
-
论文标题:Agentic Proposing: Enhancing Large Language Model Reasoning via Compositional Skill Synthesis -
论文链接:https://arxiv.org/pdf/2602.03279
TL;DR
今天解读一篇由阿里巴巴 AI DATA 团队与上海交通大学 EPIC Lab 等机构合作发表的论文《Agentic Proposing: Enhancing Large Language Model Reasoning via Compositional Skill Synthesis》,提出了一种新的合成数据生成框架——Agentic Proposing。该框架旨在解决当前大模型推理数据合成中存在的“有效性”与“难度”难以兼得的矛盾。
核心思路是将问题合成任务建模为一个目标驱动的序列决策过程(POMDP)。通过构建一个包含原子推理技能的库,利用专门训练的“提议者智能体(Proposer Agent)”动态选择并组合这些技能。该智能体具备内部反思(Self-Reflection)和工具调用(Tool Use)能力,能够通过“起草-检查-修正(Draft-Check-Refine)”的迭代循环来生成逻辑严密且难度可控的高质量推理题。
在训练方法上,作者提出了一种名为多粒度策略优化(Multi-Granularity Policy Optimization, MGPO)的强化学习算法,通过结合轨迹级(Trajectory-level)和阶段级(Stage-level)的优势估计,有效地优化了智能体的生成策略。
实验结果表明,仅使用 11,000 条由该框架合成的数据训练的 30B 模型,在 AIME 2025 基准测试中达到了 91.6% 的准确率,展现了合成数据在提升复杂推理能力方面的潜力。
1. 引言
1.1 推理数据的困境
在 OpenAI o1 发布后,提升大语言模型(LLM)的复杂推理能力(System 2 Reasoning)已成为研究的核心前沿。DeepSeek-Math 等工作证明了强化学习(RL)在解锁数学推理潜力方面的有效性。然而,这些 RL 方法的基础严重依赖于环境反馈的有效性,这转化为对大量、高质量、高难度且可验证的问题集的刚性需求。
目前,获取此类数据主要面临以下瓶颈:
-
人工标注成本高昂:难以规模化。 -
现有合成方法的局限性: -
基于种子扩展(Seed-Based):如 MetaMath, WizardMath。通过改写或进化现有题目。缺点是受限于种子题的质量,且难以动态适应模型能力的边界。 -
基于语料库提取(Corpus-Based):如 MathSmith, ScaleQuest。从文本或知识库中提取概念组合。缺点是难以精确校准难度,且容易生成逻辑不连贯或无法求解的题目。
-
1.2 核心权衡:有效性 vs. 难度
当前合成范式面临一个普遍的权衡(Trade-off):
-
为了保持结构有效性(Structural Validity),通常需要限制问题的复杂度(使用模板或固定结构),导致题目过于简单。 -
为了增加难度(Difficulty)而放松约束,往往导致生成的题目逻辑不自洽或无法求解(Unsolvable)。
1.3 Agentic Proposing 的切入点
本文提出将高难度问题的合成视为组合逻辑工程(Compositional Logic Engineering),而非单纯的文本生成任务。核心动机是将推理模式转化为可执行的组件(Atomic Skills),并通过一个智能体(Agent)来编排这些组件。
如图 1 所示,对比了传统合成范式与 Agentic Proposing 的区别。
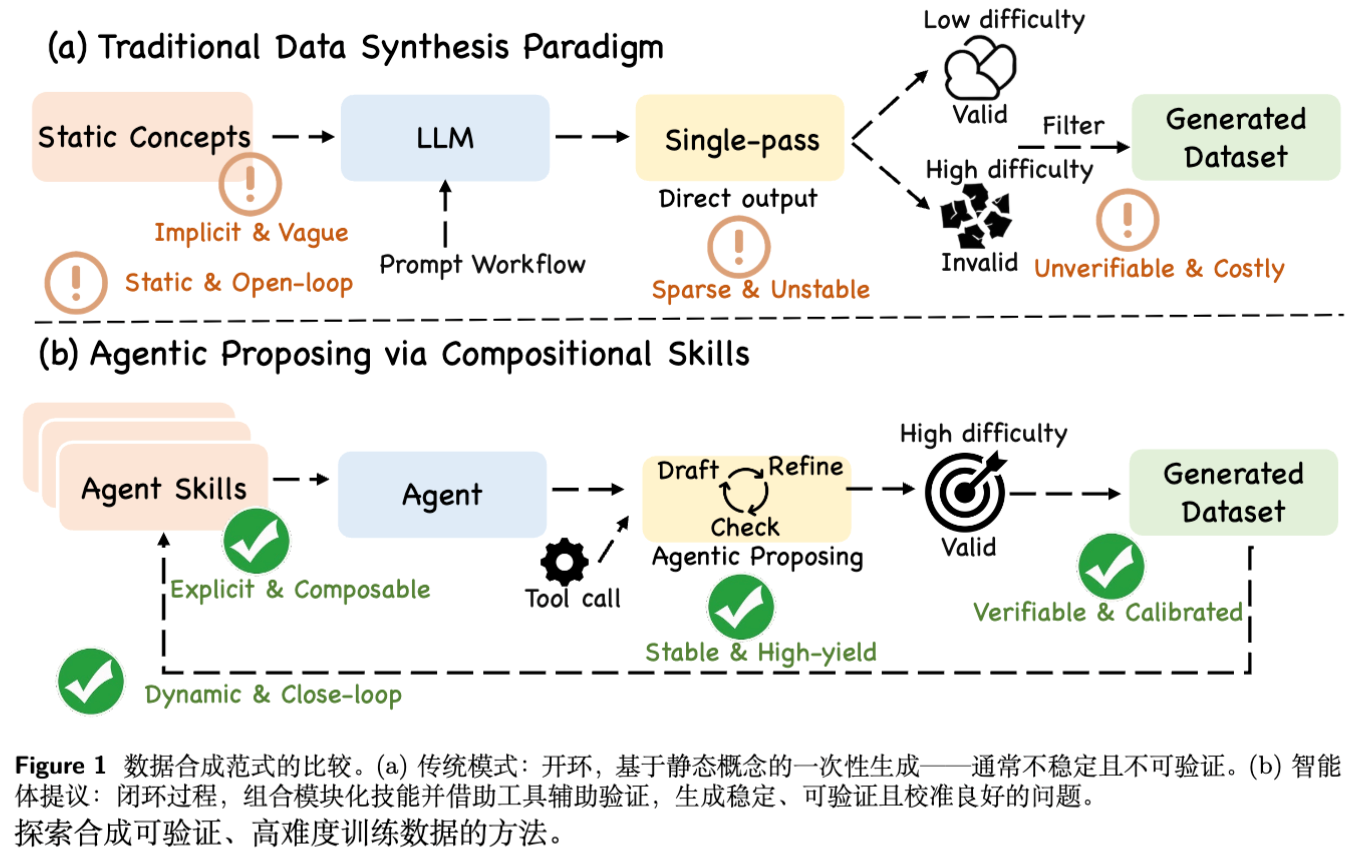
2. 作为 POMDP 的问题合成
2.1 问题定义
论文将问题合成建模为高维推理空间中对逻辑一致性和复杂度的迭代搜索。具体形式化为部分可观测马尔可夫决策过程(POMDP),定义为元组 。
-
状态空间 :潜在状态,代表问题潜在的逻辑完整性和难度。 -
动作空间 :智能体的操作集合。 -
观测空间 :智能体可见的信息。 -
转移函数 :状态转移概率。 -
奖励函数 :评估生成质量。 -
折扣因子 。
关键洞察:合成问题的“逻辑可解性”是一个潜在属性,仅通过表面的对话历史无法完全观测。因此,智能体必须通过工具使用和内部反思主动“探测”环境,以减少不确定性并收敛到一个有效的问题实例。
2.2 观测与认知上下文
在时间步 ,智能体接收到的观测 定义为:
其中:
-
:当前激活的技能子集。 -
:对话历史(包含之前的工具输出)。 -
:认知阶段指示器(Cognitive Stage Indicator)。这是一个显式的状态标记,跟踪智能体所处的语义阶段(如 Drafting, Checking, Refining)。这并非僵化的状态机,而是作为功能性上下文,允许智能体自适应地导航合成过程(例如,在验证阶段发现逻辑漏洞时主动回退到修正阶段)。
2.3 动作空间划分
动作空间 被划分为三个功能域 :
-
认知动作 :自然语言响应。包含内部反思动作 ,用于生成推理链以进行逻辑审计。 -
交互工具 :工具调用。 -
:沙盒代码执行。 -
:动态技能剪枝。允许智能体执行 ,主动移除与当前目标不匹配或导致冲突的技能 。
-
-
终结提交 :动作 ,用于提交最终合成的问题 。
2.4 技能组合性与 Lemma 3.1
论文基于“涌现组合性(Emergent Compositionality)”原理,提出了 Lemma 3.1(技能组合性引理):
设 为原子技能集。对于组合任务 ,如果强化学习目标仅在输出匹配 时提供正奖励,智能体能够学习编排 和 以高概率解决 ,即使在预训练中未见过具体的组合。
基于此,每个技能 被形式化为结构化属性元组 ,分别编码:
-
:推理意图(Intent)。 -
:构建方法(Construction Method)。 -
:难度效应(Difficulty Effect)。 -
:工具使用提示(Tool-use Hint)。
问题生成策略 建模为:
其中 将选定的技能组合转化为自然语言约束。
3. Agentic Proposing 框架详解
整个流程如图 3 所示,分为三个阶段:技能获取、Agentic SFT、Agentic RL (MGPO)。
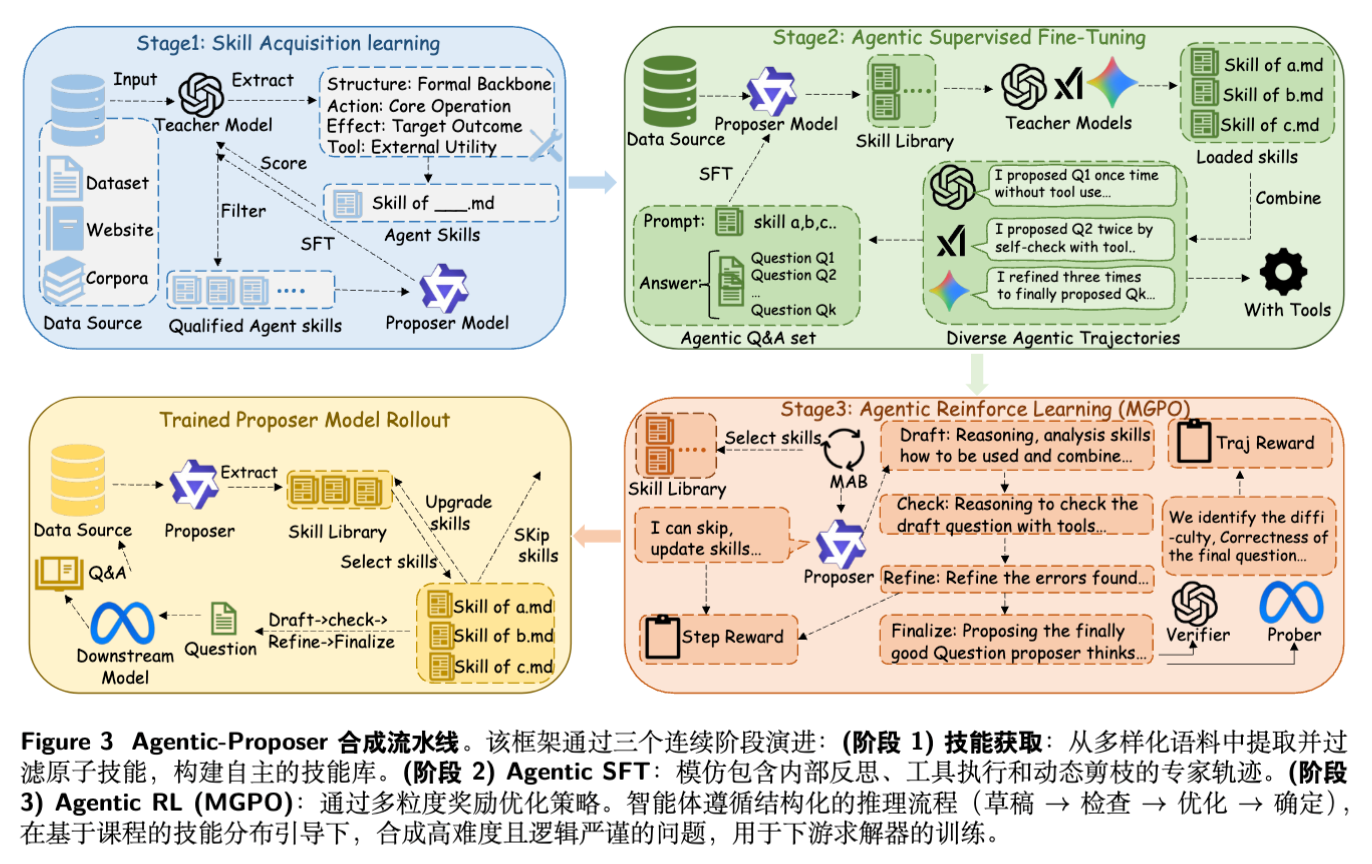
3.1 阶段 1:技能获取与动态剪枝 (Skill Acquisition)
目标是构建自主技能库 。
-
来源:混合源语料库 (教材、论文、现有题目)。 -
教师模型:利用强大的教师策略 (如 GPT-4 或 Qwen-72B)从语料中提取并形式化技能。 -
过滤机制:教师模型对每个提取的技能 进行质量打分 。通过拒绝采样构建过滤后的技能分布 。 -
训练目标:最大化技能获取的似然度:
动态剪枝机制:在合成过程中,如果智能体预测某个技能 与任务目标不一致,可通过 动作将其移除。这种前瞻性的自我纠正机制保证了合成过程的鲁棒性。
3.2 阶段 2:Agentic 监督微调 (Agentic SFT)
目标是教会模型模仿专家的复杂决策过程。
-
专家轨迹生成:使用教师策略生成包含丰富动作(反思、工具调用、剪枝)的轨迹 。 -
严格过滤:所有生成的轨迹必须通过高精度验证器 的检查,确保最终问题 逻辑一致且有解()。 -
行为克隆(BC):在过滤后的数据集 上进行微调,获得参考策略 。
3.3 阶段 3:多粒度策略优化 (MGPO)
这是论文的核心贡献之一。为了弥补逻辑有效性与极端难度之间的鸿沟,作者提出了 MGPO 算法。
3.3.1 基于课程的技能分布
为了动态关注智能体表现不佳的领域,引入了课程学习机制。系统维护一个熟练度向量 ( 为技能类别集合)。
熟练度更新采用指数移动平均(EMA):
采样概率与熟练度成反比:。这迫使智能体在“舒适区”之外进行探索。
3.3.2 分层奖励函数
奖励结构分为步骤级(Step-level)和轨迹级(Trajectory-level)。
-
终端奖励 :
其中 是验证器的二值输出, 是外部探针(Prober)估计的通过率(Pass@k)。 奖励逻辑有效性, 奖励难度。注意,只有可解的问题()才能获得难度奖励,这避免了生成无解难题的“奖励黑客”行为。 -
中间过程奖励 :对成功的工具执行()或逻辑连贯的反思()给予奖励。
3.3.3 MGPO 算法细节
MGPO 解决了 KL 约束下的奖励最大化问题。
优势估计(Advantage Estimation):
MGPO 在两个粒度上进行标准化,以平衡全局终端信号与局部过程反馈:
-
轨迹级优势 :在批次组 内对终端奖励进行标准化。 -
阶段级优势 :在共享相同认知阶段 的子组 内,对标准化过程奖励进行计算。
融合优势:
其中 是融合权重。
零和加权属性(Proposition 3.3):
作者构建了样本权重 ,使其满足零和属性(),从而消除了配分函数 的计算需求。
其中 是隐式奖励(即 log 概率比)。
最终优化目标:
实际使用的权重 经过一个非对称的双曲正割门(hyperbolic secant gate)调节,以增强训练稳定性:
其中 是重要性比率(Importance Ratio)。温度参数 设置为非对称:当权重为正时使用 ,为负时使用 (),以此抑制过大的更新。
MGPO 的损失函数为加权最大似然:
4. 实验
4.1 模型体系
框架涉及多个角色的模型:
-
Proposer (提议者) :初始化自 Qwen3-4B-Instruct,经 Agentic SFT 和 MGPO 训练。 -
Teacher (教师) :Qwen3-235B-Instruct,用于技能提取。 -
Verifier Ensemble (验证器集合) :由 Qwen3-235B-Thinking, DeepSeek-V3.2-Special, GPT-OSS-120B 组成。采用多数投票 + 二次审计机制。 -
Prober (探针) :一系列不同规模的 Qwen3 模型(1.7B 到 30B),用于估计题目难度。
4.2 基准测试 (Benchmarks)
-
竞赛数学:AIME 2024/2025, HMMT, AMO-Bench。 -
算法编程:LiveCodeBench (v5/v6)。 -
科学推理:MMLU-Redux, MMLU-Pro, GPQA, SuperGPQA, OlympicArena。
4.3 基线对比 (Baselines)
-
数据合成方法:MetaMath, WizardMath, PromptCoT 2.0, NuminaMath, MathSmith。 -
人工标注/精选方法:OpenR1, OpenMathReasoning, POLARIS。 -
SOTA 模型生成:GPT-5.2-High, Claude-4.5-Opus 等生成的题目。
所有方法均在严格控制的 10,000 - 11,000 条轨迹预算下进行评估,下游求解器(Solver)使用 GRPO 进行训练。
5. 主要结果分析
5.1 竞赛数学性能
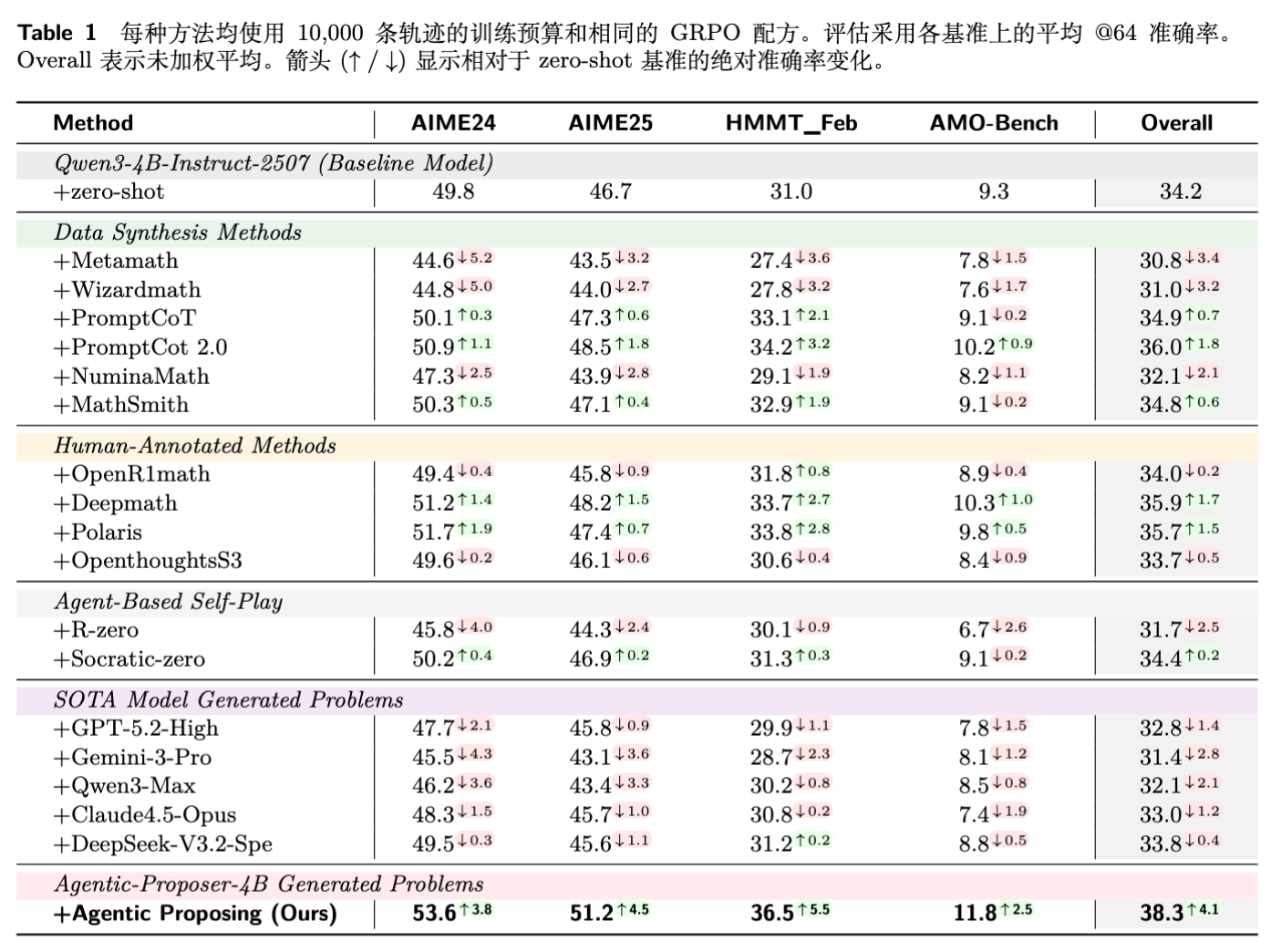
如表 1 所示,在固定数据预算下,使用 Agentic Proposing-4B 生成的数据训练的 4B Solver,在 AIME 2025 上达到了 51.2% 的准确率,相比 Zero-shot 基线(46.7%)提升显著。
值得注意的是,许多现有基线(如 MetaMath, WizardMath)在微调后反而导致性能下降(Negative Transfer)。这表明低质量或难度不匹配的数据会损害强模型的能力。而 Agentic Proposing 实现了正向迁移。
5.2 模型扩展性 (Scaling)
当将下游求解器扩展到 30B 参数时,效果更加显著。
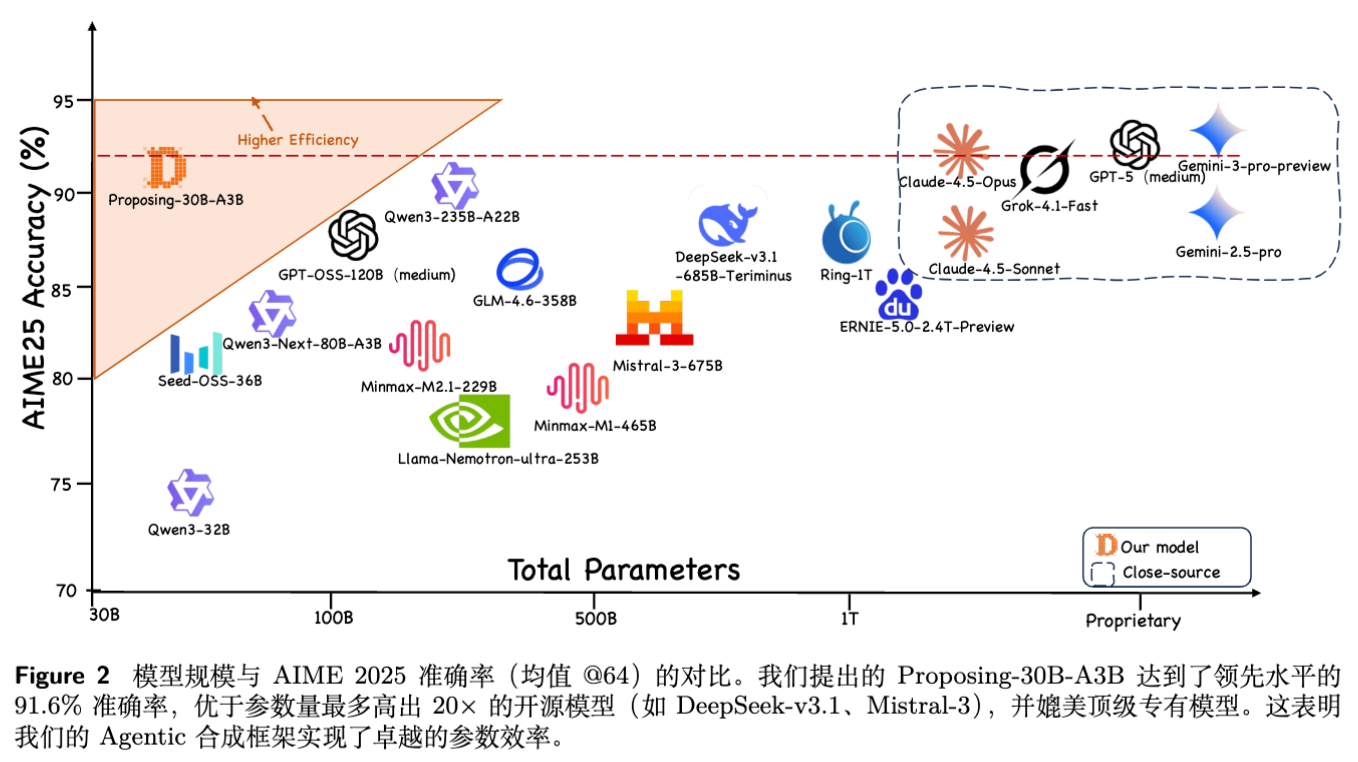
如图 2 所示,Agentic-Proposer-30B 在 AIME 2025 上达到了 91.6% 的准确率。
-
超越了开源模型 DeepSeek-v3.1, Mistral-3。 -
匹敌闭源前沿模型 GPT-5, Gemini-3-Pro。
这一结果证明了:推理性能的瓶颈不在于参数规模,而在于高质量训练信号的密度。 少量(11k)极高质量的合成数据可以替代海量低质数据。
5.3 跨域泛化
虽然主要针对数学优化,但该方法在代码和科学领域也表现出色。
-
LiveCodeBench:相比 Zero-shot 提升 +5.3%。 -
GPQA/SuperGPQA:分别提升 +6.3% 和 +7.3%。
这证实了通过组合原子技能生成的训练轨迹,能够帮助模型习得更通用的认知能力,而非仅仅过拟合特定领域的题型。
6. 深入分析与消融实验
6.1 提议者专业化 vs. Prompting
作者对比了经过专门训练的 4B Proposer 与仅仅使用 Prompt 工程的 GPT-5.2。
-
GPT-5.2 + Prompting:32.8% (AIME) -
GPT-5.2 + Skill Library + Workflow:36.4% -
Agentic-Proposer-4B (Ours):38.3%
这表明,特定领域的强化学习(RL)可以让小模型在特定任务(如问题提议)上超越通用的前沿大模型。结构化的技能组合和迭代验证是关键。
6.2 Agentic Pipeline 的有效性
消融实验显示:
-
仅加入 Tool-use:+2.3% -
仅加入 Internal Reflection:+2.1% -
完整 Pipeline (Draft-Check-Refine):+6.8%
工具和反思作为质量控制的“门控”,只有在闭环迭代中才能发挥最大效用。
6.3 MGPO 的有效性
对比 MGPO 与标准的 GRPO:
-
GRPO (Trajectory-level):31.8% -
MGPO (无阶段级优势):35.1% -
MGPO (完整):38.3%
标准 GRPO 在长合成链中面临奖励稀疏问题。MGPO 通过引入阶段级优势(),为中间行为(如工具调用、反思)分配信用,有效地指导了智能体在整个推理过程中的策略优化。
7. 案例研究:代理式修正循环
为了展示 Agentic Proposing 的实际工作机制,论文提供了一个具体的合成案例(Appendix E & F)。
案例背景:合成一个涉及多领域(分析、数列、代数)的推理题。
合成轨迹:
-
技能组合:智能体选择了三个技能: -
Skill A: 微分不等式分析。 -
Skill B: 数列渐进增长。 -
Skill C: 多项式理想的根(Radical)。
-
-
起草(Drafting)与反思: -
智能体起草题目,设定 的差分收敛到 。 -
:检测到矛盾。“如果微分不等式强制 ,那么 必须为 0,这与 冲突。” -
修正决策:决定将问题重构为“基于反证法的矛盾证明”,要求用户证明 。
-
-
代码验证(): -
调用 SymPy 验证代数假设(理想成员资格)。 -
确认 Grönwall 不等式导致的序列极限必须为 0。
-
-
最终输出:生成了一个逻辑自洽且经过验证的高难度题目。
这个案例展示了Cognitive Stage Indicator和工具辅助验证如何防止了逻辑错误的产生,这是传统单次生成模型(One-pass generation)极难做到的。
8. 讨论与局限性
8.1 现有合成方法的“熵坍缩”
论文在附录 B 中分析了为何在 MetaMath 等基线上训练会导致性能下降。诊断发现,现有基线对于 4B 模型来说过于简单(Pass Rate > 85%),导致奖励信号消失或分布呈现 J 型(而非理想的 Mirrored J-shape)。这导致模型在训练中停止探索复杂逻辑,发生“熵坍缩(Entropy Collapse)”。Agentic Proposing 通过动态调整难度,始终保持在模型的推理前沿(Reasoning Frontier)。
8.2 对验证器的依赖
该框架的一个潜在局限是高度依赖验证器(Verifier)的准确性。如果验证器存在系统性偏差,可能会误导 Proposer。论文通过使用多模型集成(Ensemble)和二次审计机制来缓解这一问题,但在更极端的难度下,验证器本身可能成为瓶颈。
8.3 计算成本
虽然生成的训练数据量很少(11k),但生成过程本身(特别是 Draft-Check-Refine 循环和 MGPO 训练)涉及大量的推理计算和工具调用。这是用推理时的计算换取了更高质量的数据。
更多细节请阅读原文。
往期文章:


