
-
论文标题:How to Allocate, How to Learn? Dynamic Rollout Allocation and Advantage Modulation for Policy Optimization -
论文链接:https://arxiv.org/pdf/2602.19208
TL;DR
在基于验证奖励的强化学习(RLVR)中,现有的方法(如GRPO)通常采用均匀的Rollout分配策略,且受限于Softmax策略固有的梯度衰减与更新不稳定性。今天解读一篇来自美团的论文 "How to Allocate, How to Learn? Dynamic Rollout Allocation and Advantage Modulation for Policy Optimization" 提出了一种名为 DynaMO 的双重优化框架。该框架在序列级别推导了最小化梯度方差的动态分配策略,利用伯努利方差作为梯度信息量的代理;在Token级别基于梯度-熵的理论界限,引入了梯度补偿与更新幅度稳定机制。实验表明,DynaMO 在 Qwen2.5-Math (1.5B/7B) 和 Qwen3 (14B) 上,于多个数学推理基准(AIME, MATH500等)中取得了一致的性能提升,并展现了更稳定的训练动态。
1. 引言
随着 OpenAI o1 和 DeepSeek-R1 等模型的出现,大语言模型(LLM)在长链思维(CoT)和自我反思能力上取得了进展。这一进展背后的核心驱动力之一是基于验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)。
在数学推理或代码生成等任务中,由于答案的正确性是客观可验证的,RLVR 通过利用结果奖励(Outcome-based Rewards)来优化策略模型。目前主流的方法通常结合 GRPO(Group Relative Policy Optimization)算法及其变体。
然而,尽管 RLVR 取得了一定成效,现有的优化范式在计算资源分配和策略优化动力学两个基本维度上仍存在未被充分解决的挑战:
-
资源分配的低效性(Sequence Level):
目前的 RLVR 方法(如 DeepSeek-Math 中的 GRPO)通常在所有训练样本上均匀分配 Rollout 预算(例如每个 prompt 采样 个回复)。这种均匀分配忽略了不同问题之间梯度信息量的异质性。对于模型已经完全掌握的简单问题,或者模型完全无法解决的困难问题,过多的采样预算边际收益递减。 -
策略优化的内在矛盾(Token Level):
理论分析表明,Softmax 策略的数学结构会导致高置信度的正确动作产生较小的梯度幅值,这被称为“梯度衰减”现象。这意味着模型对于其确信的正确路径,学习信号会变弱。另一方面,过大的梯度更新又可能导致训练不稳定(如熵崩塌)。现有的方法如 Ratio Clipping 或熵正则化,往往是粗粒度的干预,缺乏统一的理论指导来平衡“保持学习信号”与“维持训练稳定性”之间的权衡。
为了解决上述问题,论文提出了 DynaMO 框架,分别在序列级和 Token 级进行干预。
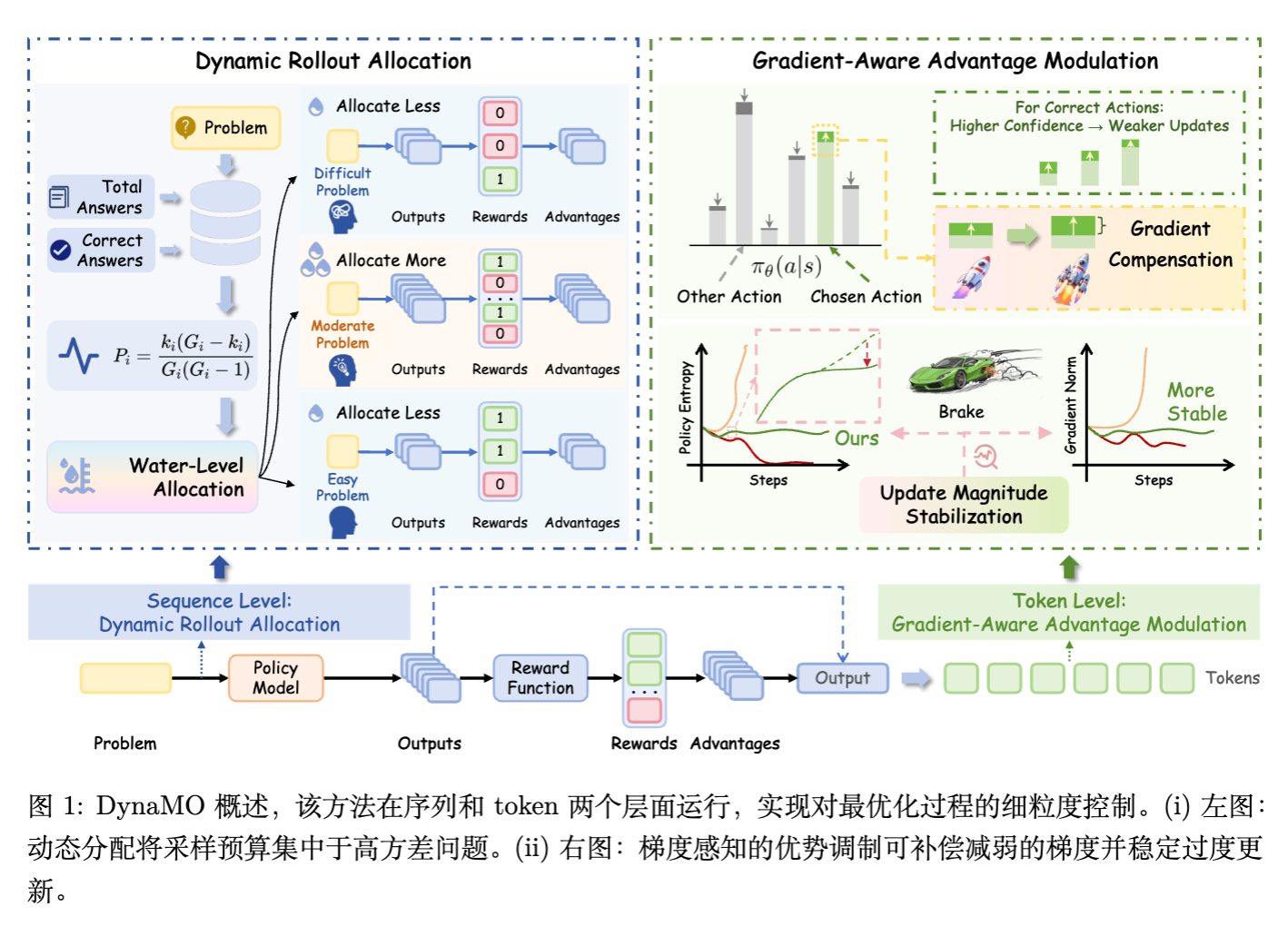
2. 预备知识与问题形式化
2.1 RLVR 与 GRPO
在 RLVR 设定下,给定从训练数据 中采样的提示词 ,策略模型 自回归地生成回复 。目标是最大化期望奖励:
其中 是验证奖励函数。
GRPO 为了减少梯度方差,对每个提示词采样 个回复 ,并通过组内归一化计算优势(Advantage):
GRPO 的损失函数为:
其中 为重要性采样比率。
2.2 策略熵
策略熵衡量了模型动作选择的不确定性,是 RL 中探索能力的关键指标。对于策略 ,其熵定义为:
熵值越高表示探索性越强,反之则表示行为趋于确定性。
3. 动态 Rollout 分配
论文首先在序列级别探讨了如何分配有限的采样预算。
3.1 优化理论:方差最小化分配
假设训练集中有 个 prompt ,总预算为 个 Rollout。对于每个 prompt ,分配 个 Rollout。
该 prompt 对应的梯度估计量 的方差为 ,其中 是单样本梯度的方差。
目标是最小化总估计方差 ,受限于预算约束 。这是一个典型的拉格朗日乘数法问题。
构造拉格朗日函数:
对 求导并令其为 0:
代入约束条件解得最优分配方案:
结论:最优的 Rollout 分配应与该问题的梯度标准差 成正比。换言之,梯度方差越大的问题,应分配越多的采样次数,以降低整体的估计噪声。
3.2 伯努利方差作为可计算代理
直接计算梯度方差 计算成本过高,需要反向传播。论文推导了如何使用历史统计数据作为代理。
对于二值奖励(Binary Rewards,即正确/错误),奖励的方差遵循伯努利分布 ,其中 是成功率。
论文在附录中证明了梯度方差与奖励方差的正相关性:
忽略 Token 级别的细微差异,奖励方差 是梯度方差的主导项。
因此,论文提出利用历史采样中的成功次数 和总次数 来估计这一方差:
这个 是 的无偏估计。
物理意义:
-
当 (问题太难)或 (问题太简单)时,方差 较小。此时模型要么完全不会,要么完全掌握,梯度信息量较低(或噪声过大/信号微弱),应减少采样。 -
当 时,方差最大。这对应于模型的能力边界(Capability Boundary),即那些模型“努努力能做对,但也容易做错”的问题。这些样本对学习最有价值。
3.3 水位填充算法实现
基于上述理论,DynaMO 设计了水位填充(Water-Level)算法来动态调整 。
算法输入为历史统计量、总预算 以及每个 prompt 的分配上下界 。
上下界的作用是:
-
:保证每个问题至少有少量采样,防止因历史统计不准而永久忽略某些问题。 -
:防止预算过度集中在少数问题上。
算法逻辑(Algorithm 1)大致如下:
-
计算每个 prompt 的优先级 。 -
初始化分配 。 -
剩余预算按照 的比例分配给未达到 的 prompt。 -
每轮训练后,更新历史统计量 。
4. 梯度感知优势调节
解决了“采样什么”的问题后,论文进一步探讨“如何利用采样数据更新”。这一部分主要针对 Softmax 策略在 RL 训练中的动力学特性。
4.1 梯度分析:梯度范数与熵的关系
论文首先在附录中建立了一个关键的理论联系:梯度更新幅值与策略熵的负相关性。
对于 Softmax 策略,参数 的更新量的平方范数期望满足:
利用琴生不等式(Jensen's inequality),可以得到上界:
其中 是熵。
这个公式揭示了两个现象:
-
高置信度(低熵)导致梯度衰减:当模型对某个动作非常有信心时(),,梯度更新量趋近于 0。这意味着对于模型确信的正确动作,即使给予正向奖励,模型也几乎不再更新参数。这阻碍了模型进一步巩固正确路径。 -
高熵导致梯度爆炸:当模型非常不确定时(熵高),梯度范数接近最大值,容易导致参数剧烈波动。
4.2 梯度补偿机制 (Gradient Compensation)
针对现象1(高置信度正确动作的梯度衰减),DynaMO 引入了梯度补偿因子 。
核心思想:对于正向优势()的 Token,如果其熵较低(即模型自信),我们人工放大其学习信号,抵消 Softmax 带来的自然衰减。
补偿函数 设计为与熵成反比:
其中 是控制补偿强度的超参数。
-
当 Token 为正样本且熵很低(自信)时,,,放大更新。 -
当 Token 为负样本时,不进行补偿,保留原始惩罚力度。
4.3 更新幅度稳定机制 (Update Magnitude Stabilization)
针对现象2(训练不稳定性),论文并不直接通过 Clip 梯度范数来解决,而是利用熵的变化作为不稳定性的可计算指标。
论文推导了熵的一阶变化近似公式:
这意味着:当策略高度集中( 大)且更新系数 (包含优势 )很大时,会导致剧烈的熵变化(通常是熵骤降),这往往是训练不稳定的前兆。
因此,定义不稳定性指标 。
设计稳定因子 来抑制那些导致熵剧烈变化的更新:
是一个 Sigmoid 形式的衰减函数:
当归一化的熵变化量 超过阈值 时,该因子会迅速下降,从而通过缩小优势 来“刹车”。
4.4 整合优势调节
最终,DynaMO 将上述两个机制整合到优势计算中:
这个修正后的优势 被代入 PPO/GRPO 的目标函数中进行训练。
5. 实验
5.1 实验配置
-
模型:Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen3-14B。 -
训练框架:基于 VeRL 框架开发,采用 FSDP 和 Tensor Parallelism。 -
数据集:DAPO-Math-17k(包含可验证整数答案的数学问题)。 -
基准测试: -
竞赛级:AIME24, AIME25, AMC23。 -
综合类:MATH500。 -
理工科:Minerva。 -
奥赛:OlympiadBench。
-
-
对比基线: -
GRPO (Shao et al., 2024) -
Clip-Higher (动态截断比率) -
Entropy Loss / Entropy Advantages (熵正则化/熵加权) -
Fork Tokens / Coverage-based methods (其他探索策略)
-
5.2 主要结果
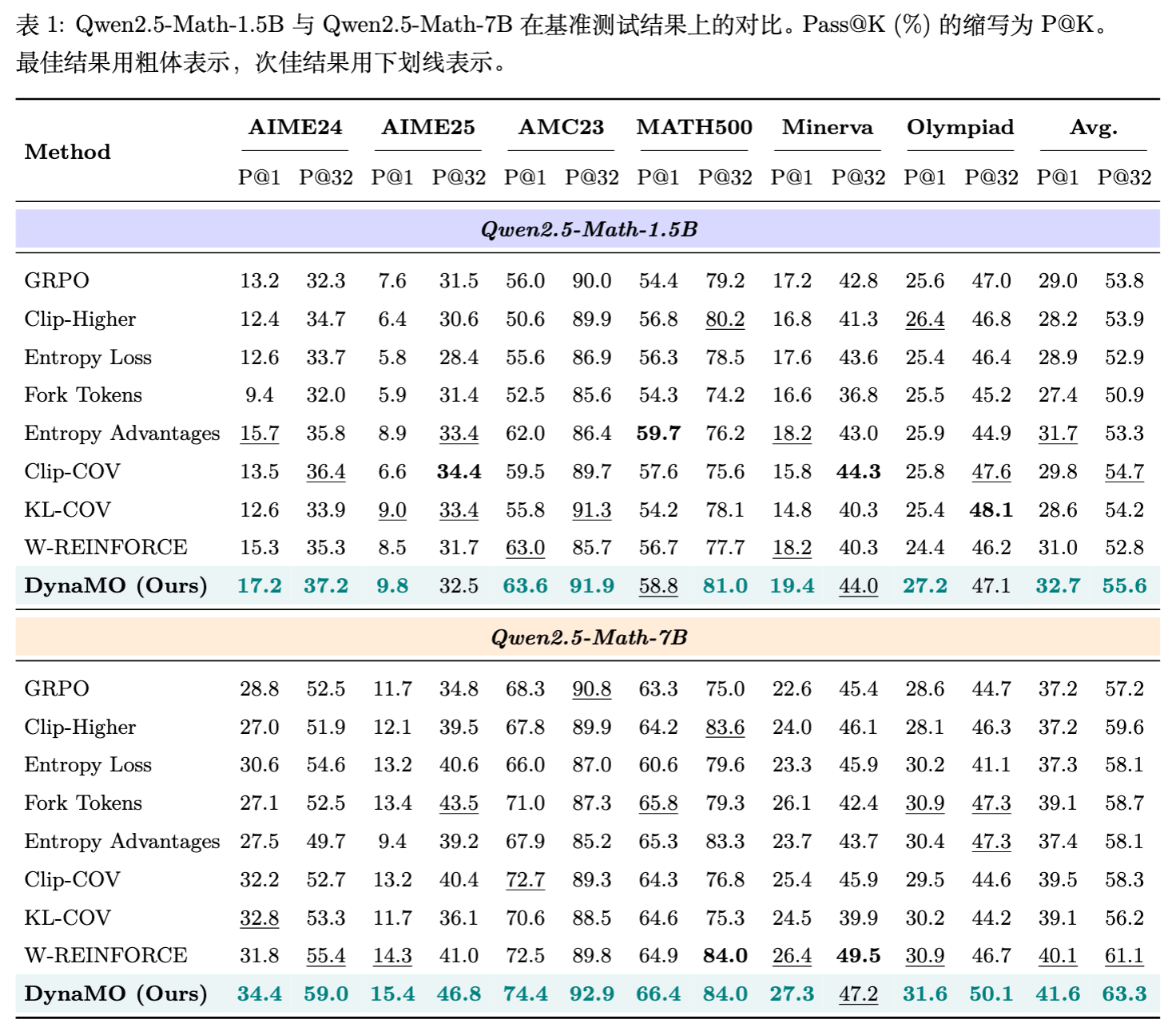
实验结果显示,DynaMO 在所有尺寸的模型和绝大多数基准上都超越了强基线 GRPO。
-
Qwen2.5-Math-7B: 平均 Pass@1 从 GRPO 的 37.2% 提升至 41.6% 。在难度较高的 AIME24 上,从 28.8% 提升至 34.4% 。 -
Qwen2.5-Math-1.5B: 平均 Pass@1 从 29.0% 提升至 32.7% 。
关键观察:
-
高难度任务提升显著:在 AIME 和 AMC 这类竞赛题上,提升幅度往往高于 Minerva 等基础学科题。这得益于动态分配策略能够将资源集中在这些处于“能力边界”的难题上。 -
稳定性:相比 Entropy Loss 等方法,DynaMO 的表现更加稳健,没有出现因激进探索导致的性能下降。
5.3 消融实验
论文对 DynaMO 的三个组件进行了消融:
-
DRA (动态 Rollout 分配) -
GC (梯度补偿) -
UMS (更新幅度稳定)
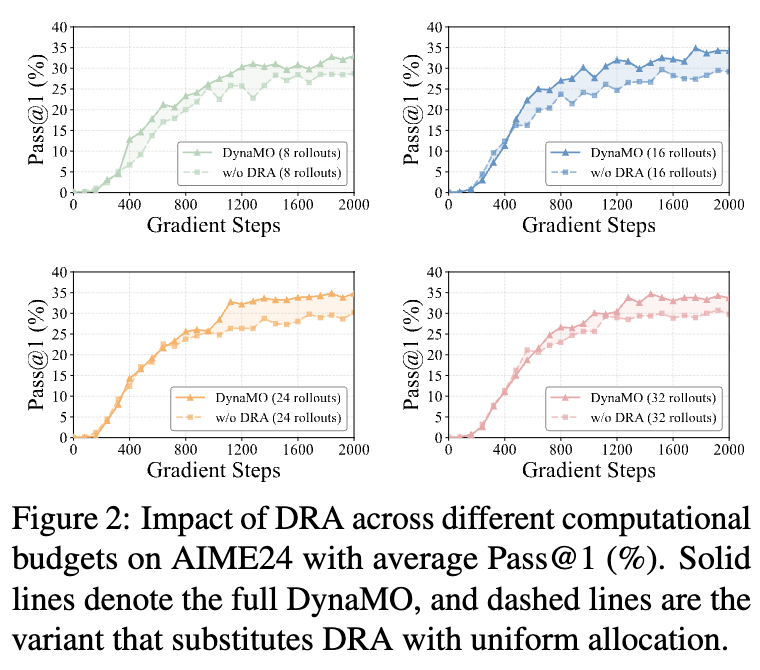
结果表明:
-
去除任意一个组件都会导致性能下降。 -
DRA 的作用:移除 DRA(退化为均匀采样)在 Minerva 和 Olympiad 上影响最大。这证实了资源分配对异质数据集的重要性。 -
GC 与 UMS 的协同:同时移除 GC 和 UMS 导致的性能下降幅度,超过了分别移除它们的总和。这说明 UMS 有效地稳定了由 GC 引入的额外梯度信号,二者通过 参数形成了有机的互补。
5.4 训练动态与案例研究
为了深入理解 DynaMO 为何有效,论文可视化了训练过程中的梯度范数和策略熵的变化。
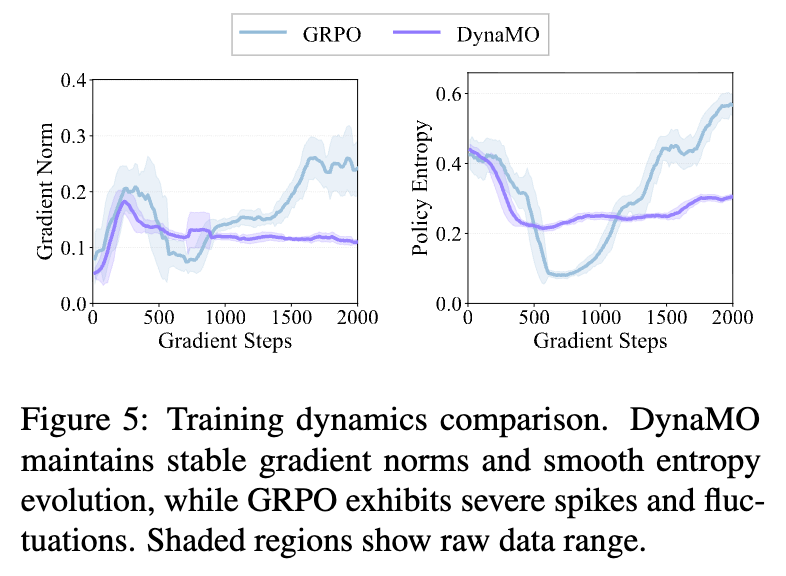
-
GRPO:表现出剧烈的梯度尖峰(Spikes)和不稳定的熵波动。这通常意味着模型在某些 Batch 上进行了破坏性的更新。 -
DynaMO:梯度范数曲线平滑,熵的下降过程稳健。即使引入了梯度补偿(理论上增加了梯度量),由于稳定机制的存在,整体训练反而更加平稳。这证实了 Token 级双重调节机制的有效性。
5.5 扩展性 (Scaling)
论文还验证了方法在 Qwen3-14B 上的有效性。随着模型规模增大,DynaMO 带来的相对提升依然显著,证明了该方法并非仅对小模型有效,而是触及了 RLVR 的通用优化痛点。
6. 讨论与技术细节
6.1 效率分析
虽然 DynaMO 引入了动态分配和额外的 Token 级计算,但论文分析显示其带来的额外计算开销微乎其微。
-
DRA:仅涉及简单的计数统计,在 CPU 上即可完成。 -
Modulation:涉及的熵计算和 Sigmoid 操作是 Element-wise 的,相对于 LLM 的反向传播矩阵乘法,开销可忽略不计。
图表显示,DynaMO 的 Step time 与 GRPO 几乎持平。
6.2 与相关工作的对比
-
与 Curriculum Learning (CL) 的区别:CL 通常关注样本的排序(先易后难),而 DRA 关注分配(在同一 Batch 内给不同样本不同的 )。且 CL 往往依赖预定义的难度指标,DRA 完全由训练过程中的实时统计驱动。 -
与 Rejection Sampling (RFT) 的区别:RFT 是离线的或半在线的,通过拒绝采样筛选数据进行 SFT。DynaMO 是在线 RL,直接优化策略梯度。 -
与 Entropy Regularization 的区别:传统的熵正则化将熵作为损失函数的一部分。DynaMO 则是利用熵作为指示器(Indicator)来调节优势函数,不改变优化目标本身,避免了直接优化熵可能带来的模式坍塌风险。
6.3 局限性
论文在末尾坦诚了局限性:
-
目前仅在 Qwen 系列模型上验证,虽然算法是架构无关的,但不同模型系列的超参数敏感度可能不同。 -
动态分配依赖历史统计,对于极少出现的 Prompt(冷启动问题),初期仍需回退到均匀采样。
更多细节请阅读原文。
往期文章:


