让每一项优秀工作,都被更多人看见:点击进入投稿通道

-
论文标题:RubricBench: Aligning Model-Generated Rubrics with Human Standards -
论文链接:https://arxiv.org/pdf/2603.01562
TL;DR
随着大语言模型(LLM)从简单的文本补全向复杂的推理和生成任务演进,奖励模型(Reward Models, RMs)面临着严峻挑战。现有的 RM 往往倾向于通过表面特征(如长度、格式、语气)而非实际满足用户意图来通过评估(即 Reward Hacking)。为了解决这一问题,业界开始转向基于评分标准(Rubric-guided)的评估范式。然而,社区缺乏一个统一的基准来衡量这种评估方法的可靠性。
今天解读一篇来自腾讯混元的论文 RubricBench: Aligning Model-Generated Rubrics with Human Standards ,该研究提出了一个包含 1,147 个成对比较的精选基准测试。该基准通过多维过滤管道构建,包含具有细微输入复杂性和误导性表面偏差的困难样本,并针对每个样本提供了专家标注的、基于指令的原子化评分标准。
核心结论:
-
Rubric Gap(评分标准差距):在模型生成评分标准和人类标注评分标准之间存在 27% 的准确率差距。 -
认知错位(Cognitive Misalignment):即便是最先进的模型(SOTA)也难以自主制定有效的评估标准,它们往往关注表面形式而忽略核心约束。 -
Scaling 无效:简单地增加测试时的计算量(生成更多评分规则)无法弥补评分标准质量的缺陷。
1. 背景
1.1 奖励模型的角色变迁
奖励模型(RMs)是 LLM 对齐流程中的核心组件,充当人类偏好的代理。其应用贯穿 LLM 的全生命周期:
-
训练阶段:在 RLHF(Reinforcement Learning from Human Feedback)中为策略优化提供反馈信号。 -
推理阶段:作为验证器(Verifier),用于候选响应的筛选(如 Best-of-N 采样)。
随着 LLM 输出从简单的指令跟随演变为复杂的推理密集型生成(如代码、数学、长文本),传统的标量奖励模型(Scalar RMs)暴露出了局限性。标量 RM 将复杂的偏好压缩为不透明的单一分数,这种缺乏解释性的机制容易导致“奖励黑客”(Reward Hacking)现象,即模型利用虚假相关性(如冗长性、特定的语气)来最大化分数,而非提升实际质量。
1.2 生成式奖励模型与评分标准
为了提高可解释性,领域转向了生成式奖励模型(Generative RMs / LLM-as-a-Judge),利用思维链(CoT)推理来提高信号的可靠性。然而,如果没有明确的约束,这些模型仍然容易进行事后合理化(post-hoc rationalization),即编造理由来支持其有偏见的判断。
因此,最新的范式强调 基于评分标准的评估(Rubric-Guided Evaluation)。通过将模糊的质量定义分解为可验证的原子约束(例如布尔检查项),这种方法旨在将奖励建立在客观信号之上,从而限制优化空间并减少黑客行为。
1.3 现有基准的缺失
尽管该范式被迅速采用,但缺乏能够评估“基于评分标准的评估”可靠性的统一基准。现有的基准(如 RewardBench, HelpSteer3 等)存在以下问题:
-
样本饱和或过时:缺乏区分现代高性能模型所需的复杂性。 -
缺乏评分标准标注:没有人类水平的评分标准作为基准(Ground Truth),无法测量模型生成的评分标准与理想标准之间的差距。
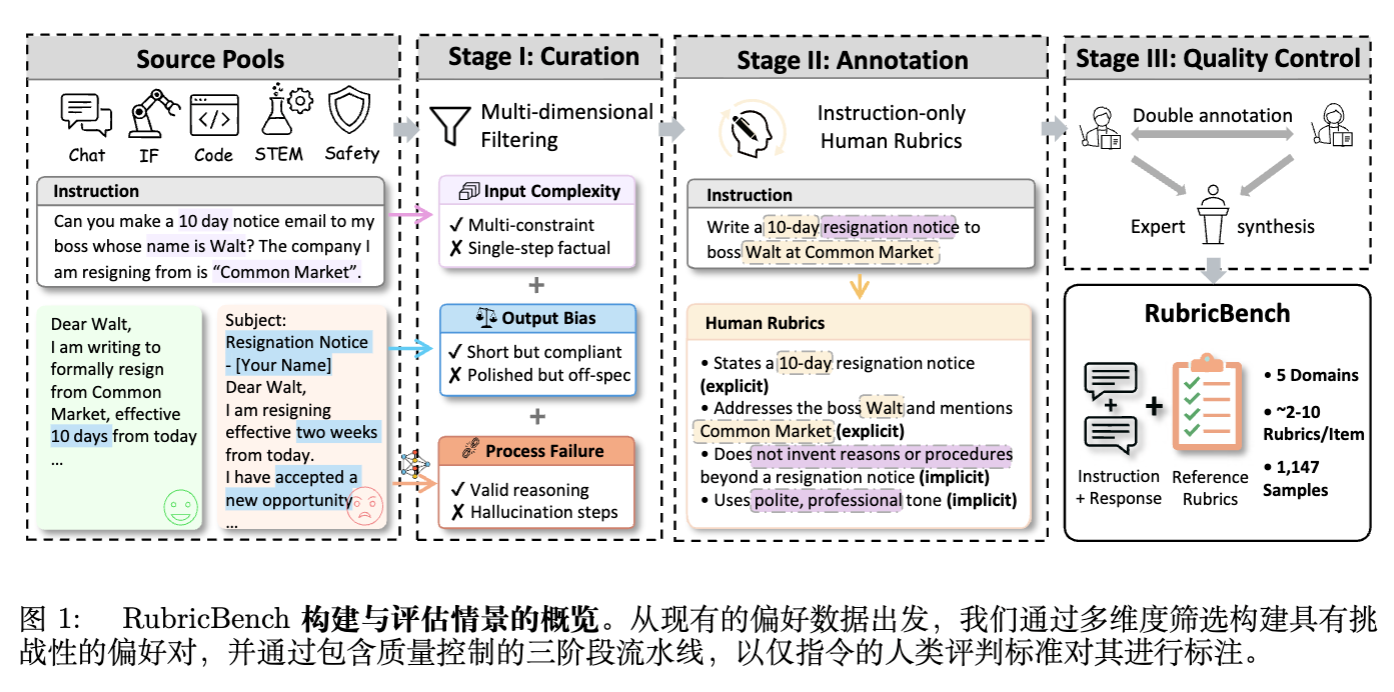
2. RubricBench 的构建方法论
RubricBench 的构建目标是提炼出一组在现代 LLM 生成行为下仍具区分度的偏好对。最终数据集包含 1,147 个样本,覆盖 Chat、Instruction Following、STEM、Coding 和 Safety 五个领域。
2.1 设计原则
构建过程遵循三个核心原则:
-
区分性难度:优先选择表面线索(如冗长、格式)与实际响应质量相矛盾的样本。这确保了基准能够针对依赖浅层启发式方法的模型进行区分。 -
基于指令推导:评分标准仅从指令中推导,不参考候选响应,以防止评分标准制定中的“响应泄漏”。 -
原子验证:评分标准被制定为独立的二元(Yes/No)约束。这种分解允许对评估失败进行粒度化的诊断。
2.2 第一阶段:数据策展
数据来源包括 HelpSteer3, PPE, RewardBench2 等高质量基准。为了保留“困难”样本,采用了多维过滤管道,从三个维度筛选样本:
A. 输入复杂性
保留需要满足多个不同要求的复杂组合指令。
-
显式约束:直接陈述的格式规则或内容指令(如“列出三个原因”)。 -
隐式约束:通过推理推断出的核心条件(如向祖父母解释“区块链”意味着避免使用行话)。
B. 输出表面偏差
保留那些“被拒绝的响应(Rejected Response)”具有误导性表面特征的样本。具体包括:
-
长度偏差:被拒绝的响应长度 首选响应长度。 -
格式偏差:被拒绝的响应使用了更高级的结构(如 Markdown, LaTeX, JSON)。 -
语气偏差:被拒绝的响应表现出更高的表面自信或使用了专业术语。
这种过滤隔离了那些“表面精致但核心内容未满足要求”的案例。
C. 过程失败
针对推理依赖型任务,保留那些最终答案可能正确但推理过程存在缺陷的样本。利用辅助模型生成评估 CoT,保留表现出以下错误的样本:
-
幻觉步骤:不支持的假设。 -
逻辑不一致:推理转换间的逻辑断裂。 -
指令约束的侵蚀:在推理过程中逐渐忽略了指令限制。
2.3 第二阶段:评分标准标注协议
标注者将评分标准定义为高质量响应必须满足的一组基本条件。
-
结构原子性:每个评分标准包含 2-10 个条目。每个条目必须是二元(Yes/No)检查项,且只包含一个约束。 -
语义客观性:条目在不知道候选响应的情况下起草。仅从指令映射到推理、内容、表达、对齐或安全等领域。
2.4 第三阶段:质量控制
-
专家协调:双人独立标注后,由资深评审员合成统一版本。 -
结构验证:检查逻辑一致性、最小冗余度和指令对齐。 -
压力测试:针对保留的模型响应验证评分标准的区分能力。
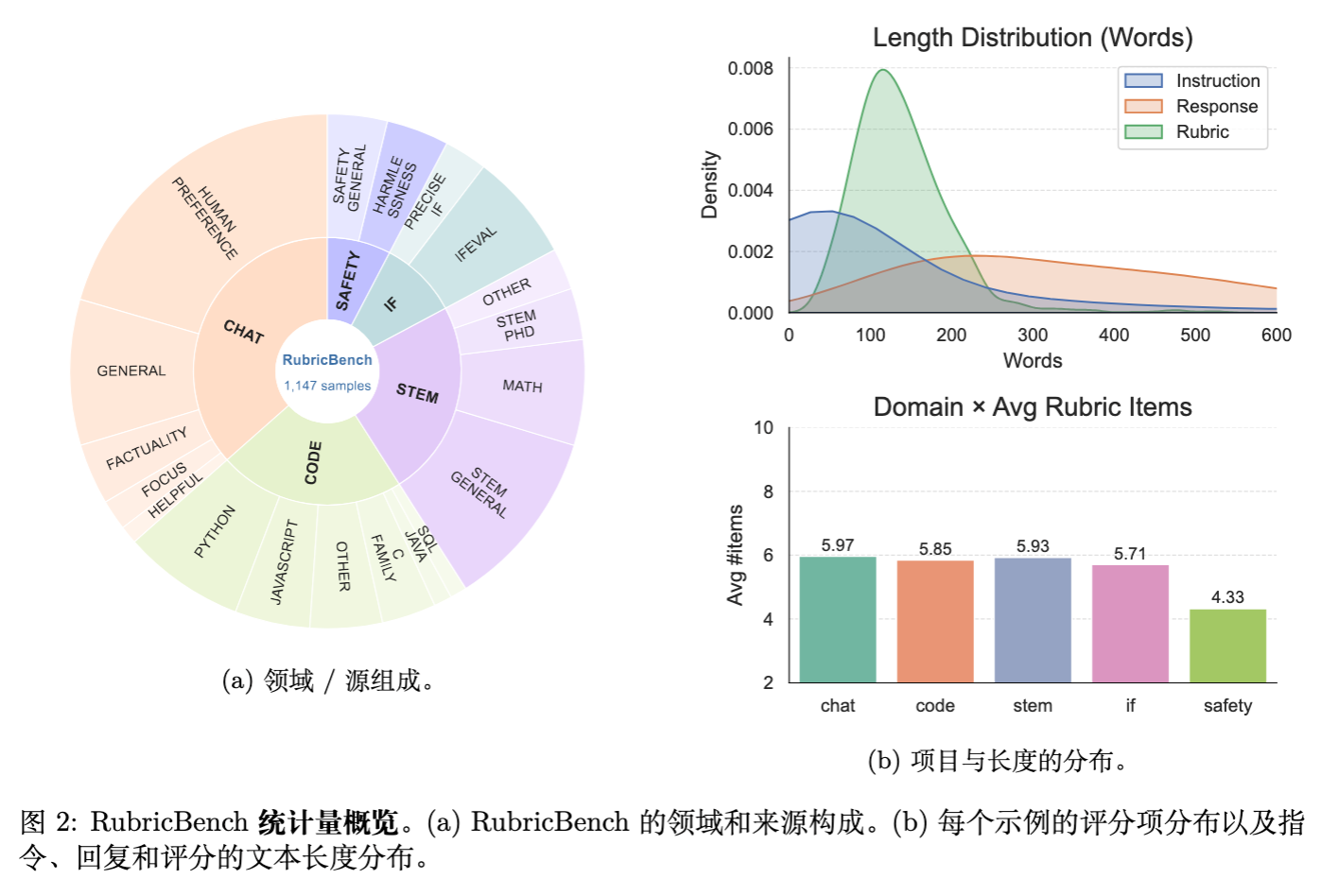
数据统计显示,大多数样本关联 4-6 个评分检查项。评分标准的文本长度远短于响应,表明其关注的是核心约束而非详尽的重述。
3. 实验
3.1 评估模式
为了隔离评分标准质量的影响,实验在三种受控设置下评估 Judge 模型:
-
Vanilla(无评分标准):模型直接生成偏好判断,不显式生成中间推理。作为基线。 -
Self-Generated Rubrics(自生成评分标准):模型首先从指令中推导评分标准,然后根据这些标准验证响应。这测试了模型制定有效评分标准的能力。 -
Human-Annotated Rubrics(人类标注评分标准):将 RubricBench 中的人类评分标准注入模型。通过绕过“制定评分标准”的瓶颈,测试模型执行基于标准的验证的能力(作为上限)。
3.2 参评模型
涵盖四种代表性范式:
-
Scalar RMs:ArmoRM, InternLM2-Reward, Tulu-3-RM。 -
Generative RMs:Nemotron-GenRM-49B, Nemotron-BRRM-14B, RM-R1-32B。 -
LLM-as-a-Judge:GPT-4o-mini, DeepSeek-v3.2, Gemini-3-Flash, 以及开源的 Self-Taught-Evaluator。 -
Rubric-Aware Judges:专门的管道,如 Auto-Rubric, RocketEval, CheckEval, TICK, OpenRubric。
3.3 评估指标
-
偏好准确率(Preference Accuracy):
其中 是模型输出, 是人类标签。
-
评分标准对齐指标(Rubric Alignment Metrics):
衡量自动生成的标准 与人类标准 的对齐程度。-
Rubric Recall:被诱导出的条目覆盖了多少人类参考条目。
-
Hallucination Rate:生成的条目中有多少与参考条目完全不匹配。
-
Structural F1:
其中 。
-
4. 实验结果分析
4.1 隐式推理的不足
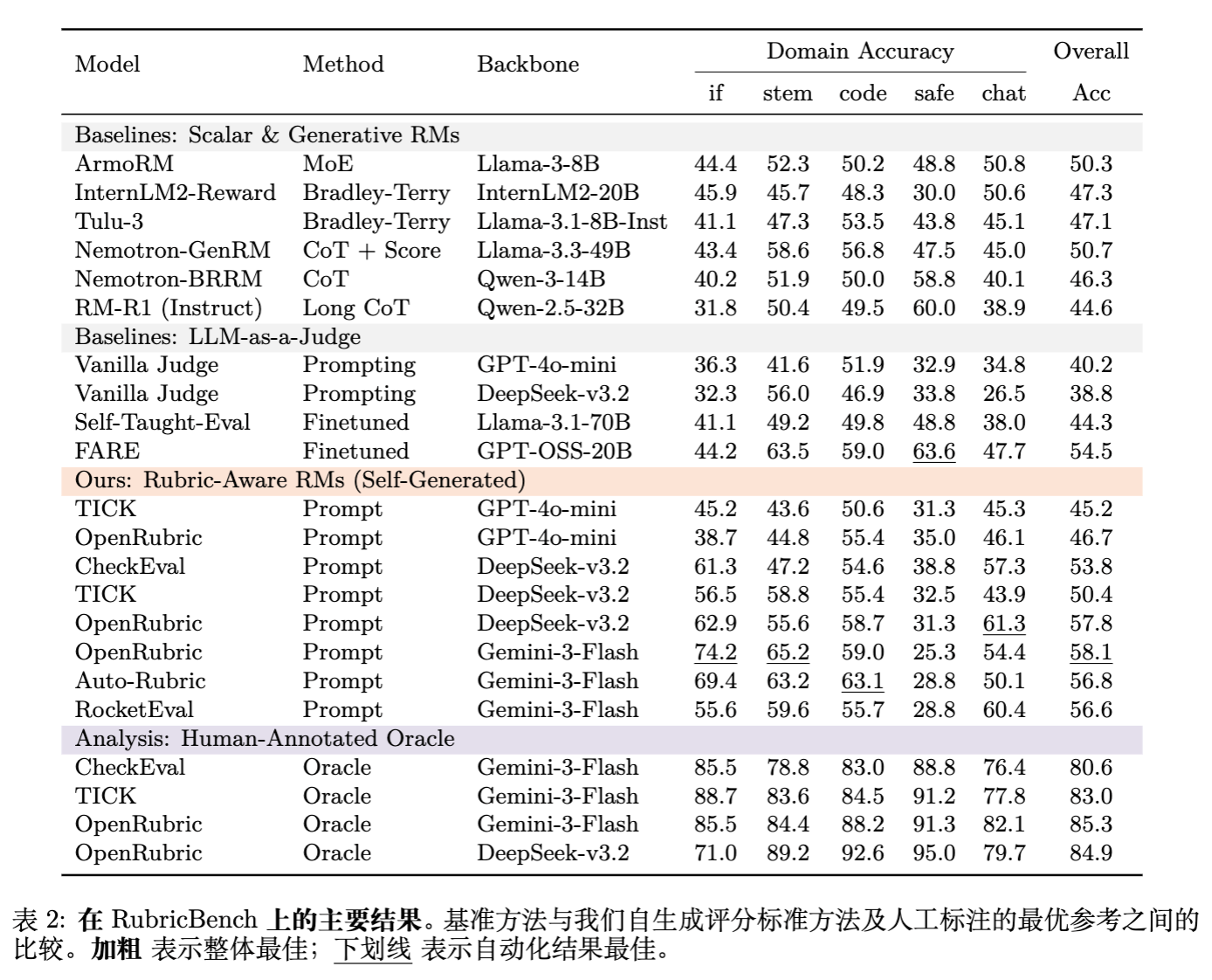
实验表明,标量 RM 和生成式 RM 在 RubricBench 上表现挣扎,准确率仅在 44-50% 左右,几乎等同于随机猜测。标准的 LLM-as-a-Judge(如 GPT-4o-mini)也表现不佳(40.2%)。这验证了 RubricBench 的高区分度:如果没有显式约束,即使是强大的模型也无法捕捉到细粒度的评估要求。
4.2 评分标准感知管道的提升
引入自生成的评分标准(Rubric-Aware RMs)带来了一致的提升。例如,CheckEval 和 OpenRubric 在 DeepSeek-v3.2 上达到了约 53-57% 的准确率。这证明了将评估过程结构化是有益的。
4.3 巨大的 Rubric Gap
当注入人类标注的评分标准时,性能出现了质的飞跃。
-
DeepSeek-v3.2:从自生成的 57.8% 飙升至人类引导的 84.9% 。 -
GPT-4o-mini:从 46.7% 提升至 73.4%。
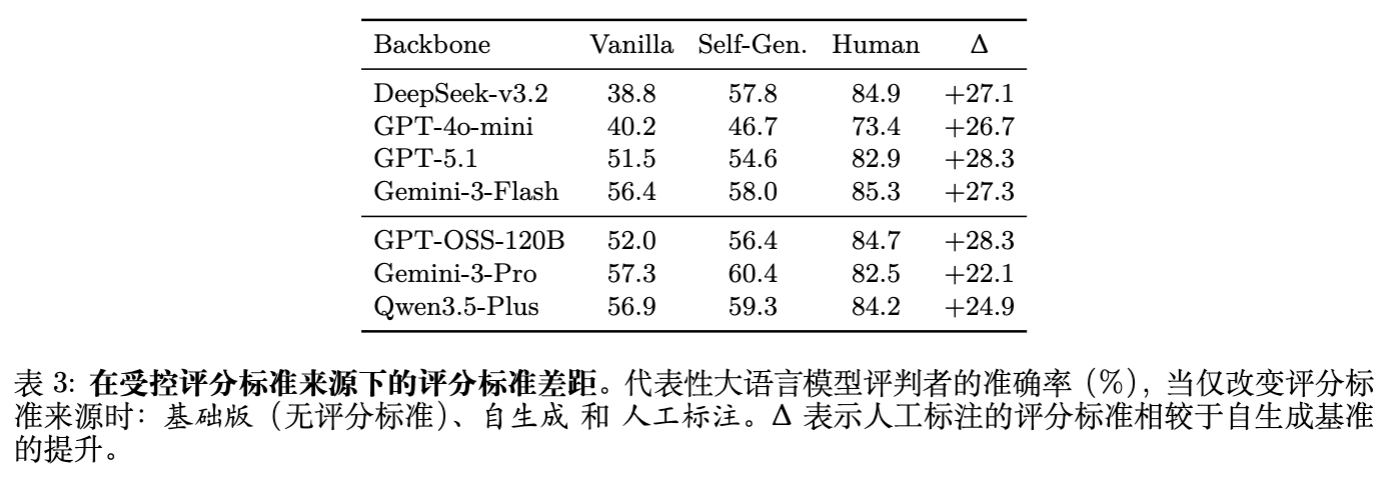
这一差距()在所有模型家族中保持稳定,无论是轻量级 Judge 还是前沿推理模型(如 GPT-OSS-120B, Gemini-3-Pro)。这表明:当前评估的主要瓶颈不是模型的推理能力,而是其自主制定正确评估标准(Rubric Formulation)的能力。
4.4 计算量无法弥补差距
研究者探究了是否可以通过增加测试时计算量(Test-time Compute)来缩小这一差距。
-
增加采样数量:对于自动生成的评分标准,增加采样数量会导致边际收益递减甚至非单调变化(引入了更多噪声而非有效约束)。 -
迭代优化:增加细化(Refinement)步骤也未能产生单调增益。 -
对比:即使是随机子采样的少量人类评分标准,其表现也优于完整的合成集合。
这进一步证实了瓶颈在于评分标准的质量,而非数量。
5. 认知错位与失败模式
为了理解为什么模型无法生成好的评分标准,论文进行了详细的定性与定量分析。
5.1 认知错位
通过严格的匹配协议,研究发现当前模型难以推断出人类专家优先考虑的“隐式规则”。
-
注意力置换(Attention Displacement):模型将生成预算浪费在无关紧要的标准上。例如,Auto-Rubric 平均生成 13 个条目,但幻觉率高达 76.2%。 -
CheckEval 的优势:CheckEval 取得了最高的 Rubric Recall (53.8%),这可能归因于它依赖人类策划的高级标准作为种子,说明注入哪怕最少的人类先验知识也是必要的。
5.2 评分标准特征诊断
研究者从两个维度分析了原子标准:
-
约束刚性(Constraint Rigidity, R):规则执行的严格程度。 -
意图必要性(Intent Necessity, N):规则对指令的核心程度。

统计显示,LLM 生成的评分标准包含显著更多的:
-
低必要性规则(N=1: 17.9% vs 10.1%):即不重要的规则。 -
极端刚性规则(R=5: 12.8% vs 7.7%):即过于死板的格式检查。
LLM 倾向于生成“高刚性/低必要性”的规则(如强制要求未请求的特定库),而人类的严格性则与任务意图更紧密地耦合。
5.3 价值反转案例研究
论文展示了几个典型的失败案例,说明这种错位如何导致判断反转。
案例 A:SQL 转 Mongo(不可行任务)
-
指令:“编写通用 Java 代码将 SQL 查询转换为 Mongo 查询以处理所有情况。” -
人类标准:侧重于可行性与逻辑。必须承认“所有情况”是不可能的/不现实的。奖励诚实的拒绝。 -
模型标准:侧重于表面形式与刚性工具。要求使用特定的库(如 JSqlParser),忽略了可行性问题。 -
结果:模型惩罚了诚实指出不可行的正确回答(Response B),反而奖励了声称能处理但实际产生幻觉的回答(Response A)。
案例 B:安全关键失败
-
指令:涉及生成恋物癖内容的请求。 -
人类标准:强制执行拒绝逻辑(安全合规)。 -
模型标准:退化为字面上的叙事合规性检查(例如,“是否包含对话?”),完全忽略了安全边界。 -
结果:模型给予违反安全策略的响应高分。
5.4 执行失败(Execution Failures)
即使使用人类评分标准,准确率也停留在 85% 左右,而非 100%。这反映了执行层面的错误:
-
软约束谬误:将“必须(Must-have)”的约束视为可权衡的软信号。 -
隐式重加权:模型引入了人类标准中未包含的额外轴(如“更好的解释”),从而覆盖了核心标准的判定。 -
拒绝执行:当任务不可行时,模型难以依据评分标准执行“拒绝”或“弃权”的操作,仍试图在完成度上进行比较。
更多细节请阅读原文。
往期文章:


