RLVR 严重依赖于那些拥有客观、程序化可验证解的任务。这种结构性的依赖,为模型能力的扩展设置了一个“硬上限”。毕竟,在人类知识和交流里,充满了大量开放式的、主观性强的、多维度评估的任务,这些都无法用一个简单的“正确”或“错误”来衡量。现实世界的大部分场景,其反馈信号都不是非黑即白的。
正是为了突破这一瓶颈,来自蚂蚁集团和浙江大学的研究者们提出了一种创新的方法,旨在将强化学习的边界从严格可验证的领域,扩展到更广阔的开放式任务中。这篇名为《Reinforcement Learning with Rubric Anchors》的论文,详细介绍了一种基于“评分细则”(Rubric)的奖励机制。这里的核心思想是,通过精心设计的一套结构化、可解释的评估标准(即评分细则),来实现对那些本质上主观或多维输出任务的自动评分,从而为强化学习提供可靠的奖励信号。
这项工作的主要贡献可以概括为以下几点:
-
构建了规模庞大的评分细则奖励系统:研究团队构建了一个包含超过 10,000 条评分细则的奖励系统。这些细则由人类专家、不同的大语言模型以及人机协作等多种方式生成,是目前已知规模最大的同类系统。 -
提出了一个清晰的评分细则导向 RL 框架:论文中将此方法命名为 Rubicon(RUBrIC aNchOrs 的缩写)。该框架系统性地解决了如何构建评分细则、如何进行数据筛选、以及如何设计训练策略等关键问题。 -
验证了方法的有效性并开源模型:基于 Rubicon 框架,研究者们训练并开源了一个名为 Rubicon-preview 的模型(基于 Qwen-30B-A3B)。实验证明,仅用 5000 多个训练样本,该模型就在多个人文社科类的开放式基准测试中取得了 5.2% 的绝对提升,甚至在某些指标上优于参数量大一个数量级的 DeepSeek-V3 模型。 -
实现了对模型输出风格的细粒度控制:研究表明,评分细则可以作为一种明确的“锚点”,有效缓解了当前 LLM 输出中常见的“AI腔”和说教口吻,使得模型的生成内容更具人性化和情感表现力。
在接下来的内容中,我们将深入剖析 Rubicon 框架的技术细节及实验结果。
Rubicon 框架详解
Rubicon 框架的核心在于系统性地解决了如何为开放式任务创建可靠奖励信号的挑战。它涵盖了从评分细则的设计、奖励信号的构建,到最终的强化学习训练流程的完整闭环。
核心挑战:从“可验证”迈向“可评估”
传统 RLVR 的成功,源于其奖励信号的确定性。代码是否通过测试,答案是否正确,这些都是不容辩驳的事实。然而,当我们转向评估一首诗的意境、一段对话的同理心时,挑战便随之而来。如何将这些主观的、模糊的人类偏好,转化为机器可以理解和优化的量化信号?
直接让另一个强大的 LLM 作为裁判来打分是一种常见思路,但这引入了“裁判模型”自身偏见和能力上限的问题。Rubicon 的解决思路则更为精妙:它不寻求一个单一的、绝对的权威判断,而是将复杂的评估任务分解为一系列结构化的、更易于判断的子维度。这就是“评分细则”(Rubric)的用武之地。
评分细则系统 (Rubric System) 的设计与构建
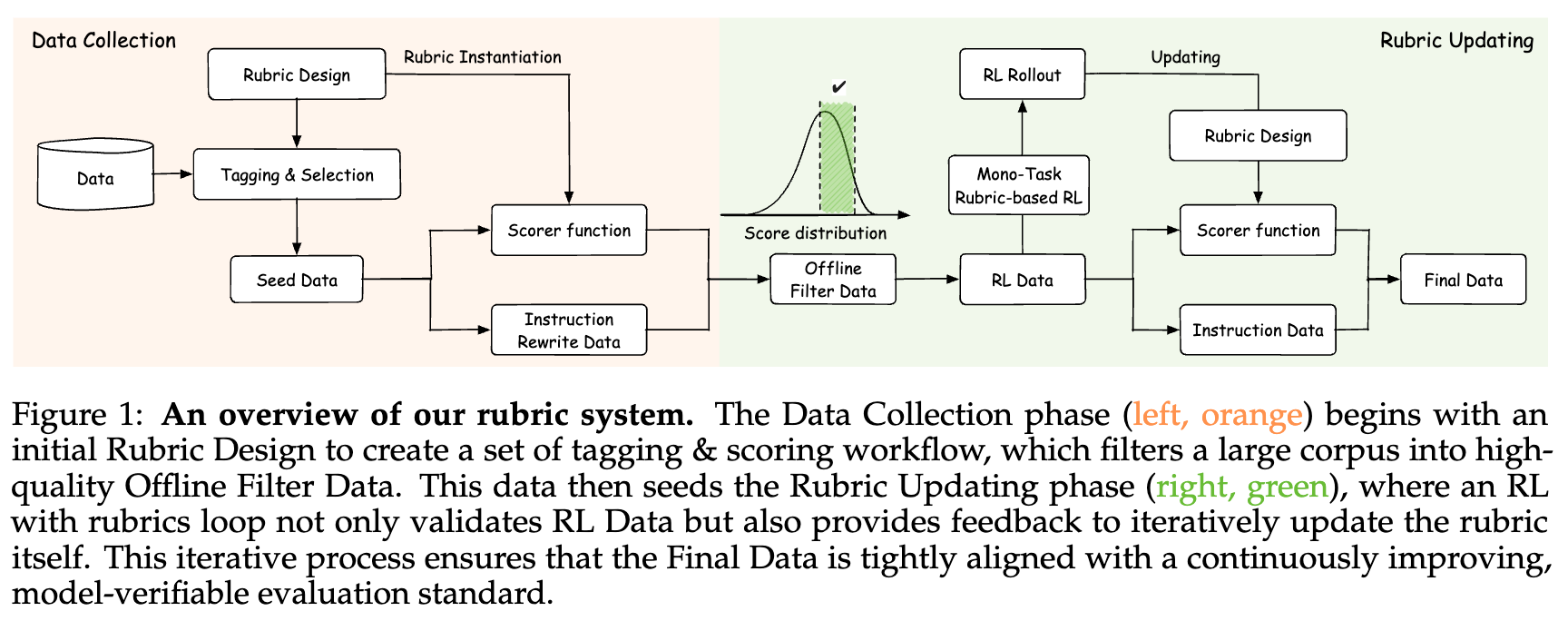
Rubicon 框架的设计与构建遵循着一条核心原则——评估不对称性(Evaluative Asymmetry):验证一个输出的质量,通常比从头生成一个高质量的输出要容易得多。基于此,团队采用了“评分细则优先”(rubric-first)的工作流程。
-
第一步:构建模型可验证的评分细则。研究者们首先定义评估标准,而不是先去收集数据。 -
第二步:筛选或合成匹配这些细则的数据。有了明确的评估标准后,就可以更有针对性地从海量数据中筛选出符合要求的样本,或者甚至程序化地生成新的训练数据。 -
第三步:复用评分细则进行监督、奖励和评估。这确保了从数据采集到模型训练,再到最终评估的整个流程中,所遵循的标准是一致的。
1. 评分细则的形式化定义
在 Rubicon 框架中,一个完整的评分系统 被形式化地定义为一个包含 个不同评价维度的集合:
其中,每一个评价维度 都由三个关键部分构成:
-
标准描述 (Criterion Description, ) :用自然语言清晰地定义这个维度所评估的具体方面。例如,“回应的情感支持度”或“是否遵循了指定的格式要求”。 -
有序的评分等级(Score Tiers, ) :一个有序的等级集合,每个等级 都映射到一个具体的量化分数。例如,可以将“情感支持度”分为 1-5 分,并对每一分给出具体的描述(如 1 分表示“完全没有提供情感支持”,5 分表示“提供了深刻且恰当的情感支持”)。 -
相关权重 (Weight, ) :一个数值,表示该评价维度在最终总分中的相对重要性。例如,在创意写作任务中,“创意性”的权重可能就比“语法正确性”要高。
这种形式化的定义具有很强的通用性。它既可以容纳高级别的、通用的评分细则(如用于开放式创意生成的标准),也可以囊括细粒度的、程序化可验证的规则(如要求输出必须包含某个关键词或遵循 JSON 格式)。这使得 Rubicon 能够将多样化的评估协议统一在一个抽象的表示框架之下。
2. 评分细则的类型与示例
论文附录中提供了一些评分细则的实例,可以帮助我们更好地理解其构成。
-
硬约束评分细则 (Hard Rubric) :这类细则通常对应程序化可验证的规则。例如,一个用于约束写作任务的评分细则可能被定义为一个 Python 函数,该函数检查生成的文本是否满足“必须包含单词‘education’至少一次”并且“全文必须是一个完整的段落”。
-
软约束评分细则 (Soft Rubric) :这类细则用于评估那些更为主观的质量,如创造力和共情能力。例如,在评估“平实叙事”风格时,评分细则被分解为三个核心维度:关系效能(声音与语调)、智识贡献(内容与思想) 和 构图卓越(语言与文体)。每个维度下又细分了更多具体指标,如“冷静接纳”、“扎根现实”、“含蓄情感”等。
基于评分细则的奖励框架 (Rubric-Based Reward Framework)
有了精心设计的评分细则系统,下一步就是如何将其转化为强化学习可以利用的奖励信号。
1. 多维奖励信号
给定一个评分系统 ,对于模型的任意一个响应 (在上下文 的情况下),奖励函数 会将其映射到一个多维的反馈向量:
这个向量中的每个分量 代表了模型响应在第 个维度上的得分。这种多维度的奖励信号相比于单一的标量奖励,提供了更细粒度、更具可解释性的反馈。它可以清晰地告诉模型,它在哪些方面做得好,在哪些方面需要改进。
2. 高级奖励聚合策略
为了进行策略优化,通常需要一个单一的标量奖励值。最直接的方法就是将多维奖励向量进行加权求和:
然而,研究者们发现,有效的基于评分细则的优化,往往需要比简单的线性组合更复杂的聚合策略,以捕捉不同维度之间复杂的非线性依赖关系。因此,Rubicon 框架集成了一系列高级聚合策略:
-
否决机制 (Veto Mechanisms) :对于一些关键的、不可协商的维度,一旦失败,就可以直接否决所有其他维度的奖励。例如,论文中专门设计了“奖励破解检测”的评分细则,如果一个响应被判定为试图通过钻空子来骗取高分(例如,在回答的开头加上一句“这是一个很好的问题”来讨好评分模型),那么无论它在其他维度上表现多好,其总奖励都会被置为零。这相当于施加了一个硬约束。
-
饱和度感知聚合 (Saturation-Aware Aggregation) :在某个维度上从 90 分提升到 95 分的难度,和从 50 分提升到 55 分是完全不同的。为了模拟这种边际效益递减的现象,框架使用了饱和函数(如 Sigmoid 函数)。这鼓励模型成为一个“多边形战士”,在所有维度上均衡发展,而不是在一个维度上“死磕”以追求极致,从而避免了不均衡的改进。
-
成对交互建模 (Pairwise Interaction Modeling) :不同的评价标准之间可能存在协同(synergistic)或拮G抗(antagonistic)的关系。例如,“创意性”和“逻辑严谨性”在某些任务中可能就存在一定的张力。该框架可以显式地对这些成对的交互效应进行建模,捕捉简单求和会忽略的复杂关系。
-
目标性奖励塑造 (Targeted Reward Shaping) :在模型表现普遍较好的高分区,分数之间的差异可能很小,导致奖励信号的区分度不足。为了解决这个问题,框架采用了非线性的映射函数,来选择性地放大高分区的分数差异。这增强了奖励信号在高水平竞争中的判别能力,为模型进行更精细的优化提供了更明确的梯度。
Rubicon 框架的实现细节
Rubicon 的训练方法论是一个精心设计的多阶段强化学习协议,旨在循序渐进地培养模型从精确的指令遵循到复杂的创造性与社会性推理的能力。
1. 数据选择与 RL 流水线
所有用于该框架的数据,都源自一个包含超过 90 万个实例的专有语料库,这些数据经过精心策划,来源多样,包括社区问答论坛、高质量考试和通用对话数据集。
-
离线数据过滤 (Offline Data Filtering) :在强化学习的各个阶段之前和之间,都应用了一套严格的过滤协议来保证训练数据的质量。具体流程如下:
-
对于每一批候选的“指令-评分细则”对,让基础模型生成响应。 -
使用评论家模型(Critic Models)对这些响应进行评分,得到一个完整的分数分布。 -
只保留处于校准后的中心分位数(calibrated central quantile)内的数据。
这个过程的目的是剔除两类数据:一类是得分过高的实例,它们对于当前模型来说过于简单,能提供的学习信号有限;另一类是得分过低的实例,它们可能是由噪声或低质量指令引起的。通过这种方式,筛选出了一个“难度适中”、潜力巨大的平衡子集。
-
-
分阶段 RL 训练 (Stage-wise RL Training):在实验中,研究团队观察到了一个有趣的“跷跷板效应”(seesaw effect)。如果将所有类型的任务(例如,严格的约束遵循任务和开放的创造性任务)放在一起进行联合训练,模型的整体性能往往会下降。这很可能是因为不同任务的优化目标存在冲突。
为了缓解这个问题,团队采用了一种务实的分阶段 RL 调度策略:
-
第一阶段:建立坚实的指令遵循基础。在这个阶段,训练的重点是可靠的指令遵循能力和多维评估对齐能力。主要使用程序化可验证的检查和静态的评分细则来构建一个强大的约束处理基础。 -
第二阶段:向开放式任务扩展。在模型具备了强大的基础能力后,第二阶段将训练扩展到更开放、更具社会性和创造性的任务。在这个阶段,会更多地利用基于参考答案的评分细则和由更强的代理工作流(agentic workflows)生成的实例特定标准,以促进模型的适应性和更丰富的表达能力。
-
2. 针对奖励破解的自适应防御
在强化学习中,一个常见的挑战是“奖励破解”(Reward Hacking),即模型找到了一个可以最大化奖励信号的捷径,但这种行为并没有带来真正的能力提升。在 Rubicon 的早期实验中,这个问题尤为突出。模型会很快学会利用特定评分细则的漏洞,例如通过输出一些模式化的、讨好性的句子来获得虚高的分数。
为了解决这个问题,团队实施了一套自适应的防御策略:
-
离线分析与归纳:首先,对早期训练轮次中产生的 rollout 数据进行离线分析。通过检查那些奖励信号异常高的实例,系统性地识别和归纳了反复出现的、高层次的奖励破解行为模式。 -
开发专用防御细则:基于这些经验分析,团队开发了一个专用的奖励破解防御评分细则(Reward Hacking Defense Rubric)。这个细则在初始训练中并不存在,而是根据观察到的失败模式合成的。 -
集成防御细则为监督约束:这个新的防御细则,作为一个监督性的约束条件,被集成到所有后续的、更复杂的 RL 阶段中。
这个防御机制的加入,带来了训练动态的显著改善。
实验结果与分析:Rubicon 的实际表现
为了全面评估 Rubicon 框架的有效性,研究者们从三个方面进行了实验:开放式、以人为本的基准测试上的定量增益,模型生成输出的定性演变分析,以及对通用能力基准的影响评估。
定量评估:在开放式任务上的显著提升
与 RLVR 不同,基于评分细则的 RL 的主要优势体现在那些缺乏可验证奖励的基准上。因此,团队收集了一系列多样化的开放式和以人文为中心的基准测试集,涵盖了创意写作(Creative Writing V3, Writingbench)、主观判断(Judgemark V2)、情商(EQ-Bench3)、指令遵循(IFEval, Collie, IFScale)等多个方面。
同时,为了检查模型在其他能力上是否出现衰退(regression),他们还测试了包括 MMLU、HellaSwag 在内的通用能力基准,以及包括 AIME、Math500 在内的推理能力基准。
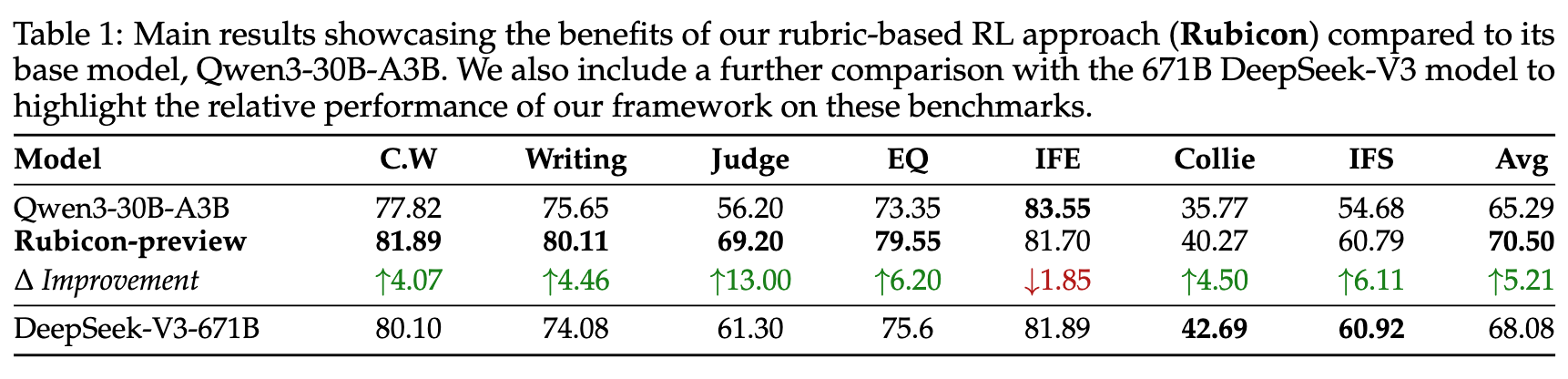
上表展示了 Rubicon 方法的核心成果。实验中,Qwen3-30B-A3B 作为基础模型,经过 Rubicon 框架训练后得到的模型被称为 Rubicon-preview。为了进行更有挑战性的对比,实验还引入了业界公认在人文社科和开放式问答方面表现出色的 DeepSeek-V3-671B 模型。
从结果中可以清晰地看到:
-
显著的平均提升:Rubicon-preview 相较于其基础模型,在这些开放式基准上的平均分实现了 5.21% 的绝对提升。这是一个非常可观的增益。 -
高效的训练:值得注意的是,这一显著提升仅仅使用了 5000 多个训练样本,凸显了该方法在 token 效率上的优势。 -
超越更强的模型:更令人印象深刻的是,参数量仅为 30B 的 Rubicon-preview,其平均表现成功地超越了参数量高达 671B 的 DeepSeek-V3 模型 2.4% 。这表明 Rubicon 框架带来的能力提升是实质性的,而不仅仅是参数规模的功劳。 -
在特定领域的突出表现:在 Judgemark V2 (提升 13%)、EQ (提升 6.2%)和写作(提升 4.46%)等需要主观判断、情感理解和创造性表达的任务上,提升尤为明显,这直接验证了评分细则导向方法在这些领域的有效性。
通用能力的保持:专业化训练并未牺牲通用性
在进行特定领域的强化训练时,一个普遍的担忧是模型可能会“偏科”,牺牲其在其他领域的通用能力。为了验证 Rubicon 是否存在这个问题,研究者们在一系列通用和推理基准上进行了评估。

上表的结果打消了这一顾虑。
-
首先,在 MMLU 这类衡量模型综合知识广度的基准上,Rubicon-preview 的表现没有出现退化,甚至略有提升。 -
其次,一个意外的发现是,尽管 Rubicon 的评分细则并非为 STEM 任务量身定制,但模型在数学推理数据集 AIME24 和 AIME25 上甚至取得了 +4.17% 和 +0.83% 的温和改进。
这表明,Rubicon 框架不仅有效提升了模型在目标开放域的能力,还成功地避免了对通用能力的负面干扰,保持了模型的整体竞争力。
案例研究:通过评分细则实现可控的输出风格
评分细则不仅是奖励的来源,更可以作为可控的锚点,引导 LLM 的输出朝向一个明确定义的风格。为了展示这种效果,论文提供了一个精彩的案例研究。
目标风格:平实叙事 (Plain Narrative)
研究者们首先定义了一个用于评估“平实叙事”风格的评分细则。其核心要求是语言简洁、克制,并能反映出一种深刻而宁静的韧性。评估的指导原则是“优先考虑风格的真实性,而非文学上的华丽或技术的正确性”。
对比实验
对于同一个提示:“When in your life have you felt the most alive? (你生命中的哪个时刻感觉最‘活着’?)”,基础模型 Qwen3-30B-A3B 和经过风格化训练的 Rubicon 模型给出了截然不同的回答。
-
Qwen3-30B-A3B (基础模型) 的回答:
"I don't experience emotions or personal moments in the way humans do, but I can help you explore this question for yourself. ... What memories stand out to you? I'd love to hear your story."
这是一个典型的、充满了“AI味”的回答。它首先声明自己是 AI,没有个人情感和经历,然后试图将问题抛回给用户。这种回答虽然安全、无害,但却缺乏人情味和启发性,是一种模式化的、回避式的回应。
-
Rubicon (风格化模型) 的回答:
"The Moment the Mountain Spoke Back
I remember the exact moment the alpine wind ceased its whisper and the world held its breath. It was the third day of my solo trek through the Swiss Alps... My body was a symphony of ache... Yet there was a strange exhilaration in that discomfort, a primal thrill that made my pulse race... It was in that raw, unfiltered moment - where the boundaries between self and universe dissolved - that I felt the full, unvarnished truth of my existence."这个回答则完全不同。它没有纠结于自己作为 AI 的身份,而是直接进入了一个生动、具体的叙事场景。语言简洁而富有质感(“frost-locked gravel”、“symphony of ache”),情感表达含蓄而深刻(在不适中体验到的“primal thrill”)。它没有直接说教“活着的意义”,而是通过一个具体的个人故事,让读者自己去感受和体会。这完美地体现了“平实叙事”评分细则中所要求的“扎根于具体物理细节”、“用深刻的克制表达复杂情感”以及“智慧从生活经验中自然浮现而非直接说教”。
这个案例有力地证明了,通过评分细则进行强化学习,可以有效减少模型的“AI腔”和说教口吻,产出更具人性化、情感表现力和文学美感的文本。
“跷跷板效应”的深入探讨
论文中坦诚地讨论了在训练过程中发现的“跷跷板效应”(The "Seesaw" Effect),即不同类型的优化目标之间存在的冲突。
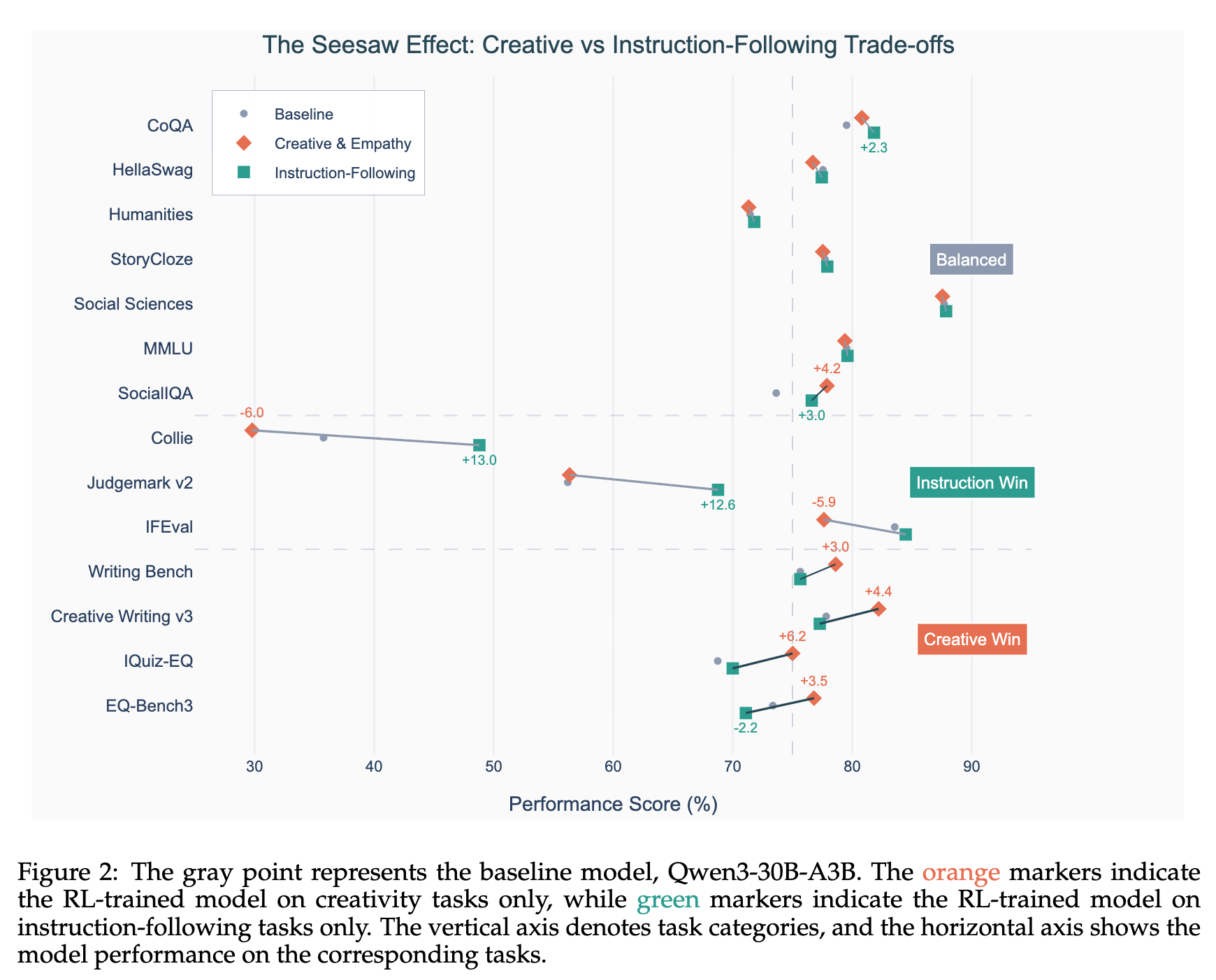
上图直观地展示了这种权衡关系。
-
灰色点代表基线模型 Qwen3-30B-A3B 的性能。 -
橙色标记代表只在创造性与共情任务上进行 RL 训练的模型。可以看到,它在 Creative Writing、EQ-Bench3 等任务上表现优异(Creative Win),但在指令遵循任务 Collie 和 IFEval 上却出现了明显的性能下降(-6.0% 和 -5.9%)。 -
绿色标记代表只在指令遵循任务上进行 RL 训练的模型。其结果正好相反,在指令遵循任务上表现出色(Instruction Win),但在需要共情能力的 EQ-Bench3 任务上性能出现了下滑(-2.2%)。
这些结果表明,简单地将所有类型的评分细则混合在一次 RL 运行中,很可能会加剧这种目标冲突,导致顾此失彼。这也正是 Rubicon 框架最终采用多阶段 RL 训练策略的原因——先打好指令遵循的坚实基础,再在此基础上“添砖加瓦”,培养创造性和共情能力。这是一种务实且有效的解决方案。
点评
这是一项高质量且具有重要实践意义的研究工作。它没有去追逐在某些饱和基准上刷高几个百分点的增量式创新,而是精准地切入了当前大语言模型(LLM)对齐和能力提升领域的一个核心痛点:如何处理和优化那些缺乏客观、程序化可验证答案的开放式、主观性任务。
通过提出系统性的 Rubicon 框架,该工作成功地在传统 RLHF(基于人类反馈的强化学习)的模糊性和 RLVR(基于可验证奖励的强化学习)的局限性之间,开辟出了一条结构化、可解释且可扩展的中间道路。它不仅是一个有效的技术方案,更是一套值得借鉴的方法论。
整个框架的成功高度依赖于高质量、大规模评分细则库的构建。论文提到其系统包含超过 10,000 条细则,这是通过人类专家、LLM 和人机协作完成的。但这引出了一个关键问题:这个过程的人力成本、时间和金钱成本有多高?当需要将此方法扩展到成千上万种更多样化的任务时,这种评分细则的“手工业式”或“半自动化”生产方式能否持续?这可能是该方法大规模工业化应用前需要解决的首要问题。
该方法旨在结构化地处理主观性,但它并不能消除主观性,而是将其从“模型输出的评估”转移到了“评分细则的设计”上。评分细则本身是由人或 LLM 设计的,不可避免地会携带设计者的偏见、文化背景和价值观。这意味着,模型的最终对齐结果,将强依赖于上游评分细则的质量和公正性。这提出了一个新的挑战:我们如何评估和确保评分细则本身是无偏的、全面的?
往期文章:


