前言:当LLM遇见强化学习,是火花还是陷阱?
近年来,大型语言模型(LLM)与强化学习(RL)的结合,特别是以人类反馈强化学习(RLHF)为代表的技术,已成为推动AI发展的重要引擎。我们见证了它在提升模型对话质量、遵循指令能力以及与人类价值观对齐方面的巨大成功。然而,在这条看似充满希望的技术路径之下,一个深刻且棘手的问题逐渐浮出水面——探索问题。
强化学习的核心在于通过“试错”来学习,即智能体(Agent)在与环境的交互中探索不同的行为并根据获得的奖励来优化自身策略。这个过程天然地需要在“探索”(Exploration)和“利用”(Exploitation)之间做出权衡。“利用”是指执行当前已知的最优策略以获取最大化奖励,而“探索”则是尝试新的、未知的行为,以期发现可能带来更高回报的策略。
在将RL应用于LLM时,这个经典的“探索-利用”困境变得尤为严峻。LLM的动作空间——即所有可能的词元序列——是离散且极其巨大的,这使得有效的探索成为一项艰巨的挑战。近期的研究和实践表明,许多基于策略梯度的RL算法在训练LLM时,会系统性地出现一种被称为“方差坍塌”(Variance Collapse)的现象,进而导致“探索失效”,最终使得模型陷入局部最优,难以实现其真正的潜力。
1. 策略梯度
要理解探索问题的根源,我们必须首先回到驱动RL算法的核心引擎——策略梯度方法(Policy Gradient Methods)上。 [2, 7] 简单来说,策略梯度方法直接对策略本身进行优化。 [1, 3] 在LLM的场景下,“策略”就是一个参数化的函数(通常是Transformer模型),它接收一个输入(prompt),然后输出一个关于下一个词元(action)的概率分布 。我们的目标是调整模型的参数 ,以最大化某种形式的累积奖励(例如,生成回答的质量得分)。 [12, 15]
1.1 可微代理模型:用概率分布描述探索
不同于直接寻找一个确定的最优参数 ,策略梯度方法通过优化一个关于参数的概率分布 来进行。在实践中,我们通常选择高斯分布作为这个代理模型:
这个模型中的参数 各有其明确的物理意义:
-
均值 :代表了当前策略的“重心”或“最优信念”。算法会努力将 移动到能够获得更高回报的参数区域。这体现了利用(Exploitation)的倾向。 -
标准差 :代表了探索的“半径”或“多样性”。 越大,意味着策略的采样范围越广,探索性越强;反之, 越小,策略就越集中在均值 附近,表现出更强的“确定性”。这直接体现了探索(Exploration)的强度。
通过这种方式,优化过程从寻找一个“点”变成调整一个“分布”,使得算法能够在参数空间中进行平滑、可控的探索。
1.2 梯度更新的内在机制:奖励信号如何塑造探索行为
那么,算法是如何自动调整这两个核心参数 和 的呢?答案隐藏在策略梯度的数学形式中。对于探索方差 ,其更新的梯度近似可以表示为:
让我们来逐项解析这个看似复杂的公式:
-
:第 次策略采样(即生成一次完整的回答)所获得的回报(Reward)。 -
:回报的基线(Baseline),通常是近期回报的平均值。 这一项被称为“优势”(Advantage),它告诉我们本次采样的结果是比平均水平好(为正)还是差(为负)。 -
:从标准正态分布 中采样的噪声。这个噪声在与 结合后,决定了具体的采样点 偏离中心的程度。 的大小直接反映了本次探索的“激进”程度。 -
:这是一个关键的“信号项”,它决定了梯度更新的方向。
这个公式揭示了这类算法一个与生俱来的内在机制:算法天生就倾向于在无法探索时缩小探索范围。
二、 “方差坍塌”:当探索的火焰逐渐熄灭
现在,我们来分析当这个优化过程陷入一个局部最优解时会发生什么。这种情况在复杂的LLM优化任务中极为常见。
2.1 陷入局部最优时的梯度信号分析
当算法在某个局部最优区域附近徘徊时,会产生两种典型的反馈循环,而这两种循环都指向同一个灾难性的结果——减小探索方差 。
-
情况一:在局部最优附近获得正反馈
-
表现:靠近当前策略中心 的采样点(即 较小)更有可能获得较高的回报,因为它们处于已知的“甜点区”。 -
数学分析:此时,优势项 为正。同时,由于 很小,信号项 倾向于为负。两者的乘积为负,这意味着梯度 指向减小 的方向。 -
算法逻辑:“既然当前区域的回报已经很高了,那就没有必要进行不必要的探索了,让我们在这里精耕细作吧。” 算法变得更加“自信”,从而收缩其探索范围,专注于利用当前已知的最优策略。
-
-
情况二:因过度探索而受到惩罚
-
表现:远离当前策略中心 的采样点(即 较大),由于探索到了未知的、可能充满风险的“外部区域”,很可能会进入低回报区。 -
数学分析:此时,优势项 为负。同时,由于 很大,信号项 倾向于为正。两者的乘积依然为负,梯度 同样指向减小 的方向。 -
算法逻辑:“外部区域充满了风险和不确定性,我们应该收缩探索范围,固守已知的安全区。” 算法因为探索失败而变得“保守”,同样选择减小探索力度。
-
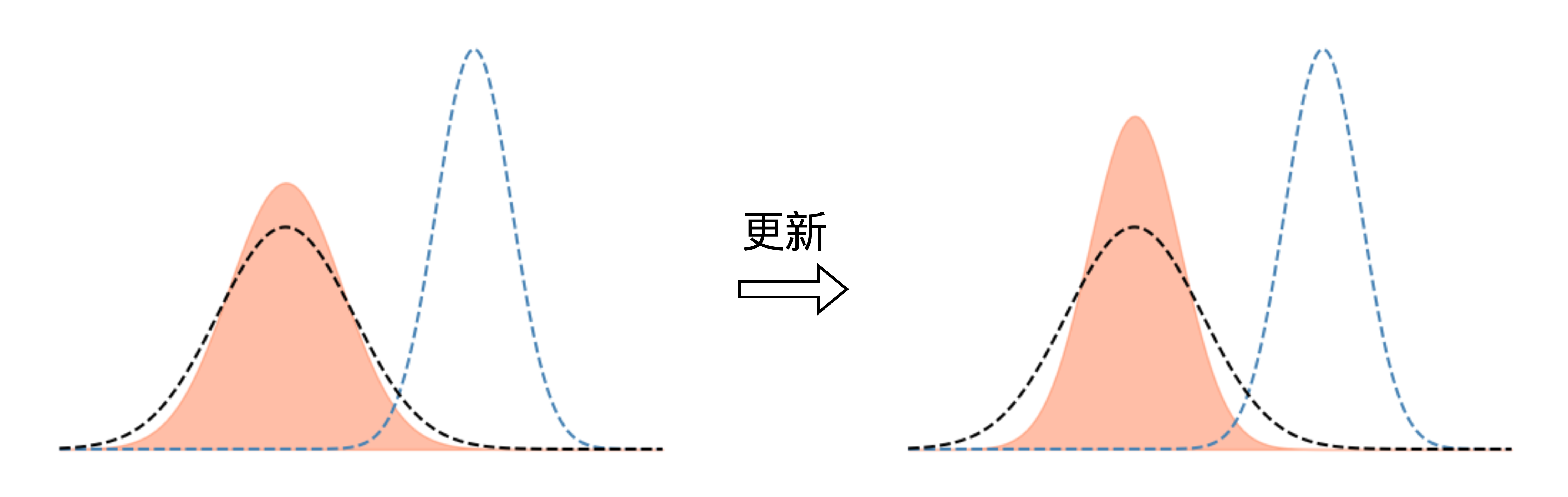
核心结论:无论是探索成功(获得正反馈)还是探索失败(受到惩罚),策略梯度算法的内在机制都会系统性地减小探索方差 。这种现象,我们称之为“方差坍塌”(Variance Collapse)。 [25] 这是一个普遍存在且内在的信号,是导致算法最终陷入局部最优的“帮凶”。 [27]
三、 “方差坍塌”的恶果:从 pass@1 提升到 pass@k 下降
“方差坍塌”并非一个纯粹的理论问题,它会直接体现在LLM的性能评估指标上,造成一系列反直觉的现象。
现象一:方差坍塌
这是最直接的表现。强化学习训练到一定程度后,模型的输出多样性会显著降低。 [26] 无论输入什么,模型都倾向于生成非常相似、固定的回答模式。这是因为探索方差 系统性地减小,导致策略分布牢牢地锁定在了某个局部最优模式上。LLM输出的熵降低、多样性丧失,正是“方差坍塌”最直观的体现。 [28]
现象二:pass@1 提升,但 pass@k 下降
这是一个在代码生成、数学推理等任务中非常典型的现象,也是“方差坍塌”最具迷惑性的后果。
-
pass@1:模型生成一次回答就通过测试的概率。 -
pass@k:模型生成 次不同回答,其中至少有一次通过测试的概率。 [21]
为什么会发生这种现象?
-
pass@1 提升:因为算法找到了一个“比较好”的局部最优解。通过减小探索方差 ,策略分布的均值 被成功地移动到了这个“小山丘”的顶峰。由于策略高度集中,每次采样都极有可能采到这个顶峰附近的点,因此单次成功的概率(pass@1)自然会提升。 -
pass@k 为何下降?:因为方差 已经变得极小。这意味着,即使我们让模型生成 次回答,这 次回答也将高度雷同,都局限在那个“小山丘”的顶峰附近。模型丧失了探索其他可能解空间的能力。如果这个“小山丘”本身不够高(即不是全局最优解),那么这 个大同小异的答案很可能都无法解决问题。因此,在多次尝试中找到一个正确答案的概率(pass@k)反而会下降。
现象三:优化后的 pass@1 未超过基础模型的 pass@k
这个现象揭示了局部最优与全局最优之间的鸿沟。它说明,在探索能力不足的情况下,RL算法会迅速收敛到一个局部最优解,即使这个解的质量(以 pass@1 衡量)还不如未经优化的基础模型通过多次采样(以 pass@k 衡量)所能达到的高度。这进一步印证了探索不足限制了模型性能的上限。
四、 核心问题与解决之道:如何设计更有效的探索机制?
综上所述,LLM+RL中出现的“方差坍塌”等现象,并非RL算法本身的“失效”,而是经典的“探索不足导致陷入局部最优”问题在LLM这一新领域的集中体现。 [15] 相关的现象都只是结果,而非原因。
因此,真正的核心问题在于:如何设计更有效的探索机制,以对抗或缓解策略梯度方法中固有的“方差坍塌”趋势? [5, 6, 8]
学界和业界已经开始积极探索解决方案,主要思路可以分为以下几类:
-
维持策略熵/多样性:
-
熵正则化:在奖励函数中直接加入一个与策略熵成正比的奖励项,鼓励模型保持输出的多样性。这是最直接也较常用的方法,但如何平衡熵奖励与任务奖励是一个挑战。 [25] -
KL散度约束:在每次更新时,限制新策略与旧策略(或初始SFT策略)的KL散度,防止策略漂移过快,从而间接保留了探索的可能性。PPO(Proximal Policy Optimization)算法就是这一思想的典型代表。 [13]
-
-
改进探索策略:
-
参数空间噪声:不仅仅在动作空间进行探索,还可以直接在模型的参数空间(权重)中注入噪声,这有时能带来更有效和一致的探索效果。 -
内在好奇心驱动(Intrinsic Curiosity Motivation):除了任务本身提供的外部奖励(Extrinsic Reward),还可以设计一种内部奖励(Intrinsic Reward),用于鼓励模型探索新的、不确定的状态。例如,模型可以根据其对下一个状态的预测误差来奖励自己,预测越不准,说明状态越新奇,奖励就越高。
-
-
分层与层级化探索:
-
分层强化学习(Hierarchical RL):将复杂的任务分解为高层次的“目标设定”和低层次的“目标执行”。高层策略负责在抽象的目标空间中进行探索,而低层策略则学习如何实现这些具体目标。这可以极大地简化探索的难度。 -
利用LLM进行高级规划:利用LLM自身的规划和推理能力来指导探索过程。例如,可以先让LLM生成一个解决问题的计划(子目标序列),然后用RL来学习如何执行这个计划中的每一步。 [9, 29]
-
-
改变动作空间:
-
从词元到动作原语:一个极具启发性的思路是改变LLM的动作空间。传统的词元级别动作空间粒度太细,探索效率低下。ICML'25的一篇前瞻性工作中提到,可以将LLM的动作空间从10万维的词元空间压缩到仅64个“动作原语”(Action Primitives)的潜在空间中。 [4] 在这个低维、更具语义的潜在空间中进行探索,效率有望得到指数级的提升。 [18, 24] 这种方法将探索的重点从“如何说”转向了“做什么”,可能是未来一个重要的突破方向。 [19]
-
-
回顾式重放(Retrospective Replay):
-
有研究发现,在训练早期,模型虽然能力有限但探索性强,可能会发现一些有潜力的解题思路,但因为能力不足而无法完成。 [5] 随着训练进行,这些早期发现的“火花”可能被策略梯度所抑制。一种名为“回顾式重放”的算法(RRL)提出,通过一个动态重放机制,让模型能够重新审视和探索这些早期发现的有价值的状态,从而提高探索的效率和效果。 [5]
-
结论:探索是通往更强AI的必由之路
强化学习与大型语言模型的结合为我们打开了通往更通用、更强大人工智能的大门。然而,正如我们在本文中深入剖析的那样,“探索失效”和其背后的“方差坍塌”机制,是横亘在这条道路上的一块巨石。它警示我们,简单地应用传统RL算法,很可能只会让我们在“局部最优”的泥潭中打转。
理解这一问题的本质——即探索与利用的永恒博弈——是设计下一代LLM+RL算法的关键。未来的研究需要在维持策略多样性、设计更智能的探索策略、甚至重构LLM的动作空间等方向上取得突破。只有解决了探索这个核心难题,我们才能真正释放出强化学习的全部潜力,驱动LLM从一个“博闻强识”的语言模型,进化为一个真正具备持续自我学习和推理能力的智能体。


