让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence -
论文链接:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
TL;DR
今天解读 DeepSeek-V4 的技术报告。DeepSeek-V4 系列包含 DeepSeek-V4-Pro(1.6T 总参数,49B 激活)与 DeepSeek-V4-Flash(284B 总参数,13B 激活)两个多专家混合(MoE)模型,均支持一百万 token 的上下文长度。
报告展示了该模型在架构、优化算法、分布式系统基础设施、预训练与后训练范式上的改进。核心改进包括:
-
引入压缩稀疏注意力(CSA)与重度压缩注意力(HCA)的混合注意力架构; -
应用流形约束超连接(mHC)以提升深层残差网络稳定性;采用 Muon 优化器并辅以牛顿-舒尔茨(Newton-Schulz)正交化迭代加速收敛; -
系统层面实现了细粒度通信与计算的重叠、基于 TileLang 的高吞吐算子库; -
后训练阶段放弃了传统的标量奖励模型,转向生成式奖励模型(GRM),并提出了全词表同策略知识蒸馏(OPD)方案。
1. 引言
随着大型语言模型(LLMs)被应用于代码生成、代理任务(Agentic workflows)及大规模跨文档分析中,对百万级别长上下文的处理需求日益增加。标准的 Transformer 架构采用的注意力机制具有关于序列长度的二次计算复杂度,这在长上下文和测试时计算伸缩(Test-time scaling)场景下构成瓶颈。
DeepSeek-V4 系列的研发目标集中于突破超长序列计算效率的瓶颈,使百万 token 上下文的日常推理与在线学习具备工程可行性。模型基于 DeepSeek-V3 的基础进行迭代,保留了 DeepSeekMoE 的核心设计与多 Token 预测(MTP)策略,在注意力机制、残差连接和优化器选择上进行了重新设计。同时,研究团队设计了一套包括算子编写、计算图优化、分布式并行及沙盒系统在内的全栈基础设施,以支持模型在预训练与后训练阶段的任务。
2. 模型架构升级
DeepSeek-V4 整体延续了基于 Transformer 的解码器架构与多 Token 预测(MTP)模块。其主要的架构变动体现在注意力层、残差连接层以及 MoE 路由机制的调整。
2.1 继承自 DeepSeek-V3 的设计与调整
DeepSeek-V4 依然采用 DeepSeekMoE 范式,设置细粒度的路由专家与共享专家。与 V3 相比,路由机制存在几处修改:
-
激活函数调整:计算亲和度得分的函数由 更改为 。 -
放弃目标节点约束:为提升负载均衡表现,模型继续采用无辅助损失(Auxiliary-loss-free)策略以及序列级别的平衡损失。V4 移除了对路由目标节点数量的硬性限制,转而通过重构底层并行策略来维持训练吞吐。 -
浅层路由变更:在网络最初的几个 Transformer 块中,V4 将原有的密集前馈网络(Dense FFN)替换为采用哈希路由(Hash routing)的 MoE 层。哈希路由根据输入 token 的 ID 计算哈希值来分配专家。 -
多 Token 预测 (MTP) :保留了与 DeepSeek-V3 一致的 MTP 模块与目标函数设计,无额外修改。
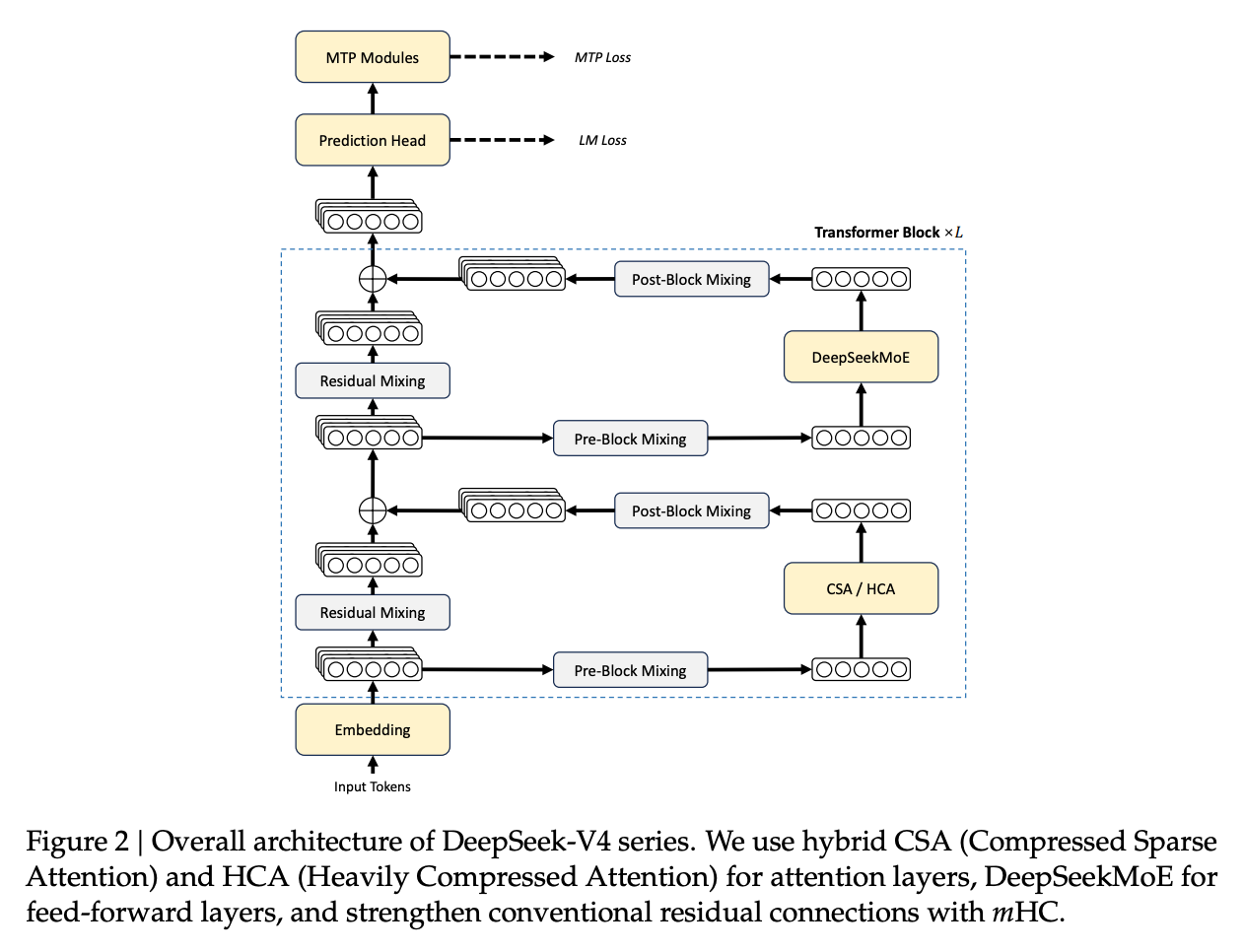
2.2 流形约束超连接 (Manifold-Constrained Hyper-Connections, mHC)
在深层 Transformer 中,标准的残差连接可能面临信号传播衰减与训练不稳定等问题。DeepSeek-V4 引入了流形约束超连接(mHC),对相邻 Transformer 块之间的残差路径进行增强。
标准超连接 (Hyper-Connections)
标准超连接(HC)将残差流的宽度扩大一个比例因子 。假设实际网络层输入的隐藏层维度为 ,令 表示第 层之前的残差状态矩阵。HC 引入三个线性映射矩阵:
-
输入映射: -
残差变换: -
输出映射:
残差状态的更新公式为:
其中 为第 层(例如 MoE 层),其输入和输出维度均为 。此设计将残差宽度与实际隐藏层大小解耦。但实验观察到,当层数增加时,HC 容易引发数值不稳定。
流形约束残差映射
mHC 的核心是将残差映射矩阵 约束在双随机矩阵(Doubly Stochastic Matrices,即 Birkhoff 多胞形 )流形上。该约束表示为:
该约束确保映射矩阵的谱范数 的上界为 1,使得残差变换操作呈现非膨胀特性(non-expansive)。这在正向传播与反向传播中增加了数值稳定性。此外,双随机矩阵集合 具有乘法封闭性,适合深层网络堆叠。输入映射 与输出映射 也通过 Sigmoid 函数被限制为非负且有界,防止信号抵消。
动态参数化
这三个线性映射的参数是动态生成的,由依赖输入的动态部分与独立于输入的静态部分组成。给定输入 ,首先对其进行展平并进行 RMSNorm 归一化,得到 。无约束的原始参数矩阵生成方式为:
其中 以及 为可学习权重参数; 负责将 的向量重塑为矩阵; 为静态偏置; 为初始化为小数值的门控因子。
参数约束的实现
生成无约束参数 后,应用 Sigmoid 函数 处理输入与输出映射:
针对残差映射 ,算法利用 Sinkhorn-Knopp 算法将其投影至流形 。首先应用指数函数保证数值为正:,随后交替进行列归一化 与行归一化 :
迭代 次后,得到的矩阵收敛为双随机矩阵 。
2.3 混合注意力架构 (Hybrid Attention with CSA and HCA)
为了处理百万级别的序列长度,注意力机制计算成为主要的延迟点。DeepSeek-V4 设计了压缩稀疏注意力(CSA)与重度压缩注意力(HCA),二者交错配置构成了混合注意力机制。
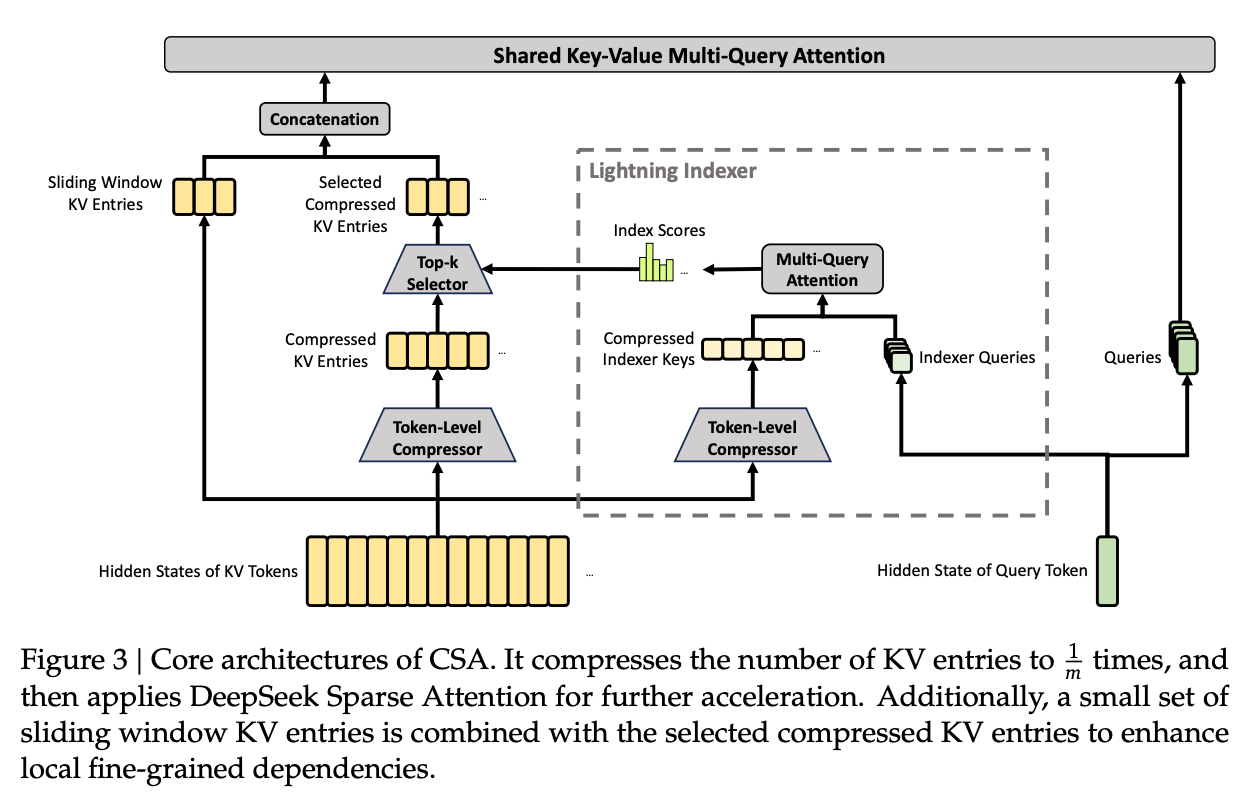
2.3.1 压缩稀疏注意力 (Compressed Sparse Attention, CSA)
CSA 的设计包含压缩与稀疏两部分。它将每 个 token 的 KV 缓存压缩为一个表征,随后采用类似 DeepSeek Sparse Attention (DSA) 的机制,让每个查询 token 仅关注 Top- 个压缩后的 KV 表征。
KV 压缩过程:
给定序列的输入隐藏状态 。CSA 先计算两组 KV 表征 及其压缩权重 ( 为注意力头维度):
这四个矩阵的 矩阵均为可学习参数。接下来,通过滑动窗口将相邻的 个 KV 表征依据权重和位置偏置融合为一个压缩条目 。具体公式使用了 Softmax 进行局部归一化,并结合 Hadamard 乘积()完成特征聚合。最终,序列长度在这一步被缩减为原本的 。
Lightning Indexer 与稀疏选择:
生成 后,需要筛选查询需要关注的 KV 表征。CSA 对 应用相同的压缩操作生成稀疏索引键 ,其中 为索引头维度。
对于查询 token ,通过低秩投影生成索引查询:
索引打分过程发生在查询 token 与在此之前的压缩块之间:
基于得分 ,系统挑选出得分最高的 个压缩 KV 块集合 用于后续的核心注意力计算。
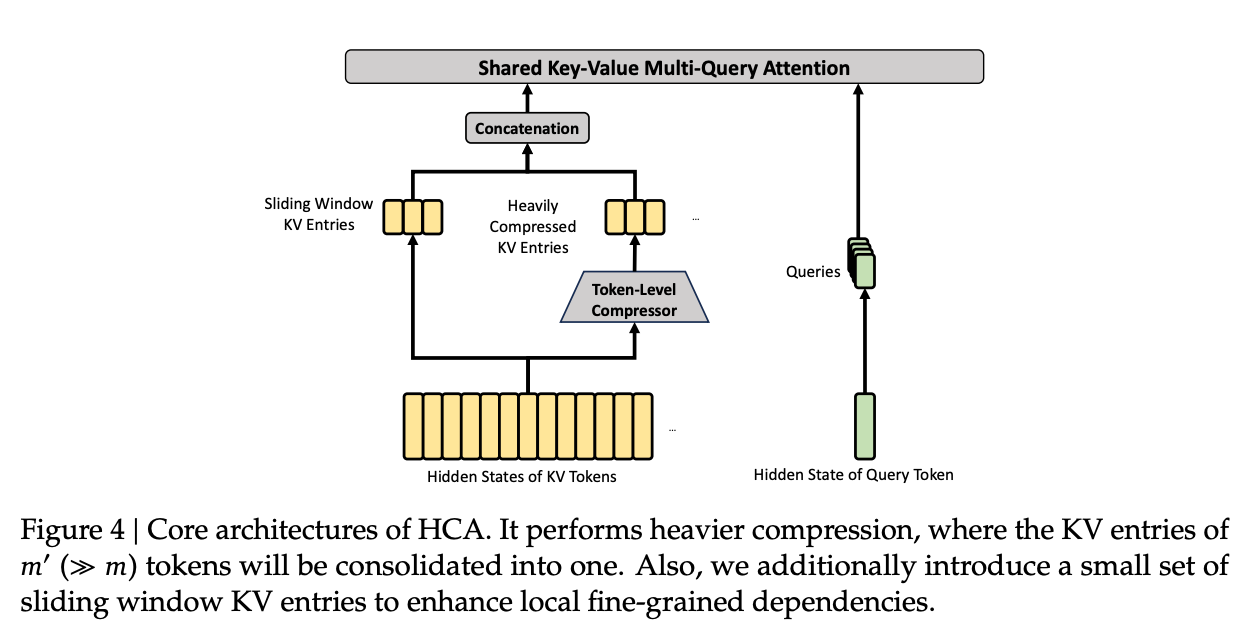
2.3.2 重度压缩注意力 (Heavily Compressed Attention, HCA)
HCA 的核心是执行更高比例的压缩,但不使用稀疏注意力筛选。
压缩过程:
HCA 设置了大于 的压缩率 。其原始 KV 表征 和权重 计算类似 CSA:
随后将连续 个表征压缩为 。由于压缩比率大,序列长度被大幅度缩短至 ,使得执行全量注意力计算在计算力消耗上变得可接受。
共享 KV 的 MQA 与分组输出投影:
无论是 CSA 还是 HCA,在选定或压缩完 KV 表征后,均采用多查询注意力(MQA)机制。在 V4 的设定中,查询头数量 较大。若将 个输出直接投影到 维隐藏层,会带来较高的计算负担。
为此,引入了分组输出投影策略:将 个注意力输出划分为 组。对于每组 ,先将其投影为 维的中间输出 (其中 )。最终将这些中间输出拼接后映射为最终输出 。
2.3.3 其他注意力细节设计
-
查询与 KV 归一化:在核心注意力计算之前,对 Query 的每个头和压缩 KV 的唯一头进行 RMSNorm 处理。该操作防止了注意力 Logits 数值爆炸。 -
部分旋转位置编码 (RoPE) :为 Query 和 KV 的最后 64 维添加 RoPE。为了解决相对位置问题,同时也对核心注意力输出施加负向位置的 RoPE 操作,使输出包含反映查询与 KV 相对距离的信息。 -
滑动窗口分支:由于 CSA 和 HCA 中的查询只能访问其所在的压缩块之前的上下文,会导致局部信息缺失。模型在混合注意力旁附加了一个滑动窗口注意力分支,处理最近的 个未压缩 KV 表征。 -
Attention Sink:在注意力分数计算公式的分母中引入可学习的 sink logits。公式如下:
这允许注意力权重总和不等于 1,在某些情况下逼近 0。
2.3.4 效率分析
混合注意力的 KV Cache 使用混合精度存储方案:针对 RoPE 的维度使用 BF16 精度,其余维度使用 FP8 精度。Lightning Indexer 内部的计算进一步采用 FP4 精度以提升速度。
相较于使用 BF16 精度和 GQA8 配置(Head 维度 128)的基线系统,DeepSeek-V4 在 1M 上下文长度下的 KV Cache 体积缩减至基线的 2% 左右。对于单 token 推理的 FLOPs 消耗,在 1M 上下文中,DeepSeek-V4-Pro 的运算量仅为 V3.2 的 27%。
2.4 Muon 优化器配置
DeepSeek-V4 训练过程中,大规模参数更新采用了 Muon 优化器,小部分模块(嵌入层、预测头、mHC 偏置项与 RMSNorm 权重)维持使用 AdamW。
优化器实现逻辑
每次训练迭代中,Muon 对梯度矩阵进行正交化处理。算法伪代码体现了动量缓冲区的累积、Nesterov 技巧以及正交化缩放:
其中 为复用 AdamW 超参数的缩放因子。
混合牛顿-舒尔茨 (Newton-Schulz) 迭代
Muon 核心的正交化步骤 旨在将矩阵 近似正交化。给定矩阵 ,先进行归一化 确保最大奇异值不大于 1。随后的迭代公式为:
该迭代过程分为两阶段进行共 10 次。前 8 步选用系数 以加速收敛至 1 附近。最后 2 步切换为 使奇异值精确稳定在 1。
由于前述结构设计中通过 RMSNorm 规避了注意力 Logits 爆炸,优化器配置中没有使用 QK-Clip 技术。
3. 分布式系统基础设施
为了支撑万亿参数模型的高效训练与推理,底层系统需要平衡互联带宽、显存以及算力资源。
3.1 细粒度通信与计算重叠
专家并行(Expert Parallelism, EP)是 MoE 模型加速的基础,但跨节点通信开销明显。DeepSeek 团队提出了通过算子融合隐藏通信延迟的细粒度流水线。
在 V4 的架构中,MoE 层的执行分为四个阶段:Dispatch(通信)、Linear-1(计算)、Act 与 Linear-2(计算)、Combine(通信)。通过将专家划分为多个波次(waves),当某一个波次的专家数据 Dispatch 完成后,即刻开始当前波次的 Linear-1 计算,同时并行处理下一个波次的 Dispatch 通信。
系统分析指出,实现全计算通信掩盖的临界点取决于计算通信比。对于 V4-Pro 模型,每个 token-expert 对消耗 6 FLOPs 的算力,但仅需要 3 字节的通信(基于 FP8 和 BF16)。算力与带宽的需求比例大致为 6144 FLOPs/Byte,这为硬件设计与选型提供了参考阈值。
3.2 基于 TileLang 的算子库开发
为了应对数百个定制化操作的实现,开发团队使用领域特定语言(DSL)TileLang 开发融合内核。
降低调用开销:通过 Host Codegen 机制,将设备端 Kernel 与主机端 Launcher 一同生成。通过底层 C++ 框架直接实现参数绑定与运行时约束检查,规避了原生 Python 运行时带来的延迟。每次调用的 CPU 验证耗时从数百微秒降至一微秒以内。
SMT 求解器优化:在编译期的布局推断和内存竞争检测中,集成了 Z3 SMT 求解器(无量词非线性整数算术 QF_NIA)。求解器处理复杂的张量索引算术问题,使编译器能够进行可变张量形状向量化与指令简化等复杂优化。
IEEE-754 一致性:禁用编译器默认的 fast-math,采用符合 IEEE 规范的内联指令,确保前向传播、反向传播与推理结果达到位级别的严格复现。
3.3 批次无关与确定性计算库
Attention 批次无关性:在注意力计算中,如果为平衡 SM 负载而切分序列(Split-KV),会引起波峰量子化问题。DeepSeek 开发了双核计算方案。第一个核在单个 SM 内处理全序列;第二个核用于尾部波次,通过线程块集群的分布式共享内存跨 SM 交换数据,以保证累加顺序的一致性。
mHC 确定性矩阵乘法:mHC 存在输出维度极小(仅为 24)的矩阵乘法,若使用常规 Split-K 算法会导致非确定性。工程上的解决方案是将各块的拆分部分单独输出,再使用独立的算子进行确定性归约。
后向传播确定性:在传统的 Attention 反向传播中,采用 atomicAdd 累加 KV 梯度会导致浮点相加的不结合律问题。为此,系统为各 SM 分配独立缓冲区,在局部累积后再进行全局确定性求和。MoE 反向传播中也加入了 Token 顺序预处理和缓冲区隔离机制。
3.4 FP4 量化感知训练 (QAT)
进入后训练阶段,引入量化感知训练使模型适应低精度。主要对象是占据大量显存的 MoE 专家权重,以及 CSA 中的 QK 计算路径。
在训练的前向过程中,将优化器维护的 FP32 主权重转换为 FP4,再无损反量化为 FP8 参与计算。由于 FP8 的动态范围宽于 FP4,只要缩放因子满足阈值要求,反量化过程不会造成信息丢失。这使得现有的 FP8 框架能直接复用于 FP4 QAT 阶段,且无需修改后向传递,梯度直接更新至 FP32 权重。
4. 训练框架优化
4.1 Muon 的高效实现
Muon 优化器要求计算整块梯度矩阵以执行奇异值相关操作。这与传统 ZeRO 将参数分片到多卡的逻辑相冲突。
对于稠密参数,系统采用背包算法将参数矩阵分组,限制每组的大小,并在组内补齐,实现低额外开销的 Reduce-Scatter。
对于 MoE 参数,由于各专家独立,直接将全层内专家的投影权重进行拼接平铺,避免拆分逻辑上不可分割的矩阵。此外,为了压缩通信带宽,计算中使用了随机舍入(Stochastic rounding)将跨节点的梯度通信精度降为 BF16。同时采用两阶段通信(All-to-all 加本地求和)代替环状通信,减小了低精度累加误差。
4.2 长上下文的上下文并行 (Contextual Parallelism)
标准的序列并行(CP)在处理压缩注意力时面临边界切断问题,因为每个 GPU 分配到的 token 可能不满足整数个压缩块。
为此设计了双阶段通信机制:
-
节点 将结尾残留的非压缩 KV 数据发送给节点 。节点 接收后与自身的头部 token 融合进行压缩,并填充缺失部分以统一长度。 -
执行全局的 All-gather 收集各节点压缩后的 KV 块,并在最终用融合操作进行统一裁剪拼接。
5. 推理框架设计
在 1M 上下文处理中,异构 KV Cache 结构对现有的 PagedAttention 框架提出了挑战。
-
异构数据表示:混合注意力产生了三种状态的缓存:Lightning Indexer 缓存、CSA/HCA 压缩缓存,以及 SWA 滑动窗口产生的未压缩序列状态缓存。 -
SWA 的状态缓存机制:SWA 只需最近的 个 token 信息,而 CSA 还需要保留未能组成一个压缩块的“尾部 token”。推理引擎将这两者合并作为一种空间状态来管理,为每条序列预分配固定大小的状态缓存块。 -
磁盘 KV Cache:针对 Prefix 复用的场景,将长序列的压缩 Cache 存储在外部介质中。对于体积庞大且不作压缩的 SWA Cache,提出三种管理方案进行资源权衡: -
全缓存:零计算冗余,但对 SSD 存储系统的随机写入压力大。 -
周期性 Checkpoint:每隔一定周期保存,加载时重计算中间少部分。 -
零缓存:完全依赖上层的 CSA/HCA 缓存,加载时仅重计算最近的 个 token。
-
6. 预训练设置
预训练数据规模超过 32T token,内容涵盖去除了模板化文本的网页内容、数学编程语料库,以及高比例的科学论文和技术报告。模型采用 Token 级别与样本级别的注意力掩码。
DeepSeek-V4-Flash(284B 参数)使用 43 层,隐藏维度 4096。DeepSeek-V4-Pro(1.6T 参数)使用 61 层,隐藏维度 7168。
在训练过程中遇到了大规模 MoE 模型的典型不稳定性问题,出现了 Loss 突增的现象。官方分享了两种工程经验:
-
预见性路由 (Anticipatory Routing) :实验发现,当前权重更新与路由分配强同步会引发负循环。系统将两步分离,在 时刻使用 时刻的路由分布来分发当前的数据。这种通过异步流水线缓解波动的方法在不增加计算的前提下维持了稳定。 -
SwiGLU Clamping:对激活函数进行数值截断,将 SwiGLU 中的线性分支限制在 之间,门控分支上限设为 10,有效削减了数值异常。
7. 后训练 (Post-Training)
后训练是整个 V4 框架演进的重点,完全放弃了原有的混合强化学习策略,转换为两阶段:领域专家独立训练与同策略知识蒸馏(OPD)。
7.1 专家训练与生成式奖励模型
各个领域专家模型首先基于高质量 SFT 数据确立基础能力,接着基于 GRPO (Group Relative Policy Optimization) 算法进行强化学习。
在 RL 阶段,不同模式(Non-think, Think High, Think Max)具有不同的推理思考时间。模型采用了专门的 <think> 标签输出中间逻辑。
放弃标量奖励模型:在难验证任务(如逻辑推理和代码调试)上,传统的标量奖励模型无法提供稳定的评价。V4 系列使用生成式奖励模型(GRM),即让正在训练的 Actor 网络同时担任判断者的角色。由于网络共享了生成分布的逻辑,可以对解题轨迹进行自我评估,这种范式依赖极少量的人类标注即实现了对复杂推理逻辑的评价。
工具调用体系:针对 Agentic 环境,模型转用 XML 风格定义工具,通过引入专用 token <|DSML|>,降低了符号转义错误率。另外,设计了在整个会话上下文中保持持续推理记忆(Interleaved Thinking)的策略,将长达百万 token 上下文的工具反馈和推理链条连贯保存,不作截断。
对于需要前端过滤意图的简单任务,增加了一组快速指令 (Quick Instruction) token。将其直接插入上下文开头,重用原有的 KV Cache,从而实现了查询意图识别、权威性判断等操作的并行,减少了 TTFT(首字返回时间)。
7.2 同策略知识蒸馏 (On-Policy Distillation, OPD)
在获得了涵盖数学、代码、通用指令等多个方向的独立专家后,如何合并专家权重以避免传统权值插值引发的能力下降是关键。V4 采用多教师 OPD 架构。
给定 个专家 ,学生网络 的优化目标为:
其中 为专家权重。模型在学生生成的样本轨迹上计算逆 KL 散度。此过程避免了单点优势估算的梯度方差偏大问题。由于采用了完整的词表 Logit 分布,蒸馏效果更平稳逼真。
全词表 OPD 基础设施扩展
实现千万级词表的 KL 散度计算会造成显存灾难。系统进行了以下优化:
-
所有教师网络参数卸载至分布式存储,前向传播时采用类 ZeRO 方式按需切片加载。 -
在教师计算前向通过网络时,不生成庞大的最终 Logits,而是仅缓存最后一层隐藏状态。只有在反向传播计算损失时,才重新流式生成 Logits。 -
按教师 ID 排序批次数据,确保单批次内只有极少部分预测头权重被载入显存。
7.3 RL 与 OPD 推理服务扩展
在强化学习的 Rollout(轨迹采样)环节,集群需要处理尾部响应带来的低利用率问题。
框架引入了可抢占与容错的 Rollout 服务。利用 Token 级别的预写日志(Write-Ahead Log, WAL)记录已生成的文本,推理任务可以被调度器随时抢占。恢复时直接读取 WAL 和持久化的 KV Cache 恢复现场。此策略从根本上规避了“重新生成会导致序列偏向于变短”的长度偏置陷阱。
7.4 Agentic AI 沙盒设施 (DSec)
应对复杂 Agent 测试环境需求,团队开发了 DSec 弹性计算平台。DSec 基于单一的 Python SDK 提供四种运行形态:无状态函数调用(Function Call)、全兼容容器(Container)、微型虚拟机(microVM)和全量虚拟机(fullVM)。
借助 EROFS 文件系统实现了基础镜像的按需懒加载。支持内存重复数据删除合并(Memory Reclamation)以提高单机并发密度。其完整的轨迹日志功能允许精确记录、快进或重新回放 Agent 与系统的所有交互操作。
8. 实验与评测结果
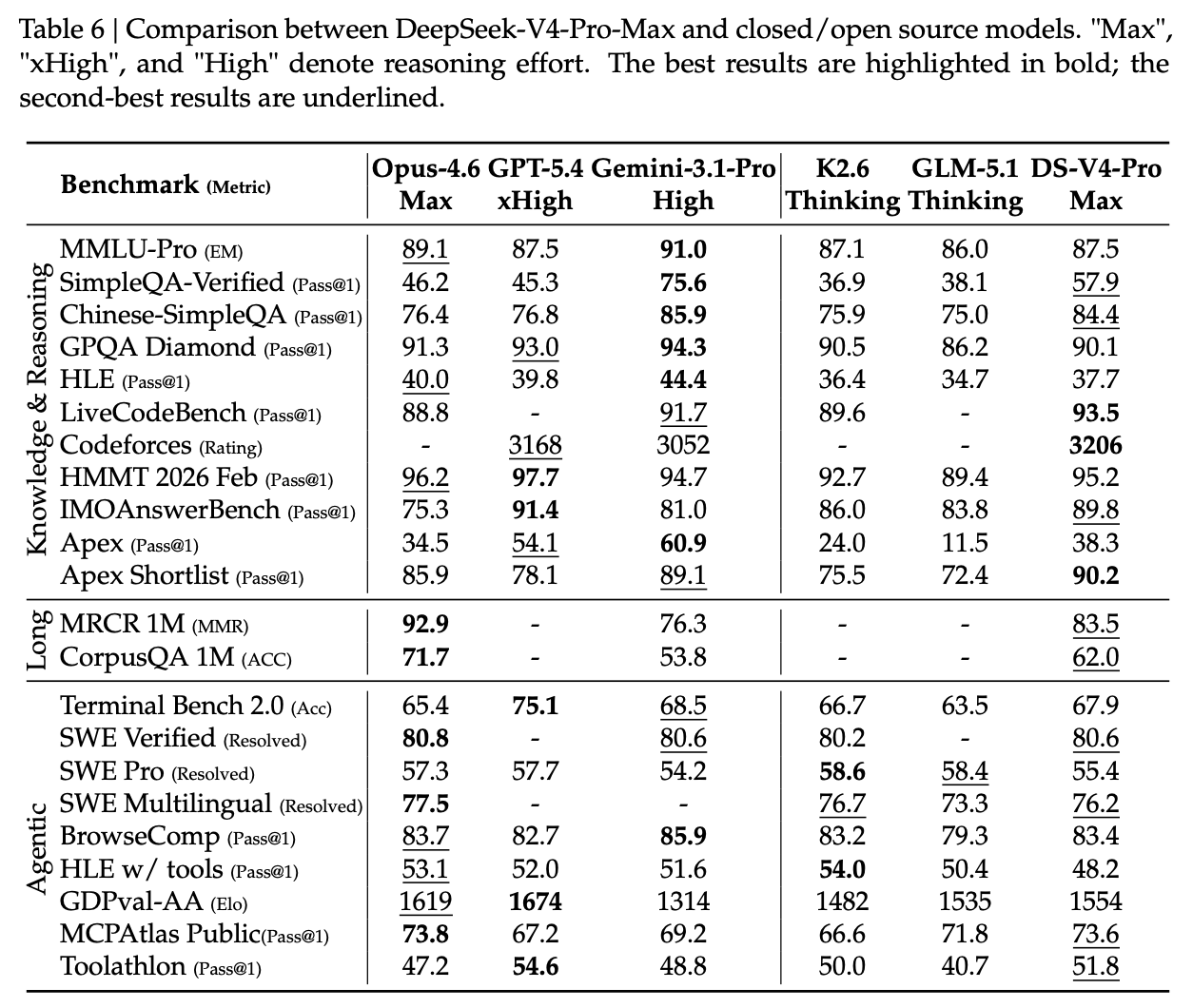
-
世界知识:DeepSeek-V4-Pro 的 Max 模式在 SimpleQA 和 Chinese-SimpleQA 上确立了新标杆。尽管在 MMLU-Pro 和 GPQA 等测试上略逊于 Gemini-3.1-Pro 闭源版本,但已经显著优于此前的同级别开源系统。 -
推理与数学:在提供足够的测试时算力(Test-time scaling)即开启 Max 模式时,V4-Pro 的表现在诸多公共指标上超越了之前的最高基准模型。形式化证明测试中(如 Lean 4),代理环境下的求解到达了证明完善的状态。 -
长上下文 (1M Token) :在 MRCR 测试中,128K 以内的上下文检索命中率平稳。即使拉长至百万 Token,其信息找回精度下降依然在可用范围内。 -
代理功能 (Agent) :在代码编辑(SWE-Verified)、终端交互(Terminal Bench)和环境规划测试上表现出通用性。但在高维多轮约束中文场景(白领文本撰写、多轮排版)中,由于遵循具体指令存在小概率疏漏,在人类双盲评估中与部分顶级闭源模型存在互有胜负的局面。
9. 结论
DeepSeek-V4 证实了通过在网络架构层面上引入混合压缩注意力机制,可以使得百万级长文本上下文在极高的计算效率下运转。通过一系列对底层框架、优化器算法及存储系统的重新设计,万亿参数模型的预训练、基于生成式奖励模型的强化学习及基于完整词表的专家知识蒸馏具备了实战可行性。
模型的进一步演进可能会聚焦于简化当前相对复杂的注意力与架构组件组合。同时,流形约束超连接以及优化器的动态削峰机理依然存在值得理论探讨的空间。总体而言,DeepSeek-V4 推进了模型架构在高可用与长序列领域的边界探索。
更多细节请阅读原文。
往期文章:

