
-
论文标题:Hybrid Reinforcement: When Reward Is Sparse, It’s Better to Be Dense -
论文链接:https://arxiv.org/pdf/2510.07242
TL;DR
多家权威媒体报道,Meta 首席 AI 科学家、负责「基础 AI 研究」(FAIR)的 Yann LeCun 预计将很快离职。在这一行业焦点时刻,Meta FAIR 团队仍持续产出前沿研究成果,今天就为大家分享其最新论文《Hybrid Reinforcement: When Reward Is Sparse, It’s Better to Be Dense》。这篇论文介绍了一个名为 HERO (Hybrid Ensemble Reward Optimization) 的强化学习框架,旨在解决大语言模型(LLM)在推理任务中奖励信号稀疏且脆弱的问题。当前方法主要依赖两类监督信号:一类是来自确定性验证器(Verifier)的稀疏、二元的 0-1 奖励,它虽然可靠但缺乏对部分正确或格式不同答案的细粒度区分;另一类是来自奖励模型(Reward Model, RM)的密集、连续的评分,它能提供更丰富的反馈但可能存在噪声和与事实不一致的问题。HERO 框架通过一种结构化的方式将这两种信号结合起来,其核心机制包括:
-
分层归一化 (Stratified Normalization) ,该机制利用验证器的 0-1 信号将模型的响应分为“正确”和“错误”两个组,然后仅在每个组内部对奖励模型的分数进行归一化,从而保证了验证器的权威性,同时利用奖励模型在组内进行更精细的区分; -
方差感知加权 (Variance-aware Weighting) ,该机制会动态地增加那些模型表现出较大不确定性(即奖励模型打分方差较大)的困难样本在训练中的权重,从而提高训练效率。论文通过在多个数学推理基准上的实验证明,HERO 在各种设置下均优于仅使用验证器或仅使用奖励模型的基线方法,显示出该混合奖励设计在保持验证器稳定性的同时,有效利用了奖励模型的细粒度信息来提升模型的推理能力。
1. 研究背景与动机
大语言模型在复杂推理任务(如数学解题、代码生成)上的后训练(Post-training)阶段,强化学习扮演了重要的角色。这个过程的核心在于如何为模型的不同输出提供准确的监督信号,即奖励(Reward)。目前,主流的奖励信号来源可以分为两大类,每一类都有其固有的优势和缺陷。
1.1 基于规则的验证器
第一类是基于规则的验证器。这是一种确定性的检查程序,例如通过精确的数值匹配、字符串匹配或符号等价性检查来判断模型输出的答案是否正确。如果答案正确,模型获得奖励 1;反之,则获得奖励 0。这种 0-1 的二元奖励信号是稀疏(Sparse)但明确(Unambiguous)的。
-
优点:可靠性高。验证器基于严格的规则,因此很少出现误判(False Positives),能够为模型提供一个稳定的“事实锚点”。 -
缺点:脆弱且低效。 -
信息损失:对于复杂的推理任务,答案可能有多种表达形式,或者存在部分正确的情况。严格的验证器可能会将这些语义上正确但格式不符的答案(例如,列表 [1, 2]与集合{1, 2})标记为错误(False Negatives),导致有价值的监督信息丢失。 -
梯度稀疏:当模型对一个问题生成的所有候选答案都被验证器判定为错误(全部奖励为 0)或全部正确(全部奖励为 1)时,基于相对优势的强化学习算法(如 GRPO)无法产生有效的策略梯度。这会导致模型在这些样本上的学习停滞,尤其是在困难问题上,模型初期很难生成完全正确的答案,从而陷入“零奖励困境”。 -
优化偏差:由于模型更容易在简单、有明确验证规则的问题上获得正反馈,训练过程可能会偏向于优化这些“低垂的果实”,而忽视了那些更具挑战性、信息量更丰富的难题。
-
1.2 奖励模型(Reward Model)
第二类是奖励模型。通常,这是一个在人类偏好数据上训练出来的另一个语言模型,它能为模型的任意输出给出一个连续的分数,以评估其质量。这种评分信号是密集(Dense)的。
-
优点:信息丰富。奖励模型可以捕捉到答案质量的细微差别,例如推理步骤的清晰度、逻辑的连贯性,或是答案与标准答案的接近程度。这种分级的反馈有助于模型从不完美的尝试中学习,为策略优化提供了更平滑、更丰富的梯度信号。 -
缺点:不可靠且不稳定。 -
信号漂移(Reward Drift):奖励模型本身可能存在事实错误或偏见,有时会给错误的答案打出高分,或给正确的答案打出低分。过度依赖这种可能有噪声的信号,会导致模型的训练偏离正确的方向,甚至学会“钻空子”来欺骗奖励模型,即所谓的“奖励骇客”(Reward Hacking)。 -
训练不稳定:如果直接将验证器的 0-1 信号与奖励模型的连续分数简单地线性相加,会产生一个既不精确又充满噪声的混合奖励。这种信号可能会破坏验证器所提供的正确性语义,导致训练过程不稳定。
-
1.3 研究动机
论文的动机正是源于上述两种监督范式之间的根本性矛盾:我们既需要验证器的可靠性来保证学习的稳定性,又需要奖励模型的密集信号来提高学习的效率和处理复杂任务的灵活性。单纯依赖任何一方都存在明显的局限性。
因此,研究的核心问题转变为:如何设计一个有效的混合奖励框架,既能保留验证器的稳定性,又能充分利用奖励模型的细粒度信息?
2. HERO
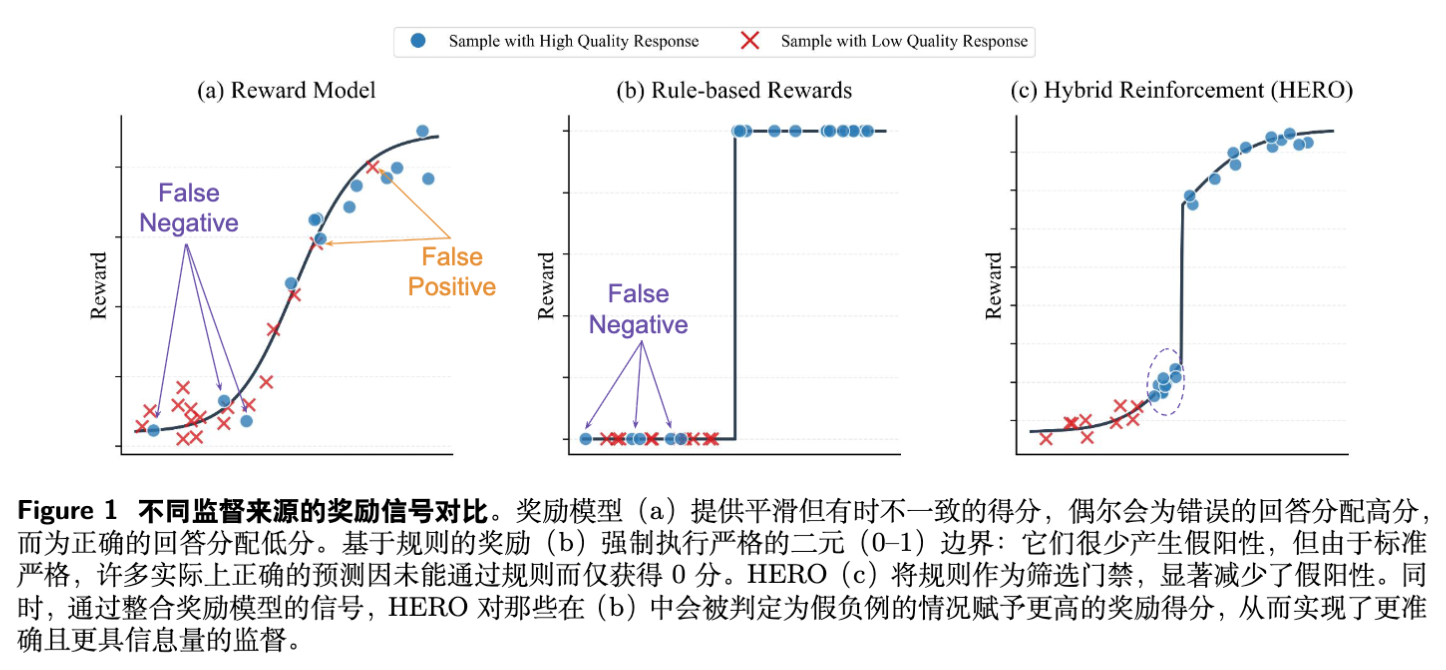
HERO (Hybrid Ensemble Reward Optimization) 框架的设计原则是:让基于规则的奖励继续主导整体的推理动态,而奖励模型则作为补充信号来丰富训练过程。为此,HERO 引入了两个核心组件:分层归一化和方差感知加权,见图 1c。
2.1 分层归一化
为了解决直接混合奖励信号导致的不稳定问题,HERO 提出了一种分层归一化的策略。其核心思想是,利用验证器的 0-1 判断作为“分层”的依据,将模型针对同一个 prompt 生成的一组(N 个)候选响应(rollouts)划分为两个互斥的集合:
-
正确响应组:通过了验证器检查的响应集合()。 -
错误响应组:未通过验证器检查的响应集合()。
然后,HERO 在每个组内部独立地对奖励模型(RM)给出的连续分数 进行 min-max 归一化,并将其缩放到一个预设的、不重叠的区间内。具体来说,最终的混合奖励 计算如下:
其中:
-
是当前响应的奖励模型分数。 -
和 分别是当前组内所有响应的奖励模型分数的最小值和最大值。 -
是超参数,用于控制错误组和正确组的奖励范围。例如,设置 ,则错误响应的最终奖励范围是 ,正确响应的奖励范围是 (论文中公式 (3) 的表达稍有不同,但核心思想一致,即将分数映射到特定区间)。 -
是一个很小的正常数,防止分母为零。
这种设计的价值在于:
-
保证正确性优先:通过将正确组和错误组的奖励区间严格分开(例如,所有正确响应的奖励始终高于所有错误响应的奖励),HERO 继承了验证器的权威性,确保模型优化的首要目标仍然是生成能够通过验证的正确答案。 -
在组内引入密集信号:在验证器看来,所有错误的答案都是一样的(奖励都为 0)。但通过分层归一化,HERO 使得奖励模型能够在错误组内部进行区分,比如一个接近正确的答案会比一个完全离题的答案获得更高的奖励(尽管总体仍然是负向或低奖励)。同样,在正确组内部,一个推理步骤更优雅的答案也可以获得比另一个仅仅是答案正确的答案更高的奖励。 -
解决梯度稀疏问题:即使所有候选响应都被验证器判为错误,HERO 依然能通过组内的奖励差异产生有效的学习梯度,从而避免了学习停滞。这对于模型在困难任务上的探索和学习至关重要。
2.2 方差感知加权
传统的强化学习算法(如 GRPO)平等地对待每一个 prompt。然而,不同 prompt 对模型训练的价值是不同的。对于一个 prompt,如果模型生成的所有响应质量都差不多(要么都很好,要么都很差),那么这个 prompt 提供的新学习信号就很少。相反,如果模型对某个 prompt 生成的响应质量参差不齐,说明模型在这个问题上存在较大的“不确定性”或“认知模糊”,这恰恰是信息量最大、最值得学习的地方。
为了让训练更高效,HERO 引入了一种方差感知加权机制。该机制根据奖励模型分数的标准差来动态调整每个 prompt 的重要性。对于一个 prompt,计算其 N 个响应的奖励模型分数 的标准差 。 越大,说明奖励模型对这些响应的评价差异越大,该 prompt 也就越“具有挑战性”和“信息量”。
HERO 定义了一个有界的单调权重函数 :
其中:
-
和 是最小和最大权重。 -
控制权重变化的陡峭程度。 -
是标准差的移动平均值,作为一个动态基准。
最终的奖励信号是分层归一化后的奖励与该权重相乘:
这种设计的价值在于:
-
提升训练效率:通过给高方差(困难、模糊)的 prompt 更大的权重,HERO 将模型的“注意力”和计算资源集中在最需要改进的地方。 -
避免在简单样本上过拟合:对于低方差(简单)的 prompt,其权重会被降低,避免模型在已经掌握的知识点上浪费过多的训练资源。
综上所述,HERO 通过分层归一化和方差感知加权这两个机制,构建了一个结构化的混合奖励系统。它不是简单地“和稀泥”,而是让验证器和奖励模型各司其职、优势互补,从而实现了更稳定、更高效的强化学习过程。
3. 实验设计与分析
为了验证 HERO 框架的有效性,论文进行了一系列实验。实验设计围绕着不同的训练数据、模型和评测任务展开,并与几个关键的基线方法进行了对比。
3.1 实验设置
-
模型:实验选用了两个不同规模的模型作为基础模型(backbone):
-
Qwen3-4B-Base:一个性能较强的模型。 -
OctoThinker-8B-Hybrid-Base:一个相对较弱的模型,用于验证方法在不同起点上的普适性。
所有强化学习实验都从一个经过监督微调(SFT)的“冷启动”模型开始,以保证比较的公平性。
-
-
训练数据:为了考察模型在不同验证难度下的泛化能力,论文构建了三种训练数据集,均来自 OPENMATHREASONING 基准:
-
易于验证(Easy-to-verify):包含 2000 个能被基于规则的 math_verifier确定性验证的问题。 -
难以验证(Hard-to-verify):包含 2000 个答案格式更灵活、规则验证器容易出错的问题。 -
混合数据(Mixed):包含 1000 个易于验证和 1000 个难以验证的问题。
-
-
基线方法:HERO 的性能主要与以下两种方法进行对比:
-
仅奖励模型(RM-only):只使用 AceMath-RM-7B 奖励模型提供的密集分数作为奖励信号。 -
仅验证器(Verifier-only):只使用基于规则的 math_verify提供的 0-1 稀疏信号作为奖励。
这两种基线恰好对应了 HERO 试图结合的两个信号源,因此是非常有说服力的对照组。
-
-
评测任务:评测数据集也分为两类:
-
易于验证的测试集:包括 MATH500, AMC, Minerva, Olympiad 四个基准,使用 math_verifier进行自动评测。 -
难以验证的测试集:包括 HardVerify-Math (HVM) 和 TextBookReasoning (TBR) 两个基准。由于这些任务没有可靠的自动验证器,评测采用了 LLM-as-a-judge 的方式,即使用 GPT-4o 来判断模型输出是否正确。
-
3.2 核心实验结果分析
实验结果清晰地表明,HERO 在几乎所有的训练和评测设置中都优于两个基线方法。
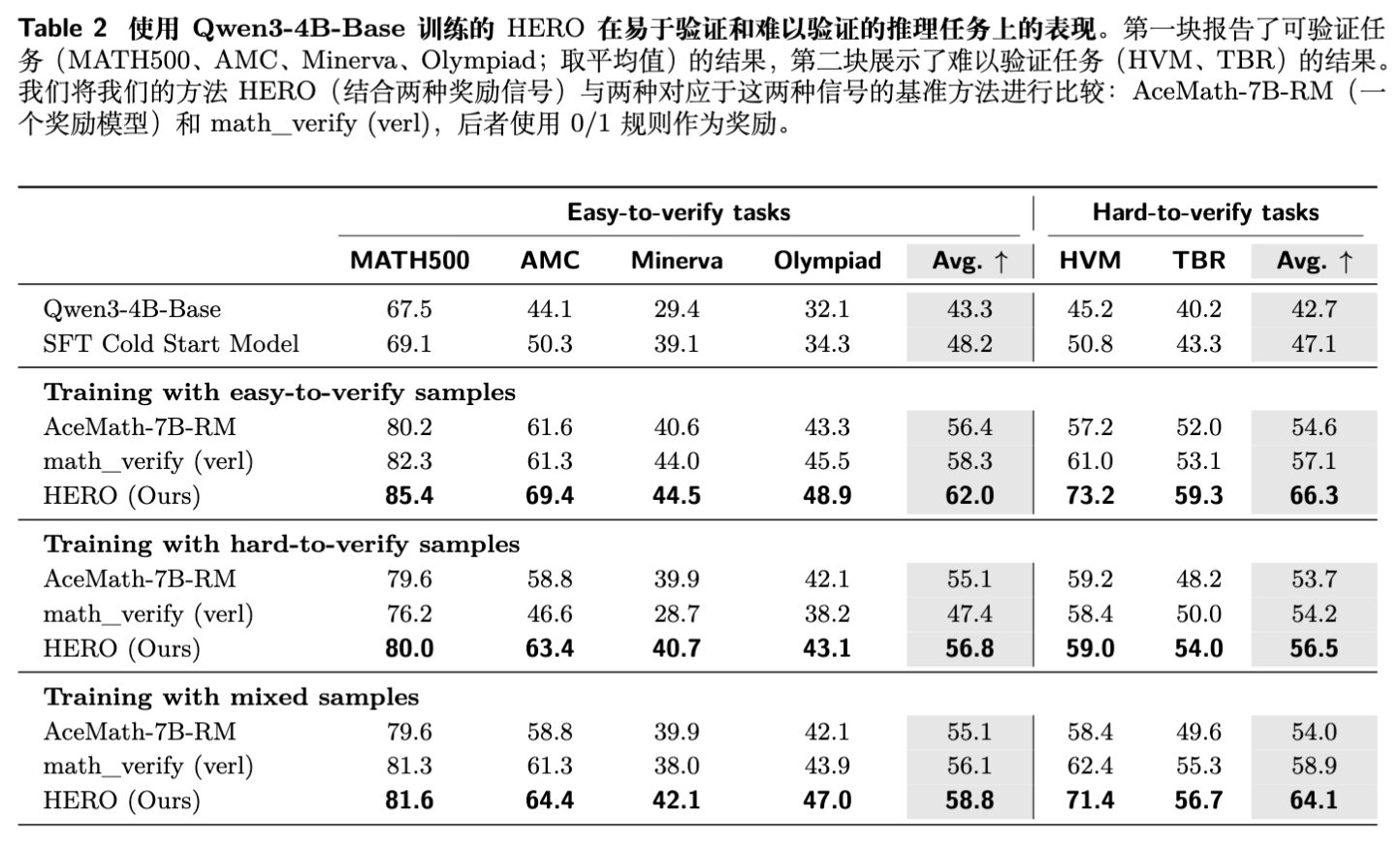
观察 1:HERO 在所有训练数据类型上都表现出色。
-
当使用易于验证的数据进行训练时,HERO 在易于验证的测试集上平均分达到 62.0,高于 RM-only (56.4) 和 Verifier-only (58.3)。在难以验证的测试集上,优势更为明显,HERO 达到 66.3,远超 RM-only (54.6) 和 Verifier-only (57.1)。 -
当使用难以验证的数据训练时,规则验证器本身就很不可靠,导致 Verifier-only 的性能大幅下降(在易验证任务上仅为 47.4)。此时 HERO (56.8) 仍然能够超过 RM-only (55.1) 和 Verifier-only (47.4)。 -
在混合数据训练下,HERO 同样在两个测试集上都取得了最高的平均分。
观察 2:HERO 在难以验证的任务上具有优势。
这是 HERO 设计中最有价值的部分。在 HVM 和 TBR 这类任务上,规则验证器因为其脆弱性而难以提供有效信号,而奖励模型又容易产生信号漂移。HERO 通过分层归一化,用验证器(即使不完美)来“锚定”奖励信号的范围,有效防止了奖励 hacking,同时利用 RM 的密集信号来学习部分正确或格式新颖的答案。例如,在易验证数据上训练后,HERO 在难验证任务上比 RM-only 高出 11.7 分,比 Verifier-only 高出 9.2 分,这是一个相当大的提升。
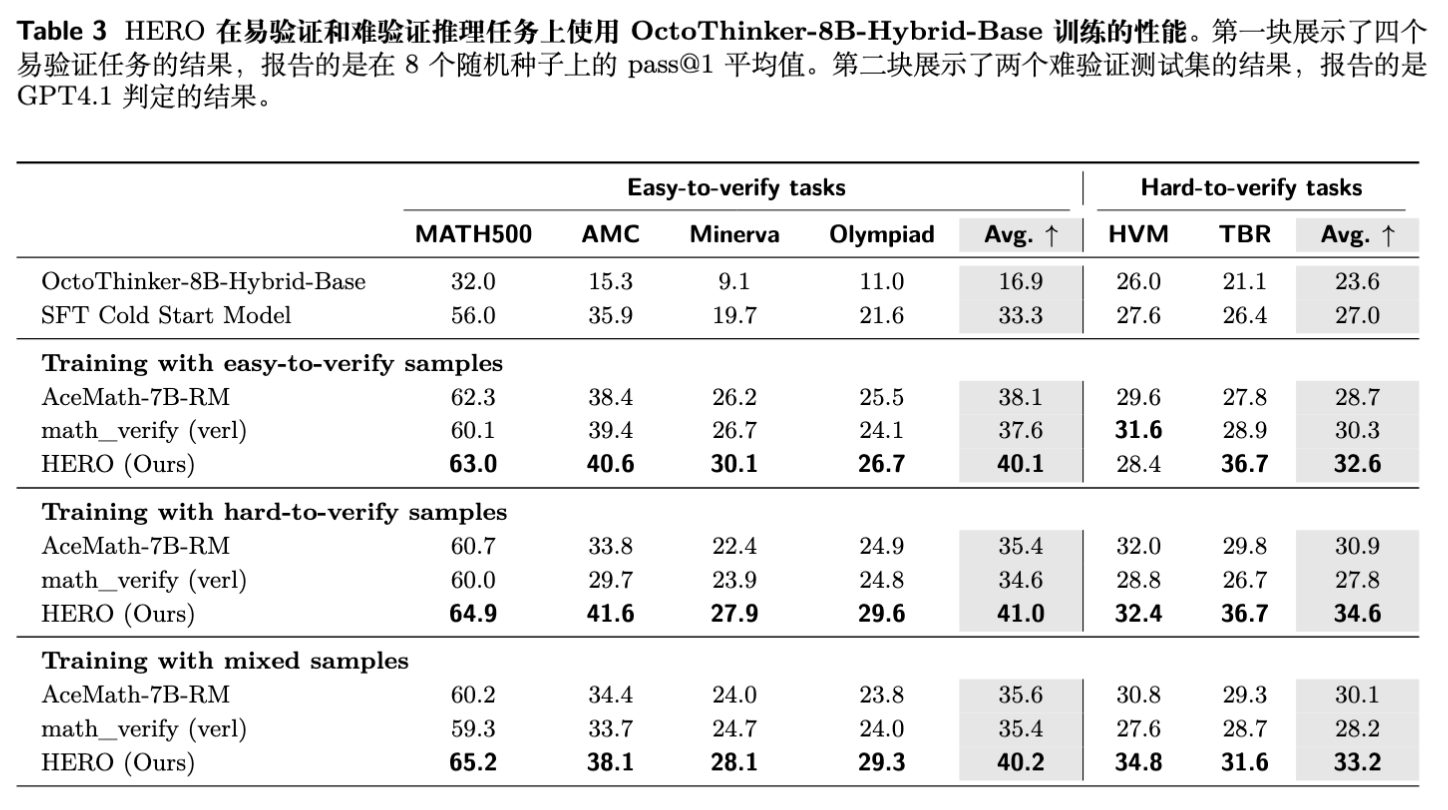
观察 3:HERO 对弱模型提升效果更显著。
在基础性能较弱的 OctoThinker-8B 模型上,HERO 带来的提升更加突出。Verifier-only 的方法在弱模型上更容易因为所有 rollouts 都得到相同(0 或 1)的奖励而导致学习停滞。而 HERO 引入的组内密集奖励信号可以维持有效的梯度流,使模型能够持续学习。实验结果显示,HERO 在所有设置下都比基线方法高出 4-6 个点,证明了该框架的鲁棒性和普适性。
3.3 消融实验与分析
为了进一步探究 HERO 各个组件的作用,论文还进行了一系列消融实验。
-
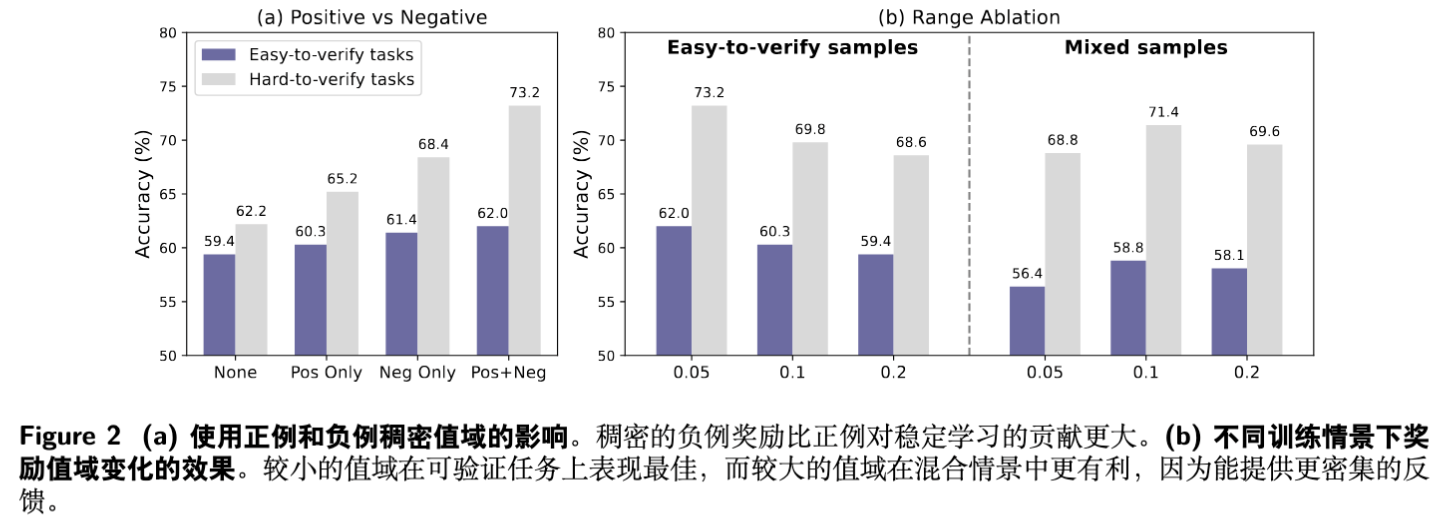
正负奖励范围的作用:实验发现,在错误响应组(负奖励范围)中引入密集信号比在正确响应组中引入密集信号更为重要。这是因为惩罚多样化的错误能够提供比奖励相似的正确答案更丰富的学习信号,帮助模型更好地理解“为什么错”以及“如何改进”。
-
奖励范围大小的影响:对于易于验证的任务,一个较小的奖励范围(如 )效果最好,这说明当验证器足够可靠时,我们只需要奖励模型提供微调信号即可,过大的范围反而会引入噪声。而对于混合任务,需要一个更大的范围来让奖励模型在验证器失效的样本上发挥更大作用。
-
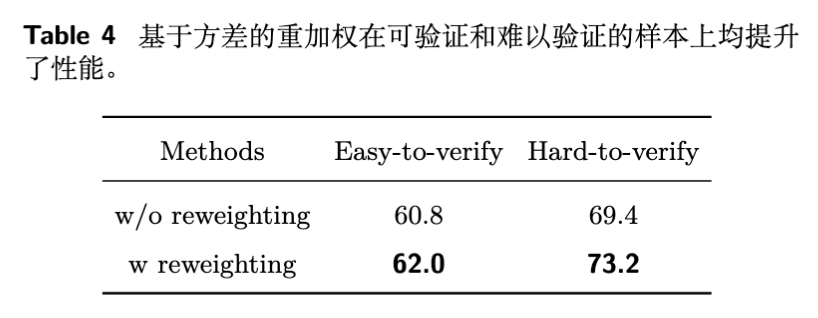
方差感知加权的作用:消融实验证实,加入方差感知加权后,模型在易于验证和难以验证的任务上性能都有提升,尤其是在难以验证的任务上提升了 3.8 个点(从 69.4 到 73.2)。这说明将训练资源向困难样本倾斜是一种有效的策略。
-
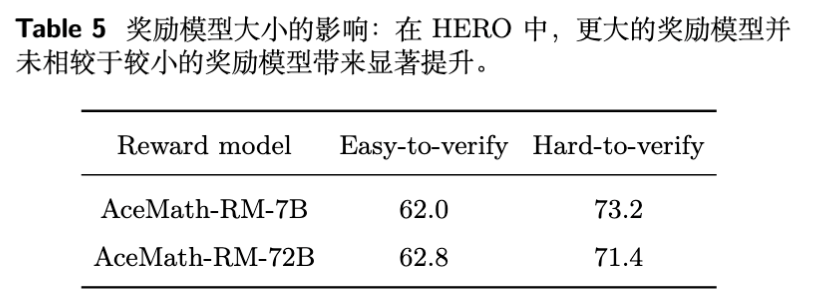
奖励模型大小的影响:一个有趣且重要的发现是,将 HERO 中的 7B 奖励模型换成一个更大的 72B 奖励模型,性能并没有显著提升,在难以验证的任务上甚至略有下降。这表明 HERO 的性能增益主要来自于其结构化的奖励设计,而非奖励模型本身的大小。这一结论对于方法的实用性和部署成本具有积极意义。
4. 总结
总的来说,这篇论文提出了 HERO 框架,该框架通过结构化的方式融合了验证器的稳定性和奖励模型的细粒度,在多个数学推理基准上取得了优于单一信号源方法的效果。
往期文章:


