
-
论文标题:QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management -
论文链接:https://arxiv.org/pdf/2512.12967v1
现在是 2025 年底,大家其实都已经发现,把 Context Window 拉长(Pre-training 阶段的 RoPE Trick 等)已经不是护城河了,真正的护城河在于:模型能不能在长窗口里进行复杂的逻辑推理(Reasoning),而不是简单的检索(Retrieval)。
Qwen 最近发布的 QwenLong-L1.5 技术报告实际上解决了三个在这个阶段最痛的痛点:没数据、练不稳、无限长。
TL;DR
阿里巴巴通义实验室发布的 QwenLong-L1.5 提出了一套针对长上下文推理(Long-Context Reasoning)的系统性后训练(Post-Training)方案。该方案旨在解决当前长文本模型在后训练阶段缺乏高质量数据、RL 训练不稳定以及物理上下文窗口限制等问题。
核心贡献包括:
-
一套能够合成需要多跳推理和全局信息聚合的高质量合成数据流水线; -
改进的强化学习策略,包括任务平衡采样(Task-balanced sampling)、任务特定优势估计(Task-specific advantage estimation)以及自适应熵控制策略优化(AEPO),有效解决了长文本 RL 的训练不稳定性; -
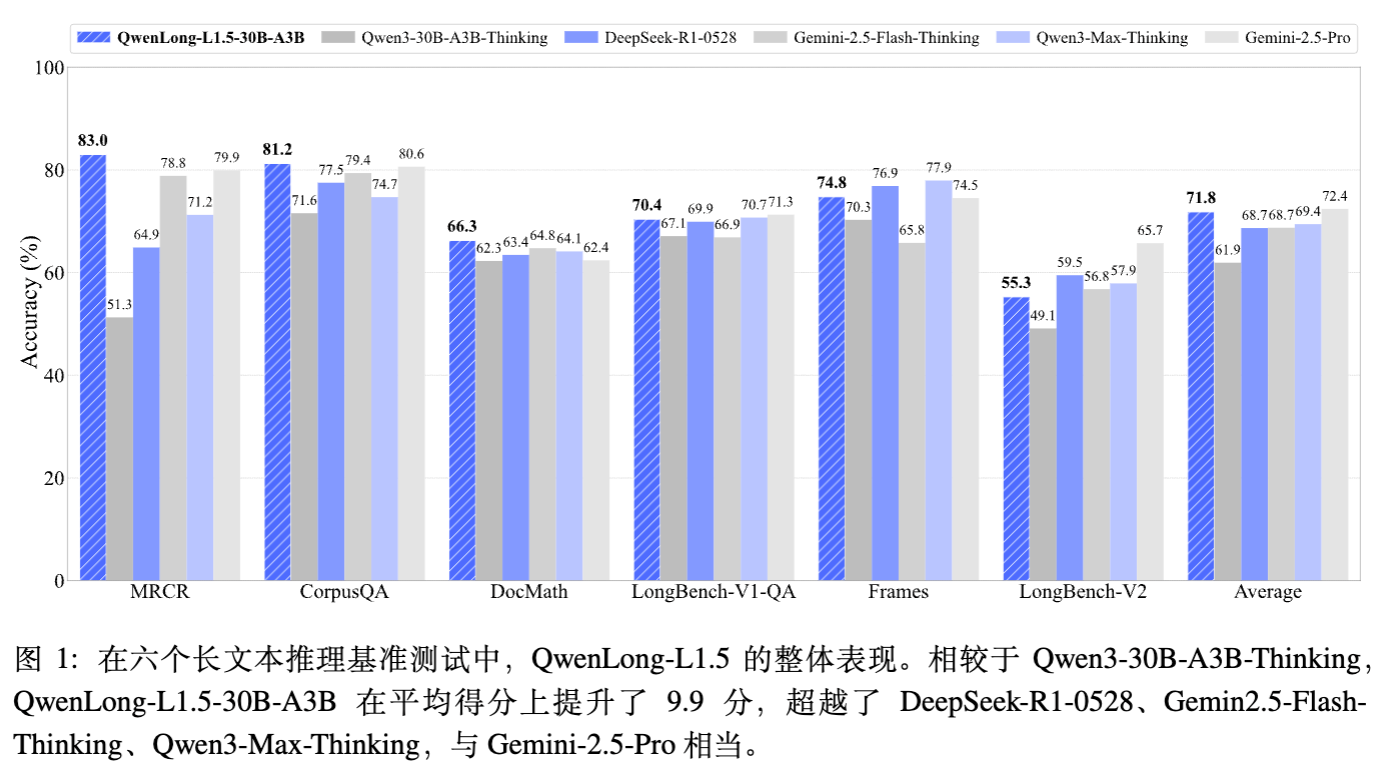
一种记忆增强架构,通过多阶段融合训练,使模型能够处理超过 4M token 的超长任务。实验表明,QwenLong-L1.5 在多个长文本基准上超越了 Qwen3-30B-A3B-Thinking 基线,在 1M~4M token 任务上表现出显著优势,综合性能可与 GPT-5 和 Gemini-2.5-Pro 比肩。
1. 引言
随着大语言模型(LLMs)的发展,长上下文处理能力已成为关键特性,推动了单次推理(Single-pass reasoning)和多轮自主智能体系统的进步。尽管目前在预训练和中间训练(Mid-training)阶段扩展上下文窗口的研究较多,但在后训练(Post-training)阶段,仍缺乏成熟的端到端系统来激发模型的长上下文推理能力。
现有的挑战主要集中在三个方面:
-
数据稀缺:缺乏能够合成具有挑战性、高价值长上下文推理数据的可扩展流水线。现有数据往往局限于简单的“大海捞针”(Needle-in-a-Haystack)或单跳检索,难以训练模型进行跨文档的复杂推理。 -
训练不稳定性:基于强化学习(RL)的方法在长上下文、多任务训练中容易出现梯度不稳定、奖励偏差大等问题。 -
架构限制:物理上下文窗口即使扩展也无法满足无限增长的序列需求(如 >1M token),缺乏有效的流式处理或记忆管理机制。
该模型基于 Qwen3-30B-A3B-Thinking 构建,通过引入记忆机制和系统的后训练配方,显著提升了长文本推理性能。
2. 长上下文数据合成流水线
高质量的训练数据是提升模型推理能力的基石。QwenLong-L1.5 团队观察到,对于复杂的长上下文任务,人工标注不仅成本高昂,而且难以保证在超过 32k token 的上下文中进行详尽的答案验证。因此,论文提出了一套全自动的大规模数据合成流水线。
该流水线的核心设计原则是:解构文档中的原子事实及其关系,并通过程序化方式组合出可验证的复杂推理问题。 这种方法超越了简单的检索任务,侧重于需要多跳(Multi-hop)锚定和全局证据聚合的挑战。
2.1 语料库收集与预处理
数据合成的基础是多元异构的长文档语料库。收集的来源主要包括五类:
-
代码仓库:高质量开源代码(主要是 Python)。 -
学术文献:STEM、法律、社会科学论文及 arXiv 文章。 -
专业文档:财报、产品手册、医疗教科书、政府出版物。 -
通用知识与文学:小说、侦探故事、维基百科页面。 -
对话数据:模拟的多轮长对话。
经过严格的基于规则和 LLM-as-a-judge 的过滤,最终保留了约 82,175 个高质量文档,总计约 92 亿 token。
2.2 问答对(QA)合成策略
为了构建高学习价值的任务,论文设计了三种针对不同信息结构和关系类型的合成方法:
2.2.1 深度多跳推理 QA
此方法利用知识图谱(KG)挖掘文档内分散信息的长程依赖。
-
KG 构建:从文档中提取三元组,通过实体和关系聚类构建跨文档的复杂 KG。 -
推理路径采样:以目标实体为中心采样相关子图,使用随机游走或 BFS 生成多跳路径。关键在于路径节点必须稀疏地分布在多个文档中,强制模型进行跨文档信息综合。 -
信息扰动:对实体进行模糊化处理(例如将具体的年份改为“20世纪后期的某一年”),增加路径复杂性。 -
问题生成:基于提取的路径,合成涵盖多事实推理、时序推理、因果分析和假设性场景的 QA 对。
2.2.2 语料库级数值推理 QA
针对需要跨多个文档进行数值计算的场景,引入了结构化表格数据引擎:
-
Schema 提取:解析非结构化文档中的统计表,形式化数据结构。 -
数据表聚合:将分散的内容转换为统一的跨文档语料库表。 -
SQL 执行:通过 LLM 将自然语言查询转换为 SQL 语句,在聚合表上执行以获得 Ground Truth。这使得能够模拟复杂的统计聚合和数值计算(如 Sum, Average 等)。
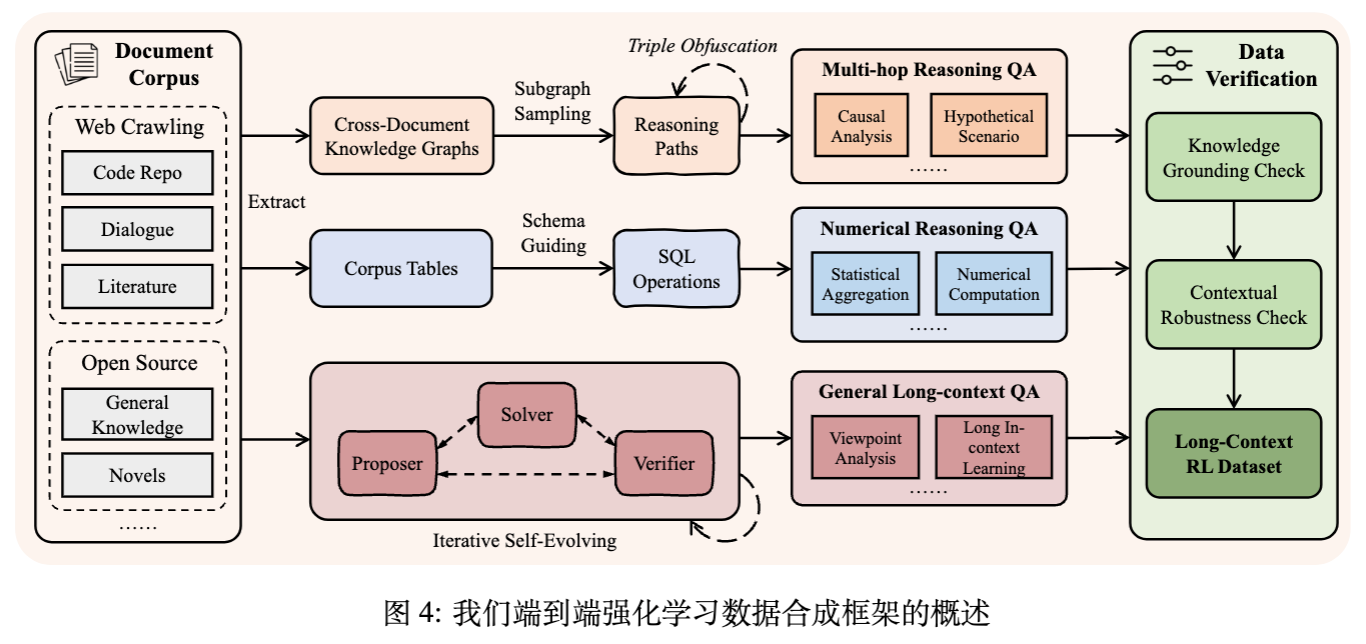
2.2.3 通用长上下文推理
对于观点分析(Viewpoint Analysis)和长上下文学习(In-context Learning)等任务,采用多智能体自进化(Multi-agent Self-evolve, MASE)框架。
-
Proposer:生成初始种子问题,并利用历史 QA 对作为少样本示例,推动生成更难、更多样化的问题。 -
Solver:尝试基于文档回答问题。 -
Verifier:验证 Solver 的答案与 Proposer 的参考答案是否语义一致。
2.3 数据验证
为确保数据质量,所有样本需通过两项关键检查:
-
知识锚定检查(Knowledge Grounding Check):移除源文档,测试模型是否仍能回答。若能回答(说明依赖模型内部参数知识而非上下文),则过滤该样本。 -
上下文鲁棒性检查(Contextual Robustness Check):在上下文中插入无关文档干扰,验证答案是否准确。若准确率下降至零,则说明问题脆弱,予以丢弃。
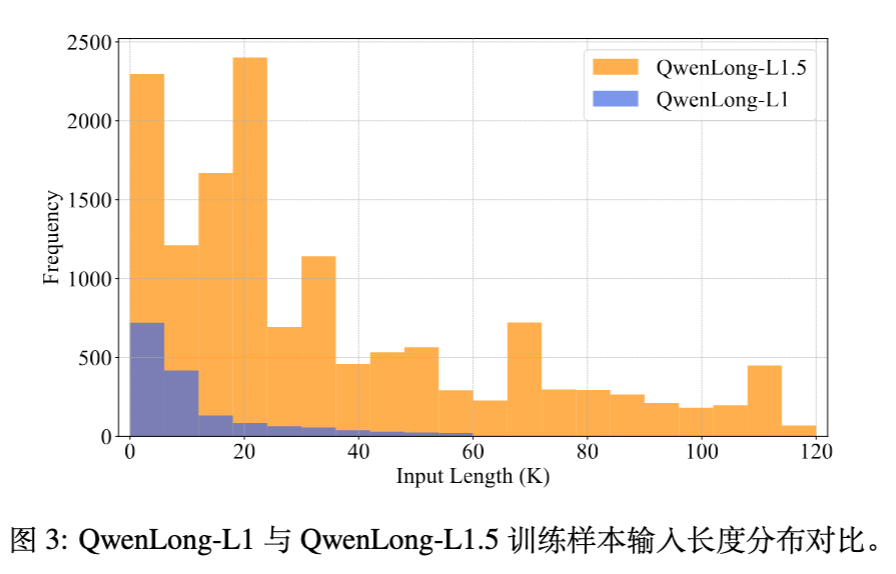
最终构建了包含 14.1k 高质量样本的数据集,相比 QwenLong-L1,不仅规模扩大,而且在 64K token 以上长度的数据量显著增加。
3. 长上下文强化学习方法
在获得高质量数据后,QwenLong-L1.5 将长上下文推理建模为强化学习(RL)问题。给定文档集 和问题 ,目标是优化策略 以最大化奖励 。
3.1 基础框架:GRPO
由于长上下文输入的注意力机制具有二次方复杂度,传统的 PPO 算法(依赖价值网络进行优势估计)计算成本过高。因此,论文采用 GRPO (Group Relative Policy Optimization) 。
GRPO 对于每个输入 采样一组 个候选回答 ,并通过组内奖励的 Z-score 标准化来估计优势(Advantage),无需独立的价值网络。目标函数如下:
其中优势 计算为:
论文中采用了 on-policy 设置(单次梯度更新),,且 ,简化了目标函数。
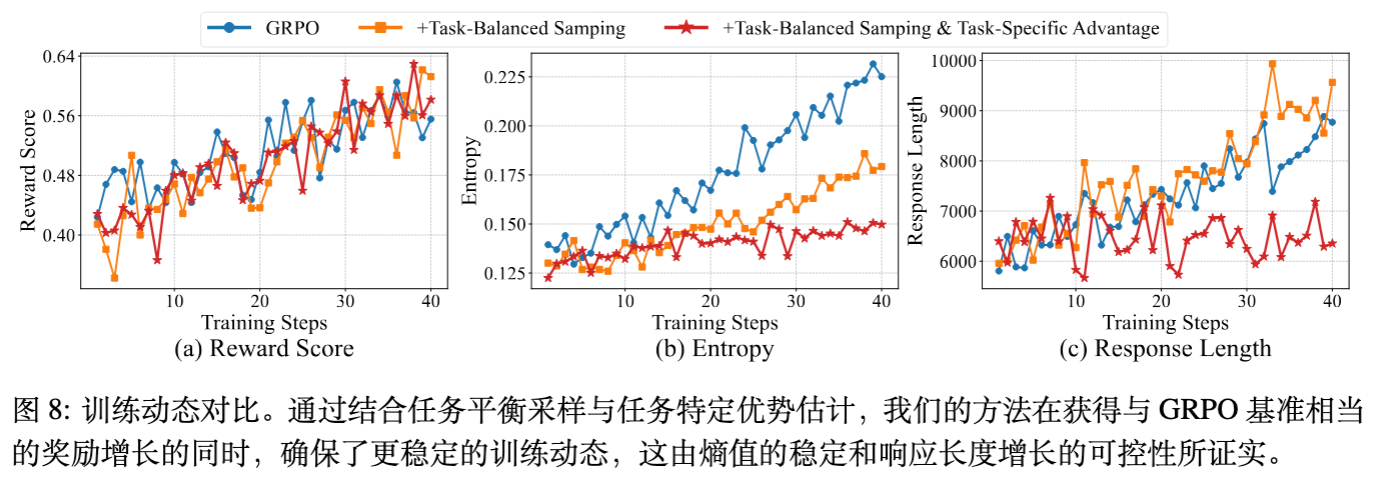
3.2 任务平衡与特定优势估计
长上下文数据具有多聚类分布特征(如代码、数学、多文档推理等),且不同任务间的奖励分布差异巨大。传统的随机采样会导致 batch 内分布不平衡,引发训练不稳定(表现为熵的剧烈波动)。
改进 1:任务平衡采样
-
训练前:根据 base 模型的 pass@k 分数对数据进行分层,并在各层中均匀采样。 -
训练中:在构建 batch 时,强制从五种指定任务类型(多选、文档多跳、一般阅读理解、对话记忆、语料库数值计算)中抽取相等数量的样本。
改进 2:任务特定优势估计
GRPO 的组级(Group-level)归一化会引入偏差,而 Batch-level 归一化在任务混合时会引入噪声。论文提出任务感知(Task-aware)的优势估计。对于策略模型的第 个响应,使用当前 batch 中属于同一任务类型 的所有样本的奖励标准差进行归一化:
这种方法隔离了密集奖励任务(如 NIAH,奖励 0-1)和稀疏奖励任务,提供了更准确的估计。
3.3 负梯度裁剪
长上下文任务的一个显著特点是:正确和错误推理路径之间存在高度相似性。模型必须先定位相关信息再推理。如果定位正确但推理错误,生成的文本与正确答案的重叠度(ROUGE-L)可能依然很高。这加剧了 RL 中的信用分配(Credit Assignment)问题。
论文发现,高熵(High-entropy)token 往往对应较大的梯度范数,且可能反映了推理过程中的探索行为。为了防止对探索行为的过度惩罚,论文提出序列级负梯度裁剪。
定义指示函数 :当优势 且序列级熵 超过阈值 时,将梯度置零(),否则为 1。这意味着:如果一个负样本是模型高度不确定(高熵)时生成的,我们选择不惩罚它,以保护探索能力。
3.4 自适应熵控制策略优化 (AEPO)
基于上述发现,论文提出了 AEPO (Adaptive Entropy-Controlled Policy Optimization) 算法。该算法动态地根据策略模型的熵来控制负样本的梯度更新。
定义 batch 级熵 。设定目标熵范围 。
-
如果当前熵 :屏蔽所有负优势样本(Negative Advantages)。此时模型仅利用正样本更新,类似于加权在线拒绝采样微调(Rejection Sampling Fine-tuning),有助于降低熵。 -
如果当前熵 :重新引入负梯度,防止熵坍塌(Entropy Collapse)。
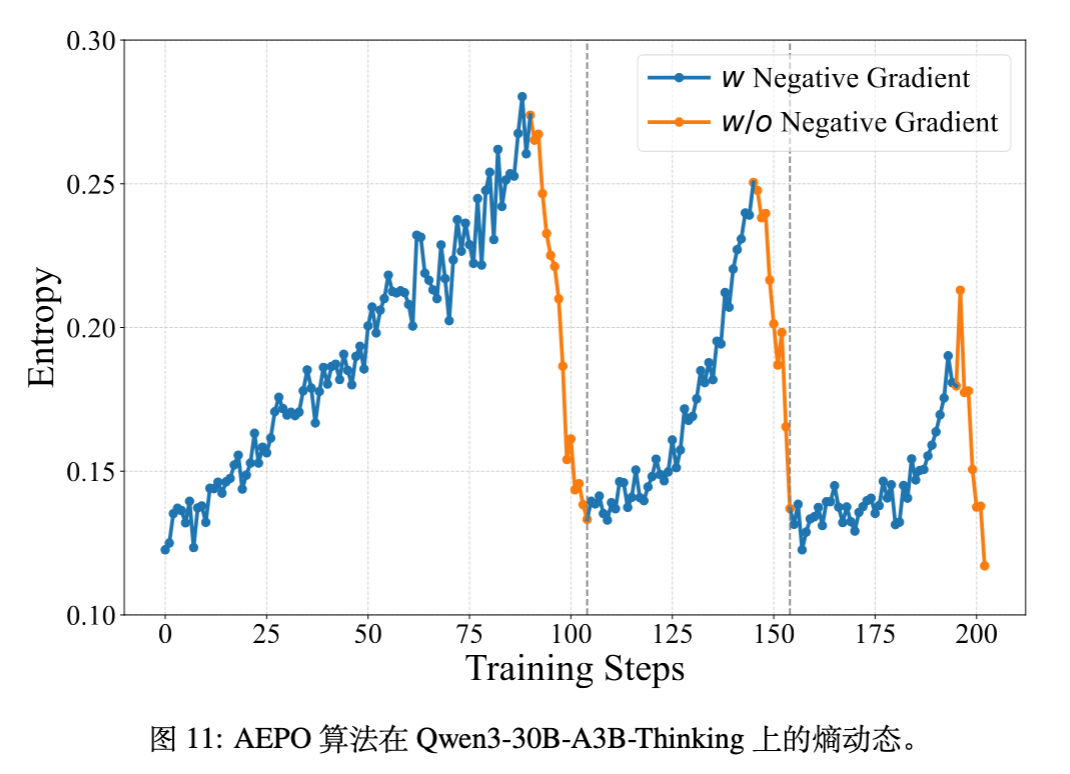
实验证明,AEPO 在保持探索(保留负梯度)和利用(去除负梯度)之间取得了最佳平衡,使模型能够稳定地进行多阶段训练。
4. 渐进式训练范式
为了避免从短文本直接跳跃到长文本推理带来的训练崩溃,QwenLong-L1.5 采用了分阶段长度扩展策略。
-
阶段 1:输入 20K,输出 12K。 -
阶段 2:输入 60K,输出 20K。 -
阶段 3:输入 120K,输出 50K。
在阶段转换时,采用“回顾性采样”(Retrospective sampling),即在进入下一阶段前,对训练数据进行基于难度和长度的过滤。
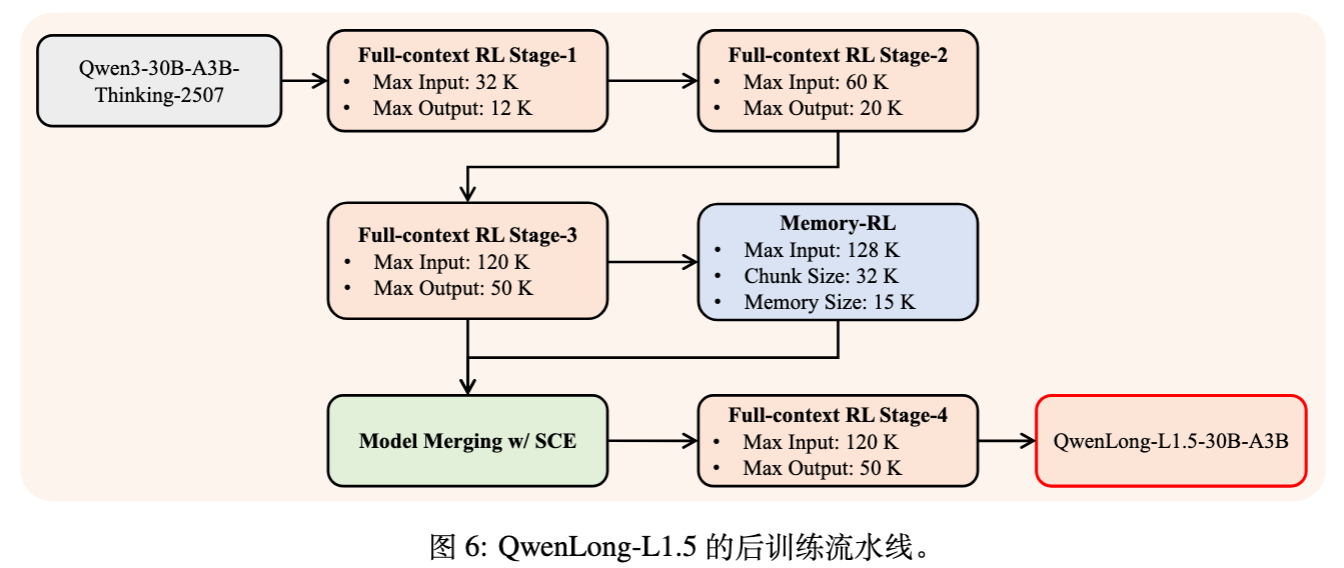
此外,为了集成记忆管理能力,论文采取了专家训练 + 模型融合的策略:
-
在完成阶段 3 的全上下文(Full-context)训练后,基于该检查点继续进行 Memory-RL 训练,获得记忆专家模型。 -
使用 SCE (Supervised Coefficient Estimation) 算法将记忆专家与阶段 3 模型融合。 -
在融合后的模型上进行阶段 4 的全上下文训练。
这种流程(如图 6 所示)确保了模型既保留了单次长文推理能力,又获得了操作记忆代理的能力。
5. 超长上下文的记忆增强架构
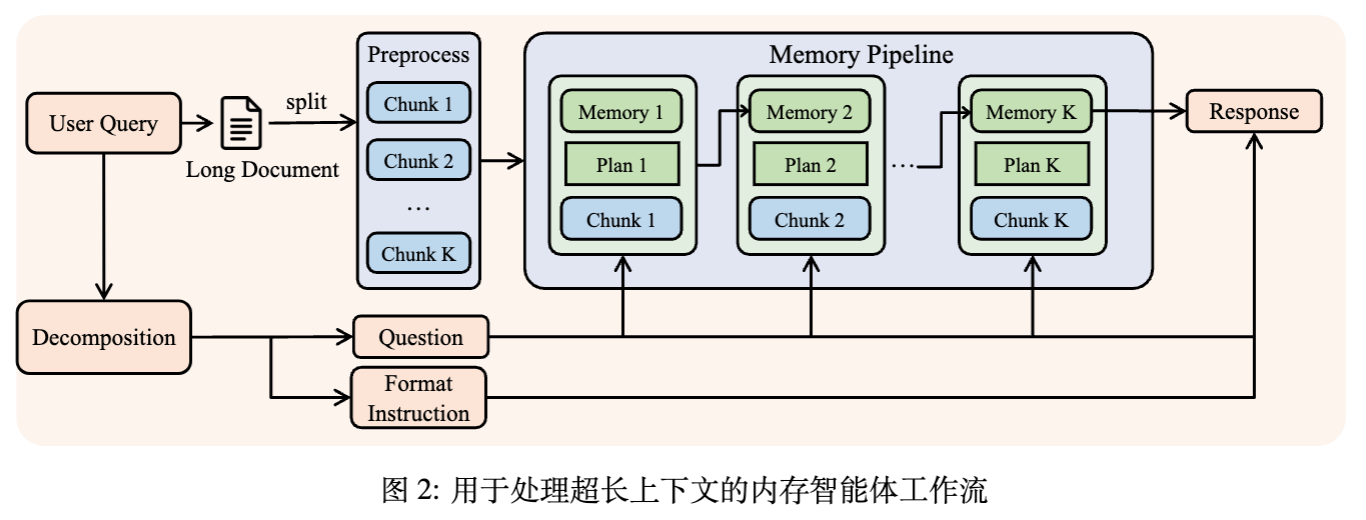
对于超过物理上下文窗口(如 > 128K 或 1M token)的任务,全注意力机制在计算上不可行。QwenLong-L1.5 采用了 Memory Agent 范式,将阅读理解转化为序列决策过程。
5.1 序列记忆处理
给定长上下文和查询,处理流程如下:
-
分解:将用户查询分为核心问题 和格式指令 。 指导推理, 用于最终生成。 -
分块:将文档切分为 。 -
迭代更新:在步骤 ,策略 观察当前块 和历史状态,更新记忆 。
规划机制(Planning Mechanism):除了更新记忆,模型还生成一个导航计划 ,用于指导下一个块 的注意力和信息提取。状态转移公式为:
这种循环机制将全局上下文“折叠”为紧凑的表示,同时主动规划推理路径。
5.2 记忆优化
处理完最后一个块 后,模型整合累积的记忆 和原始格式指令生成最终答案:
通过特定的 Memory-RL 阶段训练,模型学会了如何压缩关键信息并丢弃无关信息。
6. 实验结果分析
实验基于 Qwen3-30B-A3B-Thinking 模型,主要对比了 GPT-5, Gemini-2.5-Pro, DeepSeek-R1-0528 等模型。
6.1 整体长上下文性能
在 LongBench-V2, Frames, MRCR, CorpusQA 等基准上,QwenLong-L1.5-30B-A3B 取得了 71.82 的平均分,显著优于基线(61.92),并超越了 DeepSeek-R1-0528 (68.67),接近 Gemini-2.5-Pro (72.40)。
-
多跳推理:在需要连接不连续信息的任务(如 LongBench-V2, Frames)上表现优异。 -
信息聚合:在 CorpusQA(需跨大量文档聚合信息)上得分为 81.25,与 GPT-5 (81.56) 相当。
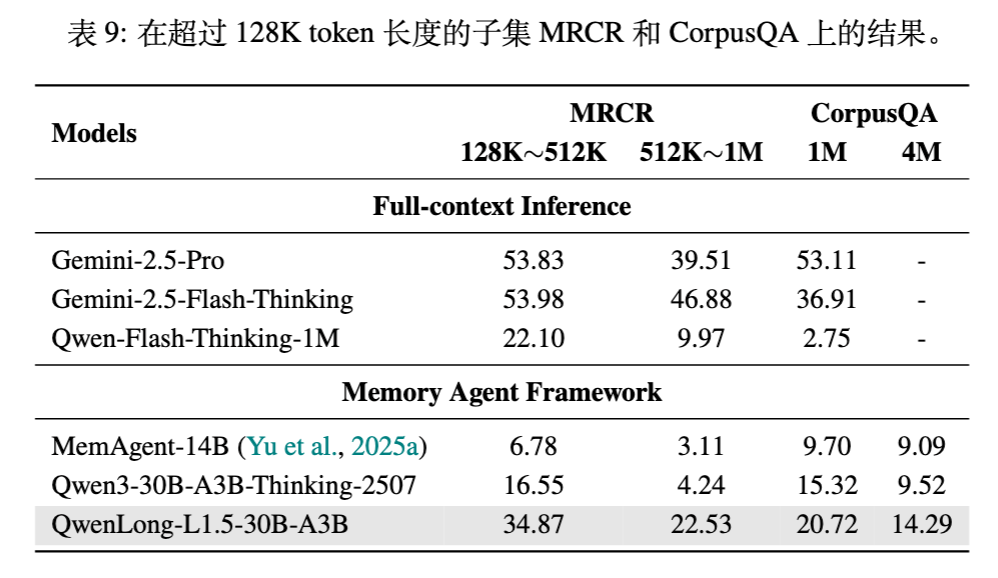
6.2 超长上下文(1M~4M Token)
在 Memory Agent 框架下,QwenLong-L1.5 展现了极强的可扩展性。
-
MRCR (128K~512K) :得分 34.87,远超基线的 16.55。 -
CorpusQA (4M) :得分为 14.29,证明了框架处理 LLM 操作极限之外任务的能力。在此设置下,QwenLong-L1.5 的表现优于其他基于 Agent 的方法。
6.3 泛化能力
长上下文训练带来的收益不仅限于长文本任务。在通用领域:
-
数学与推理:AIME25 提升了 3.65 分。 -
Agentic Memory:在 BFCL-V4 的 Memory-KV 子任务上提升 5.80 分。 -
对话记忆:在 LongMemEval 上提升了 15.60 分。
这意味着模型在长序列中维持一致性和推理的能力被内化为了通用能力。
6.4 消融实验
-
RL 策略:单独使用任务平衡采样提升不大,但结合任务特定优势估计后,模型性能显著提升且熵更稳定。 -
AEPO:相比 GRPO 基线,AEPO 在 Qwen3-4B-Thinking 上带来了 3.29 分的平均提升,且在训练后期有效防止了退化。 -
负梯度裁剪:裁剪高熵负样本比裁剪低熵负样本更有效,证实了保护高熵(探索性)行为的重要性。
7. 局限性与未来方向
尽管 QwenLong-L1.5 取得了进展,但仍存在改进空间:
-
数据覆盖与合成:目前的合成数据主要是文本,未来计划扩展到多模态数据,并覆盖“长输入-长输出”(如长篇报告生成)的任务。 -
数据飞轮:目前的合成依赖外部模型 API。未来计划建立闭环数据飞轮,利用训练好的长文本模型自身生成新的 QA 对和思维轨迹(Thinking Trajectories),实现自我提升。 -
RL 算法粒度:目前的优势估计是基于整个响应的。未来旨在开发 Token 级别的信用分配机制,区分思维轨迹中每个 token 的贡献。 -
奖励模型:当前依赖基于规则和 LLM-as-a-judge 的混合奖励。未来将探索基于细粒度评分标准的 Reward Model,以提供更丰富、更符合人类偏好的信号。
更多细节请阅读原论文。
往期文章:


