
-
论文标题:Towards a Science of Scaling Agent Systems -
论文链接:https://arxiv.org/pdf/2512.08296
TL;DR
今天解读一篇由 Google Research、Google DeepMind 和 MIT 联合发布的论文《Towards a Science of Scaling Agent Systems》。该研究旨在打破多智能体系统(Multi-Agent Systems, MAS)设计中的经验主义,建立定量的扩展法则(Scaling Laws)。研究团队在 3 个主流 LLM 家族(OpenAI, Google, Anthropic)、5 种典型架构和 4 个多样化的 Agent 基准测试上进行了 180 项受控实验。
核心结论如下:
-
工具-协作权衡(Tool-Coordination Trade-off): 在固定计算预算下,高度依赖工具的任务会因多智能体协作带来的开销而性能下降。 -
能力饱和(Capability Saturation): 当单智能体基线准确率超过 45% 时,引入协作机制往往带来递减甚至负向的收益。 -
拓扑依赖的错误放大(Topology-dependent Error Amplification): 独立(Independent)智能体架构会将错误放大 17.2 倍,而中心化(Centralized)架构通过验证机制将错误放大控制在 4.4 倍。 -
任务属性决定架构选择: 中心化协作在可并行的金融推理任务中提升了 80.9% 的性能,而去中心化协作在动态网页浏览中表现更佳(+9.2%)。然而,在强序列依赖的规划任务中,所有多智能体变体的性能均下降了 39%-70% 。
基于上述发现,作者推导出一个混合效应模型(Mixed-Effects Model),能够以 的准确度预测未见任务的性能,为智能体系统的架构设计提供了量化指导。
1. 引言
随着大语言模型(LLM)能力的提升,能够推理、规划和行动的智能体(Agents)已成为 AI 应用的主流范式。尽管学术界和工业界普遍采用多智能体系统(MAS),并存在“更多智能体即所需一切(More agents is all you need)”的观点,但这一领域仍缺乏严谨的定量扩展原则。
现有的设计往往依赖直觉,从业者难以判断何时引入多智能体协作是有效的,何时仅仅是增加了计算成本。为了填补这一空白,本论文通过系统性的受控实验,剥离了提示词工程(Prompt Engineering)和特定实现细节的干扰,专注于研究智能体数量、协作结构、模型能力与任务属性之间的相互作用。
研究者明确区分了Agentic(智能体)任务与Non-Agentic(非智能体)任务。前者(如 Web 浏览、软件工程)需要持续的环境交互、部分可观察性下的信息收集以及策略的自适应调整;而后者(如 GSM8K, HumanEval)通常通过单次推理即可解决。本研究的核心贡献在于证明了多智能体系统的有效性并非单纯随智能体数量增加而线性增长,而是受到严格的架构与任务属性制约。
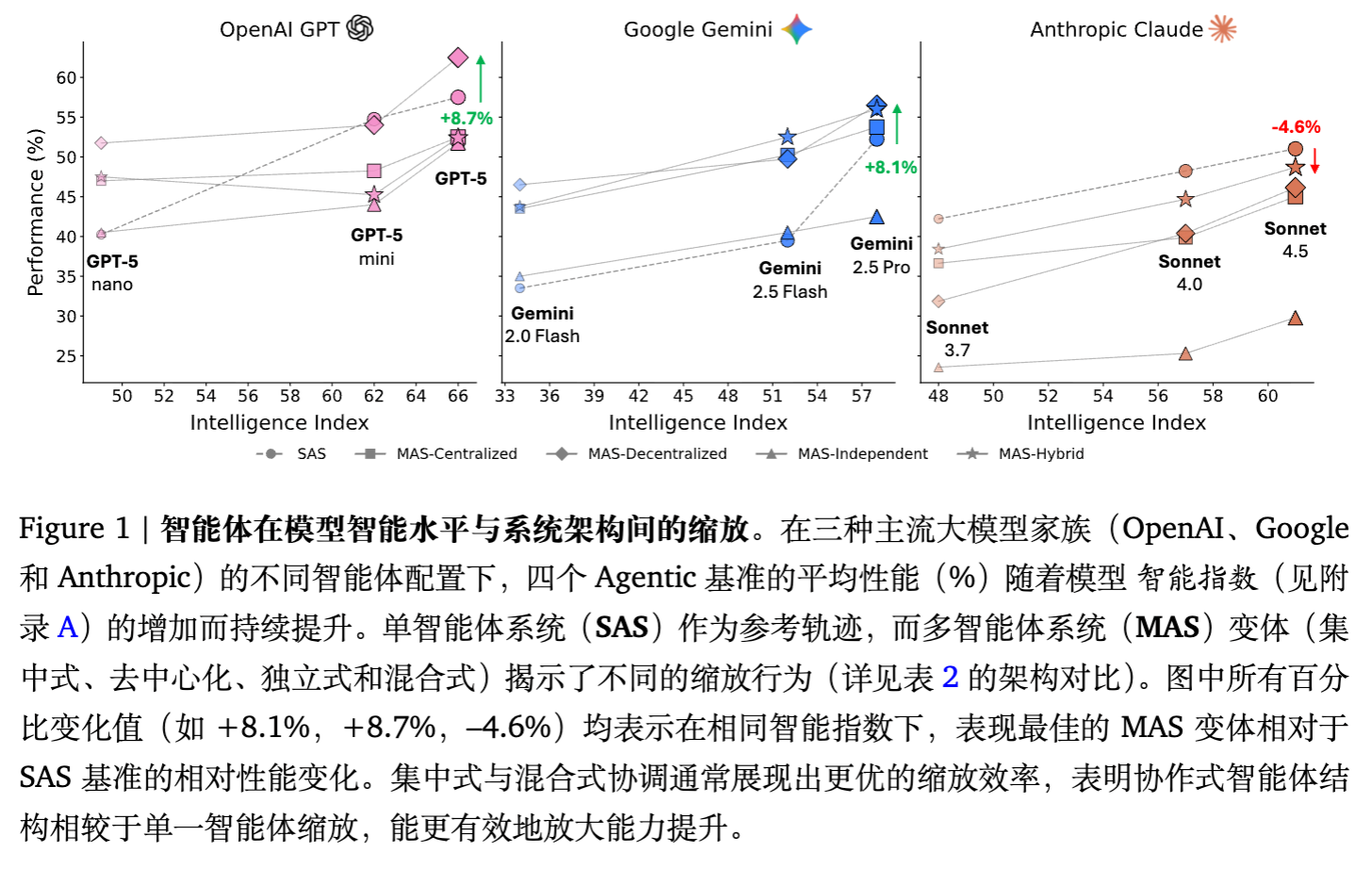
如上图所示,随着基础模型智能指数(Intelligence Index)的提升,不同架构表现出截然不同的扩展行为。
2. 形式化定义与系统分类
为了进行科学的比较,论文首先建立了智能体系统的形式化定义。
2.1 智能体系统定义
一个智能体系统定义为元组 ,其中:
-
表示智能体集合()。 -
是共享环境。 -
是通信拓扑。 -
是编排策略(Orchestration Policy)。
每个智能体 被定义为 ,其中 是推理策略(LLM), 是工具调用动作空间, 是内部记忆, 是将观察历史映射到动作的决策函数。
2.2 五种典型架构
为了通过结构消融(Structural Ablation)隔离协调机制的效果,研究选取了五种架构。表 1 展示了各架构在计算复杂度、通信开销和并行化潜力上的对比。

-
单智能体系统 (SAS): 。所有的感知、推理和行动都在一个单一的序列循环中发生。其通信开销为 0,记忆复杂度为 ( 为推理迭代次数)。这是基准参照系。 -
独立多智能体 (Independent MAS): 。 个智能体独立执行任务,最后通过简单的聚合(如投票)输出结果。具有最大的并行化因子 ,但无协作。 -
中心化多智能体 (Centralized MAS): 采用“中心辐射型”(Hub-and-Spoke)拓扑。一个编排者(Orchestrator)协调 个子智能体。虽然引入了瓶颈,但提供了层级化的验证机制。 -
去中心化多智能体 (Decentralized MAS): 全连接拓扑。智能体之间通过 轮辩论(Debate)进行点对点信息融合。记忆复杂度较高,为 ,因为每个智能体都存储辩论历史。 -
混合多智能体 (Hybrid MAS): 结合了层级控制和有限的横向通信。
研究通过参数化协调复杂度 来量化不同拓扑的成本,其中 是通信边数。
3. 实验设计与评估基准
为了确保结论的通用性,实验设计控制了实现混杂因素(Implementation Confounds),在所有配置中保持任务提示、工具和计算预算的一致性。
3.1 四个 Agentic 基准
选取的基准涵盖了从确定性到开放世界的不同任务结构:
-
Workbench: 模拟现实工作场所任务(如日历管理、邮件操作),具有确定性的代码执行和明确的成功标准。 -
Finance Agent: 涉及多步定量推理和风险评估的金融分析任务。 -
PlanCraft (Minecraft): 需要在约束条件下进行时空规划,具有高度的序列依赖性(Sequential Interdependence)。 -
BrowseComp-Plus: 动态网页导航、信息提取和跨页面综合,具有最高的环境不确定性。
这些任务均满足 Agentic 任务 的三个必要属性:
-
序列相互依赖(Sequential Interdependence): 后续动作依赖于先前的观察。 -
部分可观察性(Partial Observability): 状态信息隐藏,需主动查询。 -
自适应策略形成(Adaptive Strategy Formation): 策略必须基于反馈更新信念。
3.2 模型与智能指数
研究评估了三个 LLM 家族的多个尺寸模型:
-
OpenAI: GPT-5-nano, GPT-5-mini, GPT-5 -
Google: Gemini 2.0 Flash, 2.5 Flash, 2.5 Pro -
Anthropic: Claude Sonnet 3.7, 4.0, 4.5
为了统一衡量模型能力,研究采用了 Intelligence Index(智能指数),这是一个综合了推理、编码和知识基准的复合得分(范围 34-66)。
4. 核心实验结果与分析
论文通过 180 组配置的实验,揭示了多智能体性能的高度异质性。
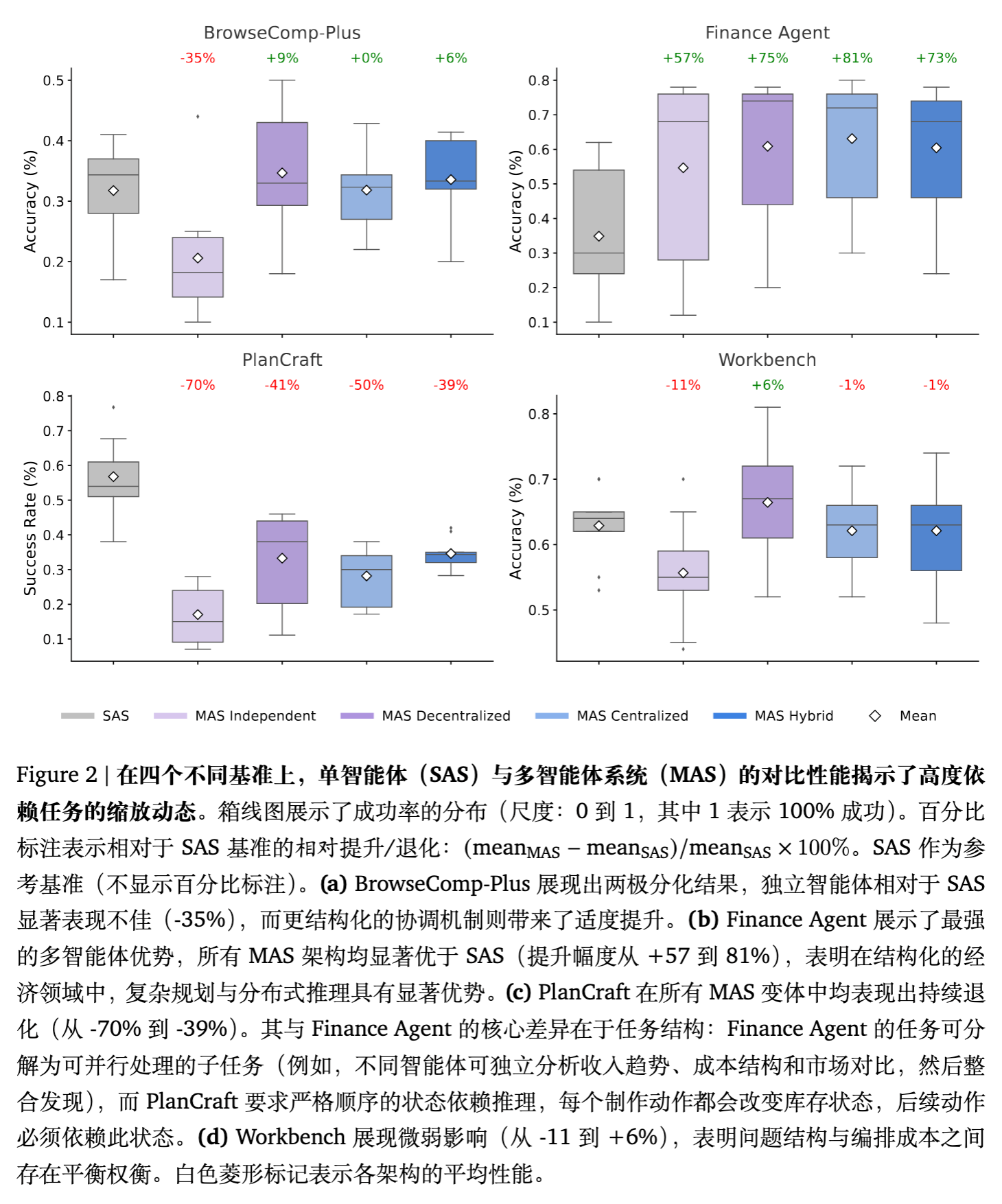
4.1 任务结构的主导作用
实验结果表明,多智能体协作并非在所有任务中都有效:
-
Finance Agent: 所有 MAS 架构均显著优于 SAS(+57% 至 +81%)。这是因为该任务可分解为并行的子任务(如分别分析收入趋势、成本结构),适合协作。 -
PlanCraft: 所有 MAS 变体均导致性能下降(-39% 至 -70%)。该任务要求严格的序列状态依赖推理,协作开销打断了推理链条,且不同智能体的状态认知难以同步。 -
BrowseComp-Plus: 结果两极分化。独立智能体表现极差(-35%),而去中心化协作取得适度提升(+9%),表明在高熵搜索空间中,并行的对等交流有助于探索。 -
Workbench: 收益微乎其微,说明在确定性强、工具使用密集的任务中,协作带来的边际收益被协调成本抵消。
4.2 协调饱和效应 (Coordination Saturation)
在 PlanCraft 等任务中观察到了协调饱和现象:除了基本的推理-通信权衡外,额外的协调不再改善结果,反而抑制了有效推理。这是因为在固定的 Token 预算下,用于智能体间通信的 Token 挤占了用于实际任务推理的 Token 配额。
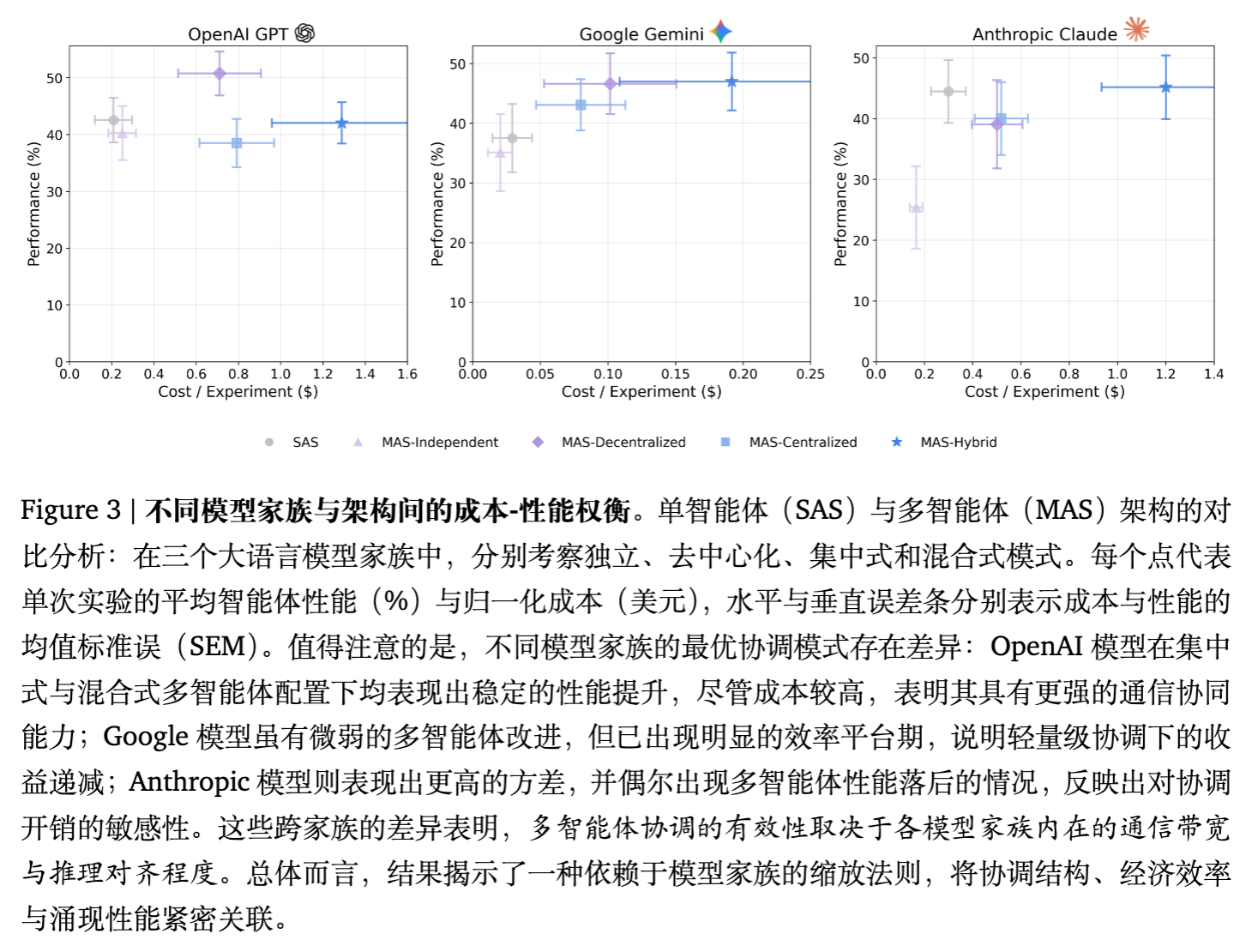
4.3 厂商特定的协作偏好
不同模型家族对架构的偏好存在差异,揭示了非均匀的扩展特性:
-
Anthropic: 在 Finance Agent 上,中心化架构提升了 127.5%,表现出稳健的层级依从性。 -
Google: 在 Finance Agent 上提升幅度最大(+164.3%),但在 PlanCraft 上,其最佳变体仅下降 25.3%(相比其他家更优),显示出其在处理协调开销方面的相对效率。 -
OpenAI: 表现出较强的混合架构协同效应,但在 PlanCraft 上也遭受了显著的性能损失。
5. 定量扩展原理(Scaling Principles)
本论文最重要的贡献是推导出了一个混合效应模型(Mixed-Effects Model),用于预测智能体系统的性能。
5.1 预测模型
研究拟合了一个包含 20 个参数的回归模型(公式 1),该模型解释了 51.3% 的交叉验证方差 ()。模型形式如下:
其中关键变量包括:
-
: 模型智能指数 -
: 工具数量 -
: 智能体数量 -
: 单智能体基线性能 -
: 协调效率 -
: 错误放大因子 -
: 协调开销
5.2 三大主导效应
模型系数揭示了三个决定性的抑制机制:
-
工具-协作权衡 (Tool-Coordination Trade-off):
系数 。这是影响最大的负面因子。对于拥有大量工具的任务(如 ),多智能体系统遭受的效率惩罚是单智能体的 2-6 倍。这反驳了“任务越复杂(工具越多),越需要更多智能体”的朴素假设。实际上,工具密集的任务放大了协作税(Coordination Tax),使得简单的架构反而更有效。
-
能力天花板 (Capability Ceiling):
系数 。当单智能体基线性能 较高时,引入协作带来的收益迅速递减。模型确定了 45% 的经验阈值(归一化后约 0.154 标准单位):当 超过此值,协作带来的开销将超过其纠错带来的收益。
-
架构依赖的错误放大 (Architecture-Dependent Error Amplification):
独立多智能体架构的错误放大因子 ,而中心化架构为 。交互项 () 表明,在工具丰富的环境中,独立智能体会发生灾难性的错误传播。这解释了为何 Independent MAS 在复杂任务中普遍表现不佳:缺乏智能体间的验证机制(Validation Bottlenecks),导致个体错误被直接聚合。
5.3 智能的二次方扩展
有趣的是,模型中智能指数 呈现二次方正相关 ()。这意味着模型能力的提升具有加速回报(Accelerating Returns):高智力模型()从每单位智力提升中获得的性能增益远超低智力模型。
6. 深入分析:协调动力学
除了顶层的性能指标,论文还深入分析了协作过程中的微观动力学。
6.1 轮次计数的幂律扩展
总推理轮次(Reasoning Turns)随智能体数量呈幂律增长:
指数 表明协调成本是超线性的。这意味着在 3-4 个智能体之后,系统将迅速撞上计算预算的墙,导致每个智能体分得的推理资源被严重稀释。
6.2 信息增益与消息密度
-
消息密度饱和: 成功率随消息密度呈对数增长,但在 条消息/轮次 时达到饱和。超过此点,额外的沟通不再提供新信息,只增加冗余。 -
信息增益 (): 在结构化任务(Finance)中,协作前后的信息增益与性能提升强相关 ()。但在 PlanCraft 中相关性极弱,说明智能体在序列约束下交换的信息缺乏可执行性。
6.3 错误分类学
基于 MAST (Multi-Agent System Failure Taxonomy) 的错误分析显示:
-
逻辑矛盾 (Logical Contradiction): 中心化架构通过共识机制将此类错误减少了 36.4%。 -
数值漂移 (Numerical Drift): 混合架构反而加剧了数值错误 (+24% 相比基线),因为多次传递导致舍入误差累积。 -
语境遗漏 (Context Omission): 中心化架构表现最好,减少了 66.8% 的遗漏,得益于编排者的全局视角。
6.4 冗余的边际效益
工作冗余(Redundancy)仅提供了微弱的正面效应 ()。这表明,简单地增加智能体进行重复工作(Ensembling)所带来的纠错能力,远不足以抵消由此产生的通信和计算开销。
7. 架构选择的工程指南
基于上述发现,论文提出了一套定量的架构选择准则,该准则在留出集(Held-out data)上达到了 87% 的预测准确率。
从业者应根据任务属性()和模型能力()计算预期收益:
-
规划类任务 (): 由于基线性能较高且工具较少,单智能体(SAS) 是最佳选择。 -
分析类任务 (): 需要平衡错误控制与开销,中心化多智能体(Centralized MAS) 最优。 -
工具密集型任务 (): 尽管开销巨大,但由于单智能体难以处理复杂的工具编排,去中心化多智能体(Decentralized MAS) 利用并行化优势可能胜出。
具体的决策边界由公式 1 给出,不再依赖“试错法”。
8. 讨论与局限性
8.1 主要启示
-
没有免费的午餐: 多智能体系统引入了根本性的上下文碎片化(Context Fragmentation)。SAS 拥有统一的内存流,而 MAS 必须将全局上下文压缩为有损的智能体间消息。这种信息压缩带来的认知负荷(Cognitive Load)是 MAS 性能下降的根源。 -
不仅仅是参数: 智能体系统的扩展不仅仅关乎模型参数量,更关乎通信拓扑与任务结构的对齐。
8.2 局限性与未来工作
-
规模限制: 当前研究主要集中在 3-9 个智能体的小型团队。更大规模的群体(如 Swarm Intelligence)是否会出现涌现行为尚待研究。 -
同质化模型: 实验主要使用了同一家族的模型。异构模型(如结合 GPT-5 的推理能力与小型模型的执行速度)的混合团队可能是未来的方向。 -
经济可行性: MAS 的 Token 消耗巨大(Hybrid 架构可达 SAS 的 5 倍以上)。如何通过稀疏通信或早期退出机制提高经济效益是落地关键。
9. 结论
论文强有力地证明了“更多智能体并不总是更好”。
通过引入效率、开销、错误放大等物理量,研究者建立了一个预测性的框架。该框架揭示了智能体协作的收益是一个关于任务可分解性(Decomposability)、工具复杂度(Tool Complexity)和基础模型能力的复杂函数。
往期文章:


