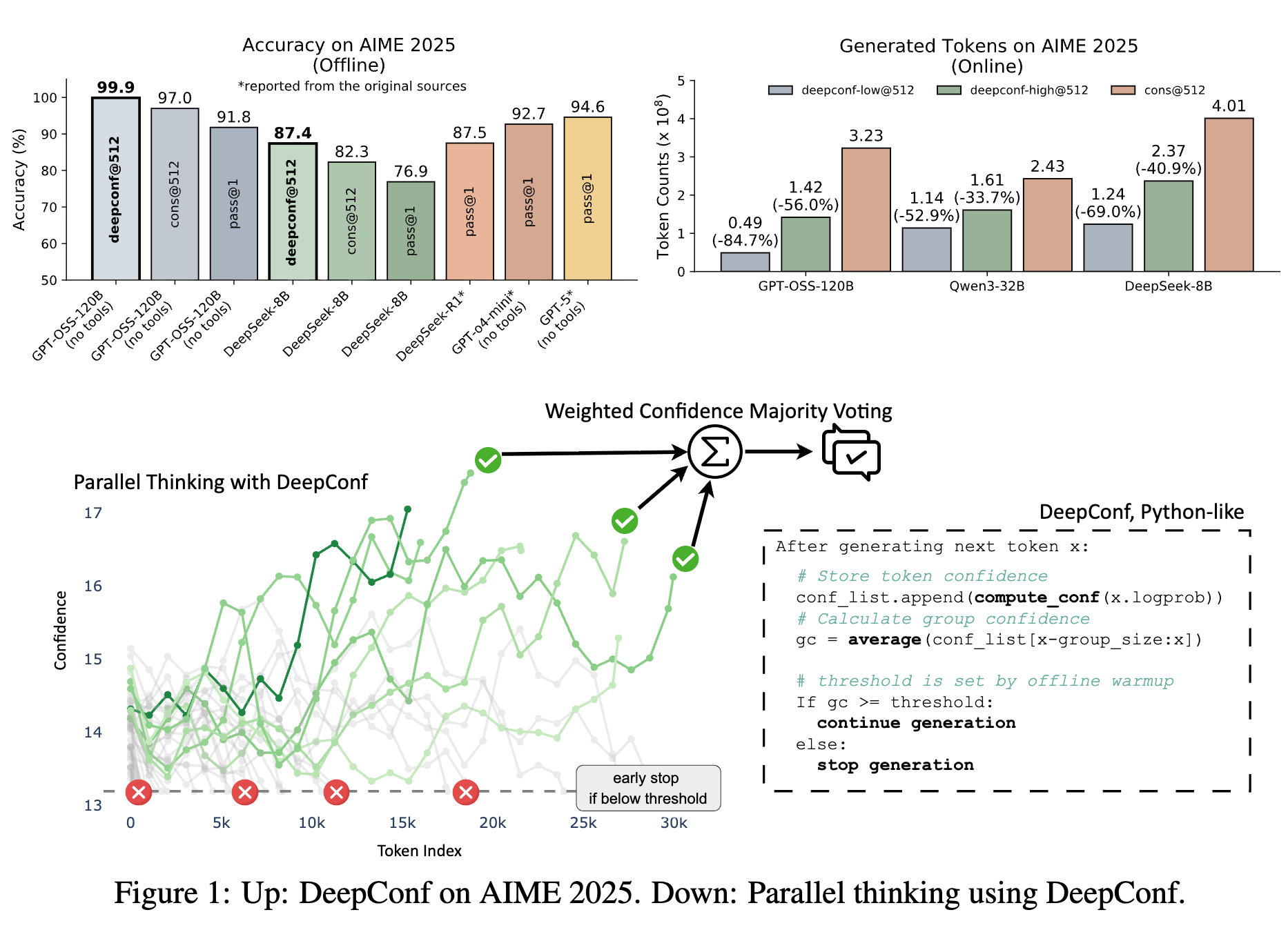
最近出了不少基于内在反馈的强化学习(Reinforcement Learning from Internal Feedback, RLIF)的研究成果,RLIF不依赖任何外部奖励,而是完全利用模型自身产生的内在信号(如不确定性、自信度等)来指导学习过程。这种“自力更生”的方法引发了一个核心问题:内在反馈究竟能在多大程度上提升LLM的推理能力?它是否是一种普适的解决方案?
本文介绍的这篇论文《No Free Lunch: Rethinking Internal Feedback for LLM Reasoning》,对这一问题进行了系统而深入的探讨。该研究不仅揭示了RLIF方法的潜力,更重要的是,它清晰地指出了其固有的局限性,并剖析了其背后的作用机制。研究结果表明,RLIF并非“免费的午餐”,其有效性与模型的初始状态紧密相关,尤其取决于模型的“初始策略熵”。

-
论文标题:No Free Lunch: Rethinking Internal Feedback for LLM Reasoning -
论文链接:https://arxiv.org/pdf/2506.17219
背景
在深入探讨RLIF之前,我们有必要简要回顾一下LLM后训练技术的发展脉络,以便更好地理解RLIF的提出动机及其独特性。
外部监督
LLM的预训练使其掌握了海量的语言知识,但如何让模型更好地遵循人类指令、符合人类偏好,并进行复杂的多步推理,是后训练阶段需要解决的核心问题。
-
基于人类反馈的强化学习 (RLHF): RLHF是该领域的一项开创性工作。它通过收集人类对模型不同输出的偏好排序,训练一个奖励模型(Reward Model)。这个奖励模型随后作为“代理裁判”,在强化学习过程中为LLM的输出打分,引导LLM生成更符合人类偏好的内容。然而,RLHF的成功建立在大量高质量的人类标注数据之上,这是一个劳动密集型且成本高昂的过程。
-
基于可验证奖励的强化学习 (RLVR): 为了降低对人类标注的依赖,研究者们提出了RLVR。RLVR适用于那些答案可以被程序自动验证的领域,例如数学问题(验证最终答案是否正确)和代码生成(执行代码看是否通过单元测试)。通过这种方式,可以自动获得一个清晰、客观的奖励信号。尽管RLVR在特定领域取得了巨大成功,但其应用场景受限,对于许多开放式、没有唯一正确答案的推理任务则无能为力。
RLHF和RLVR的共同点在于,它们都依赖于一个外部的、预先定义的“正确”标准,无论是人类的偏好还是一个可验证的答案。这种对外部监督的强依赖性,构成了它们在可扩展性和应用普适性上的主要瓶颈。
强化学习之内在反馈 (RLIF)
正是在RLHF和RLVR的局限性之上,RLIF的概念应运而生。RLIF的核心思想是,模型在生成答案的过程中,其内部状态本身就蕴含着丰富的、可用于自我改进的信号。例如,模型对于下一步生成哪个词元(token)的不确定性程度,或者对于整个生成轨迹的整体置信度,都可以被量化并用作奖励信号。
RLIF的最大优势在于其无监督的特性。它摆脱了对外部标注数据或验证器的依赖,使得在任何领域进行模型的自我优化成为可能,极大地降低了训练成本并提升了方法的通用性。 然而,这种“向内求”的方式也带来了新的问题:这些内在信号是否真的与“好的推理”正相关?它们又将如何影响模型的行为?这正是《No Free Lunch》这篇论文试图解答的核心问题。
RLIF的核心:内在反馈信号与策略熵
为了实现RLIF,首先需要定义和量化那些可作为奖励的“内在反馈信号”。该论文重点研究了三种代表性的内在信号:自我确定性、词元级熵和轨迹级熵。
三种内在反馈信号
-
自我确定性 (Self-Certainty):
自我确定性衡量的是模型输出概率分布的“自信程度”。它通常通过计算模型在每个生成步骤的输出概率分布与一个均匀分布之间的KL散度(Kullback-Leibler Divergence)来量化。如果模型的输出概率高度集中在少数几个词元上(即“尖锐”分布),那么它与均匀分布的KL散度就大,表明模型对此步生成非常“确定”。反之,如果概率分布较为平坦,则KL散度小,表示模型较为“犹豫”。RLIF的目标是最大化这种自我确定性,即鼓励模型生成它“认为”最可能的序列。
其奖励函数可以表示为:其中, 是生成的序列, 是序列长度, 是输入, 是模型策略, 是一个均匀分布。
-
词元级熵 (Token-Level Entropy):
熵是信息论中衡量不确定性的经典指标。词元级熵计算的是模型在每个生成步骤的输出概率分布的熵。低熵意味着低不确定性(分布尖锐),高熵则意味着高不确定性(分布平坦)。在RLIF中,通常使用负熵作为奖励,即最小化每一步生成的不确定性。
其奖励函数为:其中, 代表香农熵。
-
轨迹级熵 (Trajectory-Level Entropy):
与词元级熵关注每一步不同,轨迹级熵衡量的是整个生成序列 的总概率(或对数概率)。一个序列的整体概率越高,其轨迹级熵(这里指负对数概率)就越低。RLIF的目标是最大化整个序列的概率,等价于最小化轨迹级熵。
其奖励函数可以表示为(经过归一化):

内在信号的理论关联:策略熵 (Policy Entropy)
尽管这三种内在信号的计算方式各不相同,但该论文通过理论分析指出,它们在本质上是部分等价的。优化这些不同的内在奖励,最终都指向一个共同的目标:最小化模型的策略熵(Policy Entropy)。
策略熵是衡量一个策略(在这里即LLM)在其所有可能输出上的不确定性的一个宏观指标。一个高策略熵的模型,其行为更加随机和具有探索性;而一个低策略熵的模型,其行为则更加确定和固化。论文中的命题1、2、3分别从理论上论证了,使用上述三种内在信号作为奖励进行强化学习,都会直接或间接地导致模型整体策略熵的下降。
这个理论洞察至关重要,因为它将RLIF的行为统一到了一个核心机制上:熵的最小化。这也为后续解释RLIF复杂的性能变化奠定了理论基础。简单来说,RLIF就是在驱使模型变得越来越“自信”和“确定”。然而,这种“确定”是福是祸?实验部分给出了答案。
实验研究:RLIF是灵丹妙药还是昙花一现?
为了验证RLIF的实际效果及其作用机制,研究人员进行了一系列详尽的实验。
实验设置
-
模型: 实验采用了Qwen系列的不同尺寸模型,包括Qwen2.5-3B, Qwen3-1.7B, 和 Qwen3-4B等基础模型(Base Models),以及经过指令微调的模型(Instruct Models)。 -
基准测试: 评估在多个具有挑战性的数学推理数据集上进行,包括AIME2025、MATH500和GSM8K。这些数据集为评估模型的复杂推理能力提供了良好的平台。 -
训练框架: 所有实验都在包含7500个问题的MATH训练集上进行,并采用GRPO(Group Relative Policy Optimization)算法框架,这是一种无评论家(critic-free)的强化学习算法。
先甜后苦:RLIF的性能变化曲线
实验结果揭示了一个非常一致且有趣的模式:性能先升后降。
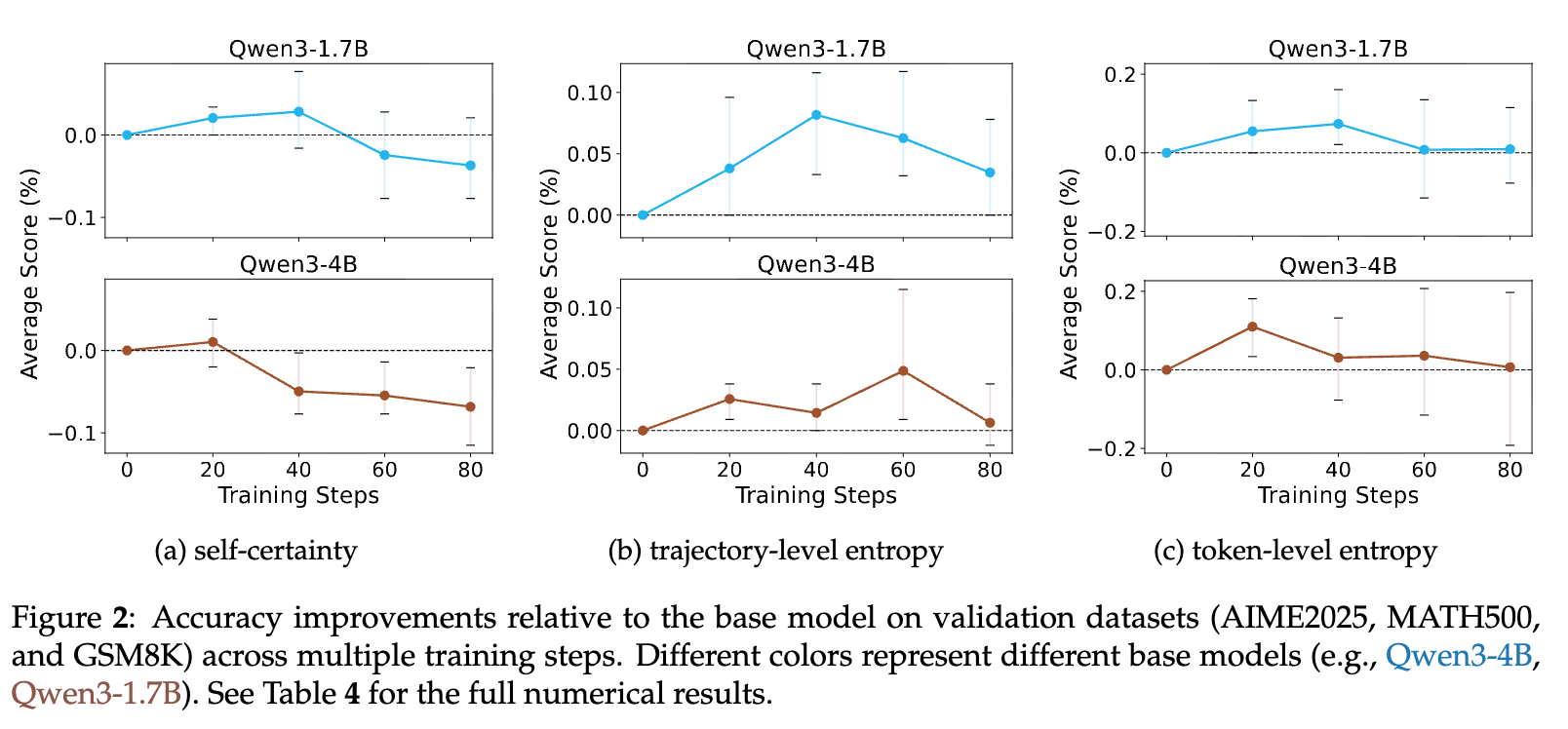
如上图所示,在训练的早期阶段(通常是前20个梯度步),与未经训练的基础模型相比,使用RLIF训练的模型的准确率有显著提升。这表明,RLIF确实能够在初期激发基础模型的推理潜力,其表现甚至能够匹配或超过一些需要外部监督的RLVR方法。
然而,美好的时光是短暂的。随着训练的继续,模型的性能开始逐渐下滑,甚至在某些情况下,最终性能比训练开始前还要差。这种性能的衰退现象在不同的模型、不同的内在反馈信号上都普遍存在,暗示了其背后有一个共同的根本原因。
这一“先甜后苦”的现象是该论文的核心发现之一,它直接挑战了将RLIF视为一种简单、普适的优化方法的看法。
深入剖析:为何性能会先升后降?
为了解释这一现象,研究者们从模型行为的角度进行了深入的微观分析,最终将原因归结为模型从欠缺自信(Underconfidence)到过度自信(Overconfidence)的转变。
“过渡词”的消失与过度自信
研究人员引入了“过渡词”(transitional words)的概念。这些词,如 "但是 (but)"、"等等 (wait)"、"让我检查一下 (let me check...)"、"或者 (alternatively)" 等,在复杂推理过程中扮演着至关重要的角色。它们通常标志着模型正在进行自我修正、探索不同思路或对中间步骤进行反思。这些词汇在生成时通常伴随着较高的熵,因为模型在这些节点上正处于决策的不确定状态。

实验分析发现,随着RLIF训练的进行(即策略熵的不断降低),这些关键的“过渡词”出现的频率显著下降。模型不再“犹豫”和“反思”,而是倾向于生成一条直接、简短、看似自信的推理路径。
这种行为模式的转变解释了性能的变化曲线:
-
初期性能提升 (缓解欠缺自信): 基础模型通常存在“欠缺自信”的问题。它们可能会生成过于冗长、充满不必要犹豫和重复检查的推理过程(例如,在一个循环中反复说“让我检查一下”),甚至因为超长而无法在规定长度内给出最终答案。RLIF通过最小化熵,有效地抑制了这种冗余的探索,使得模型的输出更加简洁、目标导向,从而提高了遵循指令(给出答案框)的能力,带来了初期的性能提升。
-
后期性能下降 (导致过度自信): 然而,当熵被过度压缩后,模型就走向了另一个极端——“过度自信”。它会过早地锁定一个思路,即使这个思路是错误的,也不会再进行充分的探索和修正。由于“过渡词”的消失,模型失去了探索替代推理路径的能力。这种“浅层推理”(shallow reasoning)和过早得出结论的行为,最终导致了推理能力的下降。
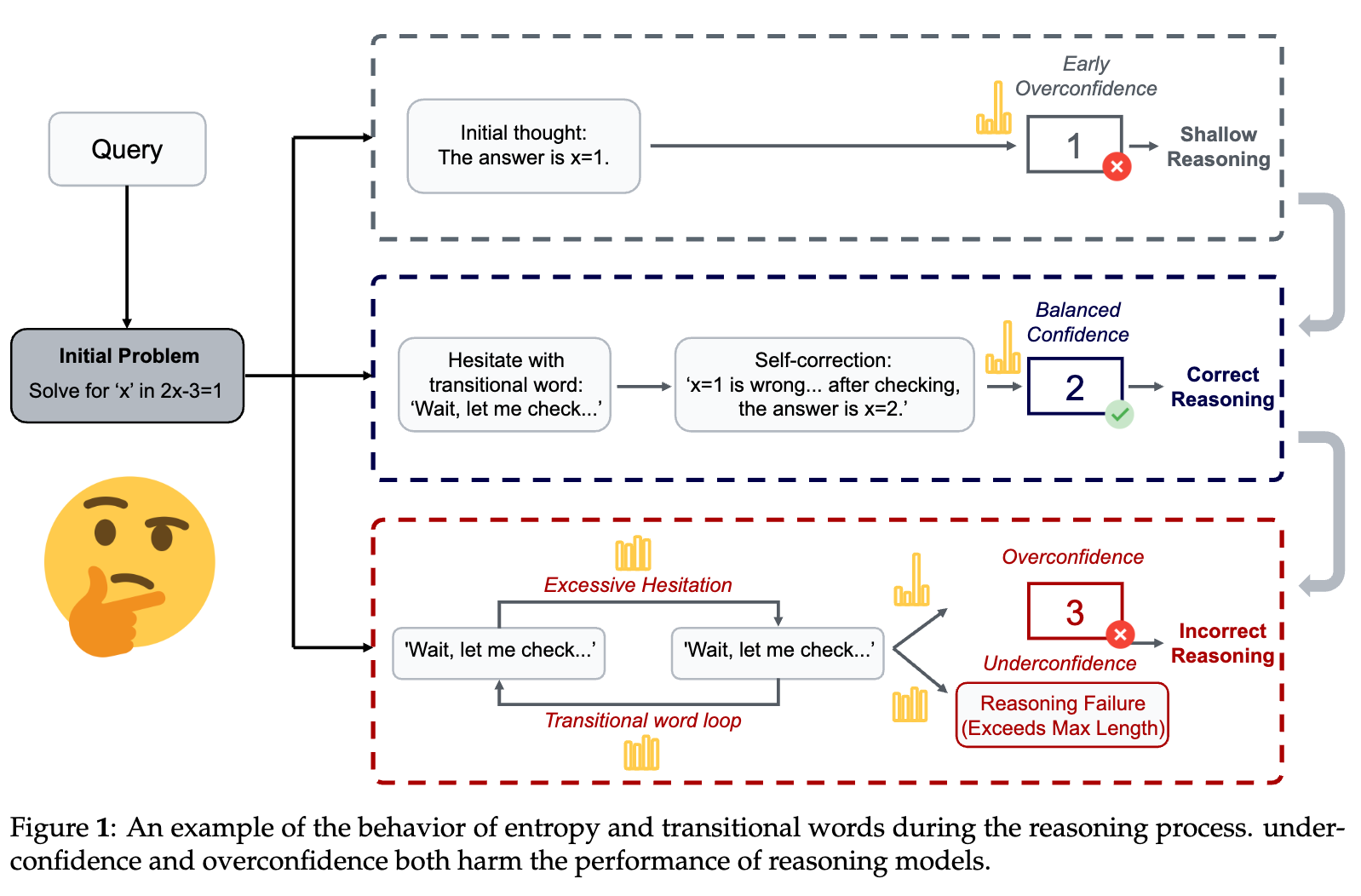
上图生动地展示了这两种状态。欠缺自信(Excessive Hesitation)和过度自信(Overconfidence)都会损害推理性能。RLIF的作用就像一个调节器,它成功地将模型从“欠缺自信”区域拉了出来,却不幸地用力过猛,将其推入了“过度自信”的深渊。
RLIF成功的关键:初始策略熵
既然RLIF的效果如此依赖于模型的自信程度,那么一个自然而然的推论是:RLIF的有效性取决于模型开始训练时的初始状态,即初始策略熵。
基础模型 vs. 指令微调模型
为了验证这一假设,研究者们比较了RLIF在两种不同类型的模型上的表现:基础模型(Base Models)和指令微调模型(Instruction-Tuned Models)。
-
基础模型: 仅经过预训练,没有经过针对性的指令遵循或对话优化。这类模型通常具有较高的初始策略熵,行为更加多样化和不确定。 -
指令微调模型: 在基础模型之上,使用大量指令-回答对进行了监督微调(SFT),使其能更好地理解和遵循人类指令。这个过程本身就会降低模型的策略熵,使其输出更加确定和格式化。
实验结果清晰地表明:
-
对于高初始策略熵的基础模型,RLIF能够带来显著的初期性能提升(尽管后期仍会下降)。 -
而对于低初始策略熵的指令微调模型,RLIF几乎没有任何效果,甚至从一开始就会导致性能下降。
这证实了初始策略熵是决定RLIF成败的关键因素。当一个模型已经被指令微调“规训”得很好、策略熵很低时,再使用RLIF去进一步压缩熵,不仅没有收益,反而会破坏其已经学到的推理结构,导致性能退化。
模型融合实验的巧妙验证
为了进一步提供更细粒度的证据,研究者们设计了一个巧妙的模型融合(Model Merging)实验。他们通过线性插值的方式,将一个基础模型(高熵)和一个指令微调模型(低熵)的权重进行融合,创造出了一系列介于两者之间的“中间模型”。融合比例 代表了指令微调模型所占的权重。
这样,他们就获得了一个初始策略熵从高到低平滑过渡的模型谱系。对这些模型分别进行RLIF训练,结果完美地印证了他们的假设。
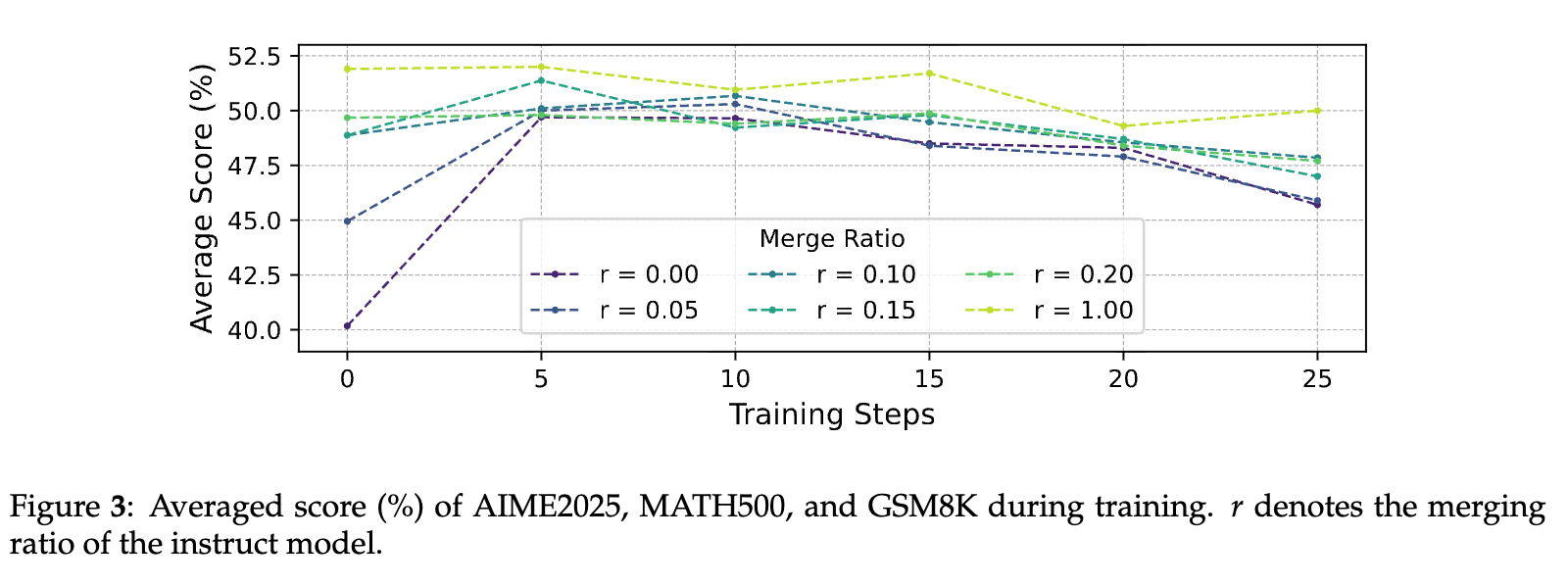
如上图所示,融合比例 越小(即模型越接近基础模型,初始熵越高),RLIF带来的性能提升越明显。而随着 的增大(模型越接近指令微调模型,初始熵越低),RLIF的效果逐渐减弱,直到在纯指令微调模型()上变为负向影响。
这个实验强有力地证明了,RLIF并非一种独立的优化技术,它的作用更像是对模型现有策略熵的一种“消耗”。只有当模型拥有足够高的初始熵时,这种“消耗”才能在初期带来正面效果。
点评
“天下没有免费的午餐”
论文的标题本身就是对其核心思想的最好概括。RLIF通过利用模型内在信号,省去了外部监督的昂贵成本,但这并不意味着它是没有代价的“免费午餐”。它的代价是策略熵的消耗,以及随之而来的探索能力的丧失。当模型从一个过于探索(欠缺自信)的状态被推向一个过于利用(过度自信)的状态时,推理能力的下降便不可避免。
这项研究为未来LLM的后训练,特别是强化学习的应用,提供了宝贵的实践指导:
-
审慎使用RLIF: 在应用RLIF时,需要首先评估模型的初始状态。它可能适合作为一种对基础模型进行初步“精炼”和“聚焦”的手段,但不应作为持续提升性能的长期策略。 -
动态熵管理: 一个更有前景的方向可能是开发能够动态管理策略熵的算法。在训练初期,可以允许熵的适度下降以提高效率;但在后期,需要有机制来维持甚至适度增加熵,以避免模型陷入“过度自信”的陷阱,保持其探索和自我修正的能力。 -
混合奖励信号: 将内在反馈信号与外部奖励信号(即使是稀疏的)相结合,可能是一种取长补短的有效策略。内在信号可以提供密集的、引导性的奖励,而外部信号则可以作为最终的、更可靠的校准标准。