploration)与利用(Exploitation)这一强化学习中的经典难题,在无标签的语言模型自进化场景下变得尤为严峻。如何在没有外部奖励指引的前提下,既能利用内在的一致性信号来巩固已有的正确认知,又能有效鼓励模型探索新的、潜在更优的解决方案,防止其陷入思维的“死胡同”?
来自腾讯 AI Lab、圣母大学和弗吉尼亚大学的研究者们在 arXiv 上提交的论文《Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation》正面回应了这一挑战。他们提出了一个名为“面向进化的无标签强化学习”(EVolution-Oriented and Label-free Reinforcement Learning, EVOL-RL)的框架。该工作的核心思想借鉴了生物进化中最基本也是最强大的法则:选择(Selection)与变异(Variation)。它不再单纯地依赖多数投票,而是将其与一个新颖性奖励(Novelty Reward)巧妙地结合起来,从根本上改变了模型在无标签数据中学习的动态过程。它让模型在通过“多数”来确定正确方向(选择)的同时,通过奖励“新颖”的思考过程来维持种群多样性(变异),从而成功地摆脱了熵坍塌的陷阱,实现了真正意义上的能力进化。

-
论文标题:Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation -
论文链接:https://arxiv.org/pdf/2509.15194
1. 熵坍塌
为了理解 EVOL-RL 的设计动机,我们首先需要深入剖析现有无标签学习方法,特别是基于多数投票的 Test-Time Reinforcement Learning (TTRL) 等方法的内在缺陷。
1.1 多数即正确?
在没有标准答案的情况下,我们如何判断一个模型的输出是否正确?一个直观且被广泛应用的思想是“群众的智慧”,即自洽性原则。如果模型针对同一个问题,在多次独立的生成尝试中(例如,使用不同的随机种子或较高的 temperature),反复得到同一个答案,那么这个答案是正确的概率就比较大。TTRL 等方法正是基于这个原理:它们在推理时对一个问题进行多次“rollout”,生成一组候选答案,然后将获得最多票数的答案(即“多数答案”)视为“伪标签”(pseudo-label)。接着,模型会通过强化学习的方式,奖励那些生成了多数答案的轨迹,惩罚那些生成了少数答案的轨迹。
这个机制在初期是有效的。它提供了一个清晰的学习信号,引导模型向着内部一致性更高的方向收敛,从而提升了单次回答的准确率(即 pass@1 指标)。
1.2 稳定性的代价:多样性的丧失与熵的衰减
然而,这种“多数即正义”的奖励机制,如果被单一地、持续地使用,就会带来灾难性的副作用。这个过程可以描述如下:
-
信号的均质化:在 TTRL 框架下,所有生成了多数答案的响应,无论其推理过程是精妙还是笨拙,是另辟蹊径还是陈词滥调,都会收到相同的、正向的奖励。同样,所有非多数答案的响应也会收到相同的、负向的惩罚。在经过强化学习中常用的 z-score 标准化后,所有多数答案拥有完全相同的正优势(advantage),而所有少数答案拥有完全相同的负优势。 -
概率质量的集中:在策略更新时,模型会根据优势信号来调整其生成概率分布。由于所有多数解的优势相同,概率质量会均匀地流向当前所有已知的、能够导出多数答案的推理路径。这个过程不断迭代,模型的概率分布会迅速地向一个狭窄的、高置信度的区域收缩。 -
熵坍塌的出现:最终,模型学会了只用少数几种,甚至一种“最安全”的方式来解决问题。它不再愿意去探索其他可能性。这种现象在多个可观测的指标上都有体现: -
策略熵(Policy Entropy)下降:衡量模型输出不确定性的策略熵急剧降低,表明模型的输出变得高度确定和单一。 -
pass@k指标恶化:pass@k衡量模型在k次尝试中至少有一次答对的概率,是评估模型解题能力广度的重要指标。当模型只会用一种方式思考时,如果这种方式恰好是错的,或者在某些问题上不适用,那么无论尝试多少次,它都无法找到正确答案。因此,我们常常观察到pass@1略微提升或持平,但pass@k却断崖式下跌的现象。 -
响应长度和复杂度的缩减:模型倾向于生成更短、更公式化的推理步骤,因为这是达到多数答案的“捷径”。复杂而详尽的推理过程,即使同样能得到正确答案,也不会获得额外的奖励,反而因为路径更长而可能在生成过程中引入更多不确定性,因此在优化的过程中被逐渐“淘汰”。
-
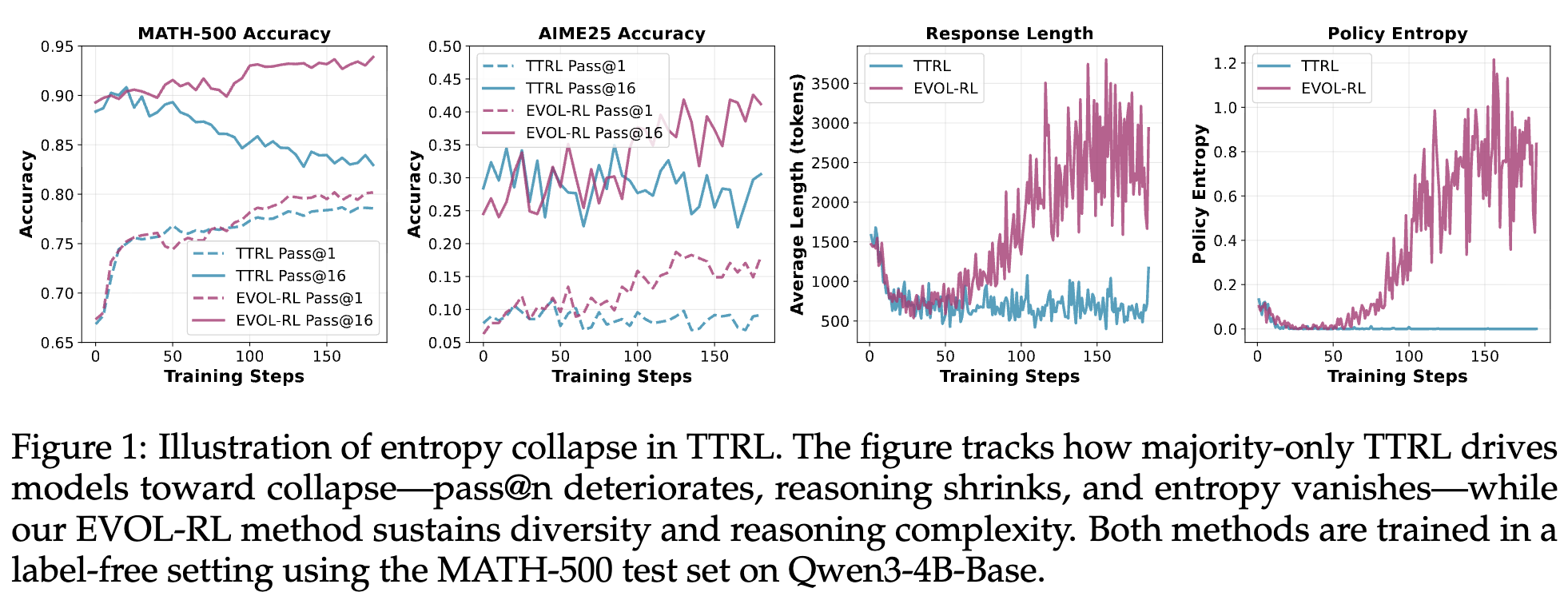
如论文图 1 所示,在使用 TTRL 对 Qwen3-4B-Base 模型进行训练时,pass@k 指标(图中 TTRL Pass@16)随着训练步数的增加而持续下降,响应的平均长度显著缩短,策略熵也迅速趋近于零。这清晰地描绘了熵坍塌的全过程。模型虽然在“利用”已知的解法上变得更加稳定,却彻底丧失了“探索”新解法的能力,最终陷入了能力的退化。
这种现象不仅仅是“过拟合”到当前的无标签数据集,而是一种更深层次的“模式坍塌”(mode collapse)。模型的能力被“锁定”在一个狭小的子空间内,无法泛化到域外(Out-of-Domain, OOD)问题,也失去了持续学习的潜力。作者将这种仅在当前任务上取得狭隘收益,但牺牲了更广泛能力的现象定义为适应(Adaptation),并将其与能够带来广泛、通用能力提升的进化(Evolution)区分开来。显然,我们的目标是后者。
2. 选择与变异
如何打破熵坍塌?EVOL-RL 的作者们从生物进化论中找到了灵感。生物界的进化,并非一个单向的“优胜劣汰”过程,而是两个核心机制协同作用的结果:
-
选择(Selection):在自然选择的压力下,能够适应环境的个体(及其基因)更有可能存活下来并繁衍后代。这个机制确保了“有效”的性状能够被保留和巩固,对应于机器学习中的“利用”过程。它防止了种群在随机漂变中迷失方向。 -
变异(Variation):通过基因突变、重组等方式,种群中会不断产生新的性状。变异是进化的原材料,为选择机制提供了新的可能性。它对应于机器学习中的“探索”过程。没有变异,进化就会停滞,种'群将无法适应变化的环境。
进化算法(Evolutionary Computation)、新颖性搜索(Novelty Search)和质量-多样性(Quality-Diversity)算法等领域的研究早已证明,单纯依赖选择压力会导致“过早收敛”(premature convergence),即算法过快地收敛到一个局部最优解。只有显式地保护和鼓励行为多样性(behavioral diversity),才能实现鲁棒和持续的进步。
TTRL 的失败,正是在于它只实现了“选择”(通过多数投票),而完全忽略了“变异”。它的奖励机制不仅没有鼓励变异,反而在主动地惩罚和消除那些与主流思维不同的“少数派”路径,即使其中一些少数派路径是正确的,或者包含了通往未来更优解的“基因片段”。
基于此,EVOL-RL 提出:构建一个同时包含“选择”和“变异”双重激励的奖励函数,在无标签的设定下模拟进化的核心动态。
3. EVOL-RL
EVOL-RL 继承了 TTRL 的基本流程,即对每个问题生成多个响应,并以此为基础进行强化学习更新。但其灵魂在于对奖励机制的彻底重新设计。它建立在 Group Relative Policy Optimization (GRPO) 算法之上,并通过一个奖励函数来引导模型的进化。
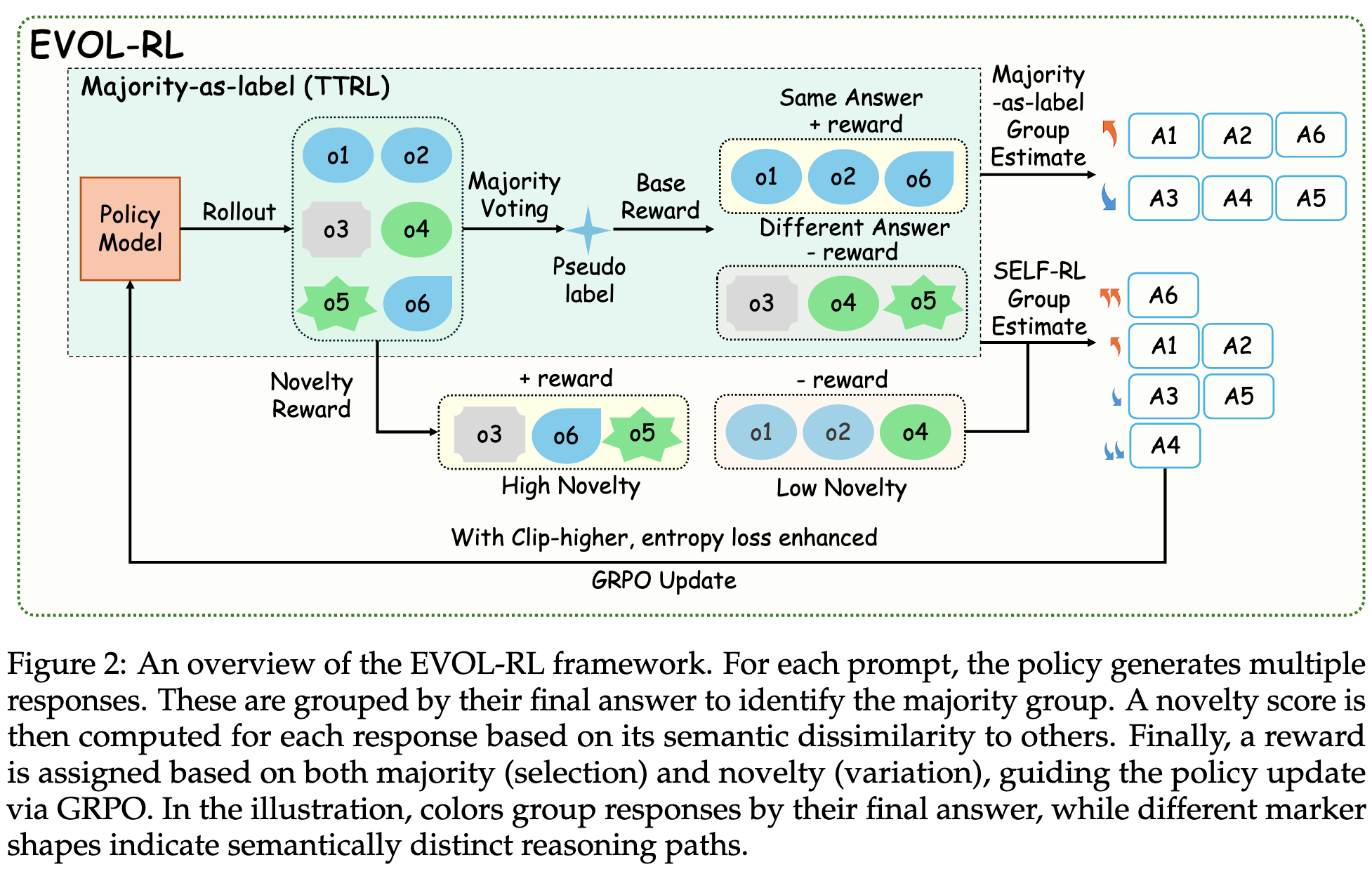
3.1 整体流程
-
Rollout 阶段:对于一个给定的 prompt,模型(policy)会生成 G个独立的、完整的响应。 -
分组与奖励计算: -
首先,从每个响应中提取最终答案,并通过多数投票确定“多数答案”。 -
所有响应根据其答案是否与“多数答案”一致,被分为多数组(Majority Group)和少数组(Minority Group)。 -
然后,计算每个响应的新颖性得分(Novelty Score),这个得分衡量了该响应的推理路径与其他响应的语义差异程度。 -
最后,结合分组信息(选择信号)和新颖性得分(变异信号),为每个响应计算一个最终的奖励值。
-
-
策略更新:使用 GRPO 算法,根据计算出的奖励来更新模型参数。GRPO 是一种无需独立价值函数的策略梯度算法,它通过比较一个响应与同组其他响应的相对奖励来计算优势,从而进行策略更新。
3.2 奖励设计的双重核心:选择与变异
EVOL-RL 奖励函数的设计是其成功的关键。它将一个响应的价值分解为三个维度进行评估:
1. 有效性(Validity)
这是一个基础的过滤器。响应必须包含一个特定格式的、可解析的数值答案(例如,在 \boxed{} 中)。任何不满足此条件的响应都会被视为无效,并获得一个固定的最低奖励(如 -1)。
2. 多数性(Selection)
这是一个二元标签 ,用于标识一个响应的答案是否是多数结果。这是 EVOL-RL 的选择信号。
3. 新颖性(Variation)
这是 EVOL-RL 的变异信号,也是其与 TTRL 的根本区别所在。新颖性得分 的计算方式如下:
-
推理路径嵌入:首先,提取每个响应中除最终答案之外的推理过程,并使用一个预训练的嵌入模型(如 Qwen3-4B-Embedding)将其转换为一个向量表示。 -
计算语义相似度:对于每个响应 ,计算其推理路径嵌入与其他响应的两个关键相似度指标: -
组内平均相似度 :计算 与其同组内(即同为多数组或同为少数组)其他所有响应的平均余弦相似度。之所以在组内计算,是因为多数解和少数解的推理路径在语义上通常相距甚远,全局平均会被这种组间差距主导,从而掩盖了组内的细微差异。 -
全局最大相似度 :计算 与整个批次中任何其他单个响应的最大余弦相似度。
-
-
计算新颖性得分 :最终的新颖性得分被定义为:
其中 是一个超参数(默认为 0.5)。这个公式巧妙地惩罚了两种形式的冗余:高的 意味着响应的推理过程趋于其所在群体的“平均水平”,缺乏独特性;高的 意味着该响应与批次中的某个其他响应几乎是“复制品”。因此,一个高新颖性的响应,既要做到与群体均值不同(局部多样性),也要做到不与任何其他个体雷同(全局多样性)。 -
组内归一化:最后,得到的新颖性得分 会在多数组和少数组内部进行独立的 min-max 归一化,得到最终的 。这一步至关重要,它确保了新颖性的比较是在“同类”之间进行的,使得多数组中的“异类”和少数组中的“异类”可以得到公平的评估。
3.3 最终奖励
有了选择信号()和变异信号(),EVOL-RL 通过一个非重叠的奖励区间映射来合成最终奖励 :
这个分段函数的设计体现了 EVOL-RL 的核心权衡:
-
选择永远优先:注意到,即使是新颖性最低的多数解(),其奖励也恒高于新颖性最高的少数解()。这个结构保证了“正确性”(由多数定义)的信号强度永远压过“新颖性”。模型的主驱动力始终是找到多数答案。 -
新颖性在组内起决定作用:在多数组内部,奖励与新颖性成正比。这激励模型在已经找到正确答案的前提下,去探索多种不同的、有效的推理路径,直接对抗 pass@k的下降。对于少数组,奖励虽然是负的,但高新颖性的少数解受到的惩罚更小。这鼓励模型不要陷入少数几种常见的错误模式,而是去探索更广阔的、未知的推理空间,这增加了它偶然发现一个全新的、正确的解决方案的概率。
3.4 辅助机制
除了核心的奖励设计,EVOL-RL 还引入了两个辅助机制来进一步强化其效果:
-
非对称裁剪(Asymmetric Clipping):在 GRPO 的目标函数中,使用了一个非对称的裁剪范围 ()。这意味着,对于那些具有很高优势的、稀有且新颖的响应,它们的梯度信号可以被更大程度地保留,而不会被 PPO-style 的裁剪过早地限制住,从而加速了对新发现的优质解的学习。 -
熵正则化(Entropy Regularizer):在损失函数中加入了一个 token 级别的熵正则项。这个机制旨在维持生成过程中的初始多样性,确保在训练初期,模型不会因为多数信号的强大引导而过快地失去探索能力。它为新颖性奖励机制提供了一个持续的、多样化的“候选池”。
4. 训练过程
EVOL-RL 的设计在理论上避免了熵坍塌,其实际训练过程的动态也清晰地验证了这一点。
为什么纯多数信号必然导致坍塌?
如前所述,纯多数奖励将所有多数解视为等同,导致概率质量无差别地涌向所有已知正确路径的集合。这是一个正反馈循环,每一次更新都使这个集合的边界更加清晰和狭窄,最终将概率分布压缩到一个点,导致熵坍塌。
EVOL-RL 如何打破循环?
EVOL-RL 通过新颖性奖励,在多数解的集合内部制造了“奖励势差”。
-
信用的重新分配:靠近“密集聚落”(即推理路径相似的解)的解,其新颖性低,奖励也相对较低。而处于“无人区”的、语义上独特的解,即使数量稀少,也能凭借高新颖性获得高奖励。 -
持续的抗坍塌压力:这种机制创造了一种持续的压力,推动概率质量从密集的、陈旧的解法区域,流向稀疏的、新颖的解法区域。模型被激励去“填补”其解法空间中的空白。 -
坍塌状态的不稳定性:在一个已经坍塌的状态下,大部分生成的样本都是高度相似的复制品。根据 EVOL-RL 的奖励设计,这些复制品会获得极低的新颖性得分。此时,任何偶然产生的、哪怕只有一丝不同的响应(由于随机性,这种响应总会以一定概率出现),都会获得一个极高的新颖性得分,从而得到巨大的相对优势。在随后的策略更新中,模型会迅速将概率质量从复制品上移开,转向这个新的方向。因此,一个完全坍塌的状态在 EVOL-RL 的动力学下是不稳定的不动点,系统会自动从中“逃逸”。
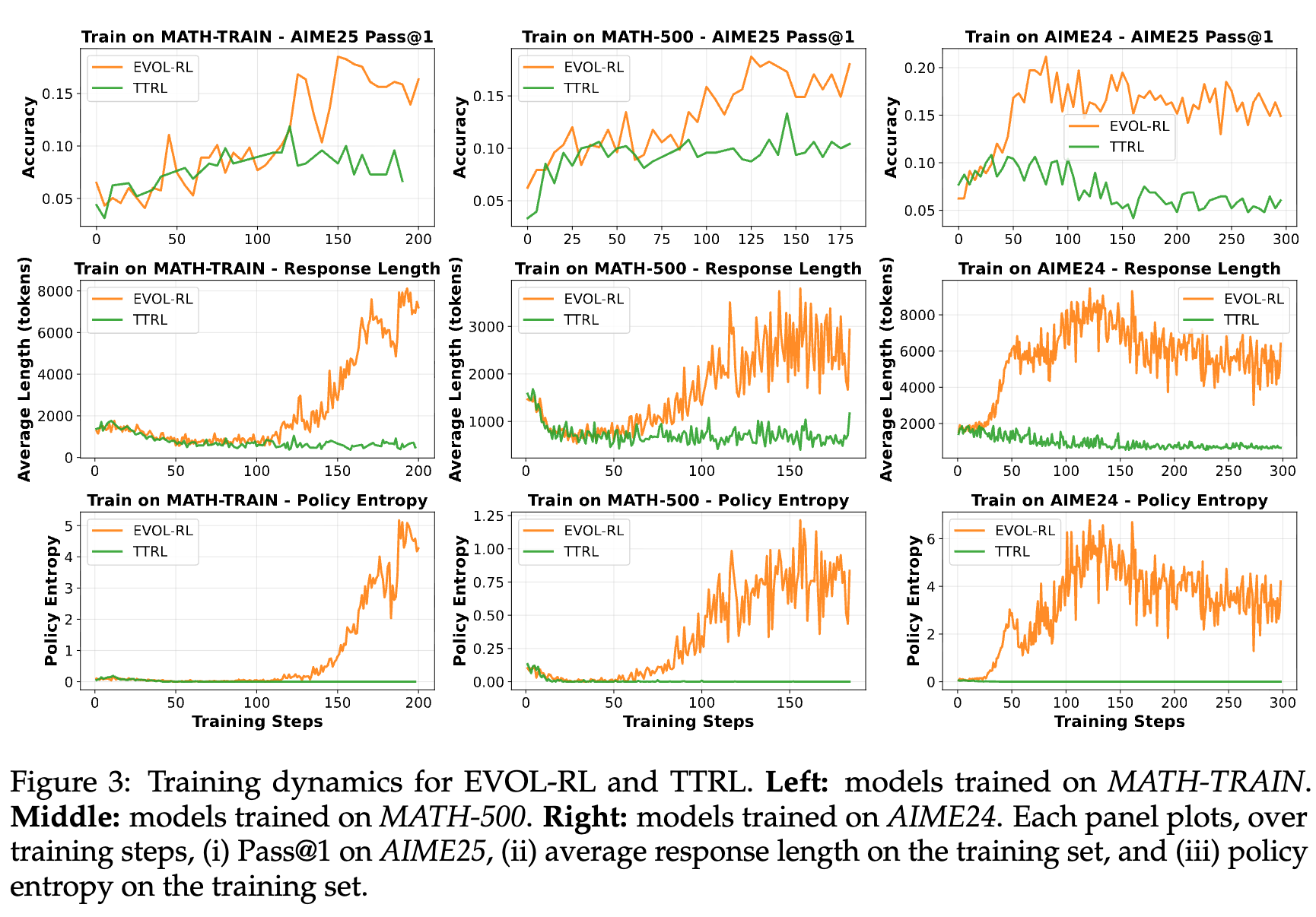
论文图 3 对比了 EVOL-RL 和 TTRL 在不同训练集上的动态过程,揭示了一个清晰的两阶段模式:
-
阶段一:初始坍塌。在训练初期,两种方法都表现出相似的行为:策略熵和响应长度急剧下降。这说明,强大的多数信号在开始时占据主导,迅速将模型推向一个初步的、收敛的状态。对于 TTRL,这个状态是终点,它被永久地困在了这个低熵的陷阱里。 -
阶段二:进化点与协调恢复。对于 EVOL-RL,在经历短暂的初始坍塌后,一个关键的“进化点”(Evolving Point)会出现。在此之后,它的轨迹与 TTRL 彻底分道扬镳。我们能观察到所有关键指标的协同复苏:策略熵开始从接近零的水平反弹,响应的平均长度开始回升,域外测试集(如 AIME25)的准确率也随之稳步攀升。
这个“进化点”的出现,标志着由新颖性奖励、熵正则化和非对称裁剪协同积累的“探索信号”达到了一个临界阈值,足以克服初始的坍塌趋势,将模型从单峰分布的“陷阱”中拉出,推向一个支持多样化、鲁棒推理的多峰分布状态。
5. 实验
EVOL-RL 的优越性不仅停留在理论层面,更在广泛的实验中得到了充分的验证。研究者们在 Qwen3-4B-Base 和 Qwen3-8B-Base 两个模型上,使用不同规模和难度的数学推理数据集(如大规模的 MATH-TRAIN,小而精的 MATH-500 和竞赛级的 AIME24)进行了无标签训练,并在包括 AIME24, AIME25, MATH500, AMC, 以及跨领域的 GPQA 在内的五个基准上进行了评测。
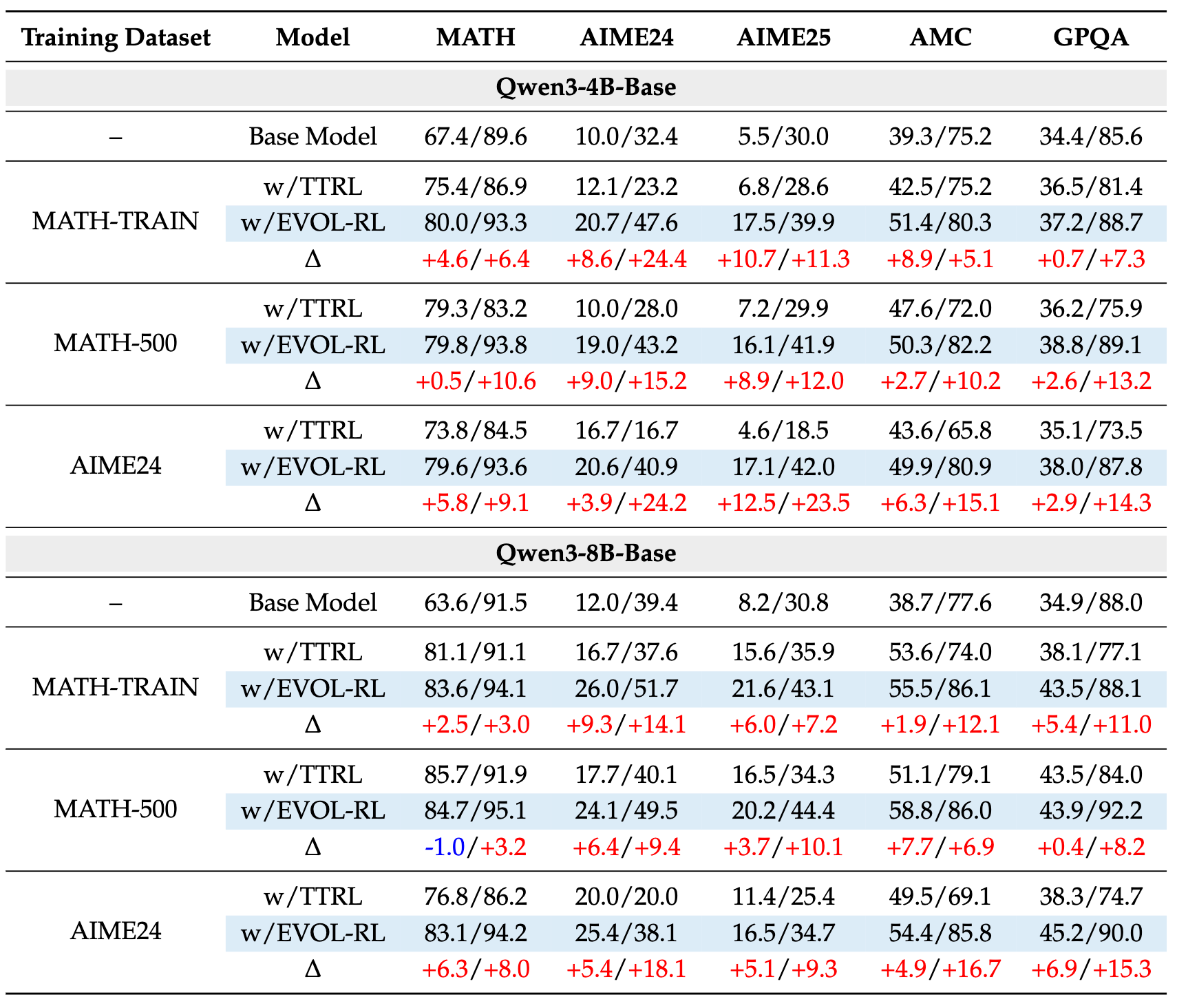
5.1 主要发现
-
pass@1和pass@16的双重提升:与 TTRL 常常牺牲pass@16来换取pass@1的微弱提升不同,EVOL-RL 在所有实验设置中都实现了pass@1和pass@16的显著、一致的提升。例如,在 AIME24 数据集上训练 Qwen3-4B 模型后,EVOL-RL 在 AIME25 测试集上的pass@1从 TTRL 的 4.6% 提升至 16.4%,pass@16从 18.5% 提升至 37.9%。这有力地证明了 EVOL-RL 不仅提升了单次求解的准确性,更极大地拓展了模型的解题思路广度。 -
跨模型规模和数据规模的鲁棒性:无论是在 4B 还是 8B 的模型上,也无论是在大规模的 MATH-TRAIN 数据集还是在小规模的 AIME24 数据集上进行训练,EVOL-RL 都展现出了稳定的优越性。这表明,其“选择+变异”的核心机制是一种普适的、可扩展的改进,而非依赖于特定的模型或数据条件。
-
强大的跨任务泛化能力:EVOL-RL 展现了出色的泛化能力。例如,仅在 MATH-500 上训练的 4B 模型,其在更难的 AIME24 和 AIME25 benchmark 上的
pass@16表现,与直接在 AIME24 上训练的效果相当。这说明 EVOL-RL 学习到的是更底层的、可迁移的数学推理能力,而非针对特定数据集的“过拟合”。 -
在非数学任务上的稳健表现:更有说服力的是,EVOL-RL 的优势延伸到了数学领域之外。在 GPQA(一个研究生水平的、需要复杂推理的问答基准)上,TTRL 训练后的模型性能相比基线模型甚至会出现下降。而 EVOL-RL 不仅扭转了这一颓势,还取得了比基线模型更高的性能,在
pass@16上比 TTRL 高出 7 到 15 个百分点。这表明,EVOL-RL 培育的通用推理能力,可以有效地迁移到不同的领域。
5.2 消融研究
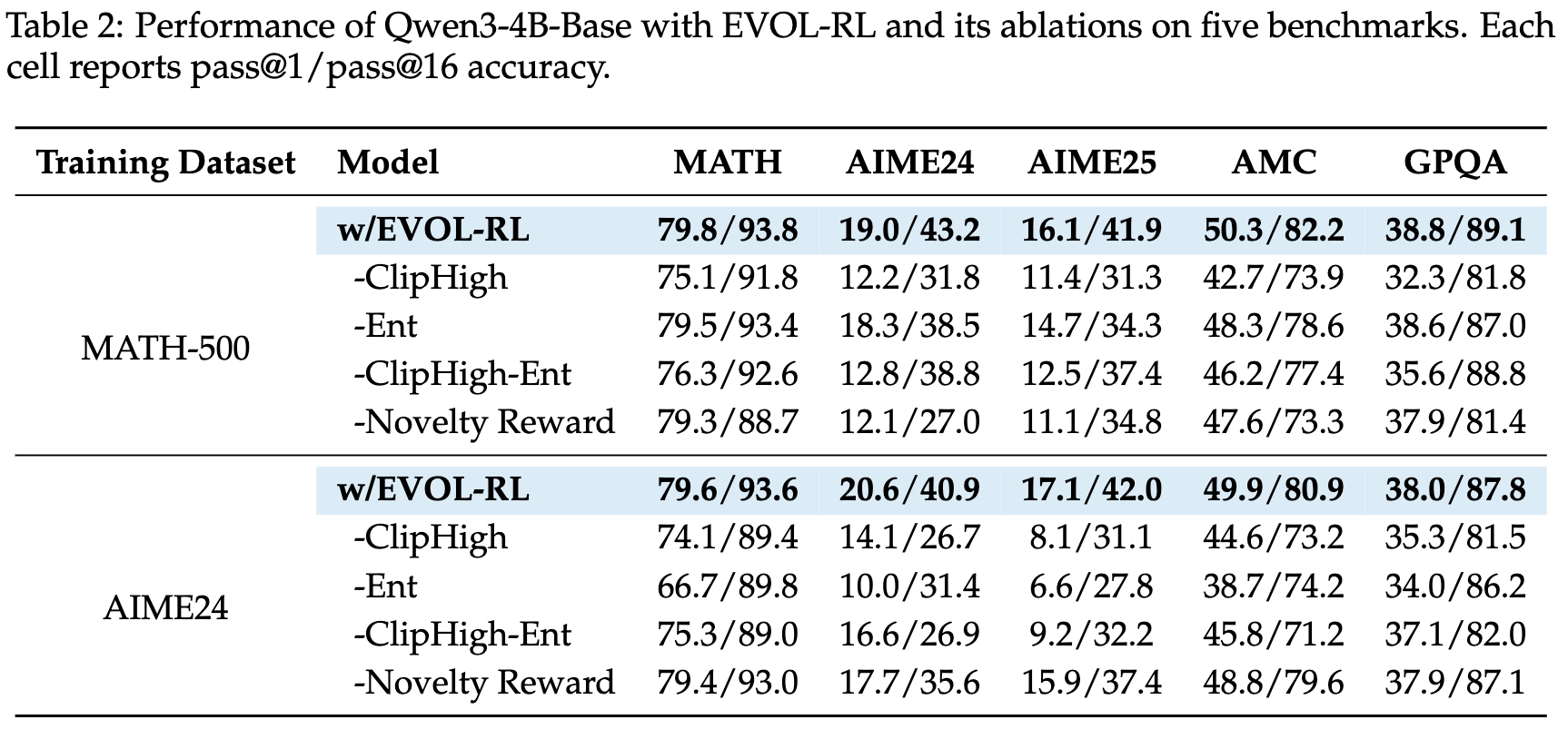
通过系统性地移除新颖性奖励、熵正则化和非对称裁剪这三个关键组件,消融实验揭示了它们之间的协同作用。
5.3 在RLVR中的应用
研究者们还将 EVOL-RL 的三个探索增强组件(新颖性奖励、熵正则化、非对称裁剪)应用到了标准的、有监督的 RLVR 训练中。结果发现,这些组件的加入同样能显著提升模型的性能,特别是在具有挑战性的域外泛化任务上。
往期文章:


