让每一项优秀工作,都被更多人看见:点击进入投稿通道

-
论文标题:Weak-Driven Learning: How Weak Agents make Strong Agents Stronger -
论文链接:https://arxiv.org/pdf/2602.08222
TL;DR
今天解读一篇来自北航和中国电信合作的一篇论文《Weak-Driven Learning: How Weak Agents make Strong Agents Stronger》。该工作提出了一种名为 WMSS(Weak Agents Can Make Strong Agents Stronger)的新型后训练范式。针对大语言模型在监督微调(SFT)后期出现的优化饱和问题——即模型过度自信导致非目标 token 的梯度消失,作者提出利用模型自身的历史弱检查点(Weak Checkpoints)作为参考。通过 Logit 混合(Logit Mixing)机制,WMSS 将弱模型的“不确定性”注入到强模型的训练过程中,重新激活了针对“困难负样本”(Hard Negatives)的梯度信号。理论分析与实验结果表明,该方法在不增加任何推理成本的情况下,显著提升了模型在数学推理和代码生成任务上的性能,验证了弱监督信号在强化强模型决策边界中的有效性。
1. 引言
在大语言模型(LLM)的后训练(Post-training)阶段,监督微调(SFT)和知识蒸馏(KD)是目前的主流范式。这些方法通常基于“模仿”的原则:SFT 模仿高质量的标签(Ground Truth),KD 模仿更强的教师模型(Teacher Model)。其底层假设是,通过不断拉近模型输出分布与更高质量目标分布的距离,模型的性能将持续提升。
然而,随着优化过程的推进,研究者观察到了显著的性能饱和(Performance Saturation)现象。具体表现为:
-
Logit Margin 固化:目标 token 的 logit 与非目标 token 的 logit 之间的差距在训练初期迅速扩大,随后趋于稳定。 -
梯度消失:由于 Softmax 函数的指数特性,当模型对目标预测产生极高置信度时,损失函数对非目标 token(即错误选项)的梯度贡献几乎降为零。 -
过拟合与遗忘:继续进行 SFT 往往导致模型在训练集上过拟合,而泛化能力不再提升,甚至出现灾难性遗忘。
现有的解决方案,如持续 SFT 或基于自我反思(Self-reflection)的微调,往往依赖于增强正确目标的信号,而在梯度已然微弱的饱和区,这种策略效率有限。
本文作者提出了一种反直觉的视角:利用弱模型(Weak Agent)来驱动强模型(Strong Agent)的进一步学习。这被称为“弱驱动学习”(Weak-Driven Learning)。与知识蒸馏不同,这里不需要一个更强的外部教师,而是利用模型历史训练阶段的较弱检查点。
其核心动机源于人类协作中的一种现象:当一个强者与弱者协作时,强者往往需要观察、分析并纠正弱者的错误。弱者的错误暴露了那些“似是而非”的推理路径(Plausible but incorrect reasoning paths),迫使强者显式地排除这些错误选项,从而打磨出更清晰的决策边界。
2. Weak-Driven Learning 核心方法论
WMSS 框架包含三个主要阶段:初始化、课程增强数据激活(Curriculum-Enhanced Data Activation, CEDA)以及弱驱动联合训练(Joint Training of Weak and Strong, JTWS)。
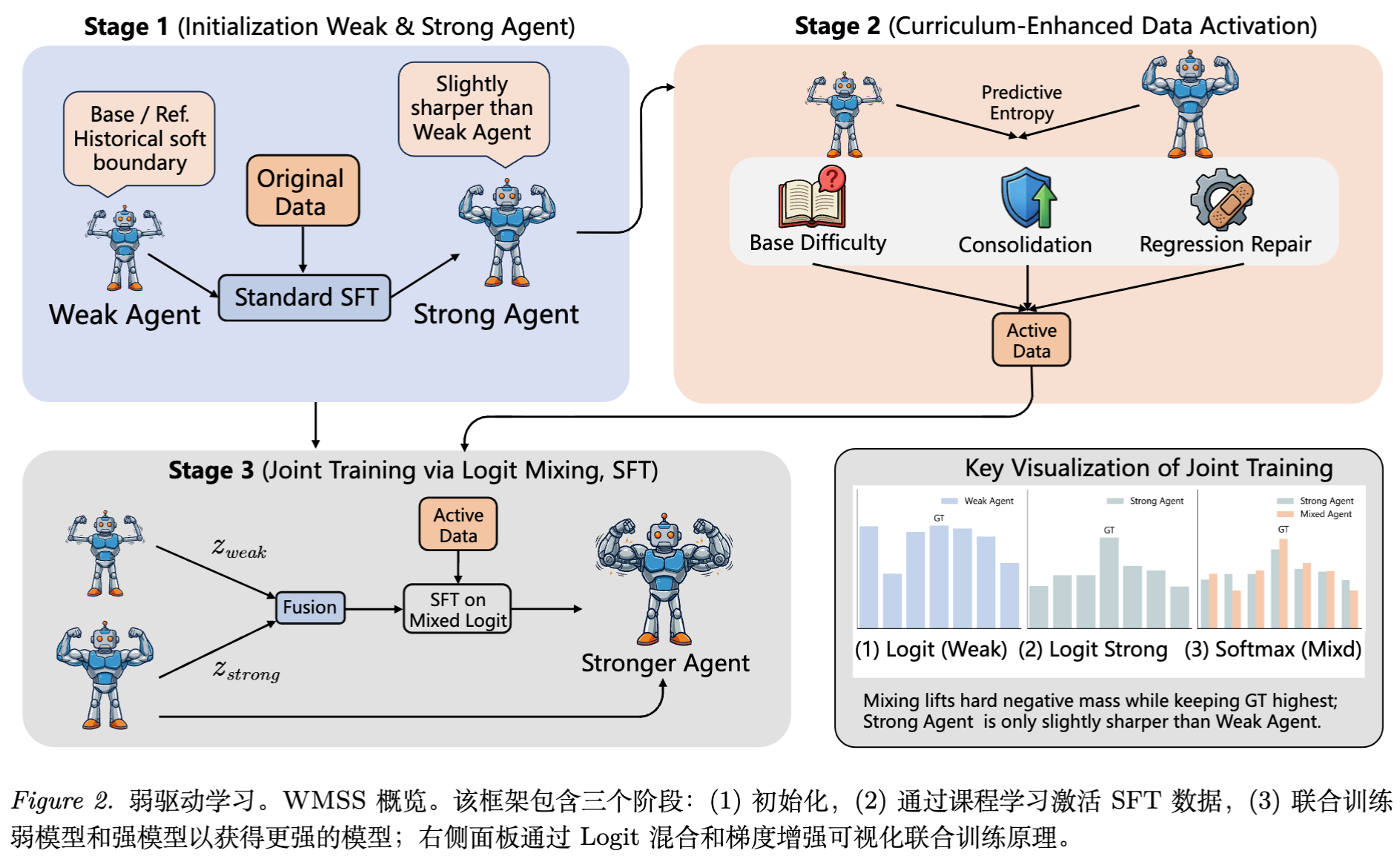
2.1 初始化
设定两个智能体:
-
弱智能体():通常选择模型训练早期的检查点(Checkpoint)。 -
强智能体():当前经过一定程度训练的模型。
在 WMSS 流程开始时:
-
从基础模型 开始,进行标准 SFT 得到 。 -
令 (或早期检查点)。 -
令 。
弱智能体的作用不是提供模仿对象,而是提供参考 logits () ,这些 logits 保留了较软的决策边界,包含了关于干扰项(Distractors)的信息。
2.2 课程增强数据激活
为了最大化训练效率,作者并未在所有数据上进行联合训练,而是构建了一个动态的数据选择机制。该机制基于弱模型和强模型之间的熵动态(Entropy Dynamics)。
对于样本 ,定义预测熵 。计算强弱模型之间的不确定性变化:
基于此,构建采样概率 ,包含三部分信号:
其中 。这三项具有明确的物理含义:
-
基础难度(Base Difficulty, ): 较高意味着该样本对弱模型本身就很难。这保证了固有难度的概念被保留。 -
巩固学习(Consolidation, ):当 时,意味着强模型比弱模型更自信(熵减小)。如果熵下降过快,可能意味着“快但脆弱”的学习,需要重访这些样本以稳固记忆。 -
回归修复(Regression Repair, ):当 时,意味着强模型比弱模型更困惑(熵增加)。既然弱模型能处理得更好(或更确定),说明该样本并非不可学习的噪声,而是强模型发生了遗忘或退化,因此需要高权重采样以修复。
通过上述分布采样得到训练集 ,用于下一阶段。
2.3 弱驱动联合训练
这是 WMSS 的核心操作。对于训练对 ,分别获取弱模型 logits 和强模型 logits 。
构建混合 Logits(Mixed Logits):
其中 为混合系数(通常取 0.5)。
优化目标是最小化混合分布 下的负对数似然损失,但只更新强模型参数:
反向传播机制:
梯度通过 传播。虽然 参与了前向计算,但不参与参数更新。这种机制的关键在于:弱模型会对那些强模型已经抑制(Suppressed)但仍然具备合理性的错误选项(Hard Negatives)分配非零的概率质量。通过混合,这些选项在 中的概率被提升,从而产生了有效的梯度信号,防止了梯度消失。
3. 弱模型如何让强模型更强?
3.1 梯度放大机制 (Gradient Amplification)
对于交叉熵损失,对于任意非目标 token ,其梯度大小为:
在标准 SFT 中,当模型收敛时,,导致梯度消失。
在 WMSS 中,混合概率 由 决定。定义 Margin(目标与干扰项的差距):
混合后的 Margin 为两者的凸组合:
定义困难负样本集合(Hard-negative set) 为那些弱模型比强模型更混淆的 token:
对于 ,混合操作会导致 Margin 缩小(相较于强模型),根据 Softmax 性质,Margin 缩小意味着概率增大。
定理 5.1(总负概率质量增加):
如果弱模型在所有非目标 token 上都比强模型更不确定,则混合分布在非目标 token 上的总概率质量及其梯度和将大于强模型单独的情况:
这直接导致了在饱和区域,非目标 token 的梯度被“再激活”。
推论 5.2(特定 token 的梯度放大):
对于困难负样本 ,梯度放大的倍数与 Margin 的差异成指数关系:
其中 是强弱模型 Margin 的差值。
3.2 训练动力学的三阶段分析
作者通过 Hessian 矩阵和梯度分析,将 WMSS 的训练过程分为三个阶段:
-
第一阶段:饱和区放大 (Saturated-region Amplification)
-
在联合训练初期,弱模型对大量非目标 token 存在混淆。 -
Logit 混合增加了总体的负概率质量。 -
梯度 偏向于困难负样本,此时强模型主导有效的更新方向,但在弱模型的“扰动”下,决策边界被迫推远那些似是而非的错误选项。
-
-
第二阶段:梯度屏蔽 (Gradient Shielding)
-
随着强模型变得极其自信,。 -
此时 Softmax 的 Hessian 矩阵 趋近于零矩阵。 -
弱模型与强模型的交互 Hessian项 也随之消失。 -
这意味着当强模型足够强时,弱模型的影响力会自动衰减。这是一种自动课程(Auto-curriculum)机制,无需人工干预停止 Logit Mixing。
-
-
第三阶段:零空间漂移 (Null-space Drift)
-
Softmax 具有平移不变性:。 -
当梯度极小时,随机更新会导致 Logits 在零空间(均值方向)上发生随机游走。 -
作者观察到弱模型的 Logit 均值在训练中显著下降(Drift),但这不影响分类性能,反映了在零空间的扩散现象。
-
4. 实验
实验主要在数学推理(Arithmetic Reasoning)和代码生成(Code Generation)两大类任务上进行。
4.1 实验设置
-
模型:Qwen3-4B-Base 和 Qwen3-8B-Base。 -
数据集: -
数学:AIME2025, MATH500, AMC23, GSM8K, SVAMP 等。 -
代码:HumanEval, MBPP。
-
-
训练数据:从 AM-1.4M 数据集中筛选出的高质量子集(约 215k 样本)。 -
基线对比:Standard SFT, UNDIAL (直接抑制 Target Token), NEFTune (Embedding 噪声注入)。
4.2 主要结果
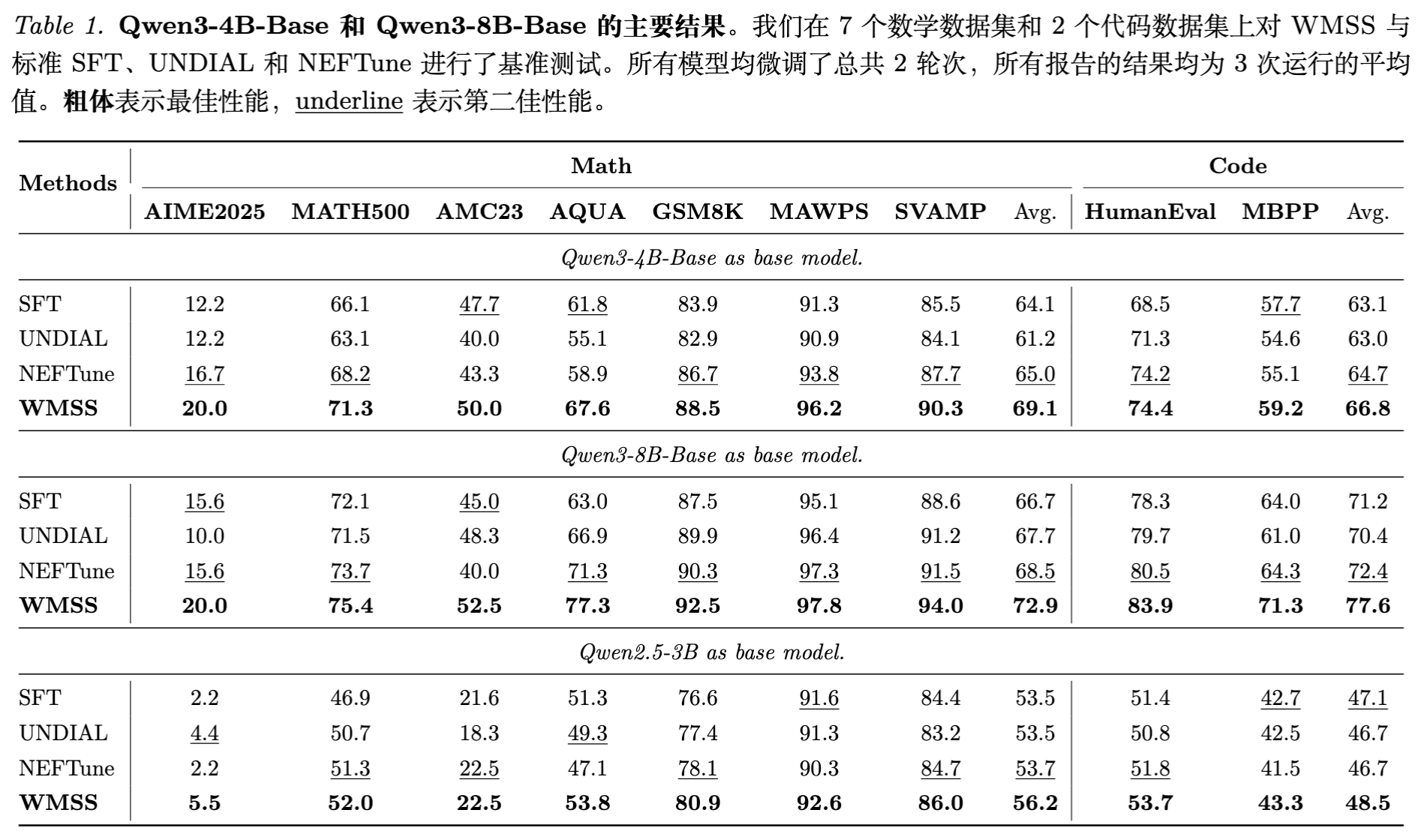
实验结果表明,WMSS 在所有基准测试中均超越了标准 SFT 和其他对比方法:
-
数学推理提升显著:
-
在 Qwen3-4B-Base 上,WMSS 将平均数学准确率从 64.1% 提升至 69.1% (+5.0%)。 -
在 Qwen3-8B-Base 上,提升幅度达到 +6.2% (66.7% 72.9%)。 -
特别是在高难度的 AIME2025 上,提升尤为明显(例如 4B 模型从 12.2% 提升至 20.0%),证明了该方法在攻克复杂推理瓶颈上的有效性。
-
-
代码生成稳步增长:
-
在 HumanEval 和 MBPP 上,WMSS 同样取得了约 3-4% 的绝对提升。
-
-
对比 UNDIAL 与 NEFTune:
-
UNDIAL 试图通过随机惩罚目标 token 来防止过拟合,但结果显示其性能下降(Avg -1.4%)。这说明单纯抑制 Ground Truth 是有害的,而 WMSS 是通过提升干扰项(Distractors)的相对概率来优化边界,这种结构化的信号优于盲目的抑制。 -
NEFTune 通过注入噪声进行正则化,虽然比 SFT 略好,但不如 WMSS。WMSS 利用的是历史的“认知混淆”作为信号,而非随机噪声。
-
4.3 深入分析
收敛性分析:
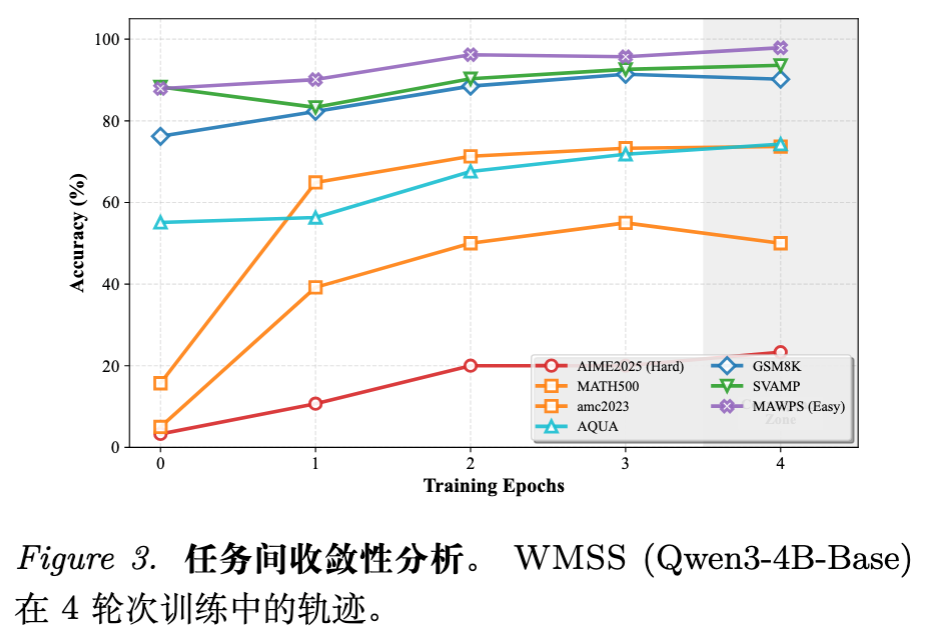
SFT 在训练后期往往出现过拟合,特别是在较难的数据集上。WMSS 的训练曲线显示出更强的持续上升动力,并在第 4 个 Epoch 左右达到泛化峰值,有效延缓了过拟合。
Logit 动力学统计:
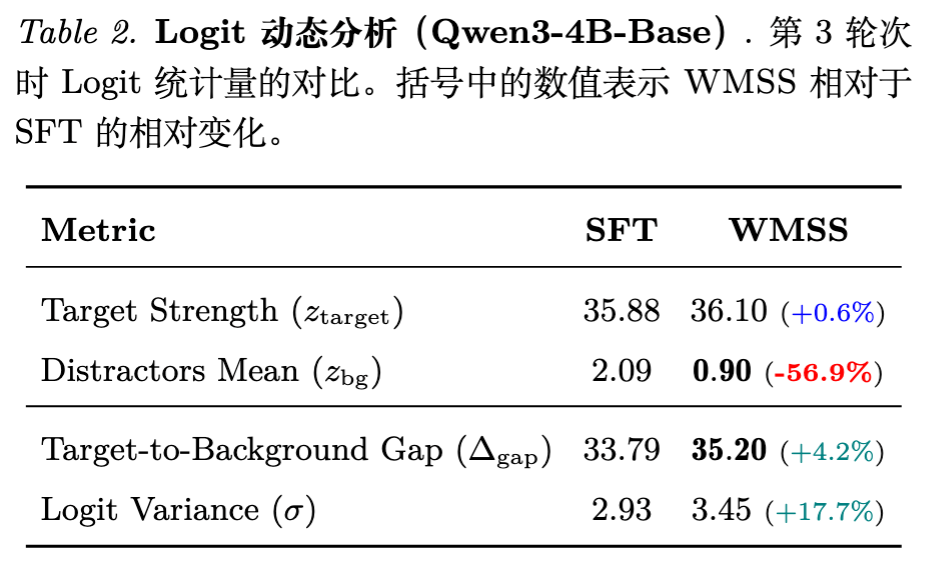
作者对比了 SFT 和 WMSS 训练后的 Logit 分布:
-
Target Strength () :两者相差不大(SFT: 35.88 vs WMSS: 36.10)。 -
Distractors Mean () :差异巨大。WMSS 显著降低了非目标 Logit 的均值(SFT: 2.09 vs WMSS: 0.90)。 -
结论:WMSS 的性能提升并非主要源于“推高正确答案”,而是源于“更强力地压制错误答案”。通过 Logit Mixing,模型被迫在训练中更积极地识别并推远那些混淆项,导致最终的非目标 Logit 值更低,决策边界更清晰。
消融实验:
-
仅使用 CEDA(课程数据):带来约 +2.2% 的提升,证明了数据选择的有效性。 -
加入 JTWS(联合训练):带来进一步的大幅提升,特别是在困难任务上。两者结合实现了最佳性能。
参数敏感性:
-
混合系数 :呈倒 U 型曲线, 时效果最佳。这符合直觉:过分依赖弱模型()会导致欠拟合,过分依赖强模型()则退化回 SFT。
5. 讨论与总结
5.1 为什么是“弱”驱动?
这篇论文挑战了“监督必须来自更强源头”的传统观念。其核心洞察在于:弱模型的价值在于其错误分布的结构性。
-
随机初始化的模型产生的是白噪声,对训练无益。 -
训练中途的弱检查点,其产生的 Logit 分布包含了“有意义的困惑”。即,它给出的高概率错误选项,往往是语义上接近、推理逻辑上易混淆的“硬伤”。 -
将这些硬伤显式地暴露给强模型,相当于进行了一次挖掘困难负样本(Hard Negative Mining)的过程。
5.2 计算开销
-
训练端:需要同时进行两次前向传播(一次弱模型,一次强模型)。这会增加约 倍的显存开销和计算时间(因为弱模型不反向传播,且可以设为 eval模式)。但考虑到无需训练额外的 Reward Model 或 Teacher Model,该开销在可接受范围内。 -
推理端:零额外开销。训练完成后,仅部署强模型 。这是 WMSS 相比于一些推理时干预(Inference-time intervention)方法的巨大优势。
5.3 局限性与未来展望
-
弱模型的选择:论文主要使用了自身的历史检查点。如果使用架构完全不同的小模型作为弱代理,效果如何?这是一个值得探索的方向。 -
适用范围:目前主要验证了推理类任务(数学、代码)。对于开放域闲聊或创意写作,这种基于“纠错”的逻辑是否适用,尚需验证。
更多细节请阅读原文。
往期文章:


