
-
论文标题:Reinforcement Learning via Self-Distillation -
论文链接:https://arxiv.org/pdf/2601.20802
TL;DR
昨天我们解读了 Self-Distillation Enables Continual Learning (SDFT) ,其核心思想是利用大模型强大的 In-Context Learning (ICL) 能力,通过专家示例构建一个“自我教师”,从而将 Offline 的示例转化为 On-Policy 的训练信号,实现了无遗忘的持续学习。
今天这篇由 ETH Zurich、MPI 等机构联合发布的 Reinforcement Learning via Self-Distillation (SDPO) ,可以看作是这一“自蒸馏”思想在 强化学习 (RL) 领域的进阶延伸与变体。如果说 SDFT 是利用 ICL 让模型“模仿正确的示例”(前瞻),那么 SDPO 则是利用 ICL 让模型“反思错误的反馈”(回顾)。
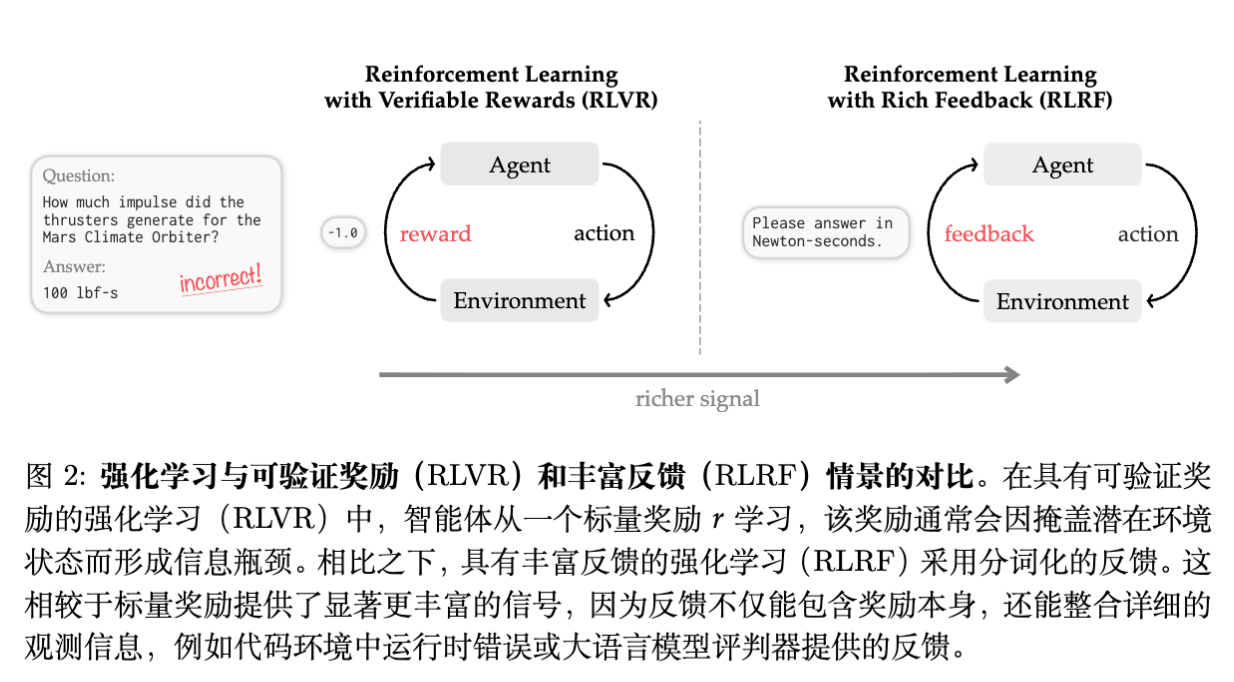
传统的 RLVR(Reinforcement Learning with Verifiable Rewards)方法(如 GRPO)通常仅依赖稀疏的标量奖励(pass/fail),忽略了编译器报错、测试用例输出等富文本反馈(Rich Feedback)。SDPO 将这种富文本反馈形式化为 RLRF (Reinforcement Learning with Rich Feedback) ,利用模型自身的上下文学习(In-Context Learning)能力,将当前策略(Policy)作为“自我教师”(Self-Teacher)。通过将包含了反馈信息的 Teacher 的 token 级概率分布蒸馏回原始 Student 策略,SDPO 实现了无需外部教师模型、无需显式奖励模型的稠密信用分配。
实验表明,SDPO 在 LiveCodeBench 等基准测试中,相较于 GRPO 具有更高的样本效率(4倍)和更高的最终准确率,并能产生更简洁的推理链。此外,SDPO 还可以应用于测试时计算(Test-Time Compute),加速解决困难问题。
1. 引言
1.1 从 RLHF 到 RLVR
随着大语言模型的发展,后训练(Post-training)阶段的强化学习(RL)已成为提升模型推理能力的关键手段。从早期的 RLHF(基于人类反馈的强化学习)到近期在 DeepSeek-R1 等模型中广泛应用的 RLVR(基于可验证奖励的强化学习),核心逻辑在于利用环境反馈优化策略。
在代码生成和数学推理等领域,验证结果通常是确定性的(如单元测试通过与否)。这类场景被称为 RLVR。目前主流的 RLVR 方法,例如 GRPO (Group Relative Policy Optimization) ,通过对同一个问题采样多个回答,并根据结果计算相对优势(Advantage),从而更新策略。
1.2 现有方法的瓶颈:标量奖励的稀疏性
尽管 RLVR 取得了一定进展,但其面临一个严重的信息瓶颈:信用分配(Credit Assignment)。
在标准的 RLVR 设定中,模型 生成答案后,环境仅返回一个标量奖励 (通常是 0 或 1)。
-
信息丢失:环境实际上提供了比 0/1 丰富得多的信息。例如,代码运行时的 Runtime Error、IndexError,或者部分测试用例未通过的详细日志。这些信息解释了 为什么 失败,而不仅仅是 是否 失败。 -
信用分配困难:对于一个生成的长序列,标量奖励无法区分哪些 Token 是导致错误的根源,哪些 Token 是正确的。GRPO 对整个序列的所有 Token 赋予相同的优势值,导致学习效率低下。
1.3 论文切入点:RLRF
论文提出将问题从 RLVR 扩展为 RLRF (Reinforcement Learning with Rich Feedback) 。在此设定下,环境反馈不仅包含标量奖励,还包含文本化的反馈信息(如错误日志)。
核心问题在于:如何在不引入强大的外部教师模型(Teacher Model)或训练额外的奖励模型(Reward Model)的前提下,将这些非结构化的文本反馈转化为稠密的训练信号?
2. Self-Distillation Policy Optimization
SDPO 的核心思想是利用 LLM 强大的 上下文学习(In-Context Learning, ICL) 能力,构建一个“事后诸葛亮”的自我教师。
2.1 自我教师(Self-Teacher)的构建
给定问题 ,模型生成了尝试 ,环境返回了富反馈 。
此时,我们可以构建两个角色:
-
Student (当前策略) :在未看到反馈 之前生成的 ,其分布为 。 -
Self-Teacher (事后策略) :在看到反馈 之后,重新评估 的合理性,其分布为 。
直觉上,模型在看到“报错信息”后,会通过 ICL 能力意识到原本生成的某些 Token 是错误的,从而在 中降低这些 Token 的概率,提升正确 Token 的概率。SDPO 的目标就是让 Student 策略 去逼近这个包含了更多信息的 Teacher 分布。
2.2 目标函数
SDPO 通过最小化 Student 和 Teacher 之间的 KL 散度来进行优化。对于生成的序列 ,SDPO 的损失函数定义为:
其中:
-
是 时刻前的历史 Token。 -
操作符阻止梯度反向传播到 Teacher 端。这是因为 Teacher 是通过当前策略构建的,我们不希望 Teacher 退化以适应 Student,而是希望 Student 追随 Teacher。
2.3 算法流程
SDPO 的具体执行步骤如下(对应论文算法 1):
-
采样:对于数据集中的问题 ,从当前策略 采样 个回答 。 -
评估:将回答提交给环境,获取对应的反馈 。反馈可以是错误日志、执行结果,甚至是如果该组内有成功样本,可以将成功样本作为参考答案。 -
自蒸馏计算: -
构建 Teacher 上下文(Prompt + Question + Answer + Feedback)。 -
计算 Teacher 对原始路径 的 Logits:。 -
计算 Student 对原始路径 的 Logits:。
-
-
更新:根据 进行梯度下降更新 。

2.4 与 RLVR (GRPO) 的关系
论文通过数学推导展示了 SDPO 与 RLVR 方法的紧密联系。
定义优势函数(Advantage):
-
GRPO 的优势:
GRPO 的优势在序列的所有 Token 上是常数(除了 Mask 掉的部分)。
-
SDPO 的优势:
SDPO 的优势是 Token 级别 的。如果 Teacher 认为某个 Token 在看到反馈后概率应提升,则优势为正;反之则为负。
SDPO 的梯度可以写为:
这本质上是一个加权的 Logit 级策略梯度。
3. 实现细节与稳定性优化
为了让 SDPO 在实际大规模训练中稳定工作,论文引入了几个关键的工程与算法改进。
3.1 教师正则化 (Regularized Teacher)
由于 Teacher 和 Student 共享参数,且 Student 在不断更新,如果 Teacher 变化太快,可能导致训练不稳定(类似于 RL 中的目标网络移动过快)。论文提出了两种正则化 Teacher 的方法:
-
显式信任域 (Trust-Region) :强制 Teacher 分布不能偏离初始模型(Reference Model)太远。
其中 控制当前模型权重的比例。
-
指数移动平均 (EMA) :Teacher 的参数 是 Student 参数 的 EMA:
论文在附录 B.3 中证明了 EMA Teacher 实际上隐式地实现了一个信任域约束。实验中发现 EMA 对于稳定性至关重要。
3.2 Top-K Logits 蒸馏
为了节省显存和计算量,SDPO 并不计算词表中所有 个 Token 的 KL 散度,而是仅针对 Student 预测概率最高的 Top-K 个 Token 进行蒸馏。
通常取 或 。这种近似大大降低了内存开销,同时保留了绝大部分梯度信息。
3.3 计算开销
相比于 GRPO,SDPO 需要额外计算一次 Teacher 的 Forward Pass。
-
时间开销:由于 Teacher 的计算是并行的(Prefill 阶段),且不需要生成新 Token,相比于采样的自回归生成过程,Teacher 的计算量很小。 -
空间开销:使用 Top-K 蒸馏后,主要开销在于加载 EMA Teacher 的权重(如果使用 EMA)。
4. 实验设置
论文在三个主要方向进行了实验评估。
4.1 任务与数据集
-
科学推理 (Science Q&A) :Chemistry, Physics, Biology 等科目,来自 SciKnowEval。此类任务通常无富文本反馈,考察 SDPO 在标准 RLVR 设定下的表现。 -
工具使用 (Tool Use) :ToolAlpaca 数据集。 -
代码竞赛 (Competitive Programming):LiveCodeBench (LCB) v6。这是论文的核心实验场景,因其提供详细的编译器报错和测试用例反馈,非常适合验证 RLRF。
4.2 基线模型与配置
-
基座模型:Qwen3-8B, Olmo3-7B-Instruct 等。 -
对比基线: -
GRPO:当前最先进的 RLVR 方法。论文复现了一个增强版 GRPO,包含了 Clip-higher、无偏归一化等最新 Trick。 -
SFT / Distillation:基于成功样本的有监督微调。
-
5. 实验结果与分析
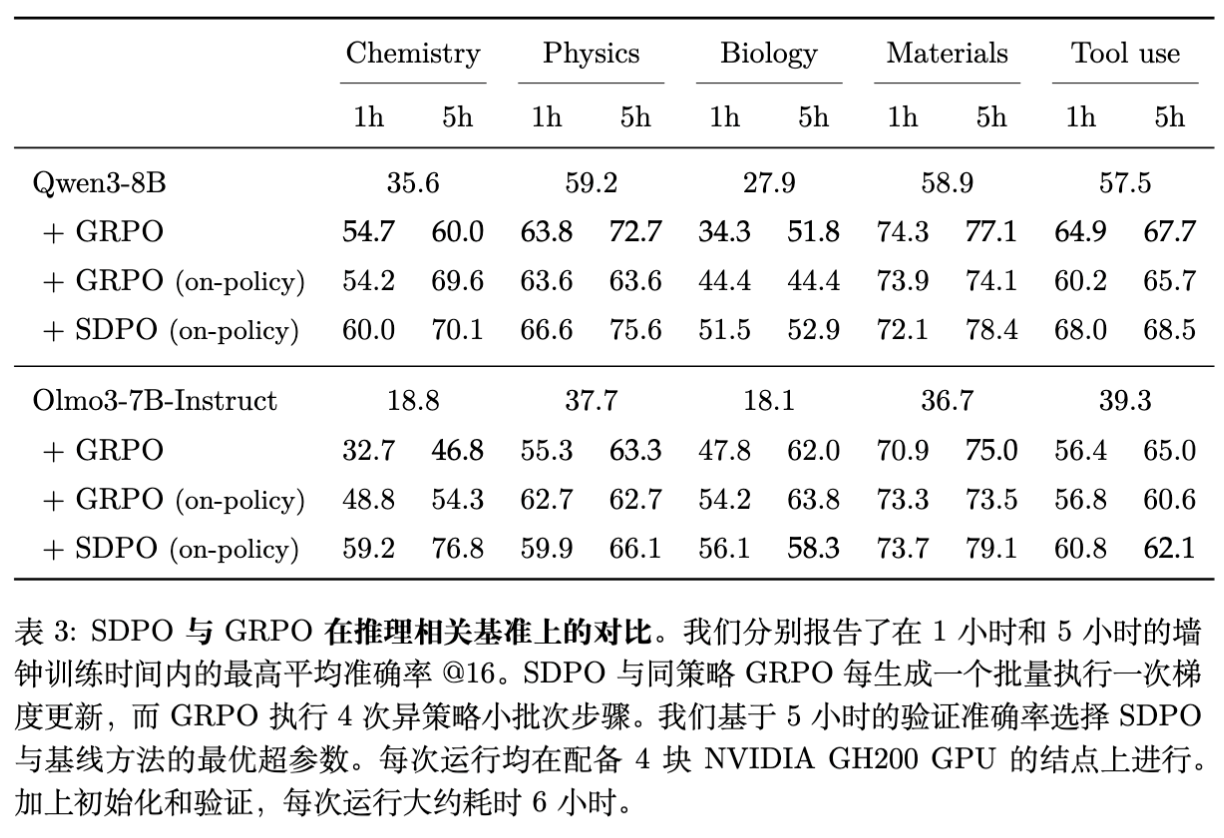
5.1 在无富反馈环境下的表现 (Standard RLVR)
即便在没有编译器报错的环境(如科学问答)中,SDPO 也可以利用“成功样本”作为反馈。即:如果 Batch 内有其他 Sample 成功了,将其作为正确答案提示 Teacher;如果没有,则无法构建有效 Teacher。
-
结果:SDPO 在 Chemistry 任务上准确率达到 70.1% (Qwen3-8B),显著高于 GRPO 的 60.0%。 -
速度:达到相同准确率,SDPO 所需的训练步数更少(Wall-clock time 加速可达 10 倍)。
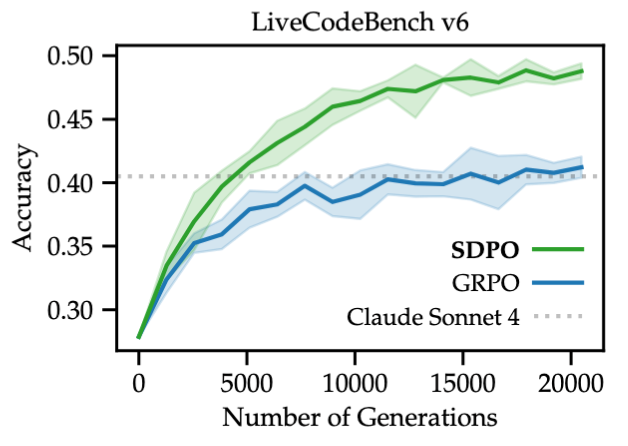
5.2 在富反馈环境下的表现 (LiveCodeBench)
这是 SDPO 的主场。反馈包含:Runtime Error, Wrong Answer (with input/output), Memory Error 等。
-
性能提升:SDPO 在 LiveCodeBench 上将 Qwen3-8B 的 Pass@1 从 Base 的 27.9% 提升至 48.8%,超越了 GRPO。 -
模型强度的影响:实验发现 SDPO 的收益与基座模型能力正相关。在 Qwen3-0.6B 等小模型上,SDPO 提升有限;而在 8B 模型上提升巨大。这验证了核心假设:SDPO 依赖于模型自身的 ICL 能力来进行自我纠错。模型越强,Teacher 越准。
5.3 简洁性与推理效率
一个非常有趣的发现是:SDPO 训练出的模型更不说废话。
在 RLVR 中,模型往往倾向于通过生成更长的思维链(CoT)来“试探”奖励,甚至出现为了凑长度而重复输出的情况(Reward Hacking 的一种形式)。
相比之下,SDPO 生成的回复长度平均只有 GRPO 的 1/3,但准确率更高。

这是因为 SDPO 提供了 Dense Credit Assignment。Teacher 会明确指出哪些 Token 是多余的或错误的,而 GRPO 只能对整个长序列给一个正奖励,导致模型误以为长篇大论是获得奖励的关键。
6. 测试时自蒸馏
论文进一步探索了 SDPO 在推理阶段的应用,针对 Test-Time Compute 场景。
对于极难的问题(Pass@1 接近 0),常规的 Best-of-N 采样或多轮对话(Multi-turn)往往无效。论文提出在测试时,针对单个问题 ,利用 SDPO 进行在线微调。
6.1 设定
-
给定一个难题 。 -
模型尝试生成 ,获得反馈 。 -
利用 进行 SDPO 梯度更新,修改模型参数 。 -
重复上述过程。
这一过程可以被视为将长 Context 中的反馈历史“压缩”进模型权重中。
6.2 结果:Discovery @ k
指标 Discovery @ k 定义为在前 次尝试中找到至少一个正确解的概率。
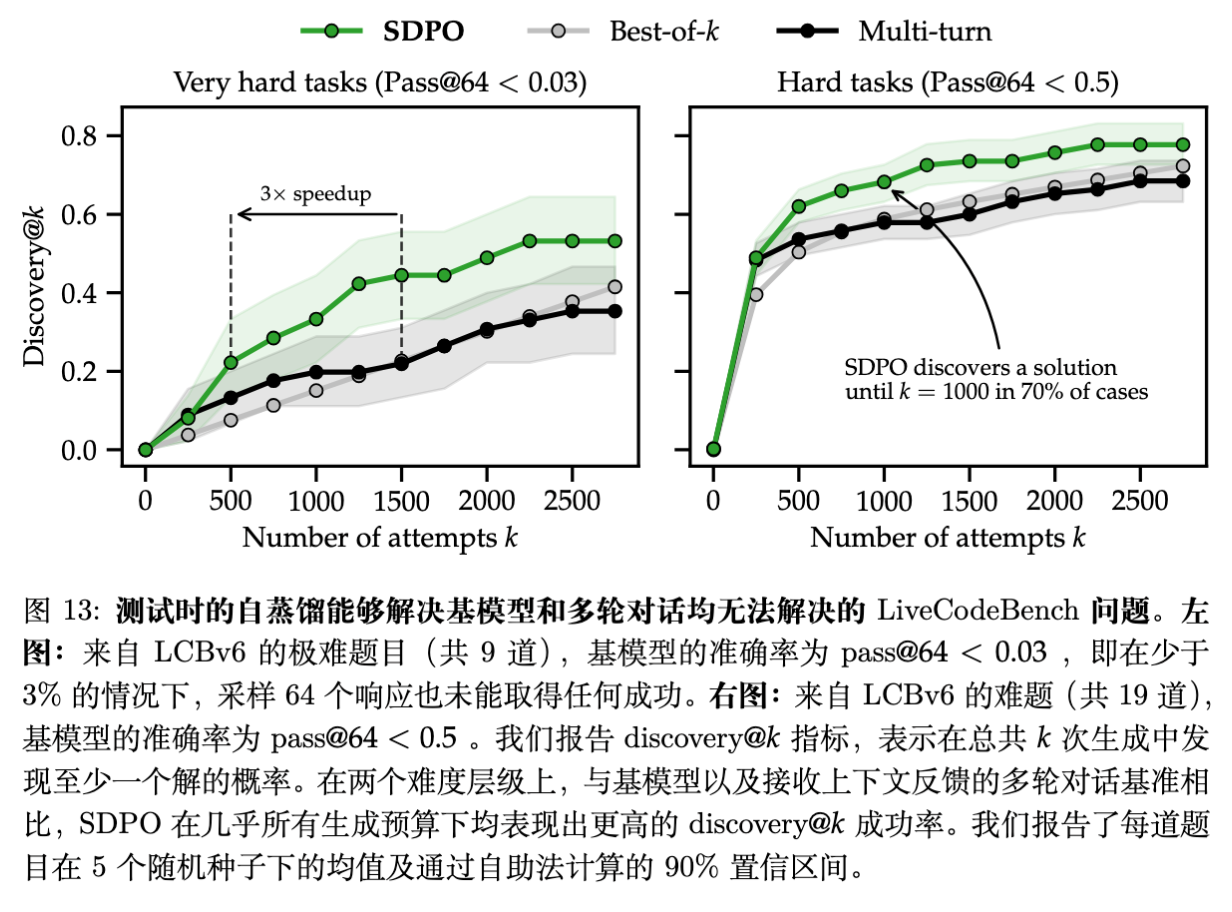
-
SDPO 在难体上的搜索效率比 Best-of-N 高 3 倍。 -
对于某些基座模型完全无法解决的问题(Initial Teacher Accuracy = 0),SDPO 通过迭代式的自我修正,最终能够搜索到解。这表明 SDPO 不仅仅是利用已有的知识,还能通过反馈引导进行探索。
7. 深入分析与消融实验
7.1 哪种反馈最重要?
论文对比了不同类型的反馈对 Teacher 质量的影响:
-
仅环境输出 (Environment Output):如报错信息。 -
仅参考答案 (Sample Solution):如果 Batch 内有其他成功样本。 -
原始尝试 (Student's Attempt):将原始错误的 放回 Prompt。
结论:环境输出和参考答案是互补的。即便没有参考答案,仅靠报错信息,SDPO 也能带来显著提升。这证明了 RLRF 的核心价值。
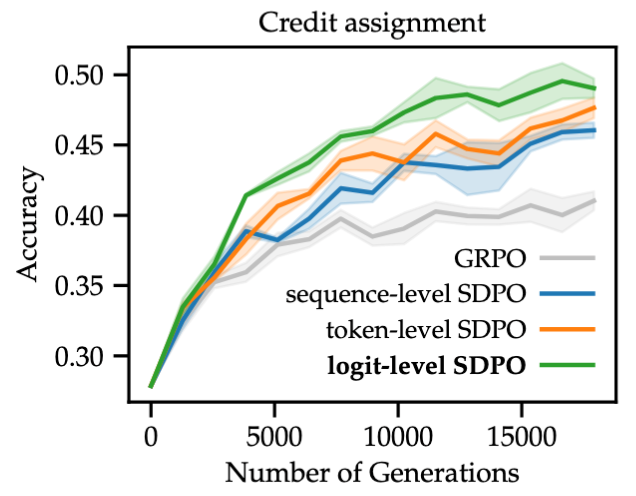
7.2 信用分配的粒度
论文对比了三种优势计算方式:
-
Logit-level (SDPO) :每个 Token 每个类别都有独立的优势。 -
Token-level:仅针对采样出的那个 Token 计算优势。 -
Sequence-level:对整个序列取平均优势(类似 GRPO)。
7.3 灾难性遗忘
On-policy 的 RL 训练通常比 Off-policy 具有更好的稳定性。论文测试了在 LiveCodeBench 上训练后的模型在通用任务(IFEval, ArenaHard, MMLU-Pro)上的表现。
结果显示,SDPO 在提升代码能力的同时,几乎没有造成通用能力的下降,表现优于 SFT 和 GRPO。
8. 理论分析:最大熵 RL 视角
论文在附录 C.1 中建立了一个理论视角:SDPO 可以看作是最大熵 RL (Maximum Entropy RL) 的一种形式。
最大熵 RL 的目标是优化:
如果我们定义后验分布 ,则目标等价于最小化 。
在 SDPO 中,Teacher 分布 扮演了 的角色。也就是说,Teacher 隐式地定义了一个 Dense Reward Function。
这意味着 SDPO 实际上是在做一个隐式的 Inverse Reinforcement Learning (IRL) :Student 试图学习由 Teacher 的“事后观察”所定义的奖励函数。
9. 结论与局限性
9.1 结论
SDPO 提出了一种优雅的方式来利用环境中的富文本反馈。它不需要训练额外的 Reward Model,也不需要外部专家,仅利用模型自身的 ICL 能力作为杠杆,通过自蒸馏实现了高效的强化学习。
其核心贡献在于:
-
形式化 RLRF:将 Textual Feedback 引入 RL 循环。 -
无需 Critic 的 Dense Reward:解决了 RLVR 中的稀疏奖励问题。 -
高效与简洁:训练收敛快,生成的答案不啰嗦。
9.2 局限性
-
依赖模型能力:SDPO 强依赖于模型的 ICL 能力。如果模型太弱(如 Qwen2.5-1.5B),无法从反馈中推断出正确修正,SDPO 甚至可能不如 GRPO。这是一种“富者更富”的方法。 -
依赖反馈质量:如果环境反馈具有误导性(Misleading),Teacher 会教给 Student 错误的信息。 -
计算开销:对于极小模型或极短序列,Teacher 的推理开销占比会变大。
9.3 未来展望
-
Agentic Settings:SDPO 天然适合多步 Agent 任务,中间步骤的反馈可以即时用于修正策略。 -
Beyond Verifiable Rewards:探索能否将 SDPO 应用于开放域文本生成,利用 LLM-as-a-Judge 的反馈作为 Rich Feedback。 -
Off-policy 扩展:目前的 SDPO 是 On-policy 的,结合 Off-policy 数据(如 Replay Buffer)可能会进一步提升样本效率。
更多细节请阅读原文。
往期文章:


