让每一项优秀工作,被更多人看见:点击进入投稿通道
论文追踪 APP 推荐:DailyPapers

-
论文标题:Trust Region On-Policy Distillation -
论文链接:https://arxiv.org/pdf/2606.01249
TL;DR
今天解读一篇来自三星研究院、牛津大学和北京大学的论文《Trust Region On-Policy Distillation》(TrOPD),该工作探讨了大型语言模型在进行在策略蒸馏(On-Policy Distillation, OPD)时面临的监督信号失真与训练不稳定性问题。当前,获取小参数量推理模型(Small Reasoning Models, SRMs)通常依赖于将大模型的推理能力蒸馏给小模型。然而,当师生模型分布差异较大时,传统 OPD 仅依赖学生生成的轨迹进行训练,会遭遇教师给予的置信度极低、产生不可靠策略梯度甚至导致优化崩溃的困境。
针对上述问题,作者提出了信任区域在策略蒸馏(TrOPD)。该方法的核心视角是将学生生成的 token 按监督可靠性划分为信任区域与离群值区域:在信任区域内执行标准的在策略蒸馏;在离群区域采用 Top-k 前向 KL 估计来替代不可靠的逆 KL 梯度,从而保留有效监督信号;同时引入离策略引导,让学生基于教师生成的前缀继续续写,以鼓励学生向教师支持的可靠区域进行探索。
实验证明,TrOPD 在数学推理、代码生成和通用领域指令遵循基准上均一致优于现有的 OPD 基线方法。具体而言,以 DeepSeek-Qwen2.5-1.5B 和 Qwen3-SFT-1.7B 为学生模型,TrOPD 较标准 OPD 在 AIME、AMC 等基准上取得了平均 3.06 至 4.62 分的提升,证实了在进行长序列推理蒸馏时,通过细粒度信任区域分配监督权重的有效性。
1. 引言
近期,诸如 DeepSeek-R1、OpenAI o1 等大型推理模型(Large Reasoning Models, LRMs)通过扩展测试时计算(test-time compute),在数学、代码生成和智能体任务中展现了卓越的性能。然而,这类模型庞大的推理成本促使研究社区转向开发适合资源受限部署的小型推理模型(Small Reasoning Models, SRMs)。
传统的序列级知识蒸馏通常是一种离策略(Off-policy)方法,即让学生模型模仿强教师模型生成的轨迹。这种范式存在一个固有的缺陷:训练阶段依赖于教师生成的轨迹,而推理阶段模型只能依赖自身生成的轨迹,这导致了严重的暴露偏差(Exposure Bias),在长思维链推理任务中尤为明显。
为了缓解这一问题,在策略蒸馏(On-Policy Distillation, OPD)应运而生。OPD 直接在学生模型自己生成的轨迹上进行训练。尽管具备潜在的效率优势,但现有的 OPD 方法在实际应用中经常遇到训练不稳定的问题。当教师和学生的分布存在较大分歧时,学生生成的轨迹可能落在教师可靠监督区域之外。这会产生错误的策略梯度,甚至导致训练崩溃。
此外,由于内存开销的限制,针对推理模型的 OPD 无法承担在完整词表上计算 KL 散度的代价。目前的主流做法是依赖样本估计器(如 估计器)来计算逆 KL(Reverse KL)散度,但这进一步降低了监督信号的可靠性。为此,本文建立了一个统一的基准测试,系统地研究了多领域评估下不同 OPD 策略的有效性,并指出现有的奖励裁剪(Reward Clipping)等方法容易将包含信息量的监督信号连同异常梯度一起剔除,从而造成性能瓶颈。
基于此,作者提出了 TrOPD,通过评估师生解码的一致率划分信任区域,并结合前向 KL 与离策略引导,实现了更稳定、高质量的推理能力蒸馏。
2. 预备知识与问题定义
2.1 语言模型的标准蒸馏
不同于基于教师生成(Teacher of Generations, ToGs)的离策略蒸馏,在策略蒸馏基于学生生成(Student of Generations, SoGs)进行训练。在基于逆 KL 散度(RKL)的 OPD 中,序列级目标函数可以写作:
这里, 是学生策略, 是教师策略。该目标的梯度自然呈现出策略梯度(Policy Gradient)的形式:学生从自身策略中采样轨迹,若该序列被教师赋予高概率,则获得正向奖励。由于期望是基于学生分布计算的,RKL 会严厉惩罚那些落入教师低概率区域的学生输出,而对学生未探索到的教师模式惩罚较小,这表现出一种寻求模式(Mode-seeking)的行为。
然而,传统的指令微调模型蒸馏(如 GKD、推测性 KD)计算完整词表上的 KL 散度或 Jensen-Shannon 散度(JSD),其目标函数为:
其中 是词表。计算全词表的 KL 散度需要 的内存开销( 为序列长度, 为词表大小),对于动辄输出数千 token 的长思维链任务而言,内存开销成为显著的瓶颈。
2.2 针对推理模型的 OPD 与 K1 估计器
为了解决内存瓶颈,近期的长推理 OPD 方法采用 估计器来获得 KL 散度的无偏估计,从而将优化目标转化为:
这种 估计器只需在采样到的具体 token 上评估概率,内存复杂度降至 。然而,作者指出该估计器存在两个核心优化瓶颈:
-
显著的策略梯度异常值(Outliers):当师生分布差异过大时,教师可能对学生策略采样的轨迹分配极低的概率,即 。在这种低置信度区域,基于 估计器的策略梯度信号会变得极其负向,即 。这些极低置信度的轨迹会引发严重的异常梯度,破坏 OPD 的优化稳定性。 -
学生生成质量低下(Low-quality SoG):由于完全基于学生采样轨迹优化,面对复杂的数学或代码问题,能力较弱的学生模型难以生成高质量的答案。低质量的 SoG 轨迹限制了有效的优化空间,阻碍了学生接收来自高质量回答的指导。
3. 核心发现与现有 OPD 基准评测
为了公平对比现有方法并验证上述瓶颈,作者在统一的实验设置下评估了代表性的 OPD 方法。
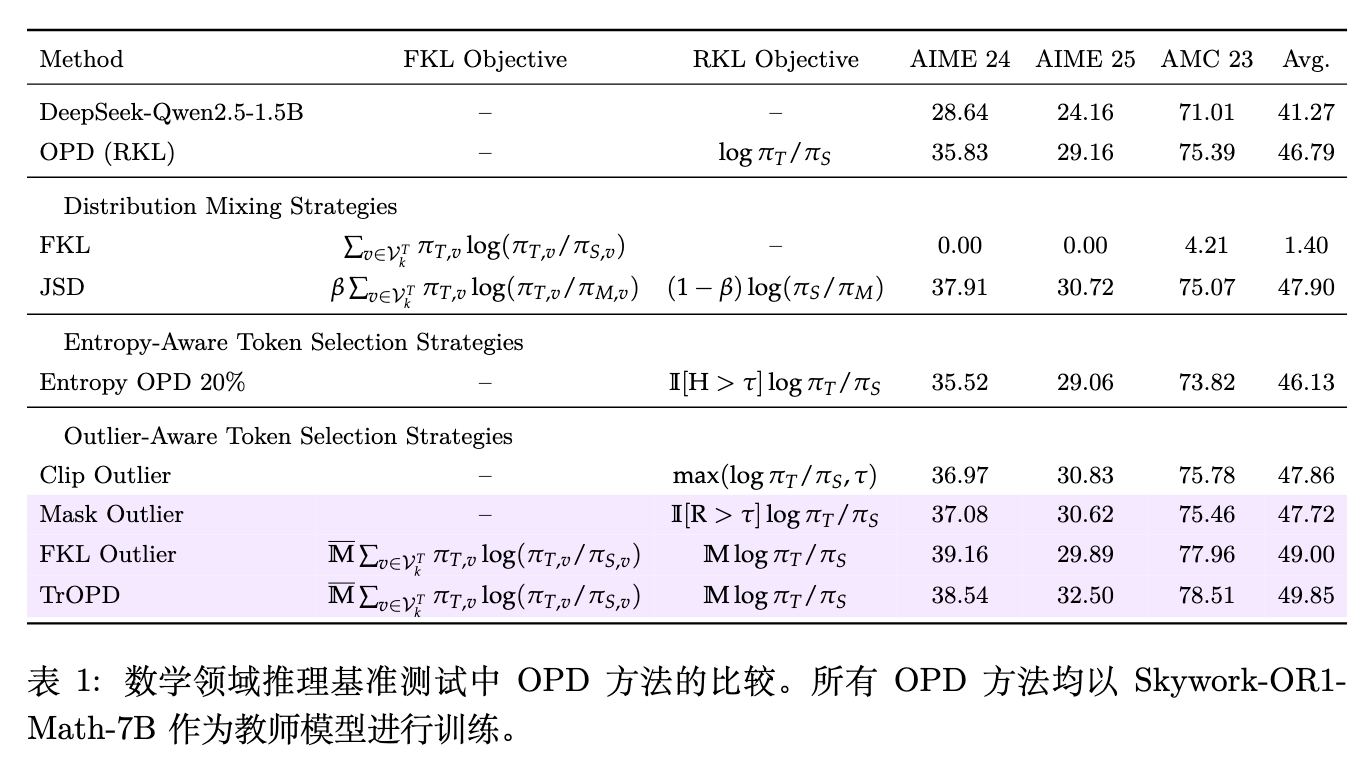
作者考察了两种主流的异常梯度缓解策略:
-
分布混合策略(Divergence Evaluation):由于 KL 散度存在不对称性,是否可以引入前向 KL(FKL)来中和 RKL?在长序列内存约束下,作者在教师的 Top-k 词汇表上实现了 FKL: 然而实验显示,如果在局部词表上单独计算 FKL,不仅无法有效训练,还会带来偏差。当采用广义 JSD 目标( 时结合 FKL 和 RKL)时: 虽然有一定效果,但受限于 Top-k 近似的偏差,单独的 FKL 并不适合作为词表受限下 OPD 的独立目标。 -
Token 过滤与奖励裁剪(Token Filtering and Reward Clipping):GRPO 等方法常采用仅在 Top 20% 高熵 token 上训练的策略,以抑制无信息 token 的干扰;而 REOPOLD 则应用奖励裁剪,将超过阈值的奖励截断。表 1 的结果表明,基于熵的 Token 选择反而降低了性能,因为这丢弃了教师能提供的常规有效监督;而 REOPOLD 的奖励裁剪虽有提升,但截断阈值的选择引入了额外超参,且限制了模型的最终潜力。
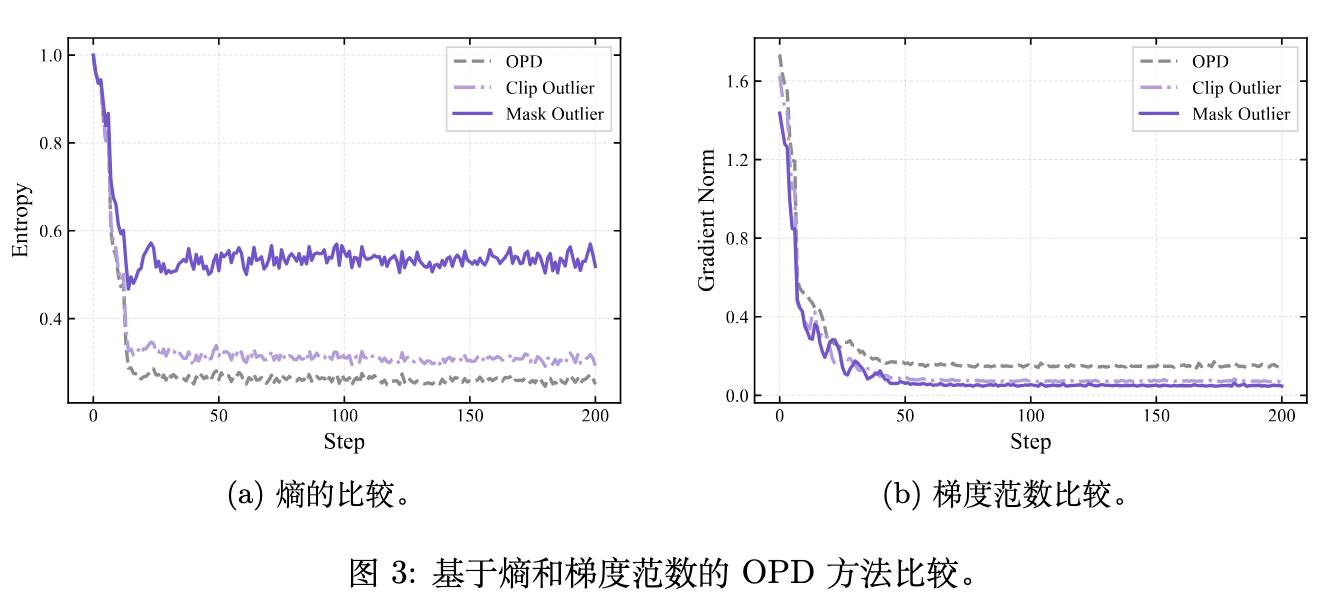
图 3 进一步展示了不同策略下的训练动态。单纯依赖奖励裁剪或掩码(Mask)可以降低梯度范数并维持较高的策略熵,但一刀切的方式丢失了离群区域中仍具有价值的监督知识。
4. TrOPD 方法解析
受强化学习中信任区域策略优化(TRPO)的启发,作者提出只在策略梯度可靠的区域进行优化的 Trust Region On-Policy Distillation (TrOPD)。
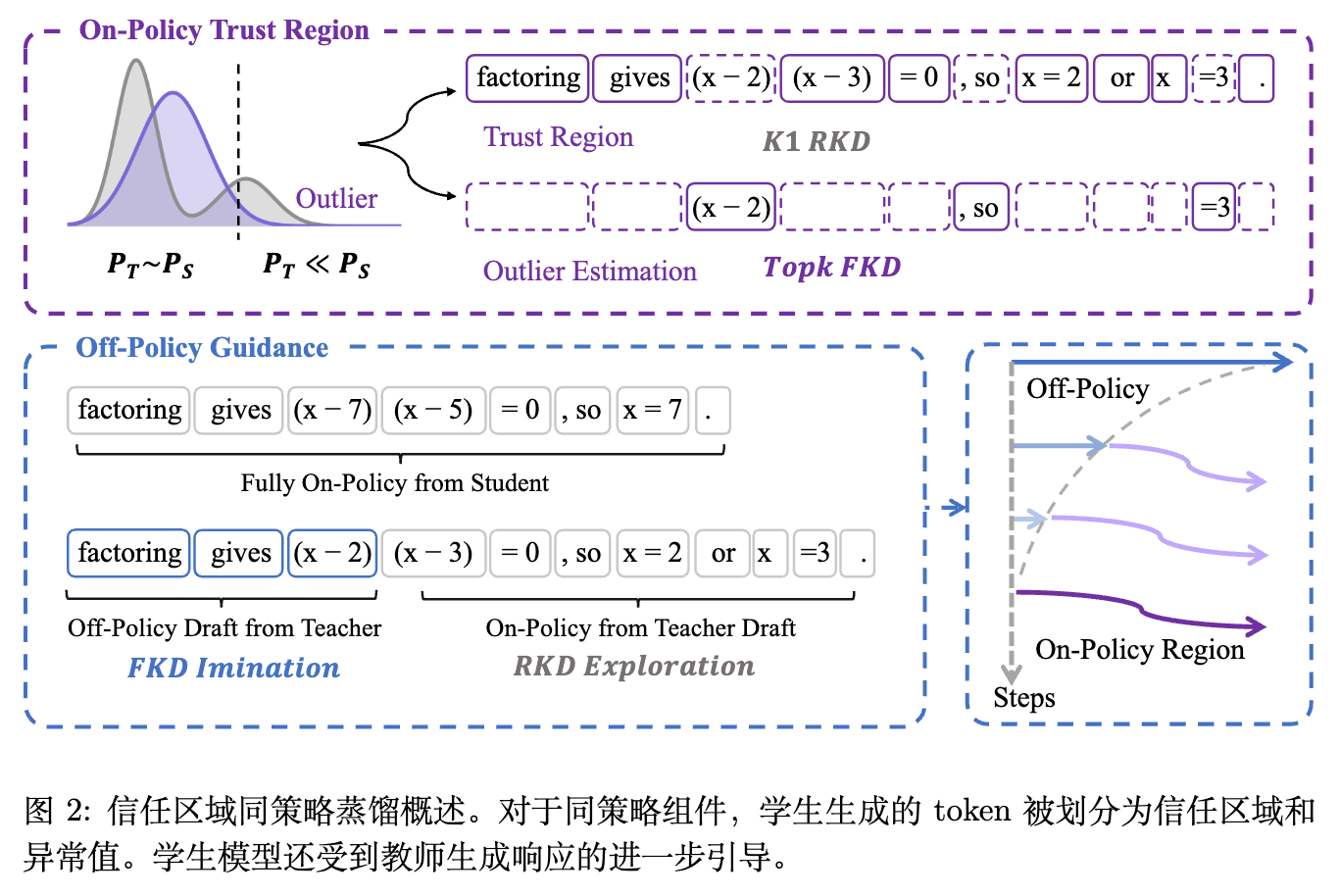
给定当前采样的 token ,作者通过掩码变量 (代表信任区域)和 (代表离群区域)将其目标函数拆分为两部分:
具体展开后,可以表示为:
围绕这一拆分公式,TrOPD 包含以下三个核心机制。
4.1 自适应信任区域划分与掩码
不同于之前使用固定阈值(如 REOPOLD 里的 ),TrOPD 根据学生策略 和教师概率 的比值自适应地定义信任区域。对于学生生成的每一个 token ,其被划分到信任区域的概率服从伯努利分布 ,其中:
这一设计受到了推测解码(Speculative Decoding)的启发,在该场景中,教师模型接受学生解码 token 的概率正比于 。通过仅选择被教师接受的解码区域,可以确保学生模型始终处于 估计器下受到有效监督的区域内。
在最初的设计探索中,作者发现直接采用“掩码离群值(Mask Outlier)”策略(即当对数比值超过某一阈值时直接将优势函数置零:)已经能够优于标准的 OPD 以及 REOPOLD 的裁剪策略。图 3 表明,Mask Outlier 直接消除了不可靠梯度的影响,维持了更高的策略熵,从而更好地保留了蒸馏过程中的探索能力。但直接丢弃离群值会导致信息损失,因此自适应区域划分显得尤为必要。
4.2 离群区域的 FKL 估计 (Outlier Estimation)
离群区域虽然表现出师生分布的巨大差异,但仍然可能蕴含教师传授的有价值的知识。直接掩码会丢弃这部分知识。为了在不引入错误梯度的情况下恢复部分监督信号,TrOPD 在离群区域引入了辅助的前向 KL(FKL)目标。
由于从学生采样的 token 在严重分布不匹配下无法提供可靠估计,作者转而从教师的角度计算这部分蒸馏信号。对于满足离群条件 的区域,目标函数设计为:
其中 是教师分布下的 Top-k 词表。当存在某个词汇 使得 时,FKL 目标允许学生从离群区域中、有教师支持的 token 那里进行模仿学习。反之,如果学生对教师支持词汇的预测概率之和趋近于 0,则 KL 惩罚也会受到抑制,不至于干扰信任区域内的正常梯度更新。
4.3 离策略信任区域引导 (Off-Policy Guidance)
为了进一步引导学生模型跟随教师的推理轨迹生成,TrOPD 设计了离策略的信任区域引导机制。蒸馏轨迹被人为分割为两部分:前半部分 由教师模型离策略生成(作为前缀),后半部分 由学生模型在策略续写。
对于长思维链任务,这一设计避免了因为学生能力有限而在早期推理阶段就偏离正确逻辑的情况。对于离策略的前缀部分,由于样本完全来自教师 ,直接使用 估计器进行前向 KL 模仿学习:
通过在前缀中采用教师的轨迹,可以鼓励学生进行向内探索(向着教师可靠区域探索),加速蒸馏早期的收敛。
4.4 统一优化目标
将以上三者结合,TrOPD 的最终统一优化目标为:

在训练初期,离策略轨迹的最大长度设置为序列总长;随着训练进行,这个长度通过余弦调度策略逐渐退火至 0,从而在训练后期完全过渡为纯粹的在策略生成。
5. 实验设置
作者在单领域(数学)和多领域(数学、STEM、指令遵循、代码)场景下全面评估了推理模型的蒸馏效果。
-
学生模型:(1) DeepSeek-Distilled-Qwen-1.5B(已具备一定推理能力,用于观察纯 OPD 能否继续提升);(2) Qwen3-SFT-1.7B(从 Base 模型通过 SFT 训练获得)。 -
教师模型:Skywork-o1-Math-7B(用于单领域和多领域基准教师)、Qwen3-Nemotron-4B。 -
数据集:OpenThoughts3 数据集。对于单领域,仅保留数学题目;对于多领域,保留数学、代码和科学题目,丢弃了其中的参考答案,仅使用 Prompt 进行生成。 -
训练超参:采用固定学习率 训练 200 步。FKL 的 Top-k 集合大小统一设定为 。离策略引导系数 。每次提示词的 batch size 为 128,每个提示词采样 4 条回复,最大生成长度限制在 8096 个 token。
在所有测试中,AIME 2024、AIME 2025、AMC 2023 分别取 32 次采样的平均准确率。STEM 测试使用 GPQA Diamond 和 MMLU-Redux v2,指令遵循使用 IFBench,代码生成使用 LiveCodeBench v6。
6. 实验结果与分析
6.1 单领域蒸馏结果
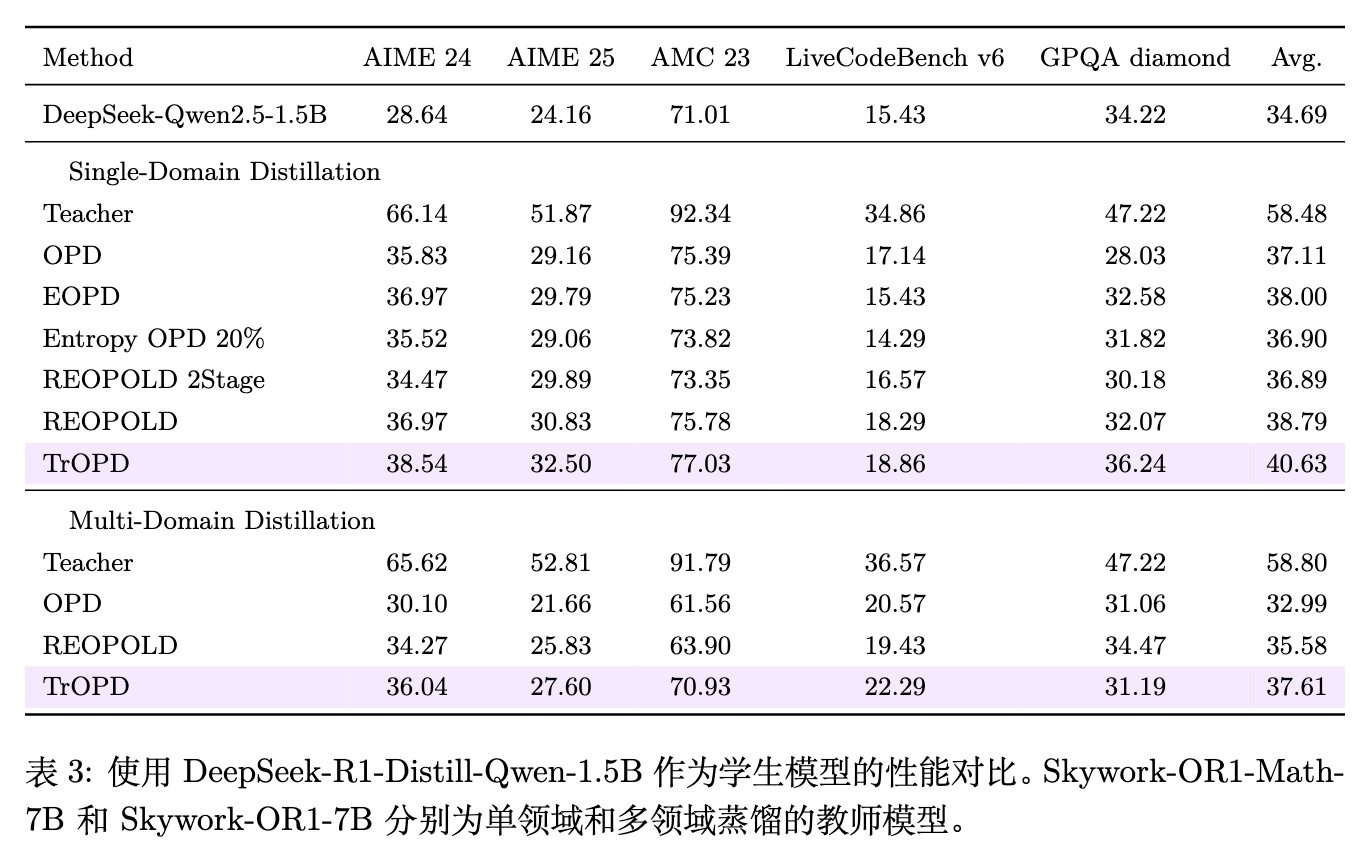
表 3 的上半部分报告了使用 DeepSeek-Qwen2.5-1.5B 作为学生,仅在数学题目上训练的单领域蒸馏结果。可以看到:
-
相比于标准的 OPD 基线,TrOPD 在包含 AIME 24、AIME 25、AMC 23 等数学推理任务上的平均表现提高了 3.06 分。 -
在包含领域外(OOD)任务(如代码的 LCB、科学的 GPQA)的测试中,TrOPD 提高了 2.63 分。这表明虽然仅在数学数据上进行了 OPD 训练,但 TrOPD 通过可靠的梯度约束,保留甚至泛化了学生模型的通用能力,而没有因为过度追求特定题目的奖励而导致灾难性遗忘。 -
与同期的其他纠正策略对比,TrOPD 击败了使用简单奖励裁剪的 REOPOLD(领先约 1.84 至 1.99 分),并且相较于依赖熵进行 Token 筛选的 EOPD 和 Entropy OPD,取得了 2.63 到 3.74 分的显著优势。这一方面印证了仅保留高熵 token 的策略会丢弃常规的有效监督,另一方面也证实了自适应信任区域的有效性。
6.2 多领域蒸馏结果
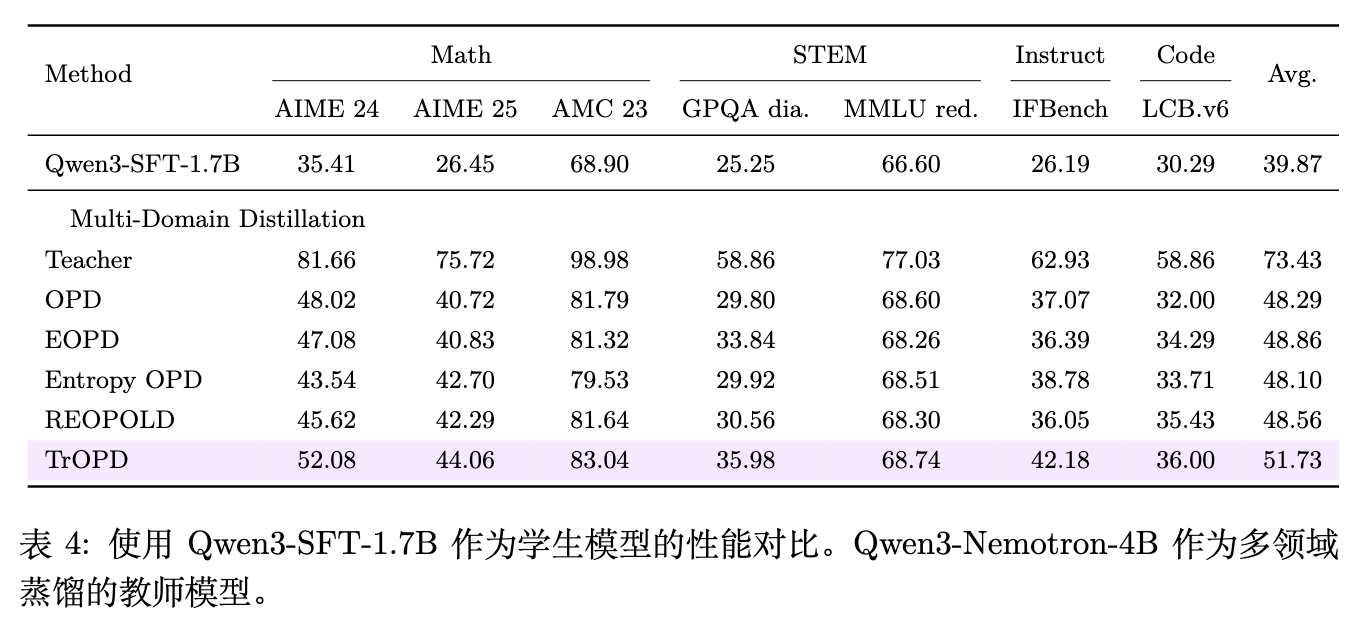
表 3 的下半部分和表 4 展示了多领域蒸馏的结果,这里使用的是 Qwen3-SFT-1.7B 模型和 Qwen3-Nemotron-4B 作为教师的组合。实验结果反映了相似的趋势:
-
在几乎所有的垂直维度上(数学、STEM、指令遵循、代码),TrOPD 都实现了稳定的正向增益。 -
在表 4 的配置下,TrOPD 在 AIME 24 上达到了 52.08 的分数,显著高于 OPD 的 48.02 和 REOPOLD 的 45.62。 -
就整体平均分而言,相比 Qwen3-SFT-1.7B 原始模型,TrOPD 将其平均性能从 39.87 分推高至 51.73 分;相比基础 OPD,平均分数提升了 3.44 分。
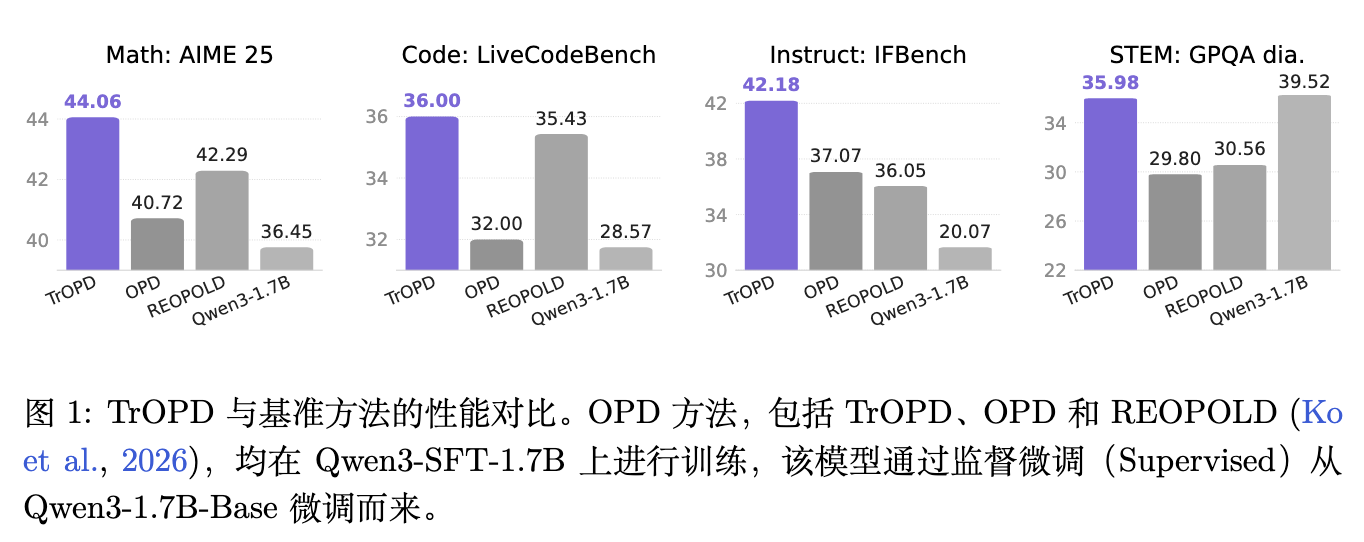
图 1 的直观对比进一步明确了,无论是对数理要求极高的 AIME 赛事题,还是考察逻辑严密性的 LiveCodeBench,TrOPD 都展现出比 OPD、EOPD 和 REOPOLD 更加平稳且更高的性能上限。
7. 消融实验与讨论
作者在单领域配置下进行了深入的消融实验,以验证各个组件的设计必要性。
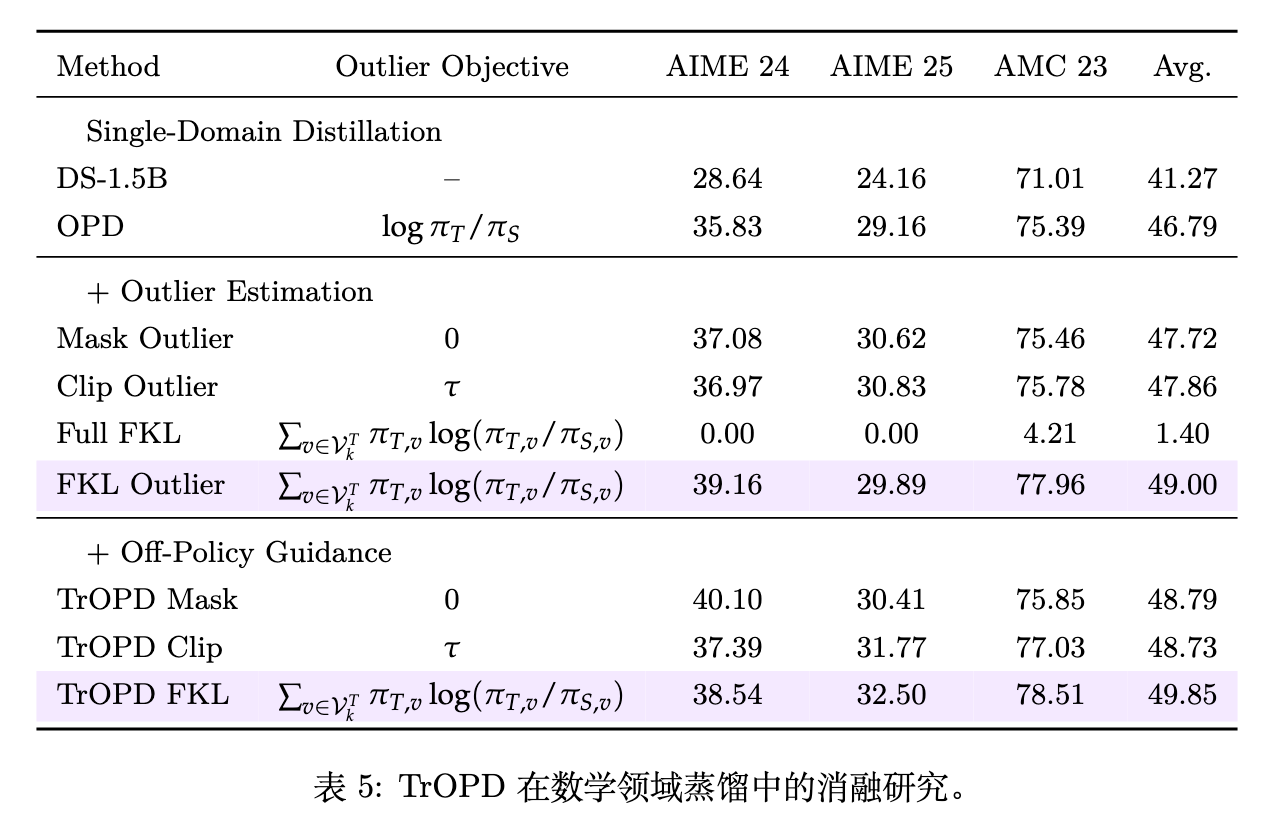
7.1 离群值目标的消融
表 5 的前半部分分析了面对离群值时的不同处理策略。当不使用离策略引导时:
-
Mask Outlier(将离群值优势函数归零)获得了 47.72 的平均分。 -
Clip Outlier(按阈值裁剪)获得了 47.86 的平均分。 -
Full FKL(仅在教师 Top-k 上完全依赖前向 KL)性能发生崩溃(1.40 分),再次证明了在局限词表内单独使用 FKL 是不可行的。 -
FKL Outlier(即在信任区域保留正常梯度,仅在离群区域使用 FKL)达到了 49.00 分。这表明将 FKL 严格限制在离群区域,不仅有效规避了有害梯度,还成功捞回了被掩码或裁剪丢弃的有效监督信息。
7.2 离策略引导的消融
表 5 的下半部分在上述基础上加入了离策略引导(Off-Policy Guidance)。对比发现,加入该引导后,Mask、Clip 和 FKL 三个变体的平均分数均进一步上升。其中,最终的完整版 TrOPD(即加入了离策略引导的 FKL Outlier 版本)达到了 49.85 分,较标准 OPD 变体领先 3.06 分。这印证了通过强制学生模型从教师的高质量推理前缀开始续写,确实能有效地约束学生生成过程,使其向更容易被教师接受的信任区域靠拢。
7.3 与并发工作 AOPD 的对比
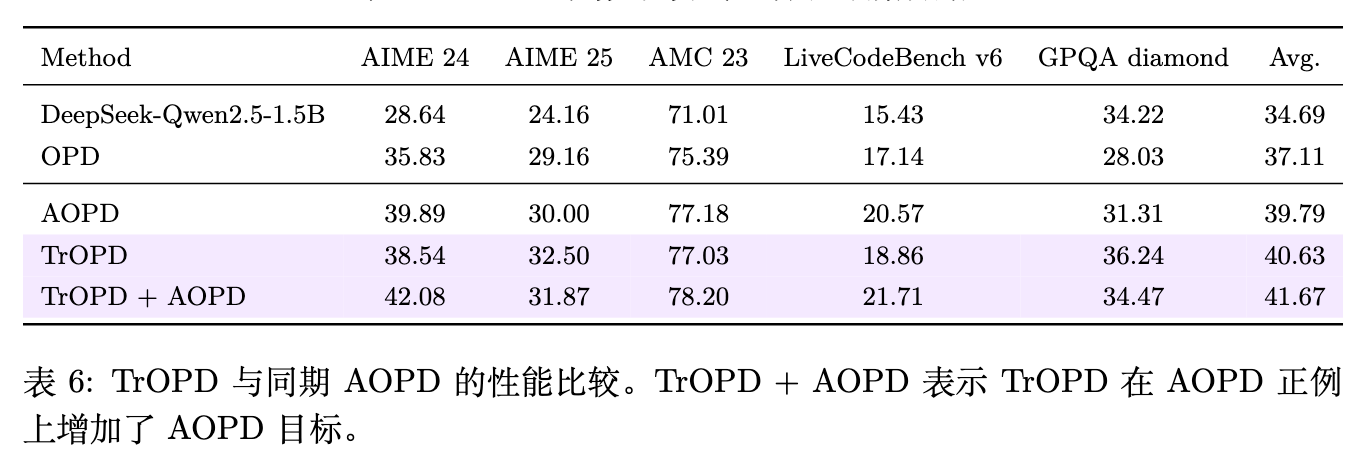
近期还有一项解决 OPD 监督缺陷的并发工作 AOPD(Jia et al., 2026),其侧重于在 token 级别桥接利用和探索。作者在表 6 中对二者进行了直接比较。结果显示,TrOPD 本身(40.63)优于 AOPD(39.79)。更有趣的是,当把 AOPD 针对正样本的目标引入 TrOPD 中(TrOPD + AOPD)时,平均得分进一步攀升至 41.67 分。这一发现说明 TrOPD 基于区域划分和异常值恢复的逻辑与 AOPD 的优化策略是互相正交(Orthogonal)且互补的,提示了未来将不同 OPD 维度的优化策略结合的潜力。
8. 总结与局限性
本文深入探究了利用在策略蒸馏(OPD)获取小规模推理模型时所面临的核心挑战:由师生分布漂移导致的低质量学生生成与不可靠的逆 KL 策略梯度。为了克服这一障碍,作者提出并验证了信任区域在策略蒸馏(TrOPD)框架。
通过将预测出的 token 基于教师与学生的概率比值自适应地分为信任区域与离群区域,TrOPD 成功在可信区域内实施无偏的参数更新;对于风险较高的离群区域,采用前向 KL 的 Top-k 估计在消除恶意梯度的同时,最大限度保留了知识迁移的可能性。外加从教师生成的逻辑前缀中退火式引入的离策略引导,TrOPD 提供了一条稳定、高效、低内存占用的长序推理蒸馏路径。
局限性讨论:
作者在文末也坦诚地指出了该研究的局限性。目前工业界在训练高性能的小型推理模型时,通常会在监督微调(SFT)和强化学习之后,插入额外的“中间训练(mid-training)”阶段,或者在预训练层面对推理相关的分布进行更深入的干预。本文的实验严格受控于通过 OPD 这一单一后训练范式(Post-training)对比不同策略的优劣,基于现成模型进行起步。这种设置可能会限制模型整体推理能力能够达到的绝对上限。未来进一步的研究应当探索如何在包含预训练、中间训练的流水线中,将基于信任区域的强化反馈嵌入到全链路中,以释放小规模语言模型在实际生产落地中的终极推理潜能。
更多细节请阅读原论文。

