大型语言模型 (LLM) 的后训练 (Post-training) 通常依赖于两种主流范式:监督微调 (Supervised Fine-Tuning, SFT) 和强化学习 (Reinforcement Learning, RL)。SFT 主要通过模仿高质量的专家数据来学习,而 RL 则通过与环境的交互和反馈进行探索性学习。将两者结合的传统做法——先进行 SFT 再进行 RL (SFT-then-RL)——虽然直观,但在实践中常常表现不佳,甚至不如单纯的 RL。其根本原因在于,来自外部专家的“离策略 (off-policy)”数据可能会严重干扰模型在 SFT 阶段已经建立的内部模式,导致模型性能下降,并可能在后续的 RL 阶段陷入过拟合。
为了解决这一难题,来自阿里巴巴的研究团队发表了一篇题为《On-Policy RL Meets Off-Policy Experts: Harmonizing Supervised Fine-Tuning and Reinforcement Learning via Dynamic Weighting》的论文。

-
论文标题:On-Policy RL Meets Off-Policy Experts: Harmonizing Supervised Fine-Tuning and Reinforcement Learning via Dynamic Weighting -
论文链接:https://arxiv.org/pdf/2508.11408
该论文从一个全新的视角——“离策略 vs. 在策略 (off-policy vs. on-policy)”——审视了 SFT 与 RL 的关系,并提出了一个名为 CHORD (Controllable Harmonization of On- and Off-Policy Reinforcement Learning via Dynamic Weighting) 的创新框架。CHORD 框架不再将 SFT 视为一个独立的预处理阶段,而是将其重新定义为在策略 RL 过程中的一个动态加权的辅助目标。
该框架的核心是一个双重控制机制:
-
全局系数 (Global Coefficient) :该系数从整体上调控专家数据(离策略)的影响力,引导模型从初期的模仿学习平滑地过渡到后期的探索性学习(在策略)。 -
逐词权重函数 (Token-wise Weighting Function) :该函数在更细粒度的层面上对专家数据进行学习,通过降低对模型现有模式干扰较大的词元 (token) 的权重,来维持学习过程的稳定性,同时保留模型自身的探索能力。
通过这种动态加权的和谐机制,CHORD 能够在有效吸收专家知识的同时,避免破坏模型原有的推理能力,从而在多个基准测试中显著超越了传统的 SFT-then-RL 范式和其他基线方法,实现了更稳定、高效的学习过程。
1. 引言
大型语言模型 (LLM) 在数学推理、代码生成、工具使用等领域取得了显著的进展。这些成就的背后,离不开两个关键的后训练技术:监督微调 (SFT) 和强化学习 (RL)。
-
监督微调 (SFT) :SFT 依赖于高质量的专家示例数据,通过模仿学习的方式来塑造模型的行为模式。它的优点是直接、有效,能够快速让模型掌握特定的技能。但其缺点也同样明显:
-
数据依赖性:SFT 的效果高度依赖于专家数据的质量和数量。 -
泛化能力有限:可能导致模型只会“背诵”而无法真正泛化。 -
暴露偏差 (Exposure Bias) :由于训练时只接触“正确答案”,模型在自主生成时可能会因遇到未见过的中间状态而偏离轨道。
-
-
强化学习 (RL) :与 SFT 不同,RL 鼓励模型主动探索,通过环境的直接反馈(奖励信号)来学习和优化策略,从而发现可能比专家更优的解决方案。这使得 RL 在泛化能力上通常优于 SFT。然而,RL 的探索过程可能是低效的,甚至会带来风险:
-
策略退化 (Policy Degradation) :模型可能会因为熵坍塌 (entropy collapse) 或对次优策略的过度利用而导致性能下降。
-
为了结合两者的优点并规避各自的缺点,业界最常用也最直接的方法就是 “先 SFT,后 RL” (SFT-then-RL) 的序列化范式。这种方法的初衷很美好:SFT 为 RL 提供一个良好的起点和有效的探索先验,帮助其跳出局部最优;而 RL 的在策略学习机制则可以缓解 SFT 带来的暴露偏差和对静态数据的过拟合。
然而,理想很丰满,现实很骨感。大量的实证研究,包括本文的实验(如下图所示),都表明 SFT-then-RL 范式并不总能胜过单纯的 RL 方法,有时甚至会产生负面效果。这引出了一个核心问题:为什么简单的“SFT+RL”组合拳打不出预期的效果?
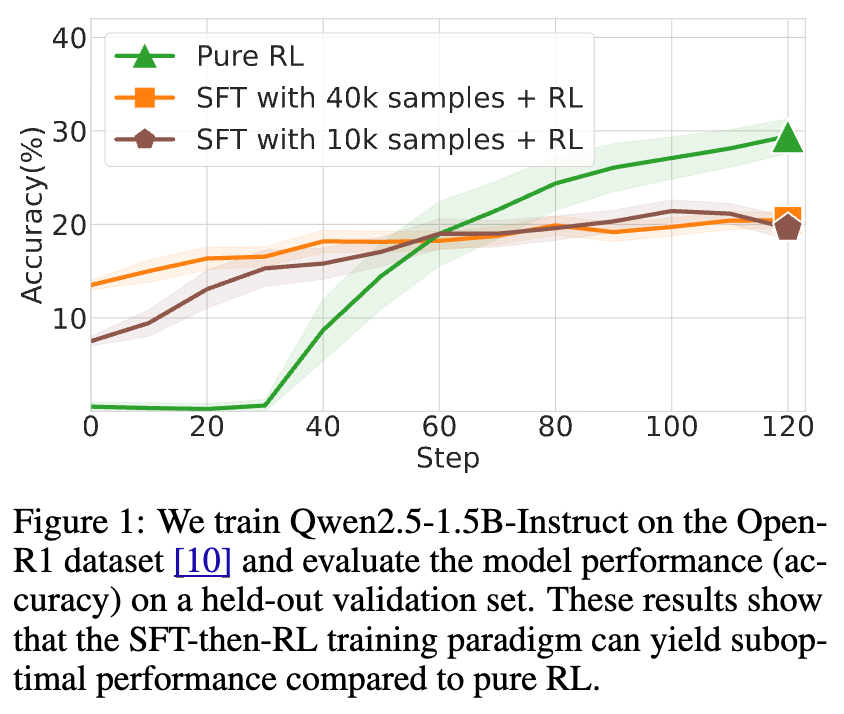
上图展示了在 Open-R1 数据集上训练 Qwen2.5-1.5B-Instruct 模型的结果。可以清晰地看到,无论是使用 10k 还是 40k 样本进行 SFT 后再进行 RL,其最终性能(准确率)都劣于直接使用纯 RL 进行训练的模型。这一现象促使研究者们深入探究其背后的根本原因。
2. 问题剖析
为了探究 SFT-then-RL 范式失败的深层原因,研究团队进行了一项关键实验。他们使用由 Deepseek-R1 模型生成的专家数据对 Qwen2.5-7B-Instruct 模型进行 SFT,并在训练过程中持续评估模型在 MATH-500 数据集上的准确率。学习曲线揭示了一个被称为 “迁移-适应-过拟合” (shift-readapt-overfit) 的三阶段动态过程。
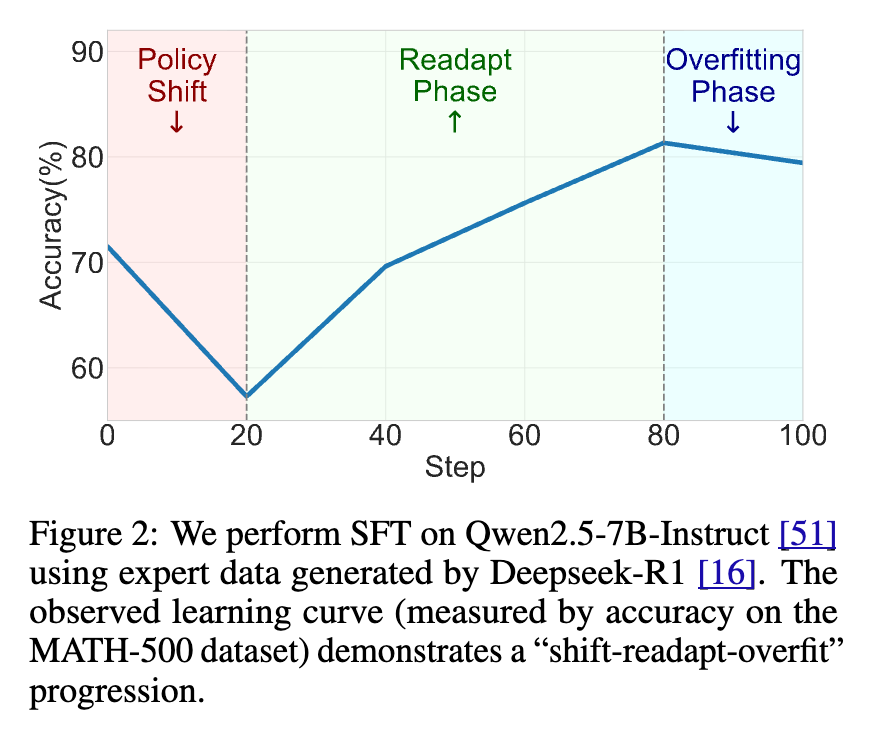
这个过程可以分解为三个 distinct 阶段:
-
迁移阶段 (Shift) :在训练初期,模型性能不升反降。这是因为专家数据(离策略)的推理模式与模型自身已建立的模式存在显著差异。强制模型去拟合这些外部模式会破坏其内部的稳定结构,导致能力暂时性地退化。这个问题在存在暴露偏差的情况下会进一步加剧,因为模型在推理时需要处理自己生成的、与专家数据分布不同的上下文。
-
适应阶段 (Readapt) :随着 SFT 的继续,模型的策略 开始逐渐与专家的模式对齐,能够生成与专家类似的响应。此时,模型性能开始回升,并逐步接近甚至超越初始水平。在这个阶段,模型对自身原有模式的依赖性降低,从而在一定程度上缓解了暴露偏差问题。但与此同时,这也可能抑制了模型进行自我探索的潜力。
-
过拟合阶段 (Overfit) :如果长时间在有限的专家数据上进行训练,模型最终会不可避免地走向过拟合。这不仅会导致模型在未见过的数据上泛化能力下降,还会使其输出的多样性大幅减少。更关键的是,这种过拟合会严重限制模型在后续 RL 阶段进行有效探索的能力。
这个三阶段的动态过程清晰地揭示了 SFT-then-RL 范式的内在脆弱性。简单地将两个阶段分开,使得我们很难精确地控制离策略专家数据的影响,也难以把握从 SFT 转换到 RL 的最佳时机。尤其当专家数据的推理模式与模型原有模式差异巨大时,这种两阶段方法的局限性就更加凸显。
3. CHORD 框架
基于以上洞察,论文提出了一种全新的统一框架——CHORD,旨在将 SFT 和 RL 无缝地融合在一起。CHORD 的核心思想是,将 SFT 重新定义为在策略 RL 过程中的一个动态加权的辅助损失项,而不是一个独立的训练阶段。
为此,CHORD 设计了一个双重控制机制,分别从宏观和微观层面来精细地调控离策略专家数据的影响。
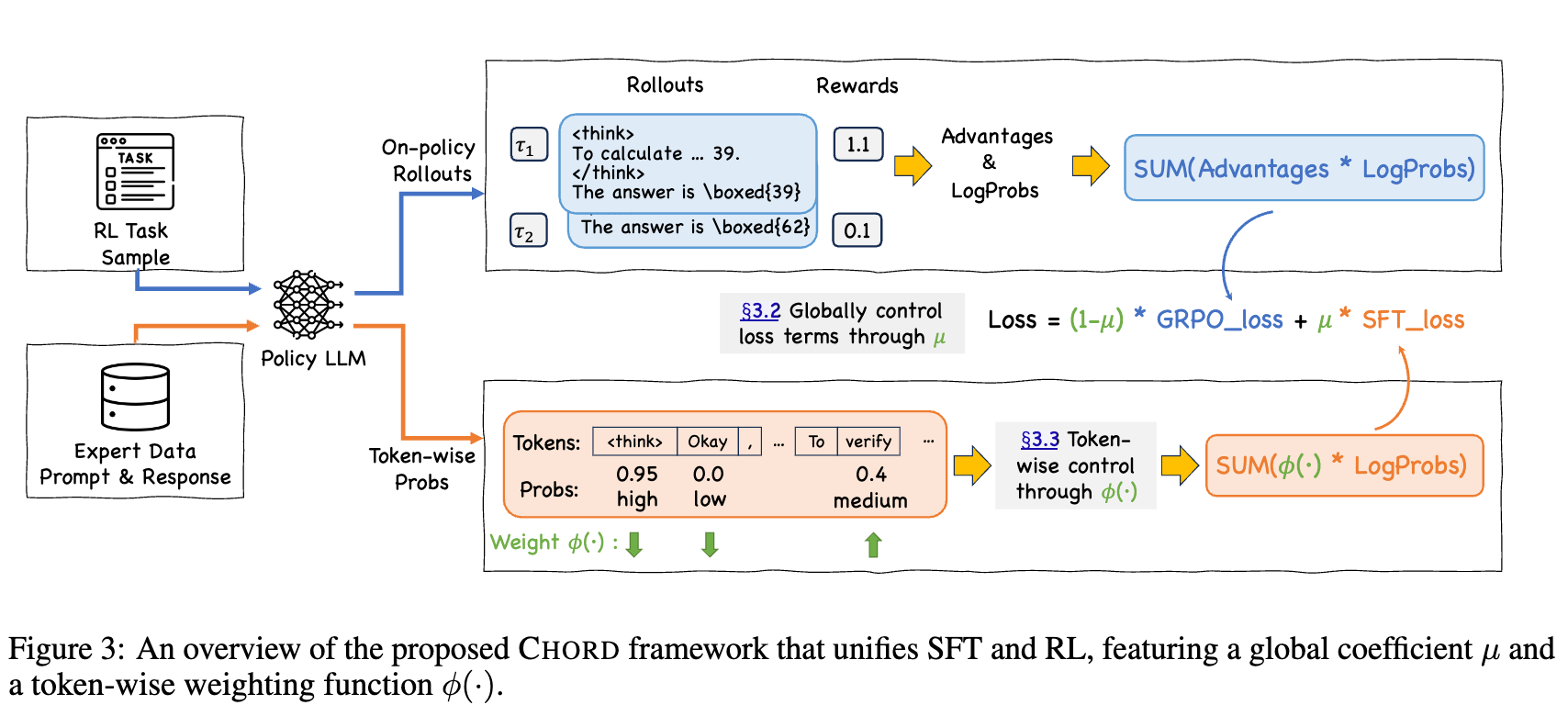
3.1 宏观调控:全局系数
首先,为了从整体上控制专家数据的影响力,CHORD 引入了一个混合损失函数:
其中:
-
是在策略 RL 的损失,这里采用了 Group Relative Policy Optimization (GRPO) 算法的损失函数。GRPO 是一种高效的策略梯度算法,它通过比较一组候选响应的相对好坏来更新策略,而不需要一个独立的价值网络,因此在内存和计算效率上具有优势。其形式化的目标函数如下:
这里的 是重要性采样比率,用于将在旧策略下采样的数据调整为适用于当前策略的更新, 是优势函数,表示当前响应相对于组内平均响应的好坏。
-
是标准的监督微调损失,即最小化专家响应的负对数似然:
-
是一个超参数,用于平衡 RL 损失和 SFT 损失的权重。
与 SFT-then-RL 范式(可以看作是 从 1 突变为 0 的二进制调度)和交错训练(可以看作是周期性的 调度)不同,CHORD 采用了一种平滑衰减的 调度策略。
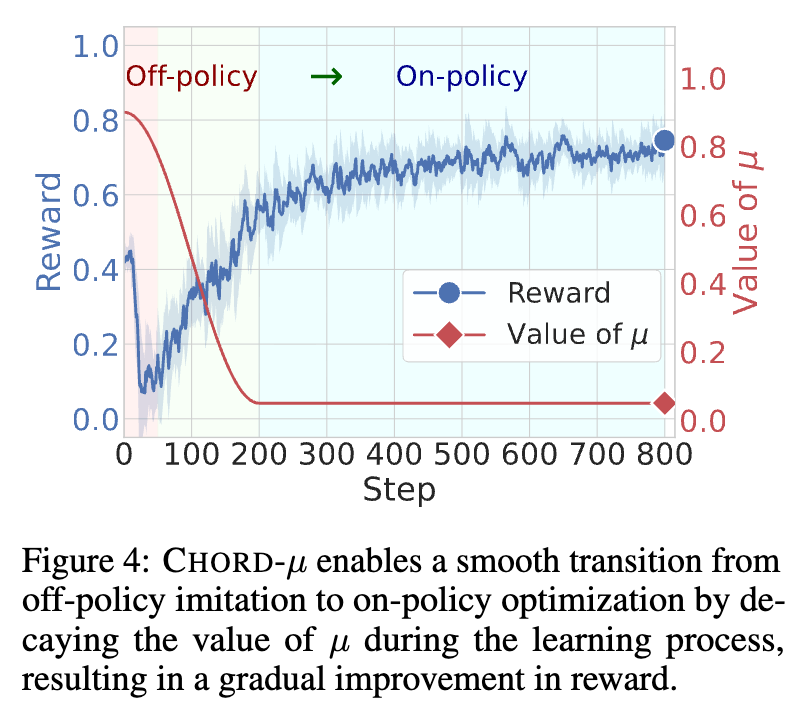
如上图所示,在训练初期, 的值较高,模型被鼓励更多地向离策略的专家数据学习,快速吸收其知识和模式。随着训练的进行, 的值逐渐衰减,训练的重心随之平滑地转移到在策略的 RL 探索上,使得模型能够在吸收专家知识的基础上,进一步探索更优的策略,同时避免对专家数据的过拟合。这种平滑过渡的策略,被证明在缓解暴露偏差方面卓有成效。
然而,仅有全局系数 的调控(在论文中被称为 CHORD-)仍然不够完美。实验表明,尽管 CHORD- 的性能优于 SFT-then-RL,其学习曲线仍然表现出类似“迁移-适应”的模式,即奖励在初期会先下降再上升。同时,模型的行为模式(如响应长度)也趋向于完全模仿专家。这说明,离策略数据在某种程度上仍然在干扰模型的原生模式,并抑制了其自主探索。
为了实现更精细的控制,让模型能够“取其精华,去其糟粕”地学习,而非全盘模仿,CHORD 引入了第二个控制机制。
3.2 微观调控:逐词权重函数
为了从更细的粒度上控制离策略数据的影响,CHORD 提出了一个逐词的权重函数 。这个设计的灵感来源于重要性采样 (Importance Sampling, IS) 的思想。IS 通过词元的生成概率来重新加权损失,旨在稳定离策略数据的学习过程。具体来说,它会降低那些在当前策略下生成概率很低的词元(即与模型当前认知差异巨大的词元)的权重,从而避免这些“异常值”对模型造成过大的冲击。
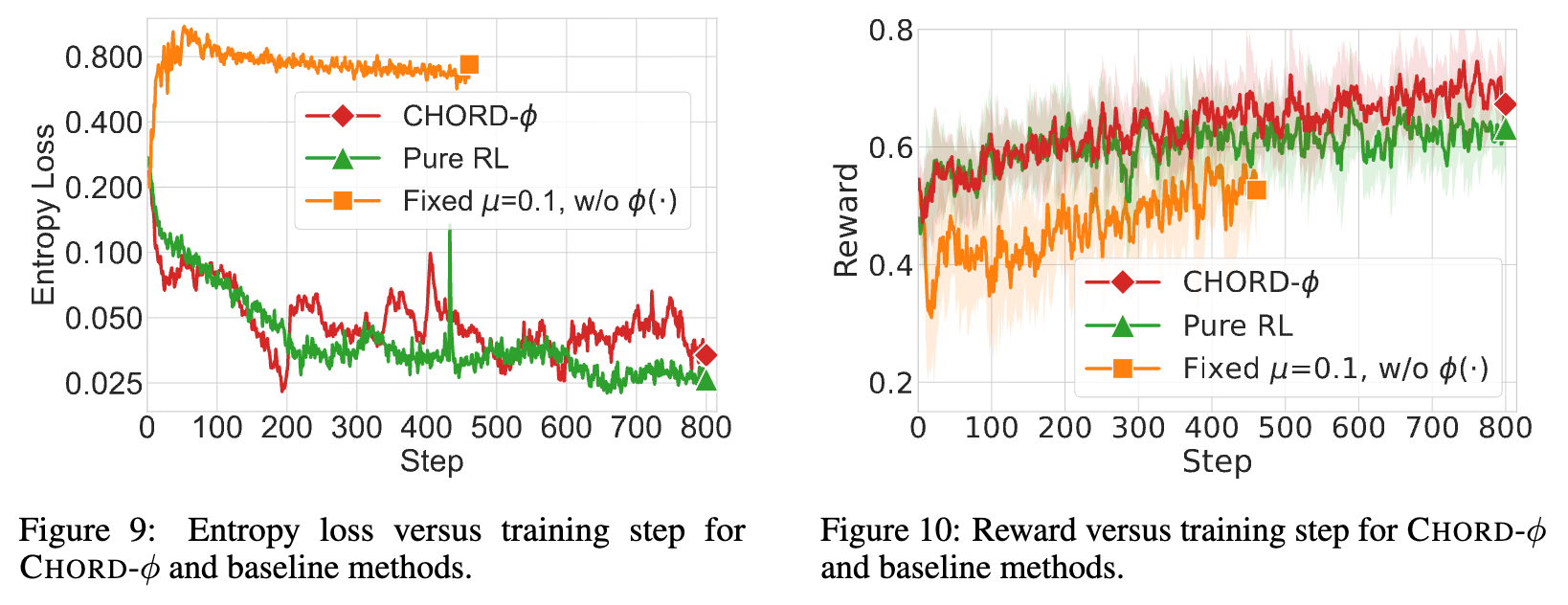
然而,传统的 IS 策略存在一个问题:它在抑制破坏性更新的同时,也可能过度强化模型已有的高概率行为,忽略那些虽然概率较低但可能包含新知识的词元,最终导致策略熵的快速下降,使模型变得过于自信,陷入次优解。
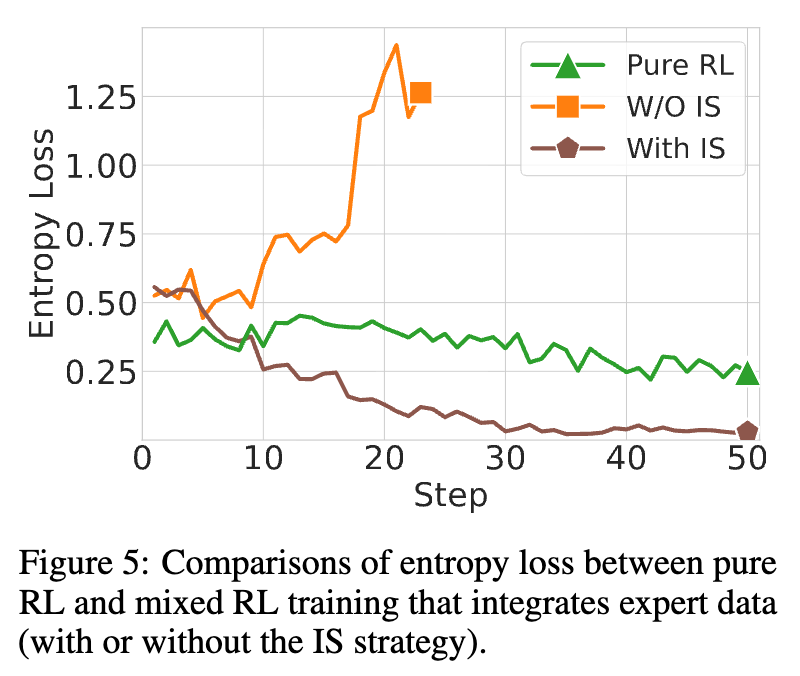
上图对比了纯 RL、混合 RL(无 IS)和混合 RL(有 IS)的策略熵损失。可以看到,混合专家数据(W/O IS)会导致熵急剧上升,表明模型原有模式被迅速破坏。而加入 IS(With IS)虽然稳定了训练,但熵的下降速度比纯 RL 更快,这正是探索能力受限的体现。
为了解决这个问题,CHORD 设计了一种新颖的、非单调的逐词权重函数:
其中, 是模型生成专家词元 的概率。
这个函数是一个开口向下的抛物线,其特性非常巧妙:
-
当 趋近于 0(模型认为这个词元极不可能出现)或趋近于 1(模型已经完全掌握了这个词元)时,权重 都会趋近于 0。 -
当 (模型最不确定时)时,权重达到最大值。
从信息论的角度看, 正是生成词元 这个二元事件的熵,它衡量了模型对于该词元的不确定性。因此,这种加权方式天然地将学习的重点偏向于那些模型最不确定的词元。它创造了一个“学习甜点区” (learning sweet spot):
-
避免干扰:对于模型认为极不可能的词元(),给予低权重,防止其对现有策略造成剧烈冲击。 -
防止冗余:对于模型已经高度自信的词元(),也给予低权重,避免在已经学会的知识上浪费梯度,从而防止熵过快坍塌,保留探索能力。 -
聚焦学习:将主要的学习资源集中在那些对模型来说既新颖(informative)又不过于离谱(not so divergent)的词元上。
最终,CHORD 的 SFT 损失函数被更新为:
将这个新的 替换掉原始的 ,就构成了 CHORD 框架的最终形态(在论文中被称为 CHORD-)。它通过全局系数 和逐词权重函数 的双重控制,实现了对离策略专家数据影响力的全面、动态和细粒度的调控。
4. 实验验证与分析
为了验证 CHORD 框架的有效性,研究团队进行了一系列详尽的实验。
4.1 实验设置
-
模型:主要使用 Qwen2.5-7B-Instruct 模型作为策略模型。选择该模型的原因是其推理模式与提供专家数据的 Deepseek-R1 模型存在显著差异,这能更好地考验框架处理策略分布差异的能力。 -
数据集:实验在 OpenR1-Math-220k 数据集上进行,这是一个包含由 Deepseek-R1 生成的数学问题和解题轨迹的大规模数据集。实验中,采样了 5k 个实例用于 SFT,20k 个实例用于 RL,两者没有交集。 -
评估:模型的能力从两个维度进行评估: -
领域内推理能力:在多个广泛使用的数学基准测试上进行评估,包括 AIME24, AIME25, 和 AMC。 -
通用推理能力:在 MMLU-pro 基准测试上进行评估,以考察模型在后训练过程中通用能力的潜在提升或退化。
-
-
基线方法: -
Original Model:未经任何微调的 Qwen2.5-7B-Instruct。 -
SFT-only:只进行 SFT。分为 SFT-light(单 epoch,低学习率)和SFT-best(经过详尽超参搜索的最优 SFT 模型)。 -
RL-only:只使用 GRPO 进行 RL 训练。 -
SFT+RL:传统的 SFT-then-RL 范式。 -
LUFFY:一种将专家数据混入 RL rollout 组并重塑重要性采样比率的方法。
-
4.2 性能对比
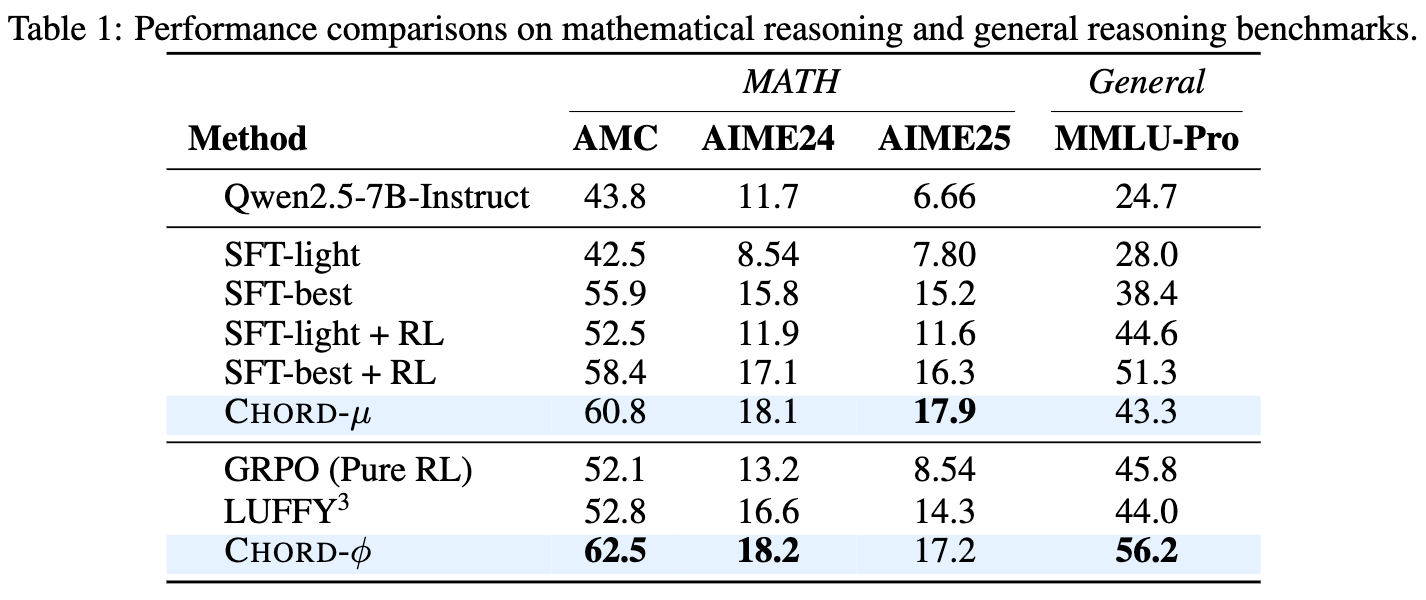
实验结果(如上表所示)清晰地展示了 CHORD 框架的优越性:
-
SFT 的必要性与局限性: SFT-light的性能甚至不如原始模型,这印证了不恰当的 SFT 会损害模型能力。而经过充分优化的SFT-best则表现出强大的性能。这说明 SFT 并非“即插即用”,需要精细调优。 -
SFT+RL vs. CHORD- : SFT-best+RL相比SFT-best有了进一步提升,证明了 RL 阶段的必要性。然而,采用平滑过渡策略的CHORD-μ在所有数学基准上都优于SFT-best+RL,这充分说明了 CHORD 统一框架相比于僵化的两阶段范式的优越性。 -
CHORD- 的全面胜出:集成了双重控制机制的 CHORD-φ在所有评估的基准(包括领域内和通用推理)上都取得了最佳性能,一致性地超越了所有基线方法。这强有力地证明了双重控制机制在灵活调控离策略专家数据影响方面的有效性。CHORD-φ能够有选择性地将 SFT 损失应用于非破坏性的词元,从而在整合专家知识的同时不损害模型的基础能力,实现了离策略专家学习和在策略探索的稳健结合。
4.3 推理模式分析
除了性能指标,研究团队还分析了不同方法训练出的模型的响应长度,以探究它们对推理模式的影响。
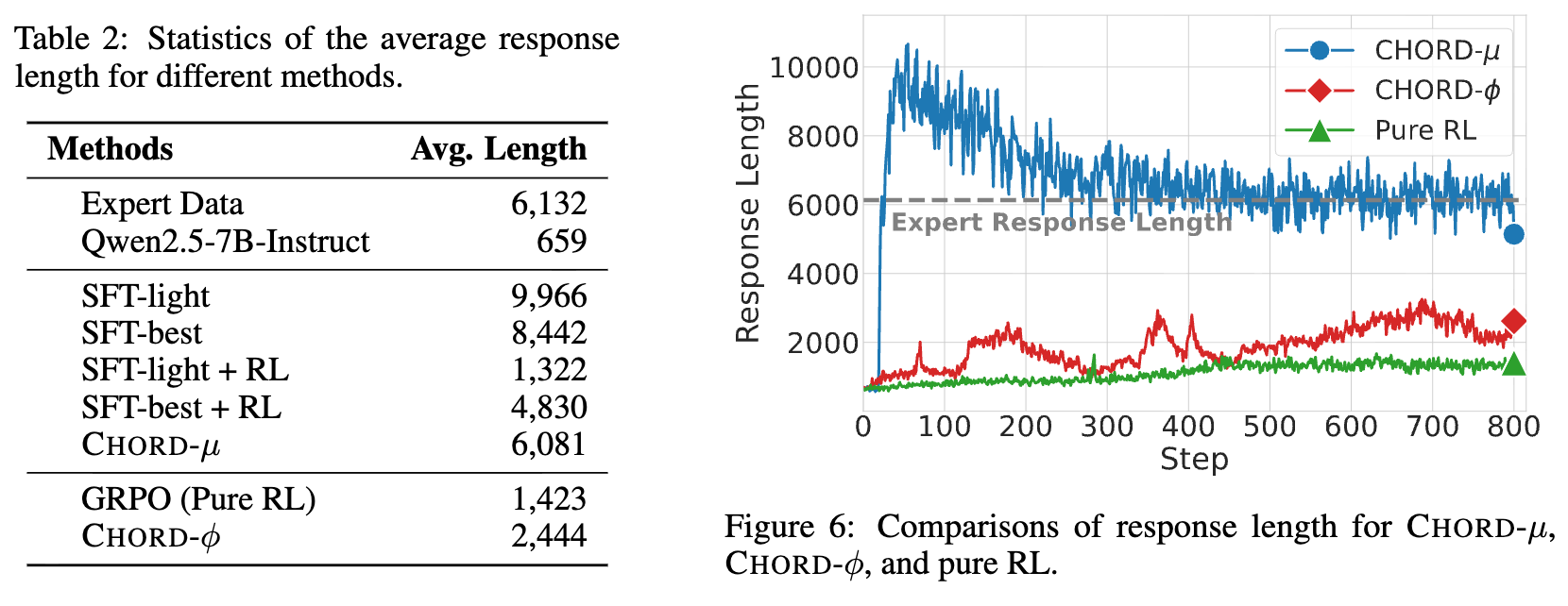
分析发现:
-
专家数据(Expert Data)的平均长度(6132)远大于 Qwen 模型的原始响应长度(659)。 -
经过 SFT 训练后,模型的响应长度显著增加,趋向于模仿专家的“冗长”风格。 -
加入 RL 阶段后 ( SFT-light+RL和SFT-best+RL),响应长度有所缩短,说明 RL 的在策略探索鼓励模型寻找更高效的表达方式。 -
CHORD-μ的响应长度变化趋势与 SFT-then-RL 类似,先增长后回落。 -
CHORD-φ的响应长度则处于 SFT-then-RL 和纯 RL 之间,达到了一种平衡。通过逐词权重的调节,CHORD-φ学会了有选择性地整合专家模式,比如在自身的“思想链”中策略性地加入验证步骤,而不是简单地全盘模仿。这使得它既能生成结构良好、逻辑清晰的响应,又能吸收专家的优秀策略,做到“博采众长,自成一派”。
4.4 消融实验: 和 的作用
-
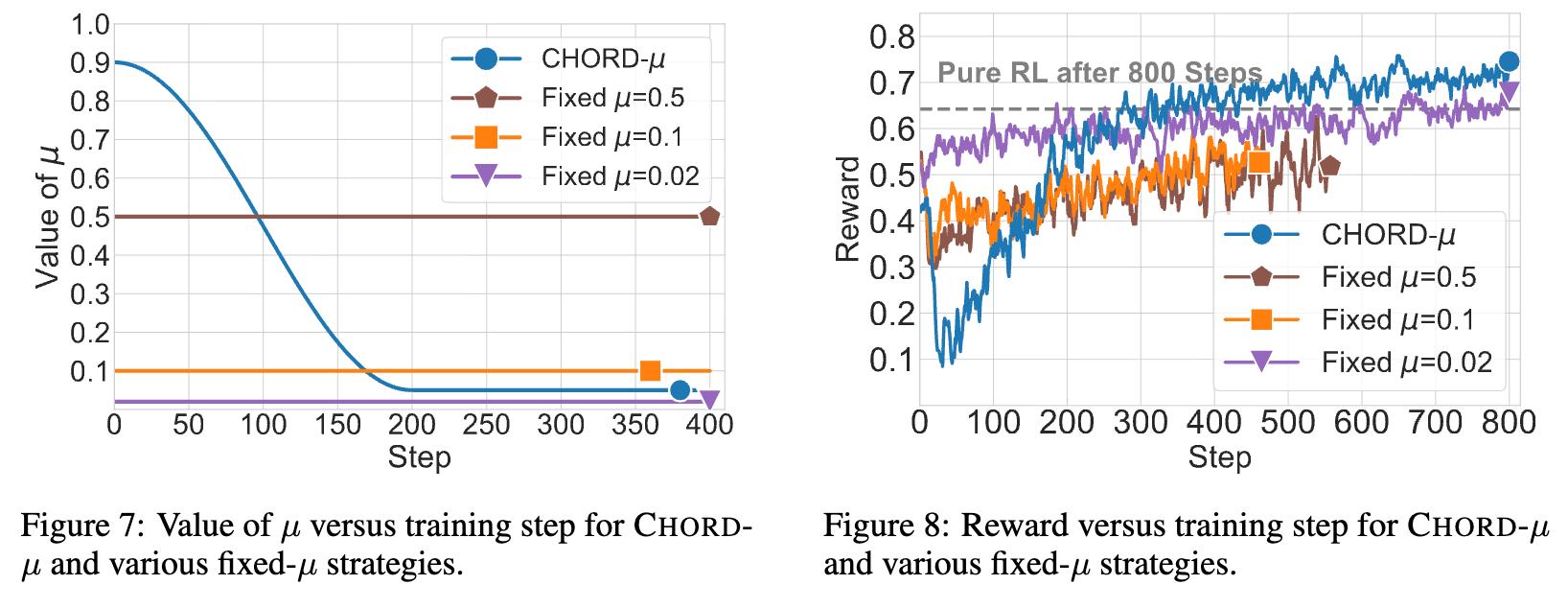
动态 vs. 固定 :实验对比了动态衰减的 调度与多个固定的 值。结果表明,任何固定的 值都无法达到动态调度的性能水平,甚至可能不如纯 RL。这说明静态地混合离策略和在策略学习目标,会让模型在两种可能冲突的推理模式之间“左右为难”,无法收敛到稳定且高性能的状态。动态 的平滑过渡策略则有效地解决了这一冲突。
-
的稳定作用:通过对比有无 函数的训练过程,可以发现 的引入带来了显著的稳定性和性能提升。在熵损失曲线上, CHORD-φ避免了熵的过早坍塌和剧烈波动,维持了探索和利用之间的良好平衡。在奖励曲线上,CHORD-φ实现了稳定持续的增长,最终达到比纯 RL 高得多的水平。这证明了逐词权重函数在有效统一 SFT 和 RL 阶段中的关键作用。
点评
论文最大的亮点之一是对 SFT-then-RL 范式失败原因的精准剖析。提出的“迁移-适应-过拟合” (shift-readapt-overfit) 动态过程,为理解“为什么外部专家数据会‘水土不服’”提供了一个非常清晰的理论框架。这个诊断不仅基于理论推测,更有实验数据(图2的学习曲线)作为支撑,极具说服力。这使得论文的出发点非常坚实。
论文强调其解决的是在一个已经经过指令微调(Instruction-tuned)的模型上继续训练的场景,这与许多从基础模型(Base Model)开始训练的“Zero-RL”工作有所不同。这是一个很好的切入点,但也引出了一个问题:如果从一个基础模型开始,同时使用专家数据和 RL 进行训练,CHORD 框架相比于其他方法(如 SRFT、Reft 等)是否仍有优势?论文虽然在附录中讨论了基础模型和指令模型的差异,但主实验中缺乏与这些“Zero-RL”方法的直接对比。
往期文章:


