让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping -
论文链接:https://arxiv.org/pdf/2604.11297
TL;DR
大语言模型在进行强化学习(特别是基于可验证奖励的强化学习)时,策略常常会陷入一种狭窄的行为模式,导致模型在不同的采样轨迹中反复生成相似的错误推理。传统的基于当前策略分布的熵正则化方法无法有效抑制这种跨历史轨迹的重复失败模式。今天解读的由 OpenMOSS 团队发布的论文《The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping》提出了一种名为 MEDS(Memory-Enhanced Dynamic Reward Shaping)的记忆增强动态奖励重塑框架。
该方法通过复用模型前向传播产生的层级逻辑值(logits)作为推理轨迹的特征表示,并使用基于密度的聚类算法(HDBSCAN)在历史采样中识别频繁出现的错误模式。对于落入高频错误聚类的样本,MEDS 会施加额外的惩罚,从而在减少重复错误的同时促进策略在更广阔的空间中探索。在 Qwen3 和 Qwen2.5-Math 等模型上的实验表明,MEDS 提升了数学推理基准测试中的 pass@1 和 pass@128 指标,并且增加了采样过程中的行为多样性。
1. 背景
随着大语言模型(LLM)基础能力的提升,强化学习(RL)在多个垂直领域(尤其是代码生成和数学推理)取得了进展。通过引入奖励信号,无论是基于规则的精确匹配评估(Rule-based Evaluation)还是基于代理模型的打分(Proxy Models),LLM 可以在采样阶段和基于梯度的优化阶段之间进行迭代更新。在这一框架下,模型性能优化的目标是最大化期望回报,因此奖励评分结构的设计成为引导模型行为的途径。
目前广泛采用的范式是带有可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)。然而,这种同策略(on-policy)优化存在一个已知的失效模式:随着训练的进行,策略往往会坍缩到一组狭窄且刻板的行为中。这种退化现象不仅会导致模型生成高度重复的回复,削弱有效的状态空间探索,浪费同策略样本,还会使模型陷入自我强化的错误推理轨迹中。
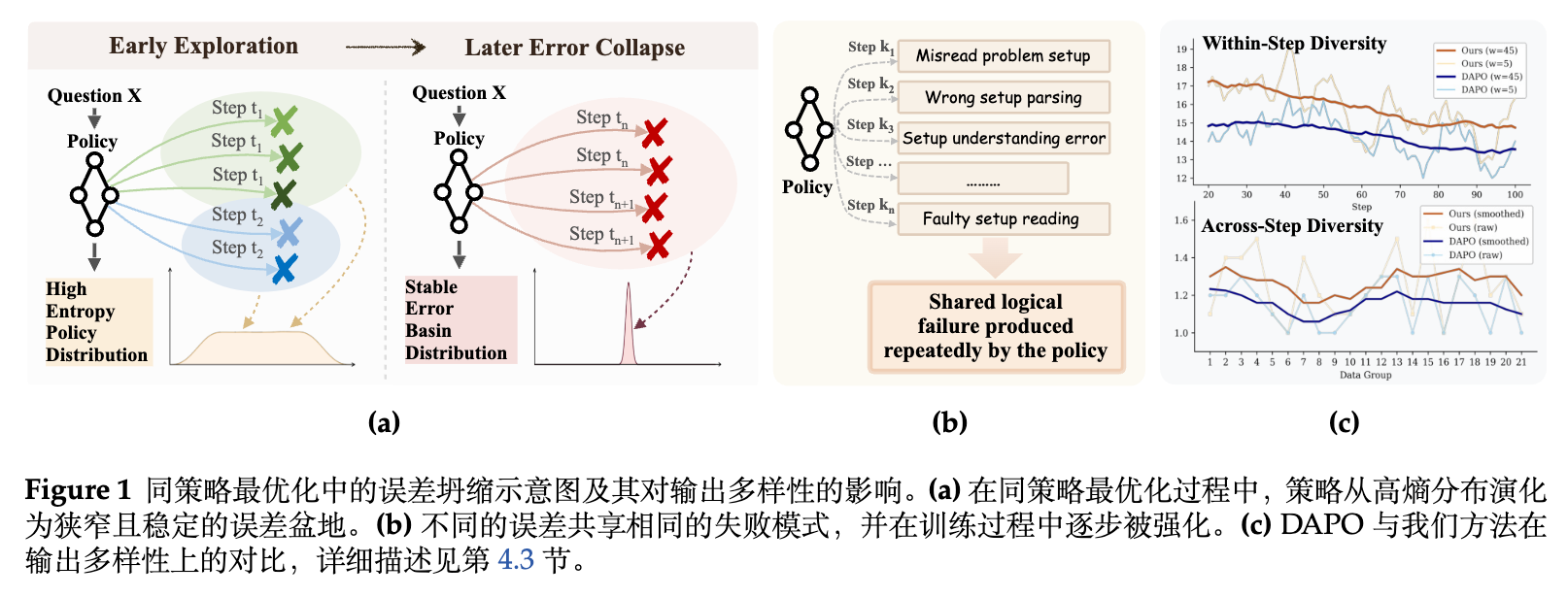
为了缓解这一问题,现有的一些研究引入了熵正则化(Entropy Regularization),通过在当前策略分布层面注入随机性来促进输出多样性。此外,也有部分研究通过 KL 散度惩罚来限制策略偏离参考模型的程度。但是,在 LLM 的复杂推理任务中,这种仅停留在分布层面的随机探索往往是不够的。由于动作空间庞大,一旦训练陷入特定的错误模式(即图 1 所示的“稳定错误盆地”),策略会在后续的步骤中通过采样略微不同的推理表达来反复重现相同的逻辑错误,使得模型在经历了多步优化后依然被困在该模式中。
人类在学习过程中,如果反复犯同一种错误,往往会在心理上对自己施加更重的惩罚,以强化对该错误路径的规避。受此启发,本文作者提出,不应仅依赖静态的奖励函数,而应引入动态的奖励机制,显式地将历史错误模式纳入奖励建模中,让策略能够识别并避开反复出现的失败行为。
2. MEDS 核心思想与框架概览
为了实现上述目标,作者提出了 MEDS(Memory-Enhanced Dynamic Reward Shaping)框架。与传统的强化学习方法独立地在当前批次(batch)内分配奖励不同,MEDS 动态地记录历史错误模式,并对重复的失败路径施加递增的惩罚。
该机制有两个主要作用:
-
促进顽固错误的修正。 -
鼓励模型跳出局部最优,增强在复杂解空间中的探索。
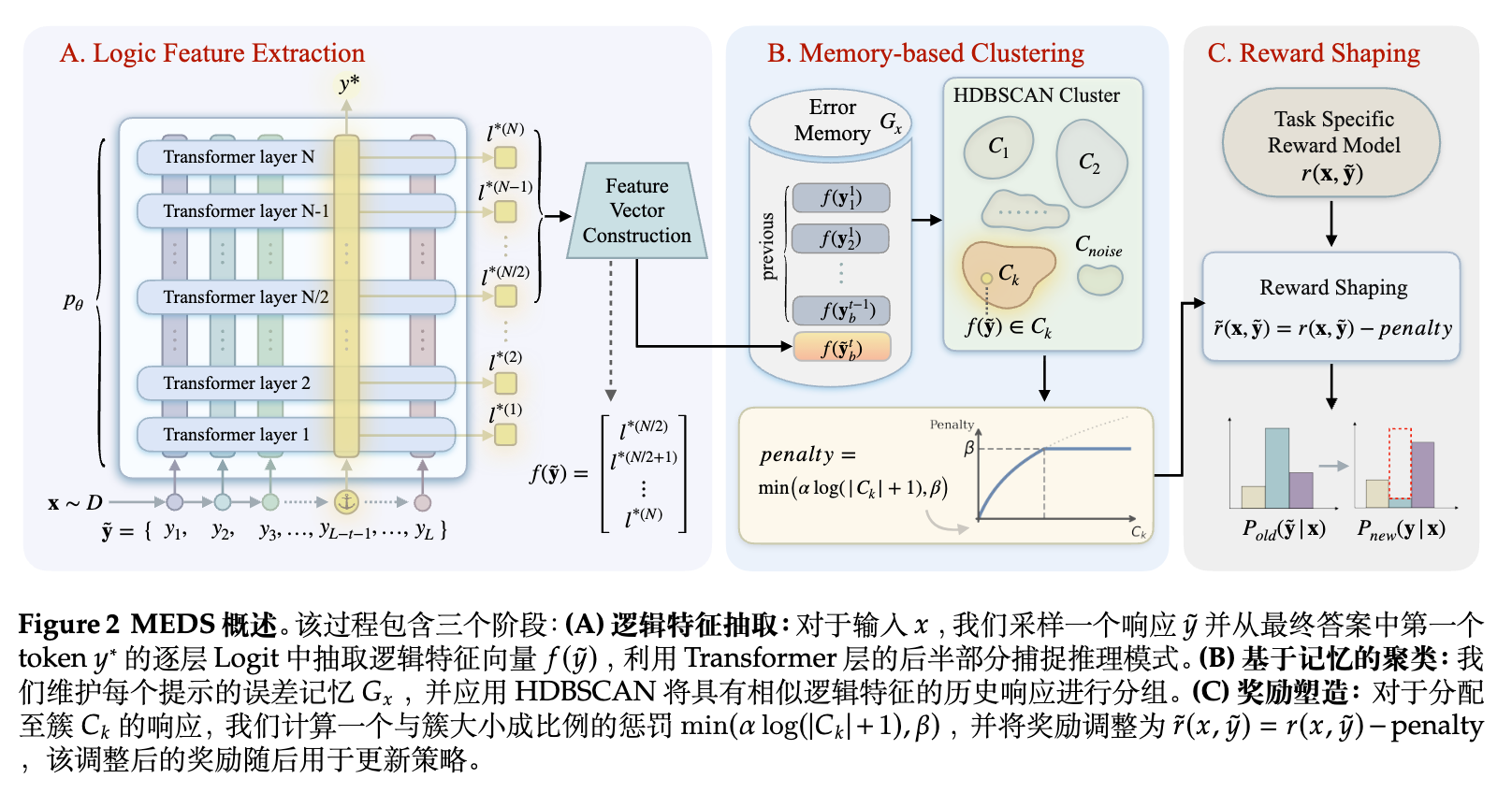
在具体实现上,MEDS 包含三个主要阶段,其整体架构如占位符所示:
-
逻辑特征提取(Logic Feature Extraction):
为了在不引入大量额外计算开销的前提下表征模型的隐式推理轨迹,MEDS 复用了模型前向传播过程中产生的层级逻辑值(layer-wise logits)。对于给定的输入 和采样得到的回复 ,方法提取最终答案的第一个 token 在 Transformer 后半部分层的 logits 向量,构建出表征逻辑特征的向量 。 -
基于记忆的聚类(Memory-based Clustering):
对于每个具体的提示(prompt),系统维护一个错误记忆库 ,并在整个训练过程中在线更新。通过引入 HDBSCAN 聚类算法,该记忆库能够自适应地捕获错误类型及其密度结构,将具有相似逻辑特征的历史回复分到同一聚类中。 -
奖励重塑(Reward Shaping):
根据聚类结果,训练目标会根据失败模式的复现频率调整惩罚强度。具体而言,对于被分配到聚类 的回复,计算一个与其聚类大小 相关的惩罚值,从而得到调整后的奖励 ,用于后续的策略更新。
3. 方法详述
3.1 预备知识与强化学习目标
给定输入 ,大型语言模型被建模为策略 ,用于生成回复序列 ,其中 表示完整的回复, 表示在第 步生成的 token。回复生成后,会经过评估并映射为一个标量奖励,奖励函数定义为 。
在实际优化中,通常采用带有 KL 正则化的目标函数,并在置信区间(trust region)内最大化期望回报。对应的训练目标可以表示为:
其中, 是参考策略,用于约束参数更新空间, 是控制约束强度的正则化系数。
3.2 逻辑特征提取
在设计动态奖励时,关键在于如何定义不同回复之间的相似度关系。为了保证计算效率,作者直接复用了每个回复在生成过程中的层级 logits。
假设最终的答案部分对应的 tokens 为 。我们令 表示最终答案区域的第一个 token(例如,在格式要求把答案放在 \boxed{} 中时,\boxed{ 后的第一个实体字符)。对应地,在第 层的 logits 表示为 ,其中 是词表大小。
方法中提取该 token 位置对应的 logits ,并将其在多个不同的网络层之间进行拼接。这种做法的直觉在于:最终答案的 logits 演化依赖于不同层之间特征激活的积累,因此包含了关于模型内部推理过程的信息。由于较浅的网络层通常建模较为简单的语义信息,较深的网络层则处理更复杂的逻辑,因此提取后半部分层的 logits 是合理的选择。
特征表示向量的构建公式为:
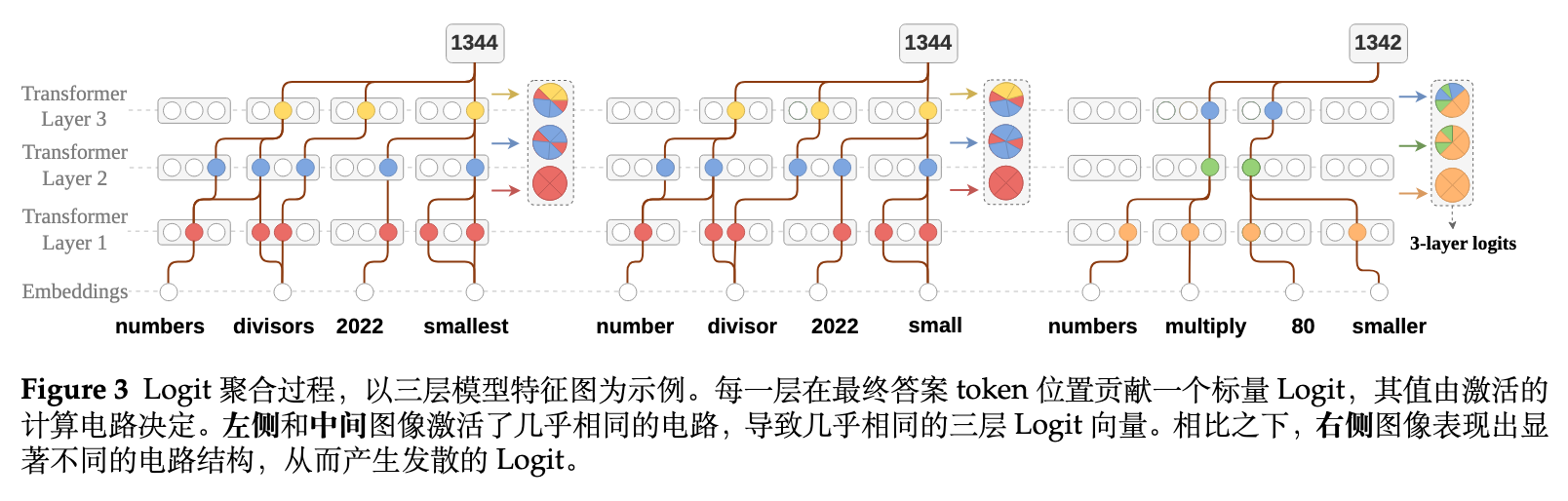
如图 3 所示,网络层的激活计算回路(computational circuits)决定了 logits 的值。如果两个回复虽然文本表述不同,但底层激活了相似的计算回路,它们的层级 logits 向量将会具有高度相似性。相比于直接进行字符串匹配,这种层级特征能反映更本质的逻辑相似度。
3.3 基于聚类的奖励重塑
基于构建好的回复特征表示,系统可以计算出表征历史采样行为的指示函数,并进行奖励重塑。对于每一个特定的提示 ,维护一个包含所有历史轮次中采样得到的回复的特征表示集合:
其中 表示每个提示在单次采样中的回复数量, 表示当前的训练轮数(epoch)。
随后,对该集合应用 HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)聚类算法:
这里 表示第 个聚类簇,聚类的数量 是由算法动态决定的。HDBSCAN 的优势在于它能够处理不同密度的聚类,并将不属于任何明确模式的离群点归入 ,这契合了大语言模型在探索中产生的长尾错误分布。
对于一个当前评估的回复 ,假设其特征向量 被分配到了聚类 中。 代表该聚类包含的样本数量。为了实施惩罚,作者定义了一个关于聚类大小单调递增的指标函数,并以此调整原始的奖励值:
公式中, 是控制惩罚强度的缩放超参数, 是设定惩罚上限的超参数。该调整后的奖励 会被传递给 RL 算法用于后续的策略更新。
4. 理论分析:惩罚重复错误的优化收益
为了论证上述经验设计的合理性,论文的附录 B 提供了相关的理论证明。理论部分分析了在重复错误上施加额外惩罚对期望回报(Expected Return)的具体影响。
定理 1(及附录定理 2)内容概述:
假设存在两种不同的奖励信号, 以及 。令 和 分别表示在这两种奖励信号下更新后的策略分布。令任务相关的期望回报为 。那么存在以下不等式:
其中 是重复惩罚系数。 表示重复错误的次数指示器,大于零的值表示该错误 在过去已经被重复采样过。函数 是任务特定的评分函数, 随错误发生次数单调递增。
证明过程解析:
为了清晰起见,证明在固定的输入 处逐点展开,并假设 是有限集。根据模型设计,额外的惩罚只针对重复错误施加,因此满足:
即重复次数较多的回复在原始任务奖励下的得分不会更高(通常都是失败的样本)。
对于任意评分信号 ,带有 KL 正则化的单步策略更新可以表示为如下优化问题:
通过拉格朗日乘子法求解约束 ,优化器给出的解呈现吉布斯分布(Gibbs form)的形式:
分别代入 和 (其中 ),可以得到策略分布 和 。
定义权重衰减函数 。对于固定的 ,两个策略之间存在以下关系:
定义在特定 下,策略 的期望任务奖励为 。使用上述策略转换公式,可以计算出:
因此两者的差值为:
由于分母 ,只需证明协方差 。
令随机变量 且 。注意到 是关于 的非增函数。根据此前的约束 , 也是关于 的非增函数。
根据切比雪夫重排不等式(Chebyshev's rearrangement inequality),两个单调性相同的函数的乘积的期望,大于等于这两个函数期望的乘积:
应用全期望公式(Tower property),可得协方差大于等于零。因此对于所有的 ,都有 。最后对输入分布 取期望,得出 。
这一理论证明给出了清晰的物理直觉:被重复采样的错误在当前策略下占据了较高的概率质量,而增加额外的惩罚有助于重新分配这些概率。由于惩罚仅作用于特定的错误路径,从优化任务目标(Task-specific scoring function)的角度来看,这种机制促使概率质量向可能获得正确答案的区域转移,从而保证了期望回报不降。
5. 实验设置
5.1 基础模型与数据集
实验在三个不同规模或架构的模型上进行:
-
Qwen3-1.7B -
Qwen3-8B -
Qwen2.5-Math-7B
其中 Qwen3-8B 和 Qwen2.5-Math-7B 分别代表具备和不具备显式长推理过程(Reasoning process)的模型,而 Qwen3-1.7B 用于验证方法在不同参数规模下的有效性。
训练语料由 DAPO-Math-17K 数据集与 MATH 数据集中难度等级为 3 到 5 的题目合并构建而成。所有的数学问题都统一格式化为 Qwen-Math 的模板形式,强化学习训练基于 verl 框架实现。
5.2 强化学习基准与训练目标
实验选取了几个主流的强化学习算法作为基线:
-
Base: 未经 RL 微调的初始模型。 -
GRPO: 遵循 DeepSeekMath 的官方配置,带有组相对优势(group-relative advantage)和 KL 散度惩罚。 -
DAPO: 使用非对称阈值解耦裁剪(decoupled clipping with asymmetric thresholds),并完全移除 KL 散度惩罚项。 -
GRPO w/ Entropy Adv: 在 GRPO 基础上,根据 Cheng 等人的方法,在优势估计中加入基于 token 的熵奖励(per-token entropy bonus)。
具体的目标函数公式在论文附录 A 中定义:
GRPO 目标函数:
DAPO 目标函数:
为了公平对比,MEDS 是在 DAPO 的基础上进行扩展的。
5.3 MEDS 的具体实现参数
对于每个提示,系统将错误样本在 Transformer 最后 14 层的 logits 进行拼接,应用 L2 归一化,然后在该特征空间中使用 HDBSCAN 算法。聚类配置方面,设置最小聚类大小(minimum cluster size)为 2,最小样本数(minimum number of samples)为 1,采用欧氏距离作为度量。
关于惩罚系数:在 Qwen3-1.7B 和 Qwen2.5-Math-7B 上设置 , ;在 Qwen3-8B 上设置 , 。训练中提示级别的批量大小(prompt-level batch size)为 512,每个提示采样 16 个回复(rollouts)。最大上下文长度等超参数根据不同模型作了针对性设定。
5.4 评估基准
使用涵盖不同难度和问题类型的 5 个数学推理基准进行评估:
-
AIME24 -
AMC23 -
MATH500 -
Minerva -
OlympiadBench
在 pass@k 评估中,采样数 设置为 128,测试温度(temperature)为 1.0,top-p 为 1.0。
6. 实验结果与分析
6.1 主实验结果
下表展示了三个模型在 5 个数据集上的测试表现:
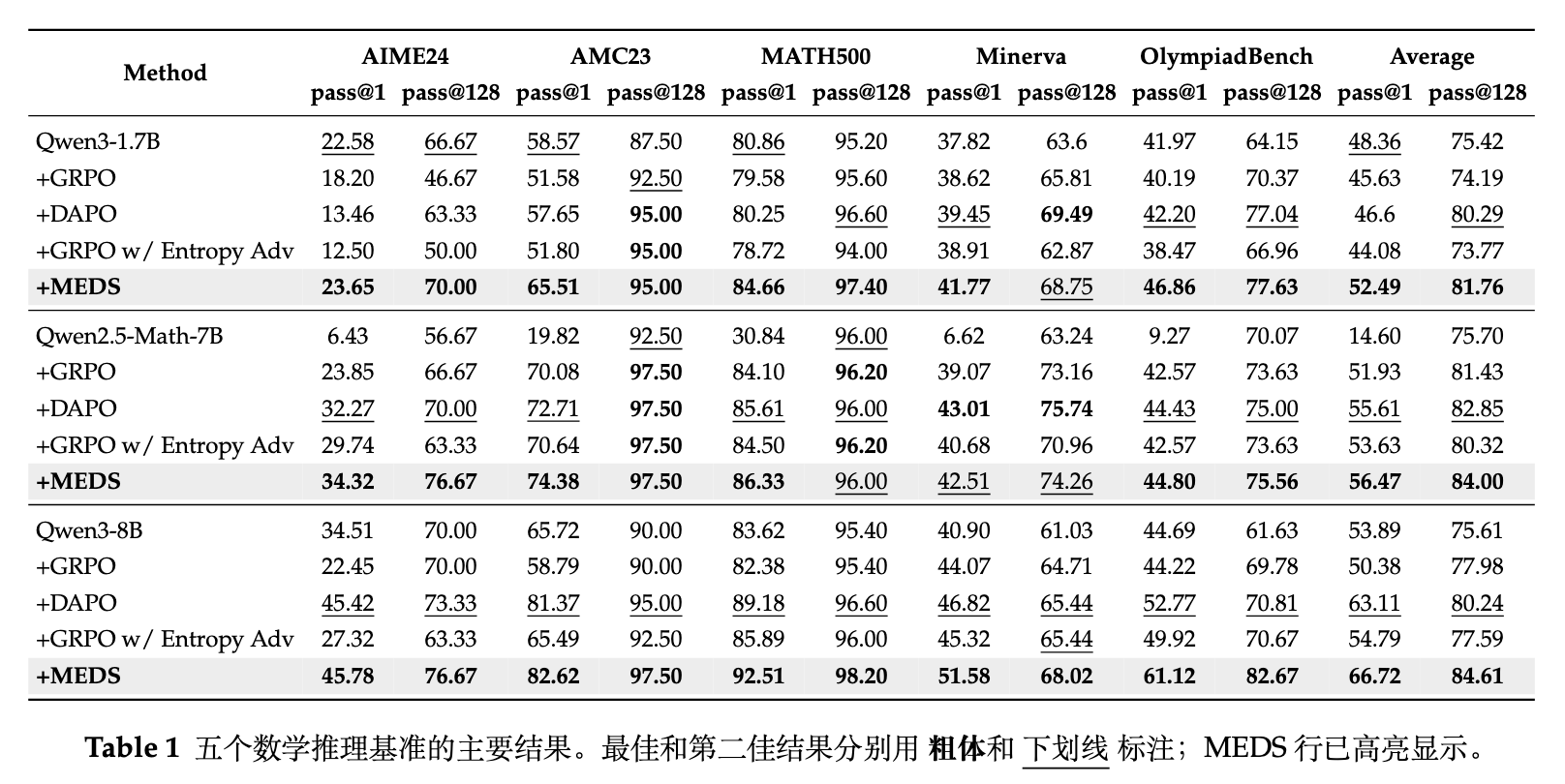
从结果中可以看出,MEDS 在各个基准上均取得了一致的提升。
-
对于 Qwen3-1.7B: MEDS 的平均 pass@1 达到 52.49,pass@128 达到 81.76,明显优于 DAPO (46.60 / 80.29)。 -
对于 Qwen2.5-Math-7B: MEDS 的平均 pass@1 为 56.47,pass@128 为 84.00,同样超越了对应的基准模型表现。 -
对于 Qwen3-8B: 这是表现最为显著的设置。相比于 DAPO,MEDS 在 AIME24 的 pass@128 指标上从 73.33 提升至 76.67,在 OlympiadBench 上的 pass@128 更是从 70.81 大幅提升至 82.67(相对增长达到 17%)。这表明 MEDS 带来的收益会随着基础模型能力的增强而进一步放大。
此外,论文给出了 pass@k ()的曲线图。
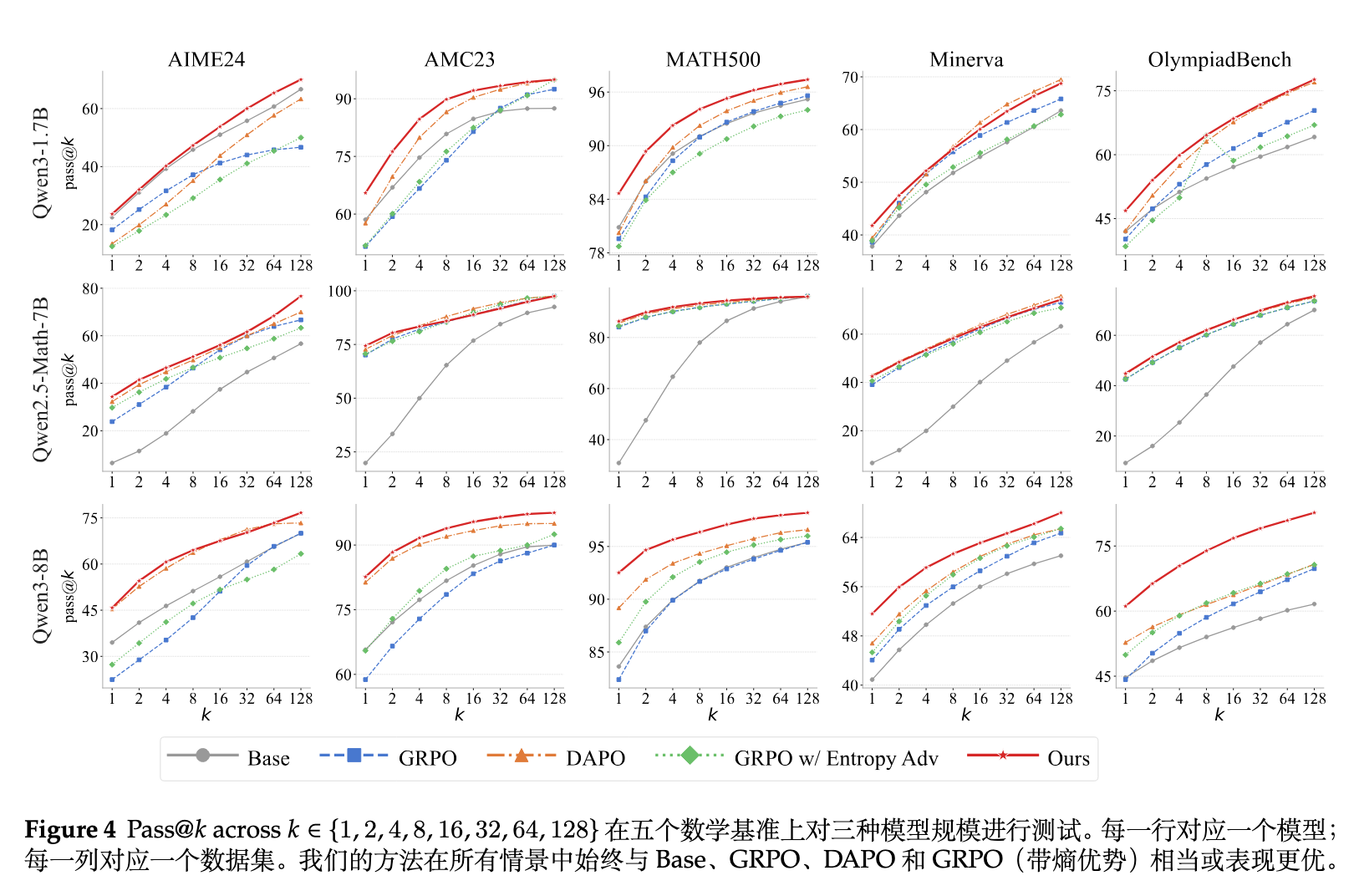
曲线图直观地反映了当允许模型进行多次尝试时,MEDS 能够在更大的采样空间中找到正确答案,这证明了模型避免了在特定的局部错误区域陷入死循环,探索的有效性得到了实质性的增强。
计算开销方面,在 Qwen2.5-Math-7B 上运行 50 个 step,MEDS 耗时 8.46 分钟,运行 100 个 step 耗时 9.73 分钟;而对应的 DAPO 耗时分别为 8.00 分钟和 8.95 分钟。引入的聚类和特征计算开销比例较小,在工程实践中处于可接受的范围。
6.2 对探索行为的影响
为了深入理解 MEDS 是如何改变模型推理过程中的探索行为的,研究者从两个维度进行了衡量:基于大语言模型的评估(行为视角)以及基于 logits 结构的统计分析(表征视角)。
6.2.1 基于大语言模型(LLM-as-a-Judge)的多样性评估
作者设计了 步内多样性(Within-Step Diversity) 和 跨步多样性(Across-Step Diversity) 两个指标,使用 Claude-Haiku-4.5 作为裁判模型。
-
步内多样性: 衡量同一训练阶段下,针对同一个提示生成的多条轨迹的多样性。在第二个 epoch 期间(大约 step 20 到 100),在每个 step 为 DAPO 和 MEDS 随机采样组别,评估它们在同一组内的解题思路是否存在差异。 -
跨步多样性: 评估模型在训练后期生成的轨迹是否展现出相较于前期轨迹而言的新颖推理模式。构建步数跨度约等于一个 epoch 的数据组,让评价模型比较后期的输出是否引入了新的解法路径。
论文的图 1(c)展示了这部分的结果,MEDS 在这两个指标上的得分均高于 DAPO,说明其能持续促使模型输出不同风格的逻辑路径。
附录 D 中详细列出了评测所使用的 Prompt。例如,步内多样性的 Prompt 要求评价模型独立对每个回答组内部的差异性在 1 到 5 分之间打分。1 分表示所有回答在推理路径和最终结论上几乎完全一致;5 分表示回答在方法、质量或结论上存在根本性差异。评判的标准明确指出需要考察“是否使用了相同的数学方法或策略”。
6.2.2 表征视角的分析:Top-1 Eigen Ratio
为了从底层特征角度证实多样性的增加,作者进一步分析了存储 logits 的协方差结构。令 表示存储的 logits 特征向量的协方差矩阵,其特征值按降序排列为 。
Top-1 Eigen Ratio 定义为:
直观上, 衡量了在 logit 空间中由第一主成分方向解释的方差占比。该比值越小,说明特征向量在表示空间中分布得越均匀,而不是集中于某单一主导的错误方向。
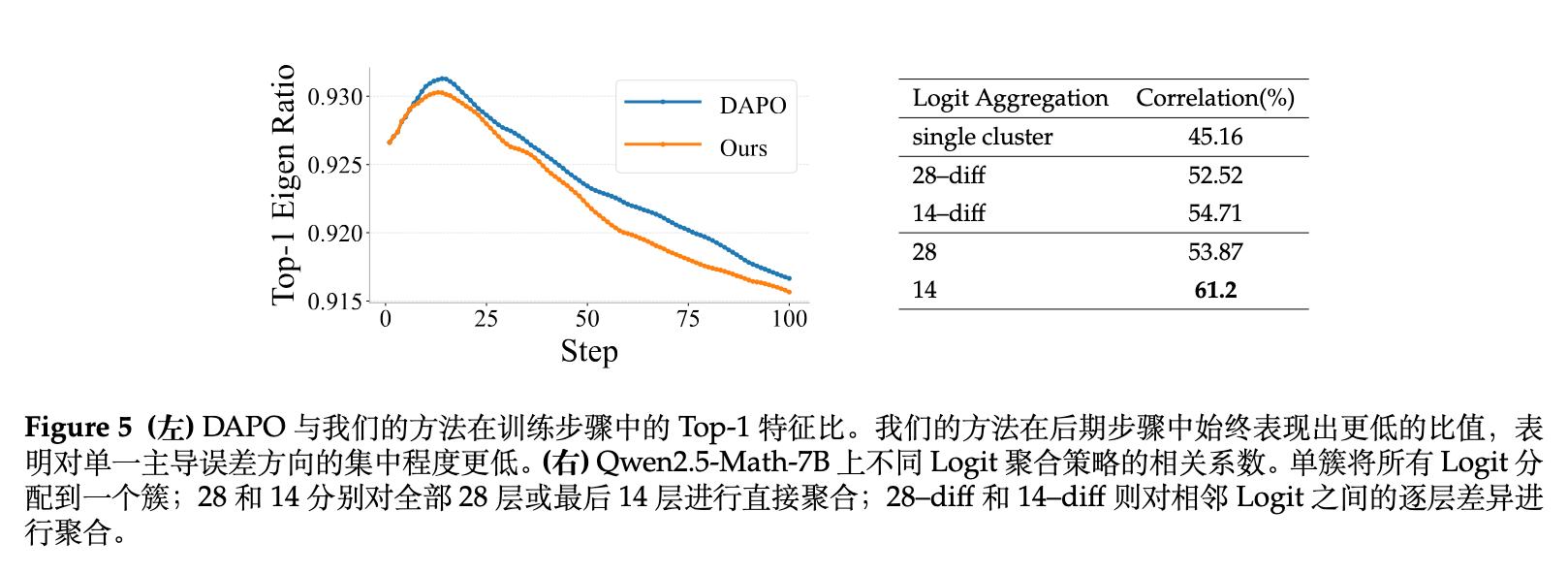
图 5 的结果显示,随着训练的进行,所有模型的探索多样性都会逐渐下降(Ratio 升高)。但 MEDS 始终保持着比基线 DAPO 更低的 Top-1 Eigen Ratio,这为模型具有更多样的探索行为提供了坚实的统计学佐证。
6.3 Logits 特征能否真正反映推理模式?
使用最终答案的第一个 token 的层级 logits 来表示长篇距的推理结构,听起来存在一定的跳跃性。为了验证这一设计的合理性,作者进行了一项定性案例分析(Case Study)。[图 6 案例分析:同一错误结果,不同推理结构]
在问题设定中,需要寻找最小的具有三个特定约数(和为 2022)的整数。
模型生成的错误回复被分为两类:
-
Cluster A: 假设满足条件的数必须是素数 的平方。通过推导得到公式 ,然后应用求根公式,发现解不是整数,于是开始通过代码枚举附近的整数来检查。 -
Cluster B: 同样假设了结构与 有关,但在处理时分析了因子的具体形式,尝试枚举所有可能的组合结构。
尽管 Cluster A 的部分回复(A1)与 Cluster B 的部分回复(B1, B2)给出了相同的最终错误答案 1342,但它们的推理结构是不同的。图 6 的热力图直观显示了 logits 值的分布:在前 20 层中,所有回复的 logits 差异不大(主要编码基础语义信息);而在深层网络中,相同聚类(例如 A1 和 A2,B1 和 B2)展现出相似的数值区间和相关性,而属于不同聚类的回复即使答案相同也能在 logits 空间中被明显区分开来。
这一现象说明,网络在生成最终答案时的深层激活特征,包含了导致该答案的先导逻辑链条信息。
6.4 聚类质量的作用(Clustering Quality Matters)
构建 logits 特征有多种方式,包括选择全部层还是部分层,使用原始值还是差分值等。作者在 Qwen2.5-Math-7B 上探讨了这些选择对聚类质量以及下游任务性能的影响。
通过让 Claude-Haiku-4.5 担任代理标注器(将随机采样的 800 个负面样本基于人工定义的 11 个常见错误类别进行分类),作者计算了基于 logits 的 HDBSCAN 聚类结果与大模型语义聚类结果之间的一致性(Correlation)。
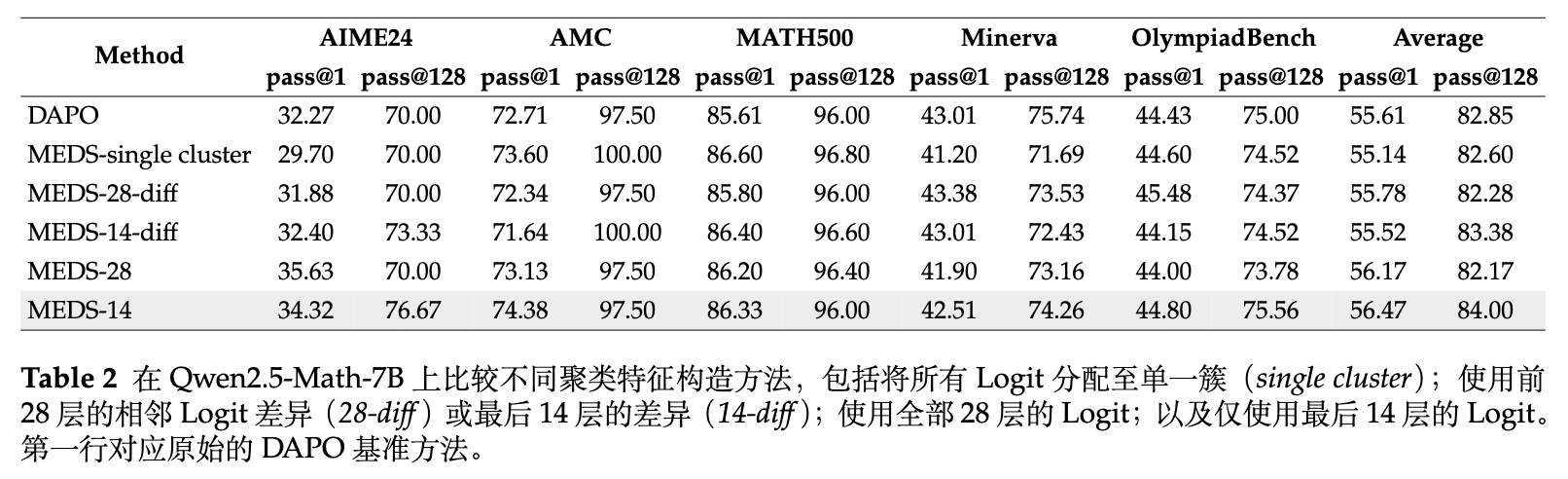
实验设置包括:
-
single cluster(退化基线): 所有样本被强行分配到一个聚类中。 -
28-diff / 14-diff: 对 28 层或最后 14 层的相邻层 logit 取差值。 -
28 / 14: 直接使用 28 层或最后 14 层的 logits 进行聚合。
结果表明,使用 最后 14 层 的特征不仅取得了与 Claude 标注最高的一致性(61.2%),而且在下游各个基准数据集上均取得了最好的性能(平均 84.00)。相反,退化的 single cluster 设置在下游任务中表现最差(82.60)。
更重要的是,聚类一致性的排名与下游性能的排名高度吻合。这进一步证实了 MEDS 方法的因果逻辑:更准确地识别重复错误模式,能够带来更有针对性的惩罚,从而在下游产生更实质的性能提升。
7. 深入探讨与总结
7.1 与现有探索增强方法的对比
在过去的研究中,为了解决强化学习推理多样性坍缩的问题,通常依赖于隐式正则化(Implicit regularization,如 KL 散度和当前策略的熵奖励)或对少见推理行为进行明确奖励的方法。然而,这些机制通常:
-
只关注当前批次(current-batch)内的差异。 -
不追踪整个长期训练历史中的解决方案模式。
也有部分工作(如 UCB 风格的探索奖励)利用了历史信息,但仅基于历史结果(Outcome frequencies)进行评估,缺乏细粒度的跨步骤推理行为追踪。另外一些使用外部模型自适应调整历史奖励的工作,则受限于额外的计算成本,难以规模化。
MEDS 的设计规避了上述问题,通过“免费”获取的层级 logits 实现了细粒度的行为感知,做到了以极小的额外开销实现基于历史的奖励重塑。
7.2 局限性与未来工作
论文在结尾处也坦诚地指出了当前方法的局限性:目前对 logits 的利用和聚合方法相对简单(简单的拼接和欧氏距离度量)。随着研究的深入,如何引入更复杂的聚合函数,或者利用稀疏自编码器(Sparse Autoencoders, SAEs)等机械可解释性(Mechanistic Interpretability)工具提取更高维度的逻辑特征,可能会带来更显著的性能改善。
更多细节请阅读原文。
往期文章:


