
-
论文标题:On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models -
论文链接:https://arxiv.org/abs/2512.07783
TL;DR
本研究通过构建完全可控的合成推理数据环境,系统性地解构了预训练(Pre-Training)、中期训练(Mid-Training)和基于强化学习的后训练(RL Post-Training)在提升大语言模型推理能力中的因果贡献。研究主要发现如下:
-
RL 的真实增益条件:RL 仅在任务难度处于模型“能力边界(Edge of Competence)”且预训练阶段留有足够探索空间时,才能产生真正的外推性能力提升(Pass@128)。对于已完全掌握的域内任务或完全超出能力的域外任务,RL 效果有限。 -
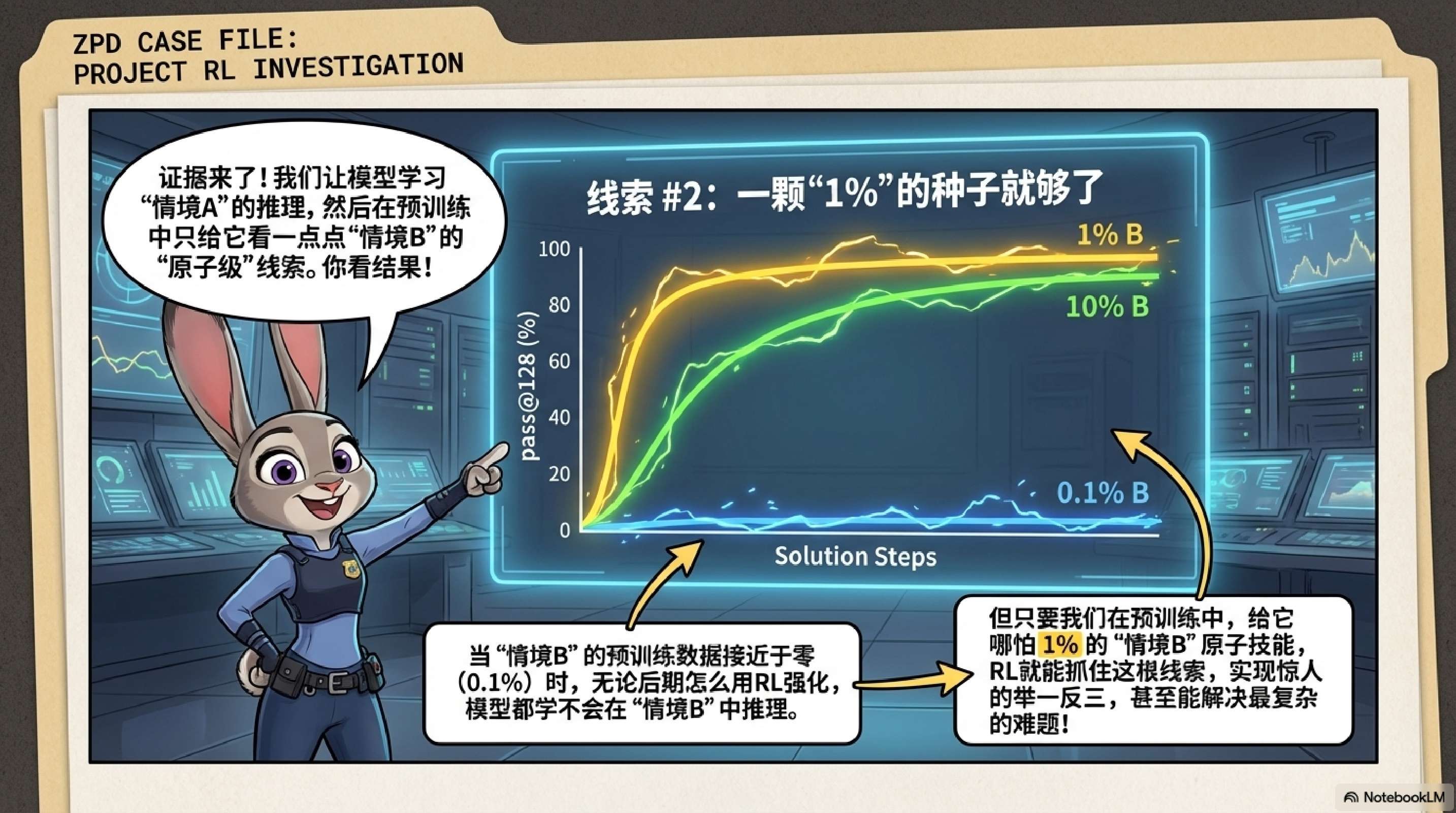
上下文泛化的“种子”效应:模型对新颖上下文(Context)的泛化能力依赖于预训练阶段的最小暴露。即使只有 1% 的长尾分布数据暴露,也足以作为“种子”,让 RL 在后训练阶段实现稳健的迁移;反之,零暴露则导致泛化失败。“数据暴露”(Data Exposure) 特指模型在预训练(Pre-training)阶段接触到特定类型数据的程度、频率或覆盖范围。 -
中期训练的关键作用:在固定计算预算下,引入连接预训练和 RL 分布的中期训练阶段,能显著提升模型在域外(OOD)任务上的表现。中期训练负责确立先验(Priors),RL 负责规模化探索(Exploration)。 -
过程奖励的必要性:相比于稀疏的结果奖励,引入过程级验证(Process Verification)能有效缓解奖励破解(Reward Hacking),提升推理过程的忠实度和复杂任务的准确率。
1. 引言
近期,以 DeepSeek-R1 和 OpenAI o1 为代表的工作表明,强化学习(RL)在提升大语言模型(LLM)推理能力方面具有显著作用。然而,学术界对于“后训练(Post-Training)是否真正扩展了模型超越预训练获取的推理能力”这一问题仍存在根本性分歧。
-
一方观点:RL 主要充当能力激发器或细化器(Refiner),即它只是更好地引出了模型在预训练中已具备的潜在知识。 -
另一方观点:RL 能够引导模型合成新的推理路径,解决预训练中未见过的复杂组合问题。
解决这一争论的主要障碍在于现代 LLM 训练流程的不透明性:大规模预训练语料的成分未知,使得我们无法断定模型是否通过死记硬背掌握了某种推理模式。此外,“中期训练(Mid-Training)”作为预训练与特定任务微调之间的桥梁,其在塑造模型分布中的作用也常被忽视。
为了消除这些模糊性,CMU 研究团队开发了一个全流程可控的实验框架。该框架不使用受污染的互联网数据,而是采用基于依赖图(Dependency Graph)生成的合成推理任务。通过精确控制原子操作、推理深度、上下文模板以及各训练阶段的数据分布,研究者在两个核心维度——外推性泛化(Extrapolative Generalization)和上下文泛化(Contextual Generalization)——上进行了严格的因果分析。
本文将详细拆解该论文的实验设计、核心发现及对模型训练策略的启示。
2. 实验框架设计:从数据生成到评估协议
为了隔离各训练阶段的贡献,研究者构建了基于 GSM-Infinite 的合成数据生成管线。这一设计遵循三个原则:完全可控的推理结构、可解析的推理过程、以及训练分布的系统化操纵。
2.1 可控合成数据生成机制
数据生成的核心是一个有向无环图(DAG),记为 。
-
节点(Nodes) :代表潜在的数值量(例如“成年狮子的数量”)。 -
边(Edges) :编码功能依赖关系,限制为基本算术操作 。 -
复杂度控制:通过图中的算术操作数量 来量化推理深度。
生成流程分为四个步骤:
-
结构采样:确定操作数量范围(如 )和图的形状参数。 -
参数实例化:为节点分配具体数值。 -
上下文渲染:应用预定义的上下文模板 (如 animals-zoo,teachers-school),将抽象图 映射为自然语言文本 。 -
显式与隐式依赖:区分哪些推理步骤在文本中直接陈述(Explicit),哪些需要模型推导(Implicit)。
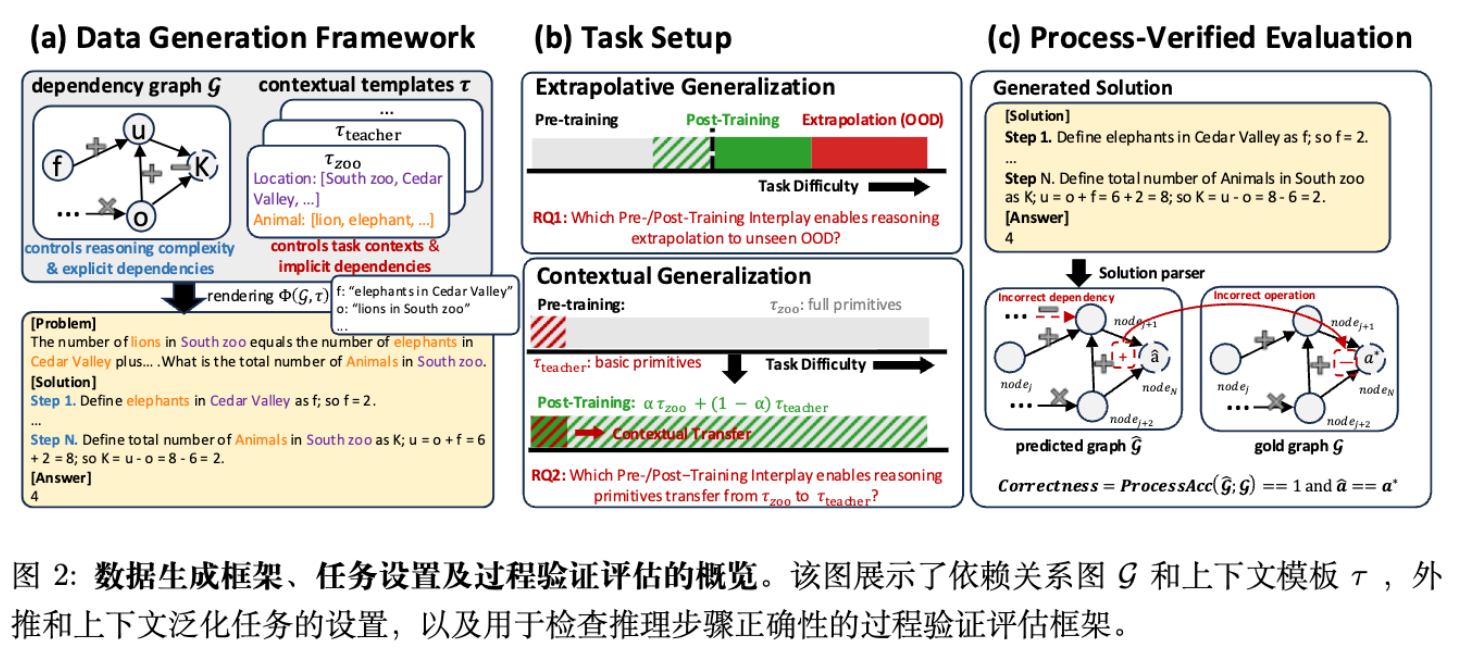
这种方法的优势在于无污染(Contamination-free)。研究者可以精确指定预训练、中期训练和后训练阶段看到的数据分布,避免了传统大规模语料库中不可知的重叠。
2.2 任务设置:推理泛化的两个维度
研究重点关注两个互补的泛化轴:
-
外推性泛化(深度泛化):
-
评估模型解决比预训练中遇到的问题更复杂(操作步数更多)的问题的能力。 -
ID(分布内):。 -
OOD-Edge(能力边界):。 -
OOD-Hard(高难度):。
-
-
上下文泛化(广度泛化):
-
评估模型将推理原语(Reasoning Primitives)迁移到具有相同底层逻辑但表面形式不同(不同模板)的新领域的能力。 -
例如,从“动物园里的狮子和老虎”迁移到“学校里的老师和学生”。
-
2.3 过程验证评估协议 (Process-Verified Evaluation)
传统的最终答案准确率(Outcome Accuracy)容易受到伪相关性的影响(即过程错误但碰巧蒙对答案)。为此,论文引入了严格的过程验证评估。
对于生成的每个实例,模型输出的自由形式解答被解析为预测依赖图 。评估指标 定义为所有金标节点(Gold Nodes)的平均步级准确率。
其中 为指示函数,仅当节点 在预测图中存在、其父节点依赖关系正确、且计算数值正确时为 1。
最终判定标准:只有当模型的推理过程完全正确()且最终答案 正确时,该样本才被计为通过(Pass)。文中所有报告的 pass@k 指标均基于此严格标准。
2.4 模型与训练设置
-
基础模型:Qwen2.5 架构,100M 参数(便于进行大量消融实验)。 -
预训练:在 10B tokens 的合成数据上从头训练(符合 Chinchilla Scaling Law,token/param 比率为 100:1)。 -
后训练:使用 GRPO(Group Relative Policy Optimization)算法,不使用 Critic 模型,通过对同一提示生成的多个样本计算相对优势。
3. 核心研究一:RL 何时能真正扩展推理能力?
本节探讨 RL 是否以及何时能让模型解决预训练期间未见过的更深层推理问题。
3.1 实验设置
-
预训练数据:仅包含 ID 任务()。 -
后训练数据:设计了四种不同难度的数据配方(Recipe),总样本数均为 200K。 -
仅 ID: -
混合: -
边界(Edge): -
高难(Hard):
-
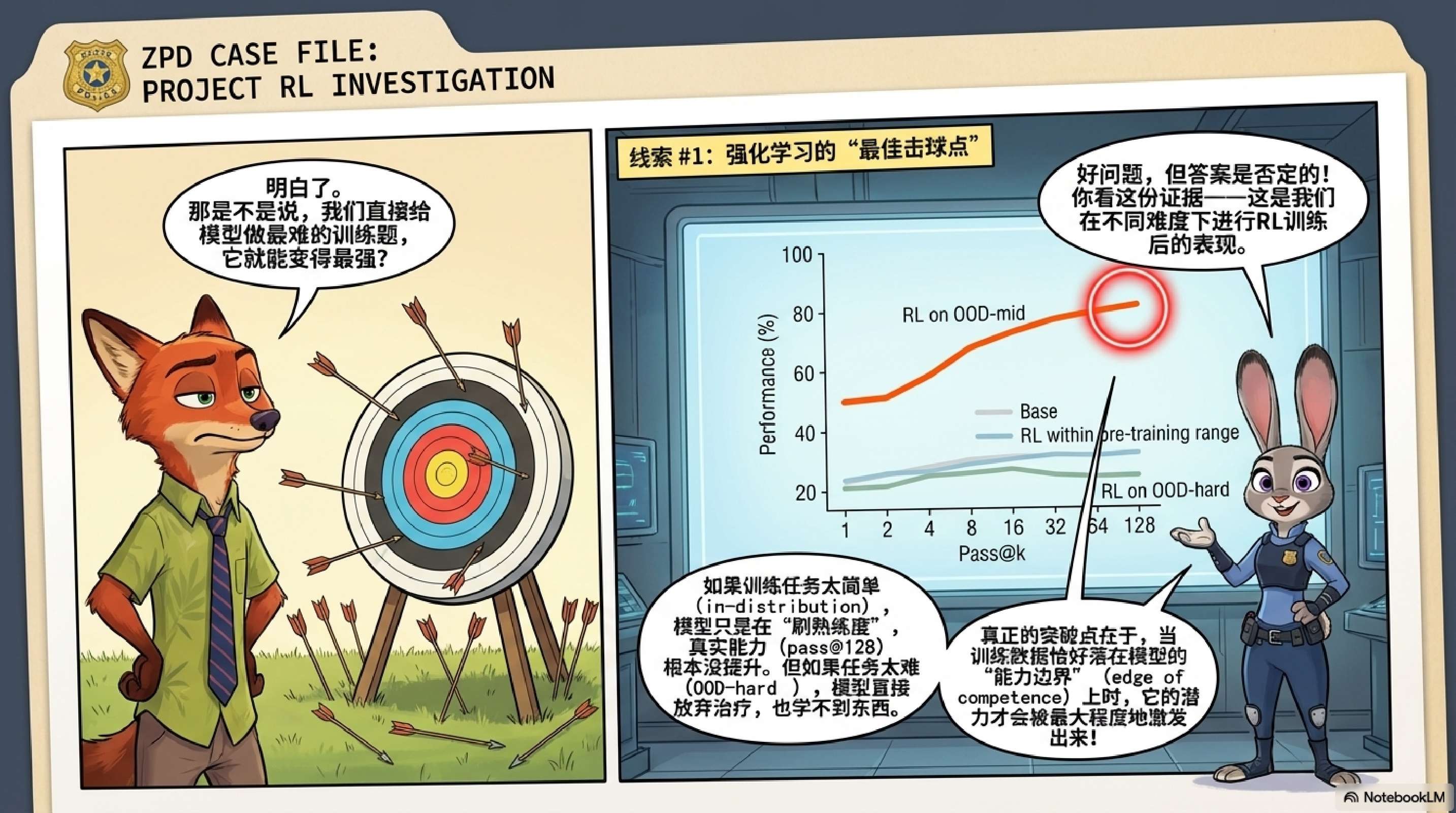
3.2 结果分析:能力边界效应
实验结果揭示了 RL 效能的明显分界线。
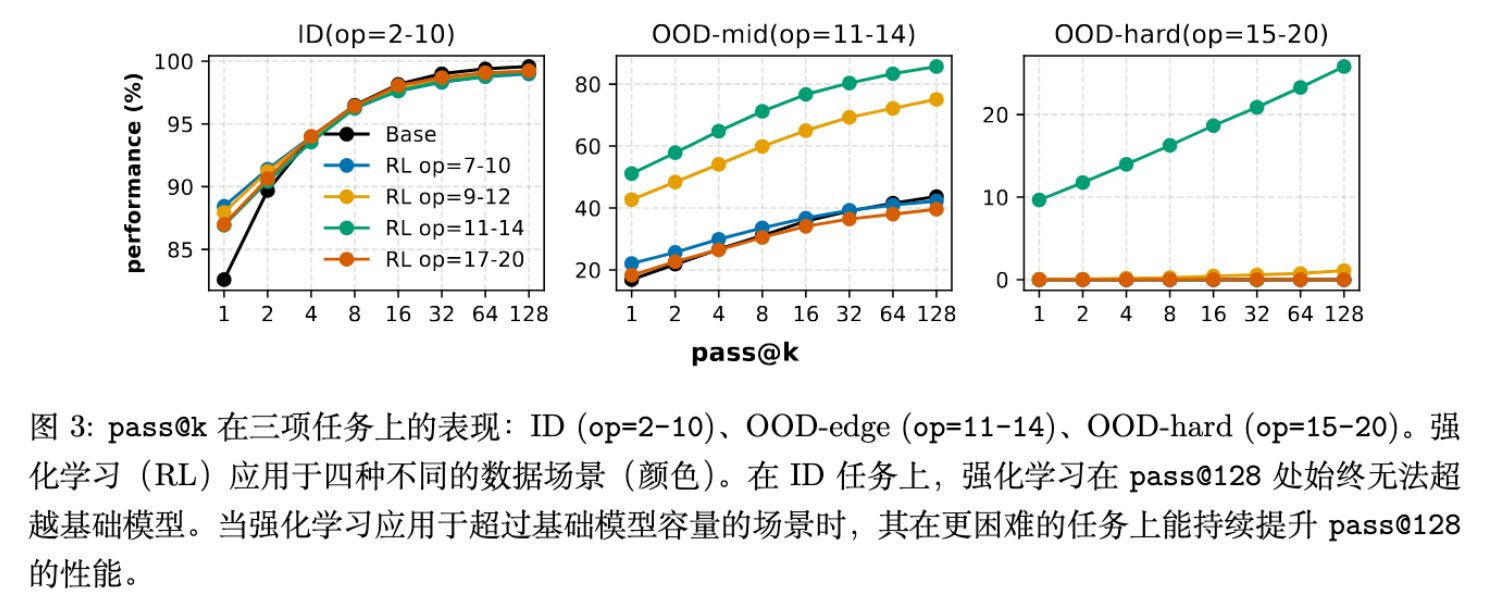
-
ID 任务(已掌握):对于预训练已覆盖的 任务,RL 提升了 pass@1,但在pass@128上几乎没有提升。这意味着在模型已熟悉的领域,RL 主要是锐化(Sharpening)现有能力,而非创造新能力。 -
OOD-Edge 任务(能力边界):当 RL 数据集中在 时,模型不仅在该区间表现提升,还能有效泛化到更难的 任务。在 区间, pass@128提升高达 42%。 -
OOD-Hard 任务(过难):如果直接使用 的数据进行 RL,模型往往难以学习,收益远不如在“能力边界”数据上训练。
核心发现:RL 产生真实能力增益(体现在 pass@128 的提升)需要满足两个条件:
-
任务在预训练中覆盖较少,留有探索余地。 -
RL 数据校准在模型的“能力边界”上——既不是太容易(ID),也不是太难(完全 OOD)。
3.3 训练动态与讨论
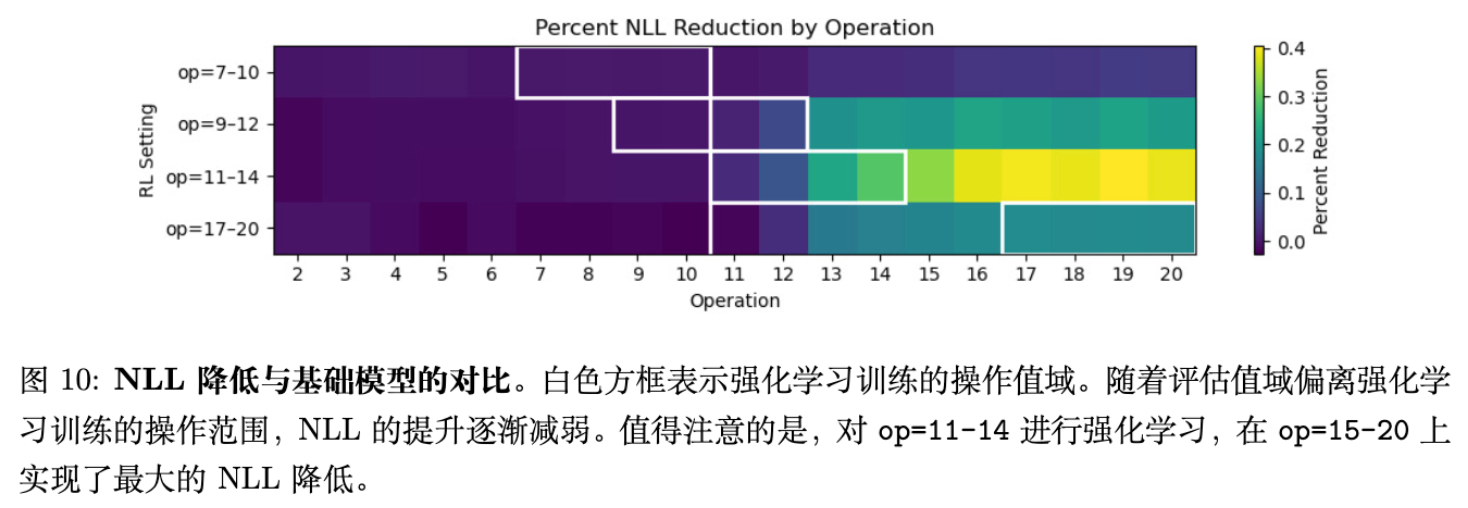
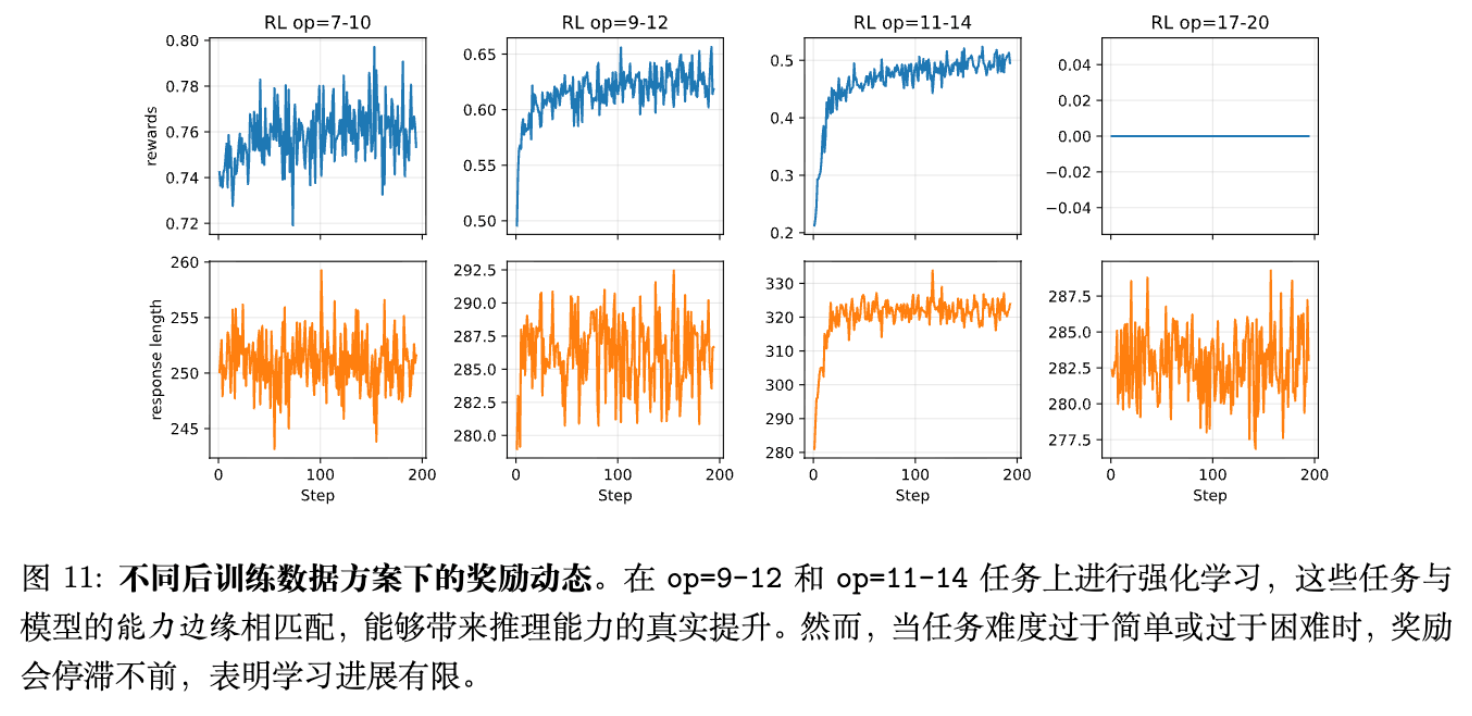
通过分析奖励曲线和负对数似然(NLL)下降情况,研究者发现:在“能力边界”数据上进行 RL 训练,能带来最大的 NLL 下降,且这种下降能平滑地泛化到更难的操作区间。这反驳了“RL 无法泛化”的悲观论点,同时也修正了“RL 无所不能”的盲目乐观,强调了数据难度课程(Curriculum)的重要性。
4. 核心研究二:预训练暴露度如何影响上下文泛化?
如果说外推性泛化是关于“深度”,那么上下文泛化就是关于“广度”。本节探究模型是否能将推理能力迁移到预训练中鲜见的长尾语境(Context)。
4.1 实验设置:长尾分布
-
Context A(常见):如 animals-zoo,占据预训练数据的绝大部分。 -
Context B(长尾):如 teachers-school,在预训练中仅占极小比例或完全缺失。 -
变量:预训练中 Context B 的原子操作()样本占比,从 0% 到 10% 不等。 -
后训练:RL 阶段使用 50% Context A + 50% Context B 的混合数据。
4.2 结果分析:种子效应
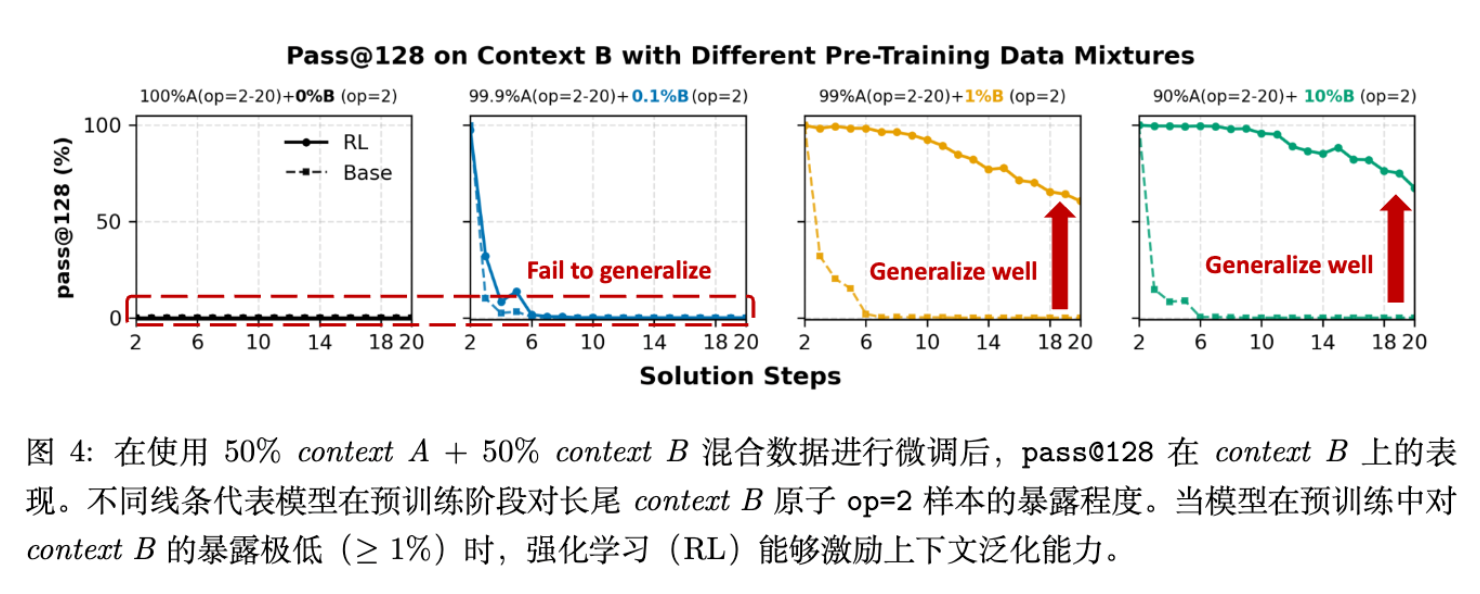
实验结果呈现出一种非线性的“相变”现象:
-
0% 或极低暴露(0.1%):如果预训练中完全没有 Context B,或者仅有 0.1% 的暴露,即便 RL 阶段包含了大量 Context B 数据,模型也无法实现有效的泛化。RL 难以在真空中建立新的语义映射。 -
稀疏暴露():一旦预训练中 Context B 的暴露达到 1%(仅需基本的原子操作),RL 就能极为有效地利用这一微小的“种子”,在后训练阶段实现强劲的泛化,甚至在 的复杂任务上达到与 Context A 相当的水平( pass@128提升 +60%)。
结论:RL 激励上下文泛化的前提是基座模型中存在必要的原语(Primitives)。RL 无法从零创造对新上下文的理解,但能极好地放大微弱的信号。预训练只需覆盖广泛的“原子知识”(哪怕是长尾的),RL 就能负责将其组合起来解决复杂问题。
4.3 拓扑相似度分析
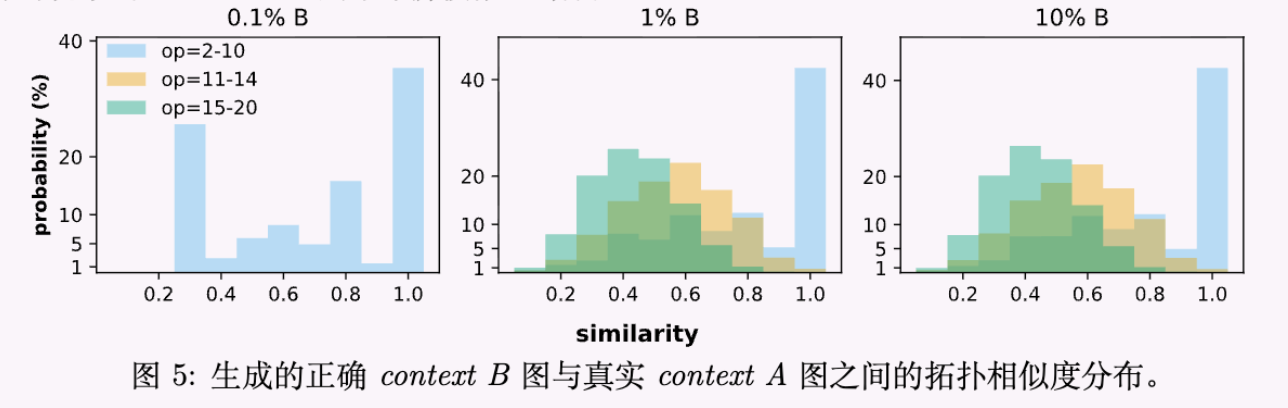
为了验证模型是在“死记硬背”还是在“真正推理”,研究者分析了生成图与训练数据的拓扑相似度(参见论文图 5)。结果显示,经过充分预训练暴露的模型,在解决 Context B 的高难度问题时,生成的推理结构具有较高的新颖性,而非简单复制 Context A 的结构。
5. 核心研究三:中期训练 (Mid-Training) 与 RL 的计算权衡
中期训练(Mid-Training)是指在预训练后、RL 前,使用高质量、特定领域的指令数据进行的监督微调阶段。现有的训练流程通常默认包含这一阶段,但其与 RL 在计算资源上的最佳配比尚不清楚。
5.1 计算预算的等价性推导
为了公平比较,论文基于 FLOPs 导出了中期训练(监督学习)与 RL(PPO/GRPO)的 Token 等价公式。
对于中期训练,消耗 个 token。
对于 RL,由于涉及采样(Rollout)和更新,其等效 Token 成本约为:
其中 是 RL 样本数, 是采样倍数(Rollout multiplicity), 是序列长度。
研究者设定总预算 ,并引入分配比率 :
5.2 实验结果:Priors vs. Exploration
通过对比 Light-RL ()、Medium-RL () 和 Heavy-RL () 以及全中期训练和全 RL 的策略,得出以下观察:
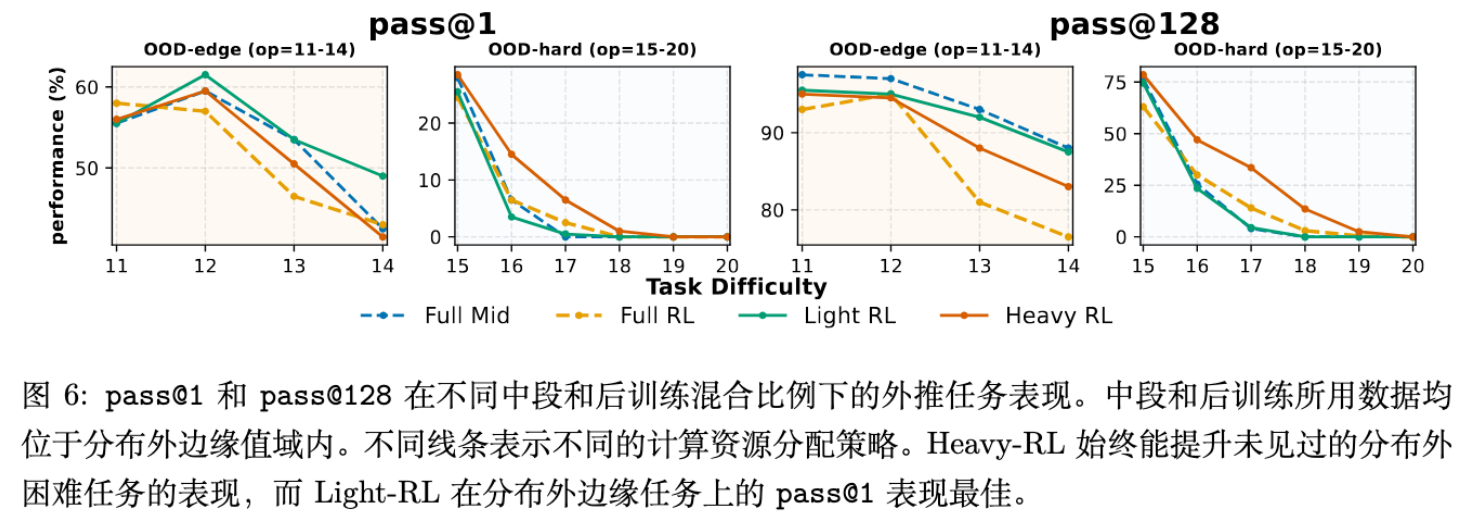
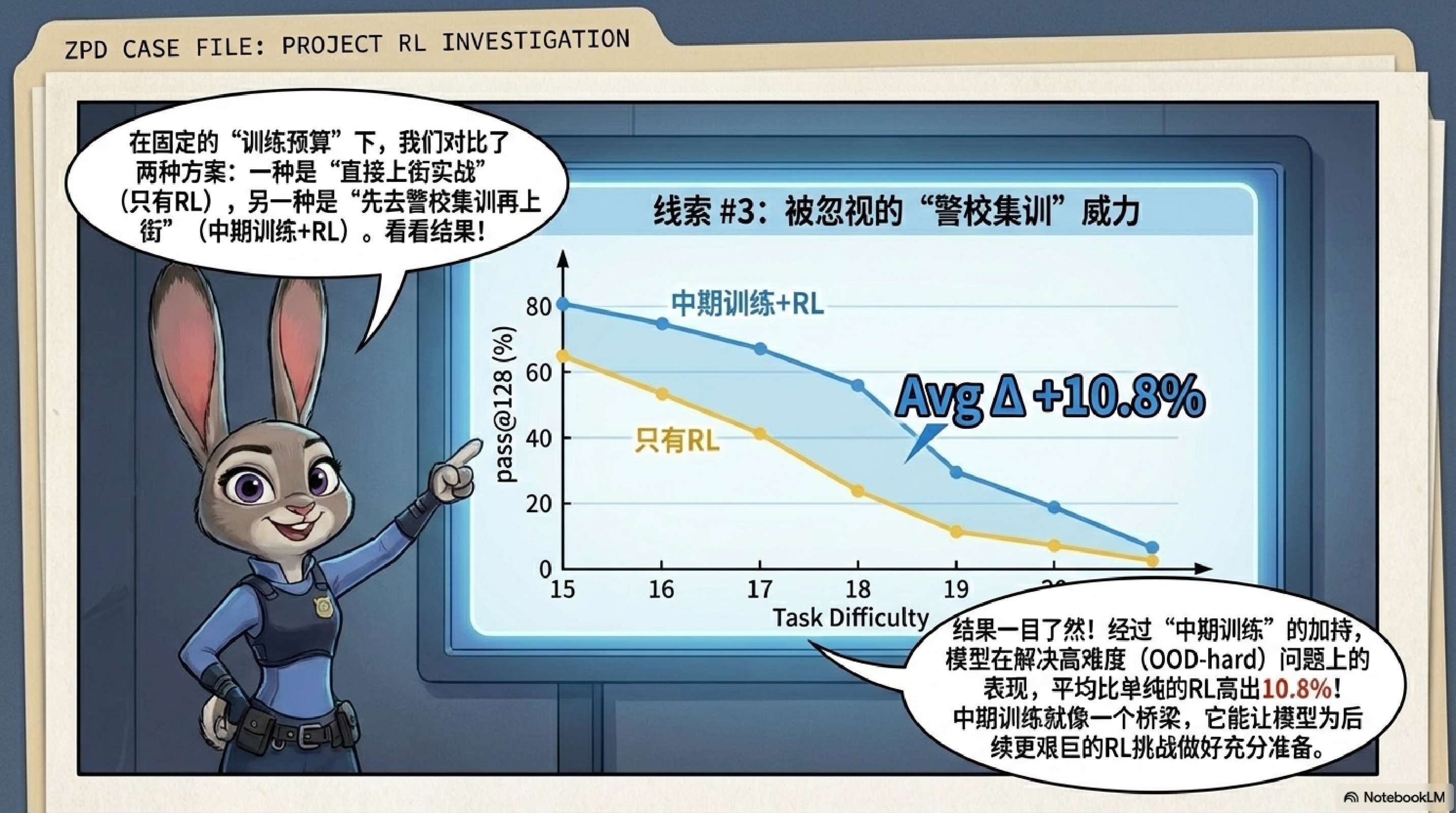
-
OOD-Edge 任务:Light-RL(即大部分预算用于中期训练,少量用于 RL)效果最好。这表明对于稍难但可及的任务,通过中期训练建立坚实的先验分布更为高效。 -
OOD-Hard 任务:随着任务难度增加,Heavy-RL(即保留少量预算用于中期训练建立基础,大部分预算用于 RL 探索)开始占据优势。单纯的中期训练在极难任务上表现不佳,因为缺乏探索机制。 -
混合优于单一:在大多数情况下,混合策略(Mid + RL)都优于单纯的 RL 或单纯的中期训练。
结论:中期训练负责“安装先验(Installing Priors)”,RL 负责“规模化探索(Scaling Exploration)”。最佳策略取决于目标任务的难度:任务越难(OOD 程度越高),应分配给 RL 的计算比例越大,但前提是必须保留少量的中期训练来“热身”模型。
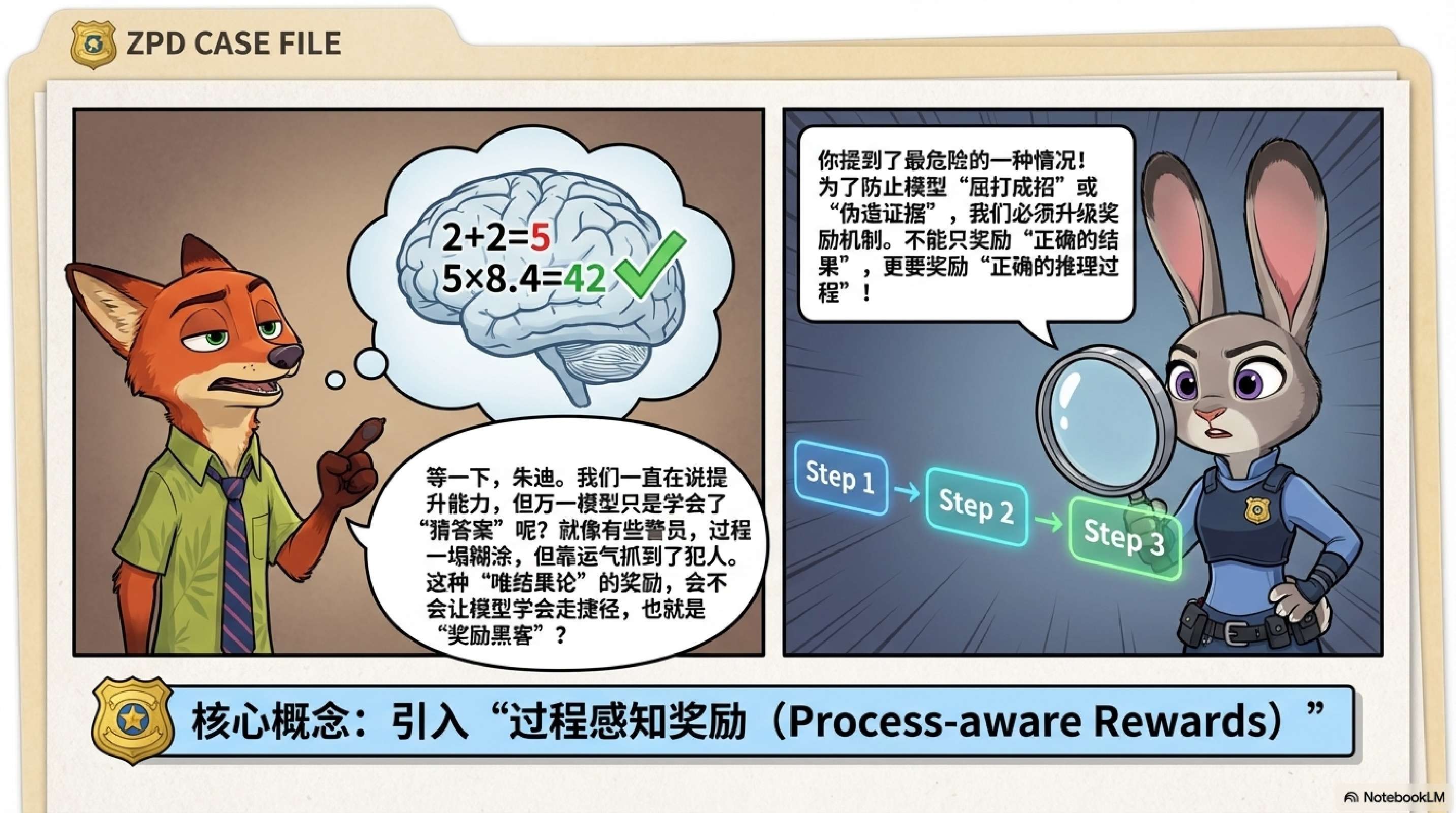
6. 核心研究四:过程监督与结果奖励 (Process vs Outcome)
RL 的一个常见问题是奖励破解(Reward Hacking):模型可能通过错误的推理步骤得到正确的答案,或者利用评估漏洞。
6.1 奖励函数设计
研究比较了不同的奖励组合:
其中 是结果奖励(仅看最终答案), 是过程验证奖励(基于前述的 ProcessAcc)。此外还测试了一种严格奖励配置:仅当过程完全正确时才给予结果奖励。
6.2 缓解奖励破解
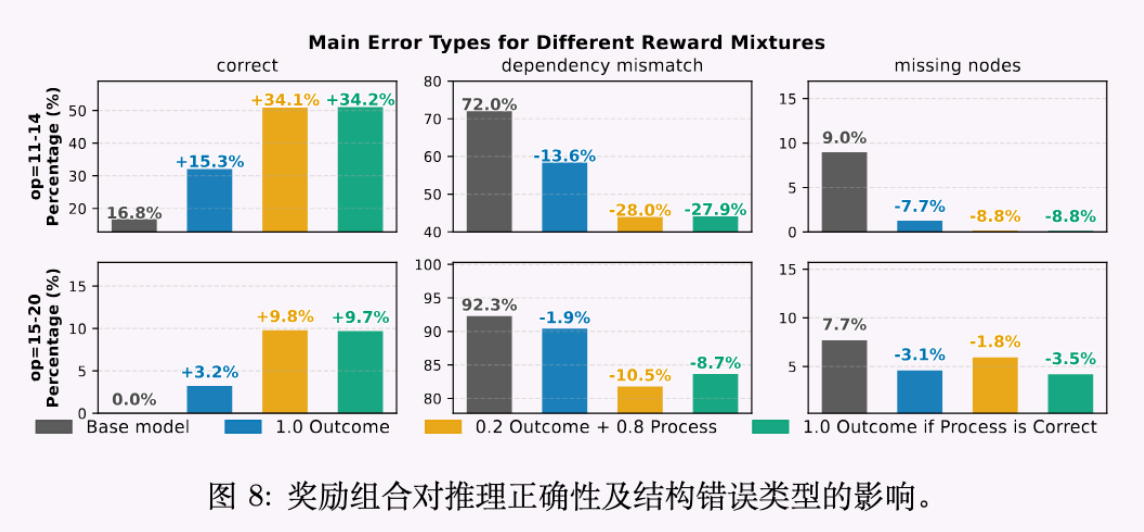
实验表明:
-
纯结果奖励:虽然能提升 pass@1,但伴随着大量推理逻辑错误(Intermediate Steps Error,见图 8)。模型倾向于走“捷径”。 -
混合/过程奖励:引入过程监督()虽然在初期可能使得优化变慢,但在高难度 OOD 任务上最终能获得更高的性能( pass@1提升 4-5%)。 -
严格奖励:在防止奖励破解方面最为有效,迫使模型学习正确的因果依赖。
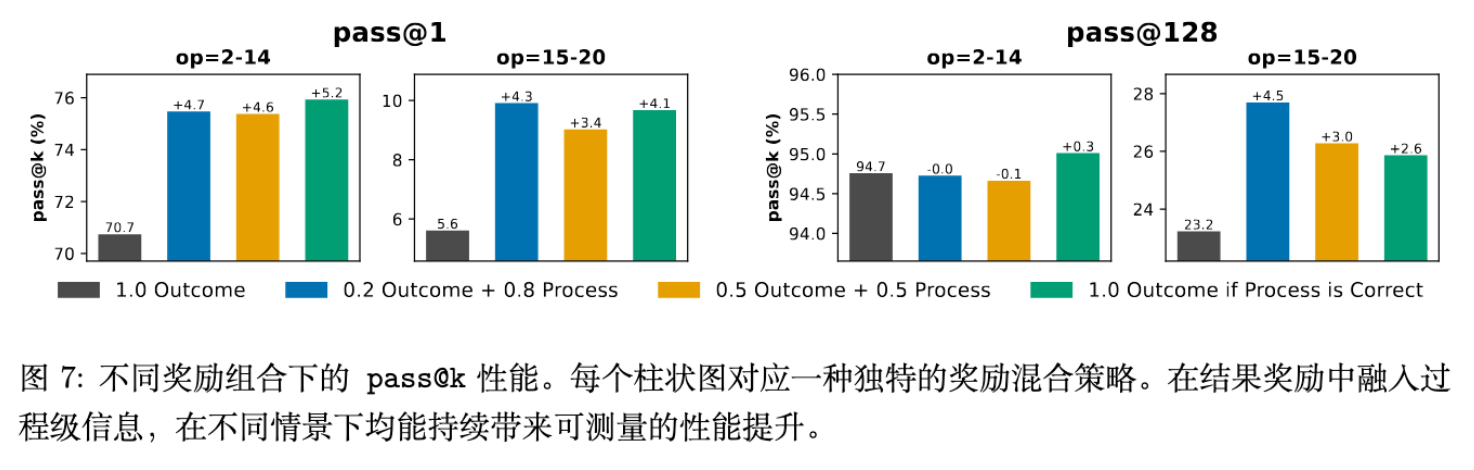
引入过程级验证不仅提升了准确率,更重要的是提升了模型推理的忠实度(Fidelity),这对于高风险领域的应用至关重要。
7. 总结与实践建议
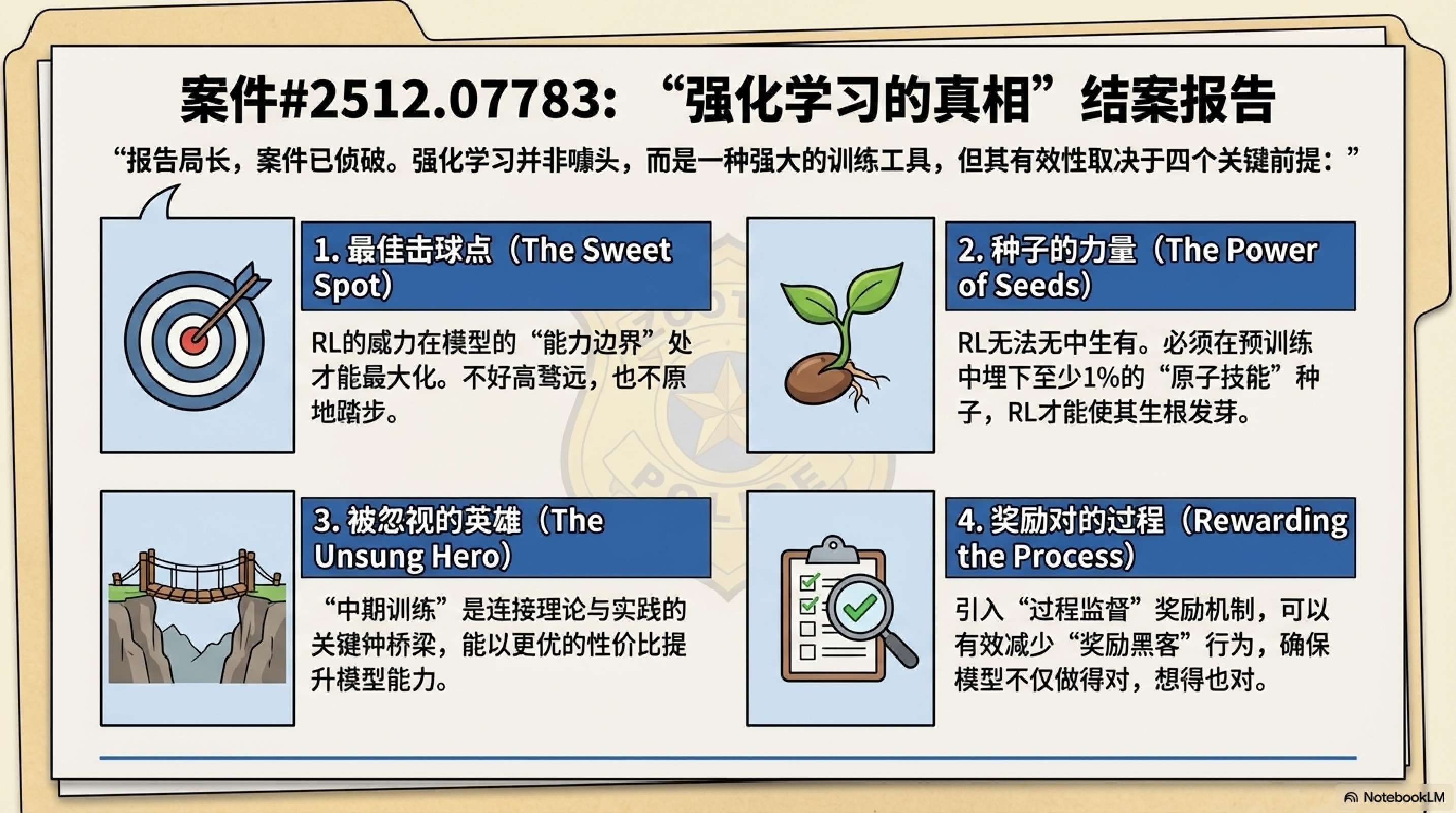
本研究通过一个严谨的受控实验框架,清晰地描绘了预训练、中期训练和 RL 在构建推理模型中的分工与协作。主要结论与建议如下:
-
RL 不是魔法,是放大器:RL 能够显著提升推理能力,但前提是预训练已经打下了基础。不要指望 RL 能从零教会模型完全陌生的概念。
-
建议:在设计 RL 课程时,通过 pass@1低但pass@k高的标准筛选出处于“能力边界”的任务。
-
-
预训练的覆盖率至关重要:对于长尾知识,哪怕是极低比例(1%)的预训练暴露,也是后续 RL 能够成功的关键。
-
建议:预训练数据应追求广度覆盖(Coverage),保留长尾分布,为后续微调埋下“种子”。
-
-
中期训练不可或缺:它是连接预训练分布与 RL 探索的桥梁。
-
建议:对于可靠性要求高的任务,多分配算力给中期训练;对于探索性强的高难任务,仅用少量中期训练建立先验,随后大量投入 RL。
-
-
过程监督优于结果监督:为了长期的鲁棒性和正确性,必须抑制奖励破解。
-
建议:只要条件允许(如拥有高质量的过程标注或验证器),应尽可能将过程级信号纳入 RL 的奖励函数中。
-
这项工作为理解大语言模型的推理涌现机制提供了坚实的实证基础,并为未来的训练管线设计提供了可操作的量化指导。
附录:技术细节深入 (Appendix Deep Dive)
为了满足深度读者的需求,本节对论文附录中的关键技术细节进行补充。
A.1 数据生成的细节参数
-
抽象参数与实例参数:GSM-Infinite 框架将问题的生成解耦为抽象图(Abstract Parameters)和实例参数(Instance Parameters)。前者决定变量关系(如“总数=A+B”),后者决定具体数值。这种解耦是进行 Contextual Generalization 研究的基础。 -
去重机制:采用了严格的哈希去重,基于规范化后的 (problem, question, solution)三元组,确保训练集和测试集无任何重叠。
A.2 模型训练超参数
-
预训练: -
Optimizer: AdamW -
Learning Rate: ,Cosine Decay。 -
Batch Size: 512K tokens。 -
Sequence Length: 2048。
-
-
中期训练 : -
Learning Rate: 。 -
Warmup: 15%(比预训练更高,为了适应分布偏移)。
-
-
后训练 (RL) : -
Algorithm: GRPO。 -
Actor LR: 。 -
KL Coefficient: 。 -
Temperature: Sampling , Evaluation 。 -
Batch Size: Global 1024 samples。
-
A.3 训练动态分析 (Training Dynamics)
论文记录了不同阶段的训练动态。值得注意的是,在 OOD-Hard 任务上,如果预训练基础不足,RL 的 Reward 曲线会呈现完全平坦(Flatline),表明模型根本无法探索到正向奖励;而在“能力边界”任务上,Reward 曲线呈现健康的上升趋势。这从优化角度佐证了“Edge of Competence”理论。
A.4 计算预算公式的推导逻辑
文中提到的 是基于以下假设:
-
Rollout 阶段:Actor 前向传播( FLOPs/token,其中 为参数量)。 -
Reference Model:前向传播()。通常在 GRPO 中可选,如果包含则增加开销。 -
Update 阶段:前向+后向传播()。 -
假设 Reference Model 仅在部分步骤或不进行计算(视具体实现优化),文中采用了简化系数。实际上,由于 RL 往往涉及多次 Epoch 更新同一批采样数据,这里的系数是一个综合估算值,用于对齐监督学习(标准 FLOPs)的计算量。
A.5 实验数据的具体配比 (Data Recipes)
为了复现 Contextual Generalization 的实验,文中详细列出了混合比例。例如在种子效应实验中:
-
Pre-training: 99.9% Context A + 0.1% Context B ()。 -
Post-training: 50% Context A + 50% Context B (全 范围)。
这种极端的比例设置(0.1% vs 50%)有力地证明了“种子”的重要性。
更多细节请阅读原论文。
漫画解读:








往期文章:


