
-
论文标题:AgentOCR: Reimagining Agent History via Optical Self-Compression -
论文链接:https://arxiv.org/pdf/2601.04786
TL;DR
今天解读一篇由南洋理工大学和阿里巴巴通义实验室联合提出的论文 "AgentOCR: Reimagining Agent History via Optical Self-Compression" 。该研究针对大语言模型(LLM)智能体在多轮交互中面临的长上下文处理难题,提出了一种基于视觉模态的解决方案——AgentOCR。该框架的核心思想是将智能体的交互历史(观察和动作)渲染为图像,利用视觉标记(Visual Tokens)相较于文本标记更高的信息密度来实现上下文压缩。
为解决长序列渲染的效率问题,论文提出了分段光学缓存(Segment Optical Caching)机制,通过哈希匹配复用已渲染片段,显著降低了渲染开销。此外,为了平衡信息损失与压缩率,作者引入了智能体自压缩(Agentic Self-Compression)机制,允许智能体通过强化学习(RL)动态调整压缩率。实验结果表明,在 ALFWorld 和 Search-based QA 等基准测试中,AgentOCR 在保留超过 95% 的文本基线性能的同时,减少了超过 50% 的 Token 消耗(峰值减少可达 80%),并保持了较低的内存和计算开销。
1. 引言
1.1 大模型智能体的上下文瓶颈
随着大语言模型(LLM)能力的提升,基于 LLM 的智能体系统(Agentic Systems)在感知、推理和行动方面取得了显著进展。当前的趋势是通过强化学习(RL)在多轮交互轨迹上微调智能体,以优化工具使用、规划和控制策略。
然而,RL 训练和长周期推理面临着严峻的长上下文处理(Long-Context Processing)挑战。在多轮决策循环中,智能体必须维护一个包含过去所有观察(Observations)和动作(Actions)的完整轨迹。这种历史数据会随着交互步数的增加而线性甚至超线性积累,导致输入上下文迅速膨胀。
具体而言,上下文膨胀带来了以下问题:
-
Token 预算耗尽:超过了当前 LLM 的最大上下文窗口限制。 -
推理延迟与计算成本:Transformer 架构中的 Attention 计算复杂度与序列长度呈二次方关系,且 KV-Cache 的管理占据了大量显存。在强化学习训练(如 PPO 或 GRPO)中,需要在整个轨迹上计算梯度,进一步加剧了计算负担。
1.2 现有解决方案及其局限性
目前的解决方法主要包括:
-
稀疏注意力与分层注意力:降低计算复杂度,但可能丢失关键细节。 -
检索增强生成(RAG):将历史存储在外部记忆中按需检索,但检索准确率限制了推理的连贯性。 -
上下文压缩/摘要:通过文本摘要缩短历史,但往往会导致关键状态信息的遗漏。
1.3 视觉信息密度的机遇
近期的研究(如 DeepSeek-OCR 等)表明,视觉模态在信息传递上可能比文本模态更为紧凑。将文本内容渲染为图像后,对应的视觉标记(Visual Tokens)数量往往远少于原始文本标记数量,压缩比可达 10 倍左右。AgentOCR 正是基于这一观察,提出利用视觉模态作为智能体历史的紧凑载体。
2. AgentOCR 方法论
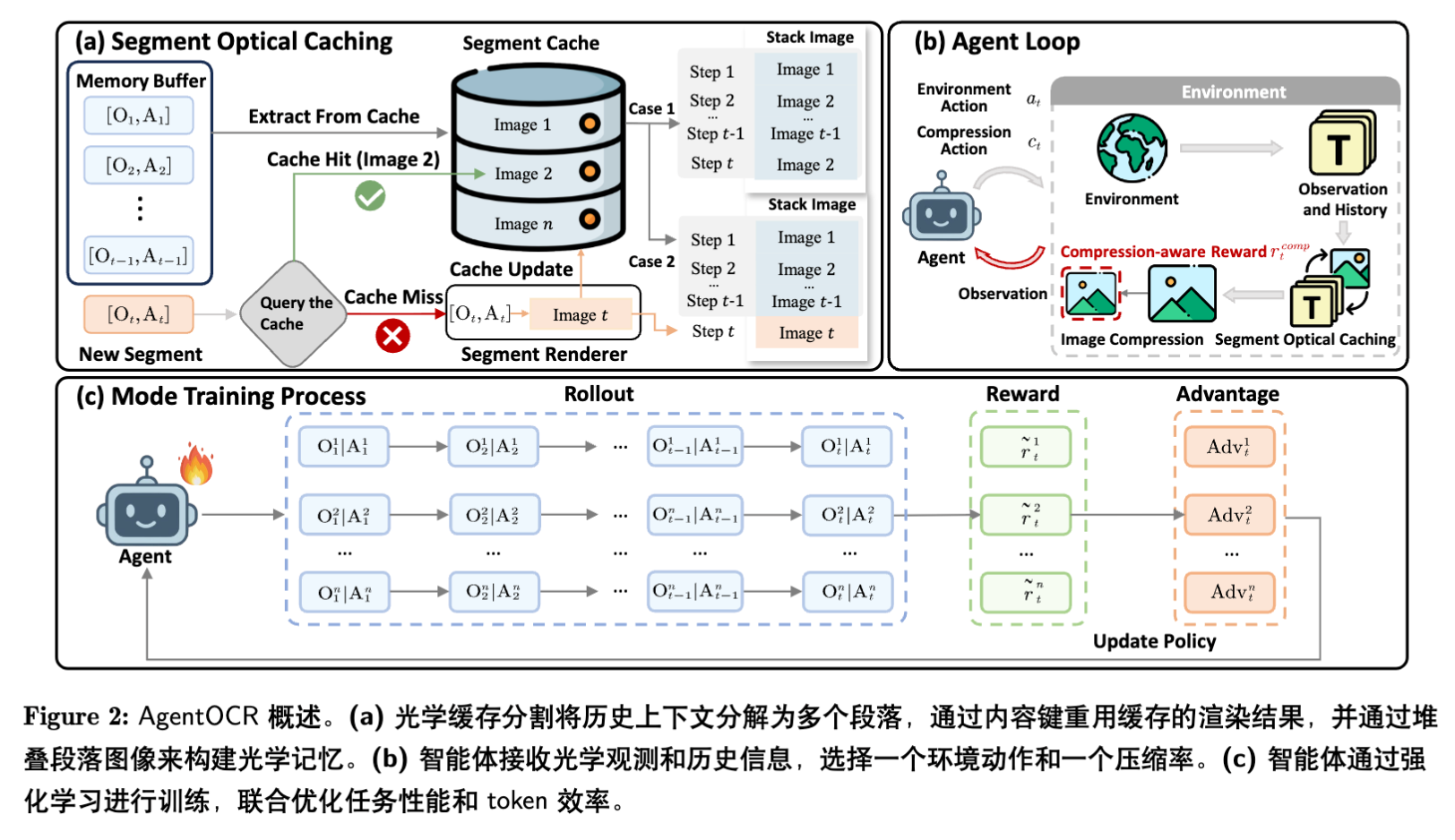
AgentOCR 的核心是将交互历史视为光学记忆(Optical Memory)。该框架并不依赖某种特定的模型架构修改,而是作为一个通用的环境包装器(Wrapper)和策略训练方案。
2.1 问题形式化
将智能体与环境的交互建模为有限视界 内的顺序决策过程。在步骤 ,智能体接收观察 ,其交互历史定义为:
智能体根据指令 和历史 采样动作 。在 AgentOCR 中,历史 被转换为图像 ,策略变为视听觉语言策略(Vision-Language Policy):
2.2 光学记忆编码
AgentOCR 维护一个外部记忆缓冲区 ,存储步骤 之前的交互记录。为了生成光学记忆,系统定义了一个确定性渲染器 ,将文本历史映射为 RGB 图像:
其中 表示渲染超参数(如字体、字号、行距、颜色编码等)。为了辅助模型解析,AgentOCR 采用了语义颜色映射,例如将观察标记为蓝色,动作标记为红色。
2.3 分段光学缓存
如果每一步都从头渲染完整的文本历史 ,将带来巨大的计算浪费和延迟,且图像大小会随时间不断增长。简单的“增量渲染”(即只渲染最新的一步并拼接到旧图上)虽然降低了渲染开销,但无法复用重复出现的文本模式(如重复的工具调用输出)。
为此,AgentOCR 提出了分段光学缓存。
2.3.1 分段表示与哈希
系统将历史上下文 拆分为独立的文本段(Segments)。定义拆分操作 ,通常以换行符为界。
对于每个环境实例 ,维护一个基于内容的缓存字典:
其中 是文本段 的哈希键(包含文本内容及样式元数据), 是该段渲染后的图像切片。
2.3.2 缓存查找与组装
在步骤 ,算法执行以下流程:
-
对当前历史进行拆分:。 -
对每个片段 进行查询: -
命中(Hit):直接从 中获取图像。 -
未命中(Miss):调用渲染器 ,并将结果存入缓存。
-
-
通过垂直堆叠(Stacking)构建完整图像:
2.3.3 复杂度分析
设 为未命中的片段数量。每步的渲染开销仅与 相关。由于智能体交互日志中存在大量重复(如相同的系统提示、重复的工具输出),通常 。这意味着渲染成本被均摊,且缓存空间复杂度取决于唯一片段的数量,而非总步数,避免了显存的冗余占用。
2.4 智能体自压缩
为了进一步减少 Token 数量,AgentOCR 引入了一种主动机制,允许智能体动态控制图像的分辨率。
2.4.1 压缩决策作为工具调用
AgentOCR 将压缩率 视为一个动作参数。智能体在输出环境动作的同时,生成一个结构化的标签:
<compression> </compression>
其中 。系统接收到此参数后,在渲染下一帧图像 时执行降采样:
这里 的缩放因子使得图像面积(即像素总数,进而近似对应 Visual Tokens 数量)减少约 倍。
2.4.2 压缩感知奖励
为了训练智能体合理使用压缩(即在不影响任务成功率的前提下尽可能压缩),引入了额外的奖励项。该奖励严格以任务成功为前提,防止智能体为了高奖励而过度压缩导致任务失败。
定义 为轨迹成功指示函数。步骤 的压缩奖励为:
对数函数 反映了信息密度的边际收益递减。
总奖励函数为:
其中 是权重系数。
稀疏奖励注入策略:如果在每一步都施加压缩奖励,智能体容易陷入贪婪策略(过度压缩)。作者采用了间歇性强化计划(Intermittent Reinforcement Schedule),仅在每 个训练迭代间隔注入压缩奖励。这使得智能体能够学习在关键推理步骤保持高分辨率,而在信息冗余步骤进行高压缩。
2.5 强化学习训练
论文采用 GRPO (Group Relative Policy Optimization) 算法进行训练。对于每个输入,采样一组轨迹 ,并通过组内归一化计算优势函数 。目标函数为:
其中 是重要性采样比率。由于 AgentOCR 使用压缩后的视觉历史 替代长文本 ,该目标函数的梯度计算和前向传播效率得到了显著提升。
3. 实验设置
3.1 基准测试 (Benchmarks)
实验选取了两个具有代表性的多轮交互基准:
-
ALFWorld:
-
类型:具身智能(Embodied AI)任务。 -
特点:涉及家庭场景下的物体操作(如 Pick & Place, Clean, Heat)。上下文随着探索和操作步骤线性增长。 -
任务数:3,827 个任务。
-
-
Search-based QA (Search-R1) :
-
类型:搜索增强问答。 -
特点:包含单跳(Single-hop)和多跳(Multi-hop)问答(如 HotpotQA, 2Wiki)。 -
难点:涉及大量文本密集的网页搜索结果,要求智能体从检索到的网页片段中提取知识。这不仅测试长期记忆,还测试 OCR 对密集文本的识别能力。
-
3.2 基线模型 (Baselines)
对比了以下几种设置:
-
Text (w/o RL) :直接输入原始文本历史,无 RL 训练。 -
OCR (w/o RL) :输入渲染后的光学历史,无 RL 训练。 -
Text + GRPO:在原始文本历史上的强 RL 基线。 -
AgentOCR:本文方法,即 OCR 历史 + GRPO + 自压缩。
3.3 训练细节
-
基座模型:Qwen2.5-VL 系列(3B 和 7B 版本)。 -
参数设置:压缩奖励权重 ,奖励注入间隔 。 -
计算资源:ALFWorld 使用 2xH100,Search-QA 使用 4xH100。
4. 实验结果分析
4.1 总体性能与 Token 效率
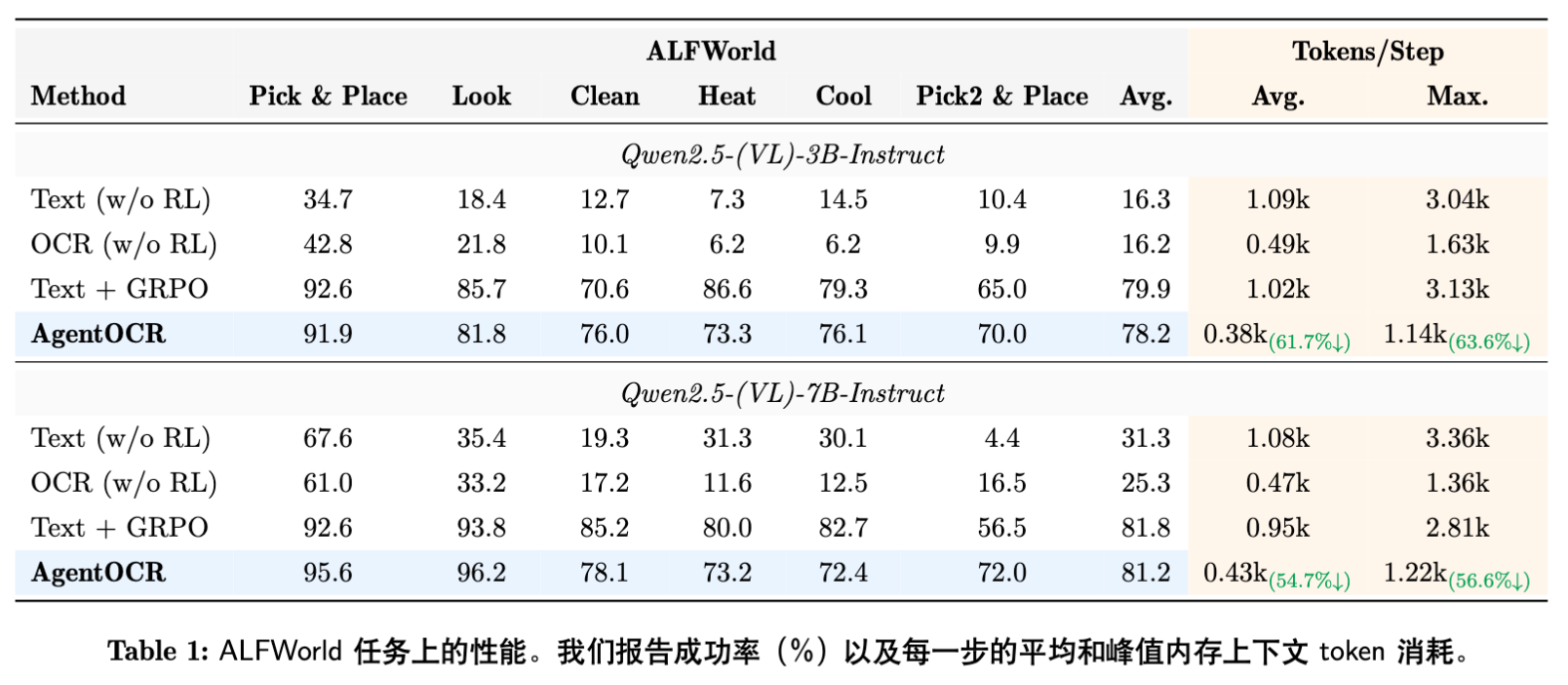

核心发现:
-
Token 消耗大幅降低:
-
在 ALFWorld 上,AgentOCR 相比 Text 基线减少了约 61.7% (3B) 和 54.7% (7B) 的平均 Token 消耗。 -
在 Search-based QA 上,减少了 57.4% (3B) 和 50.7% (7B) 的消耗。 -
峰值 Token 节省更为显著,最高达到 80.9%,这对于缓解显存 OOM(Out Of Memory)至关重要。
-
-
性能保持(Performance Preservation):
-
Inference-only (OCR w/o RL) :直接使用 OCR 模式会导致性能大幅下降(例如 ALFWorld 上从 67.6% 降至 61.0%),这说明现成的 VLM 并不完全适应这种密集的视觉历史表示。 -
经过 RL 训练后:AgentOCR 弥补了这一差距。在 ALFWorld 上,AgentOCR (7B) 达到了 81.2% 的成功率,与 Text+GRPO (81.8%) 仅差 0.6%。 -
在更难的 Search-QA 任务中,AgentOCR (7B) 达到了 40.1%,保留了 Text+GRPO (41.9%) 95% 以上的性能。
-
这证明了通过 RL 对齐,VLM 能够学会在高压缩比的视觉历史中进行有效推理。
4.2 视觉-文本压缩分析
为了探究压缩率 对性能的影响,作者进行了静态压缩系数的实验。
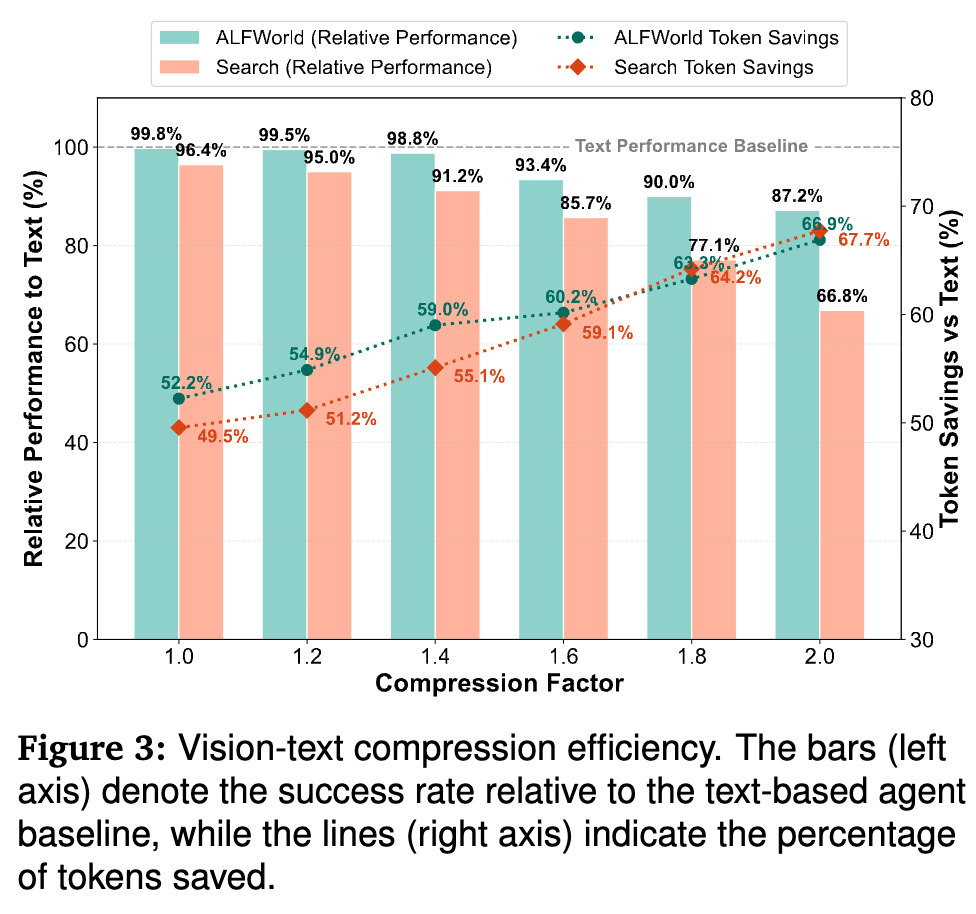
非线性权衡(Non-linear Trade-off):
-
在 区间内,存在一个“鲁棒压缩区”,模型能保持 >95% 的性能,同时节省约 55% 的 Token。 -
超过阈值后,性能开始陡峭下降。 -
任务敏感性:ALFWorld 对高压缩率更具鲁棒性( 时仍保留 87.2% 性能),因为其任务依赖粗粒度的场景理解。相反,Search-QA 对文本清晰度极度敏感,高压缩会导致文本模糊,性能暴跌至 66.8%。这凸显了自适应压缩的必要性——在不需要精细阅读时压缩,在关键信息检索时保持高分辨率。
4.3 缓存机制的效率

-
渲染速度:Segment Optical Caching 实现了 20.79倍 的渲染加速。平均渲染时间从 3509ms 降至 168ms。 -
时间增长率:No Cache 的渲染时间随步数线性增长(+115ms/step),而 Segment Cache 甚至出现了负增长(-1.23ms/step),这是因为随着缓存“预热”,缓存命中率提高,需要新渲染的片段变少。 -
内存占用:相比 Naive Cache(不断拼接大图),Segment Cache 节省了 26.82% 的峰值内存,因为它只存储唯一的文本段图像,去除了重复内容的存储。
4.4 自压缩机制的消融
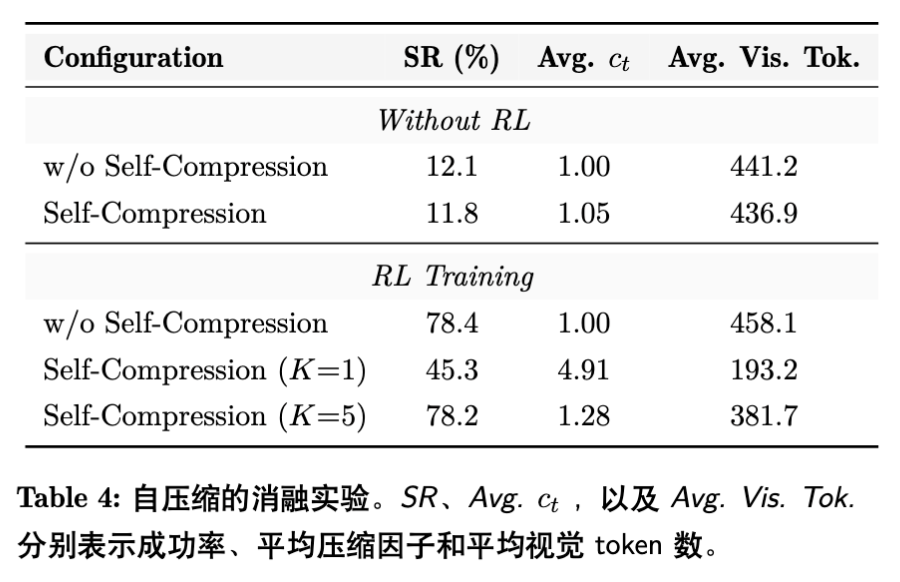
-
无 RL:模型无法理解压缩指令,性能极差。 -
RL + 密集奖励 () :模型为了贪图压缩奖励,将 推高至 4.91,导致图像不可读,任务成功率崩塌至 45.3%。 -
RL + 稀疏奖励 () :模型学会了权衡,平均压缩因子稳定在 1.28,成功率恢复至 78.2%,且平均 Token 数进一步从 458 降至 381。
6. 局限性与讨论
尽管 AgentOCR 表现优异,但论文也诚恳地讨论了局限性,这对于后续研究者具有重要参考价值:
-
VLM 依赖性:当前方法依赖通用的 VLM(如 Qwen2.5-VL)。这些模型并非专为超长文档 OCR 或特定压缩策略设计。未来如果使用专门针对 OCR 优化的视觉编码器(如 DeepSeek-OCR 提到的架构),可能会有更高的压缩上限。 -
渲染器敏感性:目前的渲染参数(字体、字号)是固定的。虽然实验中表现稳定,但非最优的排版可能影响信息读取。 -
多模态历史的扩展:目前的“光学历史”主要是将“文本”渲染成图。但实际智能体场景中可能包含原生图像(如 GUI 截图、图表)。如何混合处理“渲染的文本图”和“原生环境图”,是未来的一个研究方向。 -
通用性边界:对于极度依赖精确字符匹配的任务(如代码生成、数学公式推导),视觉压缩带来的模糊可能比自然语言任务更致命。这部分边界需要进一步探索。
7. 总结
AgentOCR 是一项扎实且具有启发性的工作,它不仅是简单的“Text-to-Image”转换,而是通过系统工程(分段缓存)和算法设计(自适应压缩 RL),构建了一套完整的视觉化智能体记忆方案。
其核心贡献在于验证了一个反直觉的假设:对于大模型而言,阅读压缩后的图像比阅读原始文本更高效(Token 层面),且在强化学习微调后,性能几乎无损。
更多细节请阅读原文。
往期文章:


