
-
论文标题:Importance-Aware Data Selection for Efficient LLM Instruction Tuning -
论文链接:https://arxiv.org/pdf/2511.07074v1
TL;DR
今天分享一篇来自阿里的论文《Importance-Aware Data Selection for Efficient LLM Instruction Tuning》。这篇论文提出了一种名为“模型指令弱点值”(Model Instruction Weakness Value, MIWV)的全新指标,用于从大规模数据集中筛选对大语言模型(LLM)指令微调最有效的数据子集。其核心思想是,通过比较模型在“零样本”(zero-shot)和“单样本上下文学习”(one-shot in-context learning, ICL)两种条件下处理同一指令时的表现差异,来识别模型的“知识弱点”。具体来说,如果一个单样本示例(即在上下文中提供的一个相关例子)反而导致模型在处理目标指令时表现更差(损失函数值更高),这恰恰说明该指令触及了模型的知识盲区或能力边界。这样的数据点因此被认为是具有高“价值”的,因为它们最有可能在微调过程中弥补模型的不足。实验结果显示,使用 MIWV 指标筛选出的仅占总数据量 1% 的高质量数据,在多个基准测试中,其微调效果能够持平甚至超过使用全量数据进行微调的模型。该方法提供了一种无需额外模型训练、全自动化的数据选择策略,旨在提升指令微调的效率和效果。
这篇文章的思路和之前分享的《NVIDIA 提出 CoDeC:通过 In-Context Learning 来区分模型“记忆”还是“泛化”》(https://www.mlpod.com/1234.html) 思路很像,不过应用不同。CoDeC 认为如果模型已经过拟合了一个任务,如果再引入相似任务做 ICL 会导致高 Loss。按照此想法,MIWV 可能是在某种程度上减少过拟合。
1. 引言
指令微调(Instruction Tuning)已成为提升预训练大语言模型(LLM)遵循人类指令、完成特定任务能力的关键技术。通过在“指令-响应”格式的数据集上进行有监督微调,模型能够更好地理解用户意图,生成更具相关性和个性化的内容。
然而,指令微调的成功在很大程度上依赖于训练数据的质量和模型自身的基础能力。当前的研究趋势一度倾向于构建规模更大、更多样化、更复杂的指令数据集。这种“多多益善”的策略虽然在一定程度上提升了模型性能,但也带来了巨大的人力和物力成本。更重要的是,盲目地扩大数据集规模并不能保证理想的效果。低质量、冗余或包含噪声的数据反而可能干扰模型的学习过程,损害其最终的指令遵循能力。
因此,研究界的关注点逐渐从“数量”转向“质量”,即如何设计有效的数据选择策略(Data Selection Strategy),从海量数据中筛选出一个小而精的高质量子集,以实现高效且经济的指令微调。一些研究工作通过引入复杂的评分函数来评估数据质量,或者利用模型推理能力来筛选样本。
本文正是在这一背景下,提出了一种新的数据选择视角。作者认为,最有价值的微调数据,应该是那些能够最大程度暴露并弥补模型现有能力短板的数据。基于此,他们提出了一个名为“模型指令弱点值”(MIWV)的度量指标,旨在量化每条指令数据对于增强特定 LLM 能力的重要性。
2. 模型指令弱点值(MIWV)
该论文提出的方法框架包含三个核心步骤:单样本示例检索、样本重要性计算(MIWV)和高质量数据筛选。
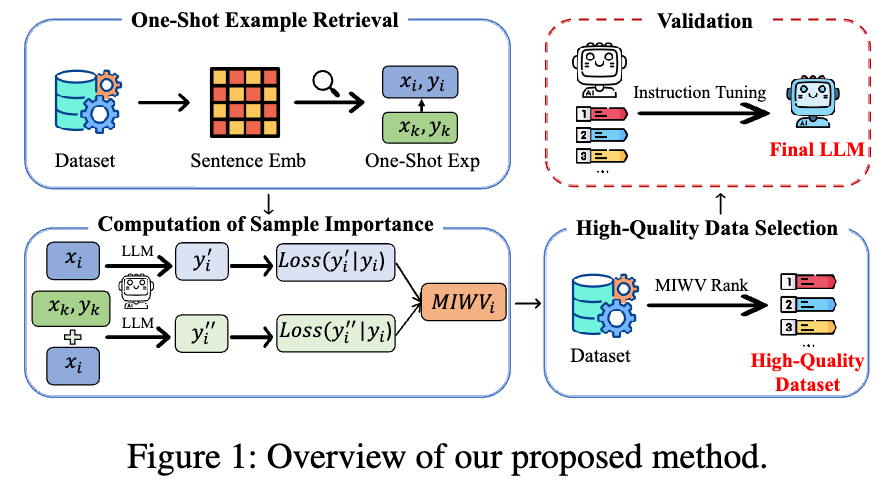
2.1 单样本示例检索
为了评估模型在有上下文参考的情况下处理指令的能力,该方法首先需要为数据集中的每一条指令 找到一个单样本示例(one-shot example)。这里的 代表指令输入, 代表期望的响应输出。
具体实现流程如下:
-
向量化表示:首先,使用一个预训练的嵌入模型(Embedding Model),例如
bge-en-large,将数据集中所有指令输入 转换为高维向量 。这个向量 可以是指令 中所有 token 嵌入向量的平均值,公式如下:
其中 是嵌入模型, 是指令 中的 token 数量。
-
相似度计算:对于每个指令 ,计算其向量表示 与数据集中所有其他指令的向量表示 (其中 )之间的余弦相似度(cosine similarity):
-
确定最佳示例:找出与 具有最高相似度的指令 ,即:
那么,这个最相似的指令-响应对 就被选为 的单样本示例。
2.2 样本重要性计算(MIWV)
这是整个方法的核心。MIWV 的设计初衷是量化一条指令在多大程度上暴露了模型的“弱点”。这里的“弱点”是通过比较模型在有、无单样本示例这两种情况下的表现差异来衡量的。
-
零样本损失(Zero-Shot Loss):首先,计算模型在没有任何上下文提示的情况下,直接根据指令 生成响应 的损失。这个损失通常是标准的自回归模型负对数似然损失(Negative Log-Likelihood Loss),计算的是在给定指令和已生成的部分响应的条件下,预测下一个正确 token 的难度。公式如下:
其中 是真实响应 的长度, 是 的第 个 token。这个 值越高,说明模型在没有帮助的情况下,独立完成该指令的难度越大。
-
单样本损失(One-Shot Loss):接下来,将上一步检索到的单样本示例 作为上下文 提供给模型,然后再次计算模型根据指令 生成响应 的损失。
对应的损失函数为:
其中 代表由 构成的上下文。这个损失衡量了模型在获得一个相关示例的“提示”后,完成任务的能力。
-
计算 MIWV:MIWV 被定义为单样本损失与零样本损失之差:
MIWV 的直观解释:
-
高 MIWV 值:。这意味着,提供一个被认为是“最相关”的示例后,模型反而更困惑了,生成正确响应的损失变得更高。这强烈暗示了该指令 触及了模型的知识盲区。模型不仅自己不会,甚至看到一个相似的例子后,也无法进行有效的类比或泛化,反而受到了干扰。这样的数据点,对于微调来说价值极高,因为它们精确地指出了模型需要学习和改进的方向。 -
低或负 MIWV 值:。这说明单样本示例对模型起到了积极的提示作用,降低了任务难度。这表明该指令类型在模型的能力范围之内,通过上下文学习就能较好地处理。因此,这类数据对于微调的“增量价值”相对较低。
-
2.3 高质量数据筛选
最后一步非常直接:
-
为数据集中的所有样本计算出 MIWV 值。 -
对所有样本按 MIWV 值从高到低进行排序。 -
选择排名最高的 top-K% 的数据作为最终用于指令微调的高质量子集。
通过这种方式,该方法筛选出了一批最能“挑战”模型当前能力的指令数据,旨在以最高效的方式提升模型性能。
3. 实验设置与结果分析
为了验证 MIWV 方法的有效性,论文进行了一系列详尽的实验。
3.1 实验配置
-
训练数据集:主要使用了两个公开的指令微调数据集: -
Alpaca (52k 条样本) -
WizardLM (约 64k 条样本)
-
-
测试数据集:使用了多个广受认可的测试集来评估模型性能,包括 Vicuna, Koala, WizardLM (test), Self-instruct, 和 LIMA。 -
基础模型:实验在多个 LLaMA 系列模型上进行,包括 LLaMA-7B, LLaMA2-7B/13B,以及为了验证跨架构有效性而引入的 Qwen2.5-7B/14B。 -
评估方法: -
成对比较(Pair-wise Comparison):使用 GPT-4 作为裁判,比较由筛选数据微调后的模型和由全量数据微调后的模型生成的响应,计算“胜率(Win Rate)”。 -
Huggingface Open LLM Leaderboard:在一个包含 ARC, HellaSwag, MMLU, TruthfulQA 等多个基准的排行榜上评估模型综合能力。 -
AlpacaEval:一个自动化的评估框架,用于衡量模型遵循指令的能力。
-
3.2 主要结果
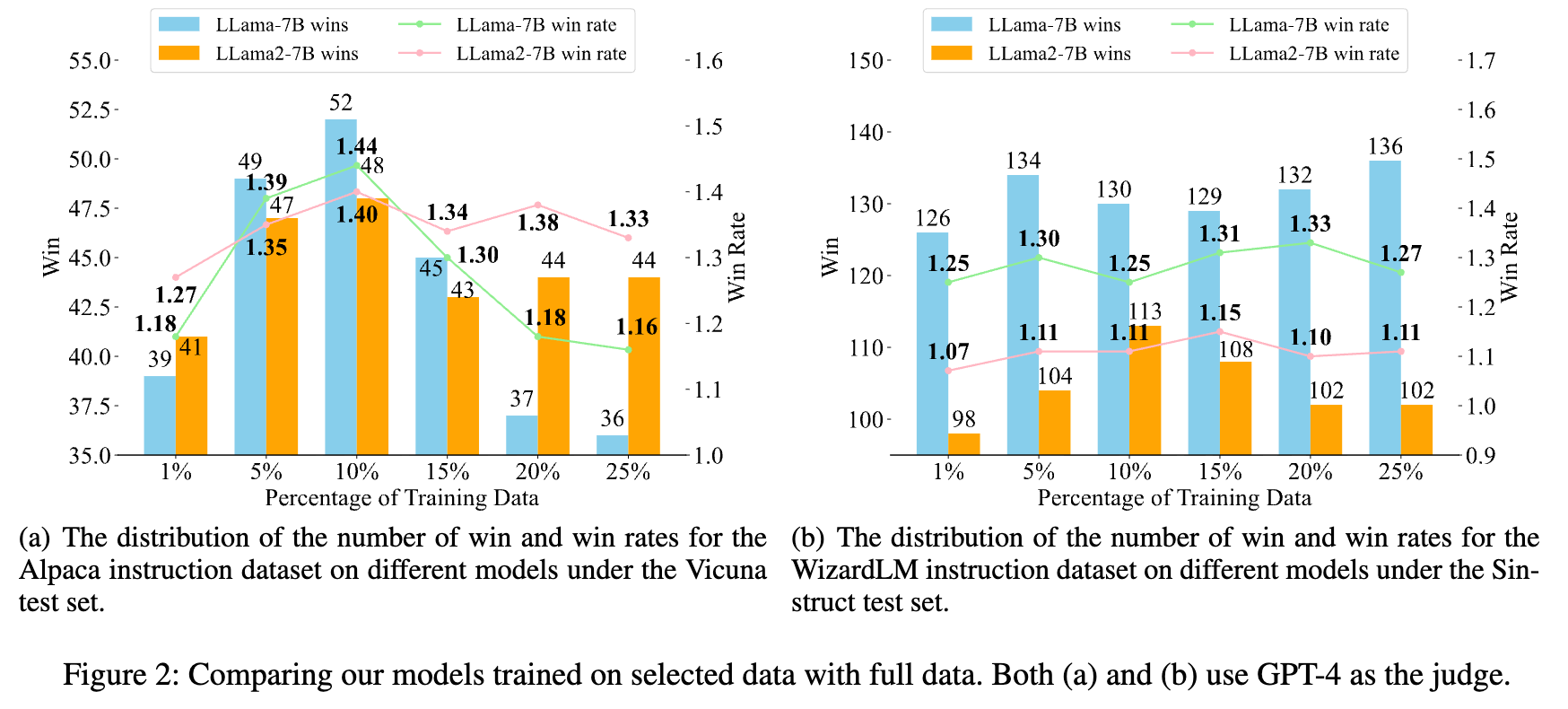
实验结果在很大程度上支持了 MIWV 方法的有效性。
-
“少即是多”:最引人注目的发现在于,仅使用通过 MIWV 筛选出的 top 1% 数据进行微调,其模型性能在多个测试集上就超过了使用 100% 全量数据微调的基线模型。如表 1 所示,在 Alpaca 数据集上,使用 LLaMA2-7B 模型,1% 的数据(520 条)在 AlpacaEval 上的得分是 39.50,远高于全量数据(52k 条)的 27.75。
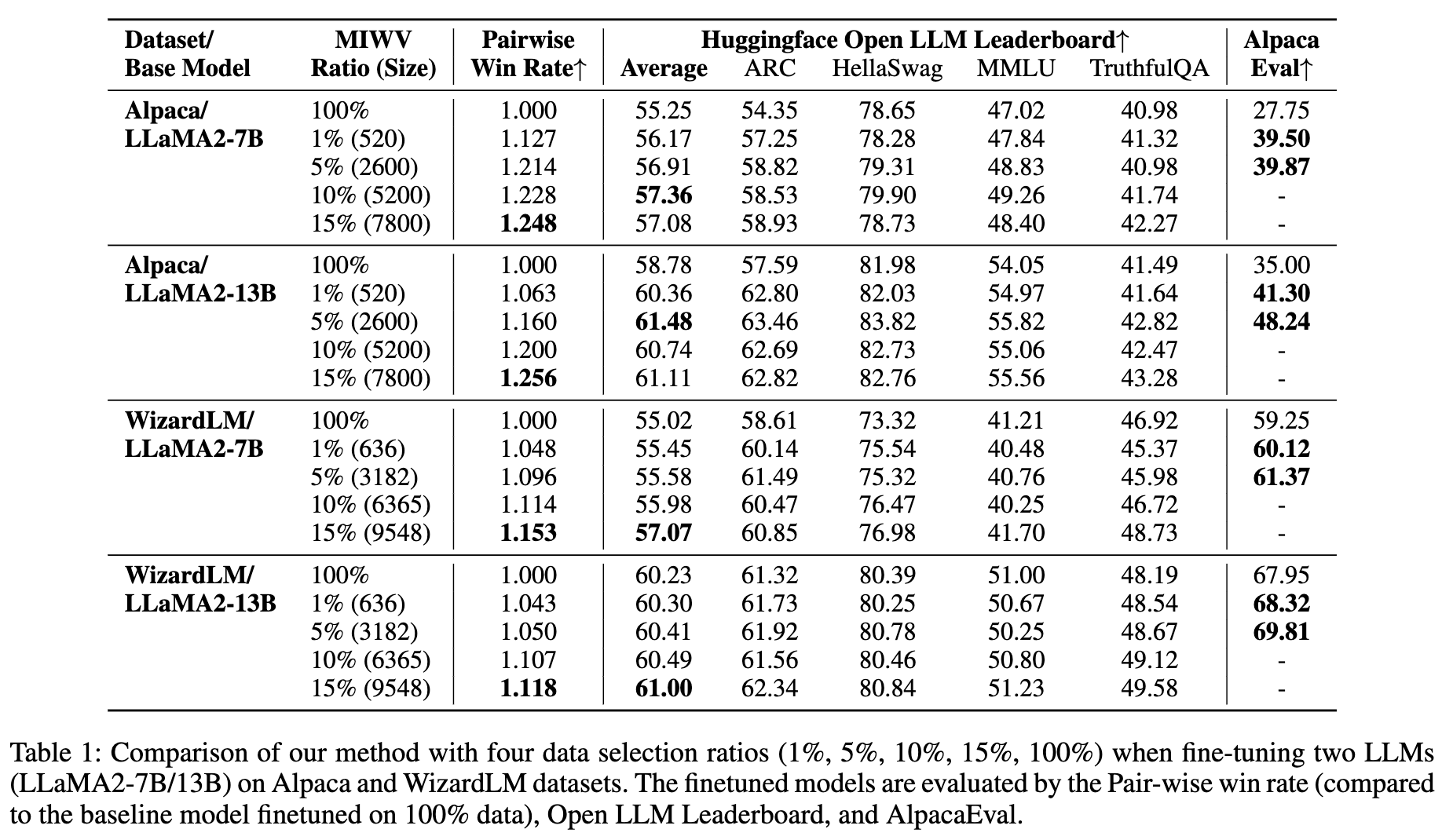
-
性能峰值与下降趋势:有趣的是,随着用于微调的数据比例增加(例如从 1% 增加到 25%),模型的胜率并非单调递增。在某些实验中,性能在 10% 或 15% 的数据比例时达到峰值,之后随着数据量的进一步增加,性能反而呈现下降趋势。作者推断,这可能是因为更大比例的数据中包含了更多的噪声或与已有知识冲突的样本,对模型学习造成了干扰,从而验证了数据选择的必要性。
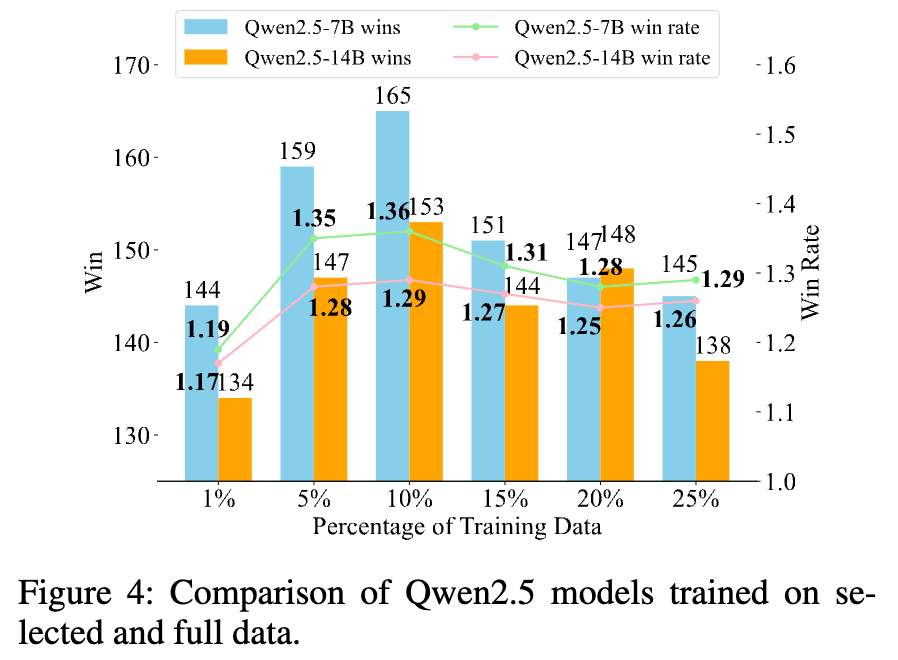
-
跨模型和数据集的有效性:该方法不仅在 LLaMA 系列模型上表现出色,在架构不同的 Qwen2.5 模型上也展示了良好的泛化能力(图 4),证明了其通用性。无论是在 Alpaca 还是在更复杂的 WizardLM 数据集上,MIWV 都表现出了一致的有效性。
3.3 与其他方法的比较
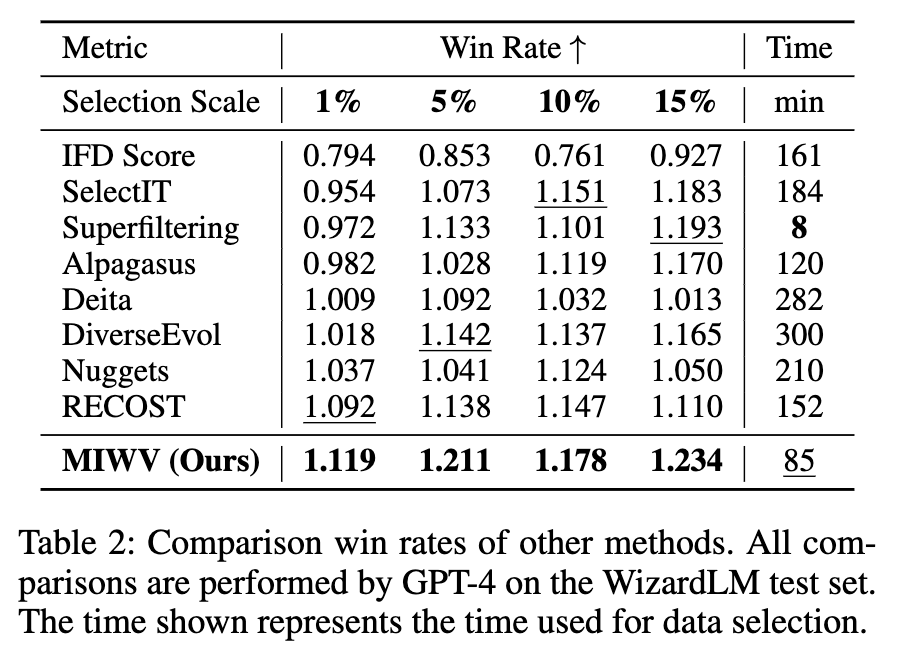
论文将 MIWV 与 IFD Score, SelectIT, Superfiltering, Alpagasus, Deita, DiverseEvol, Nuggets, RECOST 等多种主流的数据选择方法进行了比较。结果显示:
-
性能:MIWV 在胜率上表现突出,超过了大多数对比方法。 -
效率:MIWV 在数据选择所需时间上具有竞争力。它不需要像 SelectIT或DiverseEvol那样进行额外的模型训练,也不像Alpagasus或Deita那样依赖于外部 API(如 ChatGPT)进行数据标注,从而避免了 API 速率限制和高昂成本。其主要计算开销在于全量数据的向量嵌入和两次模型前向传播,总体而言效率较高。
3.4 消融研究
为了进一步验证方法设计的合理性,论文进行了消融实验。
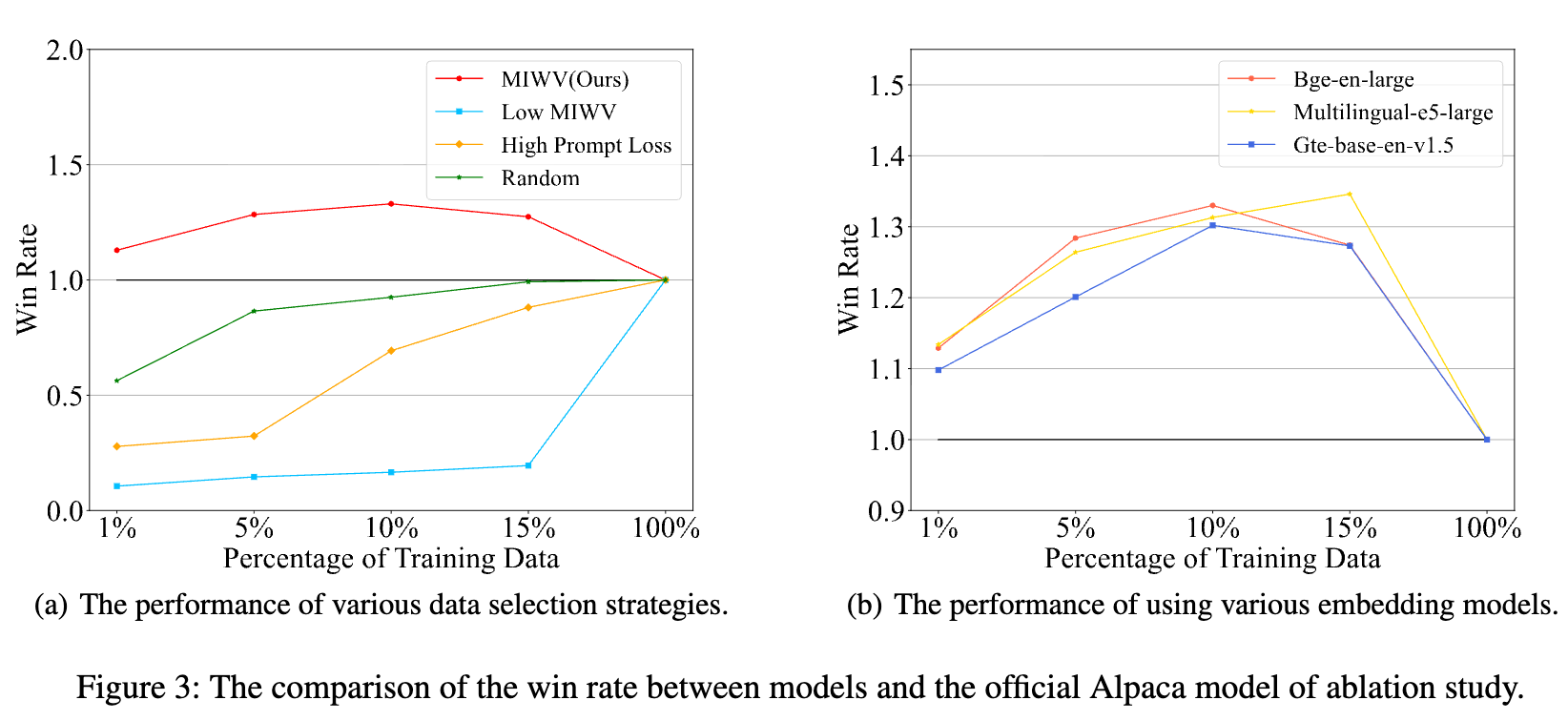
-
数据选择策略消融:图 3(a) 不同数据选择策略的性能对比。将 MIWV 与其他三种简单的选择策略进行了对比:
-
随机选择:性能远低于基线。 -
高 Prompt Loss 选择:选择那些零样本损失 最高的样本。这种策略表现不佳,说明“难”的样本不等于“有价值”的样本。 -
低 MIWV 选择:选择 MIWV 值最低的样本。结果显示其性能最差,从反面证明了 MIWV 指标的有效性。
-
-
嵌入模型消融:图 3(b) 使用不同嵌入模型的性能对比。实验替换了用于检索单样本示例的嵌入模型,包括 Bge-en-large, Multilingual-e5-large 和 Gte-base-en-v1.5。结果表明,无论使用哪种嵌入模型,MIWV 方法都能稳定地提升模型性能,显示了其对嵌入模型的鲁棒性。
4. 一些值得探讨的地方
4.1 “弱点”定义的可靠性
MIWV 的核心假设是: 精确地量化了模型的“弱点”。然而,这个差值增大的原因可能不止一种。
-
噪声示例的干扰:单样本示例的检索机制完全依赖于向量空间的余弦相似度。如果检索到的“最相似”示例 本身是一个低质量、有噪声或格式错误的样本,它很可能会对模型产生误导,从而人为地推高 。在这种情况下,MIWV 筛选出的可能并非是真正触及模型能力边界的“有价值”样本,而仅仅是受到了一个“坏邻居”影响的样本。 -
相似度的局限性:语义相似不完全等同于任务逻辑相似。嵌入模型计算出的向量相似度可能只捕捉了表层文本的相似性,而忽略了指令背后的推理复杂性或领域特异性。一个在文本上相似的例子,在解决问题的逻辑上可能毫无帮助,甚至相悖,这也可能导致 MIWV 的误判。
4.2 对基础模型 ICL 能力的依赖
该方法有效性的前提是,基础模型本身具备一定程度的上下文学习(ICL)能力。MIWV 正是通过探测这种能力的边界来工作的。如果一个基础模型的 ICL 能力很弱,那么单样本示例 C 对其输出的影响可能非常随机,导致计算出的 MIWV 值缺乏稳定性和可解释性。换言之,该方法可能更适用于那些已经具备较强 ICL 能力的模型。
4.3 计算成本问题
论文声称该方法是高效的,这主要是相对于那些需要额外训练或调用昂贵 API 的方法而言。然而,MIWV 自身的计算成本也不容忽视,尤其是在处理超大规模数据集时:
-
全局嵌入:需要对整个数百万甚至数十亿级别的指令数据集进行向量嵌入。 -
相似度搜索:对于数据集中的每一个样本,都需要与其他所有样本计算相似度,这是一个 复杂度的过程(尽管可以通过近似最近邻搜索等技术优化到 或更低,但开销依然巨大)。 -
两次前向传播:每个样本都需要在基础 LLM 上进行两次完整的前向传播(一次 zero-shot,一次 one-shot)来计算损失。当 巨大时,这同样是一笔计算开销。
因此,虽然避免了模型训练,但在“数据选择”阶段的计算量依然庞大,其“高效性”是相对的。
4.4 “最优”数据比例的不确定性
实验结果显示,性能最优的数据比例并非固定值,有时是 10%,有时是 15%。这表明“最优子集”的大小可能依赖于具体的数据集、任务领域和基础模型。在实际应用中,如何确定这个最佳比例本身就成了一个新的超参数搜索问题,缺乏先验的指导。仅仅选择 top 1% 可能是一个在多数情况下表现不错的经验法则,但未必是真正的最优解。
4.5 评估方法的潜在偏见
实验大量依赖 GPT-4 作为裁判进行成对比较。尽管这是一种常用的评估方式,但其本身存在局限性。GPT-4 的判断标准、潜在的立场偏见(position bias)、以及其自身的能力上限都可能影响评估结果的客观性和可复现性。完全依赖单一闭源模型作为评估核心,使得研究结论的稳健性打了一定的折扣。
5. 结论
总而言之,《Importance-Aware Data Selection for Efficient LLM Instruction Tuning》这篇论文提出了一种创新且有效的指令微调数据选择方法。其核心贡献在于设计了 MIWV 这一新颖的度量指标,它通过巧妙地利用模型的上下文学习行为来反向探测其能力弱点,从而筛选出最具微调价值的数据。该方法逻辑清晰,无需复杂的额外组件,并在多个实验中证明了其能够以少量数据实现超越全量数据微调的性能,为高效利用数据资源提供了新的思路。
往期文章:


