
-
论文标题:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models -
论文链接:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf -
项目地址:https://github.com/deepseek-ai/Engram/tree/main
TL;DR
DeepSeek-AI 团队联合北京大学刚刚发布了新论文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》,提出了一种名为 Engram 的条件记忆机制。该研究指出,当前的 Transformer 架构缺乏原生的知识查找(Lookup)原语,被迫通过计算(Attention/FFN)来模拟检索,这种方式处理静态或局部模式(如实体、固定短语)效率低下。
Engram 模块通过现代化的 -gram 嵌入表引入了 条件记忆(Conditional Memory),作为对混合专家模型(MoE)中 条件计算(Conditional Computation) 的补充。研究通过定义“稀疏性分配(Sparsity Allocation)”问题,发现了计算与记忆之间的 U 型权衡曲线。实验表明,将部分 MoE 专家参数重新分配给 Engram 内存,能在保持总参数量和计算量(FLOPs)不变的情况下,显著提升模型在知识密集型任务、通用推理、代码及数学任务上的性能,并大幅增强长上下文检索能力。此外,Engram 的确定性寻址特性支持从主机内存(Host Memory)无损预取,使其能够突破 GPU 显存限制,实现极大规模的参数扩展。
1. 引言
在现代大语言模型(LLM)的设计中,稀疏性(Sparsity)已成为扩展模型规模的核心原则。目前,这一原则主要通过混合专家(Mixture-of-Experts, MoE)架构实现,即通过条件计算(Conditional Computation)来扩大模型容量而不显著增加推理成本。然而,语言建模任务本身包含两种性质截然不同的子任务:
-
组合推理(Compositional Reasoning): 需要深度、动态的计算处理。 -
知识检索(Knowledge Retrieval): 涉及大量局部、静态且高度定型(Stereotyped)的文本模式,如命名实体、习语和公式化表达。
现有的 Transformer 架构缺乏原生的查找原语,迫使模型利用宝贵的注意力机制和前馈网络层来“重构”这些静态的查找表。例如,识别“Diana, Princess of Wales”这样的多词实体,模型往往需要消耗多个浅层网络的计算资源来进行上下文整合。这种通过计算模拟检索的过程造成了模型深度的浪费。
为了解决这一结构性不匹配,论文提出了 条件记忆(Conditional Memory) 这一新的稀疏轴,并实例化为 Engram 模块。与 MoE 根据动态逻辑激活参数不同,Engram 依赖稀疏的查找操作来检索固定知识的静态嵌入。该设计并非简单的 -gram 回归,而是结合了分词器压缩、多头哈希、上下文门控和多分支集成等现代深度学习技术。
2. 稀疏性分配定律
本研究的一个核心理论贡献在于形式化了 稀疏性分配(Sparsity Allocation) 问题。在给定的总参数预算和训练计算预算下,如何在 MoE 专家(神经计算)和 Engram 内存(静态存储)之间分配容量?
2.1 计算匹配形式化
研究定义了以下参数指标:
-
:总可训练参数量(排除词嵌入和 LM Head)。 -
:每 token 激活参数量,决定训练成本(FLOPs)。 -
:非激活参数量,即“免费”的参数预算。
对于 MoE,非选中的专家贡献了 ;对于 Engram,未被检索的嵌入槽位贡献了 。由于 Engram 的检索是 的且仅涉及极少量的投影计算,增加嵌入槽位数量几乎不增加每 token 的 FLOPs。
2.2 分配比率与 U 型曲线
定义分配比率 为分配给 MoE 专家容量的非激活参数比例:
-
:纯 MoE 模型。 -
:减少路由专家数量,将释放的参数预算分配给 Engram 嵌入表。
实验在两个计算量级( FLOPs 和 FLOPs)下进行,保持稀疏比 。结果显示,验证集损失(Validation Loss)随 呈现清晰的 U 型曲线(见下图)。
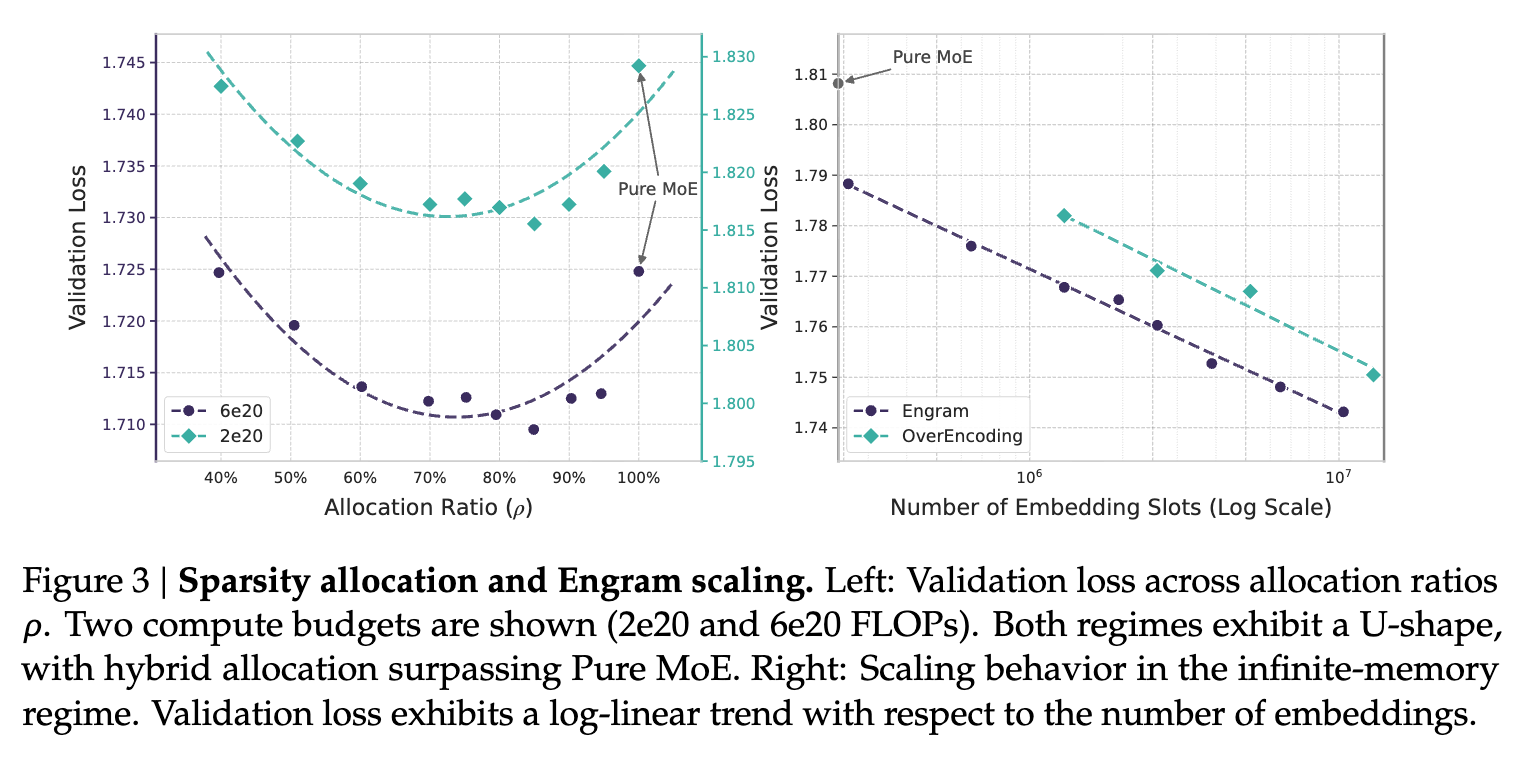
主要发现:
-
纯 MoE 非最优: 将约 20% - 25% 的稀疏参数预算重新分配给 Engram(即 )能获得最佳性能。 -
结构互补性: -
(MoE 主导):缺乏专用记忆,模型被迫用计算深度重构静态模式。 -
(Engram 主导):丧失条件计算能力,损害需要动态推理的任务。
-
2.3 无限内存机制 (Infinite Memory Regime)
如果放宽内存限制(利用系统内存层级),Engram 表现出严格的幂律缩放(Power Law)。这意味着 Engram 提供了一个独立于计算之外的可预测扩展旋钮:更大的内存可以直接转化为性能增益,且不增加计算负担。
3. Engram 架构设计
Engram 模块作为一个条件记忆单元,被插入到 Transformer 主干网络的特定层中。其工作流程分为 检索(Retrieval) 和 融合(Fusion) 两个阶段。
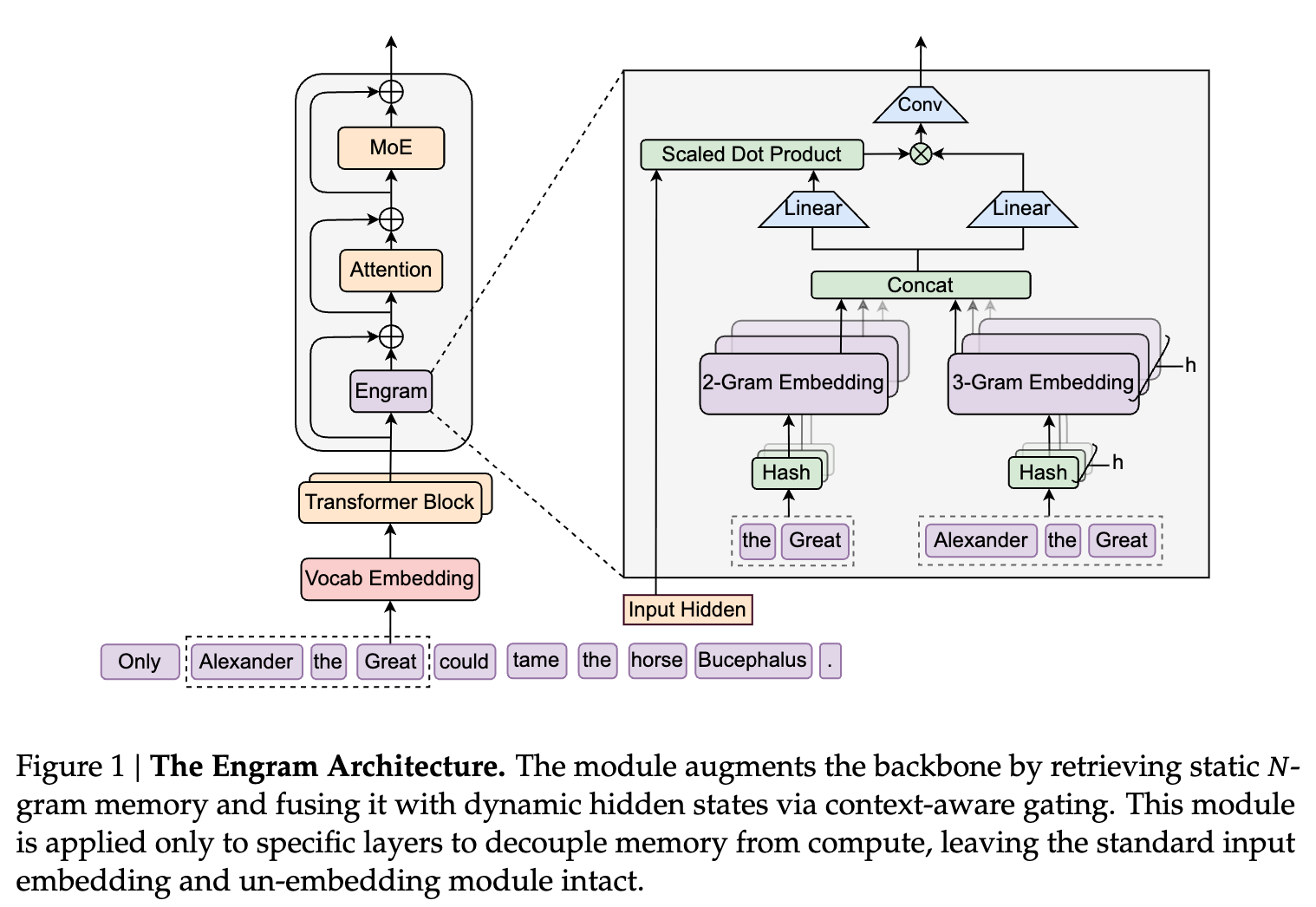
3.1 稀疏检索:哈希 -grams
为了将局部上下文映射到静态内存条目,Engram 采用了两个关键技术:
A. 分词器压缩 (Tokenizer Compression)
标准的子词分词器(Subword Tokenizers)优先考虑无损重构,导致语义上等价的项被分配了不相交的 ID(例如 Apple vs _apple)。为了最大化语义密度,Engram 实现了一个预计算的满射函数 ,将原始 Token ID 映射为规范化 ID(基于 NFKC 标准化、小写化等)。这一步骤使 128k 词表大小的有效词汇量减少了约 23%,显著提升了 -gram 的覆盖效率。
形式上,对于位置 的 token,其规范化 ID 为 ,构成的后缀 -gram 为 。
B. 多头哈希 (Multi-Head Hashing)
直接参数化所有可能的 -gram 组合是不切实际的。Engram 采用哈希方法,并引入 个哈希头来缓解冲突。每个头 将压缩后的上下文映射到嵌入表 中的索引:
最终的记忆向量 由所有检索到的嵌入拼接而成:
3.2 上下文感知门控 (Context-Aware Gating)
检索到的嵌入 是静态的,缺乏上下文适应性,且可能包含哈希冲突引入的噪声。为了解决这一问题,Engram 借鉴注意力机制,利用当前的隐藏状态 (包含全局上下文)作为动态 Query,而检索到的内存 作为 Key 和 Value。
投影计算如下:
门控标量 计算为:
门控输出 。这种设计确保了语义一致性:如果检索到的内存 与当前上下文 冲突, 将趋向于 0,从而抑制噪声。
为了增加非线性并扩展感受野,输出还会经过一个轻量级的深度卷积(Depthwise Causal Convolution):
最后, 通过残差连接加回主干网络:。
3.3 与多分支架构的集成
在 DeepSeek-V3 等采用的多分支(Multi-Head Latent Attention / MoE)架构中,Engram 采用了参数共享策略以平衡效率。所有分支共享同一个稀疏嵌入表和 Value 投影矩阵 ,但使用 个不同的 Key 投影矩阵 来实现分支特定的门控行为。这使得线性投影可以融合为单个密集的 FP8 矩阵乘法,最大化 GPU 计算利用率。
4. 系统实现:解耦计算与存储
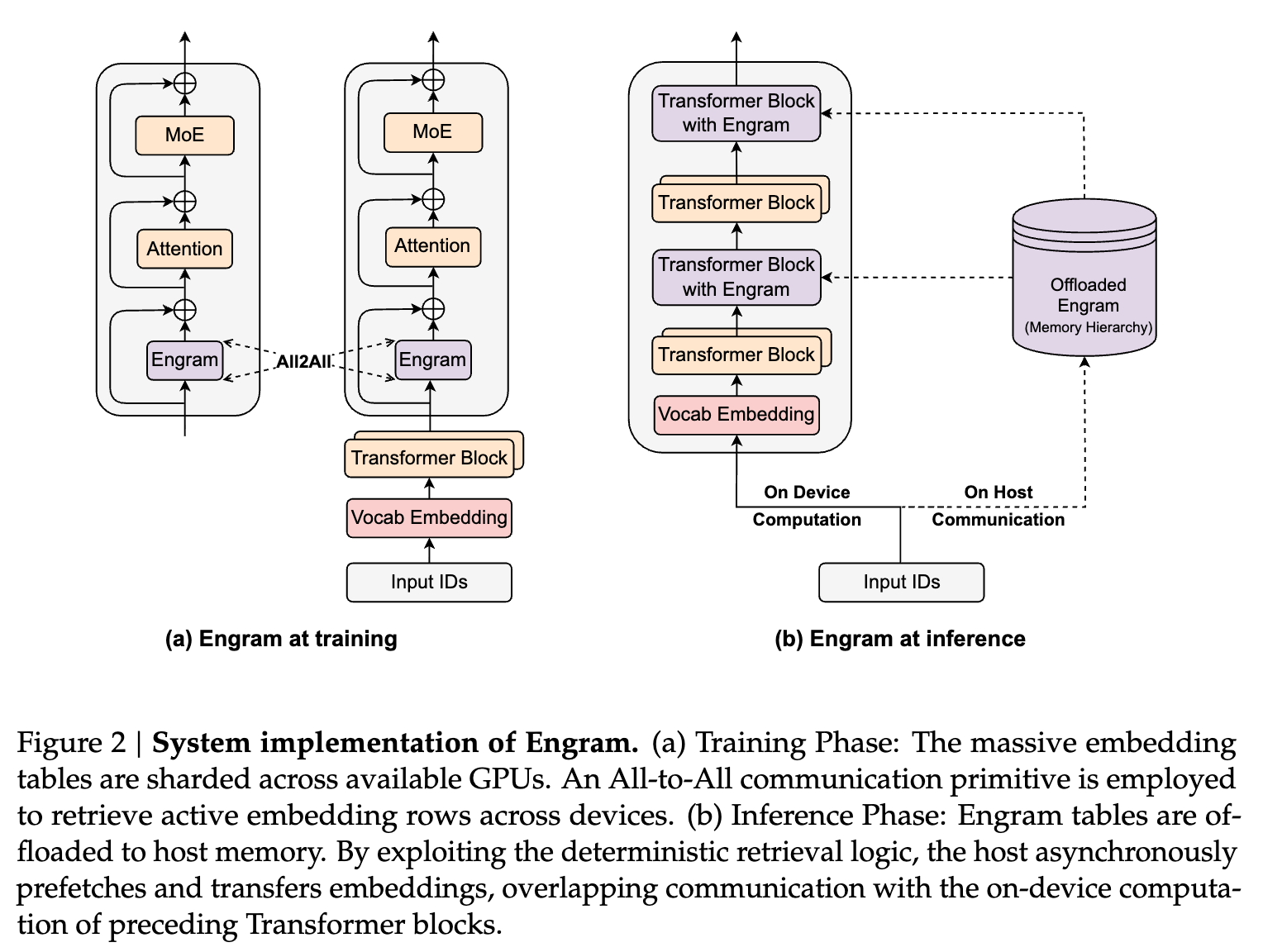
Engram 的一个关键系统优势在于其检索逻辑的 确定性(Determinism)。与 MoE 依赖运行时隐藏状态进行动态路由不同,Engram 的检索索引仅取决于输入 Token 序列。
4.1 预取与重叠 (Prefetch and Overlap)
在推理阶段,由于内存索引在执行前层计算之前即可知晓,系统可以从主机内存(Host Memory, DRAM)异步预取嵌入到 GPU 显存。
-
存储层级: 利用 Zipfian 分布特性,将高频 -gram 缓存在 GPU HBM 或 Host DRAM 中,长尾低频模式存储在 NVMe SSD 或大容量 DRAM 中。 -
通信掩盖: 将 Engram 模块放置在主干网络的较深层(如第 2 层或第 15 层),利用前序 Transformer 层(Attention/MoE)的计算时间作为缓冲,完全掩盖 PCIe 数据传输延迟。
实验显示,即使将 100B 参数的嵌入表完全卸载到 CPU 内存,推理吞吐量的损耗也可以忽略不计(< 3%),这证明了 Engram 可以有效突破 GPU 显存墙。
5. 实验结果
为了验证 Engram 的有效性,研究团队训练了四个模型,均在 262B tokens 上进行预训练:
-
Dense-4B:基线密集模型。 -
MoE-27B:基于 DeepSeekMoE 架构,总参数 26.7B,激活参数 3.8B。 -
Engram-27B:从 MoE-27B 重新分配参数而来。路由专家从 72 个减少到 55 个,节省的参数分配给 5.7B 的 Engram 内存。总参数量与激活参数量与 MoE-27B 严格一致。 -
Engram-40B:进一步扩展 Engram 内存至 18.5B,保持激活参数不变。
5.1 预训练性能

实验结果表明,Engram-27B 在绝大多数基准测试中均优于同参数、同 FLOPs 的 MoE-27B:
-
知识密集型任务: MMLU (+3.0), CMMLU (+4.0)。这一点符合预期,因为增加了静态记忆容量。 -
通用推理与代码/数学: 令研究者惊讶的是,增益在非知识类任务中甚至更为显著。 -
BBH: +5.0 -
ARC-Challenge: +3.7 -
HumanEval (Code): +3.0 -
MATH: +2.4
-
-
解释: 这种全面提升表明,Engram 不仅仅是一个知识库,它通过卸载简单的模式匹配任务,让主干网络(Backbone)能够更专注于复杂的推理逻辑。
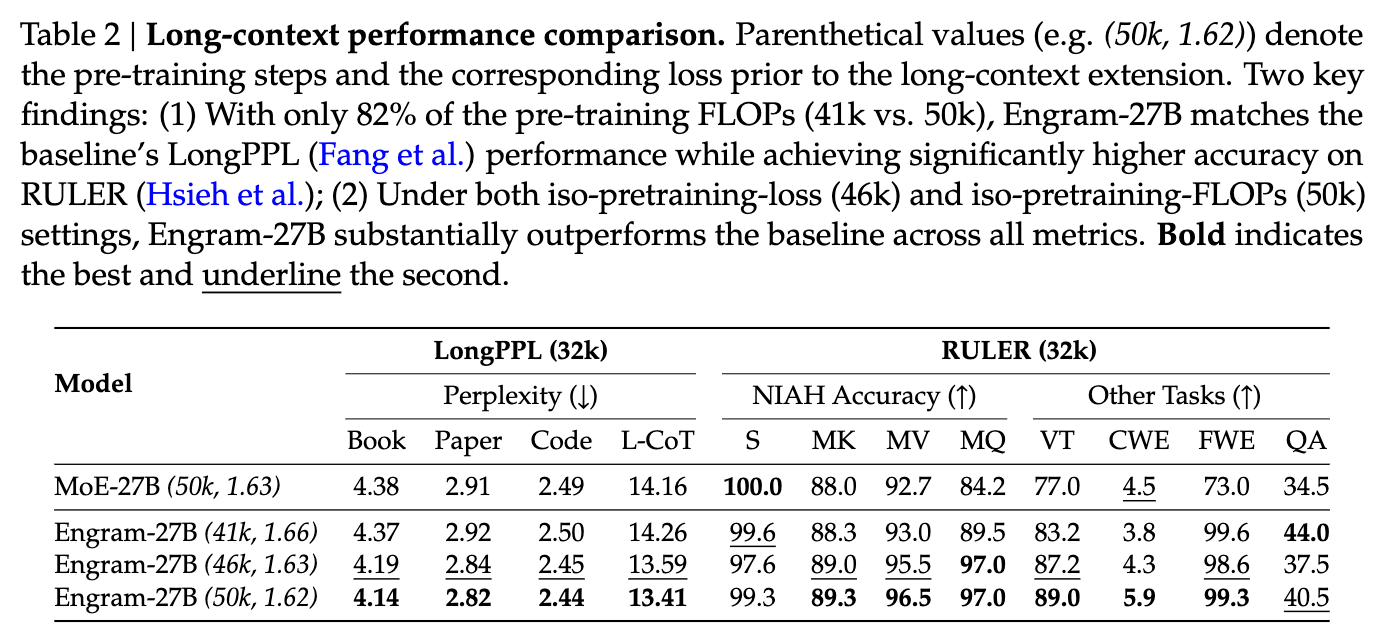
5.2 长上下文性能 (Long Context)
Engram 架构在长上下文任务中表现出显著的结构优势。通过将局部依赖(Local Dependencies)的建模委托给静态查找,Engram 释放了注意力机制的容量,使其能专注于全局上下文。
在 32k 长度的上下文扩展训练后:
-
检索任务 (RULER): Engram-27B 在 "Multi-Query NIAH"(大海捞针)任务上达到 97.0 分,而 MoE-27B 仅为 84.2 分。 -
困惑度 (LongPPL): 在同等训练 Loss 下,Engram 保持了更低的困惑度。 -
变量追踪 (Variable Tracking): 89.0 vs 77.0,证明了更强的长程推理能力。
6. Engram 如何工作?
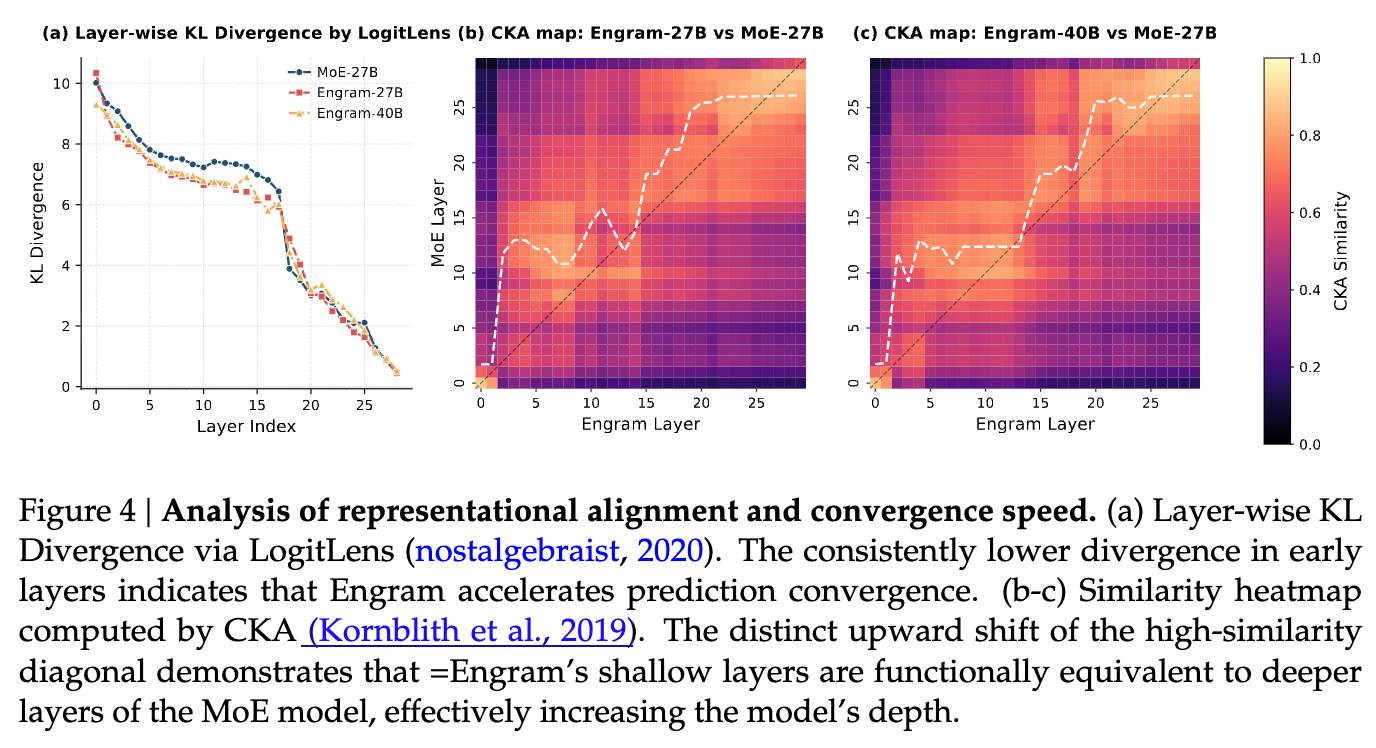
为了探究 Engram 性能提升的深层原因,论文使用了 LogitLens 和 CKA(Centered Kernel Alignment)进行分析。
6.1 加速预测收敛与增加有效深度
-
LogitLens 分析: 计算各层隐藏状态与最终输出分布的 KL 散度。结果显示,Engram 模型在浅层(Early Layers)的 KL 散度显著低于 MoE 基线。这表明 Engram 帮助模型更快地完成了特征组合,使潜在表示更早地达到了“预测就绪(Prediction-Ready)”状态。 -
CKA 相似度分析: 对比 Engram 模型与 MoE 基线模型的层间相似度。热力图显示出明显的非对角线偏移(Off-diagonal shift)。例如,Engram-27B 第 5 层的表示与 MoE 基线第 12 层的表示最为相似。 -
结论: Engram 的浅层在功能上等价于更深层的 MoE 网络。通过显式查找,Engram 有效地“加深”了网络,节省了用于静态重构的层数。
-
6.2 结构消融实验
在 3B 参数规模下的消融实验揭示了关键组件的重要性:
-
插入位置: 早期插入(如第 2 层)效果最好。这证实了 Engram 的作用是卸载底层的局部模式重构。然而,过早(第 0 层)插入效果不佳,因为缺乏足够的上下文进行有效门控。分层插入(Layer 2 + Layer 6)平衡了局部卸载和利用深层语义进行门控的需求。 -
关键组件: 移除 多分支融合(Multi-branch integration)、上下文门控(Context-aware gating) 或 分词器压缩 都会导致显著的性能下降。 -
敏感性分析: 在推理时强制屏蔽 Engram 输出。结果显示,事实性知识任务(如 TriviaQA)性能崩塌(保留率仅 29%),而阅读理解任务(如 C3)保留率高达 93%。这证实了 Engram 确实主要作为参数化知识的存储库,而主干网络负责上下文推理。
6.3 门控可视化案例

可视化显示,门控值 在完成局部、静态模式时会被强烈激活(红色)。
-
英语案例: "Alexander the Great", "Princess of Wales", "By the way"。 -
中文案例: "四大 发明", "张 仲景"。
这直观地证明了 Engram 成功识别并接管了这些定型化的语言依赖,避免了主干网络死记硬背这些静态关联。
7. 结论与展望
DeepSeek 的这项研究提出了 Engram,将条件记忆确立为大模型稀疏性的一个独立且至关重要的维度。
核心贡献总结:
-
架构创新: 提出了一种现代化、可扩展的查找模块,支持 复杂度的静态模式检索。 -
理论发现: 发现了 MoE 计算与 Engram 记忆之间的 U 型分配定律,证明了混合分配优于纯神经计算。 -
性能突破: 在不增加计算量的前提下,全面提升了模型的推理、编码、数学及长上下文能力。 -
系统效率: 利用确定性寻址实现计算与存储的解耦,为未来打破显存限制、迈向超大规模参数模型提供了基础设施层面的可行路径。
该工作不仅挑战了“所有知识都应存储在神经网络权重中”的传统观念,也为下一代稀疏模型的设计指明了方向:将局部依赖和静态知识卸载给廉价的查找操作,让昂贵的神经计算专注于复杂的全局推理。
附录:技术细节补充
A. 为什么是后缀 -grams?
论文选择后缀 -grams 是基于其能够捕捉局部上下文的特性。虽然 -gram 模型历史悠久,但将其作为一种显式的、可学习的组件集成到深层神经网络中,并配合哈希与门控机制,是其焕发新生的关键。与近期其他类似工作(如 SCONE 或 OverEncoding)相比,Engram 不仅关注推理端,更将其作为一等公民参与预训练,并严格在等参数条件下验证了其有效性。
B. 词表投影的重要性
如果不进行分词器压缩,常见的子词分词器会将 Apple 和 apple 视为完全不同的 ID,导致 -gram 空间极度稀疏且冗余。通过满射函数 将其映射到规范空间,Engram 显著提高了哈希表的命中率和参数利用效率。
C. 系统集成的微操
为了在训练时处理大规模嵌入表,Engram 使用了 All-to-All 通信原语在 GPU 间收集活跃行。而在推理时,由于 ID 的确定性,可以完全重叠 PCIe 传输与计算。这种设计体现了算法-系统协同设计(Algorithm-System Co-design)的理念。
更多细节请阅读原文。
往期文章:


