
-
论文标题:On GRPO Collapse in Search-R1: The Lazy Likelihood-Displacement Death Spiral -
论文链接:https://arxiv.org/pdf/2512.04220
TL;DR
在大语言模型(LLM)的工具集成强化学习(Tool-Integrated Reinforcement Learning, TIRL)中,Group Relative Policy Optimization (GRPO) 是一种常用的算法(如 Search-R1)。然而,研究发现 GRPO 在这种设置下极易发生训练崩溃(Training Collapse),表现为奖励值在短暂上升后骤降至零。
今天解读的这篇论文《On GRPO Collapse in Search-R1: The Lazy Likelihood-Displacement Death Spiral》指出了导致崩溃的核心机制:懒惰似然位移(Lazy Likelihood Displacement, LLD)。
LLD 指的是模型在优化过程中,正确回答的似然概率(Likelihood)出现停滞甚至下降的现象。这种现象会引发一个“死亡螺旋(Death Spiral)”:似然下降导致模型置信度降低 梯度膨胀 熵爆炸 最终模型崩溃。
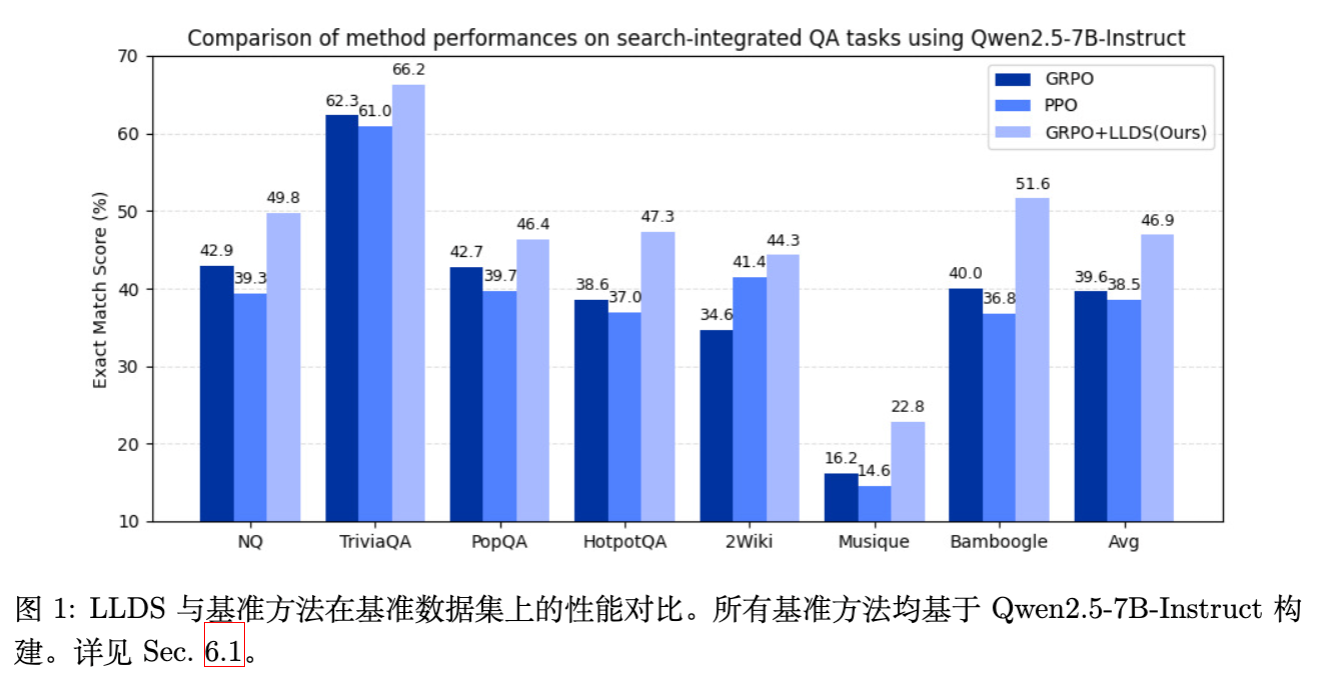
为解决这一问题,作者提出了 LLDS(Likelihood-Displacement Regularization),一种轻量级的正则化方法。该方法仅在轨迹的总似然下降时激活,并专门针对导致下降的 token 进行惩罚。实验表明,LLDS 有效稳定了训练,并在 Qwen2.5-3B 和 7B 模型上实现了高达 +37.8% 的性能提升。
1. 引言
大语言模型通过集成外部工具(如搜索引擎、代码解释器),能够显著增强其解决复杂问题的能力。为了让模型学会规划、调用工具并根据反馈进行多步推理,强化学习(RL)成为了主流的训练范式。
DeepSeek-R1 等工作展示了 GRPO 在提升模型推理能力方面的潜力。GRPO 摒弃了传统 PPO 中的价值函数(Value Function),采用组内相对优势(Group Relative Advantage)来估计策略梯度,因其收敛速度快且实现简单而备受青睐。
然而,将 GRPO 直接应用于多轮工具集成推理(Multi-turn TIRL)场景时,研究人员观察到了严重的训练不稳定性。与纯文本推理任务不同,工具调用引入了外部环境反馈,导致轨迹更长且更复杂。在 Search-R1 复现实验中,GRPO 经常在训练初期取得一定进展后,突然遭遇奖励坍塌,模型输出退化为无意义的乱码。
2. 懒惰似然位移(LLD)
为了理解训练崩溃的原因,首先需要量化模型在训练过程中的行为变化。作者定义了一个核心概念:懒惰似然位移(LLD)。
2.1 定义
在 GRPO 优化过程中,我们期望经过微调的策略 对正确轨迹的似然概率要高于旧策略 。然而,LLD 描述了相反的情况:正确回答的似然概率不仅没有显著提升,反而出现停滞或下降。
形式化地,对于一条工具集成的轨迹,包含动作 和工具反馈 (在计算似然时反馈被掩码),定义动作 的对数似然变化量 为:
当 (其中 为非正小常数)时,称该响应发生了懒惰似然位移。
在工具集成 GRPO 的背景下,作者观察到一种急性的 LLD 形式,即 ,意味着模型对正确路径的生成概率在持续衰减。
2.2 崩溃的三阶段
通过监控训练过程中的奖励(Reward)、正确响应的似然(Correct Likelihood)和梯度范数(Gradient Norm),研究揭示了崩溃过程的三个典型阶段:
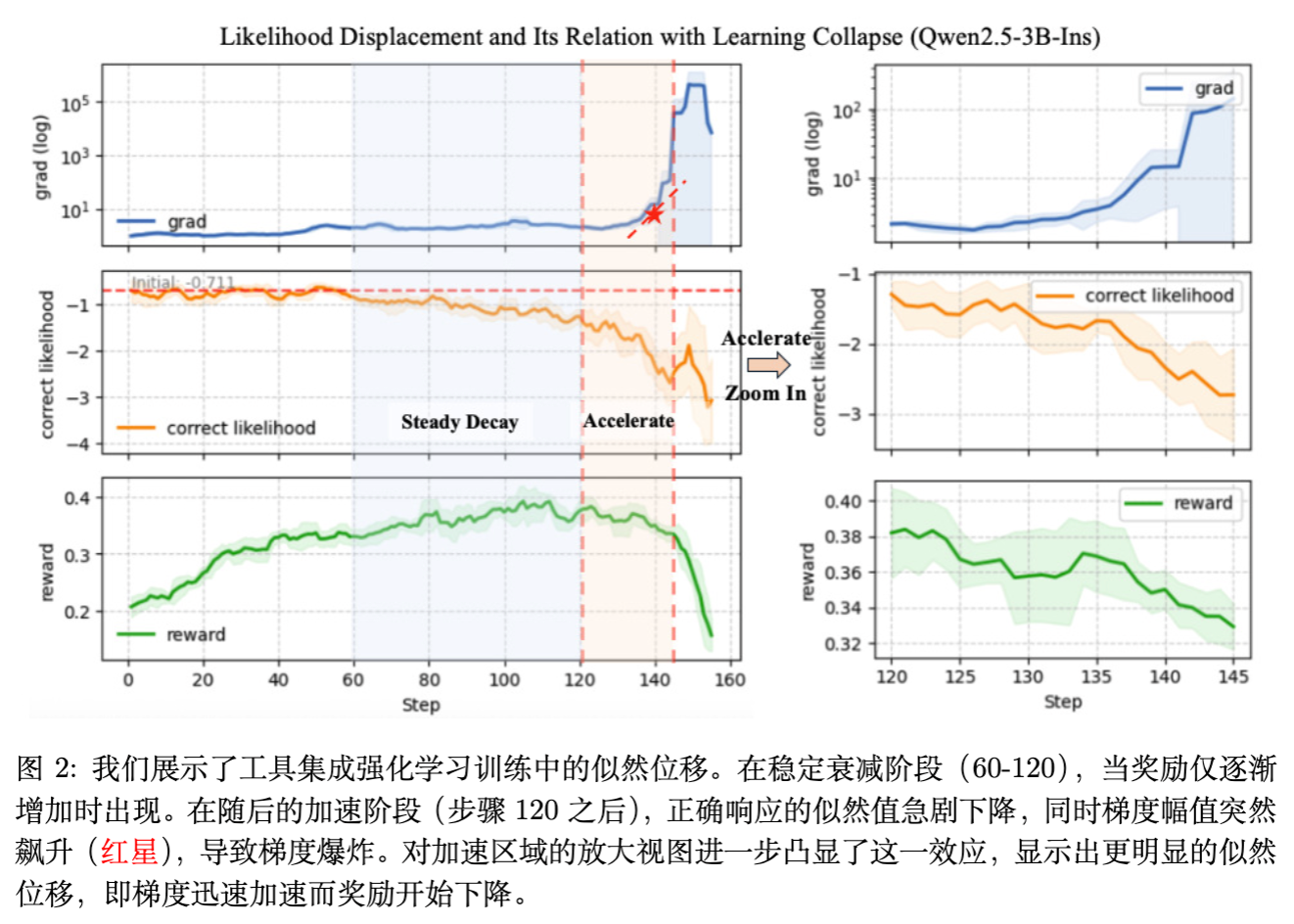
[图 2 中文标题:工具集成 RL 训练中的似然位移现象说明]
-
早期停滞期(Early Stagnation): 奖励开始缓慢上升,但正确响应的似然几乎不变。LLD 初步浮现。 -
稳步衰减期(Steady Decay): 随着训练进行,奖励继续缓慢增长。然而,正确响应的似然开始单调下降。这是一个反直觉的现象:模型虽然在获得更高的平均奖励,但它对“产生正确答案”这件事本身却变得越来越不自信。 -
加速崩溃期(Accelerated Collapse): 似然度降至临界点以下,触发“死亡螺旋”。梯度范数突然爆发(Gradient Explosion),熵(Entropy)急剧上升,模型输出彻底崩坏,奖励跌至零。
3. LLD 死亡螺旋
为什么正确响应的似然会下降?为什么这会导致最终的崩溃?本节将从 GRPO 的梯度更新机制和工具交互的特性两个方面进行理论拆解。
3.1 GRPO 的更新机制与负梯度主导
GRPO 的目标函数如下:
其中 是标准化后的优势函数。对于得分低于平均值的响应(错误响应), 为负。
作者的理论分析(基于相关工作的定理扩展)指出,轨迹层面的似然变化受两类因素影响:
-
正样本的推动:鼓励模型提高高分回答的概率。 -
负样本的抑制:迫使模型降低低分回答的概率。
在工具集成场景下,负梯度的影响往往占据主导地位,原因如下:
-
低似然的错误响应:当模型生成了一些概率极低(Low-likelihood)的错误响应时,由于重要性采样(Importance Sampling)权重的存在,这些样本会导致巨大的预测误差权重,从而产生极大的负梯度。 -
嵌入相似性(Embedding Similarity):在多轮对话的早期(例如第一步搜索),正确轨迹和错误轨迹往往非常相似(例如都发出了正确的搜索查询)。这意味着它们在特征空间中的嵌入向量高度重叠。此时,来自错误轨迹的巨大负梯度会“误伤”正确轨迹,强行拉低正确动作的概率。
3.2 死亡螺旋的形成
LLD 一旦开始,就会形成一个自我增强的负反馈回路,即 LLD 死亡螺旋(LLD Death Spiral):
-
LLD 启动:由于负梯度主导,正确 token 的概率被抑制。 -
低置信度(Low Confidence):模型对自己的输出越来越不确定,表现为预测分布变得平坦。 -
熵增(Entropy Explosion):分布平坦导致策略的熵值显著增加。 -
梯度膨胀:根据策略梯度公式,低概率的动作会导致似然比(Likelihood Ratio)的分母变小,或者在反向传播时产生更大的梯度值。 -
进一步抑制:更大的梯度导致参数更新步长过大,进一步破坏模型原本学到的知识,导致正确率继续下降,回到步骤 1。
最终,这种循环导致数值溢出或参数崩坏。
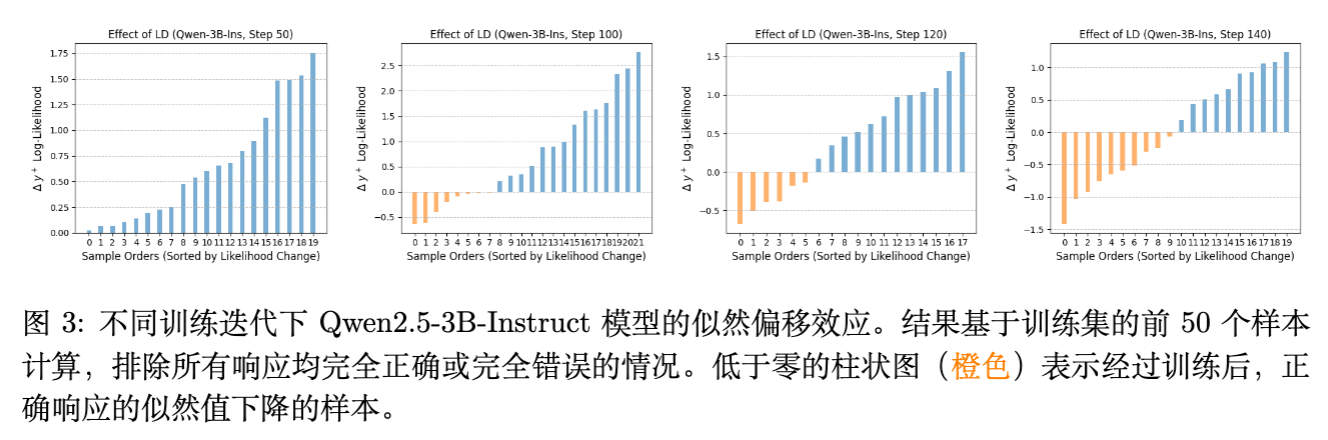
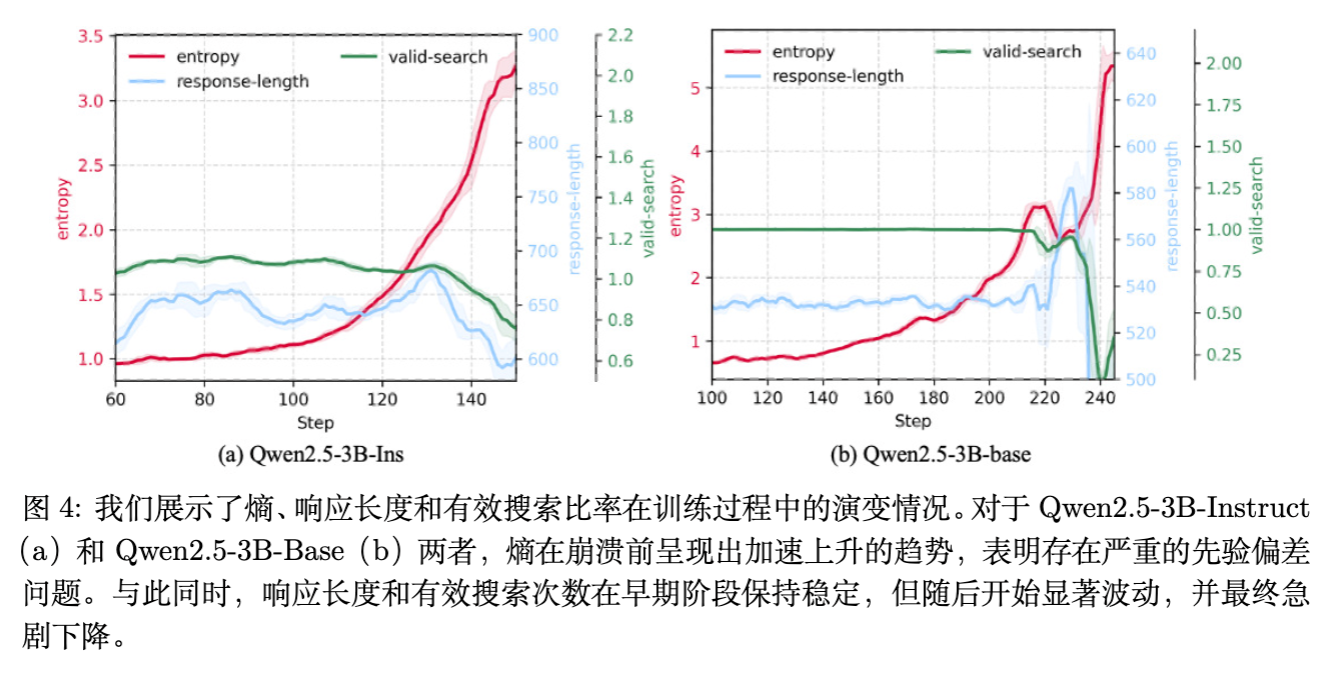
图 4 清晰地展示了熵的演变:在崩溃前夕,熵值呈现出指数级上升,这正是模型陷入“混乱”状态的直接证据。
3.3 特例分析:夹杂在错误响应中的正确动作
工具集成场景的一个独特之处在于动作的局部正确性。
在 Search-R1 中,模型通常遵循“思考 搜索 阅读 回答”的模式。实验发现,即便最终答案是错误的,模型的第一步(生成搜索查询)往往是正确的。
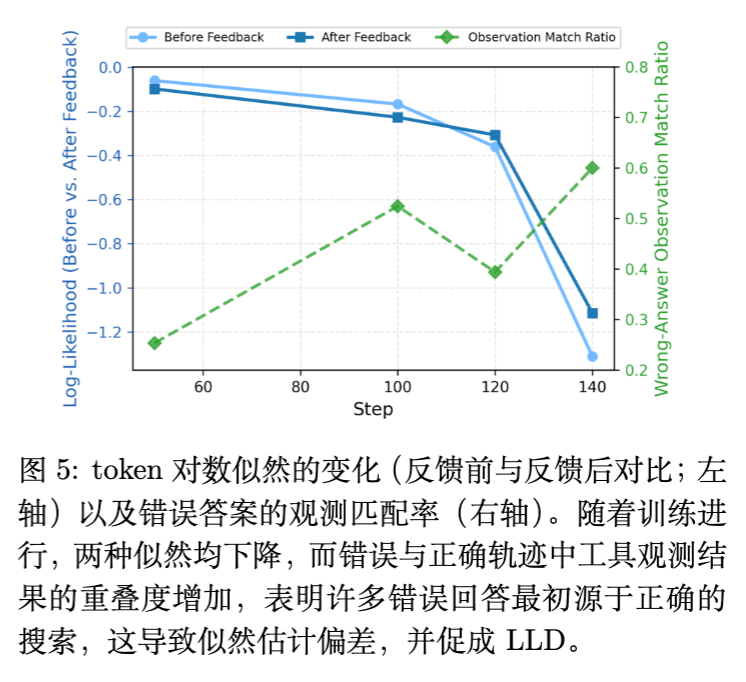
-
现象:随着训练进行,错误响应中包含“正确首动作”的比例从早期的低位上升至 60% 以上(如图 5 所示)。 -
后果:GRPO 对整个轨迹赋予一个统一的标量奖励。如果最终答案错误,整个轨迹(包括那个正确的搜索动作)都会被赋予负优势。 -
冲突:模型一方面通过正样本学习到了“这个搜索是对的”,另一方面又通过负样本收到“这个搜索是错的”的信号。由于负样本数量往往多于正样本,且如前所述负梯度影响更大,模型最终倾向于抑制这个正确的搜索动作。
这种对局部正确动作的无差别惩罚,是导致 LLD 在工具学习中尤为严重的关键原因。
4. 似然位移正则化 (LLDS)
为了打破这一死循环,作者提出了一种直观且有效的正则化方法:LLDS。其核心思想是:明确禁止模型降低正确或中性轨迹的似然概率。
4.1 基础形式:Token 级似然保留
LLDS 引入了一个辅助损失项,仅在似然值下降时产生惩罚。对于保留集 中的响应 ,损失函数定义为:
这个公式的含义是:如果新策略下某个 token 的概率比旧策略低,就产生损失;如果概率升高或不变,损失为 0。
4.2 进阶形式:响应级门控 (Response-Level Gating)
直接对每个 token 进行约束可能过于严格,因为有时为了全局最优,局部概率的微调是必要的。因此,作者提出了带门控机制的 LLDS:
其中指示函数 表示只有当整条响应的总似然下降时,才激活正则化。且激活后,仅惩罚那些导致下降的特定 token。
4.3 变体:掩码答案 (LLDS-MA)
为了进一步鼓励模型使用工具进行多步推理,而不是过早生成答案,作者提出了 LLDS-MA (Masking Answer Tokens) 。
该变体在计算正则化项时,将最终的 <answer>...</answer> 部分掩盖掉。这意味着:
-
模型在“思考”和“工具调用”阶段的似然受到保护,防止能力退化。 -
模型在生成最终答案时的似然不受约束,允许其进行较大的探索和调整。
这对于那些倾向于只搜索一次就匆忙回答的 Base 模型尤为重要。
最终的总损失函数为:
通常取 。保留集 包含所有非负优势()的响应。
5. 实验与结果分析
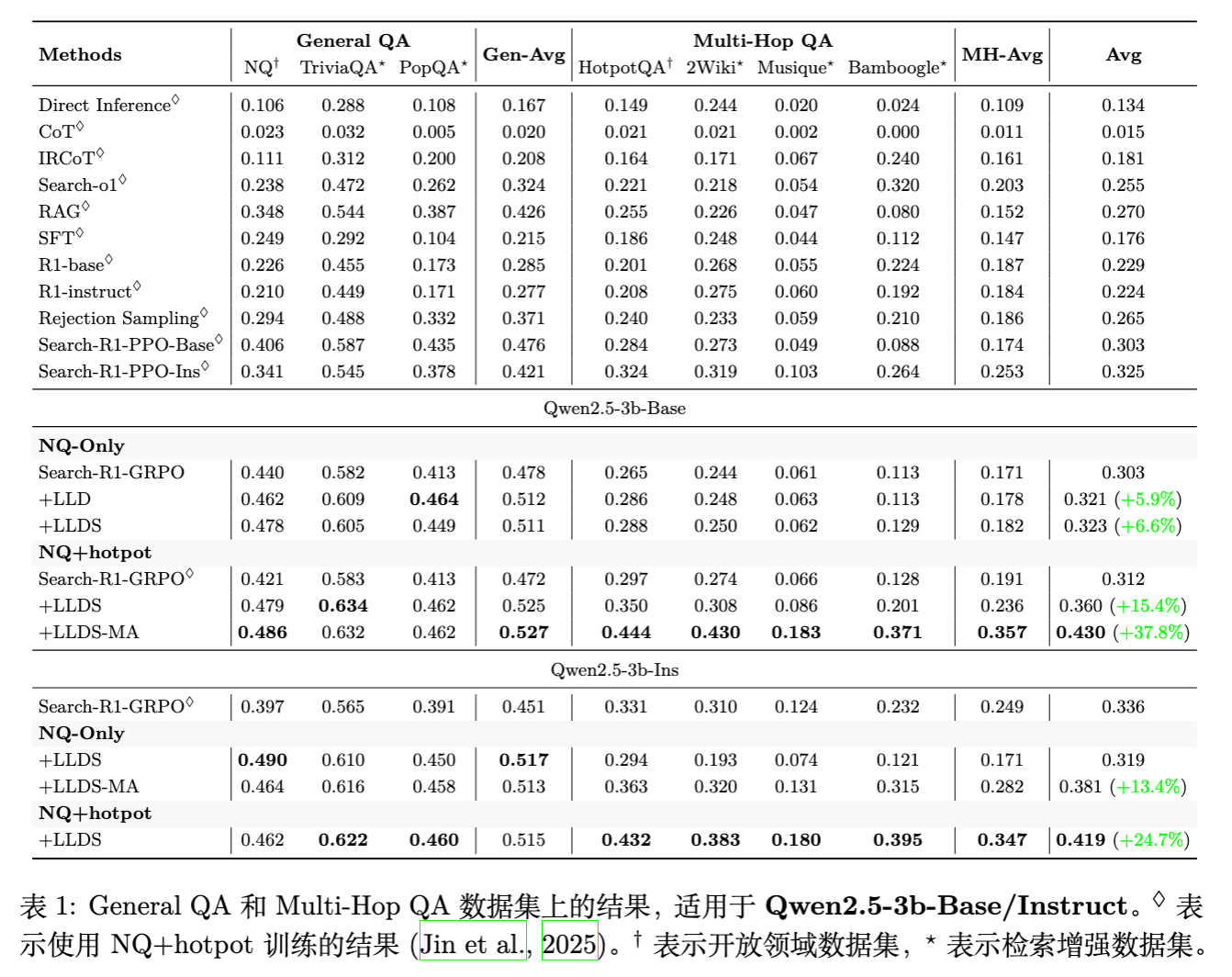
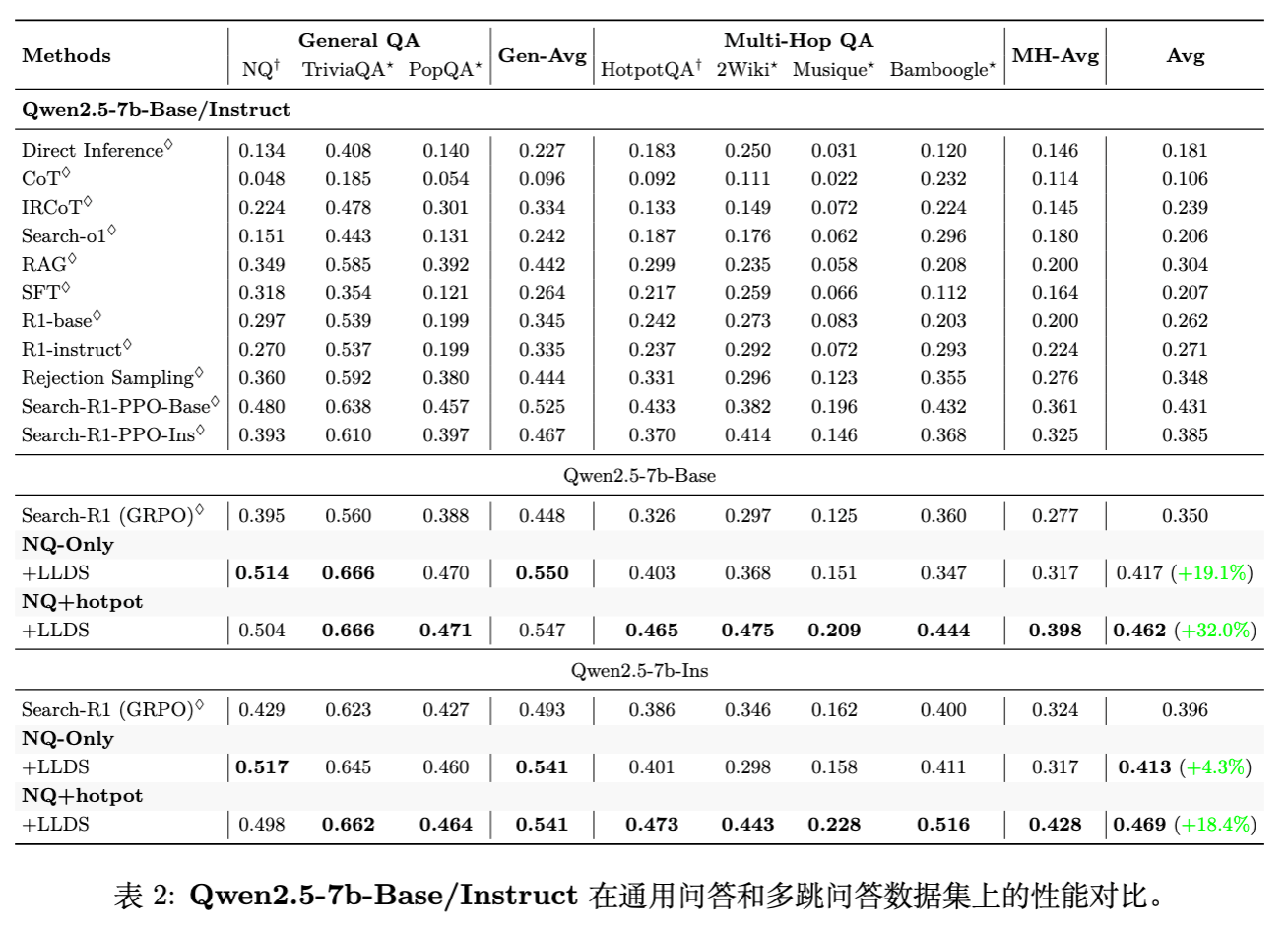
实验基于 Qwen2.5-3B 和 Qwen2.5-7B 模型(包括 Base 和 Instruct 版本),在 7 个开放域问答(QA)和多跳 QA 基准数据集上进行了评估。
5.1 实验设置
-
数据集: -
单跳:NQ (Natural Questions), TriviaQA, PopQA。 -
多跳:HotpotQA, 2WikiMultiHopQA, Musique, Bamboogle。
-
-
训练配置: -
NQ-Only:仅在 NQ 上训练。 -
NQ+Hotpot:在 NQ 和 HotpotQA 混合数据上训练。
-
-
基线:Search-R1 (基于 GRPO)。由于原生 GRPO 经常崩溃,基线结果取自崩溃前的最佳检查点。
5.2 主要结果
实验结果显示 LLDS 带来了一致且显著的提升。
关键发现:
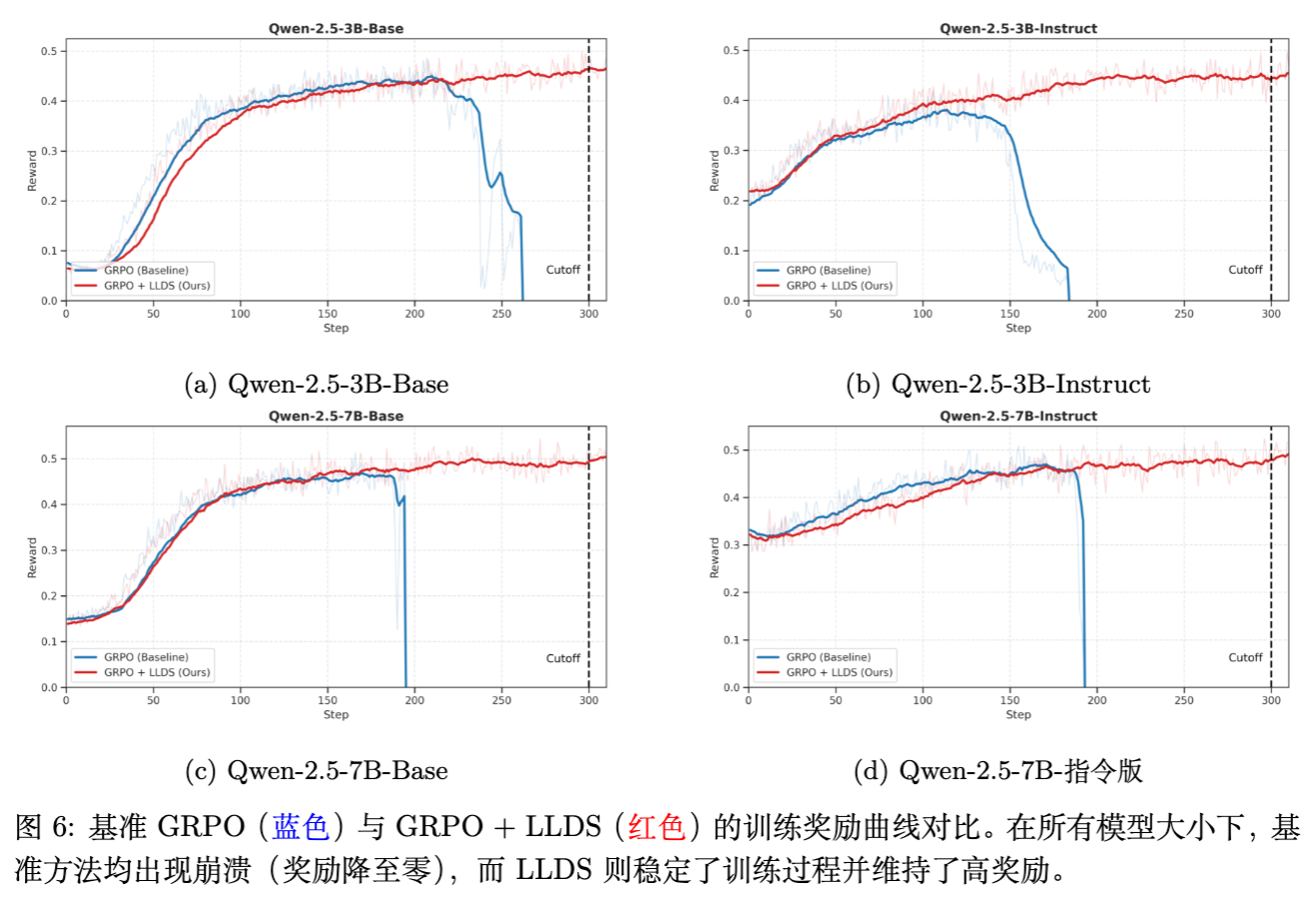
-
防止崩溃,稳定训练:如图 6 所示,引入 LLDS 后,所有模型的奖励曲线均保持稳步上升,未出现基线方法中的骤降归零现象。 -
显著的性能提升: -
对于 Qwen2.5-3B-Base,在 NQ+Hotpot 设置下,LLDS-MA 将平均得分从 0.312 提升至 0.430,相对提升达 37.8% 。 -
对于 Qwen2.5-7B-Base,LLDS 将平均得分从 0.350 提升至 0.462,相对提升 32.0% 。
-
-
多跳推理能力的唤醒: -
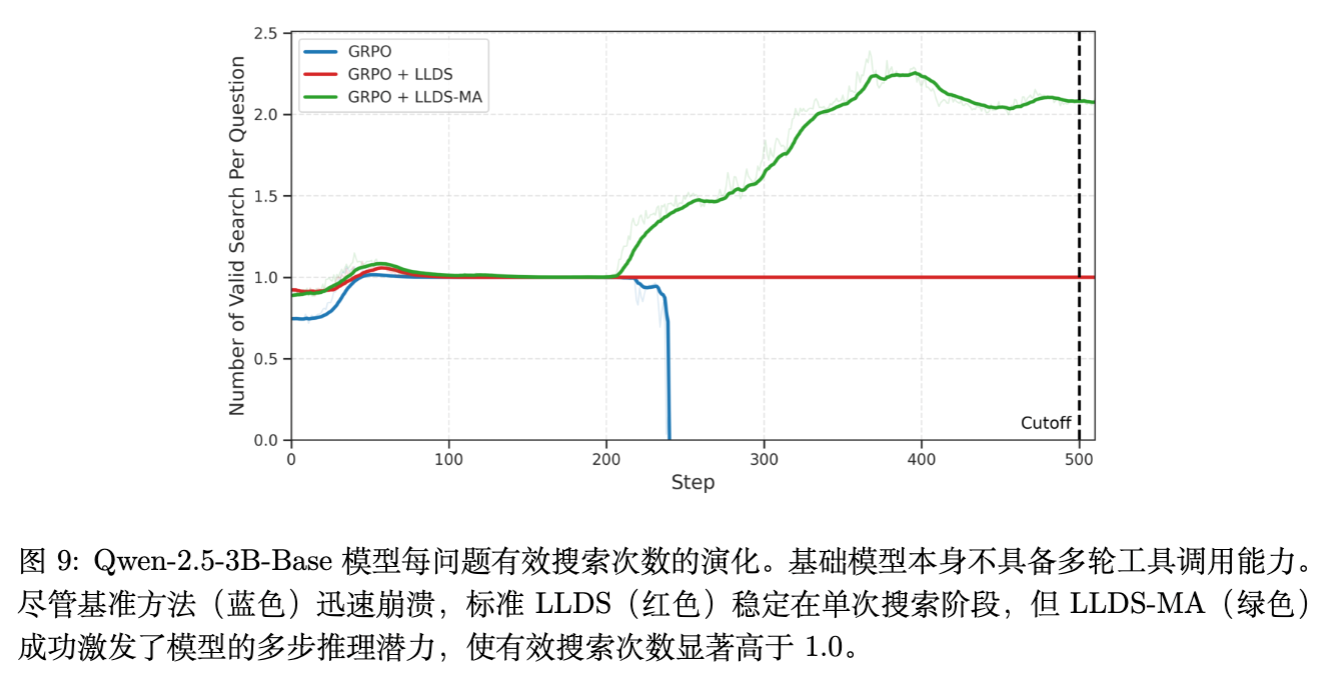
在 Qwen2.5-3B-Base 上,原生 GRPO 倾向于单步搜索。 -
使用 LLDS-MA(掩盖答案正则化)后,模型学会了进行多次搜索以收集证据。如图 9 所示,有效搜索次数显著增加。
-
-
泛化能力:即便仅在 NQ(单跳)上训练,使用 LLDS 的模型在多跳数据集(如 HotpotQA)上的表现也优于基线,说明模型学到了更鲁棒的搜索和推理策略,而非仅仅过拟合数据。
5.3 案例研究
文章展示了两个具体的案例来阐述 LLDS 的作用:
案例 1:NRL Grand Final(嵌入相似性问题)
-
问题:2015年 NRL 总决赛谁赢了? -
现象:GRPO 生成了一个正确轨迹和一个错误轨迹。两者思考过程几乎一样,搜索词一样,甚至阅读的文档也一样。唯一的区别是错误轨迹的答案截断了("North Queensland" vs "North Queensland Cowboys")。 -
分析:由于前缀高度相似,错误轨迹产生的负梯度严重干扰了正确轨迹的 embedding 学习。LLDS 通过强制保留正确路径的似然,防止了这种干扰。
案例 2:Green Eggs and Ham(低似然长轨迹问题)
-
问题:《绿鸡蛋和火腿》的主角是谁? -
现象:错误轨迹生成了一段极长的、逻辑混乱的 <think>内容,最终给出了错误答案。由于该轨迹很长且概率很低(因为乱码),其在 GRPO 中产生了巨大的负权重。 -
分析:这种“低质量、长长度”的负样本是导致梯度爆炸的元凶。LLDS 限制了模型对正常轨迹似然的破坏,使得模型能够抵抗这种噪声数据的冲击。
6. 讨论
6.1 为什么工具集成 GRPO 如此脆弱?
与纯文本 RL 不同,工具调用引入了分布外(OOD)数据。搜索结果、API 返回值等内容并非模型生成的,而是来自外部环境。
-
不确定性引入:OOD token 增加了序列的不确定性,使得相对更新更加剧烈。 -
阶段性不匹配:工具推理分为多个阶段。早期阶段(如提问)通常很快收敛,而后期阶段(如整合信息)较难。GRPO 这种“一荣俱荣,一损俱损”的整条轨迹奖励机制,容易让后期错误产生的负信号,错误地惩罚了早期正确的动作。
6.2 监控指标的选择:奖励是不够的
这是一个极其重要的工程经验:不要只盯着 Reward 曲线。
-
隐蔽性:如前所述,LLD 往往在 Reward 还在上升时就已经发生了。 -
推荐指标:必须监控 Likelihood(似然)、Entropy(熵) 以及 Gradient Norm(梯度范数)。 -
如果你看到正确回答的 Likelihood 开始缓慢下降,或者 Entropy 突然出现拐点向上,这就是崩溃的前兆,即使此时 Reward 看起来一切正常。 -
可视化 Action-level 的似然变化有助于早期发现问题。
-
6.3 梯度分析的重要性
理解梯度的来源是解决不稳定的关键。在 GRPO 中,由于采用了相对优势,,这意味着如果一组采样中大部分都很差,那个稍微好一点的(或是完全错误的)可能会得到不合理的正向激励;反之,如果一组都很好,稍差一点的正确答案可能会受到严厉惩罚。LLDS 本质上是给这个相对过程加了一个绝对的“锚点”:不论相对优势如何,你不能让原本好的东西变差。
往期文章:


