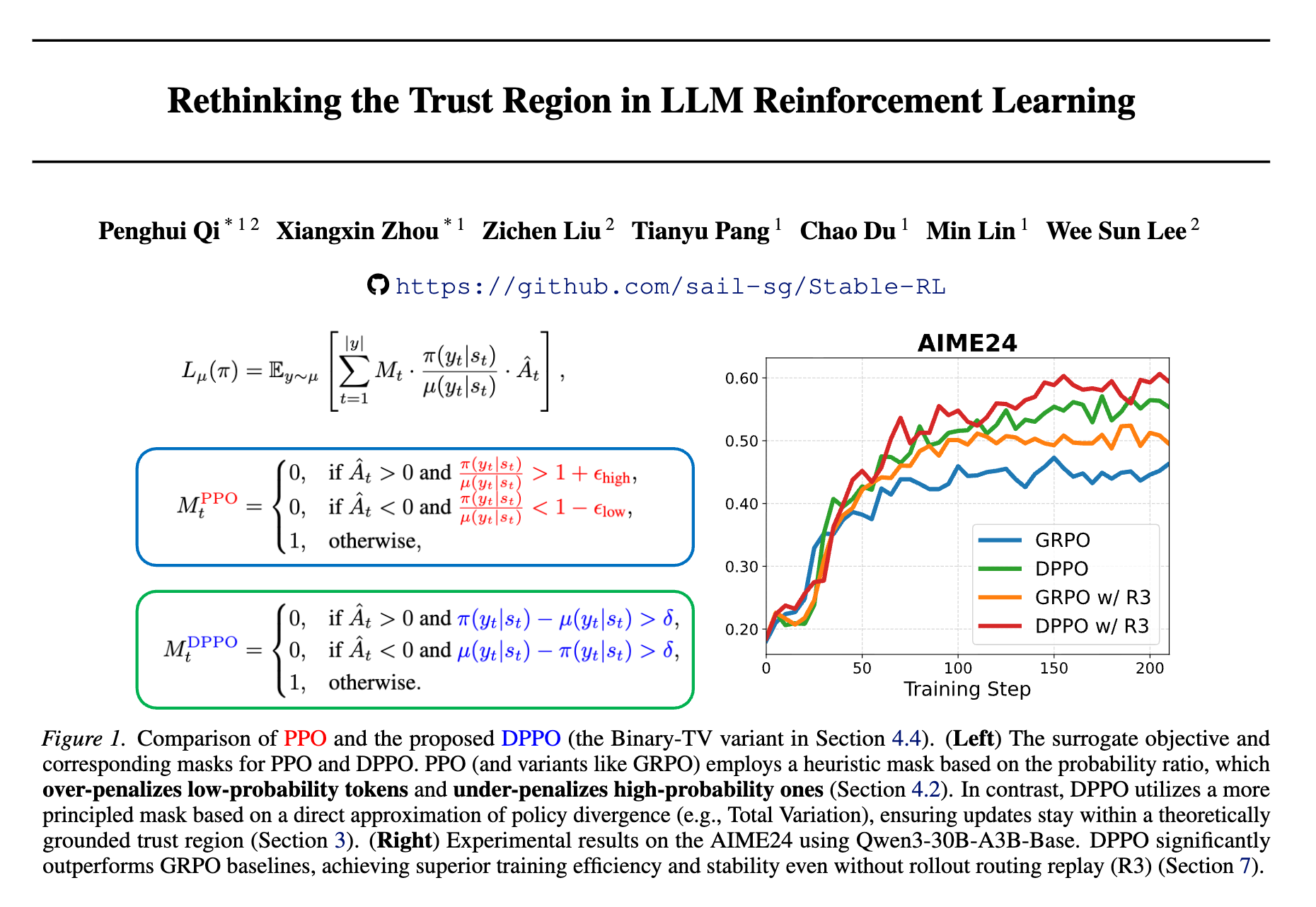
-
论文标题:Rethinking the Trust Region in LLM Reinforcement Learning -
论文链接:https://www.arxiv.org/pdf/2602.04879
TL;DR
今天解读一篇来自 Sea AI Lab 与新加坡国立大学联合发布的论文《Rethinking the Trust Region in LLM Reinforcement Learning》。该论文指出了在大型语言模型(LLM)微调中占据统治地位的 PPO 算法存在核心结构性缺陷:其基于概率比率(Probability Ratio)的截断机制(Clipping)在处理 LLM 的大词汇表和长尾分布时表现不佳。PPO 倾向于过度惩罚低概率 token 的更新,同时对高概率 token 的大幅分布偏移缺乏约束,导致训练效率低下且不稳定。
为此,论文提出了 Divergence Proximal Policy Optimization (DPPO)。DPPO 摒弃了启发式的比率截断,转而采用基于实际分布散度(如 Total Variation 或 KL 散度)的信任域约束。为了解决在大词汇表上计算全量散度的显存开销问题,论文提出了 Binary(二元) 和 Top-K 近似方法。
在大规模实验(包括 AIME24/25 数学推理任务)中,DPPO 在不依赖 Rollout Router Replay (R3) 等辅助技术的情况下,展现出了优于 GRPO、Clip-Higher 和 CISPO 等基线的稳定性与收敛效率。
1. 引言
强化学习(RL)已成为微调大型语言模型(LLM)以对齐人类偏好(RLHF)及提升复杂推理能力(RL on Reasoning)的基石范式。在这一领域,Proximal Policy Optimization (PPO) 及其变体(如 GRPO)凭借其实现简单和经验上的有效性,成为了事实上的标准算法。
PPO 的核心设计理念是“信任域(Trust Region)”:通过限制新策略 与旧策略 之间的差异,防止策略更新步幅过大导致性能崩溃。PPO 实现这一点的手段是比率截断(Ratio Clipping),即限制概率比率 在 之间。
然而,本论文通过理论分析与实证研究指出,这种为经典控制任务(低维动作空间)设计的启发式截断机制,在迁移至 LLM 语境(高维、稀疏、长尾分布的词汇表)时出现了严重的水土不服。这种不匹配导致了两个主要问题:
-
过度约束(Over-constraining):对低概率 token 的有益更新被错误地拦截。 -
约束不足(Under-constraining):未能有效阻止高概率 token 发生灾难性的分布偏移。
为了解决这一根本性矛盾,作者提出了 DPPO,试图从信任域理论的本源出发,重新构建适合 LLM 的策略优化约束。
2. 深入剖析 PPO 在 LLM 中的结构性缺陷
2.1 PPO 截断机制的数学形式
PPO 的目标函数通常写作:
其中 是概率比率, 是优势函数估计。
从理论上讲,限制 接近 1 旨在作为限制 Total Variation (TV) 散度的一种单样本蒙特卡洛近似。TV 散度的定义为:
PPO 的截断条件 实际上是在约束上述期望中的单个样本项。
2.2 低概率与高概率 Token 的不对称性
在 LLM 的长尾词表分布中,这种单样本近似变得极度不稳定。论文通过具体的数值案例揭示了这一现象:
案例 A:低概率 Token (Low-probability token)
假设某 token 在行为策略下的概率为 ,策略更新后概率提升至 。
-
比率计算:。 -
PPO 行为: 远超 (通常 ),因此该更新会被强力截断。 -
实际影响:该 token 的概率质量仅增加了 ,对整体分布的 TV 散度贡献微乎其微。 -
结论:PPO 过度惩罚了低概率 token 的更新,阻碍了模型的探索和学习。
案例 B:高概率 Token (High-probability token)
假设某 token 在行为策略下的概率为 ,策略更新后概率下降至 。
-
比率计算:。 -
PPO 行为: 位于 区间内(假设 ),该更新不会被截断。 -
实际影响:该 token 移除了 的概率质量,这是一个巨大的分布偏移,可能导致严重的策略崩溃。 -
结论:PPO 未能约束高概率 token 的大幅偏移,导致训练不稳定性。
2.3 训练-推理不匹配
这种缺陷在“训练-推理不匹配”的背景下被进一步放大。由于硬件精度(BF16 vs FP32)、推理引擎优化(vLLM 等)以及实现细节的差异,训练时的策略 与生成数据的策略 往往存在微小的数值偏差。
-
对于低概率 token,微小的数值误差可能导致巨大的比率波动(例如 变为 就是 10 倍差距),触发不必要的截断。 -
对于高概率 token,PPO 对偏差的容忍度过高,无法纠正这种系统性漂移。
论文通过实验表明,这种机制上的缺陷是导致 RL 训练中“坍塌(Collapse)”现象的主要原因之一。
3. 面向 LLM 的信任域理论
为了纠正上述问题,作者首先在 LLM 的特定设定下重构了信任域理论。LLM 生成通常被建模为有限视界(Finite-Horizon)、无折扣(Undiscounted, )的马尔可夫决策过程。
3.1 LLM 的性能差异恒等式
在无折扣 ( 步) 设定下,对于任意两个策略 和 ,性能差异(即奖励期望之差)可以分解为:
定理 3.1 (Performance Difference Identity for LLMs)
其中 是代理目标函数:
而 是误差项,包含了策略变化的高阶效应。
这一推导与经典 RL(如 TRPO)中的折扣设定不同,它是专门针对序列级奖励(Sequence-level Reward)和有限长度生成的。
3.2 策略提升下界
为了保证策略的单调提升,必须限制误差项 。论文推导出了针对 LLM 的策略提升下界:
定理 3.2 (Policy Improvement Bound for LLMs)
其中 是最大绝对奖励, 是所有状态下的最大 TV 散度。
该定理为信任域方法提供了严格的理论支撑:如果我们能将新旧策略之间的 TV 散度 限制在足够小的范围 内,最大化代理目标 就能保证真实性能 的提升。
此约束优化问题形式化为:
这也同样适用于 KL 散度约束(通过 Pinsker 不等式关联)。
4. 方法论:Divergence Proximal Policy Optimization (DPPO)
基于上述理论,作者提出了 DPPO。其核心思想是:用基于分布散度的显式约束取代基于样本比率的隐式截断。
4.1 DPPO 目标函数
DPPO 并不直接求解复杂的受限优化问题,而是借鉴 PPO 的设计,使用动态掩码(Dynamic Mask)来近似约束。目标函数定义为:
其中 是散度感知掩码。
4.2 散度感知掩码
掩码的逻辑设计非常关键,它保留了 PPO 的非对称优势,但修正了判定条件:
这里 是策略在当前状态下的真实散度(TV 或 KL)。
-
逻辑解析: -
只有当策略更新导致整体分布散度 超过阈值 时,才考虑进行拦截。 -
如果更新方向是让策略回归信任域(例如 但 ,即鼓励增加概率但当前比率小于1),则不进行拦截。 -
最关键的是,是否拦截不再取决于单个样本的 是否巨大,而是取决于该更新是否导致了整个分布的显著偏移。
-
4.3 高效近似:Binary 与 Top-K
直接在 LLM 的大词汇表(通常 >100k)上计算 TV 或 KL 散度,需要全词表 logits 的计算和存储,这在显存和计算上都是不可接受的。因此,论文提出了两种高效的近似方法,证明了它们是真实散度的下界。
4.3.1 二元近似
这是最极致的简化。将多分类分布坍缩为二元伯努利分布:当前采样的 token , 所有其他 token。
定义新分布 。
-
Binary TV:
-
Binary KL:
优势:计算开销几乎为零。
原理:它正确区分了概率的绝对变化量。对于低概率 token,即使比率变化很大,其绝对概率变化 也很小,因此 很小,不会触发截断。这完美解决了 PPO 的过度惩罚问题。
4.3.2 Top-K 近似 (Top-K Approximation)
为了更精确地捕捉分布头部的变化,可以只跟踪行为策略中概率最高的 个 token 以及当前采样的 token。
构建一个缩减的词表 ,将剩余所有 token 聚合为 "other" 类。在此缩减分布上计算散度。
实验表明, 时效果已非常接近全量散度,且 Binary 近似在大多数场景下已经足够好。
5. 训练稳定性分析
论文通过一系列控制变量实验(Fine-tuning DeepSeek-R1-Distill-Qwen-1.5B on MATH),深入探讨了导致 RL 训练不稳定的根本原因。
5.1 信任域的必要性
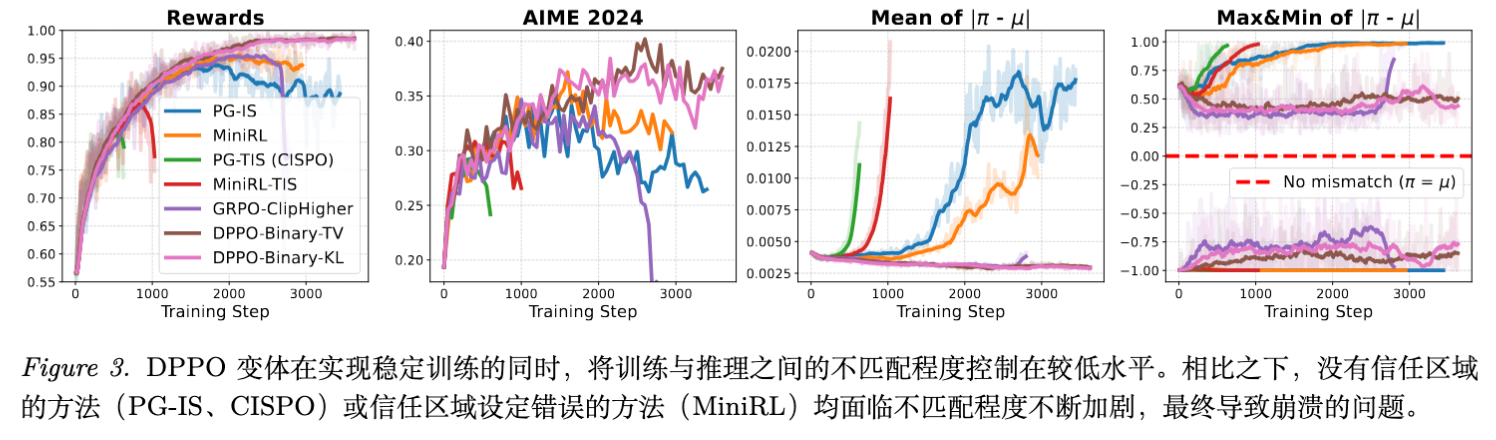
实验显示,完全移除信任域约束的方法(如 PG-IS 和 CISPO/PG-TIS)会导致训练-推理不匹配(Mismatch)随时间迅速积累,最终导致奖励曲线崩溃。即使学习率极低(),信任域依然是必须的。
5.2 行为策略 vs. 重算策略
当前一些开源实现(如 MiniRL)为了工程便利,将信任域定义为相对于重算策略(Recomputed Policy, )而非数据生成时的行为策略(Behavior Policy, )。
即计算 而非 。
论文指出并验证了这种做法的危害:
-
理论违背:所有策略提升界(Theorem 3.2)都是基于 建立的。 -
实证崩溃:使用重算策略作为锚点的实验组(MiniRL)未能控制住 Mismatch,最终导致性能下降。 -
结论:必须以原始行为策略 为锚点。DPPO 通过直接使用 计算散度,不仅理论正确,还省去了重算 logits 的大约 25% 计算开销。
5.3 负样本上的“坏更新”
论文通过逐步引入掩码机制,定位了导致不稳定的具体更新类型。
-
发现:正样本(奖励为正)的更新通常是安全的。 -
根源:极少数(占比 < 0.5%)针对负样本(奖励为负)的更新是罪魁祸首。这些更新试图大幅降低模型认为“正确”但实际获得负反馈的 token 的概率。 -
解释:当模型对某个 token 非常确信(高概率),但环境给出了负反馈,简单的策略梯度会试图剧烈压低该概率。如果没有信任域约束,这会破坏模型内部的知识结构,导致“灾难性遗忘”或参数震荡。 -
DPPO 的作用:DPPO 有效地拦截了这些导致分布剧烈变化的负样本更新。
5.4 截断重要性采样 (TIS) 的陷阱
Truncated Importance Sampling (TIS) 常被用于控制方差。但论文发现 TIS 实际上加剧了训练的不稳定性。
原因与 PPO 截断类似:TIS 倾向于截断低概率 token 的权重。这引入了有偏的梯度估计,系统性地压制了模型在探索边缘(低概率区域)的学习信号。
6. 训练效率分析
除了稳定性,DPPO 的另一个核心优势是效率。
6.1 放宽对低概率 Token 的约束
PPO 的比率截断无意中阻碍了低概率 token 的学习。论文实验表明,如果手动放宽对 的 token 的截断约束,训练效率会显著提升。
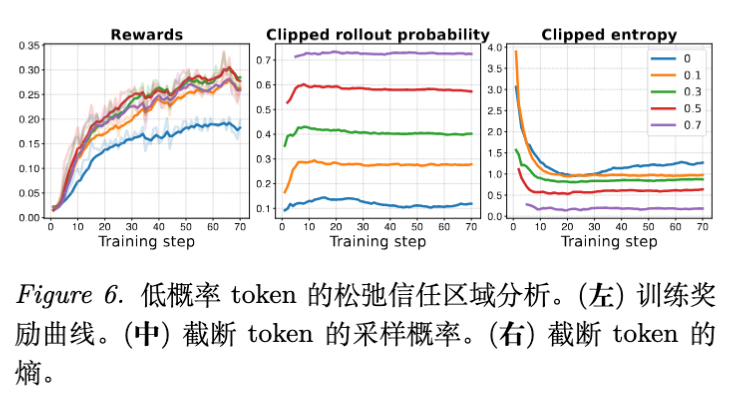
6.2 被 PPO 误杀的 Token 是什么?
通过分析被 PPO 截断的 token,作者发现它们并非噪声,而是具有高语义价值的词汇:
-
正样本中被截断的:数字('1', '4')、数学符号('+', '=')、逻辑连接词('Therefore', 'Since')。 -
现象:这些 token 往往是推理链的关键步骤,但初始概率可能较低。PPO 看到比率爆炸直接截断,导致模型难以学会这些关键推理步。 -
熵分析:被截断的 token 通常具有高熵(不确定性高),这正是信息量最大、最需要学习的部分。DPPO 通过 Binary 散度约束,允许这些 token 在不破坏整体分布的前提下进行大幅度的相对更新,从而加速了学习。
6.3 截断松弛的方向性
实验对比了 Relax-high(放宽上界)和 Relax-low(放宽下界)。结果表明,同时放宽双侧约束(即由 DPPO 自动管理的机制)能取得最佳的效率与稳定性平衡。
7. 大规模扩展实验
为了验证 DPPO 在大规模实战中的表现,作者在 Qwen3 系列模型上进行了详尽的对比实验。
实验设置:
-
模型:Qwen3-30B-A3B-Base (MoE), Qwen3-8B-Base (Dense), 以及 LoRA 微调设置。 -
数据集:DAPO-Math (约 13k 样本)。 -
基线:GRPO (with Clip-Higher trick), CISPO。 -
评价指标:AIME 24, AIME 25 (Pass@1, Avg@32)。
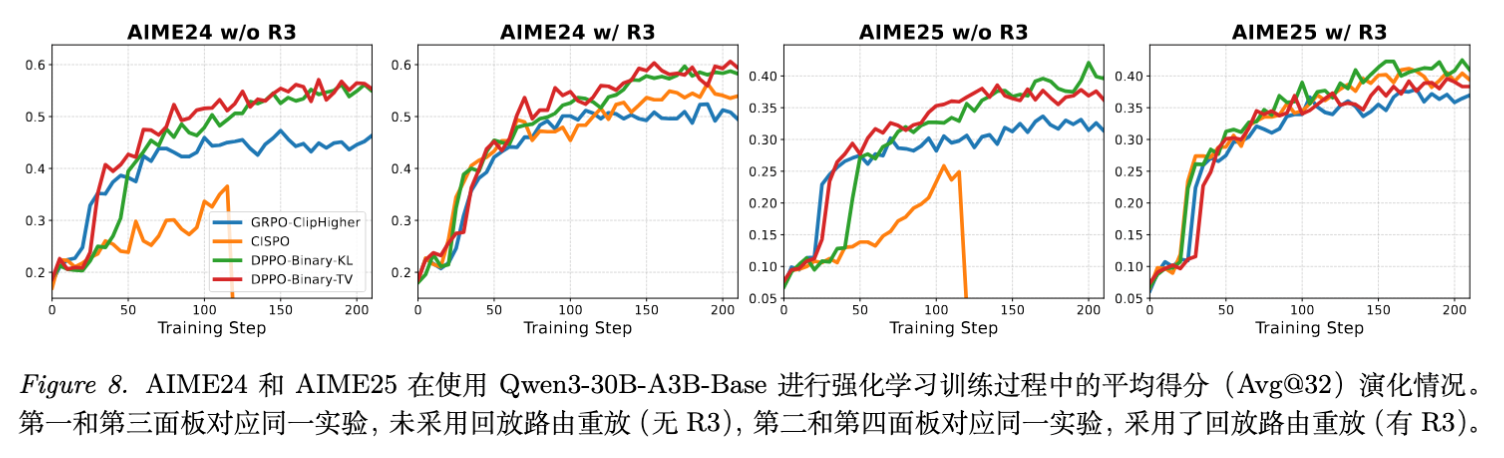
主要结果:
-
MoE Base (w/o R3): DPPO 显著优于 GRPO 和 CISPO。CISPO 在训练中期出现崩溃,而 GRPO 收敛较慢且最终性能较低。DPPO 保持了极其稳定的训练曲线。 -
MoE Thinking: 在纯推理模式下,GRPO 遭遇了训练崩溃,而 DPPO 依然稳健。 -
Dense Base: 在 8B 模型上,DPPO 同样展现出优势,证明其普适性。 -
LoRA Setting: 在参数高效微调场景下,DPPO 依然保持领先。
关于 Rollout Router Replay (R3) 的讨论
R3 是一种用于稳定 MoE 模型 RL 训练的技术(解决训练推理时的路由不一致)。
-
实验发现:DPPO 在不使用 R3 的情况下,性能已经超过了 使用了 R3 的 GRPO 基线。 -
意义:这说明 DPPO 强大的分布约束能力本身就能有效缓解 MoE 特有的训练-推理不匹配问题。当然,叠加 R3 可以进一步微幅提升 DPPO 的表现,说明两者是正交的。
近似方法的消融
对比 Binary-KL/TV 和 TopK-KL/TV ():
-
两者表现差异微乎其微。 -
这强有力地支持了在工业级大规模训练中使用极其廉价的 Binary 近似。它既保留了理论上的严谨性,又几乎不增加计算负担。
8. 总结
核心贡献总结:
-
诊断:明确了 PPO 比率截断在长尾分布下的双重失效(过严与过宽)。 -
理论:建立了适用于 LLM 的有限视界、无折扣策略提升界。 -
方法:提出了 DPPO 及其实用的 Binary/Top-K 近似,用散度约束替代比率截断。 -
验证:在大规模 MoE 模型和数学推理任务上证明了其卓越的稳定性与效率。
更多细节请阅读原文。
往期文章:


