今天深度解读一篇来自2024年阿里的有关于大模型数据配比论文,放在今天也有比较大的参考价值。
我们做SFT的时候都关注过这些问题:我们如何才能通过 SFT 有效地同时提升模型的多种能力?当我们将用于数学推理、代码生成和通用人类对齐(General Human Alignment)的 SFT 数据混合在一起时,它们之间会发生怎样的相互作用?是相互促进,还是彼此掣肘?数据量、混合比例、模型规模以及微调策略在其中又扮演着怎样的角色?
为了系统地回答这些问题,来自2024年阿里巴巴的研究团队发表了一篇题为《How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition》的论文。该研究深入探究了在 SFT 阶段,不同来源(数学、代码、通用)的数据组合对模型能力影响的复杂关系。文章通过大量详实的实验,揭示了不同能力独特的扩展规律(Scaling Law),分析了多任务学习中存在的“性能冲突”与“低资源增益”现象,并最终提出了一种名为“双阶段混合微调”(Dual-stage Mixed Fine-tuning, DMT)的有效策略,旨在平衡模型的通用与专用能力,缓解灾难性遗忘问题。

-
论文标题:How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition -
论文链接:https://arxiv.org/pdf/2310.05492
本文将对这篇内容翔实的研究进行一次深度解读,详细剖析其研究背景、实验设计、核心发现和实践启示,希望能为从事大模型研究与开发的同行们提供有价值的参考。
研究背景与核心动机
在深入探讨实验细节之前,我们有必要先理解这项研究背后的几个关键概念及其面临的挑战。
1. 监督微调(SFT):对齐模型与人类意图的关键桥梁
预训练后的大语言模型,尽管已经从海量文本中学到了丰富的世界知识和语言规律,但它们本质上是一个“文本补全”机器。它知道如何根据前面的文本生成后续最有可能出现的词元,却不一定知道如何作为一个“助手”来回答问题或执行指令。
SFT 的作用就是弥合这一差距。通过使用格式化的指令数据进行微调,模型学会了识别指令、理解任务并生成符合期望的、有帮助的回答。这个过程不仅激活了模型在特定任务上的潜力,更是将其行为与人类的价值观和期望对齐的关键一步。
本文所关注的三种核心能力,正是通过 SFT 得以显著增强的:
-
数学推理能力:这不仅要求模型具备计算能力,更考验其逻辑推理、问题分解和符号理解的复杂认知能力。 -
代码生成能力:这是一个高度结构化的任务,要求模型理解编程语言的语法、库函数以及算法逻辑,具有极高的实用价值。 -
通用人类对齐能力:这是一种更宽泛的能力,涵盖了遵循复杂指令、进行多轮对话、扮演角色、内容创作等,是衡量一个模型是否“好用”的综合指标。
2. 多任务学习的“双刃剑”:性能冲突与灾难性遗忘
当我们的目标是构建一个“全能模型”时,一个直观的想法就是将所有相关任务的 SFT 数据混合在一起,进行“多任务学习”(Multi-task Learning)。然而,这个看似简单的方法在实践中却是一把双刃剑。
性能冲突(Performance Conflicts):不同任务的数据在分布、格式和目标上可能存在巨大差异。例如,数学推理数据充满了严谨的逻辑链和符号运算,而通用对话数据则更加口语化和多样化。当模型试图同时学习这些异质数据时,可能会发生“能力竞争”。一个任务的学习过程可能会干扰到另一个任务,导致模型在所有任务上的表现都不如单独训练时出色。这就像让一个人同时学习微积分和莎士比亚戏剧,如果教学方法不当,他可能两门都学得一知半解。
灾难性遗忘(Catastrophic Forgetting):这是多阶段学习或顺序学习中的一个经典问题。如果我们采用顺序微调的策略,比如先用代码数据训练,再用数学数据训练,最后用通用数据训练,模型在学习新知识时,很容易忘记之前学到的技能。当模型完成通用对话的微调后,它可能已经忘记了如何高效地生成代码,因为模型的参数为了适应新任务而进行了大幅调整,覆盖了旧任务的知识。
理解了这些挑战,我们就更能体会到这项研究的重要性。它不仅仅是简单地“混合数据做实验”,而是试图系统性地解开数据组合、模型能力和训练策略之间的内在规律,为构建更强大的通用大模型提供科学的指导。
实验设计:量化数据组合的影响
为了确保研究的严谨性和结论的可靠性,作者设计了一套周密的实验方案。
1. 模型选择
研究采用了开源社区广泛使用的 LLaMA 模型系列,涵盖了三种不同的参数规模:7B、13B 和 33B。选择不同规模的模型,旨在观察各种现象是否具有尺度不变性,即“模型规模的扩大是否会改变或缓解数据组合带来的影响”,这对于理解大模型的扩展定律(Scaling Laws)至关重要。
2. 核心数据集与能力对应
研究选择了三个代表性的公开数据集,分别对应前述的三种核心能力:
-
数学推理 (Math Reasoning)
-
SFT 数据集: GSM8K RFT。原始的 GSM8K 是一个包含小学数学应用题的数据集。而 RFT (Reasoning-enhanced Fine-Tuning) 版本通过拒绝采样等方法,为每个问题生成了多个高质量的推理路径,数据质量更高,更能激发模型的推理能力。 -
评测基准: GSM8K 测试集。通过比较模型生成的最终答案与标准答案是否一致来评估性能,采用 maj@1(贪婪解码一次的准确率)作为指标。
-
-
代码生成 (Code Generation)
-
SFT 数据集: Code Alpaca。这是一个基于 Stanford Alpaca 构建的、专门用于代码生成的指令微调数据集,包含了约 2 万条代码相关的指令和回答。 -
评测基准: HumanEval。这是一个经典的 Python 代码生成评测集,包含 164 个编程问题。模型需要为每个问题生成一个完整的函数体,并通过单元测试来检验其正确性。
-
-
通用人类对齐 (General Human Alignment)
-
SFT 数据集: ShareGPT。这是一个从网络上收集的用户与 ChatGPT 的真实多轮对话历史记录,内容包罗万象,是训练模型通用对话和指令遵循能力的常用高质量数据集。 -
评测基准: MT-Bench。这是一个精心设计的多轮对话评测基准,它向模型提出一系列具有挑战性的问题(如写作、角色扮演、推理、数学等),并使用强大的 GPT-4 模型作为裁判,来对模型的回答进行打分,从而综合评估其作为聊天助手的能力。
-
3. 四个核心研究问题 (Research Questions, RQs)
整个研究围绕以下四个层层递进的问题展开:
-
RQ1: 单一能力如何随着 SFT 数据量的增加而变化?(基线分析) -
RQ2: 当混合这三种能力的数据进行 SFT 时,是否存在性能冲突?(现象观察) -
RQ3: 导致性能冲突的关键因素是什么?是数据绝对数量还是数据混合比例?(原因探究) -
RQ4: 不同的 SFT 策略(如顺序学习、混合学习)对最终模型性能有何影响?(方法探索)
通过回答这四个问题,论文构建了一个从现象到本质、再到解决方案的完整研究闭环。
核心发现:揭示数据组合的内在规律
接下来,我们将逐一解析论文针对上述四个核心问题的实验过程和重要发现。
RQ1: 单一能力的扩展规律各不相同
在混合数据之前,首先需要建立一个基线:如果只用一种类型的数据进行微调,模型的相应能力会如何随着数据量的变化而提升?
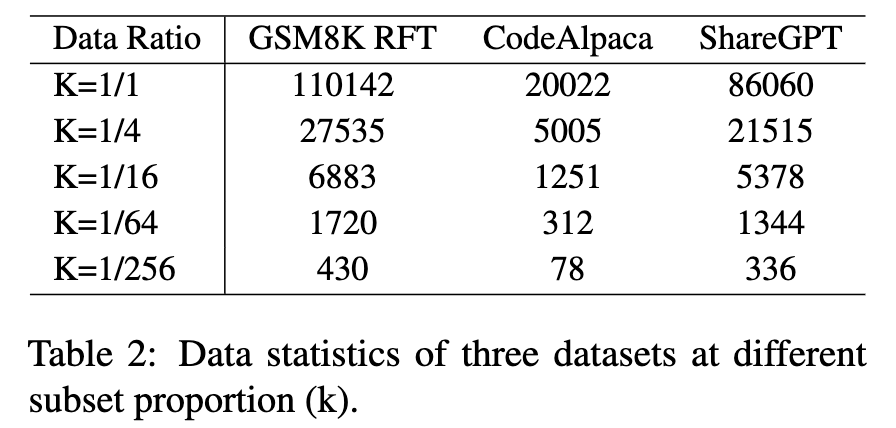
实验设计:研究人员将每种 SFT 数据集(GSM8K RFT, Code Alpaca, ShareGPT)按 1 (全部), 1/4, 1/16, 1/64, 1/256 的比例进行采样,分别对 LLaMA 的 7B, 13B, 33B 模型进行微调,并观察其在对应评测基准上的性能变化。

实验发现:
-
不同能力展现出迥异的扩展模式:
-
数学推理能力:与数据量呈现出非常清晰的正相关关系。数据越多,模型性能越强。这表明数学推理是一项需要大量高质量数据来“喂养”的复杂技能。 -
通用对齐能力:表现出“早熟”和“平顶”的特点。仅用少量数据(约 1000 个样本,对应 1/256到1/64的比例),模型就能获得不错的通用对话能力。但当数据量超过某个阈值(约1/64)后,性能提升变得非常缓慢,逐渐进入平台期。这一发现与 LIMA 等研究的结论(“Less is More for Alignment”)相呼应,即高质量的对齐数据,少量即可有效。 -
代码生成能力:在小模型(7B, 13B)上,其扩展曲线显得不那么规则,甚至有些波动。但在最大的 33B 模型上,曲线则呈现出更平滑的对数线性增长趋势。研究者推测,这可能是因为 Code Alpaca 数据集与 HumanEval 评测集在数据分布上存在差异,而更大规模的模型凭借其更强的泛化能力,能够更好地跨越这种分布差异,捕捉到底层的编程知识。
-
-
模型规模效应显著:总体而言,在数据量相同的情况下,参数规模更大的模型通常表现更好。这符合我们对大模型“越大越强”的普遍认知。
这一部分的结论为后续研究奠定了重要基础:不同能力对 SFT 数据的“胃口”和“消化效率”是不同的。
RQ2: 混合数据的“冰与火之歌”——低资源增益与高资源冲突
了解了单一能力的基线后,关键问题来了:把它们混合在一起会发生什么?
实验设计:研究人员将三种数据集按照相同的比例(例如,各取 1/16)混合,形成一个总数据量不断变化的混合数据集。然后用这个混合数据集进行微调,并将其性能与 RQ1 中使用相同数据量的单一数据集微调的结果进行对比。
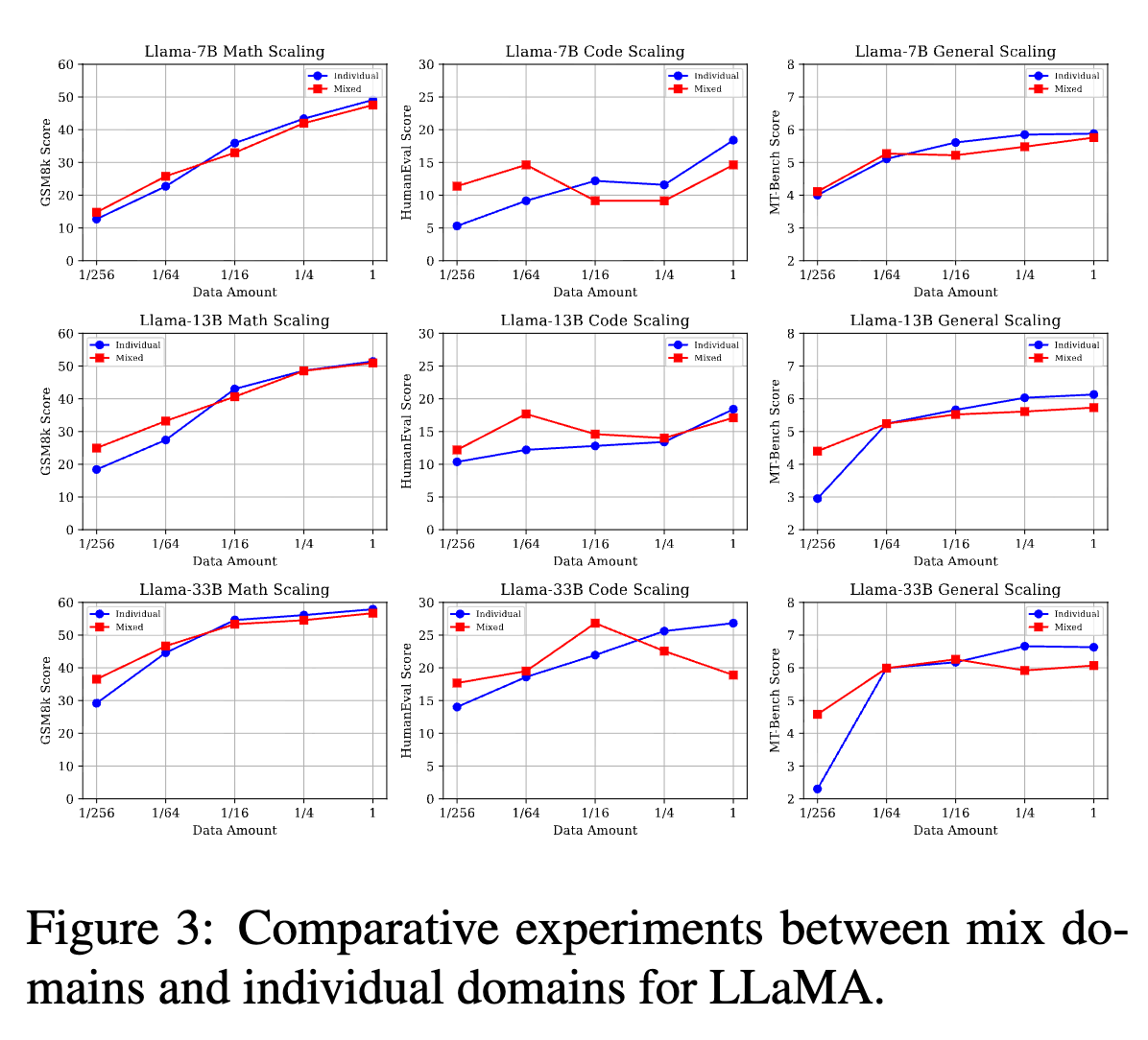
实验发现:
一个非常有趣的“反转”现象出现了,它取决于数据资源的多少。
-
高资源下的性能冲突 (High-resource Conflict):当使用大量混合数据(例如,每种数据集都使用全部或
1/4)进行微调时,模型在所有三个任务上的表现,几乎都劣于只使用对应单一任务数据进行微调的模型。这意味着,在数据充足的情况下,来自其他任务的数据起到了“噪声”或“干扰”的作用,导致了明显的性能冲突。 -
低资源下的协同增益 (Low-resource Synergy):与直觉相反,当使用的混合数据量非常少时(例如,每种数据集只用
1/256),情况发生了逆转。此时,用混合数据微调的模型,其性能在各个任务上反而优于用同样稀少的单一任务数据微调的模型。这表明,在数据稀缺的情况下,多样化的数据可以作为一种有效的正则化手段,帮助模型学习到更具泛化性的特征,实现了“三个和尚有水喝”的协同效应。 -
“转折点”的存在:随着数据量从少到多,性能曲线会经历一个从“增益”到“冲突”的转折点。对于 LLaMA-7B 模型,这个转折点大约出现在数据量为
1/64到1/16的区间内。 -
模型规模的影响:随着模型规模的增大(从 7B 到 33B),在低资源设置下的“协同增益”现象变得更加显著。这说明,更大的模型更擅长从少量、多样化的数据中汲取养分。
这个发现极具启发性:多任务 SFT 的效果并非一成不变,而是与数据量密切相关。简单地将所有数据混合在一起,在数据充足时可能是一种次优策略。
RQ3: 性能冲突的根源——数据“量”而非“比”
既然在高资源下会产生性能冲突,那么冲突的根源是什么?是因为其他任务的绝对数据量太多了,还是因为它们与目标任务的数据比例失衡了?
实验设计:为了解耦“数据量”和“数据比例”这两个变量,研究者设计了三组精巧的对比实验。他们将数学和代码视为“专业能力”,将通用对话视为“通用能力”。
-
实验组 1 (固定专业,缩放通用) :使用全部的数学和代码数据,同时改变通用数据的比例(从 1/256到1)。 -
实验组 2 (固定通用,缩放专业) :使用全部的通用数据,同时改变数学和代码数据的比例。 -
实验组 3 (固定少量通用,缩放专业) :模仿 LIMA 的设置,只使用 1/64的通用数据,然后改变专业数据的比例。
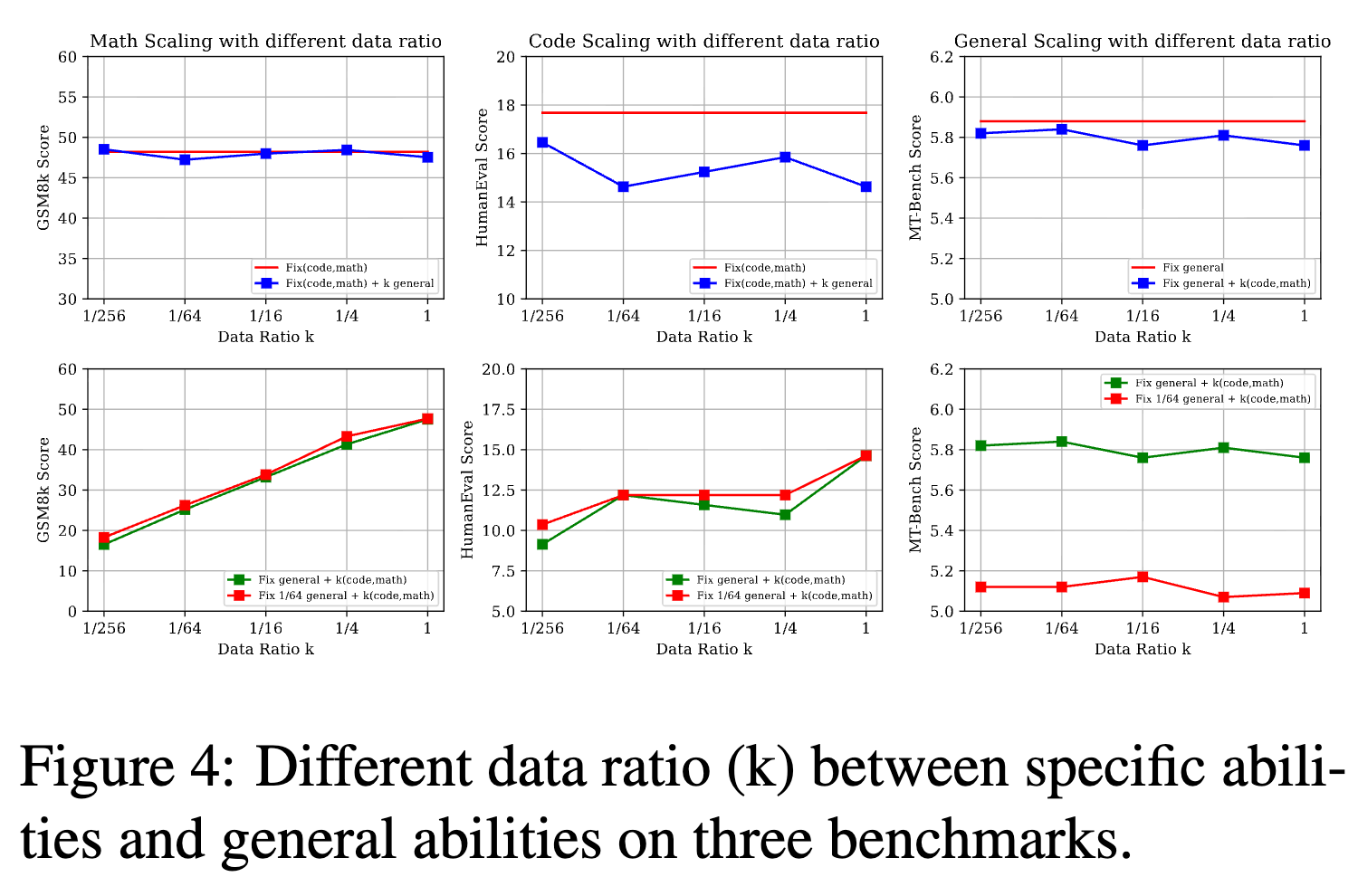
实验发现:
-
数据绝对量是主导因素:实验结果清晰地表明,模型的性能主要受到其领域内(in-domain)数据绝对数量的影响。在大多数情况下,只要领域内数据量固定,改变其他任务数据的比例(即数据 ratio),对模型性能的影响非常小。例如,在实验组 2 中,即使专业数据的比例从
1/256增加到1,通用对话能力(MT-Bench 分数)也几乎没有变化。 -
数据比例的微弱影响:数据比例只在一种情况下会产生一些可见的波动——即不同任务的数据存在一定的相似性或重叠。例如,ShareGPT 数据中本身就包含了一些用户咨询代码问题的对话。当混合 Code Alpaca 数据时,由于数据格式和分布的差异,可能会加剧这种相似特征的冲突,导致代码能力(HumanEval 分数)出现一些波动。但即便如此,这种影响也远小于数据绝对量带来的影响。
这个结论至关重要,它告诉我们:在处理多任务 SFT 冲突时,我们应该更关注每个任务是否有足够量的训练数据,而不是过分纠结于它们之间的精确比例。
RQ4: 寻求最优解——不同 SFT 策略的比较与改进
既然简单的混合训练存在问题,那么有没有更好的训练策略来平衡多种能力呢?
实验设计:研究者比较了四种不同的 SFT 策略,其中第四种是他们基于前述发现提出的新方法。
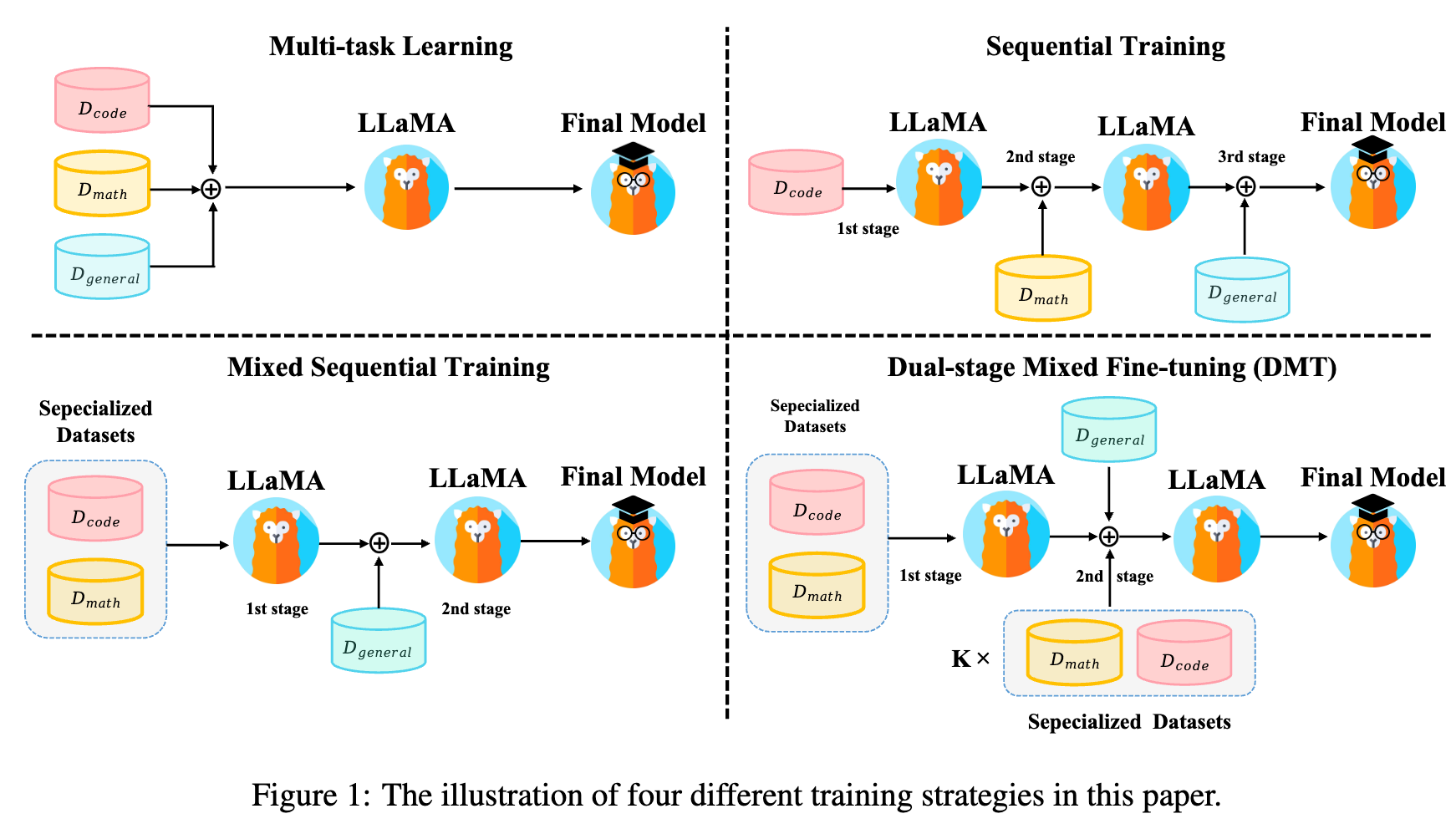
-
多任务学习 (Multi-task Learning) :即前述的简单混合训练。 -
顺序训练 (Sequential Training) :按顺序依次在不同数据集上微调。例如, 代码 -> 数学 -> 通用。 -
混合顺序训练 (Mixed Sequential Training) :先将专业能力的数据(代码+数学)混合进行第一阶段微调,然后进行通用能力的第二阶段微调。 -
双阶段混合微调 (Dual-stage Mixed Fine-tuning, DMT) :这是作者提出的新策略。
策略背后的思考逻辑:
-
多任务学习的缺点(RQ2):高资源下有性能冲突。 -
顺序训练的缺点:会导致严重的灾难性遗忘。模型在完成最后阶段的通用能力训练后,几乎会完全忘记第一阶段学习的专业能力。 -
混合顺序训练:同样无法避免灾难性遗忘,第二阶段的通用数据会“冲刷”掉第一阶段学习到的专业知识。
DMT 策略的提出:
DMT 策略的设计巧妙地融合了前面所有研究的洞见:
-
从 RQ1 我们知道,专业能力(数学、代码)需要大量数据才能学好。 -
从 RQ2 我们知道,将所有数据一次性混合会导致冲突。 -
从 RQ3 我们知道,少量异构数据并不会严重影响目标任务。 -
从顺序训练的失败我们知道,必须采取措施防止遗忘。
基于此,DMT 策略分为两个阶段:
-
第一阶段:专业能力学习。将全部的专业数据集(代码+数学)混合,对模型进行充分的微调。目标是让模型在这一阶段“学深、学透”专业技能。 -
第二阶段:通用能力对齐与专业能力“唤醒”。将全部的通用数据集(ShareGPT)与一小部分 (a small proportion k) 专业数据集混合,进行第二阶段微tuning。这里的关键在于这个“一小部分 k”。它的作用不是从头学习专业能力,而是作为一种“提醒”或“唤醒机制”,在模型学习通用能力的同时,不断地激活与专业能力相关的神经元,从而有效缓解灾难性遗忘。
实验结果:
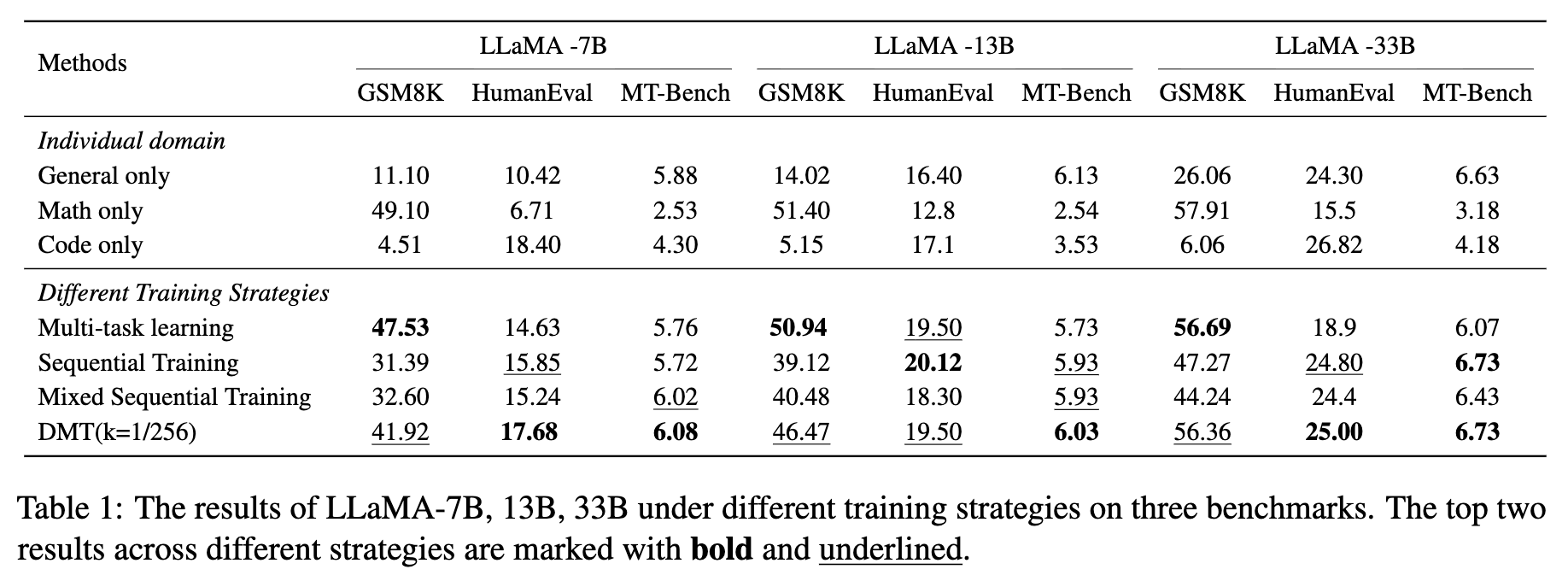
结果证明了 DMT 策略的有效性:
-
与混合顺序训练相比,DMT 策略(当 k=1/256时)在数学和代码能力上取得了大幅度的性能回升。例如,在 LLaMA-33B 模型上,数学能力(GSM8K)得分从 44.24 提升到 56.36,几乎完全恢复到了多任务学习的水平。 -
同时,DMT 策略很好地保持了模型的通用对齐能力。MT-Bench 得分甚至略有提升,说明这种“提醒”机制并未干扰通用能力的学习。 -
最终,DMT 策略在三个任务上取得了最平衡、最出色的综合表现,证明了其在协调多能力学习方面的优越性。
深入讨论与分析
除了对四个核心问题的直接回答,论文还提供了一些更深入的分析,以增强其结论的可信度。
1. SFT 能力的可视化分析
为了直观地理解不同能力在模型内部是如何表示的,研究者使用了 t-SNE 技术对模型中间层的隐藏状态(hidden layer representations)进行降维可视化。
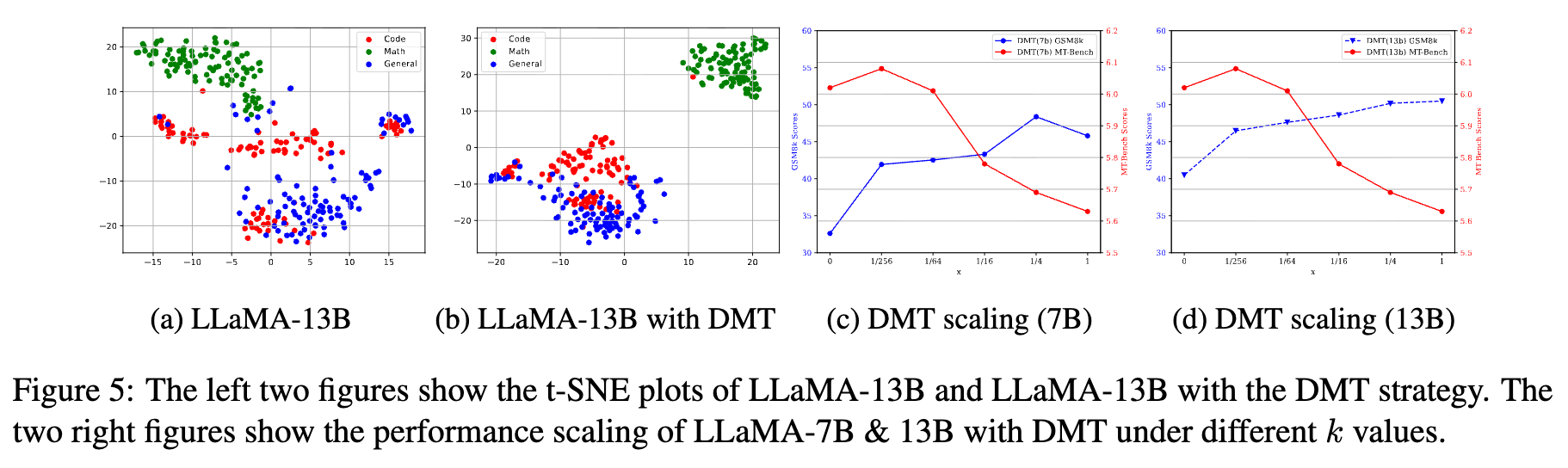
可视化结果显示:
-
在模型内部的“语义空间”中,数学推理的表征能够与其他两种能力很好地区分开,形成独立的簇。 -
然而,代码生成和通用能力的表征则存在相当程度的重叠。这从一个侧面解释了为什么代码和通用能力之间可能更容易发生冲突——因为模型在内部使用了相似的神经回路来处理它们。 -
对比使用 DMT 策略前后的模型,可以发现 DMT 能够更好地保留各个能力簇的独立性,防止它们在第二阶段被完全“同化”。
2. 消融实验:ShareGPT 中的代码/数学数据是关键吗?
一个合理的质疑是:在 RQ2 中观察到的低资源增益现象,会不会仅仅是因为 ShareGPT 数据集里本身就含有一些代码和数学的对话,为模型提供了额外的领域内数据?
为了排除这种可能性,研究者进行了一项消融实验。他们首先使用工具(一个 open-set tagger)将 ShareGPT 中所有与代码和数学相关的对话全部过滤掉,然后用这个“纯净版”的通用数据集重复了 RQ2 的实验。
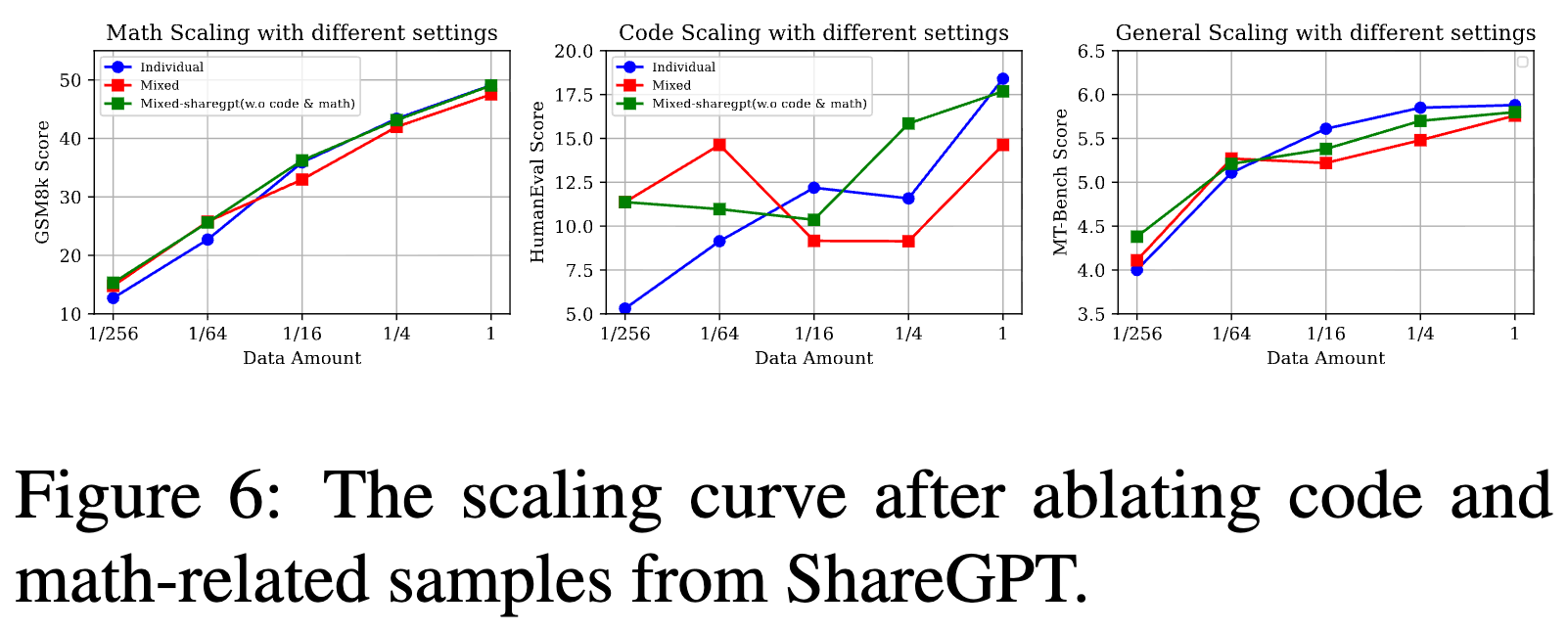
结果显示,即便去除了这些潜在的领域内样本,低资源增益和高资源冲突的现象依然存在。这有力地证明了该现象的普适性,它源于混合不同性质数据本身带来的影响(多样性带来的正则化 vs. 异质性带来的干扰),而非简单的“数据泄露”。
3. DMT 策略中比例 k 的影响
DMT 策略的成功关键在于第二阶段混合的专业数据比例 k。k 值的大小直接影响到“唤醒”效果和对通用能力的干扰程度之间的平衡。
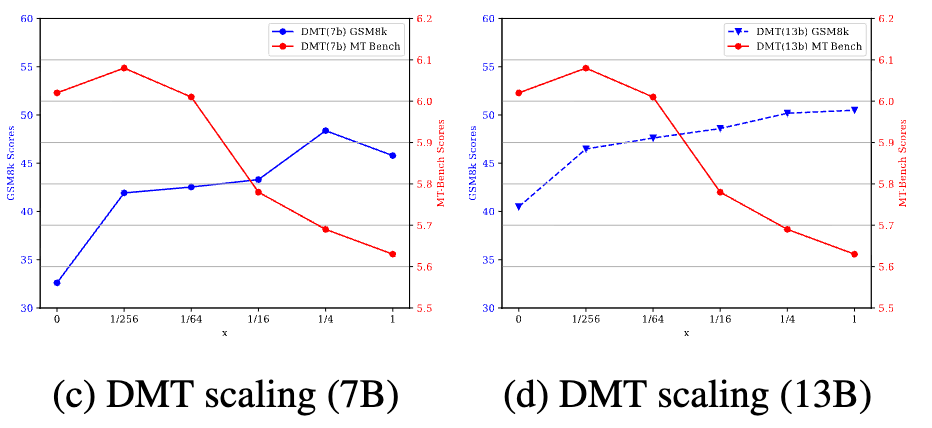
实验分析了 k 从 0 (等同于混合顺序训练) 到 1 变化时模型性能的走势:
-
当 k从 0 增加到一个很小的值(如1/256),专业能力的性能会急剧回升,同时通用能力不受影响,甚至微升。这是最佳区间。 -
随着 k继续增大(例如,超过1/4),专业能力提升逐渐饱和,而通用能力则开始下降。这再次印证了 RQ2 的结论——过多的异构数据会造成性能冲突。
这表明 k 是一个需要根据具体任务和数据进行调整的关键超参数,它控制着模型在“保持通用”和“不忘专业”之间的权衡。
点评
通过一系列系统而深入的实验,这篇论文为我们揭示了监督微调阶段数据组合的复杂动态。其核心结论可以总结如下:
-
能力的扩展规律各异:不同的模型能力(数学、代码、通用对齐)在 SFT 阶段对数据量的需求和响应模式有很大差异。通用能力“早熟”,而专业能力需要持续的“喂养”。 -
数据混合效应与资源量相关:在数据稀缺时,混合多样化的数据能带来性能增益;而在数据充足时,则会导致性能冲突。 -
数据量是冲突主因:性能冲突的根本原因在于异构数据的绝对数量,而非数据间的混合比例。 -
DMT 策略的有效性:作者提出的双阶段混合微调(DMT)策略,通过“先专业学习,后通用对齐并少量唤醒”的方式,能够有效地缓解灾难性遗忘,成功地在单个模型中平衡了多种关键能力。
对于大语言模型的开发者和研究者,这项工作带来了非常明确的实践启示:
-
告别“一锅炖”:在构建多能力模型时,简单地将所有 SFT 数据混合在一起可能不是最佳选择,尤其是在数据资源比较丰富的情况下。 -
分阶段、有策略地进行微调:DMT 提供了一个清晰且被验证有效的框架。先集中火力攻克需要大量数据的专业能力,再通过“少量提醒”的方式融入通用能力,是一种更高效、更可靠的路径。 -
低资源场景下的新思路:对于数据稀缺的场景,混合不同来源的数据反而可能成为一种提升模型泛化能力的有效手段。 -
数据工程的重要性:这项研究再次凸显了数据工程(Data Engineering)在模型能力构建中的核心地位。理解数据的特性、规划数据的配比和使用策略,与模型结构的设计同等重要。
往期文章:


