尽管 RLVR 在提升模型推理能力方面取得了显著成效,但是也有一个普遍存在的瓶颈:训练停滞期(Training Plateaus)。在经历了数千个step之后,模型的性能增长会变得异常缓慢,即便投入更多的计算资源、延长训练时间,性能的提升也微乎其微。
强化学习的困境:传统的 RLVR 方法通常依赖于有限的“推出”(Rollouts)。模型从问题出发,生成一条完整的解题路径,然后根据最终答案的正确与否获得一个稀疏的奖励信号。这种模式存在一个根本性的缺陷——探索不足(Insufficient Exploration)。模型倾向于在已知的、略有成效的推理模式上进行局部优化,而很难系统性地探索整个广阔的解题空间。它们可能会错过那些关键但罕见的推理路径,也无法从失败的尝试中进行细致的归因和学习。这导致了训练效率的递减,单纯增加训练步数(即“训练深度”)无法有效突破性能上限。
来自斯坦福大学、东京大学、理化学研究所(RIKEN AIP)等机构的研究者在论文《DEEPSEARCH: OVERCOME THE BOTTLENECK OF REINFORCEMENT LEARNING WITH VERIFIABLE REWARDS VIA MONTE CARLO TREE SEARCH》中,为这一挑战提供了新的解决方案。他们提出的 DeepSearch 框架,其核心思想是将蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)直接嵌入到 RLVR 的训练循环中。这一设计从根本上改变了学习范式,将重心从单纯增加训练“深度”转向了扩展训练“广度”。它不再让模型在黑暗中独自摸索,而是通过一个结构化的搜索过程,系统性地探索多条推理路径,并为每一步推理行为提供更精细的信用分配。

-
论文标题:DEEPSEARCH: OVERCOME THE BOTTLENECK OF REINFORCEMENT LEARNING WITH VERIFIABLE RE-WARDS VIA MONTE CARLO TREE SEARCH -
论文链接:https://arxiv.org/pdf/2509.25454
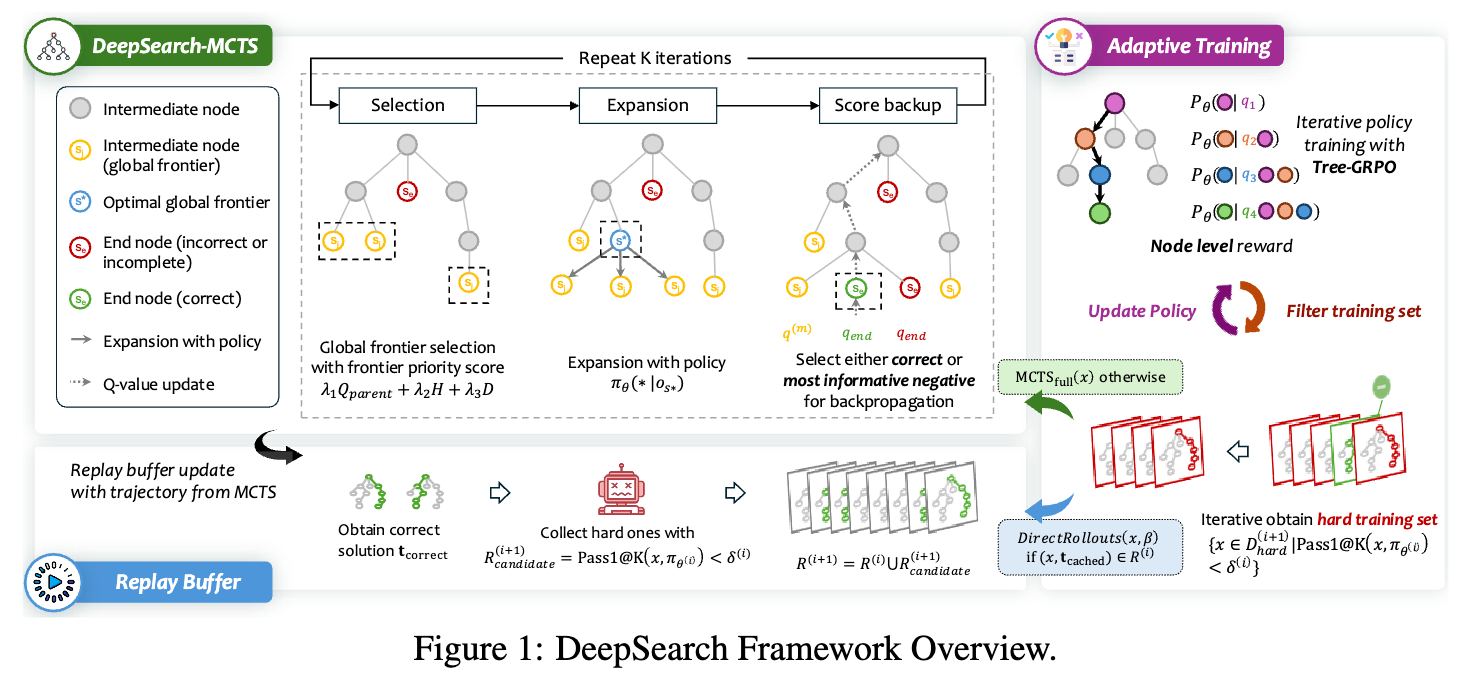
1. 背景
在深入了解 DeepSearch 的机制之前,我们有必要更清晰地理解当前 RLVR 方法所面临的困境。标准的 RLVR 训练流程可以概括为“生成-验证-学习”的循环。对于一个给定的问题,策略模型 会生成一个或多个完整的解决方案(Rollouts)。一个外部的验证器(例如,一个数学答案检查器)会判断这些方案的最终结果是否正确,并据此给予奖励(通常是 +1 或 -1)。然后,模型利用这个奖励信号来更新其参数,使其更有可能生成能够获得正奖励的解决方案。
这种方法的局限性主要体现在以下两点:
-
稀疏的奖励信号:奖励只在整个推理序列的末端给出。无论推理过程多么复杂,中间步骤的质量如何,模型都只能得到一个关于最终结果的二元反馈。这就像教一个学生解一道复杂的数学题,但不告诉他错在哪一步,只告诉他最终答案对不对。这种反馈机制使得信用分配(Credit Assignment)变得异常困难。模型无法明确知道是哪一个中间步骤导致了最终的失败,也无法识别出那些虽处于失败路径中但本身是正确的推理步骤。
-
低效的探索模式:由于奖励稀疏,模型在训练初期通常是随机探索。一旦偶然发现了几条能够通向正确答案的路径,强化学习算法的特性会使其倾向于在这些已知路径的“邻域”内进行探索和优化(Exploitation)。这种策略虽然能较快地提升在相似问题上的表现,但也极大地限制了模型探索全新、多样化解题思路的能力(Exploration)。模型被困在局部最优解中,推理能力难以实现质的飞跃,这正是导致性能停滞期的根本原因。
以往的研究试图通过“延长训练”(Prolonged Training)来缓解这个问题,即使用更多的训练数据和更长的训练时间,寄希望于模型能够通过量变引起质变,慢慢发现新的推理路径。然而,DeepSearch 论文的实验数据明确指出,这种方法的计算成本与性能收益不成正比,回报率迅速递减。这表明,算法层面的创新,即如何更智能地进行探索,比单纯的资源投入更为关键。
2. DeepSearch
DeepSearch 的核心贡献在于,它不把树搜索仅仅看作是推理时(Inference-time)提升性能的技巧,而是将其作为训练时(Training-time) 进行系统性探索和精细化信用分配的核心机制。框架主要由三个创新部分组成:带熵引导的蒙特卡洛树搜索、自适应训练与回放缓存,以及基于树的训练目标 Tree-GRPO。
2.1 树搜索
对于每个训练问题 ,DeepSearch 都会构建一个蒙特卡洛搜索树 。树的根节点是问题本身,每个子节点代表一个中间推理步骤 。从根节点到任意叶子节点的路径构成了一个完整的推理轨迹 。DeepSearch 对传统的 MCTS 流程进行了几项关键的修改。
扩展阶段
在 MCTS 的扩展阶段,当搜索到达一个叶子节点时,策略模型 会被调用以生成若干个可能的下一步。这个过程会持续进行,直到生成一个或多个终止节点 (即得出最终答案或达到最大深度)。
接下来,验证函数 会评估所有新生成的终止节点,并将它们划分为正确解集 和不正确/不完整解集 。
一个关键的问题是:如果本次扩展没有找到任何正确解(即 ),应该如何利用这些失败的探索?传统的 RLVR 可能会将这些路径全部视为负样本。但 DeepSearch 认为,不同的失败路径包含的信息量是不同的。其中,模型最“自信”但结果却是错误的路径,对于模型学习来说价值最高。因为它暴露了模型认知上的“盲区”——模型认为自己走在一条正确的道路上,但实际上却错了。
为了识别这样的路径,DeepSearch 引入了基于熵的选择策略。它会计算每条不正确路径的平均轨迹熵(average trajectory entropy),并选择熵最低的那条路径作为负样本进行反向传播。
其中, 是从根节点到终止节点 的轨迹,平均轨迹熵 的定义如下:
这里的 是在生成步骤 时策略模型输出分布的香农熵。熵越低,表示模型在做出这一步决策时的不确定性越小,即越“自信”。通过选择熵最低的错误路径,DeepSearch 能够精准定位模型最需要修正的知识领域。
回溯阶段
在选择了用于反向传播的轨迹 (一个正确解轨迹,或者上述选出的信息量最大的负样本轨迹 )后,需要将该轨迹的价值回传到路径上的所有父节点。
首先,终止节点 的奖励 被定义为:
其中 是树的最大深度。这个定义确保了不完整(即提前终止)的路径也会受到惩罚。
然后,DeepSearch 使用一个迭代式的规则来更新路径上每个中间节点 的 Q 值。在第 次回溯中,其更新规则为:
这里的 是一个时间衰减函数,它使得距离终止节点越近的节点获得越高的权重。其定义为:
其中 是轨迹的长度, 是当前节点的索引, 是一个最小衰减阈值(论文中设为0.1)。
更重要的是,DeepSearch 在此基础上引入了一个约束性更新规则,这是其信用分配机制的关键创新:
这个规则的核心思想是:保证所有通往正确解的路径上的中间节点的 Q 值始终为非负数。如果一个节点 既可以通向正确解(已有正的 Q 值),又可以通向一个负样本路径,那么负奖励不会直接拉低它的 Q 值,从而保护了它作为正确路径一部分的价值。只有当一个节点的所有下游路径都导向错误解时,它的 Q 值才会被更新为负。这种设计极大地稳定了训练过程,并提供了更清晰、更鲁棒的信用分配信号。
选择阶段
传统的 MCTS 在选择下一个要扩展的节点时,会从根节点开始,在每一层都使用 UCT(Upper Confidence bounds for Trees)算法进行决策,直到到达一个叶子节点。这种逐层遍历的方式可能导致搜索算法陷入某个局部看起来很有希望但全局并非最优的子树中,造成计算资源的浪费。
DeepSearch 提出了一种创新的混合选择策略,结合了传统的局部选择和新颖的全局选择。
-
局部选择(Local Selection):当一个节点被选中进行扩展,它会生成多个子节点。在这些兄弟节点之间进行选择时,DeepSearch 沿用传统的 UCT 算法。UCT 旨在平衡对已知高价值节点的“利用”(Exploitation)和对探索较少节点的“探索”(Exploration)。
其中 是节点的平均奖励, 是节点的访问次数, 是其父节点的访问次数。
-
全局前沿选择(Global Frontier Selection):在完成一次回溯后,需要决定下一步要扩展树中的哪一个叶子节点。DeepSearch 在这里摒弃了传统的逐层 UCT 遍历。它维护一个包含树中所有未被扩展的叶子节点的全局前沿集合 。
其中 表示节点 没有子节点。然后,它直接在整个集合 中计算每个节点的前沿优先分数(frontier priority score),并选择分数最高的节点进行下一次扩展。
这个分数由三个部分组成:
-
质量潜力项: 衡量了该节点的父节点的历史表现。使用 函数可以平滑地处理负Q值。父节点价值越高,子节点被探索的优先级也越高。 -
不确定性奖励项: 是模型在生成该节点时的策略熵。高熵代表高不确定性,这可以引导搜索去探索模型尚不确定的区域。 -
深度奖励项: 鼓励搜索向更深的层次进行。论文发现使用 的效果最好,它在鼓励深度探索和避免过早陷入单一路径之间取得了平衡。
-
这种全局前沿选择策略避免了 UCT 算法的短视问题,能够更有效地将计算资源分配到整个搜索树中最有希望的区域,显著提升了探索效率。
2.2 自适应训练
尽管 MCTS 提供了强大的探索能力,但为训练集中的每一个样本都执行一次完整的树搜索,其计算成本是难以承受的。为了使 DeepSearch 在实际应用中高效可行,研究者设计了一套自适应训练策略。
渐进式过滤的迭代训练
训练过程被划分为多个阶段。在每个阶段,模型只在当前最困难的样本子集 上进行基于 MCTS 的训练。这个“困难集”是动态调整的:
-
初始困难集构建:使用基础模型,在整个训练集上进行评估,将那些模型表现不佳(例如,使用 4 个样本的 Pass@1 成功率低于某个阈值 )的问题筛选出来,构成初始的 。
-
迭代式优化:在第 轮训练结束后,使用更新后的模型 在当前的困难集 上重新评估,并筛选出下一轮的困难集 。
通过这种渐进式过滤(Progressive Filtering)的方式,计算资源被动态地集中到对模型提升最关键的难题上,随着模型能力的增强,训练的焦点也随之转移。
带缓存解的回放机制
为了防止模型在学习新难题时遗忘已经解决的问题(即“灾难性遗忘”),并进一步节约计算资源,DeepSearch 引入了带缓存解的回放缓冲区(Replay Buffer with Cached Solutions)。
-
缓冲区填充:在每轮训练中,如果一个问题通过 MCTS 搜索找到了正确解,但其本身的 Pass@1 成功率仍然低于阈值,那么这个“(问题,正确解轨迹)”对 就会被存入回放缓冲区 。
-
混合推出策略:在处理困难集中的问题时,采用一种混合策略:
如果一个问题在回放缓冲区中存在已知的正确解 ,那么就直接使用这个解,并辅以少量从当前策略生成的普通 Rollouts,而无需再进行完整的 MCTS 搜索。如果问题没有缓存解,则执行完整的 MCTS 搜索。
最终,用于训练的数据集 由两部分构成:来自已缓存问题的(缓存解 + 少量新探索),以及来自未解决问题的大量 MCTS 探索轨迹。
这个自适应机制实现了计算效率、知识保留和持续探索三者之间的精妙平衡。
2.3 Tree-GRPO
收集了富含结构化信息的搜索树之后,最后一步是如何利用这些信息来更新模型。DeepSearch 为此设计了 Tree-GRPO(Tree-Guided Relative Policy Optimization)训练目标。
Q值软裁剪
直接使用 MCTS 中回溯的 Q 值进行训练可能会导致数值爆炸问题。为此,DeepSearch 首先使用双曲正切函数(tanh)对中间节点的 Q 值进行软裁剪(Soft Clipping)。
其中 是最大回溯次数。这种软裁剪方法相比于硬性裁剪,能够在限制数值范围的同时保留梯度信息,并维持不同节点 Q 值的相对顺序。
训练目标函数
在获得了正则化后的 Q 值后,Tree-GRPO 的目标函数定义如下:
这是一个 PPO-style 的目标函数。其中关键是优势函数(Advantage Function) 的计算。与传统 RLVR 使用整个轨迹的最终奖励作为所有步骤的优势不同,Tree-GRPO 为每个节点 定义了其自身的优势,并采用了序列级别的归一化:
这里的 是节点 经过 MCTS 评估和软裁剪后的 Q 值,而 是整个搜索树 中所有终止节点奖励的平均值。这种归一化方式至关重要,它将每个节点的价值与其在整个搜索空间中的相对表现进行比较,实践证明这对于缓解模型生成过长响应等问题非常有效。
Tree-GRPO 的精髓在于它利用了 MCTS 提供的精细化的、节点级别的奖励信号 来指导模型更新,而不是像传统方法那样,让一条路径上的所有节点共享同一个粗糙的、基于最终结果的奖励。如果始终用最终奖励 来代替 ,Tree-GRPO 就会退化为普通的 RL 算法(如 DAPO),这也反过来证明了其利用树结构信息的优越性。
3. 实验
研究者在一系列标准的数学推理基准测试上,对 DeepSearch 进行了详尽的评估。
性能表现
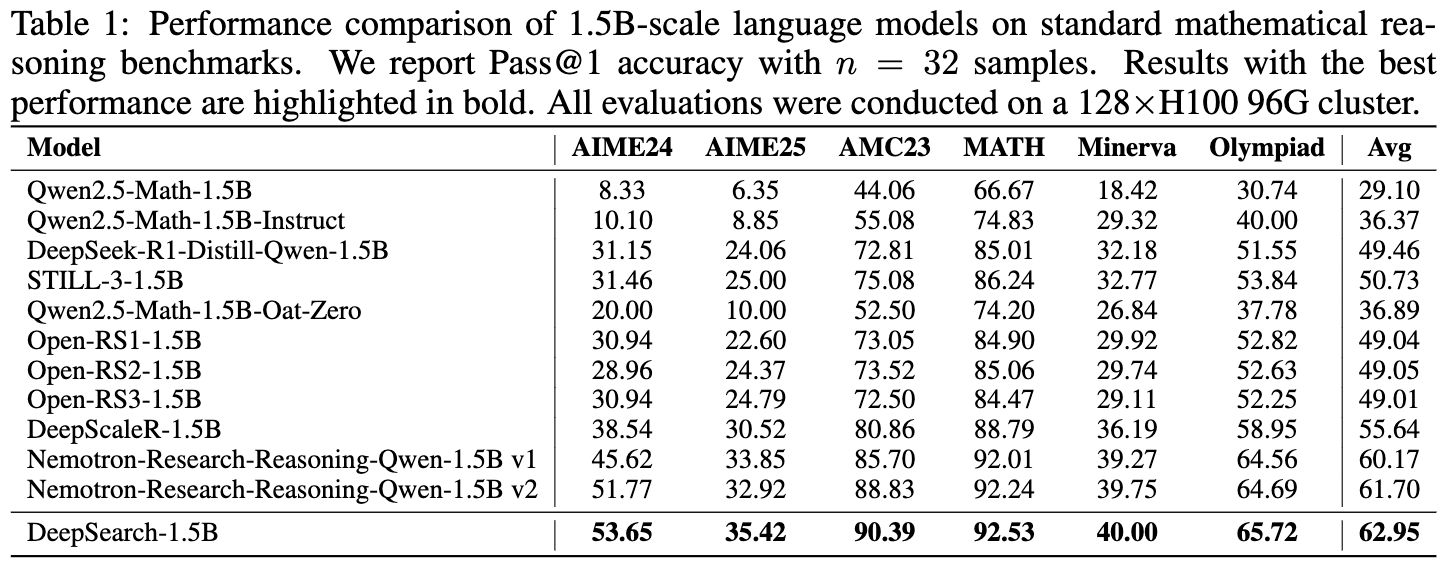
如表 1 所示,基于 Nemotron-Research-Reasoning-Qwen-1.5B v2 模型训练的 DeepSearch-1.5B,在 6 个数学基准测试上取得了 62.95% 的平均准确率,超过了之前所有的基线模型。
训练效率分析
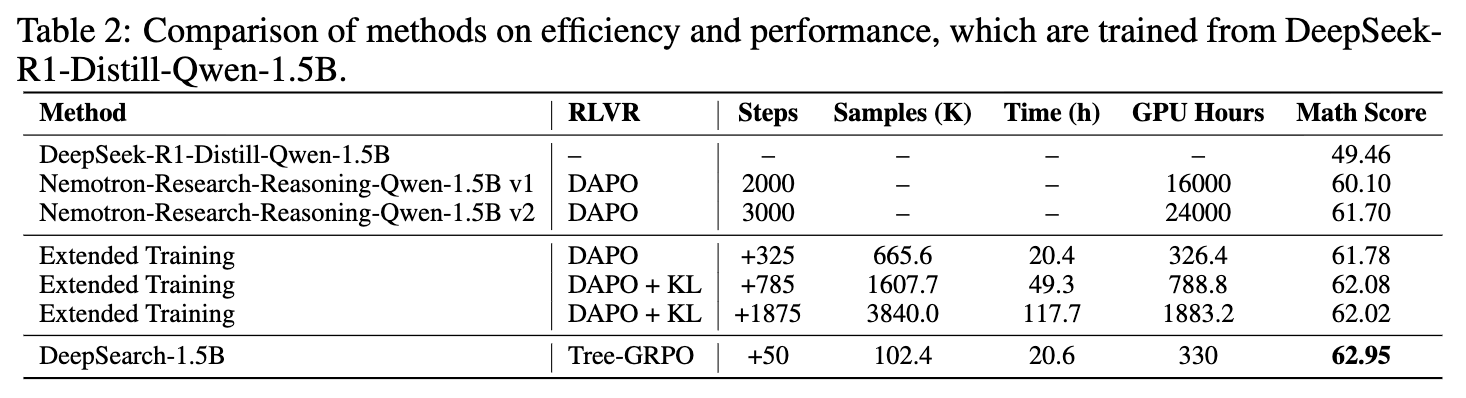
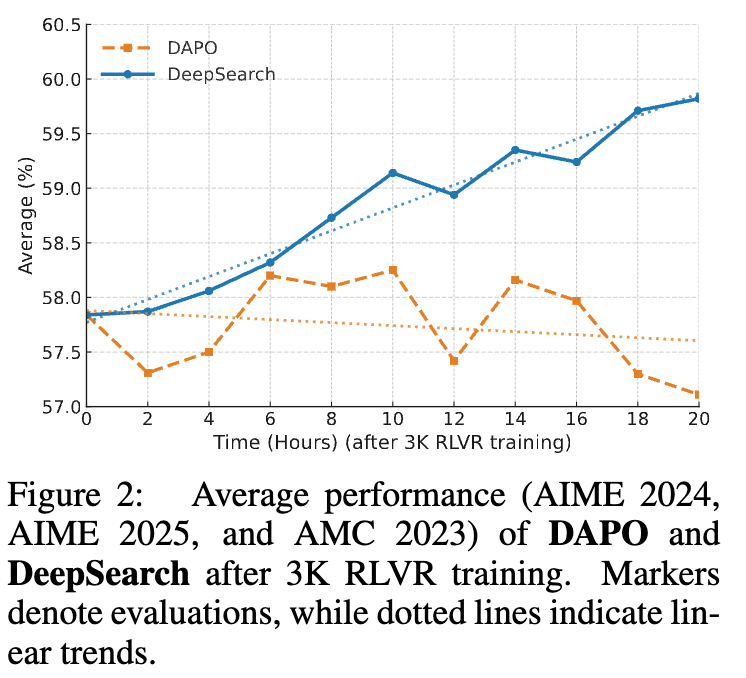
DeepSearch 最令人关注的优势体现在其训练效率上。表 2 和图 2 清晰地展示了这一点。与单纯依赖延长训练(Extended Training)的方法相比:
-
性能与成本:延长训练方法消耗了 1883.2 GPU 小时,性能也仅仅达到 62.02%。而 DeepSearch 只需额外的 50 步训练和 330 GPU 小时,就达到了 62.95% 的性能。这意味着 DeepSearch 使用了不到 1/5 的计算资源,就获得了比暴力扩展更好的结果。 -
收敛速度:图 2 显示,在相同的训练时间里,DeepSearch 的性能提升曲线斜率明显高于基线方法 DAPO,表明其学习效率和收敛速度更快。
这些结果有力地证明了论文的核心论点:RLVR 的瓶颈在于探索的质量,而非训练的时长。通过算法层面的创新,进行系统性的结构化探索,比盲目堆砌计算资源更为有效。
消融研究
为了验证框架中每个设计组件的有效性,研究者进行了一系列详尽的消融实验。
-
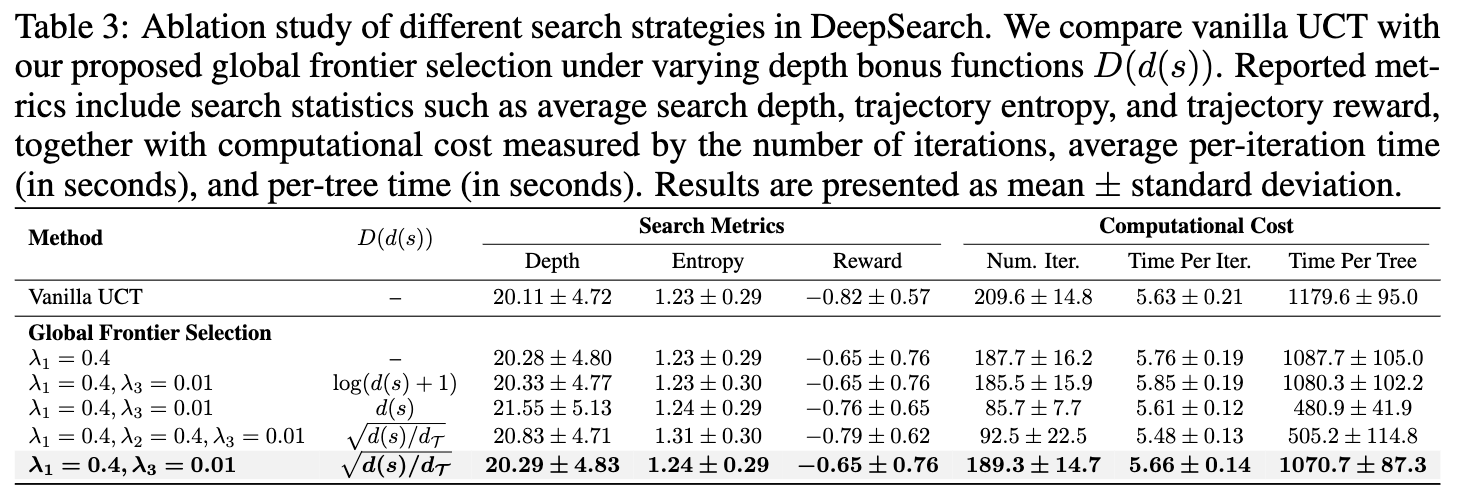
全局 vs. 局部选择:表 3 的数据显示,与传统的、基于 UCT 的逐层遍历相比,DeepSearch 的全局前沿选择策略在保持相近搜索深度的同时,能将每次搜索的迭代次数减少 10.4%,并获得更高的轨迹奖励。这证明了全局比较前沿节点比局部逐层决策更高效。
-
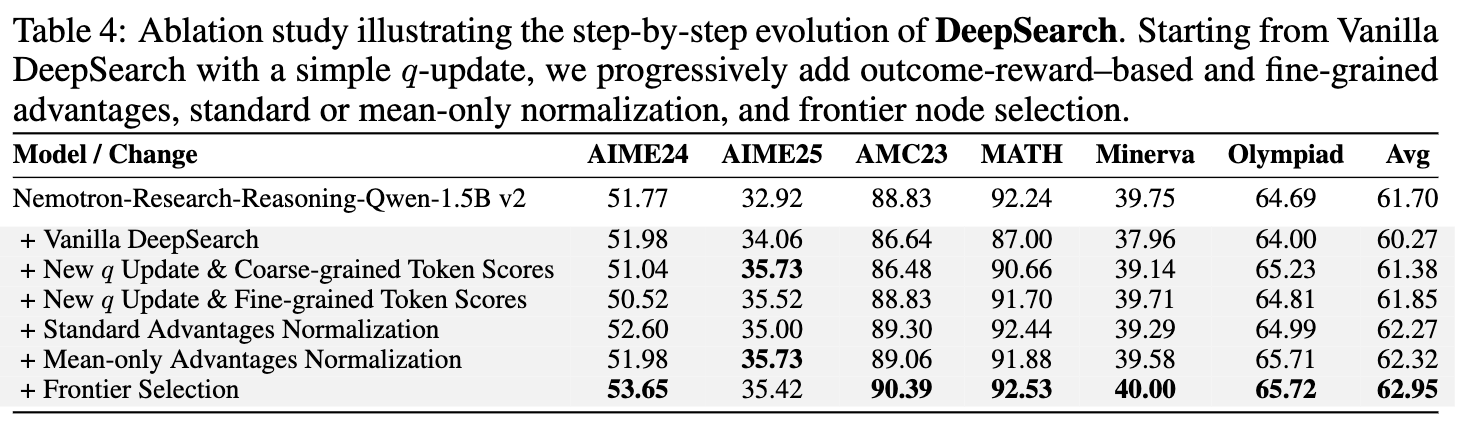
组件贡献分析:表 4 展示了一个逐步构建 DeepSearch 的过程。从一个仅集成基础 MCTS 的版本开始,逐步加入约束性 Q 值更新、精细化的节点级优势、均值归一化,最后到全局前沿选择。每一步都带来了性能的提升,其中,全局前沿选择(Frontier Selection)带来了最大单项性能增益。这个实验清晰地展示了 DeepSearch 的各项创新是如何协同工作,共同促成了最终的优异性能。
点评
论文的出发点非常明确且重要。它没有满足于在现有框架上进行微小的改进,而是直接挑战了 RLVR 实践中普遍存在的“回报递减”现象。作者深刻地洞察到,这一瓶颈的根源并非训练时长不足,而是基于有限 Rollout 的方法在探索广度上的天然缺陷。通过将重心从“训练深度”转向“探索广度”,DeepSearch 直接解决了稀疏奖励和低效探索这两个根本性问题,为突破 RLVR 的性能上限提供了全新的思路。
DeepSearch 不仅仅是一个单一的想法,而是一整套环环相扣、设计周密的系统。这体现在其框架的多个创新组件上:
-
全局前沿选择 (Global Frontier Selection) :这是对传统 MCTS 的一次重要改进。它摒弃了 MCTS 逐层遍历的短视性,通过在整个搜索树的“前沿”进行全局择优,能更高效地将计算资源分配到最有潜力的探索方向上,显著提升了搜索效率。 -
基于熵的负样本挖掘:在没有找到正确解时,并非所有失败路径的价值都相等。DeepSearch 通过选择模型最“自信”(即熵最低)的错误路径进行学习,实现了对负样本的高效利用,精准地修正了模型的认知盲区。 -
约束性 Q 值更新:该设计巧妙地解决了信用分配中的一个难题——如何在一个节点既能通往成功又能通往失败时更新其价值。通过保护通往正确解路径节点的 Q 值不被负奖励污染,它极大地稳定了训练过程,使得价值评估更为鲁棒。 -
自适应训练与缓存机制:认识到对所有样本进行 MCTS 的高昂成本,论文设计的渐进式过滤和缓存解回放策略,使得 DeepSearch 在实践中变得可行且高效。这种机制动态地将算力聚焦于“难题”,同时有效防止了“灾难性遗忘”。
一些局限性:
尽管 DeepSearch 相比于延长训练更高效,但其自身的绝对计算开销仍然不可忽视。
-
内存消耗:为训练批次中的每个样本都维护一个 MCTS 搜索树,对内存是一个不小的挑战,尤其是在问题需要非常深的推理(导致树的规模巨大)时。 -
超参数敏感性:该框架引入了多个新的超参数,例如全局前沿选择公式中的 ,UCT 的探索系数,衰减因子 等。这些超参数的最优值可能因任务和模型的不同而异,为新任务调优可能会是一个复杂的过程。 -
对长推理链的扩展性:论文中的实验主要集中在数学问题上,其推理步骤虽然复杂但有一定限度。对于需要数百甚至数千步推理的超长链任务,MCTS 搜索的广度和深度如何平衡,当前的框架是否依然有效,有待进一步验证。
往期文章:


