
-
论文标题:Does Your Reasoning Model Implicitly Know When to Stop Thinking? -
论文链接:https://arxiv.org/pdf/2602.08354
TL;DR
今天分享一篇来自北航和字节合作的一篇论文《Does Your Reasoning Model Implicitly Know When to Stop Thinking?》这篇研究提出了一项反直觉的发现:当前的推理模型往往存在严重的“过度思考”现象,产生的推理步骤远超实际所需。然而,通过深入分析,作者发现模型内部其实隐式地知道何时该停止,只是这一能力被当前的贪婪解码或随机采样策略所掩盖。
基于此发现,作者提出了 SAGE (Self-Aware Guided Efficient Reasoning) ,一种推理时的搜索策略,利用模型自身的累积置信度来挖掘简洁且正确的推理路径。进一步地,为了将这种高效推理能力内化到模型中,作者提出了 SAGE-RL,将 SAGE 集成到 RLVR(如 GRPO/GSPO)的 Rollout 阶段。实验表明,SAGE-RL 在 MATH-500、AIME 等基准上,不仅显著提升了准确率,还使得推理长度平均减少了约 40%,实现了推理效率与能力的双重提升。
1. 引言
1.1 大模型推理的现状与挑战
近年来,大型推理模型(LRMs)通过长思维链(CoT)显著提升了处理复杂任务(如数学竞赛、代码生成)的能力。OpenAI 的 o1 和 DeepSeek-R1 是这一领域的代表。普遍的观点认为,“想得越久,表现越好”。长 CoT 允许模型通过更多的中间步骤来探索问题空间,减少逻辑跳跃。
然而,这种机制带来了一个显著的副作用:冗余。在实际应用中,过长的推理链导致了巨大的计算开销和延迟。更重要的是,近期的研究(如 Balachandran et al., 2025)指出,单纯增加推理长度并不总是与正确率正相关,有时甚至是有害的。例如,DeepSeek-R1 在某些问题上的输出长度是 Claude 3.7 Sonnet 的 5 倍,但准确率相当。
1.2 核心研究问题
本文的核心切入点在于一个基础性问题:LRMs 是否知道何时该停止思考?
如果模型实际上已经得出了正确答案,但受限于采样策略(Sampling Strategy)而继续生成无效或重复的 Token,那么这种计算就是浪费。本文的研究表明,模型确实具备这种“自我意识”,但当前的 Pass@1 推理范式(通常基于贪婪或随机采样)无法有效利用这一信号。
2. 当前采样范式的困境
为了回答上述问题,作者首先对当前模型在 Pass@k 和 Pass@1 下的行为进行了定量分析。
2.1 Pass@k:长度膨胀并不保证正确性
假设模型能够可靠地判断停止时机,那么更长的 CoT 理应对应更难的问题或更高的正确率。然而,作者复现并验证了先前的发现:
-
长度与正确率解耦:在 AIME 2025 等数据集上,错误答案的长度往往比正确答案更长。 -
Pass@k 中的潜能:在多次采样(Pass@k)中,往往存在比贪婪解码更短且正确的路径。这意味着模型能力范围内存在最优解,但现有采样方法找不到它。
2.2 Pass@1:现有策略无法及时终止
为了精确量化“过度思考”,作者提出了一个新指标:首次正确步骤比率 (Ratio of the First Correct Step, RFCS) 。
-
RFCS = 1:表示模型在得出正确答案后立即停止(理想情况)。 -
RFCS < 1:表示模型在得出正确答案后,继续生成了冗余步骤。
实验观察:
在 MATH-500 数据集上使用 DeepSeek-distilled-Qwen-1.5B (DS-1.5B) 进行测试:
-
如图 2 所示,模型在第 500 个 Token 就推导出了正确答案,但直到 952 个 Token 才停止,RFCS 约为 0.52。这意味着近一半的计算是浪费的。 -
统计数据显示,超过一半的样本 RFCS < 1,表明无效推理步骤是普遍存在的。即使是经过大规模强化学习后训练(Post-training)的模型(如 DeepScaleR)也无法幸免。

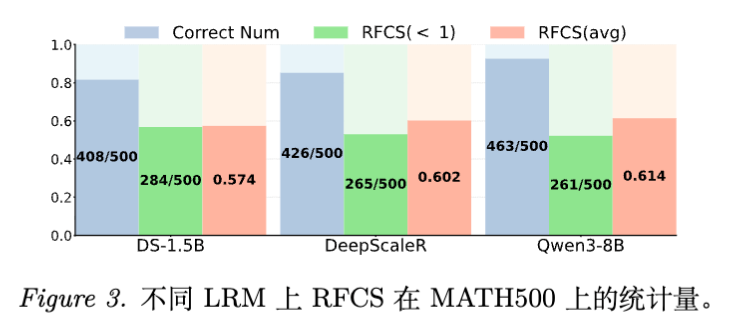
结论:
模型虽然在内部已经“算”出了答案,但在生成策略上缺乏“刹车”机制,导致 Pass@1 性能受限且效率低下。
3. SAGE
基于上述观察,作者提出了 SAGE。SAGE 的核心思想是利用累积置信度来指导搜索,从而挖掘出那些被 Pass@1 忽略的短而精的路径。
3.1 符号定义
给定查询 和已生成的前缀 ,定义 为截止到第 步的平均累积对数概率(Average Cumulative Log-Probability):
其中 是第 个 Token 的对数概率:
注意:这里选择平均累积概率 而非单纯的联合概率,是为了避免长度惩罚(长序列的联合概率天然更低),从而公平地比较不同长度的路径。
3.2 Token 级推理路径探索 (Token-Wise Exploration)
SAGE 采用了类似于 Beam Search 的探索机制,但在评分函数和终止条件上有关键区别。
扩展过程:
设定探索宽度为 (Exploration Width, EW)。在每个时间步,保留 Top- 个候选序列。
对于候选集 中的每个序列 ,模型首先选出 Top- 个最可能的下一个 Token,构成候选扩展集:
然后,计算所有扩展路径的累积得分 ,并保留全局得分最高的 个路径进入下一轮。
终止条件与 <think> 的作用:
这是 SAGE 的核心创新点。作者发现,当模型确信自己完成了推理时,</think> 标记往往会伴随着极高的置信度出现。
-
观察 1:在 SAGE 的搜索过程中,当 </think>出现时,它在候选集中的 排名往往是第一名。 -
观察 2:相比之下,如果只看单步概率 (即标准的贪婪或随机采样依赖的指标), </think>的概率可能并不高。
基于此,SAGE 的终止逻辑非常简单:一旦某条路径生成了 </think> 标记,且该路径在当前候选集中被保留(即属于 Top- 高置信度路径),则认为该路径是有效且完整的,将其加入最终结果集 。
当收集到 个完整路径或达到最大步数 时,算法结束。
3.3 为什么 SAGE 有效?(理论与消融)
为了验证 (累积置信度)的重要性,作者对比了两种变体:
-
TSearch w/ :使用累积得分 进行剪枝(即 SAGE 原型)。 -
TSearch w/ :仅使用当前步概率 进行剪枝(类似于贪婪搜索的变体)。
实验结果:
-
TSearch w/ :随着探索宽度 的增加,响应长度持续下降,同时准确率稳步上升。这证明了高置信度路径通常更短且更准确。 -
TSearch w/ :随着 增加,准确率迅速下降,且发生了严重的“长度坍塌”(Length Collapse),生成的路径过短且错误。
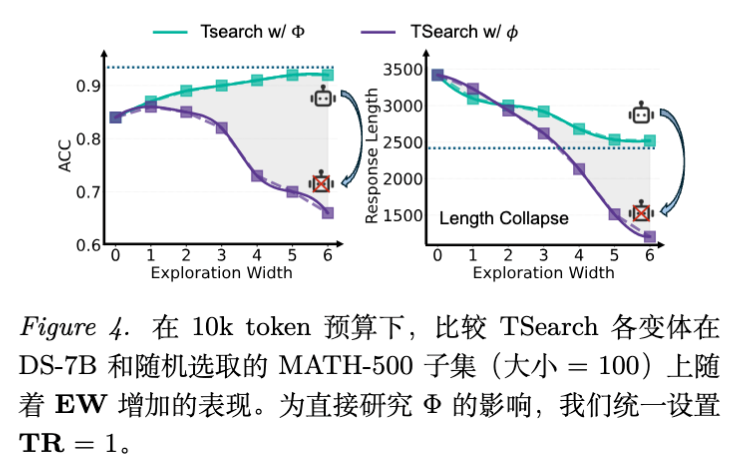
深入分析(Case A vs Case B):
作者在附录 B 中详细对比了 SAGE 与标准 Beam Search 的区别。
-
Case A(直接丢弃):在标准 Beam Search 中,如果 </think>的单步概率较低,即使之前的路径置信度很高,该路径也可能被直接丢弃。而 SAGE 看重整体 ,能保留这种路径。 -
Case B(过早剪枝):标准 Beam Search 倾向于保留当前概率高的 Token,导致生成冗长且置信度逐渐降低的路径。SAGE 通过全程监控 ,能及时识别出高质量的终止节点。
这一发现证实了:模型隐式地知道何时停止(表现为高 路径上的 </think>),但这一信号被局部的低 掩盖了。
4. 从 Token 级到 Step 级
虽然 Token 级搜索在分析上很有用,但在实际推理中效率较低。为了平衡效率,作者提出了 Step-Wise SAGE。
4.1 Step-Wise 推理链探索
在每一步 ,不再是生成一个 Token,而是采样一个完整的推理步骤(Reasoning Step) 。
推理步骤通常以换行符 \n\n 或特定分隔符为界。
其中 是从策略 中独立采样的。
这种方法大大减少了搜索的深度,同时保留了 SAGE 的核心特性:利用 来评估整个步骤序列的质量。
伪代码逻辑(基于附录 E):
-
初始化 个候选路径。 -
循环直到完成: -
对每个候选路径,并行采样 个可能的下一步骤(通过随机采样)。 -
计算所有新路径的 。 -
保留 Top- 个路径。 -
如果某路径包含 </think>,将其移入完成集。
-
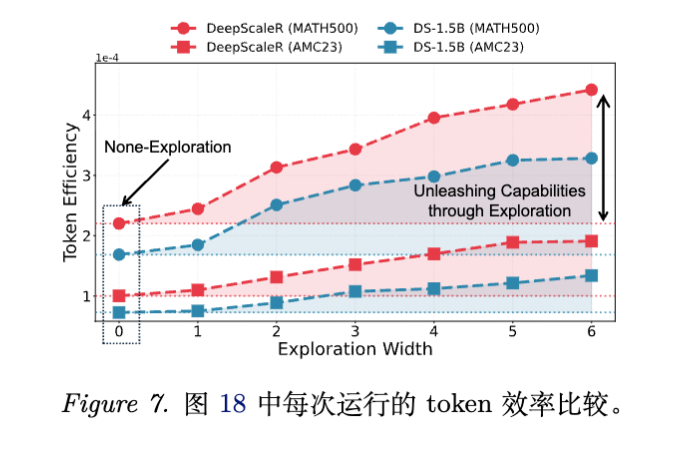
4.2 性能随探索宽度的收敛
作者研究了探索宽度 对性能的影响(图 7, 图 18)。
-
收敛性:随着 增加,模型的 Pass@1 准确率上升,长度下降,并逐渐趋于一个稳定值。 -
潜能释放:这一收敛值代表了模型在当前参数下的“固有高效推理能力边界”。SAGE 并没有教模型新知识,而是释放了被贪婪解码压抑的潜能。
5. SAGE-RL
SAGE 虽然在推理时有效,但增加了计算成本(需要维护多个 Beam)。更理想的目标是:让模型在 Pass@1(单次贪婪/随机采样)时就能直接生成 SAGE 找到的那种短而精的路径。
为此,作者提出了 SAGE-RL。这是一个与模型架构无关的通用框架,可以轻松集成到现有的 RLVR 算法中,如 GRPO 或 GSPO。
5.1 方法论:改造 Rollout 阶段
传统的 RLVR(如 DeepSeek-R1 使用的 GRPO)训练流程如下:
-
Rollout:对每个 Query,使用当前策略 随机采样 个输出。 -
Reward:验证每个输出的正确性,计算优势(Advantage)。 -
Update:优化策略以最大化高回报路径的概率。
SAGE-RL 的改进:
SAGE-RL 仅修改第一步 Rollout。它采用混合采样策略。
对于每个 Query,生成 个输出,其中:
-
个输出由 SAGE 算法生成(探索到的高效路径)。 -
个输出由 标准随机采样 生成。
这样生成的输出集合 包含了自然探索的路径和 SAGE 挖掘的高效路径。
5.2 优化目标函数
以 GRPO 为例,SAGE-GRPO 的目标函数如下:
其中,关键在于优势函数 的计算。由于 SAGE 生成的路径通常由 正确 且 短 的特性组成,它们在组内归一化(Group Relative)比较中会获得极高的优势值。
机制解释:
-
当 SAGE 找到一条比随机采样更短且正确的路径时,它的 Reward 是 1(正确),且因为长度短,并不受长度惩罚(虽然本文主要用 Outcome Reward,但短路径在某些隐式偏好或后续效率指标中更优,且 SAGE 路径的高置信度使得 KL 散度约束下的更新更为稳健)。 -
更重要的是,SAGE 路径不仅正确,而且去除了冗余。RL 算法会“看到”这些高质量数据,并更新参数,使得模型在未来更有可能直接生成类似的路径。这实际上是一种自蒸馏(Self-Distillation)过程,但通过 RL 的方式实现。
同样,该方法也可以应用于 GSPO(Group Sequence Policy Optimization),形成 SAGE-GSPO。
6. 实验设置与结果分析
6.1 实验配置
-
基座模型: -
DeepSeek-R1-Distill-Qwen-1.5B (DS-1.5B) -
DeepSeek-R1-Distill-Qwen-7B (DS-7B) -
DeepScaleR (1.5B) -
Qwen3-8B
-
-
基准测试: -
简单:MATH-500 -
中等:AMC 2023, AIME 2024 -
困难:AIME 2025, OlympiadBench, Minerva
-
-
对比基线: -
Vanilla RLVR (GRPO, GSPO) -
ThinkPrune, AdaptThink, Efficient-Reasoning, GRPO-LEAD 等近期针对推理效率的方法。
-
6.2 主要结果(准确率与效率的双重提升)
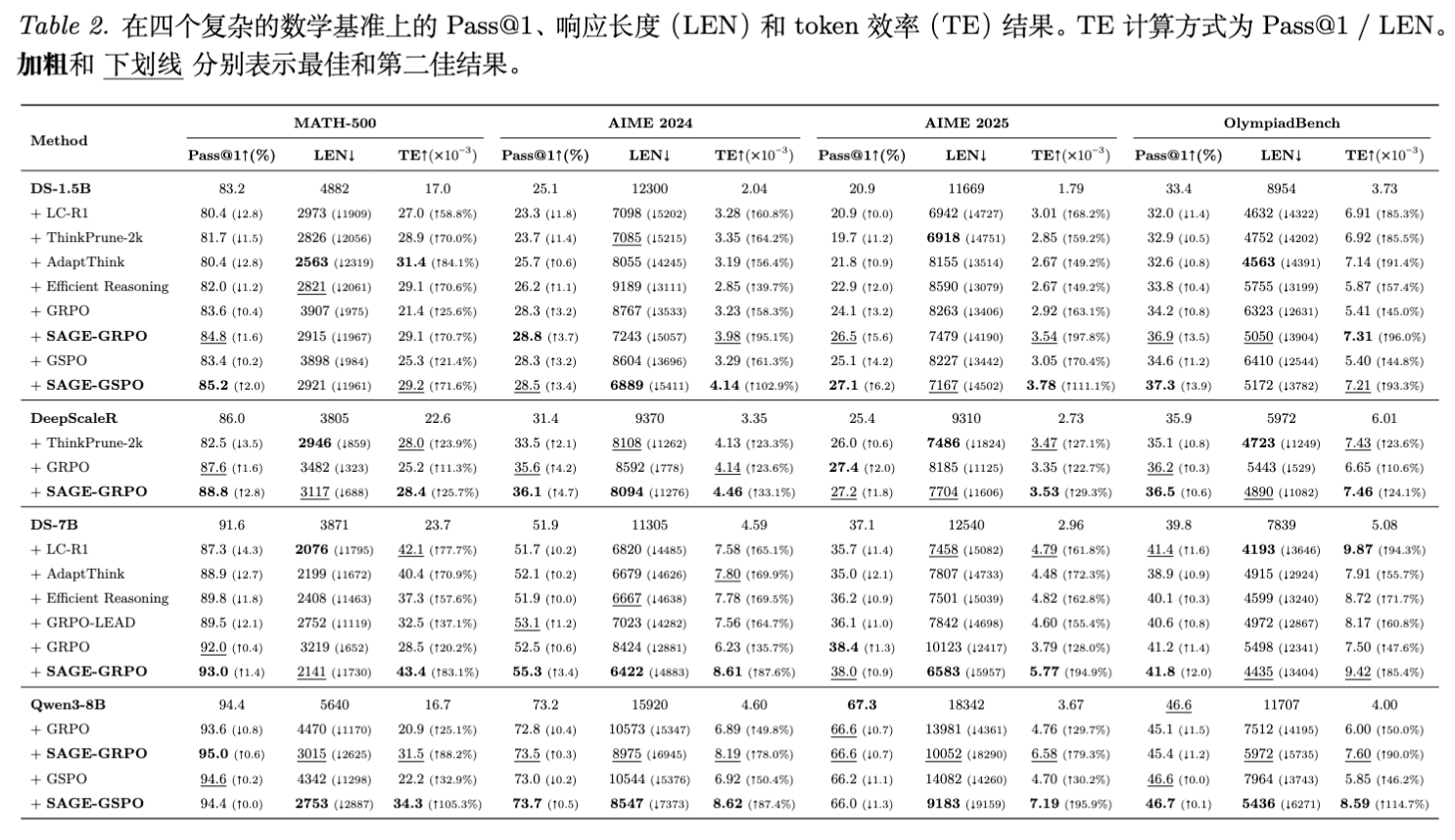
表 2 和表 4 展示了详尽的实验结果。
1. 综合性能提升:
SAGE-RL 在所有数据集和模型规模上均取得了 SOTA 或接近 SOTA 的效果。
-
DS-1.5B on AIME 2025: -
Pass@1 从 20.9% 提升至 26.5% (SAGE-GRPO)。 -
平均长度从 11669 Tokens 减少至 7479 Tokens。 -
Token Efficiency (Pass@1 / Length) 提升了近一倍。
-
2. 战胜强基线:
-
vs. AdaptThink:AdaptThink 虽然极大地压缩了 Token 数,但在困难任务(如 AIME)上导致了准确率的显著下降(过早停止)。SAGE-RL 则在保持高准确率的同时实现了合理的压缩。 -
vs. Vanilla GRPO/GSPO:标准的 RLVR 训练虽然能提升准确率,但往往伴随着推理长度的增加(模型学会了“尝试更多”)。SAGE-RL 打破了这一权衡,实现了“少即是多”。
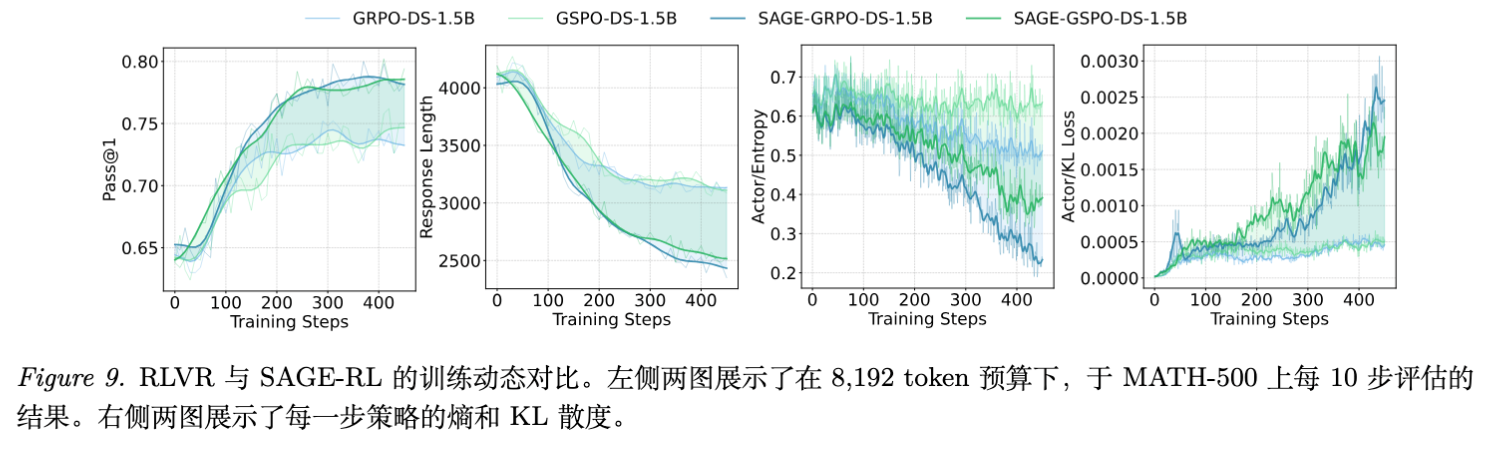
6.3 训练动力学分析
作者深入分析了训练过程中的指标变化。
-
熵(Entropy)的降低:SAGE-RL 训练的模型,其策略熵下降得比标准 RLVR 更快。这表明模型对自己的推理路径越来越自信,不再需要通过大量的随机探索来覆盖答案。 -
KL 散度的上升:SAGE-RL 的 KL 散度上升幅度较大,说明策略参数更新幅度大,模型正在发生显著的行为模式转变(从冗余推理转向高效推理)。
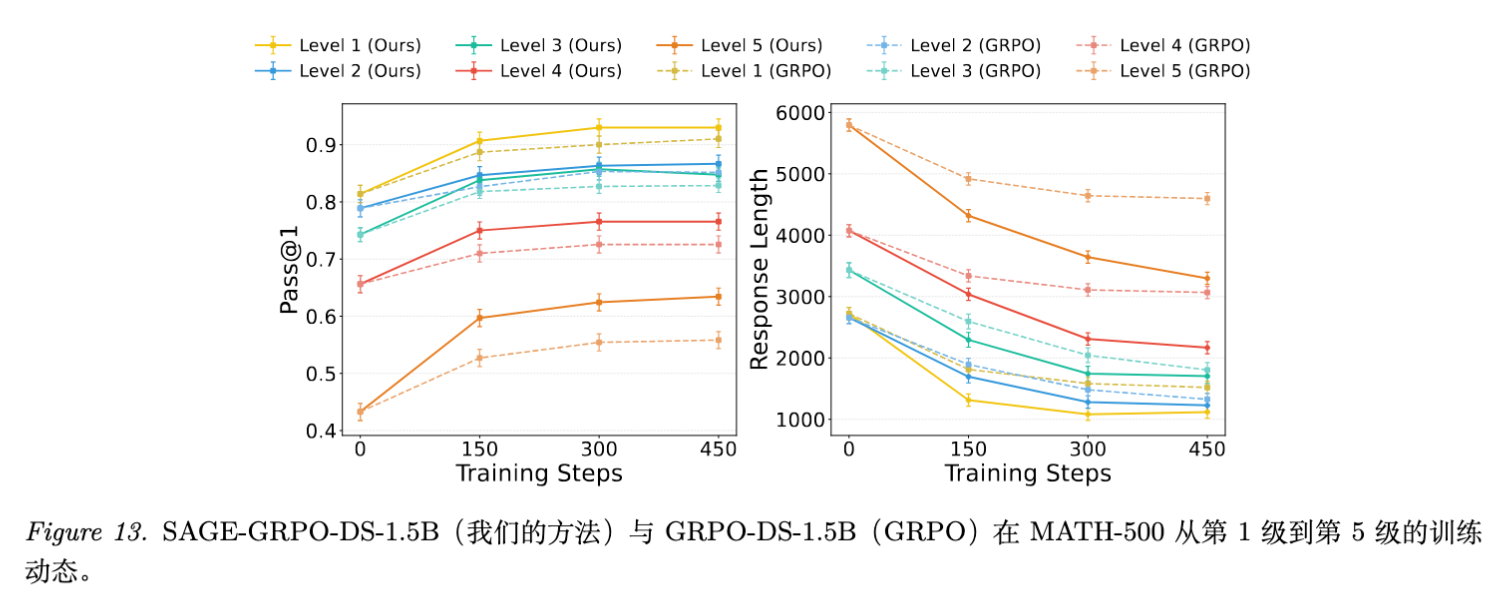
6.4 难度与效果的关系
一个有趣的发现是 SAGE-RL 在困难任务上的表现尤为突出(图 13)。
-
在简单问题(Level 1-3)上,标准 GRPO 和 SAGE-RL 表现差异不大,因为模型本身就不太需要复杂的探索。 -
在困难问题(Level 4-5)上,SAGE-RL 的优势显著拉大。这说明过度思考现象在处理难题时尤为严重,而 SAGE 正好纠正了这一点。
7. 讨论
7.1 为什么不做离线蒸馏?
读者可能会问,既然 SAGE 能生成高质量样本,为什么不直接把这些样本存下来,做 Supervised Fine-Tuning (SFT)?
作者在附录 B 中给出了回应:
-
上限限制:SFT 往往受限于教师数据的质量。如果仅使用模型自己生成的 SAGE 样本做 SFT,可能会导致模型能力过早收敛,无法探索出超出当前 SAGE 搜索范围的更优解。 -
RL 的泛化性:RLVR 允许模型通过 Trial and Error 学习。SAGE 只是提供了好的“种子”,RL 过程能让模型在这些种子的基础上进一步优化概率分布,不仅学会“走这条路”,还学会“为什么走这条路好”。
7.2 SAGE-RL 的计算开销
虽然 SAGE 推理时的计算量是标准推理的 倍,但在 SAGE-RL 训练中,SAGE 采样只占 Rollout 的一小部分(例如 个样本中只用 2 个 SAGE 样本)。
此外,SAGE 生成的样本通常更短,这意味着后续的梯度计算和 Forward Pass 更快。
综合来看,SAGE-RL 的训练时间成本与标准 RLVR 相当,甚至略低(因为平均序列长度变短了)。
7.3 时间与空间的权衡
在推理阶段应用纯 SAGE 算法时,涉及到 vLLM 的显存管理问题。SAGE 需要并行维护多个 KV Cache,这增加了显存占用。但在 SAGE-RL 训练后的模型,在标准推理模式下即可获得性能提升,完全没有额外的推理时显存开销。这就是将 Test-time Compute 转化为 Training-time Optimization 的价值。
更多细节请阅读原文。
往期文章:


