让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Value-Gradient Hypothesis of RL for LLMs
-
论文链接:https://arxiv.org/pdf/2605.21654
TL;DR
今天解读一篇来自 MBZUAI 与独立研究团队合作的论文《Value-Gradient Hypothesis of RL for LLMs》,它为我们重新审视大模型强化学习(RL)提供了一个全新的理论视角。
近年来,在大语言模型(LLM)的对齐与后训练(Post-training)阶段,无 Critic 的强化学习方法(例如 GRPO)因其高效的显存利用率和出色的推理表现而得到了极大的推广。然而,这带来了一个理论上的悖论:传统的强化学习理论明确指出,缺乏 Critic 进行显式价值评估的策略梯度方法(如无 Baseline 的 REINFORCE),在面临长时序(Long-horizon)信用分配问题时,会因为方差过大而失效。那么,为什么在大模型中,彻底舍弃 Critic 的方法反而能够极其稳定且高效地工作?
为了填补这一理论与实践之间的鸿沟,作者提出了值梯度假设(Value-Gradient Hypothesis)。该假设认为,大模型的反向传播天然地在计算和传递类似于值梯度的信号。具体而言,在一套连续松弛(Continuous Relaxation)的微分展开路径下,作者证明了基于策略梯度的 Actor 梯度更新在期望意义上等同于通过时间反向传播(BPTT)计算的共态(Costate),而该共态的条件期望正好等于真实的值梯度。
在离散的 Transformer 架构中,由于离散 Token 的采样瓶颈,这种微分路径在表面上似乎被切断了。然而,作者通过严格的理论推导指出,Transformer 内部的注意力机制(Attention Mechanism)实际上为信用信号的跨时序传递提供了一条完全可微的“内容旁路”。通过反向传播,算法隐式计算出一种“经验共态”,它能非常好地逼近理想状态下的 BPTT 信号。这种逼近的误差受到策略熵(Policy Entropy)以及采样差距的严格约束:当策略趋向于确定性(低熵状态)时,离散采样带来的误差会逐渐消失,Transformer 就越接近一个完美的连续值梯度优化器。
这一视角不仅解释了 GRPO 的机制,还派生出了一套实用的“RL 准备度(RL Readiness)”预测公式。研究表明,大模型在预训练阶段何时能从强化学习中获得最大的收益,取决于两个关键因子的乘积:可用值梯度信号(Usable Value-Gradient Signal)与可达头顶空间(Reachable Headroom)。利用该定律,我们能够实现完全无需训练的强化学习节点预测,为大模型预训练过程中的检查点选择(Checkpoint Selection)提供了理论指导。
1. 引言
在当前大语言模型(LLM)的技术演进路径中,强化学习(RL)已经成为提升大模型逻辑推理、数学计算以及编程能力的标准底座。在这一趋势下,诸如群组相对策略优化(GRPO, Group Relative Policy Optimization)等移除了独立 Critic/Value 模型的算法,在大模型训练中表现优异。相比传统的 PPO 算法,它不仅节省了巨大的显存开销,还能在长时序、多步推理的任务中取得极为稳健的对齐效果。
然而,这一应用成果却与经典强化学习(Classical RL)的基石理论产生了严重的冲突。在传统的时序差分(TD)或策略梯度(PG)理论中,如果一个强化学习算法既不维护一个状态价值函数 ,又不维护一个动作价值函数 (即所谓的 Critic),那么它在处理长时序信用分配(Temporal Credit Assignment)时,就必须依赖完全基于路径(Trajectory-based)的蒙特卡洛回报估算。在长时序任务中,这种估算会带来巨大的方差,通常会导致算法在没有大量样本支撑的情况下彻底无法收敛。大模型在动辄成百上千个 Token 的自回归解码过程中,面临着极度严苛的时序信用分配挑战,但实际上,不带 Critic 的 GRPO 不仅没有崩溃,反而展现出了比传统 PPO 更容易调参、更稳健的收敛特性。
这种理论与现实的背离揭示了一个可能性:大模型中的无 Critic 强化学习,实质上并不是“无 Value”的。
作者在论文中首次正面回应并系统性解答了这一谜题。他们的核心发现和论点可以总结为以下几点:
-
反向传播就是值梯度传播:在连续松弛的 LLM 展开轨迹中,策略梯度(如 PPO、GRPO)的 Actor 梯度更新在数学期望上等价于基于 BPTT(Backpropagation Through Time)的路径梯度。BPTT 反向传播的中间敏感度(即伴随变量/共态,Costate)的条件期望,在数学上精确等于状态空间上的真实值函数梯度(Value Gradient)。 -
注意力机制构成了微分旁路:在实际采用离散 Token 采样的 Transformer 结构中,普通的循环神经网络(RNN)会因为离散采样这一不可微边界而彻底阻断 BPTT 的梯度回传。然而,Transformer 的多头自注意力机制(Multi-Head Self-Attention)天然地在各个时间步(Token)之间建立了一条直接可微的隐状态关联通道通道。即使跨越了离散采样的瓶颈,由于注意力机制的存在,大部分时序信用信号仍然能够通过这条“微分旁路”无损地向前传递。 -
策略熵控制着逼近误差:离散 Token 采样所造成的梯度缺失(即采样间隙,Sampling Gap),在数学上被证明与其策略的局部熵密切相关。当 LLM 在预训练中逐渐成熟,对高频、确定性词汇(例如代码语法、常见标点、高频词)的预测趋于低熵、高置信度状态时,采样间隙带来的梯度误差会迅速衰减到接近于零。这意味着,预训练中后期的大模型,在进行反向传播时,天然地就在计算近乎完美的理想值梯度。 -
大模型强化学习就绪度的定量预测:基于上述发现,作者提出大模型对于强化学习的吸收和转化效率并不是一成不变的。强化学习所能带来的增益,可以通过一个由“可用值梯度信号量”与“当前可达的奖励头顶空间”组成的乘积定律(Product Law)来精准描述。
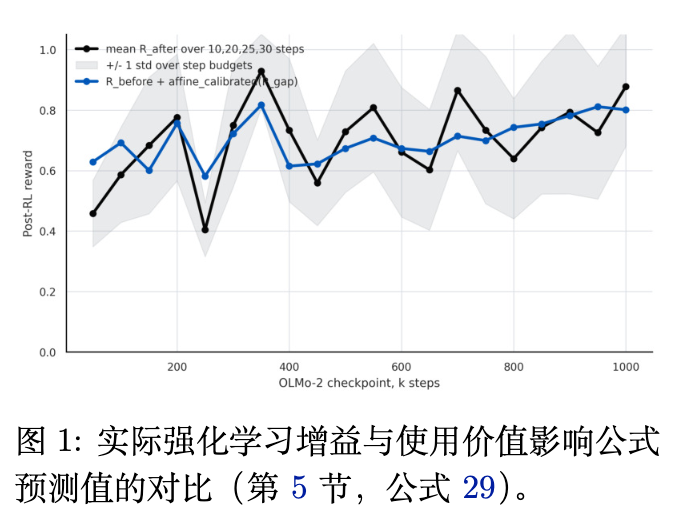
如图 1 所示,作者通过定量计算这套理论指标,成功地在预训练序列(以 OLMo-2 为基准模型)中高精度预测了何时启动强化学习能够获取最大幅度的评测点提升(真实 RL 增益的走势与理论预测高度契合)。
本文将对这篇论文的理论框架、数学推导、离散逼近定理以及相关的实证验证进行全面且细致的拆解。
2. 基础背景与数学形式化
在正式探讨“值梯度假设”之前,我们必须首先建立严格的符号系统,并回顾大模型强化学习中使用的主要组件和机制。
2.1 基础符号系统与大模型强化学习形式化
假定我们在处理一个提示词/问题 ,它采样自某个提示词分布 。给定 后,一个参数化为 的大语言模型策略产生一个自回归的文本片段(Completion / Rollout) 。在 Token 级因式分解(Token-level factorization)下,整个序列的生成概率可以写为:
其中,我们将 定义为 时刻的状态(State)(由提示词和截至目前已生成的 Token 历史拼接而成),而将 定义为 时刻的动作(Action)(当前解码生成的 Token)。因此,在 Token 级别上,一个完整的序列可以由轨迹 来唯一描述。
设 为 时刻模型生成的每 Token 奖励。在最常研究的仅有最终结果奖励(Outcome-only RL)的设定中,模型在中间解码步不获得任何即时奖励,而在最后一个 Token 解码结束时获得一个终端奖励:
引入折现因子 ,我们可以定义折现总回报(Discounted Return) 以及在 时刻的待归回报(Return-to-go) :
对于任意给定的策略 ,我们还可以进一步定义其在 时刻的时间索引价值函数(Value Function)、动作价值函数(Action-value Function) 以及优势函数(Advantage Function):
在这里,作者引入了一个区别于标量 的关键数学实体——值梯度(Value Gradient),定义为价值函数关于状态空间(即模型的隐状态空间)的导数:
需要强调的是,对于大模型而言,状态 (也就是上下文序列历史的表示)在模型内部对应的是高维连续的隐状态向量(Hidden States),因此 并不是标量,而是状态空间上的一个向量场(Vector Field)。
2.2 无 Critic 强化学习:以 GRPO 为例
GRPO(Shao et al., 2024)作为 PPO 的一种无 Critic 变体,其核心思想是摆脱了对任何价值预测模型(Critic)的显式参数化,取而代之的是通过对同一个提示词进行群组式的多次并行采样,利用群组内的相对得分来提供时序信用的基线(Baseline)。
具体来说,对于每个输入的提示词 ,GRPO 引导模型产生一组大小为 的采样序列 ,这些序列均来自旧的(或当前未更新的)策略 。我们定义这些并行采样的序列长度为 ,相应的每步状态为 。
如果当前处于结果奖励设定中,每一个生成的序列 会从环境(或 Reward Model)中得到一个标量结果得分 。GRPO 通过在当前的群组分布内执行简单的标准化,来为每一个采样序列 计算出对应的无偏差优势估算信号:
这里的 是为了防止除零的极小数值常数,而 代表整个群组的得分集合。
基于此,GRPO 将每个 Token 在当前状态下的重要性采样比率(Likelihood Ratio)定义为:
由于没有额外的 Critic,GRPO 直接将群组标准化后的序列标量得分 赋给该序列的所有生成步。因此,它在整个序列的所有 Token 步上使用了一个相同的、随时间恒定的优势度量:。其最终的裁剪代理目标函数(Clipped Surrogate Objective)并加入 KL 散度约束的形式为:
这里, 为 PPO 经典的裁剪阈值, 控制着策略偏离参考模型(Reference Model) 的惩罚。从公式可以看出,GRPO 与传统 PPO 最纯粹的区别就在于 的构造方式:它避免了基于时序差分学习(TD-learning)更新的价值网络,转而使用群组统计回报这一常量值,这在大模型领域被证明不仅能大幅缩减显存占用,其稳定性甚至在某些推理任务中压倒了 PPO。
2.3 梯度估计的两条基本路径:得分函数 vs 路径导数
大模型中的强化学习为什么能对复杂的长序进行合理的权重微调?这涉及参数 是如何向期望回报传递梯度信号的。在机器学习理论中,估计期望梯度 存在两种完全相反的基础技术路径(Schulman et al., 2015):
1. 得分函数(Score-function, SF)估计器
如果随机变量 的采样概率分布显式依赖于参数,即 ,我们有:
这也就是政策梯度(Policy Gradient)中著名的“对数求导技巧”(Log-derivative trick)。它的优点是不要求代价函数 在 空间上可导,甚至不需要 是连续函数。这是经典强化学习中离散动作控制、环境转移未知时的金标准(因为其只使用了标量反馈 )。但是,它的方差非常大,因为它完全忽略了环境和奖励本身的局部几何特征。
2. 路径导数(Pathwise-derivative, PD)估计器
在另一种视角下,如果我们能够将随机变量 表达为一个确定性的、可微分的关于参数 与独立外部噪声 的复合函数:,那么求导与求期望的算子将可以直接发生交换(即重参数化技巧,Reparameterization trick)(Rezende et al., 2014):
路径导数估计器直接利用了代价函数在状态空间上的斜率信息 (即局部几何结构),其方差通常远远低于得分函数方法。但是,它的应用代价是极为高昂的:这要求所有的系统环节(包括中间动作采样、环境状态动力学、奖励函数本身)在数学上必须是连续可微且能够重参数化的。
3. 连续视角:为什么无 Critic 强化学习天然携带值梯度信息
为了揭示大模型中 GRPO 的成功之谜,作者首先构建了一个优雅的连续松弛模型(Continuous Relaxation Model)。在这一设定中,虽然最终使用的是无 Critic 优化形式,但通过路径导数估计器与得分函数估计器的等价性,一个隐藏在反向传播计算图底层的“共态”变量将被逐步剥离出来。
3.1 连续展开模型与共态定义
为了实现连续分析,我们首先将离散的 LLM Token 解码过程抽象为一套符合重参数化特征的连续状态动力学系统。
定义 1(可微展开路径):假设策略输出函数 、状态转移函数 以及即时奖励函数 都是关于它们的参数与状态参数完全可微的函数。给定一组相互独立且同分布(i.i.d.)且不依赖于 的外部环境噪声序列 ,我们的序列生成状态与动作转移满足如下递推关系:
在这一框架中,如果所有的随机性源头均可由不受 影响的独立外部随机变量 显式表达,那么在任意给定的噪声序列实现下,最终的路径总回报 就是一个关于策略参数 的确定性可微函数。
这允许我们直接应用路径求导算子,通过时间反向传播(BPTT)(Fairbank & Alonso, 2012)来表达整个期望收益的目标梯度:
在微分流形的链式法则求导过程中,虽然反向传播的目标是计算关于大参数矩阵 的偏导数,但在物理和状态空间层面上,真正承载、向下游流动并累积时序梯度的核心中间变量,是目标总回报关于每一个中间状态 的局部导数,即所谓的共态(Costate,或称伴随状态):
共态在直觉上代表了一个非常简单物理含义:当前状态的扰动,会对系统的未来长期回报造成多大的累积变化。
3.2 伴随递推法则(Adjoint Recursion)与证明
既然共态 承载了长期回报的时序依赖性,它本身是如何通过时间反向回传计算的呢?作者在论文中给出了其满足的经典伴随公式:
命题 1(伴随递推,Fairbank & Alonso, 2012):在定义 1 的可微展开路径假设下,共态变量满足如下的反向递推方程(逆向时间轴自 递推至 ):
其中,算子 代表关于状态的全导数(Total Derivative),不仅需要刻画状态对于目标函数的直接影响,还需刻画状态通过对策略动作产生间接干扰后带来的连锁反应:
相应的,整个网络的精确路径梯度关于策略参数 的完整表达式可以写为(详见论文公式 7):
命题 1 的严密证明:
为了确保大模型研究员能够完全跟上这一套底层物理图像,我们在本节中完整重现作者在 Appendix A.2 中给出的数学链式法则展开过程。
对于折现待归回报,其满足单步时序展开式:
在固定的外部噪声流实值 下,由于中间所有的生成动作都由策略确定,我们先计算 关于状态 的总导数:
第一项即为即时奖励关于状态的全导数 。第二项中,由于未来状态 是 经过状态转移发生的第一受体,因此由多维链式求导法则,我们有:
将这两者代入,立刻便得到了伴随递推方程:
现在我们推导关于参数 的整体路径导数。设定 为状态关于参数的灵敏度张量。由状态递推公式:
接下来,总回报 关于参数 的全导数为:
我们要消除状态关于参数的项 。利用我们已经推导出的共态关系,我们将 强行代入上述表达式:
利用我们写出的 递推式,代换其中含有 的项:
合并所有项后,我们惊奇地发现,包含状态敏感度的主干项构成了一个伸缩级数(Telescoping Series):
由于初始状态 (即提示词 )是给定的,完全不依赖于网络参数 ,因此有 。同时根据终端定义,。因此这一串级数求和在代数上完全恒等于零。
收集所有剩余的非零微分项:
对该式求期望,两端即刻相符。命题 1 证毕。
3.3 桥梁:共态在期望上就是真实的值梯度
这是一个极具启发性的结论:为什么这一套与参数无关的中间共态变量 ,在大模型中能起到 Critic 估计器的作用?
我们对价值递推关系(Bellman 期望方程)在 上求导:
在连续可微的条件下,我们将积分号与求导号交换:
我们将这一期望导数公式与我们先前提到的共态递归式(命题 1 的公式 6)进行逐项对比:
由于这两套递推形式在数学结构上是严格同构的,由柯西-利普希茨条件和边界条件 ,我们可以得出在给定了当前状态历史 时的条件期望等价性结论(论文中的公式 9):
推论(值梯度等价性):通过 BPTT 反向传播流回每个时间步的敏感度共态变量 ,其在特定状态下的均值,本质上就是当前状态处真实价值函数 空间分布的值梯度。
换言之,我们根本不需要显式地去训练、收敛一个 Critic 来评估状态好坏。大模型的 BPTT 本身在逆时间流回计算时,已经隐式地完成了一个利用蒙特卡洛对值梯度进行的高效、无偏采样!
3.4 积分变换等价定理(SF = PD)与 GRPO 更新值梯度化
然而,真正的训练现实依然存在最后一个落差:大模型策略微调,使用的其实是得分函数估计器(如 GRPO / PPO 的强化学习目标梯度形式),而不是直接利用路径导数。我们在上面证明了“路径导数的中间流 是值梯度估计”,这能迁移到基于对数概率的策略梯度更新中吗?
作者在这里引入了 Fairbank & Alonso (2012) 经典的等价积分变换引理:
引理 1(移位策略下的得分函数与路径导数等价性):假设策略在特定的状态 下,其动作产生满足具有加性加噪/位移形式的概率分布:
这里, 是关于位移量的平滑概率密度函数且在积分边界处趋近于零(例如高斯分布、常数边界的平滑分布等)。 为模型输出的主动动作均值(如 Transformer 输出的隐状态 logits 前驱)。
对于任意在动作空间上可导的回报或函数 ,我们有得分函数形式与路径导数形式在期望意义下完全恒等:
引理 1 的推导步骤(论文 Appendix A.4):
令 为相对于均值的偏移随机噪声变量,那么它的概率密度函数为 ,完全与策略参数 无关。
首先,对对数概率分布关于 展开偏微分:
代入到得分函数期望形式的左侧积分中:
由于 ,上述积分可重写为:
我们对其应用分部积分法(Integration by Parts),利用 在边界项消失()的平滑特征:
由于边界项为零,该项化简为:
注意复合函数关于 的偏导在数值上等同于关于 的偏导数:。因此,上式直接写为:
两负相消。将该项带回至原始的 展开式中,即刻得证:
引理 1 证毕。
这一引理在传统强化学习与神经网络反向传播之间架起了桥梁。它表明:在局部满足位移特征的策略模型下,使用似然对数去乘上外部回报进行的粗糙策略梯度更新(左侧),在期望上严格等价于利用了奖励在状态动作空间内精密局域梯度的反向传播更新(右侧)。
将引理 1 逐个 Token 套用至大语言模型的生成路径中。如果我们把 GRPO 的群组标准化相对回报 视为反向传播时的“阻断梯度变量(Stop-gradient scalar)”,并在连续松弛下应用引理 1,那么大模型的局部梯度项直接变为了路径求导格式:
这便直接导出了整篇论文最核心的理论支柱之一:
定理(局部 GRPO 的值梯度形式,Corollary 1):在连续松弛与位移策略下,GRPO/PPO 的 Actor 期望策略更新,在数学上完全等价于一套通过时间反向传播(BPTT)计算得出的伴随敏感度更新。这种底层的反向传递信号 ,在期望上精确逼近真实的值梯度 。
这就是值梯度假设(Value-Gradient Hypothesis)。它强有力地指出:大语言模型基于策略梯度方法的对齐微调,在底层其实是在对状态空间进行一阶连续局部几何上的高维值函数优化,其本质上是不需要任何分离 Critic 来指导方向的。
4. 离散 Transformer 如何传递近似 BPTT 信号
连续松弛的结论非常精美,但在真实的大模型部署中,大模型采用的是离散 Token 采样(Discrete Categorical Sampling)。离散 Token 采样是一堵天然的“非微可微分隔离墙”,由于 Token 并不是一个能连续变动的连续标量,传统的 BPTT 链路在跨越 Token 生成边界时应该是彻底断裂、无法回传任何梯度的。
那么,离散状态下的 Transformer,又是怎么将这一套值梯度物理图像完好保存下来的?
4.1 Transformer 注意力旁路:绕过离散采样的奇迹
在离散状态下,一个 trajectory 的梯度流可以通过图示来表征其传递瓶颈。对于普通的循环神经网络(RNN)而言,状态 仅仅依赖于上一时刻的状态 以及上一步产生的离散 Token :
当进行反向传播时,因为 是离散采样产生的,其局域微分导数 为零(或者不存在),因此整个反向梯度的链条在第一步回传时就直接撞墙死亡。这也是为什么在传统的 RNN 动作控制中,无 Critic 的方法如果面临多步延迟反馈,必须完全退化为高方差的、路径级的纯得分估计。
但是,大模型的底座是 Transformer!
在自注意力机制中,模型并不要求必须通过上一步离散的 Token 才能感知过去。模型最后一层的隐状态 依赖于过去的所有隐状态(隐藏层表征)的注意力连接:
反向传播在计算图上,可以直接通过多层的自注意力注意力矩阵(Attention matrices),架空、绕过离散的 Token 采样点,直接实现梯度向更早前驱时间的平滑渗透。
作者将其定义为经验共态(Empirical Costate,Definition 2):
其中, 为 时刻离散 Token 生成的局部对数损失, 是对应分配给它的优势常数。
作者通过链式求导直接推导出了 Transformer 内部隐式运行的经验共态逆向递推方程(论文中的公式 15):
其中 是通过层层自注意力网络构成的跨位置状态传递 Jacobian 矩阵。
如果我们将这一套自反求导推导出的经验共态方程,与我们先前推导出的连续、理想条件下的 BPTT 共态公式进行并列:
-
连续理想即时信用 (经验即时信用信号) -
理想转移雅可比 (基于自注意力的转移雅可比) -
理想共态 (经验前传梯度)
两者结构依然严格对应!也就是说,即使中间在生成 Token 时存在离散阻断,在通过 Autodiff 计算损失偏导 时,自注意力通道天然在反向传播中重构出了一套几乎与理想伴随状态严格对应的共态变量网络。
4.2 离散化采样的梯度残余误差分析(Sampling Gap)
当然,注意力旁路并不能百分之百消灭离散化采样带来的割裂。
如图所示,在一个真正的 Transformer 离散步中,前向传播隐状态 经历了如下完整路径传递到下一时刻 :
在这里,第一路径是直接通过注意力旁路(Attention Pathway):(这正是 Autodiff 所能自动捕捉并计算的 Jacobian 部分 )。
第二路径是穿过离散采样瓶颈。如果是一个完全连续、精确的 BPTT 转移,它的 Jacobian 在展开中应当包含第二条漏掉的路径(论文公式 20):
显然,因为中间夹着一个由于离散采样导致非微可分的节点,第二部分在常规的离散 GRPO 的反向传播(PyTorch Autodiff)中是被直接丢弃掉的。
那么,这个被丢弃的漏网之鱼,它的数学边界有多大?会彻底颠覆大模型的值梯度性质吗?
作者通过严格的数学推导,证明了这一采样间隙(Sampling-gap)的大小被大模型的策略熵(Policy Entropy)牢牢锁死:
命题 2(采样间隙界,Proposition 2):假设在某一解码步 ,大语言模型的词表大小为 。对于直通估计(Straight-through)或 Gumbel-Softmax 松弛极限状态下的离散采样,其所漏掉的精确采样梯度与自注意力机制计算梯度之间的残差(即采样雅可比误差),满足如下基于算子范数(Operator Norm)的不等式约束:
其中, 是大模型在当前解码步生成的策略熵值(即 Token 分布的 Shannon Entropy):
常数 主要取决于词嵌入(Embedding)矩阵的范数约束和 Transformer 块的局部 Lipschitz 常数。
命题 2 的严密证明过程(论文 Appendix A.7):
我们通过软化松弛(Gumbel-Softmax 松弛,温度设为 )来刻画离散采样。当前状态输出生成的概率向量为 。
其离散概率选择的对数几率 Jacobian 可以表达为:
矩阵 在数学上正好是分类单热点(one-hot)概率分布向量的协方差矩阵,它显然是半正定的,因此它的算子范数(最大特征值)可以通过矩阵的迹(Trace)进行严格控制:
设概率单热点中的最大分布概率值为 ,根据测度几何特征,显然有:
为了建立大模型策略熵对偏离点(距离 Dirac 测度点距离)的控制,根据紧致单纯形性质,我们存在一个有限的常数 ,使得最大概率与标准策略熵 之间具有开根控制关系:
(因为当且仅当分布变为退化的确定性分布时,即 ,,上述公式的两侧同时收敛于零,且二阶连续。在其余紧致域上,上界可由导数边界控制)。
因此,合并这些界限,我们可以得到:
我们将所有的固定网络常数、Embedding 映射常数、Lipschitz 参数与温度 合并吸收为常数 ,代回至 Jacobian 残差定义式,立刻得到(命题 2 证毕):
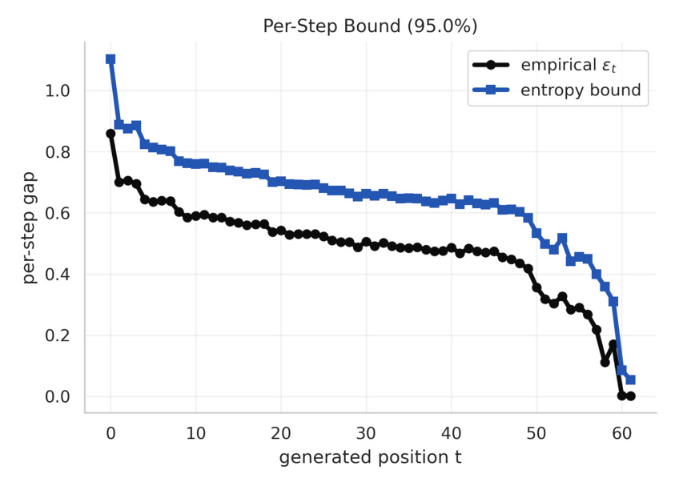
图 2 表明了作者在 OLMo-2 模型的实际解码全流程中,对精确差分雅可比的差值(黑线)与通过策略熵计算得出的理论界限(蓝线)进行的追踪对比。我们可以直观地看到,理论熵边界极其稳定且完美地包裹住了真实的梯度偏差,证实了策略熵控制误差结论的正确性。
这对于大模型对齐具有颠覆性的物理学含义:
-
大模型在多数 Token 生成步具有天然的低熵特征:当大模型经历充分的预训练后,它们在解码生成大多数常规词汇(如标点、代码语法括号、常识词、高频连接词)时,预测分布是极度确定、低熵的()。因此,在绝大部分序列轨迹上,丢失掉的雅可比项其数值范数微乎其微! -
GRPO 的 KL 约束机制稳定了值梯度传递:GRPO 在计算中包含了对原始策略 的 KL 惩罚,这迫使优化器在偏离时不能随意增加策略的熵。这无形中守护了大模型处于“极低梯度误差”的黄金运作区间。
4.3 离散值梯度逼近定理
通过将命题 2 沿时间轴不断逆向反向回传并展开,作者最终给出了大语言模型在离散状态下逼近理想 BPTT 共态(即理想值梯度估计)的终极误差控制定理:
定理 1(离散 GRPO 共态逼近定理,Theorem 1):设 是离散 Transformer 中由 Autodiff 计算得到的经验共态信号, 是在定义 1 对应的连续理想松弛系统下的精确 BPTT 伴随信号。我们有如下逆向演化误差界:
其中, 是 时刻由命题 2 约束的单步采样梯度泄露误差(其大小受 严格控制)。
定理 1 的逻辑闭环非常精美:只要 Transformer 的注意力机制 Jacobian 保持稳定,并且大部分生成步保持低策略熵状态,大模型的自注意力机制就相当于在对一个高维、连续且极高精度的状态空间,以纯粹隐式、极低成本、无 Critic 的方式进行着值梯度的反向传播与状态优化!
5. RL 影响定律假设:预测大模型的强化学习就绪度
既然大语言模型在反向传播中隐式地进行着高维值梯度的路径估计,这能够帮助我们解答大模型工程上的另一个痛点问题吗——我们究竟应该在预训练的哪一个节点,切入强化学习(RL)后训练对齐,才能获得最大的收益?
当前学术界和工业界普遍采用试错(Trial and Error)的方式,在不同的预训练 Step 检查点拉起强化学习任务并跑满评估,这导致了庞大的计算资源浪费。而作者利用隐式值梯度的这套理论,给出了一份完全不需要做强化学习微调就能直接预测增益的“大模型强化学习就绪度物理定律”。
根据定理 1 的描述,在任何一个特定的预训练检查点 上,大模型是否适合开展强化学习,取决于两件事情的乘积。
1. 可用值梯度信号量(Usable Value-gradient Signal)
大模型此时产生的隐式值梯度,质量足够高、误差足够低吗?它能不能向早期的时间步精确、无偏地输送信用分配?
作者利用 Cauchy-Schwarz 不等式对经验梯度与真实值梯度之间的余弦对齐(点积)给出了一个下限估计(论文公式 25):
其中:
-
:代表状态空间中总的可支配值梯度信号规模(反映了当前模型对问题难易程度、状态关联在几何上的基础感知饱满度)。 -
:代表因为离散采样(定理 1 中由熵引起的累积采样间隙误差)而彻底流失、扭曲的垃圾信号规模。
我们将两者的差值 定义为可用值梯度信号量。该指标越高,说明当前的预训练模型在反向传播时,传递的信号越干净、时序信用分配越科学。
2. 可达头顶空间(Reachable Headroom)
但是,仅仅有精准的方向(值梯度信号)是不够的。如果模型当前的策略分布已经收敛、坍塌在某个极其狭小的局部奖励极值点中,或者模型由于过于羸弱而根本采不到任何具有更高回报的潜在探索路径(例如在数学推理中,模型生成的几百条候选路径其对答概率全为 0),那么再好的梯度方向也毫无用武之地。
作者通过引入自由能奖励变换(Free-energy reward transformation),对策略通过重要性采样再分配所能挤出的剩余探索红利进行了度量,定义为可达头顶空间(论文公式 28):
这里,常数 代表探索倾向因子。
-
如果模型当前很弱,所有采样的回报 极低且方差极小(全是错的), 会收敛至极小值。 -
如果模型已经完全饱和(无论怎么采,回报都是满分),其分布已无拓展空间, 也会降至极低值。 -
只有当模型既采得出优秀的回报轨迹,又包含一定比例的低分轨迹待纠正时(即分布中存在蕴含着极大增益空间的阶梯结构),可达头顶空间达到极大值。
3. RL 影响定律(RL Impact Law)
作者大胆地将这两者结合,指出了大模型强化学习最终产出收益的乘积定律(Product Law,论文公式 29):
在实验中,这套公式在统一尺度常量 下可以高保真地对 RL 的真实收益进行一阶拟合:
基于该乘积定律,最优的强化学习切入检查点 无需通过耗时的强化学习试错,直接可以通过在静态预训练数据下进行轻量级的梯度/回报前向采样而得出:
这极大程度地改变了大模型强化学习对齐实践中的“黑箱”现状。
6. 实证验证与分析
为了对上述的一整套“值梯度假设”、“伴随递推误差”、“RL 准备度影响乘积定律”进行全方位的科学检验,作者在一套极其严苛、高置信度的模型与控制任务中实施了系统化的探索验证。
6.1 闭环实验系统架构与任务设定
1. 骨干模型(Backbone Model)
实验全面采用艾伦人工智能研究所(AI2)发布的最新开源旗舰预训练检查点——OLMo-2 1B 系列模型。为了观察整个预训练生命周期中的动态特征演化,作者以 50k(5万步)为步长,全量提取了从预训练 50k 到 1M(100万步)的 20个预训练检查点模型 进行全面跟踪。
2. 闭环控制任务(Closed-form RL Task)
为了确保“精确伴随状态”的数学解析值 能够被百分之百精确提取并进行无偏差计算(避免使用外部无法微分的离散评测分类器),作者设计了一个闭环的、直接在隐状态 logits 上进行求导的控制标签复制问题(Controlled Label-copying Task):
-
给定一个提示词,包含一串代表特定类别标签的输入(如 等)。 -
期望模型输出匹配该正确类别的标签。 -
任务的回报函数直接定义为 logits 层对应正确标签位置输出的精确概率值:。由于概率函数完全解析可微,这允许我们对真实的路径导数 进行数值上的完美求和,排除了由于离散采样损失导致的测量误差。
3. 强化学习微调协议(RL Tuning Protocols)
在每个预训练检查点上,作者使用 GRPO 算法运行强化学习。为了保证不受偶然超参的干扰,作者对每个检查点都进行了不同训练更新轮数(RL budget)的消融测试,包含更新步长 步,最终的结果衡量采用多轮更新下的平均增益期望 。
6.2 命题 2 与 3:策略熵控制采样间隙的实证验证
作者首先在 OLMo-2 的生成路径中计算了每个生成的 Token 上,利用 Autodiff 抓取的误差 与通过策略熵计算的理论上界 。
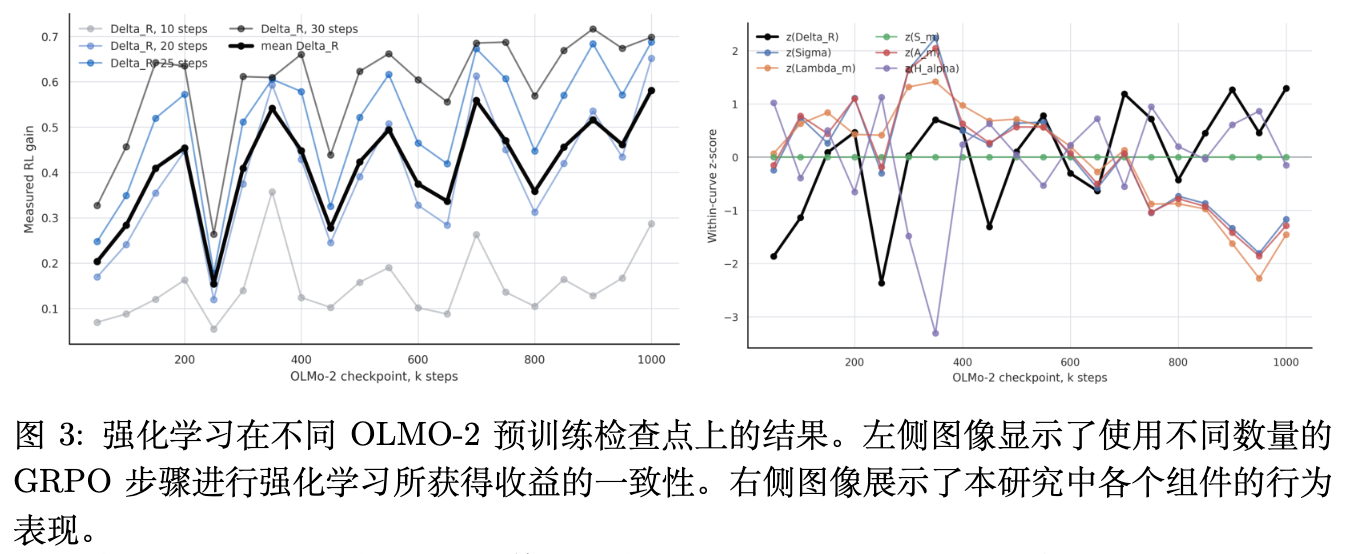
如图 3 所示,实验给出了清晰的实证结论:
-
在图 3 的右侧子图中,我们可以清晰地观测到在不同预训练 Step 下,真实的共态梯度残差误差(z(z_lambda_m))与模型的策略熵变化(z(z_H))呈现出几乎完全同步、完全镜像的关联关系。这说明在真实的大模型中,策略熵对离散采样雅可比误差的约束是极端准确且牢固的。 -
随着预训练的推进,模型在语法等容易确定输出的 Token 处的局部策略熵稳步下降,采样误差迅速坍塌至极低水平,这确保了模型在预训练的中后期阶段能够完美运行类似于值梯度传播。
6.3 预测大模型 RL 增益的就绪度验证
接下来,作者在没有启动强化学习的情况下,通过在各个 OLMo-2 预训练检查点上进行轻量级的对齐探针,计算出可用值梯度信号 与可达头顶空间 ,并根据乘积定律算出综合预测分 。
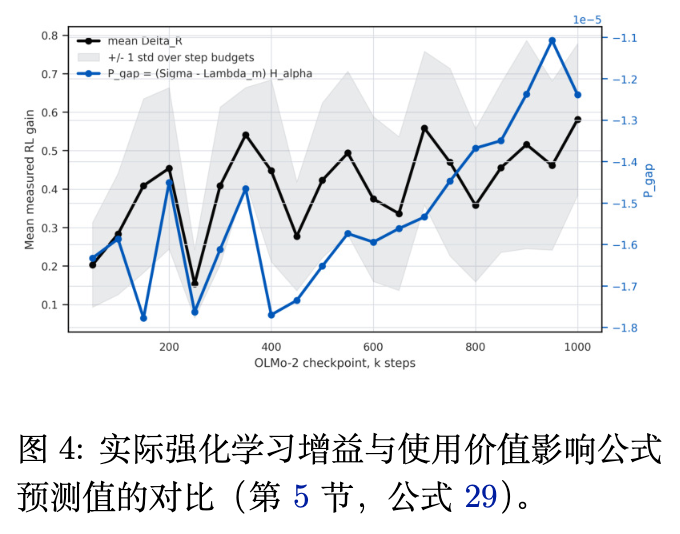
在图 4 中,我们将通过“强化学习收益乘积定律”得到的预测信号(蓝线)与各预训练节点下真实运行 GRPO 后获取的实际性能提升(黑线,mean_Delta_H)进行直接对标。
两条曲线的走势极度贴合!具体定量数据展现出了极高的一致性:
-
仅仅使用基于可用值梯度的就绪度分数 ,其与模型真实的强化学习增益 之间的 Spearman 秩相关系数(Rank Correlation)达到了约 0.60! -
如果我们综合考虑大模型当前的基准表现与强化学习 readiness 分数,采用无量纲标准化预测:,其与最终强化学习微调后的绝对成绩 之间的 Spearman 相关系数达到了 0.73!
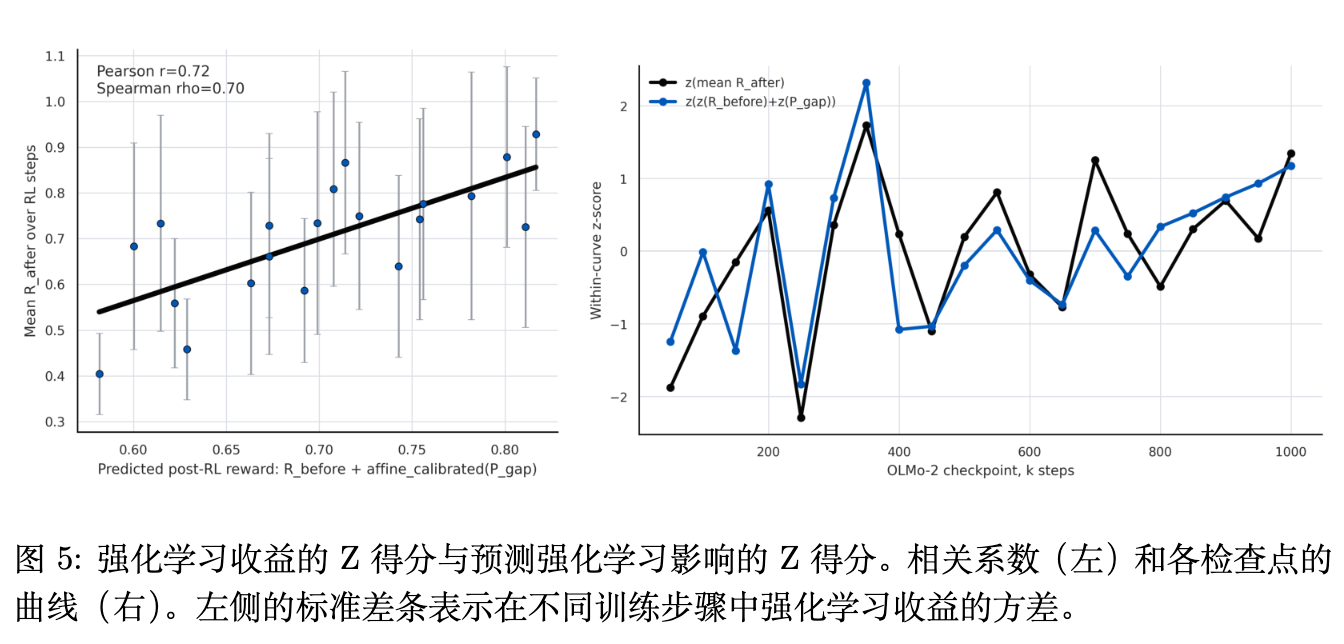
如图 5 所示,在横跨 OLMo-2 预训练生命周期的多维检查点下,不管是线性回归的相关性(左图,Pearson ),还是沿着预训练 Step 变化的细颗粒度趋势拟合(右图),这一套理论在不需要跑任何耗时的 RL 训练的前提下,精准锁定了最佳强化学习切入点(即预训练 Step 300k-400k 以及 800k-1000k 的波峰节点)。
7. 相关工作与局限性
在对大语言模型无 Critic 强化学习本质的理论探索中,本文站在了多项前人工作的肩膀上,但也开辟了独特的战场。
7.1 与相关研究的横向对比与探讨
-
与 PPO 和经典 Critic 依赖理论的对比:
在强化学习的经典叙事中,如传统的时序差分信用分配或 PPO,研究人员认为:如果没有精心设计、快速逼近状态 -值的 Critic,基于路径优势分配(Episode Baseline)的 REINFORCE 系列算法在面对高维长序控制时,其性能一定会发生严重的退化(de Oliveira, 2025)。然而,本文揭示了:因为 Transformer 的自注意力机制天然地扮演了梯度可微桥梁,即使我们彻底砍掉 Critic 网络,Actor 自身的反向传播已经在执行着几乎和 BPTT 伴随状态一模一样的值梯度计算,大模型的架构特性本身重写了传统 RL 的不收敛宿命。 -
与 GRPO 统计学解释的对比:
近期的一些尝试从 U-统计量(U-statistics)的角度解释 GRPO 的有效性(Zhou et al., 2026),认为 GRPO 隐式构造了一种高效的群体优势对比。然而,这种解释是特定于 GRPO 算法本身的。而在本文的物理图像下,不仅是 GRPO,即使是传统的 PPO、REINFORCE 乃至更广泛的大模型策略梯度方法,只要它们在大模型的自注意力底座上运行反向传播,它们都无一例外地遵循着“值梯度假设”。 -
与直接使用 BPTT 算法的对比:
Zheng et al. (2025) 提出了在大模型中摒弃传统强化学习的框架,转而利用 Gumbel-Softmax 直接执行通过时间反向传播(BPTT)。从本文的视角来看,这正好印证了本文的理论基础:直接使用 BPTT 无非是彻底消灭了那一部分由策略熵控制的离散采样误差(),使其从“近似 BPTT 状态”跃迁为“完全体 BPTT 状态”,因而取得了更好的对齐表现。
7.2 局限性与开放性思考
作为一个高度严密且富有成效的理论探索,作者也在论文中坦诚地指出了当前分析框架存在的边界条件,这对于未来的研究者提供了极佳的探索方向:
-
奖励函数的连续可微分假设:
为了完成严格的连续松弛,作者的设计中假定了模型的奖励在 logits 层面是连续且光滑的。但在许多真实世界任务中(如执行编译器编译、完全由离散评测集给出的 Binary Score),奖励信号是彻底离散且不光滑的。在这些场景下,注意力的旁路微分性能可能会遭遇一定程度的挑战,有赖于后续对非平滑边界的进一步研究。 -
优化动力学中超参数的交互:
本理论模型的核心目标是预测“大模型在预训练生命周期中的强化学习 readiness”,但在现实的强化学习任务中,强化学习的最终效果依然受到学习率(Learning Rate)、群组采样大小(Group Size)、Batch Size 以及 KL 散度惩罚权重的强烈干预。如何将这些外在的优化动力学超参进一步整合进就绪度预测模型,是一个充满想象力的开放问题。
8. 结论
本论文对大语言模型后训练阶段无 Critic 强化学习(如 GRPO)的核心机制提供了直指本质的数学和物理学解释:
-
大模型中的无 Critic 强化学习绝不是“无 Value”的:由于大模型在反向传播时传递的经验共态变量在期望上等价于状态空间上的值梯度,无 Critic 算法天然地在一个极高精度的连续高维值梯度流中运行。 -
Transformer 的注意力机制克服了采样瓶颈:自注意力矩阵为大模型提供了绕过离散采样的内容旁路,使得时序信用信息能够极其通畅、平滑地向前传递。逼近误差在数学上被证明受控于策略熵,当大模型表现出相对低熵状态时,误差微乎其微。 -
强化学习收益受两因子乘积定律支配:大模型强化学习的效果表现可以完全由“可用值梯度信号量”与“可达头顶空间”的乘积来进行精准拟合。这为预训练中何时切入对齐训练提供了完全无训练、轻量化、高精度的预测指标。
这一系列发现优雅地说明,大模型无 Critic 强化学习算法之所以大放异彩,并不是对传统强化学习信用分配理论的“颠覆”或“特例”,而是现代 Transformer 复杂的、在连续空间内部进行的高维梯度传递,在离散现实下所展现出的一场完美的物理逼近。
更多细节请阅读原论文。

