-
论文标题:Shaping capabilities with token-level data filtering -
论文链接:https://arxiv.org/pdf/2601.21571
TL;DR
作为定义了 GPT 范式的核心人物,Alec Radford 曾一手推动了无监督预训练与 Scaling Law 的普及,是 GPT 系列、CLIP 及 Whisper 的主要贡献者。在离开 OpenAI 后,他以独立研究者的身份,联合 Anthropic 及斯坦福的研究员 Neil Rathi 发布了最新成果《Shaping capabilities with token-level data filtering》。
该研究探讨了如何在预训练阶段通过Token 级数据过滤来精准移除大语言模型(LLM)的特定能力(以医学知识为代理任务),同时保留邻近领域的通用能力(如生物学)。核心结论包括:
-
粒度至关重要:相比于传统的文档级过滤,Token 级过滤在移除目标能力(Forget Set)和保留通用能力(Retain Set)的权衡上表现更优(Pareto 改进)。 -
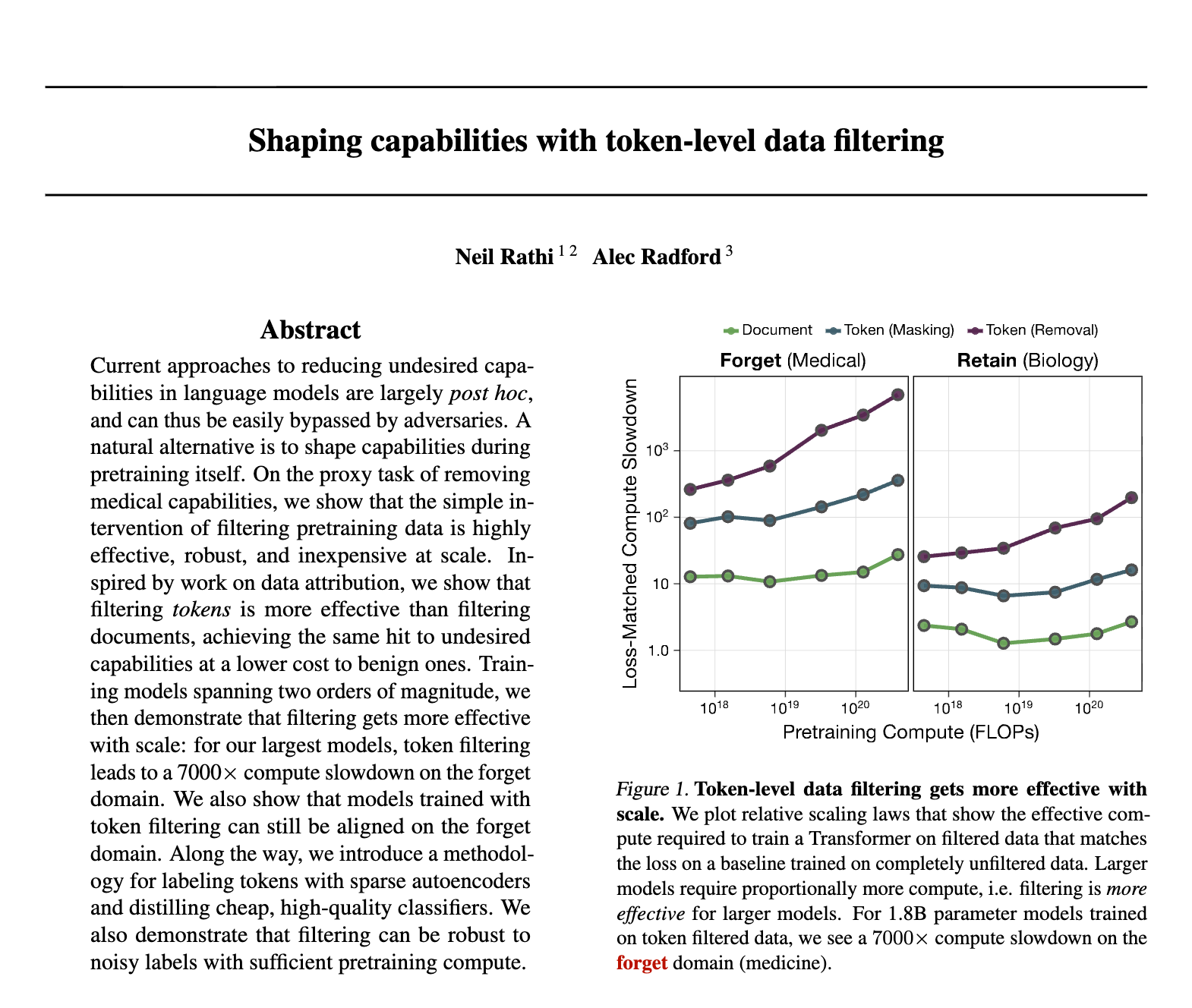
规模效应(Scaling Laws):数据过滤的效果随着模型规模的增加而显著增强。对于 1.8B 参数的模型,Token 过滤导致模型在目标领域上的收敛效率降低了约 7000 倍。 -
鲁棒性:相比于目前最先进的机器遗忘(Unlearning)方法(如 RMU),预训练阶段的过滤对对抗性微调(Adversarial Finetuning)表现出更强的鲁棒性。 -
对齐优势:与其担忧移除知识会导致模型无法识别并拒绝有害指令,研究发现经过 Token 过滤的模型反而更容易进行拒绝回答(Refusal)的对齐训练。 -
工程实现:作者提出了一套利用稀疏自编码器(SAE)生成弱标签,并蒸馏出轻量级双向语言模型(biLM)作为分类器的方法,证明了低成本分类器在大规模过滤中的有效性。
1. 引言
当前,前沿语言模型在预训练过程中会从海量文本中习得广泛的能力。为了构建安全的 AI 系统,研究人员通常通过“能力塑造”(Capability Shaping)来选择性地削弱某些不期望的能力(如制造生物武器、网络攻击),同时保留有益的能力(如生物学研究、编程辅助)。
目前的标准做法主要集中在后训练阶段(Post-training),例如通过 RLHF 让模型学会拒绝回答,或通过机器遗忘(Machine Unlearning)技术擦除特定权重。然而,这些方法往往存在局限性:
-
防御脆弱:通过 Jailbreak 或简单的微调,被压制的能力往往能被重新激活。 -
猫鼠游戏:防御者与攻击者陷入无休止的对抗循环。
另一种思路是在预训练阶段进行干预。已有的数据选择工作主要关注提升下游性能或减少毒性,而本文则系统性地研究了如何通过数据过滤(Data Filtering)来移除特定领域的知识与能力。本文的核心假设是:知识存在于 Token 级别,而非仅仅是文档级别。
2. 实验设置与方法论
为了量化研究数据过滤的效果,作者选择了一个具体的代理任务:移除医学能力(Medical Capabilities),同时保留生物学能力(Biology Capabilities)。
2.1 任务定义:Forget 与 Retain
-
Forget Set(目标移除):临床医学知识,包括症状、诊断、治疗、药物、病理学等。 -
Retain Set(目标保留):与医学紧密相关但属于基础科学的生物学知识,如生物化学、遗传学(非临床)、解剖学(非俗语)等。 -
数据集:使用 FineWeb-Edu 作为预训练语料。
2.2 两种过滤粒度
研究对比了两种数据过滤策略:
-
文档级过滤(Document-level filtering):如果一个文档被判定为包含过多医学内容,则丢弃整个文档。 -
Token 级过滤(Token-level filtering):仅针对文档中的特定 Token 进行干预。
2.3 Token 级干预的两种实现
在识别出属于 Forget Set 的 Token 后,作者尝试了两种干预方式(见下图):
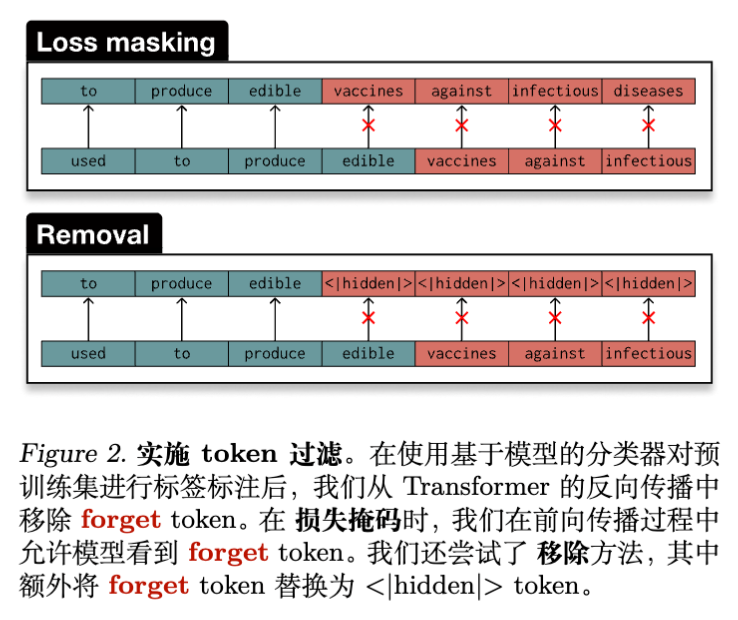
-
Loss Masking(损失掩码):
在模型前向传播时,保留 Token 不变,但在反向传播时,将属于 Forget Set 的 Token 的损失(梯度)置零。-
特点:模型在预测 Retain Token 时仍能看到 Forget Token 作为上下文,有助于保持上下文连贯性,但可能导致模型通过上下文隐式学习到 Forget 概念的表征。
-
-
Removal(移除/替换):
将 Forget Token 替换为特殊的<|hidden|>Token,并同样进行 Loss Masking。-
特点:彻底阻断了信息流,但破坏了文本的连贯性。
-
2.4 模型训练配置
作者训练了一系列计算最优(Compute-optimal)的 Transformer 模型,参数规模跨越两个数量级:
-
规模:从 61M 到 1.8B 参数。 -
架构:改进版 GPT-2(使用 RoPE, ReLU², Pre-RMSNorm)。 -
硬件:H200 GPU 集群。 -
评估基准: -
Text Perplexity:医学文本(PubMed)、生物学文本(bioRxiv)、非医学文本。 -
多选问答(MCQ):MedMCQA, MedQA-USMLE, MMLU (Medical/Biology/STEM)。 -
开放式生成:HealthSearchQA,使用 Claude Sonnet 4 作为裁判。
-
3. 核心实验结果
3.1 Token 级过滤优于文档级过滤(Pareto 优势)
研究首先对比了不同过滤阈值下的效果。通过扫描分类器的阈值,作者绘制了保留能力(生物学 Loss)与移除能力(医学 Loss)的权衡曲线。
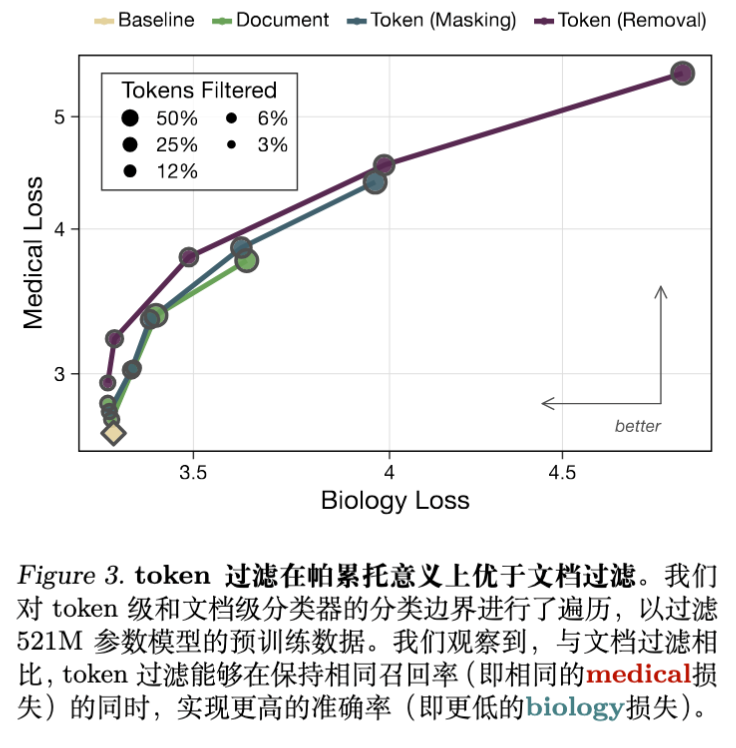
实验结果表明:
-
Token 过滤是 Pareto 改进:在达到相同的医学能力抑制水平(相同的 Medical Loss)时,Token 过滤导致的生物学能力损失更小。 -
精度与召回:文档级过滤往往过于粗糙,为了移除一个医学概念,不得不丢弃包含大量非医学信息的整篇文档(低 Token 级精度);或者为了保留文档,不得不放过其中的医学片段(低 Token 级召回)。
3.2 过滤效果随规模扩展(Scaling Laws)
这是本文最重要的发现之一。作者通过计算“相对计算降速”(Relative Compute Slowdown)来量化过滤的效果。
-
定义:为了达到在过滤数据上训练的模型所表现出的 Loss,在未过滤数据上训练基线模型所需的计算量与实际计算量的比值。
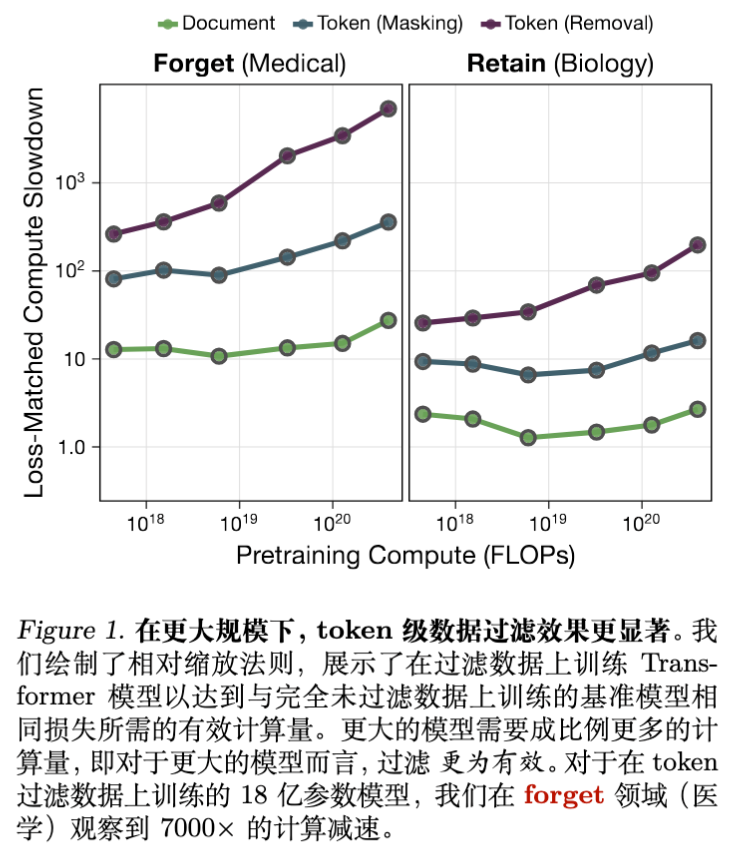
结果显示:
-
越大的模型,过滤效果越明显。对于 1.8B 参数的模型,在 Forget 领域(医学)上,Token Removal 策略导致了超过 7000倍 的计算降速。这意味着,要在未过滤数据上训练一个模型达到被过滤模型的(差劲)医学水平,仅需要极少的计算量。 -
Token 级过滤始终优于文档级。在所有规模下,Token 级过滤的计算降速倍数都显著高于文档级过滤(文档级约为 30倍)。
3.3 下游任务评估
在多项选择题(MCQ)和开放式问答中,过滤后的模型表现如下:
-
MCQ:在 MedMCQA 和 MedQA-USMLE 上,过滤模型的准确率接近随机猜测。而在 MMLU Biology 和非 STEM 学科上,性能几乎没有下降。 -
Chat:在 HealthSearchQA 上,Token 过滤模型的回答相关性降低了 4 倍,正确性降低了 10 倍。模型经常产生幻觉或重复无意义的词汇。
4. 鲁棒性分析:过滤 vs. 遗忘(Unlearning)
一个关键问题是:这种在预训练阶段“删减”的能力,是否容易通过后续的微调恢复?作者将数据过滤与最先进的表示层遗忘方法 RMU (Representation Misalignment) 进行了对比。
4.1 对抗性微调设置
-
攻击者拥有模型权重。 -
攻击者使用医学文本(PubMed)对模型进行微调。 -
测量恢复基线模型性能所需的微调步数/Token数。
4.2 实验结果
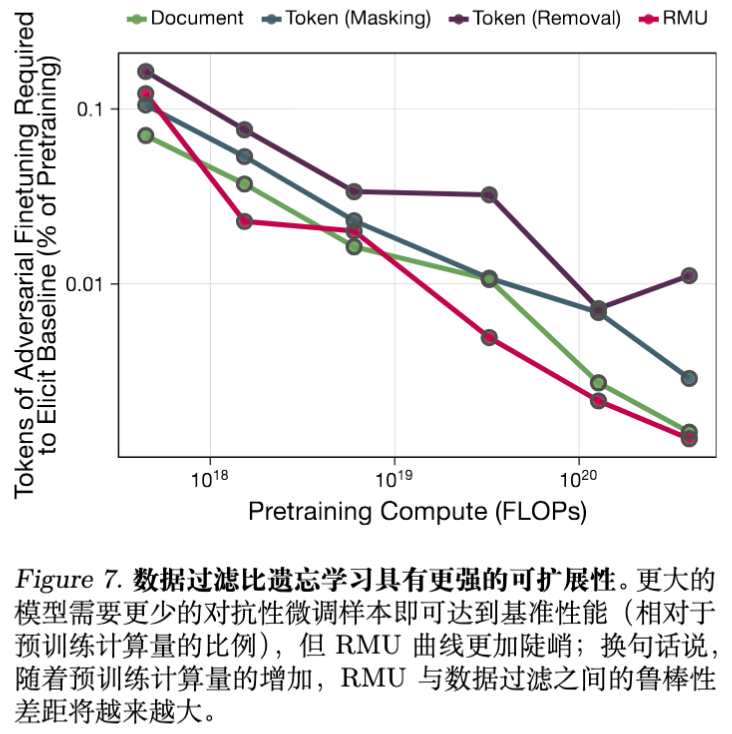
-
数据过滤更鲁棒:在所有规模下,恢复被过滤模型的医学能力所需的计算量,都远高于恢复 RMU 处理后的模型。 -
规模差异:随着模型规模增大,RMU 的鲁棒性下降得比数据过滤更快。对于 1.8B 模型,RMU 所需的微调 Token 数比 Token Removal 少了 13 倍。 -
恢复曲线:RMU 处理的模型在微调初期 Loss 急剧下降,表明其知识只是被“隐藏”或“错位”了,而非被真正移除;而数据过滤模型的 Loss 下降曲线则更为平缓,符合从头学习的特征。
5. 对齐与拒绝回答(Refusal Training)
此前有一种观点认为:模型必须先知道什么是“坏”的知识,才能学会拒绝它(Knowledge is required for refusal)。例如,为了让模型拒绝制造炸弹的指令,模型似乎需要知道炸弹是什么。
本文的实验结果反驳了这一直觉,至少在能力移除的场景下。
5.1 实验设置
-
对经过 1.8B 参数预训练的模型进行指令微调(Chat Training)。 -
在 HealthSearchQA(医学问题)上训练模型进行拒绝(输出 "I cannot answer...")。 -
在 Alpaca(通用问题)上训练模型正常回答。 -
测试模型的泛化能力:是否能在未见过的医学问题上拒绝,同时在通用问题上不拒绝。
5.2 结果分析
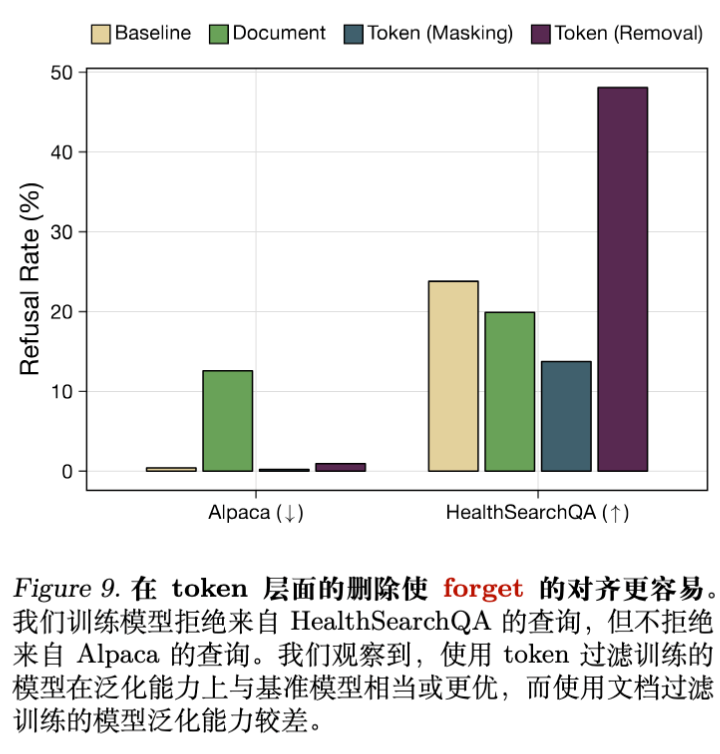
结果令人惊讶:
-
Token Removal 表现最佳:在 HealthSearchQA 上的拒绝率是基线的 2 倍,且没有在 Alpaca 上产生误拒。 -
文档过滤表现较差:经过文档过滤的模型很难泛化拒绝行为,它倾向于拒绝所有问题(包括 Alpaca)或者都不拒绝。
解释:
作者认为,对于 Token Removal 模型而言,医学领域的 Token 在预训练中从未在特定上下文中出现过(或者被 <|hidden|> 替代)。因此,拒绝训练实际上变成了一个分布外检测(OOD Detection)问题。模型只需要学会:“当输入包含这些我没见过的奇怪模式/Token 分布时,输出拒绝”。这比区分“已知的有毒知识”和“已知的无毒知识”要简单得多。
6. 如何构建低成本高效能的 Token 分类器
本文在工程上的另一大贡献是证明了:不需要昂贵的强模型,也能实现高质量的 Token 级过滤。
6.1 标签获取:利用 SAE (Sparse Autoencoders)
由于没有现成的 Token 级医学/非医学标签,作者采用了一种弱监督方法:
-
SAE 训练:使用 Gemma 2 9B 层的 SAE。 -
特征筛选:利用 Claude 3.5 对 SAE 的 Latent 特征解释进行分类,筛选出与“医学”相关的 Latent。 -
自动标注:如果一个 Token 在这些医学 Latent 上有高激活,则标记为 Medical。同时通过邻接传播(如果相邻 Token 也是医学相关的)来平滑标签,形成 Span。
这种方法生成了高质量的“银标准”数据。
6.2 分类器架构:双向模型(biLM)的胜利
为了在预训练过程中实时过滤,分类器必须极度轻量。作者对比了不同架构:
-
ModernBERT-large (395M) -
RoBERTa (61M) -
自定义双向 LM (biLM) :同时训练一个从左到右和一个从右到左的 61M 模型,并将它们的表征拼接。
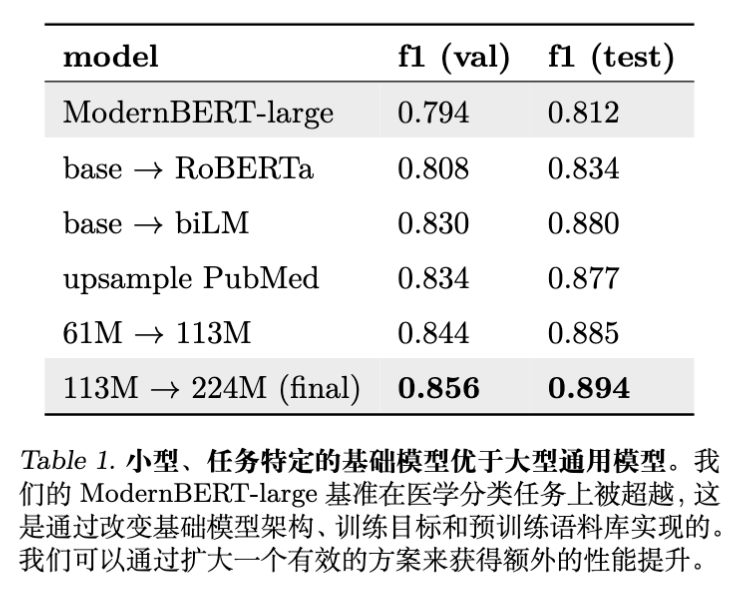
结果显示,仅 224M 参数的 biLM 在 Token 分类任务上的 F1 分数(0.894)击败了 ModernBERT-large(0.812)。这说明:
-
双向上下文对 Token 分类至关重要(例如 "virus" 在 "computer virus" 和 "flu virus" 中的含义完全不同)。 -
领域特化预训练:在包含医学数据的混合语料上预训练小模型,比使用通用预训练大模型更有效。
6.3 弱标签与强泛化
作者还探讨了分类器质量对过滤效果的影响:
-
抗噪性:即便分类器存在一定噪声,只要通过调整阈值(以牺牲 Precision 换取极高的 Recall),在足够的计算规模下,依然能实现极佳的过滤效果。 -
弱到强泛化:使用弱标签(如粗糙的文档级标签或弱分类器生成的标签)训练的 Token 分类器,表现出了良好的泛化能力,能够逼近使用强标签训练的效果。
7. 讨论与局限性
7.1 知识 vs. 能力
文章通过“知识移除”来实现“能力移除”。作者承认这是一个代理目标。理想的过滤应该针对导致危险能力的特定数据点,但基于内容的过滤(医学知识)是一个可行的近似。实验结果表明,去除知识确实导致了推理和生成能力的丧失。
7.2 对双用(Dual-use)模型的影响
对于开源模型社区,这既是好消息也是坏消息。
-
好消息:开发者可以更安全地发布模型,因为移除危险知识(如生物武器制造)是切实可行的,且难以被恶意恢复。 -
坏消息:对于希望特定恢复该能力的合法用户(如医学研究者),恢复成本虽然比从头训练低,但依然显著(需要足够的数据和计算)。不过,附录 B.5 指出,大部分过滤增益发生在早期,这意味着开发者可以发布一个“安全版”,并为受信任方提供一个通过特定数据“补全”训练的完整版。
7.3 对齐的新视角
文章关于 Refusal Training 的发现挑战了传统的“对抗训练”直觉。这表明,无知(Ignorance)有时候是实现对齐的有效途径。与其让模型学习危险知识再压制它,不如让模型对危险领域保持“陌生”,从而更容易触发拒绝机制。
8. 总结
《Shaping capabilities with token-level data filtering》一文为大模型的安全预训练提供了强有力的实证支持。它不仅在方法上确立了 Token 级过滤 的核心地位,更通过详尽的 Scaling Laws 分析证明了该方法在未来更大规模模型上的潜力。
Takeaway:
-
不要只做文档过滤:Token 级粒度能带来质的飞跃。 -
便宜的分类器够用了:专门训练的小型双向模型(biLM)配合 SAE 自动标注,足以处理海量预训练数据。 -
规模是朋友:模型越大,通过数据过滤“切除”特定能力的效率越高。 -
无知即安全:从源头移除数据,比事后通过 RLHF 让模型“学会拒绝”更稳健,也更容易训练。
更多细节请阅读原文。
往期文章:


