让每一项优秀工作,被更多人看见:点击进入投稿通道

-
论文标题:Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence -
论文链接:https://arxiv.org/pdf/2604.18292
TL;DR
今天解读由人大与字节跳动 Seed 团队共同提出的 Agent-World 框架。该研究针对当前大语言模型(LLMs)在复杂、多步交互的真实工具环境中泛化能力不足的问题,提出了一种结合可扩展环境合成与持续自进化训练的闭环系统。
Agent-World 包含两个核心组件:一是“智能体驱动的环境与任务发现”,能够从真实世界的主题(如 MCP 服务器配置、API 文档、产品需求文档)中自主挖掘数据库,并合成具有可控难度的可验证任务;二是“持续自进化智能体训练”,通过多环境强化学习(采用 GRPO 算法和可执行奖励),结合动态竞技场中的智能体诊断机制,实现策略与环境的协同进化。
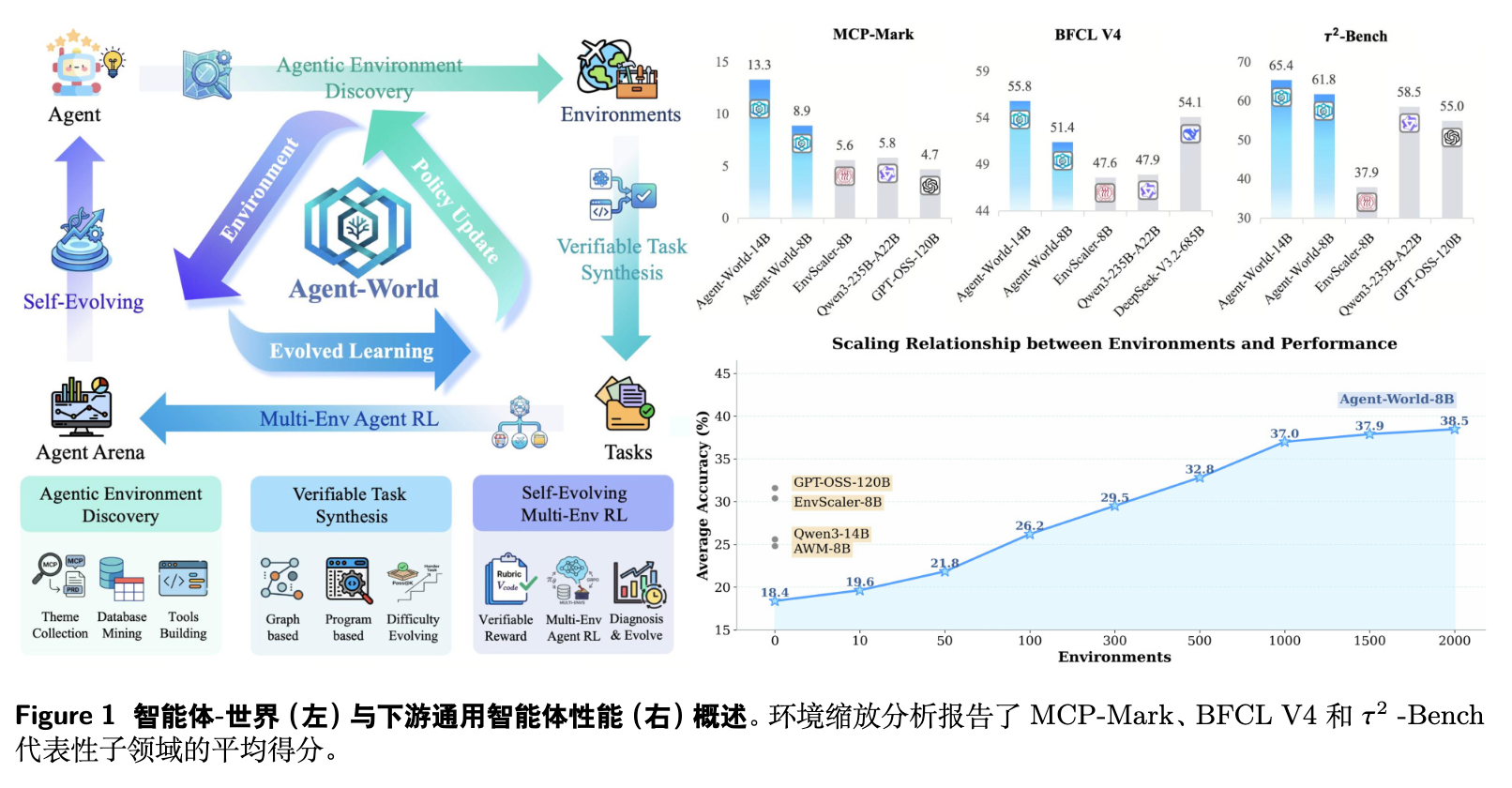
在 23 个具有挑战性的智能体评测基准上,基于 Qwen3 初始化的 Agent-World-8B 和 14B 模型表现稳定,均优于现有环境缩放基线模型和部分闭源模型。研究深入探讨了环境多样性缩放、自进化轮次对模型性能的正向影响。
1. 背景
在自然语言处理与人工智能决策领域,大语言模型的能力边界正不断向外拓展。研究的关注点正从传统的基于文本生成的聊天模式,向具备通用目的的智能体(General-Purpose Agents)助手转移。这类智能体不仅需要具备自然语言的逻辑推理能力,还需要与外部状态可变的工具环境进行无缝交互。
实现这一目标的前提是模型能够采取行动,并从环境中获取及时的观察与反馈,从而形成“生成-执行-反馈”(Generation-Execution-Feedback)的交互闭环。伴随智能体强化学习(Agent RL)的兴起,基于静态工具环境构建的智能体系统在深度信息检索和软件工程等领域展示了实用价值。然而,开放世界的工具环境本质上是组合性且状态相关的(Compositional and Stateful)。例如,在机票预订工作流中,智能体需要遵循特定的合法动作顺序(查询库存 执行预订 更新日程),同时每个动作都会改变底层的环境状态。
以往聚焦于无状态(Stateless)或单次工具调用(Single-tool)的研究设定已难以满足真实应用场景的需求。为此,学术界和工业界开始探索模型上下文协议(Model Context Protocol, MCP)以及相关的工具编排架构。但在这些复杂设定下,训练鲁棒智能体面临两个未解决的瓶颈:
-
环境合成的可扩展性与真实性不足:现有的训练环境大多完全由 LLM 生成或从有限的开源工具链中提取,缺乏与真实世界交互逻辑的对齐。此外,合成环境的复杂度受限,难以支持长视距、强状态依赖任务的训练。 -
缺乏持续的自进化训练机制:尽管真实的互动环境可以作为训练竞技场,但现有研究侧重于环境的构建与规模化,缺乏结构化的机制来利用这些环境自动诊断智能体的能力缺陷,并驱动模型进行持续的自我提升。
Agent-World 框架被提出以应对上述挑战。该框架将真实世界环境的可扩展合成与持续自进化训练机制统一在一个闭环中。
2. 基于多环境的智能体交互问题建模
在讨论具体的方法论之前,有必要明确智能体与多环境交互的数学定义。该研究遵循部分可观察马尔可夫决策过程(Partially Observable Markov Decision Process, POMDP)的框架,将其表示为元组 。
意图空间 (Intent space, )
设定 代表用户的潜在意图。智能体需要通过累积的交互历史和环境反馈来逐步推断 ,并据此选择合适的动作。
状态空间 (State space, )
全局状态被分解为环境状态(Environment state)和对话状态(Dialogue state):。在时间步 ,完整的状态为 。
-
捕捉了智能体可以查询或修改的外部世界状态(例如数据库的记录、文件系统、网络服务)。 -
总结了对话上下文(例如对话历史、约束条件、用户偏好)。
环境的具体参数化
为了将 POMDP 模型与多个异构环境连接起来,每一个环境被参数化为一个二元组 。
-
代表环境数据库,是环境状态 的主要载体,包含结构化记录或文件。 -
代表工具集,提供与 交互的可执行接口。每个工具 是一个可调用的算子,支持对数据库的读写操作,从而触发环境状态的转移。
动作空间 (Action space, )
智能体可以在工具使用动作和语言回复动作之间进行选择:。
-
当 时,智能体调用具有结构化参数的工具(例如带有 JSON 格式参数的函数)来查询或修改环境。 -
当 时,智能体输出自然语言信息(包括中间思考过程或最终答案)。
观察空间 (Observation space, )
在每个时间步 ,智能体接收观察 ,随后采取动作 。观察空间定义为 。
-
包含工具执行返回的结构化观察结果(如查询结果、系统日志、错误代码)。 -
包含对话端观察(如用户发言、系统提示,或离线训练中的终止信号)。
需要注意的是,环境状态 对于智能体而言是不可直接完全观察的,必须通过 中的工具反馈进行间接推断。
状态动态转移 (State dynamics, )
转移模型 定义了系统在动作发生后的演化规则。给定 ,系统转移至 并发出下一个观察 :
-
若 :工具 在数据库 上被执行。这可能通过读写操作更新环境状态 ,并产生结构化观察 。对话状态 通过追加新的工具交互记录进行更新。 -
若 :智能体通过发出回复更新对话状态 。在交互式设定中,这可能带来新的用户观察 ;在离线训练中,这通常产生一个终止信号。该回合环境状态保持不变,即 。
3. 核心方法论:Agent-World 架构解析
Agent-World 包含两个紧密耦合的组件。组件一负责解决环境和任务的规模化合成,组件二负责闭环的策略优化与数据迭代。
3.1 智能体驱动的环境与任务发现
此模块旨在从真实的文本素材出发,自动化地构建具有可执行后端、且具备挑战性的评估与训练任务。
3.1.1 环境主题的收集
为了确保环境的真实性与多样性,研究人员从三个真实世界的数据源中系统性地收集了环境主题作为锚点:
-
MCP Servers (模型上下文协议服务器) :从 Smithery 平台获取真实世界的 MCP 服务器规范。每份规范均附带结构化的 JSON 文档,包含源数据描述和标准化的工具定义。这一部分对应的主题集合记为 。 -
Tool Documentations (工具文档) :收集并过滤涵盖真实工具使用场景的开源数据集,提取工具定义文档,并使用 LLM 将其逆向映射为环境主题,记为 。 -
Industrial PRDs (工业级产品需求文档) :产品需求文档天然包含业务背景、领域工作流和系统接口。将这些文档作为主题锚点,记为 。
最终整合形成种子主题集合:。
3.1.2 智能体数据库挖掘与复杂化
给定主题集合 ,目标是挖掘出主题对齐的、真实存在的环境数据库。与过去强调完全由 LLM 合成数据库的研究不同,本研究认为万维网(World Wide Web)已经包含了丰富、高价值且实时更新的结构化数据。
研究设计了一个智能体工作流,自主挖掘网络数据并处理成环境数据库。具体而言,构建了一个深度研究智能体 ,其核心是一个策略模型 ,并配备了外部工具集 (包括网络搜索、浏览器、代码编译器以及操作系统 OS 工具)。对于每个主题 ,该智能体执行多轮迭代的信息检索与数据挖掘。随后,智能体利用 OS 工具将数据结构化并进行持久化存储,生成初始的环境数据库:
单次自动化挖掘往往只能产生规模受限且结构简单的数据库。为了提升数据库的复杂度,研究引入了数据库复杂化过程 。通过提示深度研究智能体迭代地扩展和丰富特定主题的数据库:
经过 轮迭代,最终生成的数据库记为 。此过程产生的数据库在结构维度上更符合真实环境的需求。
3.1.3 工具接口生成与验证
为构建基于数据库的可执行工具集,研究引入了编码智能体 ,配备代码编译器和 OS 工具,记为 。给定主题与数据库 ,该智能体生成候选工具集及其对应的单元测试用例集合:
其中每个工具 关联一组测试用例 。
为了保证代码质量,研究执行基于执行的交叉验证(Cross-validation)。对于每个候选工具 ,其测试准确率定义为:
工具的保留必须满足三个条件:
-
函数可以被 Python 编译器成功编译。 -
在其关联的测试集上,。 -
其所属的环境必须至少包含一个有效工具和一个有效测试用例。
经过上述过滤,得到质量受控的工具集 。最终构成的可扩展环境生态系统被定义为:
3.1.4 层次化环境分类系统的构建
为了对生成的环境进行系统化组织,研究通过层次聚类构建了环境分类系统。基于数千个环境主题,应用层次聚类算法得到 50 个聚类中心。回溯每个聚类覆盖的样本集并随机抽取代表性样本。随后,使用 GPT-OSS-120B 作为监督摘要模型,识别每个聚类的中心主题,生成 50 个二级标签。
为消除 LLM 生成可能带来的模板化和偏差,由人工合并这些二级标签,并将其抽象为 20 个一级类别。最终构建的分类树包含 20 个一级标签、50 个二级标签以及超过 2000 个三级标签。这为跨环境的任务合成以及分层竞技场采样奠定了基础。一级类别集合记作 。
3.1.5 可验证任务合成
在建立环境生态 后,系统通过两种互补的策略生成高质量的长视距任务:基于图的任务合成(处理序列化工具依赖)与编程化任务合成(处理复杂的非线性控制流)。
策略一:基于图的任务合成
在真实的工具使用中,特定任务通常需要按照特定逻辑顺序调用一连串工具。合法的调用序列及其返回值本身就定义了完成用户查询所需的信息流。研究采取了逆向工程范式:先生成合法的工具调用序列,再基于序列生成任务描述。
-
构建工具依赖图:对于每个环境 ,构建加权有向完全图 。节点对应工具,边代表依赖。边分为三类并由 LLM 评估权重: -
强依赖 (Strong dependency, ) :工具 的输入严格依赖工具 的输出。构成严格的有向边,保证数据流合理性。 -
弱依赖 (Weak dependency, ) : 的输入可由 输出派生,但也可能通过其他方式获得(如常量或直接查库)。建模为双向边,增加游走灵活性。 -
独立边 (Independent edge, ) :无参数依赖的工具之间。作为回退机制,保证 连通,避免随机游走陷入死胡同。
-
-
图上的随机游走:在图 上执行带权随机游走,生成原始工具调用序列 。起始节点倾向于选择有输出且无强前置依赖的工具。依据边权重矩阵 偏向性地采样下一节点。 -
参数实例化与清洗:遍历采样到的序列,利用前置输出填充强/弱依赖参数;对独立边参数,从数据库 中随机采样合法值。随后 LLM 审核该链条,删除冗余操作并输出可执行的工具序列 。 -
生成任务与评分规则 (Rubric) :LLM 依据 起草初始任务描述 (严禁包含工具名或数据库元数据以防数据泄露)。系统在沙盒中逐步执行 ,记录轨迹和最终结果。基于执行数据场和格式,LLM 将 重写为有现实基础的最终查询 。同时,生成 JSON 格式的 Ground-truth 答案 和结构化评估量表 。量表 支持字段完整性、格式匹配、数值容差等多维度的自动化校验。 -
质量一致性验证:在沙盒中部署 ReAct 智能体尝试解决生成的任务 5 次。仅当智能体至少在 2 次独立运行中得出一致的成功答案时,该任务才被保留。 -
难度扩展:通过增加随机游走步数上限、增加弱依赖及独立边的采样概率来加长工具链。对描述进行模糊化处理,隐去 API 直接指代,迫使模型基于抽象目标进行规划。由此生成的任务集记为 。
策略二:编程化任务合成
针对条件控制、多步循环和结果聚合等非线性模式,该方法直接生成基于 Python 脚本的解决方案。
-
生成任务与解决方案代码:将工具 Schema 和数据库描述输入给 LLM,令其生成复杂的任务查询 。随后,LLM 充当解答者,编写端到端的可执行 Python 脚本 来解决 。此脚本被置于 ReAct 循环中执行,若遇语法或运行时错误,智能体将迭代调试代码。成功执行则产出最终真实答案 。 -
验证代码生成:复杂的编程任务不适用字符串匹配。因此输入 至 LLM,生成可执行验证脚本 。脚本包含多级断言与定制化逻辑,用于判断候选答案 以及底层数据库状态 是否满足所有任务约束。此验证脚本同样经过 ReAct 沙盒调试以确保可靠性。 -
质量与难度控制:采用与图生成类似的一致性验证(5 跑 2 过)。在难度扩展方面,通过指令要求注入跨库聚合、排序、条件分支等逻辑。编程化合成的任务集记为 。
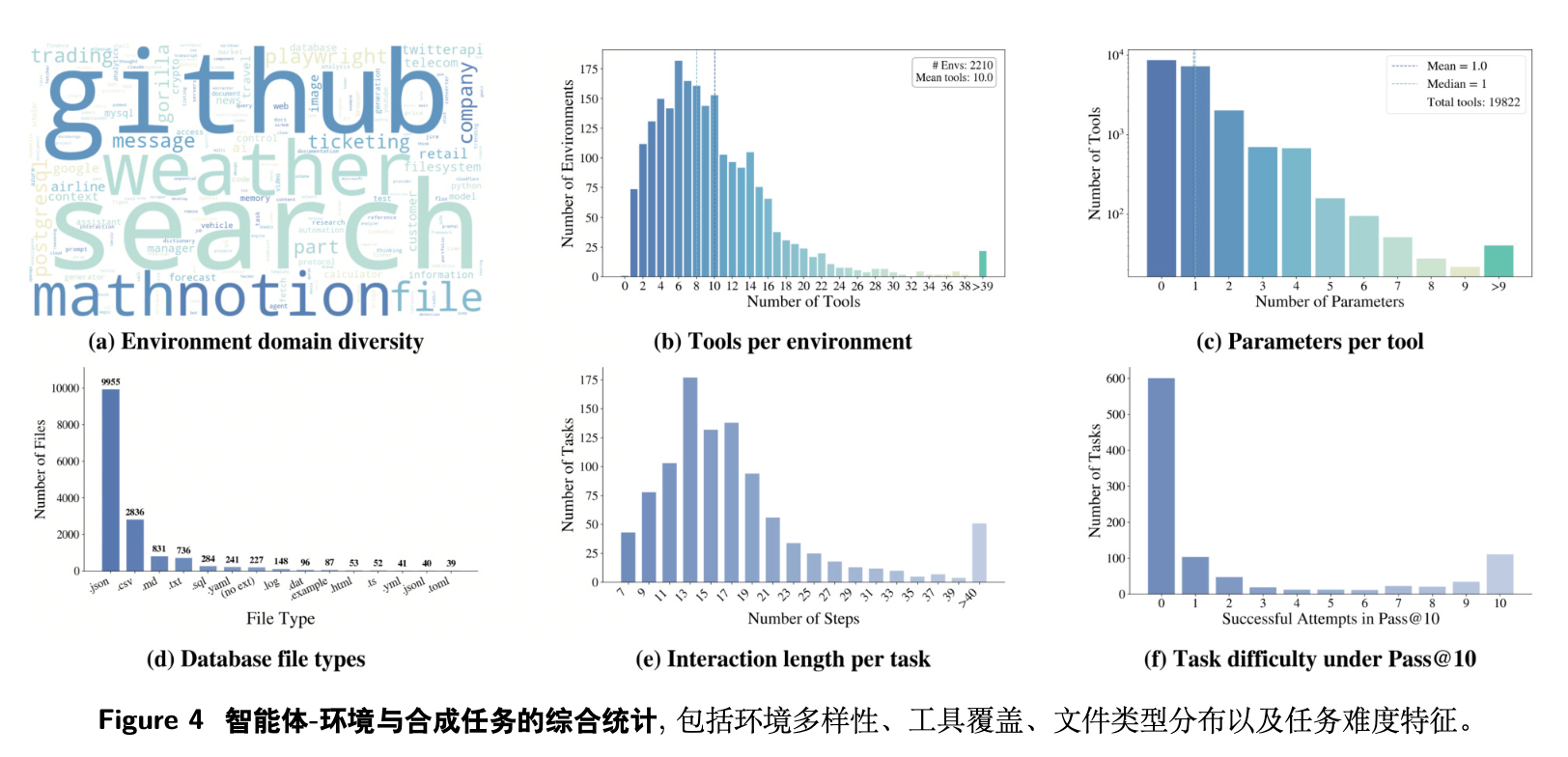
图 4 展示了环境与任务分布的详尽统计数据。过滤后共保留 1,978 个环境,环境的平均工具数量超过 10 个。数据库格式涵盖 json, csv, sql, html, tex, yaml 等,反映了现实世界工作空间的异质性。任务平均交互轮次超过 20 轮。
3.2 持续自进化智能体训练
在拥有了环境生态系统 后,研究通过多环境“智能体-工具-数据库”交互采集数据,利用可执行奖励信号对通用智能体进行强化学习。同时,该生态系统作为一个动态的诊断竞技场(Arena),能够识别当前策略的短板,并指导靶向的环境-任务扩展,形成策略与环境的协同演化。
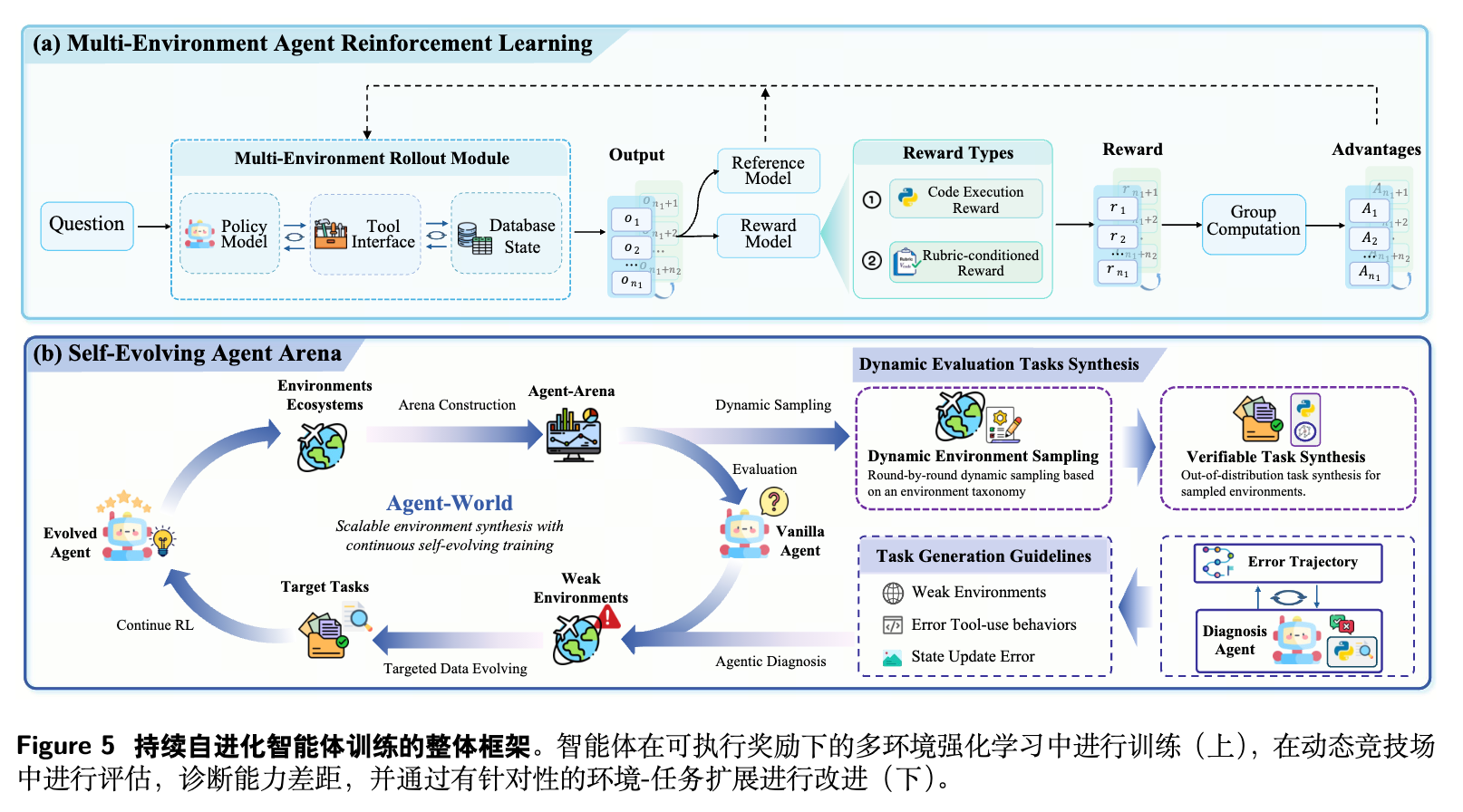
3.2.1 多环境智能体强化学习
多环境 Rollout
有别于静态工具调用场景,Agent-World 构建了一个三方互动的闭环:
-
LLM 策略 :基于历史对话和工具反馈生成下一步动作。 -
工具接口/运行时:在沙盒环境中执行特定环境的工具集 ,维护数据库连接、缓存等状态。 -
数据库状态 :作为工具执行的读写基底。
给定任务 及对应的环境,策略 根据历史 采样动作 。模型最终输出 ,其中 为交互轨迹。遵循组相对策略优化(Group Relative Policy Optimization, GRPO)算法,为每个任务采样 个输出,并在不同的动态环境中独立进行 rollout。
结构化可验证奖励 (Structured Verifiable Reward)
为了指导环境中的智能体,奖励的分配必须考量答案正确性、环境状态变动、效率约束等因素。研究定义了两种奖励形式:
(i) 针对基于图的任务 :使用带有评估量表 的 LLM 作为裁判,对模型输出 进行评分。评分通过计算各个评价标准通过率的平均值得出。
(ii) 针对编程化任务 :为每个任务提供验证脚本 ,在沙盒中运行该脚本以验证预测答案或最终的数据库状态。
输出级别的奖励函数定义如下:
其中 为指示函数。
策略更新 (Policy Update)
应用 GRPO 算法最大化可验证回报。给定从数据集 中采样的任务 ,利用行为策略 生成 个轨迹输出组 ,计算标记级优势 ,并通过最大化以下目标函数更新策略 :
这里 和 为超参数, 为重要性采样比率, 为组内标准化的优势函数。
3.2.2 自进化智能体竞技场
可扩展环境生态系统不仅仅是训练数据的来源,它更充当了动态的智能体诊断平台。
竞技场的构建与动态评估任务合成
基于 3.1 节的分类学 ,采用分层采样选取评估环境集 (每个一级类别抽取 个环境)。在第 轮迭代时,对于竞技场内的每一个环境,实时执行前述的生成管线,合成全新的评估任务集 。动态合成机制防止了智能体对静态测试集的过拟合。
智能体诊断 (Agentic Diagnosis)
在获取当前模型 于测试集上的失败轨迹后,系统指派配备 Python 解释器和搜索工具的自动诊断智能体 分析失败模式。其输入包含:
(i) 单任务失败追踪(工具日志、中间观察、验证器反馈);
(ii) 依环境与分类的错误统计信息;
(iii) 环境元数据。
诊断智能体会输出:
(a) 存在显著弱点的环境排序列表 ;
(b) 针对性的任务生成指引 ,详细描述缺失的能力特征(例如特定参数错误、状态更新遗漏)。
智能体-环境协同演化
依据弱点环境及生成指引,系统再次运行可验证任务合成管线,生成靶向的强化学习训练集 。若分析表明当前数据库状态不够复杂,还会触发数据库的复杂化步骤。
最后,使用靶向数据对 继续执行多环境强化学习,得到进化的策略 。
整体演化流程为:
4. 实验设置与基线对比
研究在 23 个具有不同侧重点的基准测试上进行了全面评估。
评估基准测试 (23 Benchmarks)
-
核心智能体工具使用套件:MCP-Mark, BFCL V4, -Bench。 -
高级 AI 助手基准 :SkillsBench, ARC-AGI-2, Claw-Eval。 -
通用推理基准:MATH500, GSM8K, MATH, AIME24, AIME25, KOR-Bench, OlympiadBench。 -
智能搜索与代码基准 :WebWalkerQA, SWE-Bench Verified, SWE-Bench Multilingual, Terminal-Bench 1.0/2.0, GAIA, HLE。 -
知识与 MCP 领域基准 :MMLU, SuperGPQA, MCP-Universe (财务、浏览器、搜索、导航、代码仓库)。
基线模型对比
实验选取了三组基线:
-
闭源前沿模型:GPT-5.2 High, Claude Sonnet-4.5, Gemini-3 Pro, Seed2.0。 -
开源基础模型 (8B-685B) :DeepSeek-V3.2-685B, GPT-OSS-120B, Qwen3 系列 (235B, 32B, 14B, 8B)。 -
开源环境缩放训练模型 (7B-14B) :Simulator-8B, TOUCAN-7B, EnvScaler-8B, AWM-8B/14B, ScaleEnv-8B。
实现细节
在环境挖掘和任务合成阶段,统一采用 GPT-OSS-120B。训练阶段,基础模型选用 Qwen3-8B 和 Qwen3-14B,经过 40K 样本的冷启动 SFT 后,利用 5K 动态生成的 RL 样本应用 GRPO 算法训练。GRPO 中剪切比率设定为 。最大轨迹长度截断在 80K token,推理温度设定为 1.0。
5. 核心实验结果与解读
表 1 报告了模型在核心智能体工具使用基准上的表现。
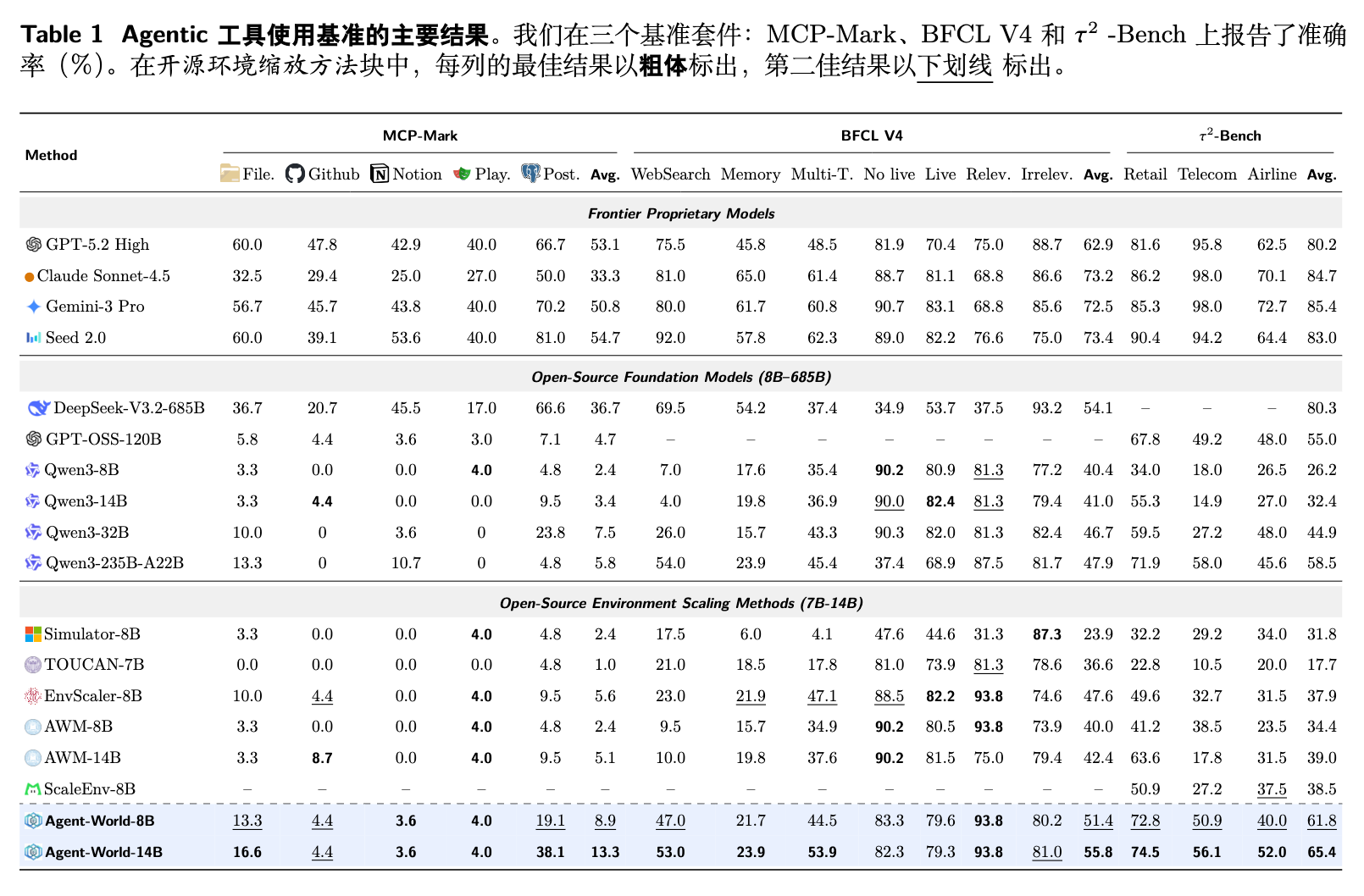
通过对各项分数的细致比对,可以得出以下结论:
-
即使是最先进的闭源模型,在长视距复杂环境中仍面临瓶颈。 例如,GPT-5.2 High 在 MCP-Mark 上的平均得分仅为 53.1%,Gemini-3 Pro 为 50.8%。开源基础模型更显不足,拥有 120B 和 235B 参数的模型得分均不足 6%。这表明常规的指令微调并不能有效地建立起多步规划和状态追踪能力。 -
现有的环境缩放模型存在能力获取的不均衡。 相比于未经特殊训练的 Qwen3 主干模型,EnvScaler-8B 等模型虽然有所提升,但提升表现并不均匀。例如,基于模拟器的 Simulator-8B 在 -Bench 表现尚可,但在 MCP-Mark 上表现糟糕。这说明,缺乏真实执行反馈的模拟环境难以教会模型处理复杂的现实状态转换。 -
Agent-World 实现了更加一致且广泛的跨环境泛化。 在相同的训练配置下,Agent-World-8B 模型在 -Bench (61.8%)、BFCL V4 (51.4%)、MCP-Mark (8.9%) 上均以明显优势超过了同样参数级别的开源基线模型(如 EnvScaler-8B 的 37.9%、47.1%、5.6%)。 -
参数扩展效应明显。 Agent-World-14B 相比 8B 模型展现出了约 5% 的绝对指标增长,并且在 BFCL-V4 上以 55.8% 的成绩逼近或超越了参数量高达数百亿的开源基础模型。
6. 定量与定性深度分析
研究围绕长视距通用推理场景与助手场景展开了进一步分析。
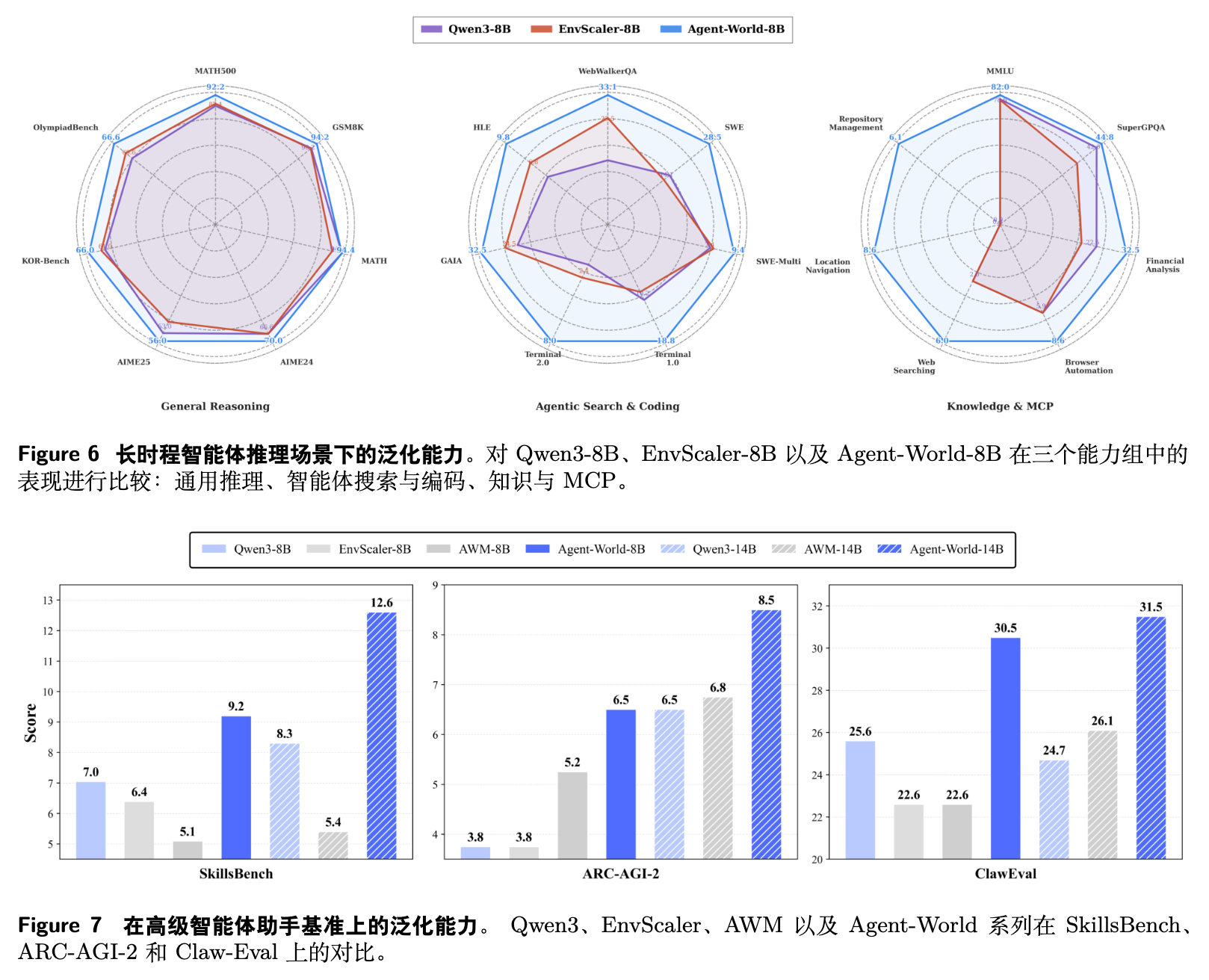
在增强智能体行为的同时,保持通用推理能力不退化。 在 MATH500, GSM8K, AIME 等七个核心推理数据集上,Agent-World-8B 的曲线紧紧包络甚至在多处超出其对应的 Qwen3 基座模型,这说明环境中的强化学习并未发生“灾难性遗忘”(Catastrophic Forgetting)。
在搜索与代码场景下取得最大收益。 在 WebWalkerQA、SWE-bench 系列及 Terminal 系列测试中,由于任务涉及迭代式的信息抓取、代码编译和上下文管理,Agent-World 的多环境强化学习让模型学会了鲁棒的试错和规划策略。
在未知领域的真实助手场景表现优异。 SkillsBench、ARC-AGI-2 和 ClawEval 等基准并未出现在训练分布中。现有的开源模型在这些基准上的平均通过率普遍低于 20%,甚至出现了规模扩展导致的性能退化(如 Qwen3 从 8B 到 14B 在 ClawEval 上从 25.6% 下降到 24.7%)。相反,Agent-World 表现出了稳定的向上扩展趋势,说明其在训练竞技场中获得了真正可泛化的底层逻辑能力。
7. 环境缩放与自进化机制消融分析
为了量化环境数量与模型性能之间的关系,研究设计了控制变量实验。
环境数量的缩放定律 (Scaling Analysis of Training Environments)
研究选取了 0, 10, 100, 500, 1000, 1978 个环境的梯度,评估四个代表性域(MCPMark Postgres, BFCL WebSearch/Multi-Turn, -Bench Airline)。
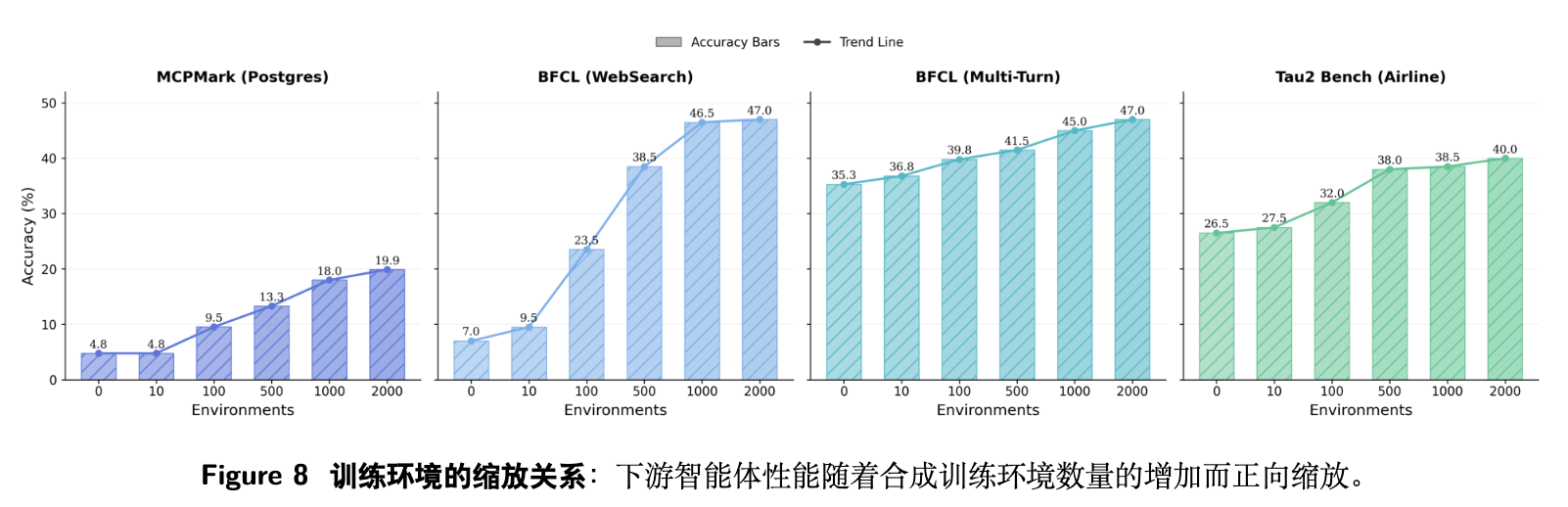
实验数据表明,随着合成环境数量的增加,下游性能持续稳定提升(四域平均分从 18.4% 上升至 38.5%)。
存在显著的“阶跃”特征:
-
从 10 增加到 100 个环境,以及 100 增加到 500 个环境时,性能增益最为明显(例如 MCPMark 从 4.8% 跃升至 19.9%)。这表明中等规模的扩展能迅速覆盖关键的交互模式类型。 -
从 500 到 2000 个环境,曲线斜率逐渐放缓。符合边际效用递减的规律,说明后期的扩展主要在于补充高阶罕见模式和提升系统的边界鲁棒性。
自进化机制分析 (Analysis of Continuous Self-Evolution)
为了验证闭环演化算法的价值,对 Agent-World-14B 以及作为基座的 EnvScaler-8B 进行了两轮演化测试。
-
Agent-World-14B 经过两轮循环,在 -Bench、BFCL-V4 和 MCP-Mark 上的得分分别从基础的 60.2%, 52.4%, 29.5% 跃升至 65.4%, 55.8%, 38.1%。 -
特别指出的是,首轮提升贡献了绝大多数的分数(如 MCP-Mark 增加 6.8 分),第二轮则集中于解决更加难以处理的长尾错误类型。 -
该自进化竞技场并非仅对特定初始化有效,即使是使用 EnvScaler-8B 模型进行接入,同样能够通过针对性的环境诊断与数据合成实现稳定涨分。这证实了该动态学习范式的普适性。
8. 训练动态分析
在强化学习的收敛性方面,研究对 GRPO 在长视距环境下的奖励曲线和策略熵进行了追踪。
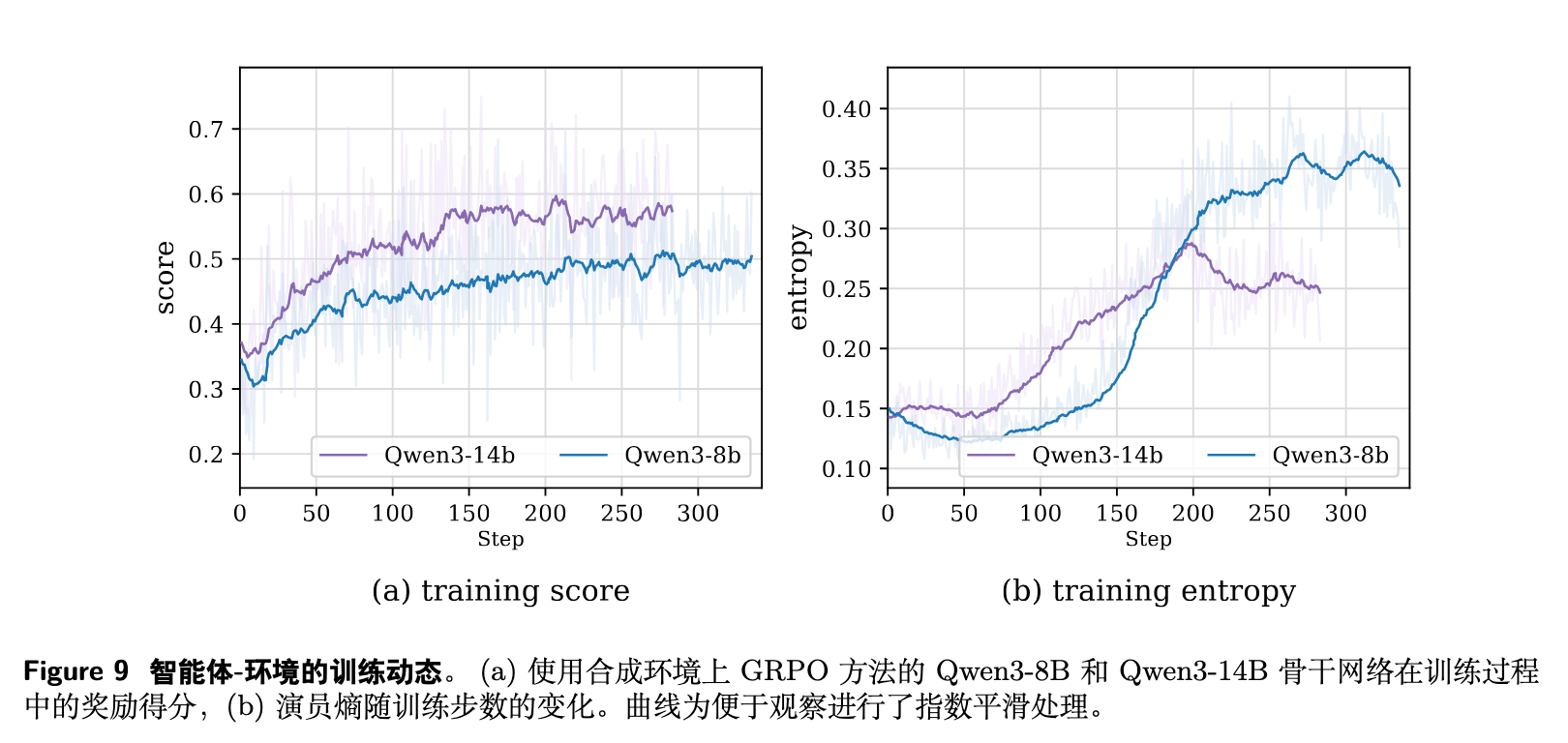
图 9a 显示,无论是 8B 还是 14B 参数级别,训练初期的奖励得分存在波动,但随着步数增加,均呈现明显的上升并最终收敛的趋势。这反映了可执行奖励在不同复杂度环境下提供的一致指导力。
图 9b 揭示了有趣的一点:模型的 Actor 熵并没有因为梯度的更新而迅速崩塌为零。相反,熵在训练过程中保持稳定甚至有小幅度的攀升。这在 RL 中被解释为:模型在面对大量未曾见过的异构 API 和状态转移时,自发维持了较高的探索空间,未陷入早期的过拟合(Narrow exploitation)。这正是通用智能体在开放世界所需要的特性。
9. 附录内容解析:典型环境配置与案例研究
本文在附录部分详细公开了合成环境的数据结构与代码实例,为复现提供了坚实依据。
9.1 环境可视化分析
文中列举了多个垂直领域的文件系统挂载与工具定义,这些构成了 POMDP 模型中的 和 。
-
Arxiv_local 环境:模拟一个本地离线文献库。文件系统包含 manifest.json索引文件以及形如1706.03762.md的元数据卡片。工具集提供list_local_papers,get_local_paper_metadata和search_local_papers。此设计使智能体可以在不进行外网请求的确定性条件下,完成多步检索引擎推理逻辑。 -
Emails 环境:模拟带有历史发件数据的邮箱。挂载了具有两千条合成邮件记录的 emails_export.json阵列,以及包含统计信息的mailbox_stats.json和用于存储附件文本的目录attachments/。工具接口支持分页检索(list_emails)、基于正则表达式或字符串的内容搜索(search_emails)以及附件内容读取。这种设计考验模型面对大量无关干扰文本时的状态维持能力。 -
Calendar 环境:构建基于 JSON 格式的后台日历体系。涉及的用户数据存储于 users.json,公共假期存储于holidays.json,而结构化的预约信息存储于events.json(包含时区处理机制)。工具操作包括对日期的区间查询(list_events_in_range)等,模型必须掌握针对时间比较的确定性逻辑,而非简单的关键字匹配。 -
Hotels 环境:实现了预订流程的状态转换测试床。包括地名解析文件 places.json、基础设施记录facilities.json、详情描述hotel_details.json以及用于存储状态变动的追加写入对象bookings.json。预订工具book_hotel被触发后,将实质性更改系统底层的 JSON 档案,此动作会被外部验证脚本用于断言评估,形成强反馈信号。 -
App_stores 环境:一个用于执行复杂的跨应用商店比对的环境。该环境中包含了具有高度字段耦合的苹果与谷歌应用商店摘要及评论。相关工具仅仅提供基于硬编码文件路径的薄层包装(thin wrapper),模型必须依赖多步调用进行特征整合,比如合并用户的隐私许可条款或处理多语言文本。 -
Food_delivery 环境:模拟多城市外卖服务。其特色在于融入了预计算的空间哈弗辛距离表 distances.json以及包含部分城市天气信息的weather_2025.json,通过将地理距离计算与恶劣天气条件组合,合成复杂的带约束多步路线规划任务。
9.2 诊断系统提示词拆解
框架能够自主进化的核心在于自动诊断智能体 接收并解析的提示模板(Prompt A 和 Prompt B)。
-
系统提示词 (Prompt A) 要求诊断器执行三项任务:(1) 对失败追踪进行根本原因分类;(2) 识别并排序最有问题的弱点环境;(3) 输出针对性指导方案。要求其必须返回格式严整的 JSON 报告。 -
用户提示词 (Prompt B) 注入了测试模型的各项元数据、由环境到分类的错误统计分布表以及每个失败样例的详细痕迹(含领域环境名称、原始任务描述、被破坏的具体评估标尺、可调用的工具 Schema 以及完整的会话记录)。这相当于让另一个强大的 LLM 执行 Debug 过程。
9.3 实际交互案例研究
通过具体的 Interaction Turn,展示了强化学习后的 Agent 在面对约束时的规划能力。
-
案例 1(电商 MCP 服务器多步退货执行):用户请求针对最近的订单发起退货。智能体首先调用 find_user_id_by_name_zip解析用户身份,然后通过get_user_details提取历史订单号。接着,模型必须使用get_order_details对数个历史订单执行迭代式的合规性检查(甄别哪些处于已送达状态)。在获取具体物品后,提交return_delivered_order_items,系统验证底层的退货状态标志位被正确置位。整个流程达 9 步,没有任何非法参数抛出。 -
案例 2(Slack 工作空间自动化):任务要求执行合规性分类审查。模型利用 get_message_by_ts获取违规文本,然后抽取发送者信息。为了判定语义差异,模型提取该用户历史发言记录并尝试计算词法差异分。其中还包含了对当前用户登录状态以及联系人依赖图的联合推理。最终模型生成了完全符合量表规范的结构化评审结果。 -
案例 3(人口数据检索与排行):模型被要求进行受数学公式约束的量化排序。智能体调用人口排行和增长数据后,需要对特定参数执行对数变换。轨迹日志显示,在面对 get_precision_constant函数由于高精度常量缺失而返回None时,模型并未崩溃,而是自发触发了基于get_logarithms_for_value的回退推理逻辑(Fallback via explicit checks),顺利给出了最终赢家。这展现了模型在不可靠外部环境中的高度韧性。
10. 总结与局限性探讨
Agent-World 系统地解决了一直以来束缚通用智能体能力提升的两大核心痛点:即环境数据获取的困难以及缺乏机制去填补模型在遇到新问题时的能力断层。该方案从底层互联网文档与真实 MCP 通信协议中自主抽取规律建构环境;使用结合了基于图拓扑的参数化合成与基于代码验证的动态合成生成难度逐渐累加的客观任务;并且借助于带有自动错误溯源的 GRPO 闭环强化学习,实现环境随模型的共同进化。实验证明,这一整套工程化与理论化并重的范式,能够有效拉平开源中小参数模型与商业闭源千亿模型在严苛工作流执行上的差距。
潜在的局限性
-
沙盒开销与安全性问题:尽管代码生成与环境复杂化是自动执行的,但在本地沙盒中运行大量非确定的 Python 脚本进行验证器开发与奖励计算,其计算开销和并行调度的复杂性依然是一个工程挑战。 -
诊断智能体的天花板:自我进化模块极大依赖于负责执行“Agentic Diagnosis”的裁判模型的能力。如果诊断智能体(当前实验使用的是 GPT-OSS-120B 等强大模型)本身产生幻觉或提供方向错误的改进指南,将会导致数据流向次优甚至有害的方向偏移。 -
多模态融合的缺失:当前 Agent-World 聚焦于纯粹的文本态和结构化 JSON/API 交互。在图形用户界面(GUI)或多模态操作环境日益普及的当下,未来的工作有必要将该合成管线拓展至基于视觉反馈的操作环境中。
总而言之,Agent-World 将环境视为与模型同等重要的持续进化实体,提供了一个稳健的大型智能体能力提升的基座,也为未来的复杂系统自主学习指明了可行方向。
更多细节请阅读原文。
往期文章:

